
Abstract
According to the probability-matching account of source guessing (Spaniol & Bayen, Journal of Experimental Psychology: Learning, Memory, and Cognition 28:631–651, 2002), when people do not remember the source of an item in a source-monitoring task, they match the source-guessing probabilities to the perceived contingencies between sources and item types. In a source-monitoring experiment, half of the items presented by each of two sources were consistent with schematic expectations about this source, whereas the other half of the items were consistent with schematic expectations about the other source. Participants’ source schemas were activated either at the time of encoding or just before the source-monitoring test. After test, the participants judged the contingency of the item type and source. Individual parameter estimates of source guessing were obtained via beta-multinomial processing tree modeling (beta-MPT; Smith & Batchelder, Journal of Mathematical Psychology 54:167–183, 2010). We found a significant correlation between the perceived contingency and source guessing, as well as a correlation between the deviation of the guessing bias from the true contingency and source memory when participants did not receive the schema information until retrieval. These findings support the probability-matching account.
Similar content being viewed by others
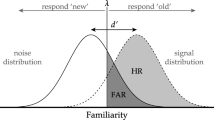

Source monitoring involves judgments regarding the origin of information (Johnson, Hashtroudi, & Lindsay, 1993). In typical source-monitoring tasks, participants are presented with items from two or more sources and are later required to judge whether the items were presented by one of the sources, and if so, which one.
How we interpret and use information is influenced by the source that we believe gave the information. For example, you trust doctors more than your hairdressers for advice on medicine but not on haircuts. According to Johnson’s source-monitoring framework (Johnson et al., 1993), two types of information are used to attribute memories to sources, namely (1) episodic memory for features of the source and (2) general knowledge, plausibility, and beliefs. Either you may remember being in a hair salon when you heard the advice, or you may rely on your general knowledge. Specifically, you know that the probability of talking to your hairdresser about your hair style is much greater than the probability of talking to your doctor about this. Thus, there are certain expected contingencies of types of information and their sources.
Contingency knowledge may stem from actual experiences with the sources (e.g., Bridget has always been helpful) or from general schematic knowledge about them (e.g., Bridget is a girl scout, and one thus infers that she must be helpful). According to the probability-matching account of source guessing (Spaniol & Bayen, 2002), participants match learned contingencies about particular sources whenever possible, relying on more general schematic expectations only if the participants do not have a contingency representation.
Probability matching has been observed in source monitoring (e.g., Bayen & Kuhlmann, 2011; Erdfelder & Bredenkamp, 1998) and in other tasks, such as old–new recognition (e.g., Buchner, Erdfelder, & Vaterrodt-Plünnecke, 1995; Ehrenberg & Klauer, 2005) and human choice behavior (e.g., Estes & Straughan, 1954). Furthermore, studies have shown that prior knowledge influences source guessing (Bayen, Nakamura, Dupuis, & Yang, 2000; Ehrenberg & Klauer, 2005; Spaniol & Bayen, 2002). Thus, there is support for the idea that source guessing can be based on learned contingencies about specific sources or on more general prior knowledge about sources, as suggested by the probability-matching account.
Hicks and Cockmann (2003) found that the time when the schema-relevant information was given to participants affected the source-guessing bias. Participants who received the information after encoding showed schema-consistent bias in their source attributions, whereas participants who had already received the information before encoding showed no such bias. However, Bayen and Kuhlmann (2011) found that source guessing in this schema-before-encoding condition was only unbiased in a full-attention condition (in contrast to a divided-attention condition) at encoding. With divided attention at encoding, schema bias occurred. This suggests that when participants can process the true contingency between sources and items, they will rely on this information rather than on prior schematic knowledge, and this supports the probability-matching account. In line with this idea, the same authors manipulated the actual contingencies between item types and sources and found that guessing matched the experimental contingencies (under full attention at encoding and when participants knew about the schema-relevant information at the time of encoding).
Importantly, the probability-matching account predicts a positive correlation between contingency perception and source-guessing bias, such that people differing in contingency perception within the same experimental setting should also differ in source-guessing bias. In other words, individual differences in contingency perception should be related to variations in source-guessing bias. For example, Spaniol and Bayen (2002) found that in the same source-monitoring task, some participants relied on schematic knowledge in source guessing, while others did not. To reconcile these differential source-guessing patterns, the authors suggested that these participants differed in their perceived contingencies. However, to date, the relationship between individual contingency perception and source-guessing bias has not been investigated.
The purpose of the present study was to demonstrate that individual differences in contingency perception relate to individual differences in source-guessing bias. We used a new methodological approach, beta-MPT modeling (Smith & Batchelder, 2010), which allowed us to estimate individual participants’ source-guessing probabilities. Bayen and Kuhlmann (2011; see also Bayen et al., 2000) used a multinomial processing tree (MPT) model, the two-high-threshold model of source monitoring (2HTSM; Bayen, Murnane, & Erdfelder, 1996), to disentangle memory and guessing in the source-monitoring paradigm. First we will describe the 2HTSM, then the basics of the beta-MPT approach. We then report an experiment to test the probability-matching account on an individual-differences level by investigating the relationship between perceived contingencies and guessing in source monitoring, using the beta-MPT approach.
The 2HTSM (Bayen et al., 1996) is a stochastic model that separates memory and guessing in source monitoring. We used Submodel 4 (see Bayen et al., 1996, for details), which assumes that the levels of item memory as well as source memory are equal for both sources, and which had fit the data from previous studies using the same standard source-monitoring paradigm we used in the present study (Bayen & Kuhlmann, 2011; Bayen et al., 2000; Kuhlmann, Vaterrodt, & Bayen, 2012). The model (see Fig. 1) assumes a source-monitoring task with two sources. Statements are presented either by the schematically expected source (e.g., the doctor presenting an expected-doctor statement) or by the schematically unexpected source (e.g., the lawyer presenting an expected-doctor statement). The first and second trees represent the cognitive processes involved in responses for items that originated from the schematically expected and the schematically unexpected sources, respectively. The third tree represents processes for unstudied distractor items (i.e., new items).

Submodel 4 of the two-high-threshold model of source monitoring. D = probability of detecting that an item is old/new; d = probability of correctly remembering the source of an item; g = probability of guessing that an item is from the expected source; b = probability of guessing that an item is old. Adapted from “Source Discrimination, Item Detection, and Multinomial Models of Source Monitoring,” by U. J. Bayen, K. Murnane, and E. Erdfelder, 1996, Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, p. 202. Copyright 1996 by the American Psychological Association
With probability D, participants correctly recognize an item as old or new. With probability d, they remember the source of the item. If they cannot remember the source (with probability 1 – d), they must guess. With probability g, they guess that the item is from the source that is consistent with the schematic expectation; with probability 1 – g, they guess that the item is from the schematically unexpected source. If participants do not remember whether an item is old or new (probability 1 – D), they guess, with probability b, that the item is old or, with probability 1 – b, that it is new. If they have guessed that an item is old, they must guess the source of the item. With probability g, the guess is the schematically expected source, and with probability 1 – g, the schematically unexpected source.
Traditionally, data are aggregated over items and participants for MPT analysis, so that there is one set of parameters for all participants. Thereby, homogeneity is assumed for items and participants; that is, the data from different items and participants are assumed to be independent and identically distributed. However, this assumption is often violated and may lead to biased parameter estimates (Klauer, 2006, 2010; Smith & Batchelder, 2008, 2010). Furthermore, this approach only yields group-level estimates for parameters, not individual estimates.
Recently, hierarchical models have been developed to deal with heterogeneity (Klauer, 2006, 2010; Smith & Batchelder, 2010). We used the beta-MPT approach (Smith & Batchelder, 2010). The advantage of this method is that it uses a hierarchical distribution for each parameter that lies within the interval (0, 1), and thus has the same scale as the MPT model parameters, which indicate probabilities. The method assumes that participants’ parameters are drawn independently from beta distributions for each model parameter. The beta distribution is a very flexible distribution that can also approximate the normal distribution (between 0 and 1).
The main purpose of our experiment was to test the core assumption of the probability-matching account: namely, that people guess according to the perceived contingency if they do not remember the source. Therefore, we should find a positive relationship between participants’ perceived contingencies and the source-guessing parameter g. Bayen and Kuhlmann (2011) only demonstrated this relationship at a group level. However, within the same experimental setting, individual variations in source-guessing bias are possible (cf. Spaniol & Bayen, 2002), requiring an individual-differences approach. With the beta-MPT approach, it is possible to link the guessing parameter directly to participants’ perceived contingencies. Along with the replication of previous results (i.e., that the guessing parameter g was larger in the retrieval than in the encoding condition), this is a crucial test of the probability-matching account, since it associates the guessing parameter directly with the perceived contingency. If guessing bias were unrelated to perceived contingency, the probability-matching account would be falsified. We additionally tested the hypothesis that the source-guessing biases of participants with good source memory would be closer to the actual contingency than would the source-guessing biases of participants with poor source memory, because participants with good source memory would be more likely to realize the actual contingency (cf. Spaniol & Bayen, 2002). Thus, there should be a negative correlation between the source memory parameter d and the difference between the perceived and the real contingencies.
In our experiment, participants in the encoding condition were told about the professions of the two sources before encoding. In contrast, participants in the retrieval condition did not know about the professions until the test phase. In both conditions, schematically expected statements were presented with equal probabilities by the expected and by the unexpected source. Previous studies with traditional MPT analyses on aggregated data had shown that the guessing bias is near the true contingency if the schematically relevant information is available during encoding (e.g., Kuhlmann et al., 2012). In this case, participants notice the contingencies during the encoding phase and later adjust their guessing accordingly. If, however, participants have difficulties accessing the true contingency (because the schema information was not available during encoding), source guessing is biased toward the schematically expected source (Kuhlmann et al., 2012). Thus, we wanted to replicate previous findings, namely that the guessing parameter g would equal .5 (i.e., reflect the true source–item contingency) in the encoding condition, and be larger than .5 (i.e., biased toward the schematically expected source) in the retrieval condition. Our main objective, however, was to test the probability-matching account more stringently with the new beta-MPT method. We hypothesized a positive correlation between guessing parameter g and the perceived contingency. Also, we expected to find a negative correlation between source memory parameter d and the deviation of the perceived contingency from the true contingency of .5.
Method
Participants
The participants were 48 native German speakers (41 students, 7 employed). The mean age was 22.6 years (range 18 to 32). All participants received €5.
Design
We used a 3 × 2 × 2 mixed factorial design, with Expectancy of Statements (expected-doctor statements, expected-lawyer statements, and equally expected filler statements) and Source of Statement (doctor vs. lawyer) as within-subjects factors, and Time of Schema Activation (before encoding vs. before retrieval) as a between-subjects factor. The participants were randomly and equally assigned to the two conditions.
Materials
The design relied on well-established doctor and lawyer schemas. We used the German version of Bayen et al.’s (2000) doctor–lawyer materials, as developed by Kuhlmann et al. (2012), who normed the sentences with expectancy ratings from 60 native German speakers. The materials consisted of 96 statement pairs, of which 32 were expected for a doctor, 32 were expected for a lawyer, and 32 were filler statement pairs that were equally expected for both. The two members of each pair differed in one word or phrase that changes the meaning, and they were randomly assigned as the target and distractor in our memory test.
Procedure
The participants were tested in groups of up to four in individual computer booths. Computerized instructions informed them that they would see the faces of Ralf and Uwe (German male names) accompanied by statements. In the encoding condition, they were also told that, for example, Ralf was a doctor and Uwe was a lawyer. The assignment of names to sources was counterbalanced. Participants were informed that they would have to recognize the statements later. There was no mention of the upcoming source memory test. The 96 statements were presented for 6 s each, in random order, above the face of the source “speaking.” Participants also saw the name (e.g., “RALF”) and, in the encoding condition, the profession of the source (e.g., “RALF = DOCTOR”). Four equally expected statements served as a primacy buffer. The statements were randomly assigned to the sources, with equal numbers of expected and unexpected statements (i.e., statements that were expected for the other source) being assigned to each source. Thus, there was a zero contingency between the source and the expectedness of the statement.
The instructions for the self-paced source-monitoring test started immediately after study. The participants had to judge whether each test statement had been said by Ralf, by Uwe, or by neither. At this time, participants in the retrieval condition were given the sources’ professions. At test, the pictures of the sources were shown side by side on the screen, along with the names and professions (e.g., “RALF = DOCTOR”). The third option, “NEITHER,” appeared centered without a picture. The 96 (32 expected-doctor, 32 expected-lawyer, and 32 equally expected filler) sentences were presented in a random order centered at the top of the screen, preceded by “Who said:”. For each source, a random half of the statements of each type were tested in their study version, whereas for the remaining statements, the distractor version was used.
Assignment of the “D” and “K” keys to the sources (doctor, lawyer) was counterbalanced. The participants pressed the space bar when they believed that a statement was new, and error feedback was not provided.
After the memory test, the participants gave contingency judgments by answering two questions in counterbalanced order: namely (in translation), “How many of the 32 expected-doctor statements were said by RALF = doctor?” and “How many of the 32 expected-lawyer statements were said by UWE = lawyer?” Finally, they completed a demographic questionnaire and were debriefed and paid.
Results
For ease of presentation, we grouped the statements into two types, namely schematically expected (those presented by their expected source) and schematically unexpected (those presented by the unexpected source) statements. Separate analyses for the expected-doctor and expected-lawyer statements revealed the same pattern of results (see Online Supplement 1 for the raw data and Supplement 2 for the parameter estimates). We conducted traditional MPT analyses (with the data aggregated over items and participants) with the multiTree program (Moshagen, 2010) and hierarchical modeling with beta-MPT (Smith & Batchelder, 2010). We used an alpha level of .05 for all significance tests.
Traditional MPT analysis on aggregated data
We estimated separate models for the encoding and retrieval conditions on the basis of the aggregated data presented in Table 1. The parameter estimates and confidence intervals are in Table 2. We tested goodness of fit with the log-likelihood statistic G 2, which is asymptotically chi-square distributed. The four-parameter version of the model fit the data in both conditions, G 2 enc(2) = 2.37, p = .31, and G 2 ret(2) = 2.00, p = .37. As expected, in the retrieval condition, the guessing parameter g was significantly larger than .5, G 2(1) = 223.55, p < .01. In the encoding condition, g was also significantly larger than .5, G 2(1) = 18.81, p < .01. Thus, contrary to expectations for this condition, we did not find that participants guessed according to the true contingency, but instead were biased toward the schematically expected source. However, participants in the retrieval condition showed significantly larger guessing biases than did participants in the encoding condition, G 2(1) = 97.05, p < .01. Thus, as predicted by the probability-matching account, participants in the retrieval condition were more likely to guess according to the schematically expected source, whereas participants in the encoding condition appeared to have adjusted their guessing bias toward the true zero contingency. The raw data for the equally expected statements are in Online Supplement 1, and the parameter estimates are in Supplement 2. For these control statements, guessing parameter g did not differ significantly from .5 in either condition, as expected: G 2 enc(1) = 0.75, G 2 ret(1) = 0.03.
Analysis with beta-MPT
We used the basic version of the Markov chain Monte Carlo (MCMC) algorithm provided by Smith and Batchelder (2010) for the pair-clustering model and adjusted it to the 2HTSM. We used WinBUGS (Lunn, Thomas, Best, & Spiegelhalter, 2000) to run the MCMC method. At convergence, the potential scale reduction factor Rhat = 1. Again, we estimated separate models for the encoding and retrieval conditions. Each algorithm was run with 100,000 iterations, with the first half removed as a burn-in period. For all parameter estimates, Rhat = 1, except for α, β, and the variance of the item memory parameter D in the encoding condition, where Rhat = 1.5. Table 3 shows the posterior distributions of the parameters of the hierarchical beta distributions. Credible intervals of the standard deviations for the parameters did not include zero for any of the parameters. This means that parameter homogeneity (i.e., SD = 0) was very unlikely. Thus, there is strong evidence for heterogeneity, especially for guessing parameter g. As is shown in Table 2, the general patterns of the results are similar for the standard aggregated analysis with multiTree and the group parameters from the beta-2HTSM analyses. The 95 % confidence intervals and the credible intervals (Bayesian confidence intervals) overlapped for all parameter estimates.
We transformed participants’ absolute contingency judgments to relative contingency judgments. The contingency judgments for expected-doctor (M enc = .57, SD enc = .10; M ret = .60, SD ret = .19) and expected-lawyer (M enc = .58, SD enc = .10; M ret = .62, SD ret = .19) statements did not differ significantly for either experimental group, both ps > .40. In the encoding condition, the mean contingency judgment was M = .57, SD = .08. In the retrieval condition, the mean contingency judgment was M = .61, SD = .17. The correlations between perceived contingency and the source-guessing bias g were significant, with r = .45, p = .02 (see Fig. 2a, all correlations one-tailed), in the encoding condition and r = .55, p < .01 (see Fig. 2b), in the retrieval condition. This means that the higher that the contingency of items and their expected sources was perceived, the higher was the probability that the participants guessed that an item was from the expected source. The main hypothesis derived from the probability-matching account was hence confirmed.

a Correlation between contingency judgments (transformed to relative frequencies) and individual guessing parameters in the encoding condition. b Correlation between contingency judgments (transformed to relative frequencies) and individual guessing parameters in the retrieval condition. c Correlation between the deviations of participants’ contingency judgments from the true contingency of .5 (transformed to relative frequencies) and their individual source memory parameters in the encoding condition. d Correlation between the deviations of participants’ contingency judgments from the true contingency of .5 (transformed to relative frequencies) and their individual source memory parameters in the retrieval condition
The correlation between source memory parameter d and the absolute deviation of the contingency judgments from the true contingency of .5 was r = .05, p = .81, in the encoding condition (see Fig. 2c), but in the retrieval condition we found a significant negative correlation, r = −.42, p = .04 (see Fig. 2d), as expected. We found the same pattern for the correlations between source memory and the absolute deviation of the guessing bias g from the true contingency—that is, r = .02, p = .46, in the encoding condition and r = −.62, p < .01, in the retrieval condition. This means that the source-guessing bias was independent of source memory in the encoding condition, but in the retrieval condition there was a significant negative correlation. That is, participants with poor source memory showed a larger bias than did participants with good source memory.
Discussion
The main purpose of this study was to test the assumption of the probability-matching account that people guess according to individually perceived source–item contingencies if they do not remember the source in a source-monitoring task. Using the beta-MPT approach, we found medium to large correlations between perceived contingencies and guessing probabilities, both in a condition in which schematic information about the sources was known at encoding and in a condition in which that information was not known until retrieval.
Our hypothesis that the source-guessing parameter g should not differ from .5 in the encoding condition but should in the retrieval condition was not confirmed in the traditional analysis with aggregated data. The provision of schematic information about the sources at encoding should have improved contingency detection (Kuhlmann et al., 2012); however, individual differences in contingency detection had consequences for the source-guessing bias. In our sample, several participants misperceived the source–item contingency as somewhat conforming with schematic knowledge, and hence the overall source-guessing bias was above .5. This finding underscores the value of our individual-differences approach with the beta-MPT analysis. According to Smith and Batchelder (2010), one of the disadvantages of the traditional analysis is that it can result in confidence intervals that are too narrow, and therefore, goodness-of-fit tests can become significant too frequently. Thus, we can place more trust into the beta-MPT analysis. Because of individual differences, experimental manipulations do not have equal effects on all participants. These individual differences are captured by the correlations made possible by the beta-MPT approach. However, even with traditional analyses, the source-guessing parameter was significantly higher in the retrieval condition, supporting the probability-matching account. In the encoding condition, we found no correlation between source memory and the deviation of the guessing bias from the true contingency. In the retrieval condition, however, we did find a significant negative correlation. Thus, the source-guessing bias was independent of source memory if participants learned about the professions of the sources before encoding. Possibly, in the encoding condition, even participants with poor source memory were able to recognize the true contingency during encoding. Thus, participants in this condition did not need good source memory to adjust their source guessing to the true contingency. For participants in the retrieval condition, on the other hand, it was more difficult to recognize the contingency during encoding; they may have recognized the contingency if they had good source memory, or else they adjusted their source guessing according to schematic knowledge.
Overall, our findings strongly support the probability-matching account of source guessing. We found a relationship between perceived source–item contingencies and source guessing, which is a core assumption of the probability-matching account. The results thus confirm a crucial prediction of this account. Contrary results would have meant falsification of the probability-matching account, which claims that participants match their response biases to the perceived ratio of different item types at test (Spaniol & Bayen, 2002). The findings concur with previous MPT analyses of aggregated data and, importantly, lend additional support through individual parameter estimates. Thus, for the first time, we have shown at an individual level that people match their source-guessing biases to perceived source–item contingencies.
References
Bayen, U. J., & Kuhlmann, B. G. (2011). Influences of source–item contingency and schematic knowledge on source monitoring: Tests of the probability-matching account. Journal of Memory and Language, 64, 1–17.
Bayen, U. J., Murnane, K., & Erdfelder, E. (1996). Source discrimination, item detection, and multinomial models of source monitoring. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 197–215. doi:10.1037/0278-7393.22.1.197
Bayen, U. J., Nakamura, G. V., Dupuis, S. E., & Yang, C.-L. (2000). The use of schematic knowledge about sources in source monitoring. Memory & Cognition, 28, 480–500. doi:10.3758/BF03198562
Buchner, A., Erdfelder, E., & Vaterrodt-Plünnecke, B. (1995). Toward unbiased measurement of conscious and unconscious memory processes within the process dissociation framework. Journal of Experimental Psychology: General, 124, 137–160. doi:10.1037/0096-3445.124.2.137
Ehrenberg, K., & Klauer, K. C. (2005). Flexible use of source information: Processing components of the inconsistency effect in person memory. Journal of Experimental Social Psychology, 41, 369–387.
Erdfelder, E., & Bredenkamp, J. (1998). Recognition of script-typical versus script-atypical information: Effects of cognitive elaboration. Memory & Cognition, 26, 922–938.
Estes, W. K., & Straughan, J. H. (1954). Analysis of a verbal conditioning situation in terms of statistical learning theory. Journal of Experimental Psychology, 47, 225–234.
Hicks, J. L., & Cockman, D. W. (2003). The effect of general knowledge on source memory and decision processes. Journal of Memory and Language, 48, 489–501. doi:10.1016/S0749-596X(02)00537-5
Johnson, M. K., Hashtroudi, S., & Lindsay, D. S. (1993). Source monitoring. Psychological Bulletin, 114, 3–28. doi:10.1037/0033-2909.114.1.3
Klauer, K. C. (2006). Hierarchical multinomial processing tree models: A latent-class approach. Psychometrika, 71, 7–31.
Klauer, K. C. (2010). Hierarchical multinomial processing tree models: A latent-trait approach. Psychometrika, 75, 70–98.
Kuhlmann, B. G., Vaterrodt, B., & Bayen, U. J. (2012). Schema-bias in source monitoring varies with encoding conditions: Support for a probability-matching account. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 1365–1376.
Lunn, D. J., Thomas, A., Best, N., & Spiegelhalter, D. (2000). WinBUGS—A Bayesian modelling framework: Concepts, structure, and extensibility. Statistics and Computing, 10, 325–337. doi:10.1023/A:1008929526011
Moshagen, M. (2010). multiTree: A computer program for the analysis of multinomial processing tree models. Behavior Research Methods, 42, 42–54. doi:10.3758/BRM.42.1.42
Smith, J. B., & Batchelder, W. H. (2008). Assessing individual differences in categorical data. Psychonomic Bulletin & Review, 15, 713–731. doi:10.3758/PBR.15.4.713
Smith, J. B., & Batchelder, W. H. (2010). Beta-MPT: Multinomial processing tree models for addressing individual differences. Journal of Mathematical Psychology, 54, 167–183.
Spaniol, J., & Bayen, U. J. (2002). When is schematic knowledge used in source monitoring? Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 631–651.
Author note
The research reported in this article was supported by Grant No. BA 3539/1-1 from the Deutsche Forschungsgemeinschaft. We thank Maike Lex and André Haese for assistance with the data collection.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(PDF 108 kb)
Rights and permissions
About this article
Cite this article
Arnold, N.R., Bayen, U.J., Kuhlmann, B.G. et al. Hierarchical modeling of contingency-based source monitoring: A test of the probability-matching account. Psychon Bull Rev 20, 326–333 (2013). https://doi.org/10.3758/s13423-012-0342-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-012-0342-7