
Abstract
Performance optimization is one of the important goals that every application developer always wants to pursue, no matter if the application is for a general desktop Windows computer or an Android device. Android is a resource-limited system and thus requires very strict resource utilization in space and processing time. Compared with a desktop system, the performance optimization for Android applications is therefore far more critical.
You have full access to this open access chapter, Download chapter PDF
Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
Like so many other things in life, you rarely get only what you optimize for.
— Erik Naggum
Performance optimization is one of the important goals that every application developer always wants to pursue, no matter if the application is for a general desktop Windows computer or an Android device. Android is a resource-limited system and thus requires very strict resource utilization in space and processing time. Compared with a desktop system, the performance optimization for Android applications is therefore far more critical.
Different applications require a different focus for optimization. Performance optimization for an Android system generally falls into three categories:
-
Optimization of the application’s running speed
-
Code size
-
Optimization for lower power consumption
Generally speaking, storage space and cost for Android on Intel Atom is not a bottleneck, so in this chapter, we will focus on performance optimization that makes an application run faster.
We will first introduce the basic principles of SOC performance optimization. We’ll follow that with an introduction of principles and methodologies of performance optimization for Android applications running on Intel architectures. We will discuss application development for Android using the Native Development Kit, and share specific case studies using the certain tools such as the Intel Graphics Performance Analyzers.
Basic Concepts of Performance Optimization
Optimization aims at reducing the time needed to complete a specific task accurately and according to specification. This is achieved by structural adjustments, or refactoring, of the application based on the optimization of either hardware or software.
There are several basic principles related to the results of the performance optimization of an application that need to be followed:
-
Equal-value principle: There is no change in the result of application execution after performance optimization.
-
Efficacy principle: After performance optimization, the targeted code runs faster.
-
Combined-value principle: Sometimes, performance optimization gains performance improvement in certain aspects, but degrades performance in others. Combined overall performance needs to be considered when deciding whether or not a performance optimization is needed.
One of important considerations for performance optimization is trading time with space. For example, in order to do a function calculation, the values of the function can be pre-calculated and put into a program storage zone (memory) as a table. When a program is running, instead of spending time on doing repetitive calculations of the function to get the value, the program can directly get the value from the table in order to reduce the execution time. For search operations, this could be done on a large space using hash methods.
The approach picked most frequently for performance optimization is the reduction of the instructions and executions frequency. For example, from the point of view of data structures and algorithms, the instructions for comparison and exchange in bubbling sequencing need to execute O(n2) times. However, by using a quick sort, the instruction time reduces to O(n log n) times. In loop optimizations, code compilation can extract irrelevant public code out of the loop and reduce the execution time of public code from n to 1, thus dramatically reducing the execution frequency. In addition, in-line functions supported by C and C++ can be used to change function calls, the instruction of function calls, and the implementation of the return instructions.
Selection of a Faster Instruction
The same function can be realized by utilizing different instructions. Different instructions take different machine clock cycles, and thus the execution times are quite different. This gives us the opportunity to choose to use a faster instruction.
Reducing computational strength is a typical example of performance optimization achieved by selecting a faster instruction set. For example, to multiply an integer by 4, the operation can be done by shifting the operator two digits to the left to complete. The shift instruction takes much fewer clock cycles and runs much faster than multiplication and division instructions.
Another example of this category of optimization is to use special instructions provided by the hardware to replace the generic instructions for faster instruction execution. For example, the Intel Atom processor provides Streaming SIMD Extensions (SSE) instruction set support. For vector operations, SSE instructions should always be used to accomplish the operation, as they run much faster due to the benefit of instruction-level parallel processing. The ordinary addition instruction width for Intel Atom is 32 bits, while SSE instructions are capable of four times 32-bit data processing. As a result, the optimized codes using SSE instructions shorten the time consumed dramatically.
Improve the Degree of Parallelism
The degree of parallelism can be improved at multiple levels, including instruction, expression, function, and threads.
Many modern embedded processors including the Intel Atom processor support instruction pipeline execution. This enables an optimization method called instruction-level parallelism. A code chain can be decomposed of several units of code that are not dependent on the chain and can be executed in parallel in the pipeline.
In addition, many embedded system processors, such as the Intel Atom processor, physically support the concurrent execution of threads. The use of an appropriate number of concurrent threads rather than a single thread can increase running speed. In order to take advantage of thread concurrency optimization, programmers need to consciously adopt multithreading technology; sometimes optimization needs to be done with compiler support.
Effective Use of the Register Cache
Writes and reads that go to and from the cache registers are much faster than those that go to and from memory. The goal of cache optimization is to try to put data and instructions that are being used and will be used often into the cache in order to improve the cache hit rate and reduce cache conflicts. Cache optimization often appears in the optimization process for a nested loop. Register optimization involves effectively using the register and keeping frequently used data in the register as much as possible.
Cache is based on locality. That is, cache assumes the data to be used is located in the most recent data that is already in use or is in the vicinity of their own register. This is called the locality principle or principle of locality, and it deeply affects hardware, software, and system design and performance. Instructions and data required by the processor are always first read by cache access. If high-speed cache has the needed data, the processor always accesses high-speed cache directly. In this situation, such an access is called a high-speed cache hit. If high-speed cache does not contain the needed data, this is referred to as a failed hit or cache miss.
If this happens, the processor needs to copy data from memory to high-speed cache. If the corresponding location of high-speed cache already is already occupied by other data, the data that are no longer needed in cache will need to be expelled and written back to memory. Failed hits will result in a sharp rise in access time; therefore the goal in increasing cache efficiency is used to improve the hit rate and lower failure rates. The data exchange between cache and memory is performed via a block unit, which is used to copy needed data or write-back blocks into memory.
Locality describes the way that accessed or referenced data locations are collected into predictable clusters for easy future reference by the processor. There are two important cases of locality, explained briefly as follows:
-
Spatial locality: When a particular data object is referenced, it is statistically likely that nearby data will be referenced in the near future. A section of adjacent data is marked off as a single block for the processor to gain faster access to that location.
-
Temporal locality: When a particular data object is referenced, it is also statistically likely that the same data will be referenced again in the near future. The referenced data is moved into cache memory so that it can be referenced more quickly in its new location.
Methodology of Performance Optimizations
There are many methods and techniques for performance optimization. One or more comprehensive optimization principles can be utilized simultaneously, such as modifying the source code to run faster. According to the type of criteria for the classification, optimization methods can be divided into different categories.
Machine-dependent optimization can be done only on specific hardware or architecture. For example, the optimizations of switching ordinary vector instruction computing to SSE instructions, which are dependent on many low-level details of the Intel Atom processor, can only be used on the Intel processors that support SSE instructions. It is difficult to use this optimization on other machines with different architecture, such as ARM, or unspecified architectures. In general, the complexity of a machine-independent optimization is higher than that of the machine-dependent optimization and difficult to achieve.
Performance Optimization Approaches
In the ideal scenario, the compiler should be able to compile any code that we write and optimize it into the most efficient machine code. But the reality is that the compiler can actually automate only some of all possible optimizations because some optimizations may be blocked by default by the compiler’s optimization blocker. In general, depending on how much of a role the human or automated tools will play, the performance optimization approaches can be divided into three main categories:
-
Performance optimizations done automatically by a compiler
-
Performance optimizations done with the assistance of development tools
-
Performance optimizations done manually by a programmer
The following sections present several approaches and methods for developers to achieve performance optimization.
Performance Optimizations Automatically Done by a Compiler
Modern compilers automatically complete the most common code optimizations. These automatic optimizations done by a compiler are also known as compiler optimizations or compiling optimizations. A compiler optimization needs to be triggered by the appropriate extensions option or switch variable.
C/C++ code optimization for Android applications can be achieved by the GNU Compiler Collection tools located in the Native Development Kit. We will cover this topic in detail in the next chapter.
Performance Optimizations Assisted by Development Tools
It is very difficult to achieve an overall comprehensive optimization of a large program. Fortunately, for applications based on Intel architecture, many useful tools are available to help the user complete the optimization. For example, Intel Profiler, Graphics Performance Analyzer (GPA), Power Monitoring Tool, and other tools can help users to analyze a program and guide them through complete optimization.
VTune and GPA are part of Intel’s product development tools and can only be used for Intel processors such as the Intel Atom processor. Intel Profiler is a GNU chain tool and can be used for all types of processors. It can be used to create a profiling process that shows which areas of the program execute frequently and use more computing resources and which areas are less frequently implemented. The profiling data provides valuable information for developers to complete the optimization.
A typical example of profile-guided optimization (PGO) is the optimization of the switch statement (such as the switch-case statement of C#). In this example, according to the profile of the collected sample run, after getting the actual frequency of occurrence of each case statement, the case statement is sorted in the switch statement by frequency sequence. The most frequently occurring statements are moved to the front (the performance of these statements require a minimum number of comparisons), so as to achieve optimal results with the least number of comparisons. In GNU terminology, the process is known as profile-guided optimization (PGO).
Like the GNU Profiler, Intel VTune is capable of locating hotspots in the program. The hotspot zone refers to the segment of programming code that takes a long execution time (which means more computing power). With VTune, programmers can find the time-consuming code segment and then take measures to optimize that code. VTune has a much higher resolution (fine granularity) and more functions for positioning the hotspot than the GNU profiler, including displaying the assembly code of the program, failed cache hits, and branch misprediction events for Intel processors.
Intel GPA was originally a development tool used for graphics processing unit (GPU) analysis. It has now been developed into a comprehensive tool for CPU speed analysis, customization, and device power consumption analysis. Intel GPA can be used to get CPU load, operating frequency, and power consumption information. It can guide the user to optimize the application, especially multithreaded optimization. Intel GPA is not only a speed optimization tool but also a very handy power optimization tool.
With optimization tools, developers no longer need to get disoriented and confused when trying to find a starting point for optimization of a large program. These tools allow you to easily locate the areas that are most in need of optimization, which are the codes segments that are potentially the most problematic. Quickly finding the hotspot allows you to achieve your optimization with less time and effort. Of course, typical performance optimization is complicated. The tool only plays a guiding and supporting role—the real optimization still needs to be completed by the compiler or developer manually.
Use of High-Performance Libraries
High-performance libraries are sets of software libraries that are usually developed by a hardware original equipment manufacturer (OEM) and which provide some commonly used operations and services. These library codes are carefully optimized based on a combination of processor features and have higher computing speeds than ordinary codes. In short, high-performance databases are libraries optimized through various methods that utilize the full potential of the processor. For example, Intel Integrated Performance Primitives (Intel IPP) libraries have been optimized based on SSE instructions for the processor, hyper-/multithreaded parallel pipelined execution, and a waterfall process. Compared with nonoptimized code, Intel IPP libraries can increase the processing power of Intel processors and save power consumption. For some important code and algorithms, using high-performance libraries is actually a simple, practical optimization method and offers the benefit of “standing on the shoulders of giants.” Intel IPP is one of Intel’s high-performance libraries. It is a library of functions for Intel processors including the Intel Atom processor and Intel Chipsets. Intel IPP is powerful; it can be used for mathematical calculations, signal processing, multimedia, image and graphics processing, vector calculations, and other fields. Intel IPP uses a C/C++ programming interface.
Performance Optimizations Done Manually
In various stages of optimization, the human factor should not be ignored. Some high-level global optimizations, such as the optimization of algorithms and data structures, cannot be done by a compiler automatically. The optimization must be completed manually by people. As a programmer, in order to write efficient code, it is necessary to learn the various algorithms and optimization techniques to develop good programming habits and style. Even if the compiler can automatically complete the optimization, additional assistance from the programmers is still needed to write efficient code at the following levels:
-
Source code (that is, high-level language) level optimization: This optimization is done by the programmers at the source code level. The programmer uses the expression of a high-level language source code to modify and transform the program.
-
Assembly language level optimization: Sometimes using high-level language is not enough to reach the optimal results, and programmers may need to modify the codes to bring them down to the assembly-language level. In some key computing areas, although the process of assembly-level optimization is cumbersome, the performance benefit of the outcome is worth it.
-
Compiling instruction-level optimization: This is an optimization accomplished by performers through additions and modifications of compiler directives, such as the typical compiler directive modification “pragma” and/or increasing the degree of parallelism in OpenMP.
Program-interactive optimization is truly a reflection of the art of the programming, and the level of accomplishment fulfills the ideal of the “unity of human and machine.” This unity is the focus of this chapter. Relatively speaking, optimizations performed at the compiling phase of the assembly-language level or the instruction level require a programmer to have comprehensive expertise in processor architecture, hardware, system, and so on. As a result, for Android systems on Intel architecture, we recommend the performance optimization at the source-code level. In the following example, we focus on the introduction of performance optimization on Android multithreaded design.
There is no doubt that optimization can be done in several ways that are related to each other and structurally undividable, while each has its own unique function. The overall process is shown in Figure 9-1.

Recommended User Optimization
As Figure 9-1 shows, compiler optimization, manual optimization, and high-performance library functions are tied together. They are final steps in optimization. The use of both manual optimization and high-performance libraries is needed in order to modify the source code. Before starting those optimizations, analyzing the programs using optimization tools has proved to be very beneficial to developers and is a must-have step.
Performance Tuning with Intel VTune
For the Linux platform, profile analysis is the most important type of software performance analysis. Profile analysis generally involves the user analyzing and identifying the source code that needs to be optimized with the assistance of various tools. The best tool for the analysis of the performance profile of software running on Intel processors is the Intel VTune family of products.
Intel VTune Performance Amplifier (commonly referred to as VTune analyzer or VTune) is performance analysis software and a useful optimization tool for Intel processors. With the capability to analyze the program’s performance, VTune can assist and guide the programmers and compiler to optimize various applications. VTune provides a user-friendly graphical user interface that does not require you to recompile the application. Performance analysis can be done directly on the executable application. VTune is applicable to a wide range of applications from embedded systems to supercomputers, has cross-platform capability, and can run on Android, Tizen, Windows, Linux, Mac OS, and so on.
VTune is based on a hotspot area analysis to guide and support the performance optimization of the application. Hotspots are code segments that require excessively long execution times. In addition to the hotspot analysis, the user needs to consider what causes the hotspot and how to resolve it. For advanced users, VTune can be used to track key function calls, monitor special CPU events (such as a cache miss), and perform a series of other advanced features.
Intel has continuously added features to VTune Performance Analyzer, and in 2012 it renamed the tool. Formerly known as Intel VTune Performance Analyzer with an Intel Thread Profiler, the company changed its name to Intel VTune Amplifier XE. The updated tool includes all of the features and functionality of the Intel Parallel amplifier and also has some advanced features for programmers who need to explore issues in depth. Its main functions are described in the following sections.
As shown in Figure 9-2, the VTune Performance Amplifier lists the entire elapsed time of the program as well as information on the top five most time-consuming functions (when the functions of the program are less than five, it lists only the actual function number), such as the percentage of elapsed time of the total elapsed time of entire program used by the top five functions.

VTune Elapsed Time and Statistics
VTune provides run-time statistics that as specific as pointers to individual lines of code, which can help users to locate which sections of code are the most time-consuming. As shown in Figure 9-3, VTune displays the running time of the program source code statements (ticks, clock ticks) occupied by the percentage of the total time consumed and instructions completed (instructions retired).

VTune displays the most time-consuming lines of source codes
VTune shows the program function call relations in an intuitive way in a call graph as shown in Figure 9-4, in which the function calls are displayed in graphical form. Highlighted in the display, the function call relationship from the root to the current function is called the critical path (also known as focus function).

VTune Call Graph for a Function Call Relationship
VTune can be displayed directly in an assembly code in the source code corresponding to the target file. Figure 9-5 shows the assembly code corresponding to the function of a program. With this feature, users can do a compilation analysis, locate the time-consuming code, and perform assembly-level optimization.

Assembly Codes and Source Codes in VTune
VTune provides a graphical interface that displays the statistics for time and other processor events, including cache miss, branch misprediction, and other information. Figure 9-6 shows the statistics for processor events corresponding to four threads of the application. Each of the four threads includes three bars: the top bar, which represents the average consumption of the number of clock ticks of executing instructions that occurred (Clockticks per Instruction Retired); the middle bar, which shows the highest number of clock ticks consumed (Clockticks); and the bottom bar, which indicates the instruction that has been completed (Instructions Retired).

VTune Display of Other Processor Events
VTune can display the CPU usage of the application and the distribution of the degree of concurrency for an application. Information can be used to analyze the degree of parallelism. Figure 9-7 is a 1000HC screenshot of an application on a device using the Intel Atom N270 processor.

Thread and CPU Usage Distribution
The Intel Atom N270 is a single-core processor, but it supports Intel Hyper-Threading Technology. The application uses two threads to calculate a degree of parallelism of the moment shown in Figure 9-7. The CPU utilization (CPU time) can be up to 200 percent.
By comparing the VTune features previously described, we can classify these features by how the tuning is used (optimization analysis). In summary, the VTune function tuning can be divided into the three levels described in the following sections.
System Tuning
System tuning is what VTune Amplifier XE is designed for but is not the main goal of application optimization. The purpose of system tuning is to change the hardware configuration, such as network bandwidth, disk read/write operations per second, and hit failure, on the memory page. System tuning and optimization are mainly for the original equipment manufacturer’s products. However, as an advanced tool, VTune can also be used to reach certain auxiliary optimizations, such as the lock and wait analysis. Here, VTune can measure the waiting time of the network socket object to complete disk write I/O, which can be configured to reduce the thread-to-block waiting time. Another use to run a hot spot analysis and find a hot spot. If the results are applicable, you can parallelize your code by manually adding threaded tasks or you can use the compiler to automatically parallelize the code using Intel Thread Building Blocks (Intel TBB). Of course, you can also adjust or tune the algorithm by checking the function-call relationship and removing duplicate computing to reduce the number of function calls.
In another scenario, where the program has been parallelized, you need VTune to run parallel analysis to determine the degree of parallelism of the program and hotspot analysis to find the hotspot as well as the degree of parallelism at the hotspot. When the degree of parallelism at the hotspot is low (such as in the case of functions consuming most of the CPU time where the thread is not parallel to the other threads), the two possible causes are uneven distribution of the tasks of each thread, which can be optimized by adjusting the algorithm, and thread blocking (wait time), which is caused by shared resources or a “lock” held by another thread. You can use VTune to do lock and wait for the analysis to find out the cause of obstruction. In this case, you need to determine whether the possession of the shared resource in the other threads is needed and time is optimized. The solution is to reduce the hot zone as much as possible to reduce data dependencies or use the locks that are more “lightweight.”
Tuning Based on the Microarchitecture of the Processor
When the tuning is based on the processor’s microarchitecture, developers are often required to have detailed knowledge of the processor. This often gives application developers a hard time, but processor-specific tuning is necessary when too many hotspots are found (or too many hotspot functions are called) in the hotspot analysis. Of the two different levels of tuning previously described, algorithm tuning is the most useful for application optimization.
VTune’s two modes
When VTune is in local mode, the analysis of the program being tested and VTune itself work on the same machine. In remote mode, the testing of the application takes place on one machine and VTune is installed on another machine. For desktop machines, VTune is generally used in local mode, which is relatively simple. The Android system is commonly used in remote mode. Here, VTune is installed on an Ubuntu/Win/MAC development system, where most development and the SDK are located, and the Android device is connected to the development system by a USB network cable or a Wi-Fi network.
Intel offers a free trial version of VTune for noncommercial use, which generally lasts for one year. Special discount prices for student and academic institutions are also available. Readers can go to Intel’s official web site ( http://www.intel.com ) to download the Linux version of VTune Amplifier XE. Before downloading, Intel will let you fill in your email information, and the serial number will be sent to you. The following is an excerpt from the Intel VTune Amplifier XE 2011 download.
You have registered Intel VTune Amplifier XE for Linux* (formerly VTune Performance Analyzer for Linux*). You will be receiving an email which includes the serial numbers listed below as well as the download links for your future reference:
… …
Serial Number:XXXX-XXXXXXXX
File to download: Install Package for IA-32 and Intel 64 (143 MB)
... ...
Intel VTune Amplifier XE for Linux*
Download:
Install Package for IA-32 and Intel 64
......
When readers go to the download link, the serial number will be shown as XXXX-XXXXXXXX. Download the software package entitled vtune_amplifier_xe_2011_update4.tar.gz (file size about 150 MB) to your local drive and install.
Note that to install and use VTune on an Android device, you will need the corresponding driver support. The driver needs to be compiled and generated using Android course codes. Typical users rarely have access to or are familiar with the source code of the Android devices. Driver preparation is generally produced by the Android device OEM. Most manufacturers are reluctant to install related drivers to commercial-grade devices (such as mobile phones), and even root privileges are not open. For non-OEM users, using VTune locally on an Android device is still a challenge, as there are some system-level configurations that only Android system engineers can handle. However, Intel is stepping up development and improving the use of VTune on Android, and it is estimated that in the near future, application developers, students, and the academic world can get access to the powerful VTune tool and use it locally on an Android device.
Intel Graphics Performance Analyzers
Intel Graphics Performance Analyzers (Intel GPA) are a suite of optimization and analysis tools used only for Intel processors that support Intel Core and Intel Atom processor-based hardware platforms. Intel GPA provides a graphical user interface for the CPU/GPU speed analysis and customization features. It enables developers to find performance bottlenecks and optimize applications for devices based on the Intel chipset platform. Intel GPA consists of the System Analyzer, Frame Analyzer, and the Software Development Kit (SDK).
Introduction
Intel GPA supports all Android devices running on Intel Atom processors. The suite offers the following features:
-
A real-time display of dozens of key indicators including CPU, GPU, and OpenGL ES API
-
Several graphics pipeline tests, which are provided instantly to isolate graphics bottlenecks
-
Compatibility with Microsoft Windows or Ubuntu OS as host development systems
Intel GPA currently only supports real Android devices using Intel Atom processors – it does not support analysis of the Android Virtual Device (AVD). Intel GPA for Android uses a typical hardware deployment model often used in Android application cross-development, in which the host system (Windows or Ubuntu) and the target device (Android Intel-based devices) are connected via a USB connection to monitor Android applications. Android GPA operates on the Android Debug Bridge utility (adb, here tied to a local server) to achieve the monitoring of the application on the target Android devices. The adb (server) runs on Android devices, and the GPA runs on the host system as the adb client applications to achieve target machine monitoring. The GPA configuration is shown in Figure 9-8.

Intel GPA Configuration for Monitoring Applications on an Android Device
Developers should be cautious given that Intel GPA is based on adb to work. Since both Eclipse and DDMS also use adb, Intel GPA may not work properly if GPA, DDMS, and Eclipse are running at the same time due to a server conflict. It is best to turn off other Android software development tools, such as Eclipse or DDMS, when using Intel GPA. Figure 9-9 shows the Intel GPA graphic interface in the process of monitoring an app running on an Android device.

GPA Graphic Interface Monitoring an App Running on an Android Device
As shown in Figure 9-9, which is screenshot for a Lenovo K800 smartphone, the GPA interface displays two frames and a toolbar pane. The Metrics toolbar displays the indicators being measured, which are organized in a tree structure, as follows:
-
Under the CPU metric are the Aggregated CPU Load, the CPU XX Load, the CPU XX Frequency, the Target App CPU Load, etc. The CPU XX numbers are determined by how many CPUs are monitored by Intel GPA. To get CPU information such as the number of cores, model, and frequency, we can use the cat/proc/cpuinfo command at a terminal window. The Lenovo K800 smartphone in the figure uses a single-core Intel Atom Z2460 processor. The figure shows two logical processors as the processor supports for Intel Hyper Threading Technology (Intel HTT). Thus, the two items shown in CPU Load and CPU Frequency are indexed as 00 and 01. In CPU XX Load, XX is the CPU number: it displays the load status for CPU XX, while CPU XX Frequency displays the frequency status for CPU XX. The Aggregated CPU Load is the total load of the CPU. The Target App CPU Load is the CPU load of the app on the target device.
-
Under the Device IO metric are the Disk Read, the Disk Write, the Network RX, and the Network TX items, which list the statuses and information for the disk read, disk write, and packets sent and received over the network, respectively.
-
Under the Memory metric are App Resident Memory, Available Memory, etc.
-
Under the Power metric are Current Charging and Current Discharging, which provide the status of charging and discharging.
By default, the right pane shows two real-time status display windows. These windows display the oscilloscope-like status of the specified indicators. The horizontal axis features the elapsed time and the vertical axis features the value of the corresponding indicator. The user can drag and drop an index entry from the left pane to one of two windows and the real-time indicator of the entry will be displayed in the window. In Figure 9-9, in which the CPU 00 Load has been dragged and dropped to the top display window and the CPU 01 Load onto the bottom display window, the vertical axis shows the CPU utilization. The maximum utilization is 100 percent.
Above the real-time status display window is the toolbar, offering tools such as taking a screenshots and pausing the display. Users can use these tools to achieve some auxiliary functions.
Installation
Hosting Intel GPA can be done in Windows or Ubuntu. The following section gives examples of the Intel GPA installation process for the Windows platform. Users can refer to Intel GPA release notes or related Intel GPA web site for the installation process and usage on the Ubuntu platform.
Intel GPA requires having version 4.0 or higher of the .NET Framework installed to run on the Windows platform. The installation of Intel GPA on the Windows platform consists of two major steps: the first step is to install the .Net Framework and the second step is the real Intel GPA installation. Detailed step-by-step instructions for installing Intel GPA on Windows host platform follow.
-
1.
Install .Net Framework.
.Net Framework v4.0 is used for these instructions. Make sure the latest Windows service pack and critical updates are installed on your computer. If the platform is a 64-bit version of XP or Windows 2003, you may need to install the Windows Imaging Component. To install it, visit http://www.microsoft.com/en-us/download/details.aspx?id=17851 and download .Net Framework 4.0.
Next, double click dotNetFx40_Full_setup.exe. The pop-up window interface shown in Figure 9-10(a) appears to start the installation. Follow the step-by-step installation prompts to complete the installation.
Figure 9-10. 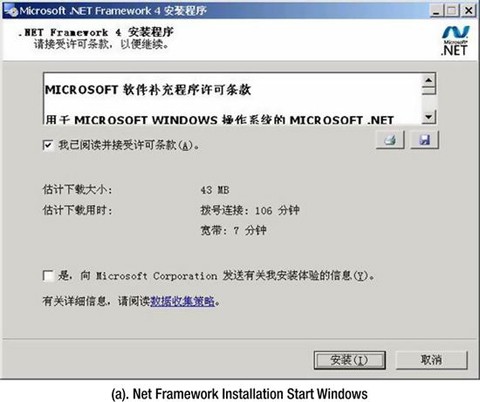
Net Framework 4.0 Installation Interface
-
2.
Install Intel GPA
The installation prerequisites follow: Make sure the latest Windows service pack and critical updates are installed on your computer. Users can go directly to the official Intel web site to download Intel GPA (here, version gpa_12.5_release_187105_windows.exe is used for the test): http://intel.com/software/gpa or http://software.intel.com/en-us/vcsource/tools/intel-gpa , as shown in Figure 9-11. Double click gpa_12.5_release_187105_windows.exe to run the program. This is a self-extracting file. Uncompressed files are saved into the same folder where the original file is located. Double click the setup.exe in the extracted folder to install.
Figure 9-11. 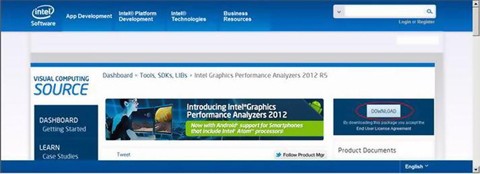
Intel GPA Software Download Site
Double click gpa_12.5_release_187105_windows.exe to run the program, which is a self-extracting file; uncompressed files are saved into the same folder where the original file is located.
Next, double click the setup.exe in the extracted folder as shown above to install.
If .Net Framework is not installed, the Intel GPA Prerequisite Setup will appear and prompt users with the necessary information, as shown in Figure 9-12.
Figure 9-12. 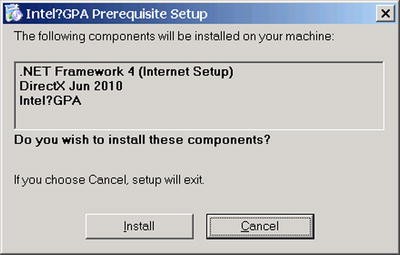
Intel GPA Installation Pop-Up that Appears When .Net Framework Is Not Found
Click the Install button. The dialog box appears as shown in Figure 9-13.
Figure 9-13. 
Installation Dialog Box
One you have installed the prerequisites, you will be returned to the first step to install Intel GPA. The installation progress bar for Intel GPA is shown in Figure 9-14.
Figure 9-14. 
Progress Bar for the Installation of Intel GPA
Once Intel GPA loads, as shown in Figure 9-15(a), click Next to continue. Intel GPA will test for compatibility and hardware support and remind you of the next step, as shown in Figure 9-15(b). Click Confirm to continue.
Figure 9-15. 
Message Boxes for Intel GPA Installation
Figure 9-16 shows the destination folder selection box (in this example, you would choose D:\GPA\2012 R5).
Figure 9-16. 
Intel GPA Destination Folder Selection
Follow the step-by-step instructions to complete the installation.









Sample Usage of Intel GPA on Android
The following example demonstrates how to use Intel GPA to monitor an application on an Android device. In this case, the target machine is a Lenovo K800 smartphone running on an Intel Atom processor.
Before Intel GPA can monitor and control applications on Android devices, Eclipse must be used to set specific application parameters. The applications can then be generated and deployed by Eclipse, run, and monitored.
The application we will use here as an example for Intel GPA monitoring is MoveCircle. The operation interface is shown in Figure 9-17(a).
The application is a simple drag-around game. The user interface is a simple circle. When the user touches any point inside the circle and drags it around, a black circle will follow the touch point and move around. When the user stops touching the spot in the circle, the circle will become still. At this point, the circle does not move when the user drags it outside the circle (that is, the initial touch point within that circle). If the user presses the phone’s Back button, the Exit dialog box will pop up. Selecting Exit will allow you to exit the application, as shown in Figure 9-17(b).

The MoveCircle Application
The major computing tasks of the application take place in the dragging of the circle. You are required to constantly calculate the circle’s new location and refresh (redraw) the display.
Following are the steps for Intel GPA monitoring of the sample application:
-
1.
Build and deploy the application in Eclipse that will be monitored by Intel GPA.
-
2.
Use general procedures to create an application project. Name the application MoveCircle.
-
3.
Write the related code for the project. The document framework is shown in Figure 9-18.

Document Framework of the Application MoveCircle
-
4.
Edit the AndroidManifest.xml file and add the following code:
1. <manifest xmlns:android=" http://schemas.android.com/apk/res/android "
2. package="com.example.movecircle"
3. android:versionCode="1"
4. android:versionName="1.0" >
5.
6. <uses-sdk
7. android:minSdkVersion="8"
8. android:targetSdkVersion="15" />
9. <uses-permission android:name="android.permission.INTERNET"/>
10.
11. <application
12. android:icon="@drawable/ic_launcher"
13. android:debuggable="true"
14. android:label="@string/app_name"
15. android:theme="@style/AppTheme" >
16. <activity
17. android:name=".MainActivity"
18. android:label="@string/title_activity_main" >
19. <intent-filter>
20. <action
21. android:name="android.intent.action.MAIN" />
22. <category android:name="android.intent.category.LAUNCHER" />
23. </intent-filter>
24. </activity>
25. </application>
26.
27. </manifest>
In line 9, we add a description of uses-permission elements, which is the same level of the application, and we grant the application’s Internet write/read access. In line 13, we specify that the application is debuggable.
-
5.
Generate the application package and deploy the application to the real target device. Be sure to close Eclipse before starting the next step.
-
6.
Start Intel GPA on the host machine to monitor the application
-
a.
Connect the Android phone to the PC. Make sure the screen is not locked or you may get error the error Unsuccessful Phone Connection.
-
b.
Make sure to turn off all tools that use the adb server, such as Eclipse and DDMS. Otherwise, you may get the error Unsuccessful Phone Connection. (This step can be skipped) Make sure the adb server is started and running (See Figure 9-19).
-
a.

ADB Server Displaying Our Medfield Device
-
7.
Select the Windows menu “\start\program\Intel Graphics Performance Analyzers 2012 RS\Intel GPA System Analyzer” to start Intel GPA.
-
8.
The Intel GPA initial window then pops up, suggesting the machine that will be monitored, as shown in Figure 9-20. Since the tuning target is a phone in this case, select the phone (in this case the Medfield04749AFB) by clicking the Connect button to the right of name of the phone.

Intel GPA Interface for Connecting to the Monitored Device
-
9.
Once you are connected, Intel GPA does an initial analysis of the applications installed on the monitored smartphone, dividing the apps into two groups: analyzable applications and nonanalyzable applications, as shown in Figure 9-21.

Initial Interface (Apps List) After Intel GPA Is Connected to the Monitored Phone Device
At the top of the window is an Analyzable applications category that can be tuned or debugged by Intel GPA. Non-analyzable applications are listed in the bottom panel. In the analyzable application list, you can see the MoveCircle application that we are using as the example for the Intel GPA monitoring exercise. The reason that an application is not analyzable by Intel GPA is usually because its parameters are not set in the way we described in earlier in this session.
-
10.
Click the name of the application that you want Intel GPA to monitor in the Analyzable applications window (in this case, MoveCircle). An icon of a rolling circle showing ongoing progress appears on the left side of the app (MoveCircle). See Figure 9-22.

App Initialization Interface in Intel GPA
While this is happening, the application start-up screen is displayed on the phone. The screen will prompt you with the message Waiting For Debugger, as shown in Figure 9-23. Note that you should not click the Force Close button but instead wait until the message box automatically closes in the interface.

Initial Message Appearing on Target Phone When Intel GPA Starts Monitoring the Application
-
11.
Next, Intel GPA monitoring interface appears, as shown in Figure 9-24.

Initial Monitoring Interface Shown on Intel GPA when the Application Is Started
While this takes place, the MoveCircle app starts to run on the phone, as shown in Figure 9-25.

The MoveCircle App That is Shown on the Target Phone Device
Drag and drop the CPU 00 Load to the top real-time status display panel in the display window, and drag and drop the CPU 01 Load onto the bottom real-time status display panel in the display window. Click and drag the MoveCircle around for a few seconds and then stop the interaction for a few seconds. The corresponding Intel GPA monitoring screen is shown in Figure 9-26.

Intel GPA Monitoring the MoveCircle App and Displaying CPU Loads in Real Time
In Figure 9-26, we can see a rule: when we drag the circle, the two CPU loads will both rise to a certain height; when we do not interact with the app, the two CPU loads will immediately drop to near 0 percent. The application’s main computing tasks are concentrated in dragging and moving the circle, and there is no or low CPU load when the circle is not being moved.
To end the Intel GPA analysis, exit the app, as shown in Figure 9-17(b). Intel GPA will return to the starting interface shown in Figure 9-20.
The previous example only demonstrates monitoring of the CPU load. An interested reader can try other app examples and other monitoring metrics. Using the MoveCircle app as an example, we chose the Disk Read metric for the top display window and the Disk Write metric for the bottom display window. We then switched apps and reviewed some photo files. When we returned to the MoveCircle app, the instant action of disk read shows the existence of Disk Read activity, as shown in Figure 9-27.

Intel GPA Monitoring Window Showing Disk Read for the MoveCircle App and Other Apps
Android Multithreaded Design
The Intel Atom processor supports hyperthreading and multicore configurations. A multithreaded design is a good way to increase the degree of parallelism and improve performance. The Intel Atom N-series processors support the parallel execution of multiple threads. Although most Intel Atom Z series processors for mobile phones and other mobile devices are single core, they support Intel Hyper-Threading Technology. Thus the Z series processors form two or four logical CPUs and also physically support a certain degree of parallel execution.
Note that the word used here is parallel rather than concurrent. For some tasks, we can follow the classic methodology in parallel computing called “divide and conquer” and divide them into two or more basic units. We assign those units to different threads to be executed at the same time. In this way, the performance potential of the processor is fully utilized, accelerating execution speed such that the software runs faster and more efficiently.
Based on the Java multithreaded programming interface, Android extensions provide a more powerful multithreaded programming interface for Android developers. With the aid of this programming interface, developers can easily implement multithreaded development and design at the Java language level without needing to use the cumbersome underlying operating system called interface.
Android Framework or a Thread
The Android threaded programming framework is based on Java. There are two methods to realize multithreaded programming in Java. The first is to inherit from the Thread class and override the run method. The second is to implement the Runnable interface and run method.
Java Thread Programming Interface
The general code framework for the first approach to realizing multithreaded programming, to inherit from the thread, is as follows: first, define the thread class (in this case, the thread class named MyThread) and its code as shown in Figure 9-28.

A Sample Custom Thread Class
Then, create an instance of our custom Thread class and start it, as shown in Figure 9-29.

Starting the Thread
Wait for the thread to finish, and handle the cases if something goes wrong, as shown in Figure 9-30.

Waiting for the Thread to Finish
The second approach to realizing multithreaded programming in Java uses the Runnable interface implementation. The following is the general code framework for Runnable. The first step is to create a custom Runnable interface, as shown in Figure 9-31.

Custom Runnable
Next, you need to actually start the thread and give it a Runnable. This can be done as shown in Figure 9-32.

Starting the Thread
These two approaches have the same effects, but the occasions on which they are used are different. Developers who are familiar with Java know that it does not have multiple inheritance, so it uses Interface Implement instead. To separately implement a thread, you can use the first approach, thread inheritance.
But some classes have themselves been inherited from another class. In such cases, if you want the thread to run, you have to use the second method (the Runnable interface method) to achieve thread implementation. In this method, you can declare that the class implements the Runnable interface and then put the code that will be run as a thread into the run function. In this way, it will not affect its previous inheritance hierarchy and can also to run as a thread.
Note the following points about Java’s threading framework:
-
1.
In Java runtime, the system implements a thread scheduler for thread execution, which is used to determine a time by which a thread will run on the CPU.
-
2.
In Java technology, the thread is usually preemptive without the need for a time slice allocation process (which assigns to each thread the process of equal CPU time). In the preemptive scheduling model, all threads are in a ready-to-run state (waiting state), but in fact only one thread is running. The thread continues to run until it terminates or a higher-priority thread becomes runnable. In that case, the low-priority thread terminates and gives the right to run to the high-priority thread.
-
3.
The Java thread scheduler supports this preemptive scheme for threads with different priorities, but the scheduler itself does not support the time slice rotation of threads with the same priority.
-
4.
If the operating system on which Java runtime is running supports the rotation of the time slice, then the Java thread scheduler supports the time slice rotation of the same priority thread.
-
5.
The system’s thread scheduler should not be excessively relied upon. For example: the low-priority thread must also get a chance to run.
For more detailed information on Java multithreaded programming methods for Android applications, developers can refer to related Java programming books.
Threaded Programming Extensions and Support
When Android is running, the Dalvik virtual machine supports multiple concurrent CPUs. That being said, if the machine has more than one logical processor, the Dalvik virtual machine will follow certain strategies to automatically be assigned different threads to run on different CPUs. In this way, Android can physically run different threads in parallel. In addition to the thread programming interfaces provided by Java, Android also provides important extensions and support. The first is the Looper-Message mechanism.
Android’s interface, including a variety of activity, is running in the main thread of the application (also known as the UI thread, the Interface thread, or the default thread). By default, the application has only one thread, which is the main thread. Thus the application is considered to be single-threaded. Some time-consuming tasks (computing), if they are run on the main thread by default, will cause the interaction of the main interface to fail to respond for a long time. To prevent the main interface interaction from remaining at a standstill for a long time, those time-consuming tasks should be allocated to the independent thread to execute.
The independent thread running behind the scenes (also known as the assistive thread or background thread) often needs to communicate with the interface of the main thread, such as by updating the display interface. If the behind-the-scenes thread calls a function of an interface object to update the interface, Android will give the execution error message CalledFromWrongThreadException.
For example, in an application (in this case GuiExam), if a worker thread directly calls the setText function of the TextView object in the interface to update the display, the system will immediately encounter an error and terminate the running application, as shown in Figure 9-33.

Running Error Message When Worker Thread Directly Calls a Function of the UI object
In order to enable the worker thread and the main thread interface to communicate well, you need to understand the Looper-Message mechanisms. In order to solve such problems, Android has a mechanism called message queue, in which the threads can be combined by the message queue, processing Handler and Looper components to exchange information.
Message
The Java class Message defines the information exchanged between threads. When a thread behind the scenes needs to update the interface, it sends a message containing the data to the UI thread (the main thread).
Handler
The Handler class is the main processor of the Message class, and is responsible for sending messages and the execution and processing of the message content. The behind-the-scenes thread, making use of the processing object passed in, calls the sendMessage function to send a message. To use the Handler class, you need a method with which to implement the class handleMessage, which is responsible for handling the message operation content, such as updating the interface. The handleMessage method usually requires subclassing.
The Handler class itself is not used to open up a new thread. A Handler is more like the secretary of the main thread, a flip-flop, and is responsible for managing the updated data from the subthread and then updating the interface in the main thread. The behind-the-scenes thread processes the sendMessage () method to send a message, and the Handler will call back (which is automatically invoked) processing in the handleMessage method to process the message.
Message Queue
The message queue is used to store the messages sent by a Handler, according to the first-in/first-out rule for execution. For each message queue, there will be a corresponding Handler. The Handler uses two methods to send messages to the message queue: sendMessage or post. These two types of messages will be inserted at the end of message queue according to the first-in/first-out rule. Messages sent by these two methods are executed in slightly different ways: a Message sent by sendMessage is a message queue object and will be processed by the handleMessage function of the Handler, whereas a Message sent through the post method is a runnable object and will be implemented automatically.
Android has no global message queue and automatically builds a message queue for the main thread (one of the UI threads), but the message queue has not been established in the subthread, so Looper.getMainLooper () must be called to get the Looper of the main thread. The main thread loop will not go to NULL, but to call Looper.myLooper () to get Looper of the current thread loop, it is possible for a NULL.
Looper
The Looper class is the housekeeper of each thread’s message queue. A Looper is a bridge between the Handler and message queues. Program components first pass the message to the Looper through the Handler, and then the Looper puts the Message in the queue.
For the main thread of default UI of the application, the system has established the message queue and Looper, and there is no need to write the message queue and looper operation code in the source code. Even having said that, both are “transparent” for the default main thread. However, the Handler is not transparent to the default main thread. In order to send messages to the main thread and handle them, users must establish their own Handler object.
AsyncTask
In addition to using the Looper-Message mechanisms to achieve the communication between the worker thread and the main GUI thread, you can use a technique called the asynchronous tasks (AsyncTask) mechanism to implement the communication. The general procedure for using the AsyncTask framework is described as follows:
-
1.
Implement the AsyncTask according one or several of the following methods:
-
onPreExecute(): begin preparatory work before Execution.
-
doInBackground(Params...): start background execution, inside this call the publishProgress method to update real-time task progress.
-
onProgressUpdate(Progress...): after the publishProgress method is called, the UI thread will call this method to show the progress of the task interface; for example, by displaying a progress bar.
onPostExecute(Result): after the completion of the implementation of the operation, send the results to the UI thread.
Of these four functions, none may be manually called. In addition to the doInBackground (Params...) method, the other three are UI thread called, causing the following requirements:
-
The AsyncTask instance must be created in the UI thread.
-
The AsyncTask.execute function must be called in the UI thread.
-
-
Keep in mind that the task can only be executed once. Multiple calls will result in inconsistent and indeterminate results.
Thread Example
The running interface Application GuiExam is shown in Figure 9-34. Here we use an example to illustrate the use of Android-threaded programming.

Demo UI of Multithreaded Code Framework
As shown in Figure 9-34, the demo app has three main activities buttons: Start Thread Run, Stop Thread Run, and Exit App; the first two buttons are used to control the operation of the auxiliary thread. When you click the Start Thread Run button, the thread starts running, as shown in Figure 9-34(b). When you click Stop Thread Run, the thread run ends, as shown in Figure 9-34(c). The worker thread refreshes output text displays TextView each period of time (in this case 0.5 s), displaying on screen “Done Step. X increments from 0 to X. Click ‘Exit’ to close the activities and exit the application demo.”
The structure of the demo app and the procedures follow:
-
1.
Edit the main activity file (in this example: activity_main.xml), delete the originalTextView window component, and then add three buttons and two TextView window components. The properties of Button’s ID are respectively: @+id/startTaskThread,@+id/stopTaskThread,@+id/exitApp. The TextView property is respectively startTaskThread, exitApp, taskThreadOutputInfo, and stopTaskThread. There is one ID of TextView for which the property is set as @+id/taskThreadOuputInfo to display the text output of the worker thread. The TextView Outline for the Demo App is shown in Figure 9-35.

Multithreaded Code Framework in activity_main.xml of Demo App
-
2.
Edit the source code MainActivity.java of activity_main class. The content is listed below:
1. package com.example.guiexam;
2. import android.os.Bundle;
3. import android.app.Activity;
4. import android.view.Menu;
5. import android.widget.Button;
6. import android.view.View;
7. import android.view.View.OnClickListener;
8. import android.os.Process;
9. import android.widget.TextView;
10. import android.os.Handler;
11. import android.os.Message;
12. public class MainActivity extends Activity {
13. private Button btn_StartTaskThread;
14. private Button btn_StopTaskThread;
15. private Button btn_ExitApp;
16. private TextView threadOutputInfo;
17. private MyTaskThread myThread = null;
18. private Handler mHandler;;
19. @Override
20. public void onCreate(Bundle savedInstanceState) {
21. super.onCreate(savedInstanceState);
22. setContentView(R.layout.activity_main);
23. threadOutputInfo = (TextView)findViewById(R.id.taskThreadOuputInfo);
24. threadOutputInfo.setText("Thread Not Run");
25. mHandler = new Handler() {
26. public void handleMessage(Message msg) {
27. switch (msg.what)
28. {
29. case MyTaskThread.MSG_REFRESHINFO:
30. threadOutputInfo.setText((String)(msg.obj));
31. break;
32. default:
33. break;
34. }
35. }
36. };
37. btn_ExitApp = (Button) findViewById(R.id.exitApp); // Code for <Exit App>Button
38. btn_ExitApp.setOnClickListener(new /*View.*/OnClickListener(){
39. public void onClick(View v) {
40. finish();
41. Process.killProcess(Process.myPid());
42. }
43. });
44. btn_StartTaskThread = (Button) findViewById(R.id.startTaskThread);
45. // Code for<Start Thread Run>
46. btn_StartTaskThread.setOnClickListener(new /*View.*/OnClickListener(){
47. public void onClick(View v) {
48. myThread = new MyTaskThread(mHandler); // Create a thread
49. myThread.start(); // Start Thread
50. setButtonAvailable();
51. }
52. });
53. btn_StopTaskThread = (Button) findViewById(R.id.stopTaskThread);
54. //code for <Stop Thread Run>
55. btn_StopTaskThread.setOnClickListener(new /*View.*/OnClickListener(){
56. public void onClick(View v) {
57. if (myThread!=null && myThread.isAlive())
58. myThread.stopRun();
59. try {
60. if (myThread!=null){
61. myThread.join();
62. // Wait for Thread Run to end
63. myThread =null;
64. }
65. } catch (InterruptedException e) {
66. // Empty statement block, ignored forcibly abort exception
67. }
68. setButtonAvailable();
69. }
70. });
71. setButtonAvailable();
72. }
73. @Override
74. public boolean onCreateOptionsMenu(Menu menu) {
75. getMenuInflater().inflate(R.menu.activity_main, menu);
76. return true;
77. }
78. private void setButtonAvailable() // New function is used to set the button optional
79. {
80. btn_StartTaskThread.setEnabled(myThread==null);
81. btn_ExitApp.setEnabled(myThread==null);
82. btn_StopTaskThread.setEnabled(myThread!=null);
83. }
84. }
In lines 17 and 18 of the code just given, we define the variable myThread of the defined thread class as MyTaskThread and the default main thread handler object as mHandler, respectively. From line 25 to line 36, we define the Handler class. The What attribute field of the message class indicates the type of message. The custom handler class uses a switch-case statement for different handlers depending on the type of message, of which MSG_REFRESHINFO is the message type of custom thread class MyTaskThread, which means that the worker thread requires an updated interface display message. The purpose of lines 29 to 31 is to process the message. The code is very simple; it updates the widget display of TextView according to the message with the parameter object.
Lines 47 to 49 consist of the response code given when the start running threads button is clicked. It first creates the custom thread object and then calls the Thread.start function to make the self-defined thread class MyTaskThread run, which runs execution code in the run function as a single thread. Line 49 calls the custom setButtonAvailable function to set each button’s option (that is, grayed as not selectable, or white, which is selectable).
Lines 55 to 65 are the code responsible for the Stop Thread Run button. Line 55 first determines whether the thread already exists or is running, and then stops a thread run in line 56 by calling the defined stop-the-thread prototype function from the custom thread class MyTaskThread and then calling the Thread.join () function. It then waits for the thread run to end. Finally, it sets the optional status of the interface buttons.
Lines 75 to 80 consist of a customized function, which is used to determine the optional status of each button: white as selectable; gray as not selectable.
-
3.
Create a new class MyTaskThread in the application. This class inherits from Thread and is used to implement the worker thread. The source code file MyTaskThread.java of this class is as follows:
1. package com.example.guiexam;
2. import android.os.Handler;
3. import android.os.Message;
4.
5. public class MyTaskThread extends Thread {
6. private static final int stepTime = 500;
7. // Execution timeof each step(unite:ms)
8. private volatile boolean isEnded;
9. //mark if the thread is running. Used to stop thread run
10. private Handler mainHandler;
11. //Handler used to send message
12. public static final int MSG_REFRESHINFO = 1; // Update message on interface
13.
14. public MyTaskThread(Handler mh) // Define a constructor
15. {
16. super(); // Call the parent class builder to create objects
17. isEnded = false;
18. mainHandler = mh;
19. }
20.
21. @Override
22. public void run() // Write run code in thread body run method
23. {
24. Message msg ;
25. for (int i = 0; !isEnded; i++)
26. {
27. try {
28. Thread.sleep(stepTime); // designate time for every step of the thread to sleep
29. String s = "Complete" + i +"step";
30. msg = new Message();
31. msg.what = MSG_REFRESHINFO; // Define message type
32. msg.obj = s; // attach data to message
33. mainHandler.sendMessage(msg); // send message
34. } catch (InterruptedException e) {
35. e.printStackTrace();
36. }
37. }
38. }
39.
40. public void stopRun() // Stop control function for stop thread run
41. {
42. isEnded = true;
43. }
42. }
This is the implementation code of the custom thread class MyTaskThread, which is the key to this application. This application is using the first approach, thread inheritance, to achieve threading. In line 5, let the customized class inherit from Thread, and then from line 14 to line 39, let the threads run code on the rewrite run function. To cope with the work of the thread, in line 6 to line 9 we define the relevant variables. The constant stepTime represents the length of every step of the thread delay time, measured in milliseconds. The mark isEnded controls whether to continue every step in the body of the loop in the run function to continue. Note that the variable is preceded by the volatile modifier: Volatile variables. Each time a thread accesses the variable, it will read the final values in the memory after the variables have been modified. A write request must be written to memory too. This avoids the copy that is in cache or in the register not matching with the value in the memory variable, which causes an error. The mainHandler is the variable that saves the main thread handler. MSG_REFRESHINFO is a constant type that handles custom message.
Line 10 to line 15 is a constructor. In this function body, we initialize the value of the thread-running control variables isEnded and then save mainHandler as the main thread handler object passed as a parameter.
Line 16 to line 33 is the core thread code that rewrites the run function. The code is composed of a loop to determine whether to continue to use the control variable isEnded. Here, we call one loop as a step. Every step of the work is also simple: when the Thread class static function sleep is called in line 28 after a specified time, a message is generated and assembled in line 24 to line 27. Finally, in line 28, the message is sent to the specified (message loop) handler.
Line 34 to line 37 is a custom control function to stop the thread from running. The code is very simple; it changes the run loop control variable value.
Thread Synchronization
A multithreaded process inevitably involves a problem: how to deal with threads’ access to shared data, which relates to thread synchronization. Thread data sharing is also known as critical section. Access to shared data is also known as the competition for resource access. In general, in operating system textbooks, thread synchronization includes not only the synchronization of this passive selected access to shared data but also the active choice synchronization between threads in order to collaborate to complete a task. Thread synchronization especially focuses on access to shared data. In this section, we discuss synchronization issues on shared data access.
In multithreaded programming, if the access to shared data does not use certain synchronization mechanisms, data consistency and integrity cannot be guaranteed. There are two ways to do the Java thread synchronization: one is called an internal lock data object and the other is just called synchronization. Both of these methods are implemented with the synchronized keyword. Statements modified by the synchronized block can guarantee the exclusivity of the operations between threads, considered unique or atomic in the term of the operating system. In Java it is called synchronization. A synchronized block is also known as Genlock.
In the first method of locking data objects, at any time, only one thread may access the object that is locked. The code framework is shown in Figure 9-36.

Method One
In the above code, var must be the variable that each thread can access, so that it becomes a synchronization variable. In practice, the synchronization variable and shared variables can be either the same or different variables. The Object class in the code in the figure can be replaced with the subclass of Object, because besides the simple classes in Java, any class can be the Object offspring class. Object in the code can be replaced by any class.
Note that a primitive type (such as int and float, but not String class) cannot be the synchronization variable, as shown in Figure 9-37.

Invalid Synchronized Block
When you use the second method, the synchronization method, only one thread visits a code segment at any time, such as in Figure 9-38.

Synchronizing a Method
Besides the synchronization for the general class (function) shown in the previous figure, there is also synchronization for the static function of the class, as shown in Figure 9-39.

Synchronizing a Static Method
In the synchronization method, what gets locked is the object that calls the synchronization method. When an object of MyClass: obj1 implements the synchronization method in a different thread, mutual exclusion will be formed to achieve the synchronization result. But another object, obj2, generated by the class MyClass can call this method with the synchronized keyword. As a result, the code in the previous figure can be written in equivalent terms to those in Figure 9-40.

Synchronizing General Method
The static synchronization method is shown in Figure 9-41.

Locking on a Class
In the second method, the static method, the class literally is treated as a lock. It generates the same result as the synchronized static function. The timing to get a lock is also special; the lock is acquired when calling the class that this object belongs to, and no longer the specific object that this class generates.
The rules that Java uses to implement a lock by the synchronized function are generalized in the following:
-
Rule 1: When two parallel threads visit the synchronized(this) synchronization code segment of the same object, there is only one thread that can be run at any time. Another thread must wait until the current thread finishes running the code segment to run the same code segment.
-
Rule 2: When a thread visits a synchronized(this) synchronization code segment of an object, another thread can still visit a non-synchronized(this) synchronization code segment of an object.
-
Rule 3: When a thread visits a synchronized(this) synchronization code segment of an object, the visit of all other threads to all other synchronized(this) synchronization code segments of the object will be blocked.
-
Rule 4: When a thread visits a synchronized(this) synchronization code segment of an object, it acquires the object lock of this object. As a result, all visits from other threads to all synchronized(this) synchronization code segments of an object will be temporally locked.
-
Rule 5: The previously stated rules apply to all other object locks.
Although synchronization can guarantee granularity of the object or block of statements executed, mutual exclusiveness of this granularity degrades the thread concurrency, so that the code, which originally could run in parallel, has to run in serial execution. Therefore, we need to be cautious and limit use the synchronized function to cases where a synchronized lock is needed. On the other hand, we need to make the lock granularity as small as possible in order to both ensure the correctness of the program and improve operational efficiency. This is done by raising the degree of concurrency as high as possible.
Thread Communication
In multithreaded design, with data exchange among threads, setting the signal collaboration to complete a task is a common problem. Generalized threading issues are a large part of the problem, similar to the typical example of the producer-consumer problem. These are the threads that have to cooperate to accomplish a task.
It is generally recommended that a semaphore be used to achieve thread synchronization primitives. Java does not directly provide the semaphore primitives or programming interface but rather achieves the function of the semaphore with a class function such as wait, notify, notifyAll, and so on.
The classes wait, notify, and notifyAll belong to the function of the Object class, and are not part of the Thread class. Every object has a waiting queue (Wait Set) in Java. When an object has just been created, its wait queue is empty.
The wait function can make the objects in the current thread wait until another thread calls the notify or notifyAll method of this object. In other words, when a call waits in the queue of the object, there is a thread where the thread enters a wait state. Only when the notify method is called can we put the thread from the queue out to make this thread become runnable. The notifyAll method waits for all threads in the queue to become runnable. Notify and notifyAll are not much different in function.
The wait, notify, and notifyAll functions need to be used in conjunction with synchronized to establish the synchronization model, which can guarantee the granularity of the former functions. For example, before calling wait, we need to get the object’s synchronization lock so that this function can be called. Otherwise the compiler can call the wait function, but it will receive an IllegalMonitorStateException runtime exception.
Following are several examples of code frameworks of wait, notify, and notifyAll.
Figure 9-42 shows code to wait for a resource.

Locking on an Object
Figure 9-43 shows the code for using notify and providing resources (an example of which is the complete use of resources and returned to the system).

Using Notify
The previous figure is the stand-alone use case of synchronization object obj. We can also write synchronization code in a class. The framework of this code can be written as in Figure 9-44.

A Class Example of Synchronized
The thread that is waiting for resources calls the myclass.func1 function, and the thread that provides resources calls myclass.func2 function.
Principles of Multithreaded Optimization for Intel Atom Processors
The multithreaded software design allows program code in different threads to run at the same time. However, blind or excessive use of multithreaded programming may not lead to performance improvement and may even downgrade the software performance. Therefore, we need to look at the principles of multithreaded optimization on Android x86.
First of all, the start, or scheduling, of a thread requires a certain amount of overhead and occupies a certain amount of processor time. For processors that do not support hyperthreading and multicore processing, the system cannot physically let the threads run at the same time. There is significant overhead if we split one physical processor into multiple logical processors with virtualization technologies to have each thread run on a logical core in an attempt to support multithreaded programs. Such a multithreading strategy not only makes it difficult to achieve improvement in performance but may even lead to the multithreaded execution speed being slower than a single-threaded program. Therefore, to achieve multithreaded performance acceleration (a prerequisite to being faster than single-threaded execution speed) using multithreaded design, the processor must support hyperthreading, contain multicores, or have multiple processors.
Second, for processors that support hyperthreading or multicore, it is not always true that more threads will make the software run faster. There is a performance/price ratio that needs to be considered. The physical basis for multithreaded design in performance tuning can be explained as allowing multiple threads to run at the same time in parallel on the physical layer. The maximum number of concurrently running threads supported by the processor is therefore the optimum number of threads for multithreaded optimization.
Intel Hyper-Threading Technology can support two threads running in parallel, and also has multicore support for multiple threads running in parallel. For example, for a dual-core Intel processor that supports Intel Hyper-Threading Technology, the maximum number of threads supported to run in parallel is:
2 core × 2 (Intel HTT) = 4 threads
Therefore, this machine supports multithreaded optimization, and the maximum number of threads (threads running concurrently) is equal to four.
For example, if the target machine is a Lenovo K800 phone, which uses a single-core Intel Atom Z2460 processor, in accordance with the above formula, we can conclude that running two threads can make the machine achieve optimal performance. For a Motorola MT788 target machine, which uses a single-core Intel Atom Z2480 processor, the optimal number of threads is two. If the target machine is a Lenovo K900 with a dual-core processor, the Intel Atom Z2580 processor with Intel HTT, then the optimal number of threads reached will be four.
In general, when we consider multithreaded optimization on the Android platform, it is necessary to carefully look into the processor information to see if it supports hyperthreading or multicore technology.
Case Study: Intel GPA–Assisted Multithreaded Optimization for an Android Application
In the previous section, we explained several optimization techniques and principles. In this section, we use a comprehensive example to explain the knowledge of the optimization. In this case, the multithreaded optimization is combined with optimization assisted by Intel GPA to optimize the application to make it run faster.
The app that we use as an example performs the calculation of Pi (π). We will now introduce the background of this app. We know the mathematical formula to be as follows:
We know that the integration formula can be expressed using the infinitive:
s
In fact, ∆x cannot be infinitely small, so we only can make ∆x as small as possible. Therefore, the result of the formula is closer to π. If we use step to represent ∆x, then
must be at maximum to get an accurate approximation of Pi. Consider that
is a raised function. Here, we take a median value to calculate the sum; that is, we use
to replace
to calculate the sum. The result calculated by this formula will not always be smaller than the actual value of π. So eventually we get the final formula upon which this application is based:
Based on this formula, we can derive the equivalent computing source code.
Original Application and Intel GPA Analysis
We can derive the source code for our case study app from the formula we just came up with in the previous section. The source code will not be optimized. We’ll refer to it as the original application and name it SerialPi.
The design of this app is the same as the example given in the preceding Thread Example section. The task of calculating π is put into a worker thread (here named a task thread). A button is set on main application screen to control the running of the thread, and a TextView is used to display the result of the task thread. The interface showing the app’s single run is shown in Figure 9-45.

App Run Interface of SerialPi
The interface that comes up after the application starts is shown in Figure 9-45(a). When you click the Start Calculating button, all buttons on the interface gray out until the computing of πthread is complete. The interface then displays the computation result of π as well as the total running time of the thread. You can click the Exit App button, as shown in Figure 9-45(b), which allows you to exit the application. From the interface shown, we know it takes about 22 seconds for this app to calculate π. When running this application repeatedly, the calculation time is about the same every time (22 seconds).
The structure of the application steps and key code is as follows:
-
1.
New build SerialPi. The proposed project property is set to use the default value. Note that the [Build SDK] is set to support the x86 API.
-
2.
Edit activity_main.xml; place two Buttons and two TextViews in the layout, the ID attribute of a TextView is set as @+id/taskOuputInfo, which is used to display the results of the task thread, as shown in Figure 9-46.

Main Outline of SerialPi App
-
3.
Create a new thread class MyTaskThread in the new project and use it to calculate the value of π. Edit the source code file MyTaskThread.java as follows:
1. package com.example.serialpi;
2. import android.os.Handler;
3. import android.os.Message;
4. public class MyTaskThread extends Thread {
5. private Handler mainHandler;
6. public static final int MSG_FINISHED = 1;
7. // Defined the message type for the end of the calculation
8. private static final long num_steps = 200000000;
9. // num_steps variables in Formula, the total number of steps
private static final double step = 1.0 / num_steps;
10. // Step variable in formula, step length
11. public static double pi = 0.0;
12. // the calculation of results of π
13.
14. static String msTimeToDatetime(long msnum){
15. // The function converts the number of milliseconds into hours: minutes: seconds. Milliseconds "format
16. long hh,mm,ss,ms, tt= msnum;
17. ms = tt % 1000; tt = tt / 1000;
18. ss = tt % 60; tt = tt / 60;
19. mm = tt % 60; tt = tt / 60;
20. hh = tt % 60;
21. String s = "" + hh +"hour "+mm+"minute "+ss + "秒 " + ms +"Miliseconds";
22. return s;
23. }
24.
25. @Override
26. public void run()
27. {
28. double x, sum = 0.0;
long i;
for (i=0; i< num_steps; i++){
29. x = (i+0.5)*step;
30. sum = sum + 4.0/(1.0 + x*x);
31. }
32. pi = step * sum;
33. Message msg = new Message();
34. msg.what = MSG_FINISHED; // Define message Type
35. mainHandler.sendMessage(msg); // Send Message
36. }
37.
38. public MyTaskThread(Handler mh) // Constructor
39. {
40. super();
41. mainHandler = mh;
42. }
43. }
Similar to the framework and the example of code given in the preceding Thread Example section, thread inheritance laws are used to achieve thread initialization. Pay close attention to the code segments highlighted in gray. They are the ones most directly related to the calculation of π. In lines 7 and 8, we define variables of the same name in the formula for calculation of π in the form of a static variable. Line 9 defines the variable for saving the results of the π calculation. Note that this variable is public, so that the main thread can access it.
Lines 22 through 28 are the code for calculating π according to the formula. Where the x variable is an independent variable x of function
the sum is a cumulative variable of ∑. After the cumulative ∑, finally in line 28, let π = step × ∑ to calculate the final results. Refer to the two long sections of code framework in the preceding Thread Example section; it should not be difficult to understand the mathematics behind the code.
Note that in the thread’s run function, once the calculation is complete, the message is sent to the main thread (interface) in line 29.
-
4.
Edit the source code of the main activity class file: MainActivity.java. The code is allowed to control the run of the thread and displays the calculated results as follows:
1. package com.example.serialpi;
2. import android.os.Bundle;
3. import android.app.Activity;
4. import android.view.Menu;
5. import android.widget.Button;
6. import android.view.View;
7. import android.view.View.OnClickListener;
8. import android.os.Process;
9. import android.widget.TextView;
10. import android.os.Handler;
11. import android.os.Message;
12. public class MainActivity extends Activity {
13. private MyTaskThread myThread = null;
14. private TextView tv_TaskOutputInfo; // Display (Calculated) Task thread output
15. private Handler mHandler;;
16. private long end_time;
17. private long time;
18. private long start_time;
19. @Override
20. public void onCreate(Bundle savedInstanceState) {
21. super.onCreate(savedInstanceState);
22. setContentView(R.layout.activity_main);
23. tv_TaskOutputInfo = (TextView)findViewById(R.id.taskOuputInfo);
24. final Button btn_ExitApp = (Button) findViewById(R.id.exitApp);
25. btn_ExitApp.setOnClickListener(new /*View.*/OnClickListener(){
26. public void onClick(View v) {
27. exitApp();
28. }
29. });
30. final Button btn_StartTaskThread = (Button) findViewById(R.id.startTaskThread);
31. btn_StartTaskThread.setOnClickListener(new /*View.*/OnClickListener(){
32. public void onClick(View v) {
33. btn_StartTaskThread.setEnabled(false);
34. btn_ExitApp.setEnabled(false);
35. startTask();
36. }
37. });
38. mHandler = new Handler() {
39. public void handleMessage(Message msg) {
40. switch (msg.what)
41. {
42. case MyTaskThread.MSG_FINISHED:
43. end_time = System.currentTimeMillis();
44. time = end_time - start_time;
45. String s = " The end of the run,Pi="+ MyTaskThread.pi+ " Time consumed:"
46. +
47. MyTaskThread.msTimeToDatetime(time);
48. tv_TaskOutputInfo.setText(s);
49. btn_ExitApp.setEnabled(true);
50. break;
51. default:
52. break;
53. }
54. }
55. };
}
56.
57. @Override
58. public boolean onCreateOptionsMenu(Menu menu) {
59. getMenuInflater().inflate(R.menu.activity_main, menu);
60. return true;
}
61.
62. private void startTask() {
63. myThread = new MyTaskThread(mHandler); // Create a thread
64. if (! myThread.isAlive())
65. {
66. start_time = System.currentTimeMillis();
67. myThread.start(); // Start thread
68. }
}
69.
70. private void exitApp() {
71. try {
72. if (myThread!=null)
73. {
74. myThread.join();
75. myThread = null;
76. }
77. } catch (InterruptedException e) {
78. }
79. finish(); // Exit the activity
80. Process.killProcess(Process.myPid()); // Exit the application process
81. }
}
The code listed here is similar to the code framework of the example MainActivity class in the Thread Example section. The lines of code highlighted in gray are added to estimate the running time of the task code. Three variables are first defined in line 16 to line 18: start_time as the task’s start time, end_time as the end time of the task, and time as the length of the task’s running time. These three variables are parts of the following formula:
time = end_time - start_time
In line 65, when we start the task threads, the current time of the machine is recorded in the start_time variable. In line 43 to line 44, when the message is received that the task thread has finished running, the machine’s time is recorded in end_time. The currentTimeMillis function is a static function provided by the Java System class in the java.lang package. This function returns the current time in milliseconds.
-
5.
With reference to the example given in the Sample Usage of Intel GPA on Android section, modify the project AndroidManifest.xml file to make it comply with the requirements of Intel GPA monitoring.
After the coding is completed and the app is compiled and generated, we can deploy applications to the actual target device. In this case, we use the Lenovo K800 mobile phone as a test target.
Now we use Intel GPA to analyze our SerialPi application. Specific steps can be found in the Sample Usage of Intel GPA on Android section. The first step is to monitor and analyze the case of the two CPU loads. Clicking the Intel GPA Start button will start recording the CPU load. The results of the analysis are shown in Figure 9-47 (a), (b), and (c).



Intel GPA Analysis Screen for SerialPi
Figure 9-47 (a) shows the analysis of clicking on the Start button, with the task thread running at the start. Figure 9-47(b) shows task threads running. Figure 9-47(c) shows task threads at the end of the run. From these three screens, we can see that the load on the CPU is at a low level before the app starts to run or after the end of the run. Once the computing task threads start to run, the load on the CPU sharply rises to 100 percent of the full load level. We can also see that during the running of the task threads, only one of two CPUs is at full capacity, and the other is at a low load level. By analyzing the graph, you will notice that the 100 percent-full load does not always occur on a specific CPU. Instead, the 100 percent-full load is alternatively rotating between two CPUs, which reflects the Java Runtime time support for task scheduling; the processor system itself is transparent to applications. Although a two-CPU load rate is subject to rotation, the load rate is in a “complementary” state: a rising load on one CPU means the load on the other drops. That is, the total load (the sum of loads of two CPUs at any time) does not exceed the 100 percent-full load of a single CPU, which is useful when running more than one application.
Optimized Application and Intel GPA Analysis
The previous example is the code derived directly from the formula for calculating the value of π. In this simple mathematical example, is there any room for optimization? The answer is definitely yes! Optimizing requires us to look into the algorithm of the app and to apply the principles we just learned, making full use of the hardware features of Intel’s Atom processors to release the full performance potential.
How do you tap the performance potential of the Intel Atom processor? As we explained earlier, multicore Intel Atom processors with Intel Hyper-Threading Technology have support for multithreading running in parallel on multiple physical cores. For example, the Lenovo K800 phone uses an Intel Atom Z2460 processor and supports two threads running in parallel. This is the entry point of our algorithm optimization in accordance with the previously mentioned strategy to divide and conquer. By carefully analyzing the code of the Run function of the MyTaskThread class, we managed to make computing tasks allocated to multiple threads run (in this case two); the threads running in parallel can make the app run faster. In order to calculate the cumulative value of the integral area for π, in line 24 we calculated the integral area one step at a time and added the cumulative sum. Now we take a different approach and divide the integral area into many blocks and let each thread be responsible for calculating one such block. Finally, we get the π value by adding the cumulative area of blocks calculated by each thread. In this way, we use a “divide and conquer” strategy to complete the task distribution and get the final results. We call this algorithm optimization approach ThreadPi. When ThreadPi is calculating the cumulative value of the integral area (which is the π value), we let the calculation step of each thread accumulate the step size to increase the total number of threads. This allows each of them to be responsible for the cumulating sum of their own area of the block.
The UI of the app ThreadPi when running is shown in Figure 9-48.

User Interface of ThreadPi Running Separately
The interface of this optimized application (ThreadPi) is the same as in the original application (SerialPi). In Figure 9-48(b), we can see that this application uses thirteen seconds to complete the calculation of the π value. Its time is reduced to almost half of that of the original application (twenty-two seconds). The only difference is that the optimized application uses two threads to calculate π.
This application is based on modifying the original application code; the key changes that were made are as follows:
-
1.
The thread class of the computing tasks’ MyTaskThread source code file was modified to MyTaskThread.java as follows:
1. package com.example.threadpi;
2. import android.os.Handler;
3. import android.os.Message;
4. public class MyTaskThread extends Thread {
5. private Handler mainHandler;
6. public static final int MSG_FINISHED = 1;
7. private static final long num_steps = 200000000;
8. // num_steps variable in formula, total steps
9. private static final double step = 1.0 / num_steps;
10. // step variable in formula, step length
11. public static double pi = 0.0; // Calculated result of π
12. public static final int num_threads = 2; // Thread count
13. private int myNum; // Thread #
private static Object sharedVariable = new Object();
14. // synchronization lock variable for Pi variable
15. private static int finishedThreadNum = 0;
16. // count of threads finishing calculation
17.
18. static String msTimeToDatetime(long msnum){
19. // The function to convert the number of milliseconds into hours: minutes: seconds. Millis
20. long hh,mm,ss,ms, tt= msnum;
21. ms = tt % 1000; tt = tt / 1000;
22. ss = tt % 60; tt = tt / 60;
mm = tt % 60; tt = tt / 60;
23. hh = tt % 60;
24. String s = "" + hh +"hour "+mm+"minute "+ss + "秒 " + ms +"milliseconds";
25. return s;
26. }
27. public void setStepStartNum(int n)
28. // set thread # for thread, in response to startting position of i
29. {
30. myNum = n;
31. }
32.
33. @Override
34. public void run()
35. {
36. double x, partialSum = 0.0;
37. long i;
38. for (i = myNum; i < num_steps; i += num_threads) {
39. x = (i + 0.5) * step;
40. partialSum += 4.0 / (1.0 + x * x);
41. }
42. synchronized (sharedVariable) {
43. pi += partialSum * step;
44. finishedThreadNum++;
45. if (finishedThreadNum >= num_threads) {
//waiting all threads finishing run and send message
46. Message msg = new Message();
47. msg.what = MSG_FINISHED; //Define message type
48. mainHandler.sendMessage(msg); //Send message
49. }
50. }
51. }
public MyTaskThread(Handler mh) // constructor
{
super();
mainHandler = mh;
}
}
The code segments highlighted in gray in the preceding code represent the main difference between the application (ThreadPi) and the original application (SerialPi). In lines 10 through 13, we define the variables required for multithreaded computing tasks. The variable num_threads computes the number of threads when a computing task starts. In this case, the Lenovo K800 has an Intel Atom processor with two logical CPUs, so the value is set to two. The myNum variable computes the thread number, which is selected in the range of zero to num_threads-1. The variable sharedVariable is introduced by a synchronization lock applied to the variable pi. Since pi is a simple variable, it cannot be directly locked. The finishedThreadNum variable represents the number of threads used to complete calculation. When the value of finishedThreadNum is equal to that of num_threads, we consider all computing threads are at the end of the run.
In lines 23 through 26, there is a function we added specifically for the MyTaskThread. It marks the index number of the thread.
Lines 30 through 44 are the prototype code of the computing thread. Lines 30 through 35 are the direct code to calculate π. Compared with the corresponding code for the original application, we can see that the sum variable of the original application has been replaced with partialSum instead, which reflects the fact that the area of this thread is just part of the total area. The most important difference is in line 32: the step length variable i is not 1, but num_threads, which means that every time the application is run, the thread counter moves forward a number of steps. The initial position of variable i is not 0, but derived from the thread number. This is a little like the track-and-field competition, where each athlete (thread) starts at the beginning of their lane rather than at the same starting point. Following thread computing is like athletes running in their own lanes around the track.
When a thread calculates the cumulating sum and needs to add this data onto the total cumulating sum (which is the pi variable), this is a variable shared by multithreads, and therefore needs to add a synchronization lock. This step corresponds to lines 36 through 44. In line 36, we add a synchronization lock, while in line 37 the result of the thread’s own calculations is added to the public results of pi. In line 38, we add 1 to the number of threads at the end of the calculation. In line 39, by comparing the number of threads finishing the calculation to the total number of threads, we determine if all computing threads have run to completion. Only by the end of all threads is the message sent to the main thread.
-
2.
The source code file of the main activity class MainActivity MainActivity.java was modified, as in the following:
1. package com.example.threadpi;
2. import android.os.Bundle;
3. import android.app.Activity;
4. import android.view.Menu;
5. import android.widget.Button;
6. import android.view.View;
7. import android.view.View.OnClickListener;
8. import android.os.Process;
9. import android.widget.TextView;
10. import android.os.Handler;
11. import android.os.Message;
12. public class MainActivity extends Activity {
13. private MyTaskThread thrd[] = null;
14. private TextView tv_TaskOutputInfo;
15. private Handler mHandler;;
16. private long end_time;
17. private long time;
18. private long start_time;
19. @Override
20. public void onCreate(Bundle savedInstanceState) {
21. super.onCreate(savedInstanceState);
22. setContentView(R.layout.activity_main);
23. tv_TaskOutputInfo = (TextView)findViewById(R.id.taskOuputInfo);
24. TextView tv_Info = (TextView)findViewById(R.id.textView1);
25. String ts = "This example currently has"+ MyTaskThread.num_threads + "threads on calculatingπvalue";
26. tv_Info.setText(ts);
27. final Button btn_ExitApp = (Button) findViewById(R.id.exitApp);
29. btn_ExitApp.setOnClickListener(new /*View.*/OnClickListener(){
30. public void onClick(View v) {
31. exitApp();
32. }
33. });
34. final Button btn_StartTaskThread = (Button) findViewById(R.id.startTaskThread);
35. btn_StartTaskThread.setOnClickListener(new /*View.*/OnClickListener(){
36. public void onClick(View v) {
37. btn_StartTaskThread.setEnabled(false);
38. btn_ExitApp.setEnabled(false);
39. startTask();
40. }
41. });
42. mHandler = new Handler() {
43. public void handleMessage(Message msg) {
44. switch (msg.what)
45. {
46. case MyTaskThread.MSG_FINISHED:
47. end_time = System.currentTimeMillis();
48. time = end_time - start_time;
49. String s = "Run End,Pi="+ MyTaskThread.pi+ " Time spent:"
50. + MyTaskThread.msTimeToDatetime(time);
51. tv_TaskOutputInfo.setText(s);
52. btn_ExitApp.setEnabled(true);
53. break;
54. default:
55. break;
56. }
57. }
58. };
59. }
60.
61. @Override
62. public boolean onCreateOptionsMenu(Menu menu) {
63. getMenuInflater().inflate(R.menu.activity_main, menu);
return true;
64. }
65.
66. private void startTask() {
67. thrd = new MyTaskThread[MyTaskThread.num_threads];
68. start_time = System.currentTimeMillis();
69. for( int i=0; i < MyTaskThread.num_threads; i++){
70. thrd[i] = new MyTaskThread(mHandler); // Create a thread
71. thrd[i].setStepStartNum(i);
72. thrd[i].start();
}
73. }
74.
75. private void exitApp() {
76. for (int i = 0; i < MyTaskThread.num_threads && thrd != null; i++) {
77. try {
78. thrd[i].join(); // Wait for thread running to end
79. } catch (InterruptedException e) {
80. }
81. }
82. finish();
83. Process.killProcess(Process.myPid());
}
}
The code segments highlighted in gray in the source code represent the main difference between the optimized application and the original application. In line 13, the single thread object variable of the original application changes to an array of threads. In the section on starting computing tasks that goes from line 67 through line 71, starting a single thread in the original application is changed to starting all threads in the array and setting the index number of the thread when starting the app. As for the meaning of the thread number, it has been introduced in the MyTaskThread code description. Other changes include waiting for the end of a single thread in order to wait for the end of the thread array (lines 74 through 79).
After these optimizations are completed, we need to compile, generate, and deploy the application to the target device, the same way as we did with the original application. We can run the application independently and measure the run time of this optimized application. The computing time is reduced to almost half of its original length.
Figure 9-49 shows the results of using Intel GPA to analyze this optimized application (ThreadPi). The analysis process is the same as the process we used for the original application (SerialPi).



Screenshots for Intel GPA Analysis of ThreadPi
As can be seen in the diagram, when the Start button is clicked, the calculation (task) thread starts running. Both CPU loads raise from a low load to 100 percent-full capacity. When the calculation is complete, two CPU loads drop back down to the low-load condition. Unlike the original application (SerialPi), during the time that the computing task is running, both CPUs are 100 percent fully loaded. There is no longer any load rotation. This indicates that the optimized application (ThreadPi) has two parallel CPUs working at full capacity on the calculation task, which makes the application run an order of magnitude faster.
Overview
In this chapter, we have done a deep dive into performance optimizations on the Android x86 platform. Starting with a high-level overview of performance optimization methodologies, we talked about the key points to remember: reducing instructions, reducing frequency of execution, choosing the most efficient instructions, using parallelism correctly, and optimizing the available caching features. We also discussed optimizations that are done for us and common misconceptions with performance. From here, we looked into Intel VTune, a performance-profiling tool for Android and x86, with an in-depth installation and setup guide. Next, we covered Android-specific multithreading and design and looked at how it is implemented from an in-depth, code-centric point of view. Finally, we connected all of the dots and used Intel GPA to observe our Android application and then performed a small case study on how a correct parallel implementation should look.
Author information
Authors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (http://creativecommons.org/licenses/by-nc-nd/4.0/), which permits any noncommercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this chapter or parts of it.
The images or other third party material in this chapter are included in the chapter’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the chapter’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2013 Iggy Krajci
About this chapter
Cite this chapter
Krajci, I., Cummings, D. (2013). Performance Optimizations for Android Applications on x86. In: Android on x86. Apress, Berkeley, CA. https://doi.org/10.1007/978-1-4302-6131-5_9
Download citation
DOI: https://doi.org/10.1007/978-1-4302-6131-5_9
Published:
Publisher Name: Apress, Berkeley, CA
Print ISBN: 978-1-4302-6130-8
Online ISBN: 978-1-4302-6131-5
eBook Packages: Professional and Applied ComputingApress Access BooksProfessional and Applied Computing (R0)