
Abstract
Substantial evidence suggests that individual differences in estimates of working memory capacity reflect differences in how effectively people use their intrinsic storage capacity. This suggests that estimated capacity could be increased by instructions that encourage more effective encoding strategies. The present study tested this by giving different participants explicit strategy instructions in a change detection task. Compared to a condition in which participants were simply told to do their best, we found that estimated capacity was increased for participants who were instructed to remember the entire visual display, even at set sizes beyond their capacity. However, no increase in estimated capacity was found for a group that was told to focus on a subset of the items in supracapacity arrays. This finding confirms the hypothesis that encoding strategies may influence visual working memory performance, and it is contrary to the hypothesis that the optimal strategy is to filter out any items beyond the storage capacity.
Similar content being viewed by others

Introduction
Visual working memory (VWM) is a fundamental cognitive construct that is associated with a number of factors, including educational achievement, fluid intelligence, and top-down attentional control (Bengson & Mangun, 2011; Cowan, 2005; Vogel, McCollough, & Machizawa, 2005; Kane, Bleckley, Conway, & Engle, 2001; Conway, Cowan, & Bunting, 2001). Despite extensive study concerning the relationship between VWM and other cognitive processes, the exact mechanism by which capacity limits manifest is an issue of continuing debate (Franconeri, Alvarez, & Cavanagh, 2013; Cusack, Lehmann, Veldsman, & Mitchell, 2009; Luck & Vogel, 2013; Zhang & Luck, 2008; Bleckley et al., 2003). Estimates of VWM capacity (denoted K max) are often assumed to reflect the whole capacity of the memory system (i.e., the number of “slots” or the amount of some representational resource). However, performance on working memory tasks is limited by other factors as well, such as the ability to avoid mind wandering (Mcvay & Kane, 2009; Mrazek, Smallwood, Franklin, Chin, Baird, & Schooler, 2012), variations in encoding strategy (Cusack, Lehmann, Veldsman, & Mitchell, 2009), and the effectiveness of attentional filtering (Cowan & Morey, 2006). Consequently, individual differences in estimated capacity may not reflect differences in the amount of representational medium but may instead, or in addition, reflect variations in these other factors. To distinguish between actual and estimated storage capacity, we will use K max to denote an individual’s actual storage capacity (which is a purely theoretical construct), and we will use k̂ max to denote an estimate of this storage capacity in a given task.
Attentional filtering is the best-studied factor that influences k̂ max (Cowan, & Morey, 2006; Vogel & Machizawa, 2004; Kane, et al., 2001). There are two ways that filtering may be important. First, irrelevant information must be filtered out to maximize the amount of relevant information stored in VWM; indeed, physiological measures have shown that low-k̂ max individuals store more irrelevant information than high-k̂ max individuals (Vogel, McCollough, & Machizawa, 2005; McNab & Klingberg, 2008). Second, when the set size of the to-be-encoded array exceeds K max, attempting to store all of the items may cause interference that leads to inefficient storage. Consistent with this possibility, several studies have observed a drop in k̂ max at higher set sizes (e.g., Cusack et al., 2009), especially among low-k̂ max individuals and people with schizophrenia (Gold, Fuller, Robinson, McMahon, Braun, & Luck, 2006; Fukuda, Woodman, & Vogel, 2015; but see Morey & Cowan, 2005 and Saults & Cowan, 2007 for studies that failed to observe this decline in k̂ max). An explicit assumption of prior work (Cusack et al., 2009; Linke, Vicente-Grabovetsky, Mitchell & Cusack, 2011) is that this latter kind of filtering is under strategic control and that some individuals achieve high k̂ max scores because they realize that, when faced with a supracapacity array, the optimal strategy is to select only a subset of the array for VWM encoding. In contrast, other individuals exhibit low k̂ max scores because they take a suboptimal strategy of attempting to encode everything into VWM (Cusack et al., 2009; Linke et al., 2011).
In the present study, we tested the effect of these strategic factors on estimates of K max directly at varying set-sizes by instructing participants explicitly to: (1) try to remember the entire display regardless of set-size; (2) focus on a subset of the display when capacity is exceeded; or (3) simply “do your best” (which served as a control condition). We predicted that trying to remember the entire display should yield decreased performance at higher set sizes whereas focusing on a subset of the display should yield increased performance at higher set-sizes.
To preview the results, we found exactly the opposite: relative to the do-your-best condition, performance at the higher set sizes was increased in participants who were instructed to remember the entire display and decreased in participants who were instructed to focus on a subset of the items. Some possible explanations will be described in the Discussion.
Methods
Participants
A group of 168 undergraduate students at the University of California, Davis participated in the experiment in exchange for course credit.Footnote 1 Informed consent was obtained, and all participants had normal or corrected-to-normal visual acuity and normal color vision. Four participants were removed from the sample due to confusion about the stimulus-response mapping. Each participant was assigned to one of three instruction groups. The assigned instruction rotated systematically as participants were recruited so that each condition was equally likely to be tested at a given point in the academic term.
Stimuli and procedure
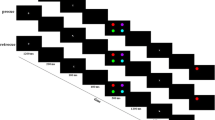
All stimuli were presented on a 19-inch CRT monitor with a gray background. Figure 1 depicts the stimulus sequence for the change-detection task. For a given trial, arrays of four, six, or eight colored squares (0.95° × 0.95°) were presented with the color of each square selected randomly from a set of seven colors: blue, red, violet, yellow, black, white and green (these colors were selected randomly with replacement for all set-sizes, with the constraint that no color appeared more than twice in a display). The squares were presented within a 13° × 9° region, and each square was at least 4° from the neighboring squares.

Example of the stimulus sequence used in the change detection task. (Not to scale)
Participants completed five blocks of 45 trials each. On each trial, a sample array of either four, six or eight squares was presented for 100 ms (Fig. 1). After a 900-ms delay, a test array was presented for 2000 ms, and participants were instructed to indicate via an unspeeded button press whether the two arrays were the same or different. The sample and test arrays were identical except that a single square was replaced with a square of a different color on 50 % of the trials.
Each participant was given standard task instructions (based on Luck & Vogel, 1997), except that the final sentence was varied across groups. A control group was told: “Do your best and try to get as many trials correct as possible” (N = 51). A remember-all group was told: “Try to remember the entire display, no matter how many items are present” (N = 56). A remember-subset group was told: “If you can’t remember the entire array, focus on a subset and try to remember them well”.
Data analysis
VWM performance was quantified for each combination of instruction type and set size using Pashler’s K formula (Pashler, 1988), which is the appropriate formula for this variant of the change detection paradigm (Rouder, Morey, Morey, & Cowan, 2011). We use k̂ to refer to the estimated number of items’ worth of information stored by a given participant at a given set size, whereas k̂ max can be measured only for set sizes at or above an individual’s capacity. k̂ values were analyzed using a 3 × 3 analysis of variance (ANOVA) with instruction type as a between-subjects factor and set size as a within-subjects factor.
There is considerable controversy about whether VWM is best conceived as a set of fixed-resolution, slot-like representations or a flexible pool of resources (see review by Luck & Vogel, 2013). Most previous research on individual differences in VWM capacity have quantified performance with the k̂ measure of capacity (or some variant on it), which assumes slot-like representations, and we have therefore used this same measure. However, the fundamental conclusions of the present study do not depend on this conceptualization of VWM. Moreover, we also provide the hit rates and false alarm rates so that interested readers can compute alternative measures of capacity.
Results
Figure 2 illustrates the effect of instruction type on k̂ as a function of set size; the raw hit rates and false alarm rates are provided in Table 1. The remember-all group had substantially higher mean k̂ values than the control group at set sizes six and eight, whereas the performance of the remember-subset group was nearly identical to that of the control group. These observations were supported by the ANOVA, which yielded a main effect of instruction type, F (2, 160) = 6.590, P = .002, η2 = .076, and a main effect of set-size, F (2, 160) = 49.78, P < .001, η2 = .236. Although the differences among instruction groups were numerically much larger at set sizes six and eight than at set size four, the set-size × instruction-level interaction did not reach significance, F (4, 322) = 1.855, P = .118, η2 = .023.

Estimates of visual working memory capacity (K) as a function of set size and instruction type. Error bars Standard error of the mean
To decompose the main effect of instruction type, we collapsed each participant’s k̂ scores across all set sizes and compared the remember-all and remember-subset groups with the control group with independent-samples t tests. k̂ was significantly greater in the remember-all group than in the control group, t (105) = 3.289, P = .001. d = .63, but there was no significant difference between the remember-subset group and the control group, t (111) = .052, P = .959, d = .02.
Traditional null hypothesis statistical testing does not make it possible to conclude that the remember-subset and control instructions lead to equivalent performance. However, it is possible to convert a t value into a Bayes factor, which indicates the relative likelihood of the null hypothesis versus the alternative hypothesis (Rouder, et al, 2009). When we converted the t values to Bayes factors (using the calculator at http://pcl.missouri.edu/bayesfactor), we found that the null hypothesis of no difference between the remember-subset group and the control group was 6.9 times more likely to account for the data than the alternative hypothesis of a difference. For the comparison of the remember-all group with the control group, in contrast, the Bayes factor indicated that the alternative hypothesis was 13.2 times more likely to account for the data than the null hypothesis. Thus, we can conclude with substantial confidence that instructing participants to “focus on a subset and try to remember them well” does not lead to better performance than an instruction to “do your best.” In contrast, instructions to “remember the entire display, no matter how many items are present” led to enhanced performance.
Discussion
These findings provide clear evidence that instructional manipulations can influence estimated VWM capacity. Along with the substantial evidence that individual differences in filtering ability explain a significant proportion of the across-subject variation in k̂ max (Cowan & Morey, 2006; McNab & Klingberg, 2008), the present study makes it clear that performance in simple VWM tasks can be influenced by factors other than the amount of representational medium (whether conceived as a set of fixed-resolution slots or a flexible pool of resources). Thus, studies of individual differences in estimated VWM capacity must be careful about assuming that they have measured the amount of representational medium (i.e., that k̂ max is actually a good estimate of K max). For example, studies concerning the genetic basis of working memory have concluded that estimates of WM capacity across the lifespan are determined by genetic factors that are also predictive of activity within the parietal cortex (Heck, et al., 2014) and that performance on working memory tasks are almost entirely genetic in origin (Friedman, et al., 2008). The present results, which show that varying one sentence of instruction can significantly impact k̂ max, are not easily reconciled with a view of working memory performance as reflecting an innate, inflexible cognitive capacity. The present results are, however, consistent with the finding that estimates of working memory capacity can be increased by training (Jaeggi, Buschkuehl, Jonides, & Perrig, 2008) and decreased by stress (Arnsten, 1998) and sleep deprivation (Ilkowska & Engle, 2010).
Prior work using similar tasks has shown that k̂ max declines when capacity is exceeded (Cusack et al., 2009; Matsouyoshi, Osaka, & Osaka, 2014), especially in low-k̂ max participants (Fukuda, Woodman, & Vogel, 2015). An explicit assumption in prior work is that a decline in k̂ max at higher set-sizes is due to a maladaptive encoding strategy in which participants try to remember the entire display regardless of set size (Cusack et al., 2009; Linke et al., 2011). We therefore expected that performance would be impaired at higher set sizes if we explicitly instructed participants to follow this strategy and that performance would be enhanced if we encouraged the assumed-to-be optimal strategy of focusing on a subset of the items in supra-capacity arrays. However, we found exactly the opposite, with no benefit in the remember-subset group and enhanced performance in the remember-all group (relative to the “do your best” control group).
Although it is conceivable that some different variant of the remember-subset instructions would lead to enhanced performance, the present results provide no support for the hypothesis that encoding a subset will lead to better performance than attempting to encode the entire array. Moreover, the fact that the remember-all instructions led to superior performance compared to do-your-best instructions provides strong evidence against the hypothesis that attempting to encode the entire array is a maladaptive “default encoding” strategy that typically leads to a decline in k̂ max at higher set-sizes. In fact, the finding of equivalent performance in the remember-subset and control groups suggests that the default strategy is to focus on a subset of the items once capacity limits are reached at higher set sizes.
The present results may appear to conflict with a study by Zhang and Luck (2011), which reported no effect of strategic manipulations on the quality and quantity of representations in VWM were examined. However, this previous study examined whether participants could trade quality for quantity, increasing k̂ max by storing less precise representations. That is very different from asking whether focusing on a larger or smaller subset of the array would impact k̂ max, which was the goal of the present study. Indeed, the Zhang and Luck (2011) results suggest that the benefit observed in the remember-all condition of the present study is unlikely to reflect the storage of a larger number of lower-precision representations. However, it would be useful for future research to directly test this explanation of the present results.
A more likely explanation of the improved performance in the remember-all group is that this instruction may have encouraged participants to form a representation of the statistics of the overall array (Brady, Konkle, & Alvarez, 2011) in parallel with representations of the individual objects. This could have allowed participants to detect changes either by noticing that an individual object had changed color or by noticing that the overall scene statistics had changed. Future research could test this by using a task that cannot be influenced by ensemble representations and assessing whether this eliminates the advantage of the remember-all instructions.
Another possible explanation is that the remember-all condition leads to increased arousal or vigilance and therefore a reduction in mind wandering (see Mrazek et al., 2012). If this were true, we would expect improved performance across all set sizes. However, we saw little or no effect of the remember-all instruction at set size four (see Fig. 2). Moreover, there is no obvious reason why the remember-all instructions would lead to greater arousal or vigilance than do-your-best instructions.
Yet another possibility is that the remember-all instruction leads to a chunking strategy, in which similar colors are stored together. For example, when participants are instructed to remember every item, this may cause them to notice that two items in an array have the same color, and this might help them store the information more efficiently. Note, however, that the sample array was presented for only 100 ms, which minimizes the opportunity for elaborate encoding strategies.
No matter what the explanation turns out the be, the present results demonstrate that attempting to encode the entire array is not a maladaptive strategy, as might be expected by the idea that working memory performance is limited by failures of filtering. Indeed, attempting to encode the entire array may actually be the best strategy, at least under the very standard conditions of the present study.
In summary, the present findings add to the existing literature in four critical ways. First, these results highlight the sensitivity of VWM to subtle variations in instructions, revealing the practical importance of choice of instructional strategies for future working memory research. Second, the strategy of trying to remember the entire display beyond capacity limits at higher set-sizes does not appear to produce decreases in k̂ max. If anything, instructing participants to adopt this strategy increases k̂ max, at least under the conditions used here. Third, the default strategy employed by individuals in a change-detection task may be to focus on a subset of the items when capacity limits are reached, as demonstrated by the equivalent performance in the do-your-best and remember-subset conditions. Finally, these data suggest that estimates of working memory capacity are at least in part determined by task-dependent and flexible strategic factors rather than inflexible and innate limitations.
Notes
These data were collected in the context of a larger study that was designed to look at individual differences, and the sample sizes were therefore larger than is typical for group-level studies of working memory. Given the observed effect sizes, future studies could use smaller sample sizes, especially if a within-participant manipulation was used instead of the between-participant manipulation used here.
References
Arnsten, A. F. (1998). The biology of being frazzled. Science, 280, 1711–1713.
Bengson, J. J., & Mangun, G. R. (2011). Individual working memory capacity is uniquely correlated with feature-based attention when combined with spatial attention. Attention, Perception, & Psychophysics, 73, 86–102.
Bleckley, M. K., Durso, F. T., Crutchfield, J. M., Engle, R. W., & Khanna, M. M. (2003). Individual differences in working memory capacity predict visual attention allocation. Psychonomic Bulletin & Review, 10, 884–889.
Brady, T. F., Konkle, T., & Alvarez, G. A. (2011). A review of visual memory capacity: Beyond individual items and towards structured representations. Journal of Vision, 11(5), 4.
Conway, A. R. A., Cowan, N., & Bunting, M. F. (2001). The cocktail party phenomenon revisited: The importance of working memory capacity. Psychonomic Bulletin & Review, 8, 331–335.
Cowan, N. (2005). Working memory capacity limits in a theoretical context. In C. Izawa & N. Ohta (Eds.), Human learning and memory: Advances in theory and application. The 4th Tsukuba InternationalConference on Memory (pp. 155–175). Mahwah: Erlbaum.
Cowan, N., & Morey, C. C. (2006). Visual working memory depends on attentional filtering. Trends in the Cognitive Sciences, 10, 139–141.
Cusack, R., Lehmann, M., Veldsman, M., & Mitchell, D. J. (2009). Encoding strategy and not visual working memory capacity correlates with intelligence. Psychonomic Bulletin and Review, 16, 641–647.
Franconeri, S. L., Alvarez, G. A., & Cavanagh, P. (2013). Flexible cognitive resources: Competitive content maps for attention and memory. Trends in Cognitive Sciences, 17, 134–141.
Friedman, N. P., Miyake, A., Young, J. C., Defries, R. P., & Hewit, J. K. (2008). Individual differences in executive functions are almost entirely genetic in origin. Journal of Experimental Psychology: General, 137, 201–225.
Fukuda, K., Woodman, G. F., & Vogel, E. (2015). Individual differences in visual working memory capacity: Contributions of attentional control to storage. In P. Jolicoeur, C. Fevebvre, & J. Martinez-Trujillo (Eds.), Mechanisms of Sensory Working Memory. New York: Academic.
Gold, J. M., Fuller, R. L., Robinson, B., McMahon, R. P., Braun, E. L., & Luck, S. J. (2006). Intact attentional control of working memory encoding in schizophrenia. Journal of Abnormal Psychology, 115, 658–673.
Heck, A., Fastenrath, M., Ackermann, S., Auschra, B., Bickel, H., Coynel, D., …, Papassotiropoulos, A. (2014). Converging genetic and functional brain imaging evidence links neuronal excitability to working memory, psychiatric disease, and brain activity, Neuron, 5, 1203–1213.
Ilkowska, M., & Engle, R. W. (2010). Trait and state differences in working memory capacity. In A. Gruszka, G. Matthews, & B. Szymura (Eds.), Handbook of individual differences in cognition: Attention, memory, and executive control (pp. 295–320). New York: Springer.
Jaeggi, S. M., Buschkuehl, M., Jonides, J., & Perrig, W. J. (2008). Improving fluid intelligence with training on working memory. Proceedings of the National Academy of Sciences of the United States of America, 105, 6829–6833.
Kane, M. J., Bleckley, M. K., Conway, A. R., & Engle, R. W. (2001). A controlled-attention view of working-memory capacity. Journal of Experimental Psychology: General, 130, 169–183.
Linke, A. C., Vicente-Grabovetsky, A., Mitchell, D. J., & Cusack, R. (2011). Encoding strategy accounts for individual differences in change detection measures of VSTM. Neuropsychologia, 49, 1476–1486.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281.
Luck, S. J., & Vogel, E. K. (2013). Visual working memory capacity: From psychophysics and neurobiology to individual differences. Trends in Cognitive Sciences, 17, 391–400.
McNab, F., & Klingberg, T. (2008). Profrontal cortex and basal ganglia control access to working memory. Nature Neuroscience, 11, 103–107.
Morey, C. C., & Cowan, N. (2005). When do visual and verbal memories conflict? The importance of working memory load and retrieval. Journal of Experimental Psychology: Learning, Memory and Cognition, 31, 703–713.
Mrazek, M. D., Smallwood, J., Franklin, M. S., Chin, J. M., Baird, B., & Schooler, J. W. (2012). The role of mind-wandering in measurements of general aptitude. Journal of Experimental Psychology: General, 141, 788–798. doi:10.1037/a0027968
Matsouyoshi, D., Osaka, M., & Osaka, N. (2014). Age and individual differences in visual working memory deficit induced overload. Frontiers in Psychology, 5, 384. doi:10.3389/fpsyg.2014.00384
McVay, J. C., & Kane, M. J. (2009). Conducting the train of thought: Working memory capacity, goal neglect, and mind wandering in an executive control task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 196–204.
Pashler, H. (1988). Familiarity and visual change detection. Perception & Psychophysics, 44, 369–378.
Rouder, J. N., Morey, R. D., Morey, C. C., & Cowan, N. (2011). How to measure working memory capacity in the change detection paradigm. Psychonomic Bulletin & Review, 18, 324–330.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16, 225–237.
Saults, J. S., & Cowan, N. (2007). A central capacity limit to the simultaneous storage of visual and auditory arrays in working memory. Journal of Experimental Psychology: General, 136, 663–684.
Vogel, E. K., & Machizawa, M. G. (2004). Neural activity predicts individual differences in visual working memory capacity. Nature, 428(6984), 748–751.
Vogel, E. K., McCollough, A. W., & Machizawa, M. G. (2005). Neural measures reveal individual differences in controlling access to working memory. Nature, 438, 500–503.
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453, 233–235.
Zhang, W., & Luck, S. J. (2011). The Number and Quality of Representations in Working Memory. Psychological Science, 22, 1434–1441.
Author Notes
This study was made possible by NIH grant R01MH076226 to S.J.L. We thank Chris Donkin and an anonymous reviewer for several excellent suggestions regarding the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bengson, J.J., Luck, S.J. Effects of strategy on visual working memory capacity. Psychon Bull Rev 23, 265–270 (2016). https://doi.org/10.3758/s13423-015-0891-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0891-7