
Abstract
We focus on Burmese name Romanization, a critical task in the translation of Burmese into languages using Latin script. As Burmese is under researched and not well resourced, we collected and manually annotated 2, 335 Romanization instances to enable statistical approaches. The annotation includes string segmentation and alignment between Burmese and Latin scripts. Although previous studies regard syllables as unbreakable units when processing Burmese, in this study, Burmese strings are segmented into well-designed sub-syllabic units to achieve precise and consistent alignment with Latin script. The experiments show that sub-syllabic units are better units than syllables for statistical approaches in Burmese name Romanization. The annotated data and segmentation program have been released under a CC BY-NC-SA license.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
- 2.
Typical ones are the Myanmar Language Commission Transcription System, the Library of Congress’ ALA-LC Romanization index system for Burmese (http://www.loc.gov/catdir/cpso/romanization/burmese.pdf), and the Okell’s system [13].
- 3.
Yayit originally represents
 while in the modern standard Burmese the phoneme
while in the modern standard Burmese the phoneme 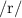 has been merged into
has been merged into 
- 4.
Actually a voiceless sign, e.g., changing
 to
to  .
. - 5.
Yapin can also be combined with
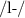 .
. - 6.
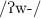 may be argued in some references. The combination appears marginally in borrowing words and interjections.
may be argued in some references. The combination appears marginally in borrowing words and interjections. - 7.
E.g.,
 is actually
is actually  or
or  .
. - 8.
E.g., changing
 to
to 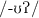 and changing
and changing  to
to  .
. - 9.
The visarga is usually not transcribed and aukmyit is inconsistently represented by a final t in Romanization.
- 10.
Multiple medial consonants for one initial consonant is possible while yapin and yayit cannot appear simultaneously.
- 11.
As mentioned, glottal endings take no tones.
- 12.
However, the swapped order may introduce no problem in displaying, so both orders are used in daily typing.
- 13.
Using GIZA++ [12] at http://www.statmt.org/moses/giza/GIZA++.html.
- 14.
An open-sourced tool is available at https://github.com/lemaoliu/Agtarbidir.
- 15.
- 16.
- 17.
I.e., on the level in the bottom rank in Fig. 1, with no explicit alignment or unit boundaries between characters.
- 18.
SEG cannot be applied to the RNN approach as the alignment and segmentation are not explicit variables.
- 19.
- 20.
The Romanization instance is directly taken from the released data set. A more common Romanization of the Pali-derived name is Wunna.
 while in the modern standard Burmese the phoneme
while in the modern standard Burmese the phoneme 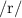 has been merged into
has been merged into 
 to
to  .
.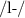 .
.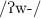 may be argued in some references. The combination appears marginally in borrowing words and interjections.
may be argued in some references. The combination appears marginally in borrowing words and interjections. is actually
is actually  or
or  .
. to
to 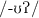 and changing
and changing  to
to  .
.References
Banchs, R.E., Zhang, M., Duan, X., Li, H., Kumaran, A.: Report of NEWS 2015 machine transliteration shared task. In: Proceedings of NEWS, pp. 10–23 (2015)
Costa-Jussà, M.R.: Moses-based official baseline for NEWS 2016. In: Proceedings of NEWS, pp. 88–90 (2016)
Ding, C., Thu, Y.K., Utiyama, M., Finch, A., Sumita, E.: Empirical dependency-based head finalization for statistical Chinese-, English-, and French-to-Myanmar (Burmese) machine translation. In: Proceedings of IWSLT, pp. 184–191 (2014)
Ding, C., Thu, Y.K., Utiyama, M., Sumita, E.: Parsing Myanmar (Burmese) by using Japanese as a pivot. In: Proceedings of ICCA (Myanmar), pp. 158–162 (2016)
Ding, C., Thu, Y.K., Utiyama, M., Sumita, E.: Word segmentation for Burmese (Myanmar). ACM Trans. Asian Low Resour. Lang. Inf. Process. 15(4), 22 (2016)
Finch, A., Liu, L., Wang, X., Sumita, E.: Neural network transduction models in transliteration generation. In: Proceedings of NEWS, pp. 61–66 (2015)
Finch, A., Liu, L., Wang, X., Sumita, E.: Target-bidirectional neural models for machine transliteration. In: Proceedings of NEWS, pp. 78–82 (2016)
Lafferty, J., McCallum, A., Pereira, F.: Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of ICML, pp. 282–289 (2001)
Liu, L., Finch, A., Utiyama, M., Sumita, E.: Agreement on target-bidirectional LSTMs for sequence-to-sequence learning. In: Proceedings of AAAI, pp. 2630–2637 (2016)
Naing, H.M.S., Hlaing, A.M., Pa, W.P., Hu, X., Thu, Y.K., Hori, C., Kawai, H.: A Myanmar large vocabulary continuous speech recognition system. In: Proceedings of APSIPA, pp. 320–327 (2015)
Neubig, G., Nakata, Y., Mori, S.: Pointwise prediction for robust, adaptable Japanese morphological analysis. In: Proceedings of ACL-HLT, pp. 529–533 (2011)
Och, F.J., Ney, H.: A systematic comparison of various statistical alignment models. Comput. Linguist. 29(1), 19–51 (2003)
Okell, J.: A guide to the Romanization of Burmese (1971)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of ACL, pp. 311–318 (2002)
Sha, F., Pereira, F.: Shallow parsing with conditional random fields. In: Proceedings of HLT-NAACT, pp. 134–141 (2003)
Thu, Y.K., Pa, W.P., Finch, A., Ni, J., Sumita, E., Hori, C.: The application of phrase based statistical machine translation techniques to Myanmar grapheme to phoneme conversion. In: Hasida, K., Purwarianti, A. (eds.) Computational Linguistics. CCIS, vol. 593, pp. 238–250. Springer, Singapore (2016). https://doi.org/10.1007/978-981-10-0515-2_17
Thu, Y.K., Pa, W.P., Ni, J., Shiga, Y., Finch, A., Hori, C., Kawai, H., Sumita, E.: HMM based Myanmar text to speech system. In: Proceedings of INTERSPEECH, pp. 2237–2241 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix
Appendix
Figure 6 shows specific annotation instances for a further illustration and demonstration. The data are organized in a three-section format of
-
original Burmese name,
-
original Romanization, and
-
aligned Burmese/Latin graphemes,
separated by |||.
The descriptions of specific instances are as follows.

Specific annotation instances on Burmese name Romanization.
-
I.
An ordinary Romanization instance.
-
II.
A Burmese name with a western expression (Grace) as a component. Generally, such western expressions are segmented according to the Burmese spellings. In this instance, Grace is segmented into /G /@ /r /a /@ /ce. Notice that we just apply the same @ for the dummy vowel on Burmese side and for the silent placeholder on Latin side, which causes no confusion.
-
III.
A Burmese name derived from Pali (Wanna),Footnote 20 where stacked consonants appear (/n /n). The stacked consonants are split and aligned to separate Latin letters. If no doubled Latin letters are used, the second Burmese character will be simply aligned to a silent placeholder @. The stacking operator is always aligned to @.
-
IV.
A Burmese name with complex stacking, that the rhyme of the previous syllable (/in) is stacked with the following onset (/gy).
-
V.
A Burmese name with more complex stacking, that part of the rhyme of the previous syllable (/ein) is stacked with the following onset (/g), which is taking a further vowel diacritic (/i). The instances IV. and V. illustrate the necessity on the segmentation of stacked characters.
-
VI.
A Burmese name with stacked consonants, for which two syllables are kept as one word (Thinzar) in Romanization.
-
VII.
A Burmese name with stacked consonants, for which two syllables are separated as two words (Thin Zar) in Romanization. Notice the Burmese names in instance VI. and VII. are identical. They are treated as two different Romanization instances due to the spellings in Romanization are different.
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ding, C., Pa, W.P., Utiyama, M., Sumita, E. (2018). Burmese (Myanmar) Name Romanization: A Sub-syllabic Segmentation Scheme for Statistical Solutions. In: Hasida, K., Pa, W. (eds) Computational Linguistics. PACLING 2017. Communications in Computer and Information Science, vol 781. Springer, Singapore. https://doi.org/10.1007/978-981-10-8438-6_16
Download citation
DOI: https://doi.org/10.1007/978-981-10-8438-6_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-8437-9
Online ISBN: 978-981-10-8438-6
eBook Packages: Computer ScienceComputer Science (R0)