
Abstract
There has been considerable controversy in recent years as to whether information held in working memory (WM) is rapidly forgotten or automatically transferred to long-term memory (LTM). Although visual WM capacity is very limited, we appear able to store a virtually infinite amount of information in visual LTM. Still, LTM retrieval often fails. Some view visual WM as a mental sketchpad that is wiped clean when new information enters, but not a consistent precursor of LTM. Others view the WM and LTM systems as inherently linked. Distinguishing between these possibilities has been difficult, as attempts to directly manipulate the active holding of information in visual WM has typically introduced various confounds. Here, we capitalized on the WM system’s capacity limitation to control the likelihood that visual information was actively held in WM. Our young-adult participants (N = 103) performed a WM task with unique everyday items, presented in groups of two, four, six, or eight items. Presentation time was adjusted according to the number of items. Subsequently, we tested participants’ LTM for items from the WM task. LTM was better for items presented originally within smaller WM set sizes, indicating that WM limitations contribute to subsequent LTM failures, and that holding items in WM enhances LTM encoding. Our results suggest that a limit in WM capacity contributes to an LTM encoding bottleneck for trial-unique familiar objects, with a relatively large effect size.
Similar content being viewed by others

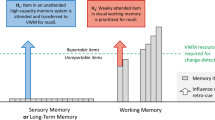

Introduction
Working memory (WM) is a system for holding mental representations temporarily for use in thought and action (Cowan, 2017). A crucial feature of this system is its limit of three to four objects concurrently (Adam et al., 2017; Cowan, 2001). In contrast, we seem able to store unlimited information in long-term memory (LTM) (e.g., Brady et al., 2008). Still, a large proportion of the information we encounter is quickly forgotten. For instance, you might forget your colleague’s outfit despite recently seeing it in the hallway. This illustrates what we term the LTM-encoding bottleneck. Even if all of the information one encounters is somehow encoded into LTM, much of it is at least not encoded in a manner sufficient for later recognition. Here, we asked whether this bottleneck can be explained by WM limitations.
How WM and LTM systems interact has implications for theories of memory, learning, and cognition. WM capacity is linked to fluid intelligence (Conway et al., 2005; Daneman & Carpenter, 1980) and educational attainment (Gathercole et al., 2004). High-WM-capacity individuals’ advantages may stem partly from their ability to retain comparatively more information in WM at once, which promotes better LTM transfer.
The relationship between WMFootnote 1 and LTM remains controversial (Cowan, 2019). Some theorists view the two systems as closely related, regarding WM as a temporarily activated, capacity-limited subset of LTM information, which can include rapidly learned and still active new associations (e.g., Cowan, 1988, 2019; Morey et al., 2013). Others propose that WM and LTM are separate streams, based largely on neurological findings of selective deficits of WM with relatively intact LTM (e.g., Shallice & Warrington, 1970). In the visual modality, on which we focus, some propose that information is held in WM via a “visual cache,” likened to a mental sketchpad from which information is not retained for long; it is seen as an inconsistent precursor of episodic LTM (Logie et al., 2009; Shimi & Logie, 2019). Here, we re-examine whether holding visual information in WM improves LTM encoding.
The idea that WM acts as a bottleneck for LTM storage was already present in Atkinson and Shiffrin’s (1968) seminal model of memory. The transfer from verbal WM to LTM has been controversial, and the time available to encode items is often conflated with the time available for maintenance. Hartshorne and Makovski (2019) meta-analytically reviewed and supplemented this literature, which includes only a few studies using visual materials and suggests a small effect size (d=~0.2) for the benefit of WM encoding on LTM. A WM-encoding bottleneck may contribute to discrepant results, and our study pursues the hypothesis that the likelihood of evidence of LTM encoding depends on the likelihood of an item from an array entering WM.
Recent attempts to explore the relationship between visual WM and LTM have produced intriguing results. Some evidence indicates that WM is cleared out on a moment-by-moment basis, as participants failed to notice the repetition of identical arrays of color–shape–location bindings during a WM task, suggesting that arrays were not well encoded into LTM (Logie et al., 2009; Shimi & Logie, 2019). In contrast, Fukuda and Vogel (2019) found that participants remembered items from a WM task in a subsequent LTM test, and that high-WM-capacity individuals recalled more items from the WM task. Others found that while repetition of WM arrays does not necessarily boost WM performance, repeated arrays were recognized above chance levels in a subsequent LTM test (Olson & Jiang, 2004; Olson et al., 2005; see also Chun & Jiang 1998; Chun & Jiang 2003). Hartshorne and Makovski (2019) compared LTM for single items that were passively viewed, retained in WM for recognition, or attended and used as probes, and found mixed evidence for an LTM benefit for WM items.
Here, we test LTM formation in a simple fashion, presenting arrays of different numbers of known objects for immediate recognition of a probe that could come from the array, and later testing LTM recognition of items not probed before. We allowed an equal processing time per item regardless of the array set size. In previous work, Logie et al. (2009) and Shimi and Logie (2019) instead examined slow effects of array repetitions in situations in which participants may not have managed to encode the complete WM array on a given trial because the number of objects exceeded typical WM capacity. Comparing partial array representations might explain the failure to notice array repetition. Fukuda and Vogel (2019) tested LTM for the WM items, but did not allow an equal amount of processing time per item across all array sizes. Time is important not only to allow initial entry of items into a capacity-limited WM (Woodman & Vogel, 2005), but also to allow further consolidation of WM information (Ricker et al., 2018). By using known objects rather than abstract objects such as colored bars, and presenting each object in only one array, we attempt to maximize the likelihood that pre-existing knowledge can play a role to allow the creation of accessible new LTM representations (Endress & Potter, 2014; Shoval et al., 2020).
We relied on a core distinguishing feature of the WM system: its capacity limit (three to four 4 items; Adam et al., 2017; Cowan, 2001). Thus, by manipulating an item’s WM set size, we manipulated the probability that it was held in WM. We restricted LTM testing to items that were not probed in WM or used as WM probes to avoid repeated exposure or, worse, a repeated testing confound (Roediger III & Karpicke, 2006). If items being held in WM matters for their LTM encoding, then items from lower array sizes in the WM procedure should be better remembered in a later LTM test, because an item in a smaller array is more likely to be held in WM.
We examined our basic hypothesis by assessing the mean LTM contents as a function of the mean WM contents and by examining the correlation between an individual’s success at the WM task and the LTM task.
Method
The methods, and all analyses (except those labeled as “exploratory”) were pre-registered on the Open Science Framework at [https://osf.io/jrzwg?view_only=fca6a8ce3aa54c05b18675f73291d9be].
Participants
Pilot data and sample size rationale
We tested 30 pilot participants to detect any issues in our online data collection procedure and to ensure that participants could complete the study in a reasonable timeframe (see Online Supplementary Material, Section 1, for mean performance values and sample size determination procedures). Based on simulations, 100 participants appeared to be required for results to be of interest to others in the field, regardless of the outcome.
Final sample
For online data collection, the software PsyToolKit was used (Stoet, 2010, 2017). We recruited participants via prolific.com, for safe and convenient remote data collection, producing results seemingly comparable to those obtained in laboratory studies (Germine et al., 2012; Peer et al., 2017). Participants were paid £5 for completing the study. See Online Supplementary Material, Section 2, for detailed inclusion criteria. Our pre-registered target sample size was 100, but 104 participants were accidentally recruited online. One participant was excluded per our set exclusion criteria (see Online Supplementary Material, Section 3), so the final N was 103 participants. The age of the final sample was 24.2 years (SD = 3.50, range 18–30 years), with the gender distribution female 62.1% and male 37.9%. Detailed demographic information is reported in the Online Supplementary Material, Section 4. On average, participants completed the experiment in 32.2 min (SD = 8.4; range = 21–78 min). The study was approved by the local Internal Review Board.
General study design
Participants completed three different tasks: First, a WM probe-recognition task, followed by a brief mathematical distraction task, and, finally, a second probe-recognition memory test, assessing LTM for items from the WM task. Participants read written instructions prior to each task. Figure 1 shows a trial in the WM phase and two trials within the LTM phase. The crucial manipulation was the WM set size (i.e., the number of items presented simultaneously: two, four, six, or eight items). The WM array presentation time was adjusted according to the number of items (250 ms per item). Participants were not informed that they would be tested on the WM items again but, at the very end of the session, we asked them whether they had expected a retest on these items.

Outline of some typical trials. (A) Working-memory (WM) task trial. (B) Two trials in the long-term memory (LTM) task. The memory array set size in the WM task varied between two, four, six, or eight items, and the presentation time was adjusted to be 250 ms per item. During the WM response phase, participants indicated whether the probe item was the same as an item in the array, or different, and also selected their level of confidence, by a mouse-click on the relevant option. In the LTM task, participants indicated whether items had been studied in the WM task
Working memory (WM) task
Memory items were selected from the Microsoft Office “Icons,” consisting of various easily recognizable images, including animals, symbols, furniture, food items, etc. All items were presented in black on a light gray background. Participants studied a total of 384 unique memory items in the WM task, at varying set sizes (two, four, six, or eight items). Items in an array were presented in an imaginary circle around a central fixation cross ( + ), such that one item could be placed at every 45° increment (Fig. 1). For set size 8, each space was occupied, and for lower set sizes, locations were selected at random.
Each trial started with a 250-ms central fixation cross, followed by the memory array, and a 2,000-ms delay, before the probe item and response options were presented. On each trial, an array was presented for 250 ms times the number of items in the array, and was followed by a 2,000-ms delay and then a probe item, which was drawn randomly from the array on half of the trials and was a new item not seen in any array on the other half. Particpants responded by clicking on one of the following options presented on the screen along with the probe: “sure same,” “believe same,” “guess same,” “guess different,” “believe different,” or “sure different.” As a way to ensure that participants could not let the experiment finish without responding, after a 10-min period of no response the program timed out and the participant would not be counted in the analysis, though no one did this. The order of trials and selection of items for each trial were randomized for each participant. The number of trials at the four array sizes was 48, 24, 16, and 12, respectively, resulting in 96 unique memory items at each set size.
Distraction task
Next, participants completed a distraction task lasting 60 s. During this task, participants verified mathematical equations of the form a×b+c=d, where a, b, and c were integers from 1 to 9, and d was equal to a×b+c or differed from that expression by ±1. The integers for a, b, and c were drawn randomly with replacement from the integers 1–9, inclusive. The number d that was shown was correct on half the trials and incorrect on the other half. Participants responded by clicking “Correct” or “Incorrect” on the screen. Participants completed as many trials as possible during the 60-s interval.
Long-term memory (LTM) task
On each trial, participants saw a probe item and had to say whether that item was studied in the WM task or was a new item (see Fig. 1). Participants responded to each probe item by clicking on one of the following options on the screen: “sure studied,” “believe studied,” “guess studied,” “guess new,” “believe new,” or “sure new.” Items that were probed in the WM task or served as lures in that task were not probed in the LTM task, to avoid repeated exposure. Each participant responded to a total of 213 items in the LTM task (46 new items, 36 items from set size 2, 42 items from set size 4, 44 items from set size 6, and 45 items from set size 8). As in the WM task, a 10-min pause was grounds for exclusion of the participant.
Results
Memory tasks
Accuracy
In statistical analyses, we use a nomenclature in which BF10 refers to the Bayes Factor for the presence of an effect and BF01 refers to absence of an effect, where BF01 = 1/BF10. Figure 2 shows the use of the response scale for the WM task (left panel) and the LTM task (right panel). Lower ratings indicate more confident same/studied responses, and higher ratings indicate more confident “different/new” responses. The general important pattern can be observed from Fig. 2. Clearly, in WM, participants distinguished fairly well between trials with probes that were old (present in the array, or same) versus new (not in any array, or different). As set size increased, however, ratings began to come closer together, indicating poorer average performance. Similarly, the average LTM rating for items originally presented in set size 2 (M=2.80, SD=1.70) was lower than for those presented at set size 8 (M=3.63, SD=1.63; d=0.50), reflecting a stronger tendency to correctly – and confidently – identify items from lower WM set sizes as studied.

Average ratings (1–6; 1 = sure same/studied, 2 = believe same/studied, 3 = guess same/studied, 4 = guess different/new, 5 = believe different/new, 6 = sure different/new) by set size in the working memory (WM) task. (A) WM task ratings; (B) long-term memory (LTM) task ratings. Circles show ratings on trials when the probe item was different or new, and diamonds show performance when the probe item was the same as one in the studied set, or old. The black circles and diamonds represent the overall mean ratings. The transparent, smaller circles and diamonds represent individual participants’ mean ratings. These are jittered to avoid overlap. Higher ratings indicate higher confidence that the item was different, and lower ratings indicate higher confidence that the item was the same. New items in the LTM phase were not studied within any set size in the WM phase. Error bars on the group means represent 95% confidence intervals
We used two types of accuracy scoring. First, “strict” scoring, in which responses were only considered correct when participants reported some confidence in their response (using “Sure” or “Believe”) but guessing (e.g., guess new for a new item) was considered as incorrect in this scoring. Next, “lenient” scoring in which all correct responses (including guessing in the correct direction) were scored as correct. WM accuracy across set sizes is presented in Fig. 3. Using Bayesian Logistic Regression (brms; R, Bürkner; 2017, 2018), and considering responses marked as guesses as incorrect (i.e., “strict” scoring), we found credible evidence that memory performance decreased as set size increased (η=-0.47; SE=0.01, 95% CI [-0.50, -0.45]). This trial-level analytical approach was appropriate to account for the increased uncertainty at set sizes with lower trial numbers. For details, see Online Supplementary Material, Section 5. The BF in favor of the model including set size was 3.38 × 10306 over a model not including this factor, indicating that the set size manipulation influenced WM performance as expected.

Memory accuracy by working memory (WM) set size. (A) WM hits (i.e., correctly identified “Same” trials); (B) WM correct rejections (i.e., correctly identified “Different” trials); (C) long-term memory (LTM) accuracy. Black triangles and the solid line show the average WM accuracy across trials in which responses in the guessing range were always were scored as incorrect (strict scoring). The dashed line and squares show accuracy in selecting same or different regardless of participants’ exact confidence rating (lenient scoring). Light squares show individual subjects’ accuracy by set size for the lenient scoring (the points are jittered slightly in the figure to avoid overlap). Error bars represent 95% confidence intervals
Two separate pre-registered analyses addressed the key question of whether successful encoding of items in WM influences subsequent LTM representations. First, we tested whether performance in the LTM task varied as a function of WM set size (coded as a continuous numeric variable) using generalTestBF (R package BayesFactor’ see Online Supplementary Material, Section 6 for details). We found “decisive” evidence that LTM memory performance was better for items presented for lower-set size items, both when coding “guesses” as incorrect (BF10 = 7.06 × 1097) and when coding them correct (BF10 = 1.99 × 1072). See Fig. 3 for accuracy rates across set sizes. The LTM accuracy for items originally presented in set size 2 (M = 0.65, SD = 0.48) was higher than that for items presented at set size 8 (M = 0.45, SD = 0.50; d = 0.41). The ratio of novel to old items was uneven (46 new items vs. 167 old). Although the prevalence of old items may alter the bias so as to affect the levels of both hits and false alarms, any such effect would presumably be across all set sizes and therefore could not in itself produce the set size effect.
The 29.1% of participants who reported expecting a LTM test of the WM items did not remember items better than naïve participants (exploratory Bayesian ANOVA; BF01 = 51.68 and 7.88 for strict and lenient accuracy scoring).
Analysis of the number of items in WM and LTM for each WM set size
A second kind of measure was used to address the question of how many of the items encoded into WM in fact made it into LTM. For each individual, the proportion of items from a given size of WM set was in memory at the time of (1) WM testing; p(WM), and (2) LTM testing; p(LTM). The goal was to form a ratio of LTM to WM item presence. For this measure, we ignored whether a response was sure, believe, or guess, and just considered whether the correct half of the response scale was used. The p(WM) estimates were obtained using correct detection of an old item (i.e., a hit, h) and calling a new item old (i.e., a false alarm, f). The model to estimate p(WM) is derived from work by Pashler (1988) as applied to the present test situation by Cowan et al. (2013, “reverse-Pashler” formula).Footnote 2 Participants should respond correctly when the probed item is in WM and otherwise guess that the item is new with a certain rate (g). The rate of correct detection of old items, h, equals the probability that the probe item is in WM plus the probability that it is not in WM but that a correct “old” guess g is given:
When the item is new there is no match, so performance depends on the guessing rate and an incorrect response (f) is made at the rate, f=g.
Combining these formulas, it can be shown that
A comparable formula can be used with LTM data (hits, hl for correctly detected old items and false alarms, fl for incorrect responses that a novel item was old) to yield the proportion of items in LTM:
Multiplying p(WM) and p(LTM) by the set size yields an estimate of the number of items from an array available at those test stages. In accordance with preregistered exclusion criteria, 45 observations of negative p(WM) values (6) or p(LTM) values (39) resulted in the exclusion of 34 participants, some of whom had more than one negative value. Figure 4 shows the number of items in WM (left-hand panel) and LTM (right-hand panel) for each WM array size.

Estimated items in working memory (WM) and long-term memory (LTM). (A) Items in WM (k). (B) Items in LTM. Items in LTM were calculated for each participant by multiplying p(LTM) by the number of items in the relevant WM set size. P(LTM) < 0 values were recoded as 0. Black circles represent the mean number of estimated items. Gray circle outlines represent individual subject estimates and are jittered slightly to avoid overlap. Error bars on the mean are 95% confidence intervals
As Table 1 shows, the likelihood that items that were encoded in WM were subsequently remembered in the LTM task seems higher for set size 2 (54%) than for larger set sizes, which seem similar to one another (37-39%), and the LTM/WM. The ratio differed across set sizes (BF10 = 40.93). An exploratory analysis excluding set size 2 showed evidence against a difference between the remaining set sizes (BF01 = 6.59). These findings suggest that when WM reached capacity, items encoded into WM had a certain likelihood of being recalled in LTM. When the stimuli were presumably below capacity at set size 2, it appears that more intensive transfer into LTM could take place. Thirty-four participants with floor-level scores in at least one set size had been excluded, but, to include them, in an exploratory analysis we adjusted k < 1 to 1, and p(LTM) ≤ 0 to 0 and again obtained the difference in LTM/WM ratio between set sizes, BF10 = 9.85, and evidence for the null when set size 2 was excluded, BF01 = 7.70 (see Fig. 5).

Long-term memory (LTM)/working memory (WM) ratios, by WM set size. The large black triangles show the average for each set size (and error bars are 95% confidence intervals). Smaller triangle outlines show individual subject points. Gray triangles show adjusted values (either WM k < 1, and was adjusted to 1, or p(LTM) was negative and was adjusted to 0). To avoid excessive whitespace, 11 LTM/WM Ratio values > 1 were removed from this figure (four from set size 6, seven from set size 8); see Online Supplementary Material, Fig. S2 for the complete figure including these values
The effect of WM trial inaccuracy on LTM
We conducted an exploratory analysis to test the effect of WM trial-accuracy on LTM retention. We used only data from same trials, since errors guessing “different” when the item was the same is the clearest indication that at least one item (i.e., the probed item) in that array was not held in WM. The beneficial effect of WM trial accuracy on LTM appeared greater at lower set sizes (BF = 29.36; see Table S3, and for detailed parameter estimates, see Online Supplementary Material, Section 10, in which we also report a similar analysis for Different trial data and a more holistic registered analysis). The effect was by far the clearest for two-item arrays with a “same” probe, which resulted in higher LTM performance on array items from trials in which the WM probe was recognized (M = .53, SD = .50) compared to when it was not recognized (M = .37, SD = .49).
Correlations between items in WM versus LTM
We carried out an exploratory analysis in which we averaged the number of items across supra-capacity set sizes (4, 6, and 8), at which most participants were below ceiling, for WM (k) and for LTM (multiplying p(LTM) by the relevant set size). To allow inclusion of all participants at each set size, we replaced instances in which WM k<1 with 1 and values of p(LTM)≤0 with zero. The result (Fig. 6) indicated a positive correlation, r = .24, BF10 = 6.01. There was imperfect transfer from WM to LTM in every participant (i.e., all points below the diagonal line). See Online Supplementary Material (Section 11) for an alternative, pre-registered analysis.

Estimated number of items in long-term memory (LTM) for each subject as a function of their working memory (WM) capacity (k). The LTM estimate was calculated for each participant by multiplying p(LTM) by the number of items in the WM set size, and averaging this across all set sizes, not including values from set size 2. The WM capacity (k) value was obtained by averaging k from all set sizes except set size 2. Black points represent individual participants, gray points participants for which at least one p(WM) or p(LTM) value was adjusted. The black line represents a frequentist linear regression line, and the shaded area includes the 95% confidence region. The gray diagonal line represents hypothetical perfect transfer in which the number of items in LTM=WM k
Mathematical distraction task
On average, participants attempted 14.8 (SD = 5.0, range 4–32) problems during this 1-min distraction task, and the average accuracy rate was 86.6% (SD = 12.3, range 40–100% accurate), indicating that participants were generally engaged with this task.
Discussion
Although the visual WM and LTM systems are often considered to be linked, specifics of their relationship are contentious. Our results provide strong evidence that WM encoding enhances subsequent LTM representations, contradicting suggestions that items held in visual WM are quickly erased (e.g., Logie et al., 2009; Shimi & Logie, 2019). To summarize our key findings: (1) both WM and LTM performance levels were higher for items presented as part of a smaller set in WM (Figs. 3 and 4). For LTM, this difference appeared especially large between items sub-capacity (set size 2), and supra-capacity set sizes (4, 6, and 8); (2) the ratio of items in LTM to WM was constant across arrays of four, six, and eight items (Fig. 5); and (3) performance levels on WM and LTM were correlated on an individual-participant level. When one attempts to hold an overwhelming amount of information in mind, one is likely to forget some of it, in both immediate and delayed testing. Our results suggest that WM encoding acts as a bottleneck for visual LTM retention (Atkinson & Shiffrin, 1968; Fukuda & Vogel, 2019), and verify that WM and LTM encoding are both constrained by a WM capacity limit (Brady et al., 2008; Endress & Potter, 2014; Shoval et al., 2020). Our effect size for unique, familiar objects, comparing the smallest and largest WM array set sizes (d = 0.41), is about double what Hartshorne and Makovski (2019) obtained in the research literature using less familiar objects, reinforcing the importance of linking into distinct information already in LTM (Brady et al., 2008; Endress & Potter, 2014; Shoval et al., 2020).
The pattern of ratios between items in LTM and WM indicated stronger LTM encoding at a sub-capacity set size of two items (Fig. 5). That pattern warrants follow-up research as it would be consistent with studies indicating that precision declines when set size increases from one to two to three items, though not much beyond three. Embedded processes models of WM suggest that some items may be held in a limited focus of attention (Cowan, 1988), which may hold one to two items (Öztekin et al., 2010; Sutterer et al., 2019) or three to five items (Cowan, 2001). Being in the focus of attention might enhance LTM encoding (see Cowan, 1988, 2019). Perhaps the greater difference between LTM retention at set size two, as compared to all larger set sizes, reflects that items from set size 2 are more likely to enter the focus of attention, compared to items presented as part of larger set sizes.
At lower WM set sizes, and especially in trials with a two-item array and a probe drawn from the array, WM trial-failure resulted in poor LTM memory for items in arrays drawn from those trials. This result for two-item arrays cannot be attributed to a capacity limit, but it corresponds to the expected effect of trial inattention (looking away or mind-wandering), as in the model of Rouder et al. (2008). Indeed, ongoing fluctuations of attention, WM maintenance, and LTM performance are known to be linked (e.g., Adam et al., 2015; Aly & Turk-Browne, 2016; deBettencourt et al., 2019; Murray et al., 2011; Unsworth & Robison, 2016).
We observed a correlation among individuals for information in WM and LTM, in an exploratory analysis of the number of items held in WM and LTM averaged across set sizes 4, 6, and 8. This result provides further support for the notion that holding information in WM is beneficial for subsequent LTM retrieval, and is aligned with the results of Fukuda and Vogel (2019). Given that the association was not very strong, future work could investigate individual differences in encoding style that might distinguish between those with good versus poor LTM (e.g., along the lines of Craik & Lockhart, 1972), or on individual differences in the functioning of brain areas highly relevant to LTM, including the hippocampus and nearby areas (e.g., Wixted et al., 2018).
Various WM processes may produce the LTM bottleneck effect we have observed. It may be driven by a limit in the number of items that can be actively represented in the brain simultaneously, if such active representations underlie LTM encoding (Cowan, 2019). Interestingly, our results differed from those of Bartsch et al. (2019), who did not find evidence for a set size effect on LTM, using sequential presentation of word pairs. Perhaps sequential presentation resulted in equal entry to focus of attention for all items, regardless of set size. In contrast, in our procedure, perhaps only certain items were held in the focus of attention during the 2,000-ms retention interval. This discrepancy may indicate that an item’s presence in the focus of attention during WM maintenance may be crucial for subsequent LTM recognition (Cowan, 1988, 2019).
Maintenance of items in WM may rely on attentional refreshing (Barrouillet et al., 2004; Camos et al., 2018) or verbal rehearsal (Baddeley et al., 1975; Forsberg et al., 2019), but their effects on LTM have been disputed (Bartsch et al., 2018; Hartshorne & Makovski, 2019).
Elaboration strategies, such as mental imagery or chunk formation, do boost LTM (Dunlosky & Hertzog, 2001) and should only be possible for items concurrently in WM. Undoubtedly, participants approach the task with various strategies (Logie, 2018). Inasmuch as the strategic approaches efficient for WM differ from those efficient for LTM (Bartsch et al., 2018), voluntary elaborative strategies seem unlikely to drive our finding that WM array size affected LTM retention, since expecting the LTM test did not seem to improve performance (cf. Fukuda & Vogel, 2019). However, it is still possible that participants opted for different strategies for different set sizes. Future research, perhaps with sequential presentation, should explore which specific WM processes contribute to the effect.
To conclude, items successfully held in WM were more likely retained in LTM. The ratio of the number of items held in LTM to items held WM from the array during which the item was first presented appeared fairly constant for arrays above capacity. When the WM array did not fill up WM capacity, additional resources seemed to boost LTM encoding further. Overall, our results suggest that WM processes are indeed part of the LTM encoding bottleneck.
Open practices statement
The methods, and all analyses (except those labeled as “exploratory”) were pre-registered on the Open Science Framework at [https://osf.io/jrzwg?view_only=fca6a8ce3aa54c05b18675f73291d9be]. Due to space limitations, some preregistered analyses are reported in the Online Supplementary Material. Data, analysis code, and study materials are available at [https://osf.io/qfzn3/?view_only=490083f12cb1461694f8afc6b1109b70].
Notes
We use the term visual WM for our procedure but some find the term “visual short-term memory” more appropriate, and some consider the two terms interchangeable (Cowan, 2017).
Note that we have found it more natural to redefine hits as correct detection of an “old” or studied item, and false alarms as incorrect indications that a novel item was “old” or studied, differing from Pasher and Cowan et al.
References
Adam, K. C., Mance, I., Fukuda, K., & Vogel, E. K. (2015). The contribution of attentional lapses to individual differences in visual working memory capacity. Journal of Cognitive Neuroscience, 27(8), 1601-1616.
Adam, K. C., Vogel, E. K., & Awh, E. (2017). Clear evidence for item limits in visual working memory. Cognitive Psychology, 97, 79-97.
Aly, M., & Turk-Browne, N. B. (2016). Attention promotes episodic encoding by stabilizing hippocampal representations. Proceedings of the National Academy of Sciences, 113(4), E420-E429.
Atkinson, R. C., & Shiffrin, R. M. (1968). Human memory: A proposed system and its control processes. Psychology of Learning and Motivation, 2(4), 89-195.
Baddeley, A.D., Thomson, N., & Buchanan, M. (1975). Word length and the structure of short term memory. Journal of Verbal Learning and Verbal Behavior, 14, 575-589.
Barrouillet, P., Bernardin, S., & Camos, V. (2004). Time constraints and resource sharing in adults' working memory spans. Journal of Experimental Psychology: General, 133(1), 83.
Bartsch, L. M., Singmann, H., & Oberauer, K. (2018). The effects of refreshing and elaboration on working memory performance, and their contributions to long-term memory formation. Memory & Cognition, 46(5), 796-808.
Bartsch, L. M., Loaiza, V. M., & Oberauer, K. (2019). Does limited working memory capacity underlie age differences in associative long-term memory?. Psychology and Aging, 34(2), 268.
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences, 105(38), 14325-14329.
Bürkner P. C. (2017). Brms: An R Package for Bayesian Multilevel Models Using Stan. Journal of Statistical Software, 80(1), 1–28.
Bürkner P. C. (2018). Advanced Bayesian Multilevel Modeling with the R Package brms. The R Journal, 10(1), 395–411.
Camos, V., Johnson, M. R., Loaiza, V. M., Portrat, S., Souza, A. S., & Vergauwe, E. (2018). What is attentional refreshing in working memory? Annals of the New York Academy of Sciences, 1424(1), 19-32.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36(1), 28-71.
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(2), 224.
Conway, A. R., Kane, M. J., Bunting, M. F., Hambrick, D. Z., Wilhelm, O., & Engle, R. W. (2005). Working memory span tasks: A methodological review and user’s guide. Psychonomic Bulletin & Review, 12(5), 769-786.
Cowan, N. (1988). Evolving conceptions of memory storage, selective attention, and their mutual constraints within the human information-processing system. Psychological Bulletin, 104(2), 163.
Cowan, N. (1992). Verbal memory span and the timing of spoken recall. Journal of Memory and Language, 31, 668-684.
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24(1), 87-114.
Cowan, N. (2017). The many faces of working memory and short-term storage. Psychonomic Bulletin & Review, 24, 1158–1170.
Cowan, N. (2019). Short-term memory based on activated long-term memory: A review in response to Norris (2017). Psychological Bulletin, 145, 822-847.
Cowan, N., Blume, C. L., & Saults, J. S. (2013). Attention to attributes and objects in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(3), 731.
Craik, F. I., & Lockhart, R. S. (1972). Levels of processing: A framework for memory research. Journal of Verbal Learning and Verbal Behavior, 11(6), 671-684.
Daneman, M., & Carpenter, P. A. (1980). Individual differences in working memory and reading. Journal of Memory and Language, 19(4), 450.
DeBettencourt, M. T., Keene, P. A., Awh, E., & Vogel, E. K. (2019). Real-time triggering reveals concurrent lapses of attention and working memory. Nature Human Behaviour, 3(8), 808-816.
Dunlosky, J., & Hertzog, C. (2001). Measuring strategy production during associative learning: The relative utility of concurrent versus retrospective reports. Memory & Cognition, 29(2), 247-253.
Endress, A. D., & Potter, M. C. (2014). Large capacity temporary visual memory. Journal of Experimental Psychology: General, 143(2), 548.
Fukuda, K., & Vogel, E. K. (2019). Visual short-term memory capacity predicts the “bandwidth” of visual long-term memory encoding. Memory & Cognition, 47(8), 1481-1497.
Forsberg, A., Johnson, W., & Logie, R. H. (2019). Aging and feature-binding in visual working memory: The role of verbal rehearsal. Psychology and Aging, 34(7), 933.
Gathercole, S. E., Pickering, S. J., Knight, C., & Stegmann, Z. (2004). Working memory skills and educational attainment: Evidence from national curriculum assessments at 7 and 14 years of age. Applied Cognitive Psychology: The Official Journal of the Society for Applied Research in Memory and Cognition, 18(1), 1-16.
Germine, L., Nakayama, K., Duchaine, B. C., Chabris, C. F., Chatterjee, G., & Wilmer, J. B. (2012). Is the Web as good as the lab? Comparable performance from Web and lab in cognitive/perceptual experiments. Psychonomic Bulletin & Review, 19(5), 847-857.
Hartshorne, J. K., & Makovski, T. (2019). The effect of working memory maintenance on long-term memory. Memory & Cognition, 47(4), 749-763.
Logie, R. (2018). Human cognition: Common principles and individual variation. Journal of Applied Research in Memory and Cognition, 7(4), 471-486.
Logie, R. H., Brockmole, J. R., & Vandenbroucke, A. R. (2009). Bound feature combinations in visual short-term memory are fragile but influence long-term learning. Visual Cognition, 17(1-2), 160-179.
Morey, C. C., Morey, R. D., van der Reijden, M., & Holweg, M. (2013). Asymmetric cross-domain interference between two working memory tasks: Implications for models of working memory. Journal of Memory and Language, 69(3), 324-348.
Murray, A. M., Nobre, A. C., & Stokes, M. G. (2011). Markers of preparatory attention predict visual short-term memory performance. Neuropsychologia, 49(6), 1458-1465.
Olson, I. R., & Jiang, Y. (2004). Visual short-term memory is not improved by training. Memory & Cognition, 32(8), 1326-1332.
Olson, I. R., Jiang, Y., & Moore, K. S. (2005). Associative learning improves visual working memory performance. Journal of Experimental Psychology: Human Perception and Performance, 31(5), 889.
Öztekin, I., Davachi, L., & McElree, B. (2010). Are representations in working memory distinct from representations in long-term memory? Neural evidence in support of a single store. Psychological Science, 21(8), 1123-1133.
Pashler, H. (1988). Familiarity and visual change detection. Perception & Psychophysics, 44, 369 378.
Peer, E., Brandimarte, L., Samat, S., & Acquisti, A. (2017). Beyond the Turk: Alternative platforms for crowdsourcing behavioral research. Journal of Experimental Social Psychology, 70, 153-163.
Ricker, T.J., Nieuwenstein, M.R., Bayliss, D.M., & Barrouillet, P. (2018). Working memory consolidation: insights from studies on attention and working memory. Annals of the New York Academy of Sciences, 1424, 8-18.
Roediger III, H. L., & Karpicke, J. D. (2006). The power of testing memory: Basic research and implications for educational practice. Perspectives on Psychological Science, 1(3), 181-210.
Rouder, J.N., Morey, R.D., Cowan, N., Zwilling, C.E., Morey, C.C., & Pratte, M.S. (2008). An assessment of fixed-capacity models of visual working memory. Proceedings of the National Academy of Sciences USA (PNAS), 105, 5975–5979.
Shallice, T., & Warrington, E.K. (1970). Independent functioning of verbal memory stores: A neuropsychological study. Quarterly Journal of Experimental Psychology, 22, 261-273.
Shimi, A., & Logie, R. H. (2019). Feature binding in short-term memory and long-term learning. Quarterly Journal of Experimental Psychology, 72(6), 1387-1400.
Shoval, R., Luria, R., & Makovski, T. (2020). Bridging the gap between visual temporary memory and working memory: The role of stimuli distinctiveness. Journal of Experimental Psychology: Learning, Memory, and Cognition, 46, 1258–1269.
Stoet, G. (2010). PsyToolkit - A software package for programming psychological experiments using Linux. Behavior Research Methods, 42(4), 1096-1104.
Stoet, G. (2017). PsyToolkit: A novel web-based method for running online questionnaires and reaction-time experiments. Teaching of Psychology, 44(1), 24-31.
Sutterer, D. W., Foster, J. J., Adam, K. C., Vogel, E. K., & Awh, E. (2019). Item-specific delay activity demonstrates concurrent storage of multiple active neural representations in working memory. PLoS biology, 17(4), e3000239.
Unsworth, N., & Robison, M. K. (2016). The influence of lapses of attention on working memory capacity. Memory & Cognition, 44(2), 188-196.
Wixted, J.T. Goldinger, S.D., Squire, L.R., Kuhn, J.R., Papesh, M.H., Smith, K.A., Treiman, D.M., & Steinmetz, P.N. (2018). Coding of episodic memory in the human hippocampus. PNAS, 115, 1093–1098.
Woodman, G.F., & Vogel, E.K. (2005). Fractionating working memory: Consolidation and maintenance are independent processes. Psychological Science, 16, 106 113.
Acknowledgements
We thank Bret Glass for assisting in data collection and acknowledge NIH Grant R01-HD021338 to N. Cowan.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 838 kb)
Rights and permissions
About this article

Cite this article
Forsberg, A., Guitard, D. & Cowan, N. Working memory limits severely constrain long-term retention. Psychon Bull Rev 28, 537–547 (2021). https://doi.org/10.3758/s13423-020-01847-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-020-01847-z