
Abstract
Recent developments of data monitoring and analytics technologies in the context of wireless networks will boost the capacity to extract knowledge about the network and the users. On the one hand, the obtained knowledge can be useful for running more efficient network management tasks related to network reconfiguration and optimization. On the other hand, the extraction of knowledge related to user needs, user mobility patterns and user habits and interests can also be useful to provide a more personalized service to the clients. Focusing on user mobility, this paper presents a methodology that predicts the future Access Point (AP) that the user will be connected to in a Wi-Fi Network. The prediction is based on the historical data related to the previous APs which the user connected to. Different approaches are proposed, according to the data that is used for prediction, in order to capture weekly, daily and hourly user activity-based behaviours. Two prediction algorithms are compared, based on Neural Networks (NN) and Random Forest (RF). The methodology has been evaluated in a large Wi-Fi network deployed in a University Campus.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
The demand of new multimedia services (i.e. online multimedia applications, high quality video, augmented/virtual reality, etc.) has dramatically increased in the last years. A solution to cope with the high bandwidth and strict Quality of Service (QoS) requirements associated to these new services consists on network densification through the deployment of Small Cells (SC) operating cellular technologies (e.g. 4G/5G), complemented with Wi-Fi hotspots using the unlicensed spectrum. In fact, Wi-Fi technology is a competitive option for serving multimedia demands due to its popularity among mobile users. In the last years, a dramatic increase in the amount of IEEE 802.11 (i.e. Wi-Fi) traffic has been observed. It is estimated that by 2021, 63% of the global cellular data traffic will be offloaded to Wi-Fi or small cell networks [1]. Globally, there will be nearly 549 million public Wi-Fi hotspots by 2022, up from 124 million in 2017, a fourfold increase.
In the last years, we have witnessed a widespread use of powerful (Big) Data monitoring and analytics technologies in many areas of our lives. In particular, in the context of cellular and Wi-Fi networks, the use of these technologies will be one of the main pillars to cope with the above-mentioned challenges. The monitoring system provides the ability to collect information about the users and the network, while the analytics system allows to extract knowledge of the collected data by means of Artificial Intelligence (AI) mechanisms [2]. There are different ways to extract knowledge (e.g. by using classification, clustering and prediction mechanisms) [3].
Multiple applicability examples of data monitoring and analytics in the context of Wi-Fi or cellular networks can be found in the literature. As an example related to mobile cellular networks and concerning the characterization of user habits, the collection of the Base Station and the mobile terminal communication activity (messages, calls, etc.) has been used for urban and transportation planning purposes to identify daily motifs, given that human daily mobility can be highly structural and organized by a few activities essential to life [4]. Similarly, [5] proposed a methodology to partition a population of users tracked by their mobile phones into four predefined user profiles: residents, commuters, in transit and visitors. Applications envisaged are traffic management, to better understand how traffic is affected by the residents mobility compared to the commuters, or studying how the city is receiving people from outside and how their movements affect the city. [6] proposed an agglomerative clustering to identify user’s daily motifs according to the cells in which the user is camping during the day. Real measurements obtained from a 3G/4G network were used.
The obtained knowledge related to the network status, the performance of the services, user habits, user requirements, etc. can also be useful for supporting different decision-making processes over the network (e.g. adjusting the usage of the network resources) which will lead to more efficient network management tasks related to network reconfiguration and optimization. As an example, the use of prediction methodologies for identifying the future SC/AP which the user will be connected to, together with an estimation of the future user traffic volume and perceived user performance may provide a more accurate future user characterization. This can be useful for carrying out a more proactive network reconfiguration approach. In the context of mobility management in 5G cellular networks, anticipating the cell to which users will be connected in the future is useful to facilitate handover procedures [7]. In the context of Wi-Fi networks, the prediction of APs to which a client will connect in the future can be useful for a more efficient Pairwise Master Key (PMK) caching or Opportunistic Key Caching (OKC) techniques which can reduce the time for re-authentication when roaming to a new AP [8]. Concerning the AP selection in Wi-Fi networks, [9] proposed a mobility prediction methodology based on a Hidden Markov Model that is used to forecast the next AP that users will connect to, based on current and historical user location information. On the other hand, from the point of view of traffic offloading from cellular to Wi-Fi systems, length of stay prediction at an AP can be useful for user bandwidth allocation e.g. giving higher priority to soon-to-depart Wi-Fi users so that the larger amount of traffic is sent through the Wi-Fi before performing the handover to the cellular system [10].
The extracted knowledge related to user location and mobility, user habits and interests, etc. can also be useful for companies for commercial purposes. As an example, a reliable prediction of future user location and length of stay connected to the different SC/AP enables the use of Location Based Advertising (LBA) mechanisms. This presents the possibility for advertisers to personalize their messages to people based on their location and interests [11].
Within this context, this paper proposes a methodology that predicts the future user connections to the different APs of a Wi-Fi network according to historical user records. The main contribution of the paper is the proposal of a prediction methodology that is able to extract user periodical patterns at different time-levels in order to capture weekly, daily and hourly user activity-based behaviours. Two prediction algorithms based on a supervised learning process are compared, one using a Neural Network (NN) and the other one based on Random Forest (RF). The proposed methodologies are evaluated for a large Wi-Fi network deployed in a University Campus. The remaining of the paper is organized as follows. Section 2 presents the proposed AP prediction methodology, while Sect. 3 describes the considered prediction tools. The results are presented in Sect. 4, while Sect. 5 summarizes the conclusions.
2 Proposed Methodology
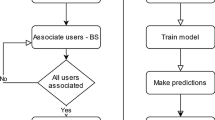
The proposed prediction methodology is shown in Fig. 1 and assumes a Wi-Fi Network with monitoring capabilities for the collection of measurements reported by the users when connected to the different APs. The Collection of Network Measurements process collects a list of metrics for each u-th user (u = 1, … , U) when connected to each AP (e.g. the instants of time when the user begins and ends a connection to each AP, the average SNR -Signal to Noise Ratio-, the average RSSI -Received Signal Strength Indicator-, the amount of bytes transmitted/received during the connection of the user to each AP, etc.). All this information is stored in a database. Then, for each user, a pre-processing of the collected data is done so that the measurements collected during each d-th day (with d = 1, … , D) are grouped in M time periods with equal duration T. In particular, the pre-processing step generates a matrix A for each user, so that each term ad,m (with m = 1, … , M and d = 1, … D) represents the AP identifier to which this user was connected during the m-th time period of the d-th day. In case that the user connects to more than one AP at the same m-th time period, it is assumed that the term ad,m will correspond to the AP with the highest connection duration.

Proposed prediction methodology.
For the prediction of the AP to which the user will be connected in a specific m*-th time period of a specific d*-th day in the future (ad*,m*), the proposed methodology makes use of some historical information of the AP to which the user was connected in the past and a prediction function f(·) that is obtained by means of a supervised learning. For that purpose, the Selection of historical data process selects some specific terms in matrix A. Different approaches are presented below:
Prediction Based on Time-Period Patterns (PBTP):
In this case, the prediction of ad*,m* is based on the APs to which the user was connected in the last N previous time periods (i.e. ad*,m*−N, … , ad*,m*−n, … , ad*,m*−1). In order to obtain the prediction function f(·), a vector \( \varvec{B}\; = \;\left( {b_{1} ,\, \ldots \,,\,b_{f} ,\, \ldots \,b_{F} } \right) \) is built from all the F = D · M previous time periods in the last D days, i.e. \( \varvec{B}\; = \;\left( {a_{1,1} ,\, \ldots \,,\,a_{1,m} ,\, \ldots ,\,a_{1,M} ,\, \ldots \,,\,a_{d,1} ,\, \ldots ,\,a_{d,m} ,\, \ldots \,,\,a_{d,M} ,\, \ldots \,,\,a_{D,1} ,\, \ldots \,,\,a_{D,m} ,\, \ldots \,,\,a_{D,M} } \right) \). Then, B is split into I different training tuples \( \varvec{B}^{i} \), each one composed of the i-th element and its N previous elements. This split is done by applying a sliding window of length N over the set of F measurements, resulting in a training set of F-N training tuples of the form \( \varvec{B}^{i} = \left( {b_{i - N} , \ldots ,b_{i - n} , \ldots ,b_{i} } \right) \) with i = 1, … , F − N. The f(·) function is learnt by a supervised learning that consists on observing the relationship between bi and its N previous elements (bi−N, … , bi−1) for all the I = F − N tuples. The rationale of this approach is to identify user frequent AP connectivity patterns in N consecutive time periods.
Prediction Based on Daily Patterns (PBDP):
In this case, the prediction of ad*,m* is done according to the APs to which the user was connected in the previous N days at the same time period of the day (i.e. ad*−N,m*, … , ad*−n*,m, … , ad*−1,m*). In order to obtain the prediction function f(·), a set of M vectors Bm = (b1,m, … , bf,m, … , bF,m) is built. Each Bm consists on the AP to which the user connected in the last F = D days at the m-th time period of the day, i.e. Bm = (a1,m, … , aD−d,m, … , aD−1,m, aD,m). Then, each Bm is split into I different training tuples \( \varvec{B}^{i}_{m} \), each one composed of the i-th element and its N previous elements, i.e. \( \varvec{B}^{i}_{m} = (b_{i - N,m} , \ldots ,b_{i - n,m} , \ldots ,b_{i,m} ) \) with i = 1, … , D − N. Then, a total of (D − N) · M tuples with size N + 1 are generated. The rationale of this is to identify user periodical AP connectivity patterns in N consecutive days at the same time of the day.
Prediction Based on Weekly Patterns (PBWP):
In this case, the prediction of ad*,m* is done according to the APs to which the user was connected in the N previous weeks at the same day of the week and time period of the day (i.e. ad*−7N,m*, … , ad*−7n,m*, … , ad*−7,m*). Again, a set of M vectors Bm = (b1,m, … , bf,m, … , bF,m) is built, each one consisting on the AP to which the user connected in the last F = W weeks at each m-th time period of a specific day of the week, i.e. Bm = (ad−7W,m, … , ad−7w,m, … , ad−7,m, ad,m). Then, each Bm is split into different I training tuples \( \varvec{B}^{i}_{m} \), each one composed of the i-th element and its N previous elements, i.e. \( \varvec{B}^{i}_{k} \) = (bi−N,m, … , bi−n,m, … , bi,m) with i = 1 ,… , W − N. In this case, the total number of tuples is (W − N) · M. The rationale of this is to identify weekly AP connectivity patterns at the same day of the week and time of the day.
Joint Based Prediction (JBP):
It consists on the same methodology but doing a combination of the three approaches described previously. In this case, the prediction of ad*,m* is done according to the APs to which the user connected in the last N time periods (i.e. ad*,m*−N, … , ad*,m*−n, … , ad*,m*−1), the APs at the same m-th time period for the last N days (i.e. ad*−N,m*, … , ad*−n,m*, … , ad*−1,m*) and the APs at the same day of the week and time period of the day for the last N weeks (i.e. ad*−7N,m*, … , ad*−7n,m*, … , ad*−7,m*). The prediction function f(·) is learnt in a similar way as before by observing the relationship of specific ad,m and the observations in the last N time periods, the last N days at the same time period and the last N weeks at the same day of the week and time period of the day. A total number of (W − N) · M tuples with size 3N + 1 are obtained.
It is worth noting that all these terms ad,m in matrix A correspond to categorical values (e.g. an AP identifier). For both the training and prediction, these terms are converted into numerical attributes by means of the so-called dummy coding process [11]. A dummy variable is a binary variable coded as 0 or 1 to represent the absence or presence of some categorical attribute. Therefore, each of the N elements used for prediction aλ (λ = 1, … , N) are converted into a set of G dummy variables cλ = (cλ,1, … , cλ,g, … , cλ,G), where G is the number of different APs in the set of N measurements, so that the term cλ,g = 1 if aλ corresponds to the g-th AP and cλ,g = 0 otherwise. Then, the resulting number of dummy variables D = N · G are used for the prediction of ad*,m* according to (1). Before the training, the same dummy coding is also done for all the training tuples of the training set.
3 Considered Supervised Learning Algorithms
In this paper, a supervised learning algorithm based on Neural Networks and Random Forest are compared. A brief description of them is provided below.
Neural Networks (NN):
In this case, the prediction is done by means of a feedforward Neural Network that consists on an input layer, one or more hidden layers and an output layer [12]. Each layer is made up of processing units called neurons. The inputs are fed simultaneously into the units of the input layer. Then, these inputs are weighted and are fed simultaneously to the first hidden layer. The outputs of the hidden layer units are input to the next hidden layer, and so on. A supervised learning technique called backpropagation is used for training. Back propagation iteratively learns the weights of the Neural Network by comparing the inputs and outputs of the training set.
Random Forest (RF):
Ensemble methodologies are used to increase the overall accuracy by learning and combining a series of individual classifier models. Random Forests is a popular ensemble method. RF is based on building multiple decision trees, generated during the training phase, and merge them together in order to obtain a more accurate and stable prediction [3]. Different from the single decision tree methodology, where each node of the tree is split by searching for the most important feature, in random forest, additional random components are included (i.e. for each node of each tree the algorithm searches for the best feature among a random subset of features). Once all the trees are built, the result of the prediction corresponds to the most occurred prediction from all the trees of the forest.
4 Results
The considered scenario consists on a large Wi-Fi network with 429 APs deployed in a University Campus with 33 buildings with four floors per building. The reported user measurements are collected by the Cisco Prime Infrastructure tool [13]. The users’ measurements were collected during D = 84 consecutive days (i.e. W = 12 weeks). The prediction methodology was run for U = 967 users. According to the methodology described in Sect. 2, the matrix A is built for each user by determining the AP to which the user is connected in each of the M = 96 periods of T = 15 min for each of the D = 84 days. According to this data, the proposed prediction methodology is run in order to predict the AP which each user will be connected to in all the M = 96 time periods of T = 15 min in the subsequent week. The obtained predictions are compared to the real APs which the user connected to. The prediction accuracy is calculated as the percentage of time periods that have been predicted correctly in the range between 6:00 h and 22:00 h for all the weekdays (from Monday to Friday) for all the users that connected to the Wi-Fi network at least one time every day. The prediction methodology has been implemented by means of Rapidminer Studio [14]. The parameters of each supervised learning algorithm have been tuned to obtain the maximum prediction accuracy. In particular, the Neural Network is configured with learning rate 0.05, momentum 0.9, 100 training cycles and 1 hidden layer of size 20 and the Random Forest has been configured with 100 trees, gain_ratio criterion and maximal depth 10.
4.1 Example of the AP Prediction Methodology
In order to illustrate the performance of the proposed prediction methodology, let first focus on the AP prediction for a specific user for all the time periods on a Wednesday. Assuming here the PBWP approach, the AP prediction at the m-th time period is based on the APs to which the user connected to in the previous N = 6 Wednesdays at the same m-th time period of the day. The training set is built by using the last F = 12 weeks. For validation purposes, the predictions are compared to the real AP where the user connected to during this Wednesday. According to this, Fig. 2 presents this comparison when using the Neural Network algorithm. As shown, for this particular user, the methodology is able to correctly predict the AP in 60 out of 64 periods of 15 min (i.e. a 93.75% of prediction accuracy). In general, most of the transitions between AP are correctly predicted. In fact, only an error of one period of 15 min is observed in predicting the user time of arrival while a slightly higher error is also observed for the prediction of departure.

Comparison of real and predicted AP for a specific user for Wednesday with NN.
During lunch time, the connection to AP XSFD4P202 is not correctly-predicted, but the prediction was AP XSFD4P102 that is located just in the lower floor of the same building. This indicates that, although the AP is not well predicted in this case, the methodology predicted correctly the region where the user was located.
4.2 Comparison of the Different Proposed Approaches
In order to gain insight in the performance of the proposed methodology, the prediction process has been run for all the set of users in all the time periods of 15 min during a whole week. Then, the predictions were compared to the AP to which each user connected at each time period. Table 1 presents the percentage of users in which each approach provides the best prediction accuracy for PBWP, PBDP and PBTP. As shown for both NN and RF predictors, PBTP approach provides better prediction accuracy than PBWP or PBDP for most of the users. This indicates that the AP to which a user was connected in the most recent time periods is the most useful information for prediction. However, it is worth noting that, for a relatively high percentage of users, the best approach is obtained with PBWP or PBDP (e.g. around 30% and 18% for NN and RF, respectively). This result indicates that the daily or weekly periodical behavior of some users can be captured better by PBDP or PBWP approaches, respectively.
Figure 3 presents the Cumulative Distribution Function of the prediction accuracy for the different prediction approaches with Neural Network. For comparison purposes, in all the approaches, the prediction is based on the 6 previous observations. Therefore, in PBWP, PBDP and PBTP, the sliding window is set to N = 6. In JBP approach, the sliding window is set to N = 2, i.e. the prediction is based according to the APs to which the user connected to in the last N = 2 time periods (i.e. ad*,m*−2, ad*,m*−1), the APs at the same m-th time period for the last N = 2 days (i.e. ad*−2,m*, ad*−1,m*) and the APs at the same day of the week and time period of the day for the last N = 2 weeks (ad*−14,m*, ad*−7,m*). As shown in Fig. 3, the JBP approach is able to provide a better prediction accuracy than the rest of the approaches separately. The reason is that the JBP is able to jointly capture the hourly, daily and weekly user behavior.

CDF of the prediction accuracy the different approaches.
In Table 2, the average prediction accuracy and the average computation time, required for running the methodology for each user, are compared for the different approaches for both NN and RF. The methodology was executed in a computer with a Core i5-3330 processor at 3.00 GHz and RAM memory of 8 GB running Microsoft Windows 10. It has been observed that the computation time is mainly due to the process of training while the time for the prediction step is negligible. As shown in Table 2, the PBTP and PBDP approaches exhibit higher computation time per user since they make use of larger number of training tuples, leading to longer training times. As shown in Table 2, the JBP approach provides the best prediction accuracy with a relatively low computation time.
It is worth noting that the computation time required for the training may impose some restrictions in the maximum number of users that can included in the AP prediction or the frequency in which the training is updated. The values of the average computation time per user obtained in Table 2 may be excessively high in a Wi-Fi network that may have several thousands of simultaneous user connections. As a consequence, running the proposed methodology for such a high amount of users may require the parallelisation of the proposed methodology using multiple processors, each of them to run the prediction of a group of users.
4.3 Impact of the Amount of Data Used for Training
This section presents the impact of the amount of historical data used for building the training set. In particular, Fig. 4a presents a comparison of the prediction accuracy for JBP with N = 2 for Neural Network and Random Forest as a function of the number of days with measurements considered for generating the training set. On the other hand, Fig. 4b shows the average computation time required per user. As shown in Fig. 4a, the Neural Network predictor provides higher average prediction accuracy than Random Forest. Figure 4a also shows that the use of larger amount of data for generating the training set provides higher prediction accuracy. However, processing larger amount of data requires higher computation time, especially for the Neural Network, as shown in Fig. 4b.

a. Average prediction accuracy. b. Average Computation Time per user.
4.4 Impact of the Size of the Sliding Window
This section evaluates the impact of the size of the sliding window for the JBP approach when D = 84 days of measurements are considered for generating the training set. In particular, Table 3 presents the average prediction accuracy and the computation time per user for different values of the sliding window N. As shown in Table 3, a too low value of the sliding window reduces the capability to detect weekly, daily and hourly user periodical behaviour, which leads to a lower prediction accuracy. However, when setting a too high sliding window, the number of the tuples for generating the training set will become lower and, as a consequence, a worse training process is done, which reduces the prediction accuracy.
5 Conclusions
This paper has proposed a methodology for the prediction of future APs to which users will be connected in a Wi-Fi network. The proposed methodology is based on a supervised learning that makes use of historical user connectivity to build a prediction model. Different approaches have been defined depending the historical data that is used. In general, the PBTP approach, in which the prediction is based according to the most recent APs to which the user connected, provides the best prediction accuracies. However, PBDP or PBWP perform better for users that follow some daily or weekly periodical behavior. As shown, a joint approach (JBP) is able to provide better prediction accuracy than the rest of the approaches separately with a relatively low computation time per user. The impact of the training set size has been illustrated for the JBP approach in terms of prediction accuracy and computation time. As shown, higher amount of days with measurements considered for generating the training set provides higher prediction accuracy at expenses of higher computation time, especially for Neural Networks. The impact of the size of the sliding window has been also evaluated. A too low value of the sliding window results in a worse capability to detect weekly, daily and hourly user periodical behavior while a too large value leads to a too low number of tuples for training. The results indicate that the prediction based on the Neural Network provides a higher prediction accuracy than the prediction based on Random Forest at expenses of an increase in the computation time.
References
Cisco Visual Networking Index: Forecast and Trends, 2017–2022. Cisco White Papers, November, 2018
Chih-Lin, I., Liu, Y., Han, S., Wang, S., Liu, G.: On big data analytics for greener and softer RAN. IEEE Access 3, 3068–3075 (2015)
Nisbet, R., Miner, G., Yale, K.: Handbook of Statistical Analysis and Data Mining Applications, 2nd edn. Academic Press, Cambridge (2017)
Jiang, S., Ferreira, J., González, M.C.: Activity-based human mobility patterns inferred from mobile phone data: a case study of Singapore. IEEE Trans. Big Data 3, 208–219 (2015)
Furletti, B., Gabrielli, L., Rinzivillo, S., Renso, C.: Identifying users’ profiles from mobile calls habits. In: International Workshop on Urban Computing (2012)
Sánchez-González, J., Sallent, O., Pérez-Romero, J., Agustí, R.: On extracting user-centric knowledge for personalised quality of service in 5G Networks. International Symposium on Integrated Network Management (2017)
3GPP TR 23.791: Technical Specification Group Services and System Aspects. Study of Enablers for Network Automation for 5G, Release 15 (2017)
Kumar, A., Om, H.: A secure seamless handover authentication technique for wireless LAN. In: International Conference on Information Technology (2015)
Khong-Lim, Y., Yung-Wey, C.: Optimised access point selection with mobility prediction using hidden Markov model for wireless networks. In: International Conference on Ubiquitous and Future Networks (ICUFN) (2017)
Manweiler, J., Santhapuri, N., Choudhury, R.R., Nelakuditi, S.: Predicting length of stay at WiFi hotspots. In: IEEE International Conference on Computer Communications (INFOCOM), April 2013
Yan, C., Wang, P., Pang, H., Sun, L., Yang, S.: CELoF: WiFi dwell time estimation in free environment. In: Amsaleg, L., Guðmundsson, G., Gurrin, C., Jónsson, B., Satoh, S. (eds.) MMM 2017. LNCS, vol. 10132, pp. 503–514. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-51811-4_41
Han, J., Kamber, M., Pei, J.: Data Mining: Concepts and Techniques. Morgan Kaufman (MK), Elsevier (2006)
Cisco Prime Infrastructure 3.5 Administrator Guide. www.cisco.com
RapidMiner Studio. http://www.rapidminer.com
Acknowledgements
This work has been supported by the Spanish Research Council and FEDER funds under SONAR 5G grant (ref. TEC2017-82651-R).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 IFIP International Federation for Information Processing
About this paper

Cite this paper
Shaabanzadeh, S.S., Sánchez-González, J. (2020). On the Prediction of Future User Connections Based on Historical Records in Wireless Networks. In: Maglogiannis, I., Iliadis, L., Pimenidis, E. (eds) Artificial Intelligence Applications and Innovations. AIAI 2020 IFIP WG 12.5 International Workshops. AIAI 2020. IFIP Advances in Information and Communication Technology, vol 585. Springer, Cham. https://doi.org/10.1007/978-3-030-49190-1_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-49190-1_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-49189-5
Online ISBN: 978-3-030-49190-1
eBook Packages: Computer ScienceComputer Science (R0)