
Abstract
We consider an Information-Plus-Noise type matrix where the Information matrix is a spiked matrix. When some eigenvalues of the random matrix separate from the bulk, we study how the corresponding eigenvectors project onto those of the spikes. Note that, in an Appendix, we present alternative versions of the earlier results of Bai and Silverstein (Random Matrices Theory Appl 1(1):1150004, 44, 2012) (“noeigenvalue outside the support of the deterministic equivalent measure”) and Capitaine (Indiana Univ Math J 63(6):1875–1910, 2014) (“exact separation phenomenon”) where we remove some technical assumptions that were difficult to handle.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
References
G. Anderson, A. Guionnet, O. Zeitouni, An Introduction to Random Matrices (Cambridge University Press, Cambridge, 2009)
Z.D. Bai, J.W. Silverstein, Spectral Analysis of Large-Dimensional Random Matrices. Mathematics Monograph Series, vol. 2 (Science Press, Beijing, 2006)
Z. Bai, J.W. Silverstein, No eigenvalues outside the support of the limiting spectral distribution of information-plus-noise type matrices. Random Matrices Theory Appl. 1(1), 1150004, 44 (2012)
J.B. Bardet, N. Gozlan, F. Malrieu, P.-A. Zitt, Functional inequalities for Gaussian convolutions of compactly supported measures: explicit bounds and dimension dependence (2018). Bernoulli 24(1), 333–353 (2018)
S.T. Belinschi, M. Capitaine, Spectral properties of polynomials in independent Wigner and deterministic matrices. J. Funct. Anal. 273, 3901–3963 (2017). https://doi.org/10.1016/j.jfa.2017.07.010
S.T. Belinschi, H. Bercovici, M. Capitaine, M. Février, Outliers in the spectrum of large deformed unitarily invariant models. Ann. Probab. 45(6A), 3571–3625 (2017)
F. Benaych-Georges, R.N. Rao, The eigenvalues and eigenvectors of finite, low rank perturbations of large random matrices. Adv. Math. 227(1), 494–521 (2011)
F. Benaych-Georges, R.N. Rao, The singular values and vectors of low rank perturbations of large rectangular random matrices (2011). J. Multivar. Anal. (111), 120–135 (2012)
S.G. Bobkov, F. Götze, Exponential integrability and transportation cost related to logarithmic Sobolev inequalities. J. Funct. Anal. 163(1), 1–28 (1999)
M. Capitaine, Additive/multiplicative free subordination property and limiting eigenvectors of spiked additive deformations of Wigner matrices and spiked sample covariance matrices. J. Theor. Probab. 26(3), 595–648 (2013)
M. Capitaine, Exact separation phenomenon for the eigenvalues of large Information-Plus-Noise type matrices. Application to spiked models. Indiana Univ. Math. J. 63(6), 1875–1910 (2014)
M. Capitaine, C. Donati-Martin, Strong asymptotic freeness for Wigner and Wishart matrices. Indiana Univ. Math. J. 56(2), 767–803 (2007)
F. Benaych-Georges, C. Bordenave, M. Capitaine, C. Donati-Martin, A. Knowles, Spectrum of deformed random matrices and free probability, in Advanced Topics in Random Matrices, ed. by F. Benaych-Georges, D. Chafaï, S. Péché, B. de Tiliére. Panoramas et syntheses, vol. 53 (2018)
R. Couillet, J.W. Silverstein, Z. Bai, M. Debbah, Eigen-inference for energy estimation of multiple sources. IEEE Trans. Inf. Theory 57(4), 2420–2439 (2011)
R.B. Dozier, J.W. Silverstein, On the empirical distribution of eigenvalues of large dimensional information-plus-noise type matrices. J. Multivar. Anal. 98(4), 678–694 (2007)
R.B. Dozier, J.W. Silverstein, Analysis of the limiting spectral distribution of large dimensional information-plus-noise type matrices. J. Multivar. Anal. 98(6), 1099–1122 (2007)
J. Dumont, W. Hachem, S. Lasaulce, Ph. Loubaton, J. Najim, On the capacity achieving covariance matrix for Rician MIMO channels: an asymptotic approach. IEEE Trans. Inf. Theory 56(3), 1048–1069 (2010)
A. Guionnet, B. Zegarlinski, Lectures on logarithmic Sobolev inequalities, in Séminaire de Probabilités, XXXVI. Lecture Notes in Mathematics, vol. 1801 (Springer, Berlin, 2003)
U. Haagerup, S. Thorbjørnsen, Random matrices with complex Gaussian entries. Expo. Math. 21, 293–337 (2003)
U. Haagerup, S. Thorbjørnsen, A new application of random matrices: \(\mathrm {Ext}(C^*_{\mathrm { red}}(F_2))\) is not a group. Ann. Math. (2) 162(2), 711–775 (2005)
W. Hachem, P. Loubaton, J. Najim, Deterministic Equivalents for certain functionals of large random matrices. Ann. Appl. Probab. 17(3), 875–930 (2007)
A.M. Khorunzhy, B.A. Khoruzhenko, L.A. Pastur, Asymptotic properties of large random matrices with independent entries. J. Math. Phys. 37(10), 5033–5060 (1996)
O. Ledoit, S. Péché, Eigenvectors of some large sample covariance matrix ensembles. Probab. Theory Relat. Fields 151, 233–264 (2011)
M. Ledoux, The Concentration of Measure Phenomenon (American Mathematical Society, Providence, 2001)
P. Loubaton, P. Vallet, Almost sure localization of the eigenvalues in a Gaussian information-plus-noise model. Application to the spiked models. Electron. J. Probab. 16, 1934–1959 (2011)
L.A. Pastur, M. Shcherbina, Eigenvalue Distribution of Large Random Matrices. Mathematical Surveys and Monographs (American Mathematical Society, Providence, 2011)
D. Paul, Asymptotics of sample eigenstructure for a large dimensional spiked covariance model. Stat. Sin. 17(4), 1617–1642 (2007)
P. Vallet, P. Loubaton, X. Mestre, Improved subspace estimation for multivariate observations of high dimension: the deterministic signal case. IEEE Trans. Inf. Theory 58(2), 1043–1068 (2012)
D.V. Voiculescu, K. Dykema, A. Nica, Free Random Variables: A Noncommutative Probability Approach to Free Products with Applications to Random Matrices, Operator Algebras and Harmonic Analysis on Free Groups. CRM Monograph Series, vol. 1 (American Mathematical Society, Providence, 1992). ISBN 0-8218-6999-X
J.-s. Xie, The convergence on spectrum of sample covariance matrices for information-plus-noise type data. Appl. Math. J. Chinese Univ. Ser. B 27(2), 181191 (2012)
Acknowledgements
The author is very grateful to Charles Bordenave and Serban Belinschi for several fruitful discussions and thanks Serban Belinschi for pointing out Lemma 4.14. The author also wants to thank an anonymous referee who provided a much simpler proof of Lemma 4.13 and encouraged the author to establish the results for non diagonal perturbations, which led to an overall improvement of the paper.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendix 1
We present alternative versions on the one hand of the result in [3] about the lack of eigenvalues outside the support of the deterministic equivalent measure, and on the other hand of the result in [11] about the exact separation phenomenon. These new versions (Theorems 4.5 and 4.6 below) deal with random variables whose imaginary and real parts are independent, but remove the technical assumptions ((1.10) and “b 1 > 0” in Theorem 1.1 in [3] and “ω σ,ν,c(b) > 0” in Theorem 1.2 in [11]). The proof of Theorem 4.5 is based on the results of [5]. The arguments of the proof of Theorem 1.2 in [11] and Theorem 4.5 lead to the proof of Theorem 4.6.
Theorem 4.4
Consider
and assume that
-
1.
X N = [X ij]1≤i≤n,1≤j≤N is a n × N random matrix such that [X ij]i≥1,j≥1 is an infinite array of random variables which satisfy (4.1) and (4.2) and such that \( \Re (X_{ij})\) , ℑ(X ij), \((i,j)\in \mathbb {N}^2\) , are independent, centered with variance 1∕2.
-
2.
A N is an n × N nonrandom matrix such that ∥A N∥ is uniformly bounded.
-
3.
n ≤ N and, as N tends to infinity, c N = n∕N → c ∈ ]0, 1].
-
4.
[x, y], x < y, is such that there exists δ > 0 such that for all large N, \( ]x-\delta ; y+\delta [ \subset \mathbb {R}\setminus \mathrm {supp} (\mu _{\sigma ,\mu _{A_N A_N^*},c_N})\) where \(\mu _{\sigma ,\mu _{A_N A_N^*},c_N}\) is the nonrandom distribution which is characterized in terms of its Stieltjes transform which satisfies Eq.(4.4) where we replace c by c N and ν by \(\mu _{A_N A_N^*}.\)
Then, we have
Since, in the proof of Theorem 4.4, we will use tools from free probability theory, for the reader’s convenience, we recall the following basic definitions from free probability theory. For a thorough introduction to free probability theory, we refer to [29].
-
A \(\mathbb {C}^*\)-probability space is a pair \(\left (\mathbb {A}, \tau \right )\) consisting of a unital \( \mathbb {C}^*\)-algebra \(\mathbb {A}\) and a state τ on \(\mathbb {A}\) i.e. a linear map \(\tau : \mathbb {A}\rightarrow \mathbb {C}\) such that \(\tau (1_{\mathbb { A}})=1\) and τ(aa ∗) ≥ 0 for all \(a \in \mathbb {A}\). τ is a trace if it satisfies τ(ab) = τ(ba) for every \((a,b)\in \mathbb {A}^2\). A trace is said to be faithful if τ(aa ∗) > 0 whenever a ≠ 0. An element of \(\mathbb {A}\) is called a noncommutative random variable.
-
The noncommutative ⋆ -distribution of a family a = (a 1, …, a k) of noncommutative random variables in a \(\mathbb { C}^*\)-probability space \(\left (\mathbb {A}, \tau \right )\) is defined as the linear functional μ a : P↦τ(P(a, a ∗)) defined on the set of polynomials in 2k noncommutative indeterminates, where (a, a ∗) denotes the 2k-uple \((a_1,\ldots ,a_k,a_1^*,\ldots ,a_k^*)\). For any selfadjoint element a 1 in \(\mathbb {A}\), there exists a probability measure \(\nu _{a_1}\) on \(\mathbb {R}\) such that, for every polynomial P, we have
$$\displaystyle \begin{aligned}\mu_{a_1}(P)=\int P(t) \mathrm{d}\nu_{a_1}(t).\end{aligned} $$Then we identify \(\mu _{a_1}\) and \(\nu _{a_1}\). If τ is faithful then the support of \(\nu _{a_1}\) is the spectrum of a 1 and thus \(\|a_1\| = \sup \{|z|, z\in \mathrm {support} (\nu _{a_1})\}\).
-
A family of elements (a i)i ∈ I in a \(\mathbb {C}^*\)-probability space \(\left (\mathbb {A}, \tau \right )\) is free if for all \(k\in \mathbb {N}\) and all polynomials p 1, …, p k in two noncommutative indeterminates, one has
$$\displaystyle \begin{aligned} \tau(p_1(a_{i_1},a_{i_1}^*)\cdots p_k (a_{i_k},a_{i_k}^*))=0\end{aligned} $$(4.85)whenever i 1 ≠ i 2, i 2 ≠ i 3, …, i k−1 ≠ i k, (i 1, …i k) ∈ I k, and \(\tau (p_l(a_{i_l},a_{i_l}^*))=0\) for l = 1, …, k.
-
A noncommutative random variable x in a \(\mathbb {C}^*\)-probability space \(\left (\mathbb {A}, \tau \right )\) is a standard semicircular random variable if x = x ∗ and for any \(k\in \mathbb {N}\),
$$\displaystyle \begin{aligned}\tau(x^k)= \int t^k d\mu_{sc}(t)\end{aligned} $$where
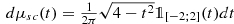 is the semicircular standard distribution.
is the semicircular standard distribution. -
Let k be a nonnull integer number. Denote by \(\mathbb {P}\) the set of polynomials in 2k noncommutative indeterminates. A sequence of families of variables (a n)n≥1 = (a 1(n), …, a k(n))n≥1 in C ∗-probability spaces \(\left (\mathbb {A}_n, \tau _n\right )\) converges in ⋆ -distribution, when n goes to infinity, to some k-tuple of noncommutative random variables a = (a 1, …, a k) in a \(\mathbb {C}^*\)-probability space \(\left (\mathbb {A}, \tau \right )\) if the map \(P\in \mathbb {P} \mapsto \tau _n( P(a_n,a_n^*))\) converges pointwise towards \(P\in \mathbb {P} \mapsto \tau ( P(a,a^*))\).
-
k noncommutative random variables a 1(n), …, a k(n), in C ∗-probability spaces \(\left (\mathbb {A}_n, \tau _n\right )\), n ≥ 1, are said asymptotically free if (a 1(n), …, a k(n)) converges in ⋆ -distribution, as n goes to infinity, to some noncommutative random variables (a 1, …, a k) in a \(\mathbb {C}^*\)-probability space \(\left (\mathbb {A}, \tau \right )\) where a 1, …, a k are free.
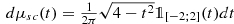 is the semicircular standard distribution.
is the semicircular standard distribution.We will also use the following well known result on asymptotic freeness of random matrices. Let \(\mathbb {A}_n\) be the algebra of n × n matrices with complex entries and endow this algebra with the normalized trace defined for any \(M\in \mathbb {A}_n\) by \(\tau _n(M) =\frac {1}{n}\mathrm {Tr}(M)\). Let us consider a n × n so-called standard G.U.E matrix, i.e. a random Hermitian matrix \(\mathbb {G}_n = [\mathbb {G}_{jk}]_{j,k=1}^n\), where \(\mathbb {G}_{ii}\), \(\sqrt {2} \Re (\mathbb {G}_{ij})\), \(\sqrt {2} \Im (\mathbb {G}_{ij})\), i < j are independent centered Gaussian random variables with variance 1. For a fixed real number t independent from n, let \(H_n^{(1)}, \ldots , H_n^{(t)}\) be deterministic n × n Hermitian matrices such that \(\max _{i=1}^t\sup _n \Vert H_n^{(i)} \Vert < +\infty \) and \((H_n^{(1)}, \ldots , H_n^{(t)})\), as a t-tuple of noncommutative random variables in \((\mathbb {A}_n, \tau _n)\), converges in distribution when n goes to infinity. Then, according to Theorem 5.4.5 in [1], \( \frac {\mathbb {G}_n}{\sqrt {n}}\) and \((H_n^{(1)}, \ldots , H_n^{(t)})\) are almost surely asymptotically free i.e. almost surely, for any polynomial P in t+1 noncommutative indeterminates,
where h 1, …, h t and s are noncommutative random variables in some \(\mathbb {C}^*\)-probability space \((\mathbb {A}, \tau )\) such that (h 1, …, h t) and s are free, s is a standard semi-circular noncommutative random variable and the distribution of (h 1, …, h t) is the limiting distribution of \((H_n^{(1)}, \ldots , H_n^{(t)})\).
Finally, the proof of Theorem 4.4 is based on the following result which can be established by following the proof of Theorem 1.1 in [5]. First, note that the algebra of polynomials in non-commuting indeterminates X 1, …, X k, becomes a ⋆ -algebra by anti-linear extension of \((X_{i_1}X_{i_2}\ldots X_{i_m})^*=X_{i_m}\ldots X_{i_2}X_{i_1}\).
Theorem 4.5
Let us consider three independent infinite arrays of random variables, \( [W^{(1)}_{ij}]_{i\geq 1,j\geq 1}\) , \( [W^{(2)}_{ij}]_{i\geq 1,j\geq 1}\) and [X ij]i≥1,j≥1 where
-
for l = 1, 2, \(W^{(l)}_{ii}\) , \(\sqrt {2}\Re (W^{(l)}_{ij})\) , \(\sqrt {2} \Im (W^{(l)}_{ij}), i<j\) , are i.i.d centered and bounded random variables with variance 1 and \(W^{(l)}_{ji}=\overline {W^{(l)}_{ij}}\) ,
-
\(\{\Re (X_{ij}), \Im (X_{ij}), i\in \mathbb {N}, j \in \mathbb {N}\}\) are independent centered random variables with variance 1∕2 and satisfy (4.1) and (4.2).
For any \((N,n)\in \mathbb {N}^2\) , define the (n + N) × (n + N) matrix:
where \(X_N=[X_{ij}]_{ \begin {array}{ll}1\leq i\leq n{,}1 \leq j\leq N\end {array}}, \; W^{(1)}_n= [W^{(1)}_{ij}]_{1\leq i,j\leq n},\; W^{(2)}_N= [W^{(2)}_{ij}]_{1\leq i,j\leq N}\).
Assume that n = n(N) and \(\lim _{N\rightarrow +\infty }\frac {n}{N}=c \in ]0,1].\)
Let t be a fixed integer number and P be a selfadjoint polynomial in t + 1 noncommutative indeterminates.
For any \(N \in \mathbb {N}^2\) , let \((B_{n+N}^{(1)},\ldots ,B_{n+N}^{(t)})\) be a t −tuple of (n + N) × (n + N) deterministic Hermitian matrices such that for any u = 1, …, t, \( \sup _{N} \Vert B_{n+N}^{(u)} \Vert < \infty \) . Let \((\mathbb {A}, \tau )\) be a C ∗-probability space equipped with a faithful tracial state and s be a standard semi-circular noncommutative random variable in \((\mathbb {A}, \tau )\) . Let \(b_{n+N}=(b_{n+N}^{(1)},\ldots ,b_{n+N}^{(t)})\) be a t-tuple of noncommutative selfadjoint random variables which is free from s in \((\mathbb {A},\tau )\) and such that the distribution of b n+N in \((\mathbb {A},\tau )\) coincides with the distribution of \((B_{n+N}^{(1)},\ldots , B_{n+N}^{(t)})\) in \(({ M}_{n+N}(\mathbb {C}), \frac {1}{n+N}\mathrm {Tr})\).
Let [x, y] be a real interval such that there exists δ > 0 such that, for any large N, [x − δ, y + δ] lies outside the support of the distribution of the noncommutative random variable \( P\left (s, b_{n+N}^{(1)},\ldots ,b_{n+N}^{(t)}\right )\) in \((\mathbb {A},\tau )\) . Then, almost surely, for all large N,
Proof
We start by checking that a truncation and Gaussian convolution procedure as in Section 2 of [5] can be handled for such a matrix as defined by (4.87), to reduce the problem to a fit framework where,
-
(H)
for any N, (W n+N)ii, \(\sqrt {2}\Re ((W_{n+N})_{ij})\), \(\sqrt {2} \Im ((W_{n+N})_{ij}), i<j, i \leq n+N,\; j\leq n+N\), are independent, centered random variables with variance 1, which satisfy a Poincaré inequality with common fixed constant C PI.
Note that, according to Corollary 3.2 in [24], (H) implies that for any \(p\in \mathbb {N}\),
Remark 4.3
Following the proof of Lemma 2.1 in [5], one can establish that, if (V ij)i≥1,j≥1 is an infinite array of random variables such that \(\{\Re (V_{ij}), \Im (V_{ij}), i\in \mathbb {N}, j \in \mathbb {N}\}\) are independent centered random variables which satisfy (4.1) and (4.2), then almost surely we have
where
Then, following the rest of the proof of Section 2 in [5], one can prove that for any polynomial P in 1 + t noncommutative variables, there exists some constant L > 0 such that the following holds. Set \(\theta ^*=\sup _{i,j}\mathbb {E}\left (\left |X_{ij}\right |{ }^3\right )\). For any 0 < 𝜖 < 1, there exist C 𝜖 > 8θ ∗ (such that \(C_\epsilon >\max _{l=1,2} \vert W^{(l)}_{11}\vert \) a.s.) and δ 𝜖 > 0 such that almost surely for all large N,
where, for any C > 8θ ∗ such that \(C>\max _{l=1,2} \vert W^{(l)}_{11}\vert \) a.s., and for any δ > 0, \(\tilde W_{N+n}^{C,\delta }\) is a (n + N) × (n + N) matrix which is defined as follows. Let \((\mathbb {G}_{ij})_{i\geq 1, j\geq 1}\) be an infinite array which is independent of \(\{X_{ij}, W^{(1)}_{ij}, W^{(2)}_{ij}, (i,j)\in \mathbb {N}^2\}\) and such that \(\sqrt {2} \Re \mathbb {G}_{ij}\), \( \sqrt {2} \Im \mathbb {G}_{ij}\), i < j, \(\mathbb {G}_{ii}\), are independent centred standard real gaussian variables and \({\mathbb {G}}_{ij}=\overline {\mathbb {G}}_{ji}\). Set \(\mathbb {G}_{n+N}= [\mathbb {G}_{ij}]_{1\leq i,j \leq n+N }\) and define \(X_N^C=[X_{ij}^C]_{ \begin {array}{ll}1\leq i\leq n{,}1 \leq j\leq N\end {array}}\)as in (4.18) . Set
\(\tilde W_{N+n}^{C,\delta }\) satisfies (H) (see the end of Section 2 in [5]). (4.89) readily yields that it is sufficient to prove Theorem 4.5 for \(\tilde W_{N+n}^{C,\delta }\).
Therefore, assume now that W N+n satisfies (H). As explained in Section 6.2 in [5], to establish Theorem 4.5, it is sufficient to prove that for all \(m \in \mathbb {N}\), all self-adjoint matrices γ, α, β 1, …, β t of size m × m and all 𝜖 > 0, almost surely, for all large N, we have
((4.90) is the analog of Lemma 1.3 for r = 1 in [5]). Finally, one can prove (4.90) by following Section 5 in [5].
We will need the following lemma in the proof of Theorem 4.4.
Lemma 4.16
Let A N and c N be defined as in Theorem 4.4 . Define the following (n + N) × (n + N) matrices: \(P=\begin {pmatrix} I_n & (0) \\ (0) & (0) \end {pmatrix} Q=\begin {pmatrix} (0) & (0) \\ (0) & I_N\end {pmatrix}\) and \(\mathbf {A}=\begin {pmatrix} (0) & A_N \\ (0) & (0) \end {pmatrix}\) . Let s, p N, q N, a N be noncommutative random variables in some \(\mathbb {C}^*\) -probability space \(\left ( \mathbb {A}, \tau \right )\) such that s is a standard semi-circular variable which is free with (p N, q N, a N) and the ⋆ -distribution of (A, P, Q) in \(\left (M_{N+n}(\mathbb {C}),\frac {1}{N+n} \mathrm {Tr}\right )\) coincides with the ⋆ -distribution of (a N, p N, q N) in \(\left ( \mathbb {A}, \tau \right ). \) Then, for any 𝜖 ≥ 0, the distribution of \( ({\sqrt {1+c_N}}\sigma p_N s q_N+ {\sqrt {1+c_N}}\sigma q_N s p_N + {\mathbf {a}}_N+ \mathbf { a}_N^*)^2 +\epsilon p_N\) is \(\frac {n}{N+n} T_\epsilon \star \mu _{\sigma , \mu _{A_NA_N^*}, c_N} +\frac {n}{N+n} \mu _{\sigma , \mu _{A_NA_N^*}, c_N}+\frac {N-n}{N+n} \delta _{0}\) where \({T_\epsilon } {\star } \mu _{\sigma , \mu _{A_NA_N^*}, c_N}\) is the pushforward of \( \mu _{\sigma , \mu _{A_NA_N^*}, c_N}\) by the map z↦z + 𝜖.
Proof
Here N and n are fixed. Let k ≥ 1 and C k be the k × k matrix defined by

Define the k(n + N) × k(n + N) matrices
For any k ≥ 1, the ⋆ -distributions of \((\hat A_k, \hat P_k, \hat Q_k)\) in \(( M_{k(N+n)}(\mathbb {C}), \frac {1}{k(N+n)}\mathrm {Tr})\) and (A, P, Q) in \(( M_{(N+n)}(\mathbb {C}), \frac {1}{(N+n)}\mathrm {Tr})\) respectively, coincide. Indeed, let \(\mathbb {K}\) be a noncommutative monomial in \(\mathbb {C}\langle X_1,X_2,X_3,X_4\rangle \) and denote by q the total number of occurrences of X 3 and X 4 in \(\mathbb {K}\). We have
so that
Note that if q is even then \(C_k^q=I_k\) so that
Now, assume that q is odd. Note that PQ = QP = 0, A Q = A, Q A = 0, A P = 0 and P A = A (and then Q A ∗ = A ∗, A ∗Q = 0, P A ∗ = 0 and A ∗P = A ∗). Therefore, if at least one of the terms X 1X 2, X 2X 1, X 2X 3, X 3X 1, X 4X 2 or X 1X 4 appears in the noncommutative product in \(\mathbb {K}\), then \( \mathbb {K}(P,Q,\mathbf {A}, {\mathbf {A}}^*)=0,\) so that (4.91) still holds. Now, if none of the terms X 1X 2, X 2X 1, X 2X 3, X 3X 1, X 4X 2 or X 1X 4 appears in the noncommutative product in \(\mathbb {K}\), then we have \({\mathbb {K}}(P,Q,\mathbf {A}, {\mathbf {A}}^*)=\tilde {\mathbb {K}}(\mathbf {A}, {\mathbf {A}}^*)\) for some noncommutative monomial \(\tilde {\mathbb { K}}\in \mathbb {C} \langle X,Y\rangle \) with degree q. Either the noncommutative product in \(\tilde {\mathbb {K}}\) contains a term such as X p or Y p for some p ≥ 2 and then, since A 2 = (A ∗)2 = 0, we have \(\tilde {\mathbb {K}}(\mathbf {A}, {\mathbf {A}}^*)=0\), or \(\tilde {\mathbb {K}}(X,Y)\) is one of the monomials \( (XY)^{\frac {q-1}{2}}X\) or \(Y(XY)^{\frac {q-1}{2}}\). In both cases, we have \(\mathrm {Tr} \tilde {\mathbb {K}}(\mathbf {A}, {\mathbf {A}}^*)=0\) and (4.91) still holds.
Now, define the k(N + n) × k(N + n) matrices
where \(\check { A}\) is the kn × kN matrix defined by

It is clear that there exists a real orthogonal k(N + n) × k(N + n) matrix O such that \(\tilde P_k=O\hat P_k O^*\), \(\tilde Q_k=O\hat Q_k O^*\) and \(\tilde A_k=O\hat A_k O^*\). This readily yields that the noncommutative ⋆ -distributions of \((\hat A_k, \hat P_k, \hat Q_k)\) and \(({\tilde A}_k, \tilde P_k, \tilde Q_k)\) in \(( M_{k(N+n)}(\mathbb {C}), \frac {1}{k(N+n)}\mathrm {Tr})\) coincide. Hence, for any k ≥ 1, the distribution of \(({\tilde A}_k, \tilde P_k, \tilde Q_k)\) in \(( M_{k(N+n)}(\mathbb {C}), \frac {1}{k(N+n)}\mathrm {Tr})\) coincides with the distribution of (a N, p N, q N) in \(\left ( \mathbb {A}, \tau \right ). \) By Theorem 5.4.5 in [1], it readily follows that the distribution of \(({\sqrt {1+c_N}}\sigma p_N s q_N+ {\sqrt {1+c_N}}\sigma q_N s p_N + {\mathbf {a}}_N+ {\mathbf {a}}_N^*)^2 +\epsilon p_N\) is the almost sure limiting distribution, when k goes to infinity, of \(({\sqrt {1+c_N}}\sigma \tilde P_k\frac {\mathbb {G} }{\sqrt {k(N+n)}}\tilde Q_k+ {\sqrt {1+c_N}} \sigma \tilde Q_k \frac {\mathbb {G} }{\sqrt {k(N+n)}}\tilde P_k+\tilde A_k+\tilde A_k^*)^2+\epsilon \tilde P_k\) in \(( M_{k(N+n)}(\mathbb {C}), \frac {1}{k(N+n)}\mathrm {Tr})\), where \(\mathbb {G}\) is a k(N + n) × k(N + n) GUE matrix with entries with variance 1. Now, note that
where \(\mathbb {G}_{kn\times kN}\) is the upper right kn × kN corner of \( \mathbb {G}\). Thus, noticing that \(\mu _{\check { A}\check { A}^*}=\mu _{A_NA_N^*}\), the lemma follows from [15].
Proof of Theorem 4.4
Let W be a (n + N) × (n + N) matrix as defined by (4.87) in Theorem 4.5. Note that, with the notations of Lemma 4.16, for any 𝜖 ≥ 0,
Thus, for any 𝜖 ≥ 0,
Let [x, y] be such that there exists δ > 0 such that for all large N, \( ]x-\delta ; y+\delta [ \subset \mathbb {R}\setminus \mathrm {supp} (\mu _{\sigma ,\mu _{A_N A_N^*},c_N})\).
-
(i)
Assume x > 0. Then, according to Lemma 4.16 with 𝜖 = 0, there exists δ′ > 0 such that for all large n, ]x − δ′;y + δ′[ is outside the support of the distribution of \( ({\sqrt {1+c_N}}\sigma p_N s q_N+ {\sqrt {1+c_N}}\sigma q_N s p_N + {\mathbf {a}}_N+ {\mathbf {a}}_N^*)^2 \). We readily deduce that almost surely for all large N, according to Theorem 4.5, there is no eigenvalue of \(({\sqrt {1+c_N}}P\frac {\sigma W}{\sqrt {N+n}}Q+ {\sqrt {1+c_N}}Q\frac {\sigma W}{\sqrt {N+n}}P+\mathbf {A}+{\mathbf {A}}^*)^2 \) in [x, y]. Hence, by (4.92) with 𝜖 = 0, almost surely for all large N, there is no eigenvalue of M N in [x, y].
-
(ii)
Assume x = 0 and y > 0. There exists 0 < δ′ < y such that [0, 3δ′] is for all large N outside the support of \(\mu _{\sigma , \mu _{A_NA_N^*}, c_N}\). Hence, according to Lemma 4.16, [δ′∕2, 3δ′] is outside the support of the distribution of \( ({\sqrt {1+c_N}}\sigma p_N s q_N+ {\sqrt {1+c_N}}\sigma q_N s p_N + {\mathbf {a}}_N+ {\mathbf {a}}_N^*)^2 +\delta ' p_N\). Then, almost surely for all large N, according to Theorem 4.5, there is no eigenvalue of \(({\sqrt {1+c_N}}P\frac {\sigma W}{\sqrt {N+n}}Q+ {\sqrt {1+c_N}}Q\frac {\sigma W}{\sqrt {N+n}}P+\mathbf {A}+{\mathbf {A}}^*)^2 +\delta ' P \) in [δ′, 2δ′] and thus, by (4.92), no eigenvalue of \( (\sigma \frac {X}{\sqrt {N}}+A_N)(\sigma \frac {X_N}{\sqrt {N}}+A_N)^*+\delta ' I_n\) in [δ′, 2δ′]. It readily follows that, almost surely for all large N, there is no eigenvalue of \( (\sigma \frac {X_N}{\sqrt {N}}+A_N)(\sigma \frac {X_N}{\sqrt {N}}+A_N)^*\) in [0, δ′]. Since moreover, according to (i), almost surely for all large N, there is no eigenvalue of \( (\sigma \frac {X_N}{\sqrt {N}}+A_N)(\sigma \frac {X_N}{\sqrt {N}}+A_N)^*\) in [δ′, y], we can conclude that there is no eigenvalue of M N in [x, y].
The proof of Theorem 4.4 is now complete. □
We are now in a position to establish the following exact separation phenomenon.
Theorem 4.6
Let M n as in (4.84) with assumptions [1–4] of Theorem 4.4 . Assume moreover that the empirical spectral measure \(\mu _{A_NA_N^*}\) of \(A_NA_N^*\) converges weakly to some probability measure ν. Then for N large enough,
where ω σ,ν,c is defined in (4.5). With the convention that \(\lambda _0(M_N)=\lambda _0(A_NA_N^*)=+\infty \) and \(\lambda _{n+1}(M_N)=\lambda _{n+1}(A_NA_N^*)=-\infty \) , for N large enough, let i N ∈{0, …, n} be such that
Then
Remark 4.4
Since \(\mu _{\sigma ,\mu _{A_N A_N^*},c_N}\) converges weakly towards μ σ,ν,c assumption 4. implies that ∀0 < τ < δ, \([x-\tau ; y+\tau ] \subset \mathbb {R} \setminus \mathrm {supp}~ \mu _{\sigma ,\nu ,c}\).
Proof of Theorem 4.4
(4.93) is proved in Lemma 3.1 in [11].
-
If ω σ,ν,c(x) < 0, then i N = n in (4.94) and moreover we have, for all large N, \(\omega _{{\sigma ,\mu _{A_N A_N^*},c_N}}(x)<0\). According to Lemma 2.7 in [11], we can deduce that, for all large N, [x, y] is on the left hand side of the support of \(\mu _{\sigma ,\mu _{A_N A_N^*},c_N}\) so that ] −∞;y + δ] is on the left hand side of the support of \(\mu _{\sigma ,\mu _{A_N A_N^*},c_N}\). Since [−|y|− 1, y] satisfies the assumptions of Theorem 4.4, we readily deduce that almost surely, for all large N, λ n(M N) > y. Hence (4.95) holds true.
-
If ω σ,ν,c(x) ≥ 0, we first explain why it is sufficient to prove (4.95) for x such that ω σ,ν,c(x) > 0. Indeed, assume for a while that (4.95) is true whenever ω σ,ν,c(x) > 0. Let us consider any interval [x, y] satisfying condition 4. of Theorem 4.4 and such that ω σ,ν,c(x) = 0; then i N = n in (4.94). According to Proposition 4.1, \(\omega _{{\sigma ,\nu ,c}}(\frac {x+y}{2})> 0\) and then almost surely for all large N, λ n(M N) > y. Finally, sticking to the proof of Theorem 1.2 in [11] leads to (4.95) for x such that ω σ,ν,c(x) > 0.
Appendix 2
We first recall some basic properties of the resolvent (see [12, 22]).
Lemma 4.17
For a N × N Hermitian matrix M, for any \(z \in \mathbb {C}\setminus \mathrm {spect}(M)\) , we denote by G(z) := (zI N − M)−1 the resolvent of M.
Let \(z \in \mathbb {C}\setminus \mathbb {R}\) ,
-
(i)
∥G(z)∥≤|ℑz|−1.
-
(ii)
|G(z)ij|≤|ℑz|−1 for all i, j = 1, …, N.
-
(iii)
G(z)M = MG(z) = −I N + zG(z).
Moreover, for any N × N Hermitian matrices M 1 and M 2,
The following technical lemmas are fundamental in the approach of the present paper.
Lemma 4.18 (Lemma 4.4 in [6])
Let \(h: \mathbb {R}\rightarrow \mathbb {R}\) be a continuous function with compact support. Let B N be a N × N Hermitian matrix and C N be a N × N matrix. Then
Moreover, if B N is random, we also have
Lemma 4.19
Let f be an analytic function on \(\mathbb {C}\setminus \mathbb {R}\) such that there exist some polynomial P with nonnegative coefficients, and some positive real number α such that
Then, for any h in \(\mathbb {C}^\infty (\mathbb {R}, \mathbb {R})\) with compact support, there exists some constant τ depending only on h, α and P such that
We refer the reader to the Appendix of [12] where it is proved using the ideas of [20].
Finally, we recall some facts on Poincaré inequality. A probability measure μ on \(\mathbb {R}\) is said to satisfy the Poincaré inequality with constant C PI if for any \(\mathbb {C}^1\) function \(f: \mathbb {R}\rightarrow \mathbb {C}\) such that f and f′ are in L 2(μ),
with \(\mathbf {V}(f) = \int \vert f-\int f d\mu \vert ^2 d\mu \).
We refer the reader to [9] for a characterization of the measures on \(\mathbb {R}\) which satisfy a Poincaré inequality.
If the law of a random variable X satisfies the Poincaré inequality with constant C PI then, for any fixed α ≠ 0, the law of αX satisfies the Poincaré inequality with constant α 2C PI.
Assume that probability measures μ 1, …, μ M on \(\mathbb {R}\) satisfy the Poincaré inequality with constant C PI(1), …, C PI(M) respectively. Then the product measure μ 1 ⊗⋯ ⊗ μ M on \(\mathbb {R}^M\) satisfies the Poincaré inequality with constant \(\displaystyle {C_{PI}^*=\max _{i\in \{1,\ldots ,M\}}C_{PI}(i)}\) in the sense that for any differentiable function f such that f and its gradient gradf are in L 2(μ 1 ⊗⋯ ⊗ μ M),
with \(\mathbf {V}(f) = \int \vert f-\int f d\mu _1\otimes \cdots \otimes \mu _M \vert ^2 d\mu _1\otimes \cdots \otimes \mu _M\) (see Theorem 2.5 in [18]) .
Lemma 4.20 (Theorem 1.2 in [4])
Assume that the distribution of a random variable X is supported in [−C;C] for some constant C > 0. Let g be an independent standard real Gaussian random variable. Then X + δg satisfies a Poincaré inequality with constant \(C_{PI}\leq \delta ^2 \exp \left ( 4C^2/\delta ^2\right )\).
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this chapter

Cite this chapter
Capitaine, M. (2018). Limiting Eigenvectors of Outliers for Spiked Information-Plus-Noise Type Matrices. In: Donati-Martin, C., Lejay, A., Rouault, A. (eds) Séminaire de Probabilités XLIX. Lecture Notes in Mathematics(), vol 2215. Springer, Cham. https://doi.org/10.1007/978-3-319-92420-5_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-92420-5_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92419-9
Online ISBN: 978-3-319-92420-5
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)