
Abstract
In this study, the role of expectancies in cognitive control was tested. On the basis of the original interpretation of the congruency sequence effect (Gratton, Coles, & Donchin, Journal of Experimental Psychology: General 121:480–506, 1992), we sought evidence for a repetition bias steering attentional control. In a series of four Stroop experiments, we investigated how participants’ explicit predictions about the upcoming (in)congruency proactively influenced subsequent Stroop performance. Similar to the fallacious “hot-hand” belief in gambling, repeating stimulus events were overpredicted, as participants consistently expected more repetitions of the congruency level than the actual presented number of congruency-level repetitions (50 %). Moreover, behavioral adjustments (i.e., a congruency sequence effect) were only found when participants anticipated a congruency-level repetition, whereas no modulation of the Stroop effect was found following alternation predictions. We propose that proactive control processes in general, and repetition expectancy in particular, should be given more attention in current theorizing and modeling of cognitive control, which is characterized by an emphasis on reactive, conflict-induced control adjustments.
Similar content being viewed by others

Cognitive control allows us to adaptively adjust to an ever-changing environment. Therefore, the cognitive system not only monitors the environment, it also generates predictions. Research has predominantly focused on the monitoring aspect, by studying reactive, postconflict adjustments. Recent influential models (e.g., Alexander & Brown, 2011) have stressed the importance of learning on the basis of prediction-driven outcomes. Still, experimental work on how expectancies can steer attentional control is relatively scarce.
Human predictions themselves have been widely investigated. Kahneman, Slovic, and Tversky (1982), for instance, convincingly showed that predictions are inherently biased. When predicting random events, people often expect too many alternations (Nickerson, 2002). Faced with a run of “heads” in coin tossing, for example, the gambler will believe that the run will be broken (the gambler’s fallacy). On the other hand, one expects a winning poker player to keep on winning (the hot-hand fallacy). According to Kareev (1995), human predictive behavior reveals a tendency toward expecting repeating events, in line with the hot-hand fallacy.
These biased predictions can influence reaction times (RTs) in relatively simple tasks. In serial two-choice RT tasks, for example, responses to stimulus repetitions are typically faster than responses to stimulus alternations (e.g., Remington, 1969). Soetens, Boer, and Hueting (1985) explained this repetition effect in terms of subjective expectancy. However, once the intertrial interval was sufficiently stretched, Soetens et al. demonstrated an alternation effect, corresponding to faster responses to different than to repeated stimuli. These authors assumed that, in accordance with the gambler’s fallacy, participants expect too many alternations in a random run of binary stimuli.
According to Gratton et al. (1992), biased expectancies also drive the congruency sequence, or Gratton, effect. Applying a flanker task, in which participants have to react to a central target flanked by either congruent (< < <) or incongruent (> < >) flankers, they found a reduced congruency effect after incongruent trials. The authors theorized that these sequential modulations reflect strategic adjustments in cognitive control. Gratton et al. presumed a congruency repetition bias: Despite objectively equal chances of encountering a congruent (C) or an incongruent (I) trial, participants tend to expect easy (congruent) trials after easy trials, and difficult (incongruent) trials after difficult trials. Participants strategically narrow attention to the central target when anticipating an incongruent stimulus, thereby minimizing the impact of the misleading flankers. In anticipation of a congruent trial, participants broaden their attentional focus, so that the congruent flanking information is allowed to contribute more to response selection. This proactive, expectancy-based regulation of attentional strategies leads to faster responses on trial transitions involving a congruency-level repetition (i.e., on CC and II trial transitions). When expectancies are violated (i.e., on CI and IC trial transitions), these preparatory adjustments backfire and impair performance, in terms of slower responses or higher error rates.
A recent test did not support the existence and influence of such a congruency-level repetition bias. Jiménez and Méndez (2013) interleaved blocks of standard Stroop trials with blocks in which participants were asked to indicate which trial (congruent or incongruent) would come next. The results revealed that participants fell into the gambler’s fallacy after only one sequence of repeated congruency. Moreover, analysis of the separate Stroop blocks suggested a dissociation between expectancies and performance: Following sequences of repeated congruency, performance benefited from a congruency-level repetition, despite an expectancy for congruency-level alternations.
Since evidence supporting the proactive repetition expectancy account is rather scarce, the congruency sequence effect (CSE) is predominantly conceptualized in terms of reactive, conflict-induced adjustments (Botvinick, Braver, Barch, Carter, & Cohen, 2001). According to a reactive account, the detection of response conflict on incongruent trials leads to a temporary up-regulation in the control settings, enhancing the processing of task-relevant stimulus information, irrespective of participants’ expectancies for the upcoming trial.
In the present article, we aimed to investigate the impact of expectancies on attentional control more directly, by presenting participants with a vocal Stroop task and asking them explicitly to predict the congruency level of the upcoming Stroop trial. Contrary to Jiménez and Méndez (2013), we measured predictions and performance on the same trials.
We predicted a repetition bias, in the sense that participants would expect the congruency level of the last-encountered trial to repeat on the next trial. We also investigated the influence of these predictions on task performance, by calculating the CSE separately for repetition expectancies and alternation expectancies. Importantly, while a proactive account predicts a repetition bias and an influence of these predictions on subsequent task performance, a reactive account does not.
Experiments 1A and 1B
In Experiment 1A, we ran an eight-color Stroop task in which participants were asked to try to predict the congruency level before the actual presentation of the color word. We verified whether participants were biased to expect a repeated congruency level in successive trials and probed how the CSE is influenced by this repetition expectancy. In order to assess a pure measure of the CSE, we constrained random selection of the color word and color so that no stimulus feature was repeated relative to trials n – 1 and n – 2 (see also, e.g., Duthoo & Notebaert, 2012). In the otherwise identical Experiment 1B, we used only four colors and allowed complete and partial stimulus feature repetitions. Apart from verifying the replicability of our results, we also tested how these stimulus feature repetitions influenced predictions.
Method
Participants
A group of 15 Ghent University students (11 female, four male; ages 18–24 years) provided written informed consent to participate in Experiment 1A. Another fifteen (12 female, three male; ages 18–25 years) were recruited for Experiment 1B.
Stimuli and apparatus
Stimuli were displayed on a 17-in. monitor, with a viewing distance of approximately 50 cm. In Experiment 1A, the stimuli consisted of eight (Dutch) color words presented in one of the eight possible colors (red, green, blue, yellow, pink, brown, purple, or gray). For Experiment 1B, the selection of colors and color words was restricted to red, green, blue, and yellow. All text was presented in Courier font, size 20. Participants had to react by saying out loud the font color, and responses were detected by means of a Sennheiser MD 421-U-4 microphone.
Design and procedure
Equal numbers of congruent and incongruent trials were presented. In Experiment 1A, we constrained random selection of the color and color word by precluding complete stimulus repetitions or relevant or irrelevant feature repetitions, relative to both trials n – 1 and n – 2. In other words, all stimulus and response features changed across three consecutive trials. For Experiment 1B, random selection of the color and color word was unconstrained, allowing complete and partial stimulus feature repetitions.
Participants were presented with a practice block of 90 regular Stroop trials. The participants then completed a second practice block containing 15 trials, during which they not only had to predict the congruency of the upcoming trial by clicking the left or the right mouse button (counterbalanced across participants), but also to report afterward whether or not their prediction was confirmed, again by mouse click. The data revealed that the participants understood the basic idea of the experiment, since all participants judged their predictions accurately above chance level. Finally, four experimental blocks of 90 trials were presented, during which participants had to make predictions about the difficulty of the upcoming stimulus and subsequently to respond accurately to it.
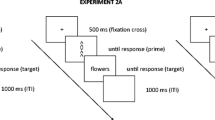
Each experimental trial started with the presentation of a fixation dot for 500 ms, followed by an instruction (“Next trial?”) that remained visible until participants clicked one of the mouse buttons. Then, the screen turned black for 1,000 ms, after which the Stroop trial appeared on screen until a response was registered by the microphone (max 2,000 ms). The moment that the voice key was triggered, the stimulus word shortly tilted 20º to the right for 300 ms before the screen turned black, and the experimenter coded the actual response given by the participant. When the voice key was triggered too early (caused by a noise other than the participant’s voice) or too late (because of the participant hesitating, hissing, or raising his or her voice during the response), the experimenter coded the trial as a false alarm. After coding, another 500 ms passed before the next trial began. No error feedback was provided.
Results
Data cleaning
We excluded one participant from Experiment 1A for not engaging in the prediction task (by “predicting” all trials to be incongruent). Then we removed the first trial of each block and all trials containing misses and false alarms caused by voice key malfunctioning (Exp. 1A, 11.7 %; Exp. 1B, 8.2 %). Next, error trials (Exp. 1A, 2.6 %; Exp. 1B, 2 %) and trials with extreme RTs (<300 or >1,500 ms; Exp. 1A, 0.71 %; Exp. 1B, 1.3 %) were removed. Finally, responses following an error trial or nonresponse (Exp. 1A, 10.7 %; Exp. 1B, 7.7 %) were also excluded.
Prediction performance
On average, participants’ predictions matched the congruency level of the previous trial on 65 % of their choices in Experiment 1A, and on 62 % of their choices in Experiment 1B. A paired-samples t test revealed that these percentages were significantly larger than the actual numbers of presented congruency-level repetitions in both Experiment 1A [50 % on average; t(13) = 6.41, p < .001] and Experiment 1B [49 %; t(14) = 4.66, p < .001]. For Experiment 1B, this congruency-level repetition bias was not different following exact repetitions (59 %), relevant-feature repetitions (60 %), or irrelevant-feature repetitions (62 %), all ps > .2. Contrary to the findings of Jiménez and Méndez (2013), we observed an even stronger repetition bias when the previous sequence (n – 2 to n – 1) had entailed a congruency-level repetition than when the previous sequence had entailed a congruency-level alternation. This difference was significant for Experiment 1A (69 % vs. 62 %, t(13) = 2.31, p < .05), yet only marginally significant for Experiment 1B (65 % vs. 60 %, t(14) = 1.88, p = .082).
Reaction times
We ran a repeated measures analysis of variance (ANOVA) with the within-subject factors Repetition Expectancy (two levels: repetition and alternation), Previous Congruency (two levels: congruent and incongruent), and Current Congruency (two levels: congruent and incongruent). As is depicted in Fig. 1, a significant three-way interaction was found in both Experiments 1A, F(1, 13) = 20.02, p < .001, and 1B, F(1, 14) = 13.92, p < .01. When participants expected a repetition of congruency level, a significant interaction between previous and current congruency (i.e., a CSE) was found [Exp. 1A, F(1, 13) = 45.05, p < .001; Exp. 1B, F(1, 14) = 41.26, p < .0001] that was completely absent when an alternation of congruency level was expected [Exp. 1A, F(1, 13) < 1; Exp. 1B, F(1, 14) < 1].

Mean reaction times (RTs, in milliseconds) and error percentages for incongruent (dashed lines) and congruent (solid lines) trials of Experiments 1A and 1B as a function of the congruency level of the previous trial, separately for repetition and alternation predictions. Error bars represent 95 % confidence intervals around the means
Error percentages
For Experiment 1A, only the main effect of current congruency turned out to be significant, F(1, 13) = 20.12, p < .001. Neither the three-way interaction nor the interaction between previous and current congruency reached significance, F(1, 13) < 1. For Experiment 1B, the main effect of current congruency, F(1, 14) = 10.47, p < .01, as well as the interaction between current and previous congruency, F(1, 14) = 12.73, p < .01, turned out significant. Contrary to our predictions, the three-way interaction between repetition expectancy and previous and current congruency was not significant, F(1, 14) = 2.35, p = .148, indicating similar CSEs after repetition and alternation predictions (see Fig. 1). However, we would stress that these results have to be interpreted with caution, since overall error rates were low and response errors could not be dissociated from technical errors. Still, the results at least suggest that the RT effects were not due to a speed–accuracy trade-off. Experiments 2A and 2B, in which manual responses were registered, were better suited for investigating error rates.
Discussion
Experiments 1A and 1B provided evidence for an influence of predictions on cognitive control, unaffected by stimulus and/or response sequences. Both experiments, however, artificially increased the congruency rate to 50 %, so that congruent trials occurred more often than they would have if features had been selected randomly (i.e., 12.5 % in Exp. 1A and 25 % in Exp. 1B). As Mordkoff (2012) argued, increasing the proportion of congruent trials makes the irrelevant task dimension (i.e., the color word in the Stroop task) informative (see also Dishon-Berkovits & Algom, 2000). As a consequence, participants might have been encouraged to pay more attention to the distractor word. In order to verify whether the results of the previous two experiments would replicate when the irrelevant word dimension did not predict the target color, we ran a similar two-choice version of the Stroop task, in which every word–color combination was presented equally often (Exp. 2A). Moreover, we now ran a manual version of the Stroop task that enabled a proper error analysis in the absence of the technical confounds (i.e., voice-key errors) associated with our voice-key procedure.
In order to further investigate the discrepancy between our findings of a bias toward repetitions of the same congruency level over successive trials and the recent results of Jiménez and Méndez (2013), showing a bias toward alternations after one repetition, we also ran a second version of the experiment (Exp. 2B) that more closely resembled the procedure applied by Jiménez and Méndez.
Experiments 2A and 2B
We tested whether the findings reported above would replicate in a two-choice manual version of the Stroop task (Exp. 2A). We also ran an otherwise identical Experiment 2B in which the expectation measure applied by Jiménez and Méndez (2013) was copied. Instead of the categorical decision about the congruency level of the upcoming trial, we asked participants to indicate whether they were sure, fairly sure, or guessing that the next trial would be congruent or incongruent. Apart from these differences, the methods and procedures of Experiments 2A and 2B were identical to those of the previous experiments.
Method
Participants
A group of 15 Ghent University students (13 female, two male; ages 18–23 years) provided written informed consent to participate in Experiment 2A. Another fifteen (13 female, two male; ages 18–23 years) were recruited for Experiment 2B.
Stimuli and apparatus
The Stroop stimuli were restricted to the words ROOD (Dutch for “red”) and GROEN (Dutch for “green”), presented in either red or green. Participants had to react to the font color by pressing the “S” or the “D” key on a QWERTY keyboard for red or green, respectively.
Design and procedure
Following the practice block of 90 trials, participants in Experiment 2A were asked to predict whether the upcoming trial would be easy (congruent) or difficult (incongruent) by pressing the “4”or the “6” key on the numeric keypad. The mapping of congruencies to the number keys was counterbalanced across participants. The participants in Experiment 2B were asked to indicate their congruency-level prediction by pressing the appropriate key on the numeric keypad corresponding to one of the six points of a Likert scale, ranging from sure easy (“1” key), over fairly sure easy (“2”), guess easy (“3”), guess difficult (“4”), and fairly sure difficult (“5”), to sure difficult (“6”). In order to make sure that both this extra task and its response mapping were clear, participants in both experiments first completed a practice block containing ten trials, during which they not only had to predict the upcoming trial, but also to report afterward whether or not their prediction was confirmed, by clicking the “7” (yes) or “9” (no) key. On the basis of the accuracy of these judgments, one participant whose performance did not exceed chance level was excluded from the analysis in both experiments. Hereafter, four blocks of 80 trials were presented, during which participants had to make predictions about the difficulty of the upcoming stimulus and respond to it accurately.
Results
Data cleaning
For both experiments, we excluded one participant who did not engage in the prediction task (by “predicting” all trials to be incongruent in three [Exp. 2A] or four [Exp. 2B] of the four experimental blocks), and another participant who did not grasp the basic idea of the experiment, as evidenced by bad performance in the practice block reported above. Then we removed the first trial of each block, as well as all trials on which participants failed to respond within the response deadline (Exp. 2A, 3.1 %; Exp. 2B, 4 %), error trials (Exp. 2A, 4.4 %; Exp. 2B, 8.7 %), trials with extreme RTs (<200 or >1,200 ms; another 2.9 % [Exp. 2A] and 5.5 % [Exp. 2B]), and trials following an error trial or null response (Exp. 2A, 5 %; Exp. 2B, 8.1 %).
Prediction performance
On average, participants’ predictions matched the congruency level of the previous trial on 56 % of their choices in Experiment 2A. A paired-samples t test revealed that this percentage exceeded the actual number of congruency-level repetitions presented to the participants [i.e., 50 %; t(12) = 2.98, p < .05]. In order to compare the prediction pattern of Experiment 2B with that of the previous experiments, we first ran a similar analysis by recoding the Likert scale scores back into categorical congruent or incongruent predictions. On average, the participants’ predictions matched the congruency level of the previous trial on 58 % of their choices, significantly exceeding the actual number of congruency-level repetitions presented to the participants [i.e., 50 %; t(12) = 2.78, p < .05].
We ran a second analysis on these expectancy scores collected in Experiment 2B, after recoding guess, fairly sure, and sure congruent responses into scores of 1, 2, and 3, respectively, and guess, fairly sure, and sure incongruent into −1, –2, and −3, respectively (e.g., similar to the procedure of Jiménez & Méndez, 2013). The factor Context coded the number of congruent or incongruent predecessors to a trial, ranging from one to three congruent (C) or incongruent (I) trials. A repeated measures ANOVA with the factor Context (six levels: 3C, 2C, 1C, 1I, 2I, 3I) was performed on the choice data. The results revealed a significant effect of the preceding context, F(5, 60) = 5.46, Greenhouse–Geisser corrected p < .05. As is depicted in Fig. 2, participants’ expectations tended more strongly toward a congruent trial following one, two, or three congruent trials than following one, two, or three incongruent trials, and vice versa (all ps < .05). Moreover, the expectancy ratings did not differ between one, two, or three consecutive congruent or incongruent trials (all ps > .13).

Mean averaged expectancy scores of Experiment 2B as a function of the preceding context, ordered from three congruent to three incongruent preceding trials. Positive values denote increased expectancy for an upcoming congruent trial, whereas negative values denote increased expectancy for an upcoming incongruent trial. These values are summarized in the table below the figure. Error bars represent 95 % confidence intervals around the means
Reaction times
A significant three-way interaction between repetition expectancy, previous congruency, and current congruency was found in both Experiments 2A, F(1, 12) = 15.46, p < .01, and 2B, F(1, 12) = 6.33, p < .05, after collapsing expectancy scores into categorical predictions (see Fig. 3). When participants expected a repetition of the congruency level, a significant interaction between previous and current congruency (i.e., a CSE) was found [Exp. 2A, F(1, 12) = 17.84, p < .001; Exp. 2B, F(1, 12) = 21.88, p < .001] that was completely absent when an alternation of congruency levels was expected [Fs(1, 12) < 1 in both experiments].

Mean reaction times (RTs, in milliseconds) and error percentages for incongruent (dashed lines) and congruent (solid lines) trials of Experiments 2A and 2B as a function of the congruency level of the previous trial, separately for repetition and alternation predictions. Error bars represent 95 % confidence intervals around the means
Error percentages
As in the RT analysis, a three-way interaction emerged that was significant in Experiment 2A, F(1, 12) = 7.93, p < .05, yet only marginally significant in Experiment 2B, F(1, 12) = 4.01, p = .068 (see Fig. 3). In anticipation of a congruency-level repetition, a significant CSE was found [Exp. 2A, F(1, 12) = 6.17, p < .05; Exp. 2B, F(1, 12) = 7.14, p < .05] that was completely absent when an alternation of congruency level was expected [Fs(1, 12) < 1 in both experiments].
General discussion
In a series of four experiments, we asked participants to predict the congruency level of the upcoming Stroop trial. The results revealed that participants expected the congruency level to repeat in the majority of the trials, and that participants’ predictions influenced their subsequent task performance: Only when they predicted a congruency-level repetition was a congruency sequence effect (CSE) observed. These results were found in two-, four-, and eight-color Stroop tasks.
Expectancy bias
The observed congruency repetition bias confirms the assumption that Gratton et al. (1992) took for granted. In line with the hot-hand fallacy, participants expected a positive autocorrelation when none was actually present. This finding stands in contrast to studies that have shown an alternation bias in the perception, prediction, and generation of randomness (Nickerson, 2002). In the present task, participants were asked to predict the upcoming event as accurately as possible, and thus were implicitly encouraged to look for a systematic relationship between successive trial events. Thus, even though the trials were generated in a random fashion, participants still believed that the sequence was essentially nonrandom. Therefore, finding a repetition bias in the present experiments does not come as a surprise, as we have assumed (in line with Kareev, 1995) that repetition expectancy is an inherent preference aiding the search for meaningful (i.e., causal) relations in everyday life, one that is overcompensated for by an alternation bias when people are asked to evaluate or produce series of random events.
Expectancy in cognitive control
More important to our understanding of cognitive-control processes, our study revealed that repetition expectancies had a crucial impact on subsequent performance. Our results revealed sequential adjustments in the size of the Stroop effect only when participants predicted a repetition of congruent or incongruent trials. According to the repetition expectancy account (Gratton et al., 1992), participants strategically focus or widen attention on the basis of their implicit expectations of the congruency level to repeat. The results of our study both support and qualify this account, by showing that a CSE was present when participants explicitly expected a congruency repetition, and that no performance adjustments occurred when participants expected a change in congruency.
Traditional reactive models, such as the conflict-monitoring model (Botvinick et al., 2001), do not predict an influence of repetition expectancy on the size of the CSE: Following conflict trials, and irrespective of participants’ expectancy of the upcoming trial, task focus is up-regulated to overcome potential conflict on the subsequent trial. Therefore, a purely reactive account would predict CSEs of similar size following repetition and alternation predictions. In line with the dual-mechanisms-of-control framework (Braver, 2012), our results suggest that proactive, expectancy-based control processes can complement or dominate more automatic, reactive control mechanisms in response to situational demands. In the present experiments, explicitly probing for participants’ expectancies might have triggered these proactive control strategies.
The present results might reflect the net effect of simultaneously operating control processes, one preparatory and proactive and the other conflict-induced and reactive. According to this view, preparatory control entails focusing more strongly on the color in expectation of an incongruent trial, or allowing the word-reading process to contribute more strongly to response selection in anticipation of a congruent trial. In contrast, reactive conflict regulation entails increasing controlled color processing following incongruent trials, and decreasing this controlled color processing after congruent trials (Botvinick et al., 2001). When combined, proactive and reactive control processes will complement each other following repetition predictions, producing a strong CSE. Following alternation predictions, however, both control adjustments will work in opposite directions, thereby canceling each other out, reflected in the absence of sequential performance adjustments.
In contrast to our findings of an increased congruency-level repetition bias following two consecutive trials of the same type, in a recent study Jiménez and Méndez (2013) reported evidence suggesting that participants already tended to fall into a gambler’s fallacy after only one sequence of repeated congruency. In an attempt to clarify this discrepancy, we set up an experiment that bridged the methodological gap between the two studies, by implementing a six-point Likert scale measure of congruency predictions similar to that of Jiménez and Méndez. Just as in their study, this procedure produced scores that did not diverge much from the 0 score, reflecting pure guessing. The pattern of expectancy scores (see Fig. 2), however, was qualitatively different: Participants tended to expect a repeated congruency level following one, two, or three congruent or incongruent trials. Moreover, whereas Jiménez and Méndez only found a significant CSE when taking into account the previous two or more trials (i.e., a progressive CSE), showing RT benefits in the opposite direction from expectancies, we found a robust CSE following repetition predictions when taking into account only one preceding trial. In other words, expectancies, and not previous context, seemed to have driven the behavioral adaptation. We suspect that in the study of Jiménez and Méndez, the response–stimulus interval of 0 ms in the blocks in which no predictions were measured left no room for participants to prepare for what they expected. At a theoretical level, these differences can be interpreted in terms of the dual mechanisms of control theory (Braver, 2012): Whereas the methodology of Jiménez and Méndez’s study mainly probed fast and automatic reactive control processes, our prediction experiments might have triggered (additional) strategic, expectancy-based proactive control processes.
This also brings us to a possible limitation of our study. By inserting congruency-level predictions as a second task into the normal Stroop procedure, we might have introduced a procedural change that hampered a comparison with typical Stroop performance. Admittedly, it is not clear to what extent we can generalize our findings to “normal” Stroop or congruency tasks. Further research will be needed to verify whether participants actively generate predictions when they are not explicitly asked to. Irrespective of this, our findings demonstrate an impact of expectancies on sequential modulations of congruency effects, and this finding makes a strong case for the cognitive malleability of the processes underlying transient conflict adaptation. Consequently, we propose that proactive control processes in general, and repetition expectancy in particular, should be given more attention in current theorizing and modeling of cognitive control, which is characterized by an emphasis on reactive, conflict-induced control adjustments.
References
Alexander, W. H., & Brown, J. W. (2011). Medial prefrontal cortex as an action-outcome predictor. Nature Neuroscience, 14, 1338–1344. doi:10.1038/nn.2921
Botvinick, M. M., Braver, T. S., Barch, D. M., Carter, C. S., & Cohen, J. D. (2001). Conflict monitoring and cognitive control. Psychological Review, 108, 624–652. doi:10.1037/0033-295X.108.3.624
Braver, T. S. (2012). The variable nature of cognitive control: A dual mechanisms framework. Trends in Cognitive Sciences, 16, 106–113. doi:10.1016/j.tics.2011.12.010
Dishon-Berkovits, M., & Algom, D. (2000). The Stroop effect: It is not the robust phenomenon that you have thought it to be. Memory & Cognition, 28, 1437–1449. doi:10.3758/BF03211844
Duthoo, W., & Notebaert, W. (2012). Conflict adaptation: It is not what you expect. Quarterly Journal of Experimental Psychology, 65, 1993–2007. doi:10.1080/17470218.2012.676655
Gratton, G., Coles, M. G. H., & Donchin, E. (1992). Optimizing the use of information: Strategic control of activation of responses. Journal of Experimental Psychology. General, 121, 480–506. doi:10.1037/0096-3445.121.4.480
Jiménez, L., & Méndez, A. (2013). It is not what you expect: Dissociating conflict adaptation from expectancies in a Stroop task. Journal of Experimental Psychology: Human Perception and Performance, 39, 271–284. doi:10.1037/a0027734
Kahneman, D., Slovic, P., & Tversky, A. (1982). Judgement under uncertainty: Heuristics and biases. Cambridge: Cambridge University Press.
Kareev, Y. (1995). Positive bias in the perception of covariation. Psychological Review, 102, 490–502. doi:10.1037/0033-295X.102.3.490
Mordkoff, J. T. (2012). Three reasons to avoid having half of the trials be congruent in a four-alternative forced-choice experiment on sequential modulation. Psychonomic Bulletin & Review, 19, 750–757. doi:10.3758/s13423-012-0257-3
Nickerson, R. S. (2002). The production and perception of randomness. Psychological Review, 109, 330–357. doi:10.1037/0033-295X.109.2.330
Remington, R. J. (1969). Analysis of sequential effects in choice reaction times. Journal of Experimental Psychology, 82, 250–257. doi:10.1037/h0028122
Soetens, E., Boer, L. C., & Hueting, J. E. (1985). Expectancy or automatic facilitation? Separating sequential effects in two-choice reaction time. Journal of Experimental Psychology. Human Perception and Performance, 11, 598–616. doi:10.1037/0096-1523.11.5.598
Author note
The research reported in this article was supported by Grant No. 3 F009109 from the Research Foundation Flanders (FWO). We thank Nico Boehler for his helpful comments and suggestions on an earlier version of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Duthoo, W., Wühr, P. & Notebaert, W. The hot-hand fallacy in cognitive control: Repetition expectancy modulates the congruency sequence effect. Psychon Bull Rev 20, 798–805 (2013). https://doi.org/10.3758/s13423-013-0390-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-013-0390-7