
Abstract
The debate over unitary/multiple category-learning utilities is reminiscent of debates about multiple memory systems and unitary/dual codes in knowledge representation. In categorization, researchers continue to seek paradigms to dissociate explicit learning processes (yielding verbalizable rules) from implicit learning processes (yielding stimulus–response associations that remain outside awareness). We introduce a new dissociation here. Participants learned matched category tasks with a multidimensional, information-integration solution or a one-dimensional, rule-based solution. They received reinforcement immediately (0-Back reinforcement) or after one intervening trial (1-Back reinforcement). Lagged reinforcement eliminated implicit, information-integration category learning but preserved explicit, rule-based learning. Moreover, information-integration learners facing lagged reinforcement spontaneously adopted explicit rule strategies that poorly suited their task. The results represent a strong process dissociation in categorization, broadening the range of empirical techniques for testing the multiple-process theoretical perspective. This and related methods that disable associative learning—fostering a transition to explicit-declarative cognition—could have broad utility in comparative, cognitive, and developmental science.
Similar content being viewed by others

Categorization is an essential cognitive function with great evolutionary depth. It increases fitness because categories—that is, psychological equivalence classes—support adaptive behavior toward the members of natural kinds (e.g., members of prey and predator species). Given its importance, categorization is a sharp focus of cognitive research with animals (e.g., Cerella, 1979; Herrnstein, Loveland, & Cable, 1976; Medin, 1975; Pearce, 1994; Smith, Redford, & Haas, 2008; Wasserman, Kiedinger, & Bhatt, 1988) and humans (e.g., Ashby & Maddox, 2011; Brooks, 1978; Feldman, 2000; Knowlton & Squire, 1993; Medin & Schaffer, 1978; Murphy, 2003; Nosofsky, 1987; Rosch & Mervis, 1975; Smith & Minda, 1998).
Categorization could be important enough that organisms bring complementary categorization processes to bear on different situations. Cognitive systems are often diversified, not parsimoniously unitary, as when animals use circadian or interval timing, dead-reckoning or landmark navigation, and so forth. There are trade-offs between alternative processes in human categorization (e.g., Ashby & Maddox, 2011; Blair & Homa, 2003; Homa, Sterling, & Trepel, 1981; Reed, 1978; Smith, Chapman, & Redford, 2010; Smith, Murray, & Minda, 1997). There are parallel trade-offs in animal categorization, pointing to evolutionary continuities (e.g., Cook & Smith, 2006; Smith, Beran, Crossley, Boomer, & Ashby, 2010; Smith et al., 2010; Smith, Coutinho, & Couchman, 2011; Smith, Zakrzewski, Johnson, & Valleau, 2016; Wasserman et al., 1988).
To organize these results, some take a multiple-process theoretical perspective toward categorization (e.g., Ashby & Maddox, 2011; Erickson & Kruschke, 1998; Homa et al., 1981; Minda & Smith, 2001; Rosseel, 2002; Smith & Minda, 1998). They suppose that multiple categorization utilities can be called upon when necessary to learn classifications and discriminations. Not everyone endorses this perspective, though. Some favor explaining categorization as a single, unitary process (e.g., Nosofsky & Johansen, 2000; Nosofsky, Little, Donkin, & Fific, 2011). The present article sheds additional light on this debate by presenting a new dissociative paradigm that broadens the empirical support for a multiple-process theoretical perspective.
Implicit-procedural and explicit-declarative category learning
Implicit-procedural learning
Our approach is grounded in a multiple-process perspective drawn from cognitive neuroscience (e.g., Ashby & Ell, 2001; Ashby & Valentin, 2005; Maddox & Ashby, 2004). One integrated set of processes—called here implicit-procedural learning—is linked to the basal ganglia. It is an important reinforcement-based learning system. It may underlie humans’ procedural, skill, and habit learning (e.g., Mishkin, Malamut, & Bachevalier, 1984) and performance in instrumental-conditioning, perceptual-categorization, and some discrimination-learning tasks (Ashby & Ennis, 2006; Barnes, Kubota, Hu, Jin, & Graybiel, 2005; Divac, Rosvold, & Szwarcbart, 1967; Filoteo, Maddox, Salmon, & Song, 2005; Knowlton, Mangels, & Squire, 1996; Konorski, 1967; McDonald & White, 1993, 1994; Nomura et al., 2007; O’Doherty et al., 2004; Packard, Hirsh, & White, 1989; Packard & McGaugh, 1992; Seger & Cincotta, 2005; Waldschmidt & Ashby, 2011; Yin, Ostlund, Knowlton, & Balleine, 2005). Categorization and discrimination are old and crucial adaptations that might have originated in evolutionarily older brain regions such as the basal ganglia. This implicit system learns associatively through procedural-learning processes akin to conditioning. It learns slowly, relying on temporally contiguous reinforcement. Participants generally cannot describe their implicit categorization strategies.
Explicit-declarative learning
Another integrated set of processes—called here explicit-declarative category learning—is linked to the prefrontal cortex, the anterior cingulate gyrus, the head of the caudate nucleus, and the hippocampus. It uses executive attention (Posner & Petersen, 1990) and working memory (Fuster, 1989; Goldman-Rakic, 1987), capacities that would support hypothesis testing and rule formation (Brown & Marsden, 1988; Cools, van den Bercken, Horstink, van Spaendonck, & Berger, 1984; Elliott & Dolan, 1998; Kolb & Whishaw, 1990; Rao et al., 1997; Robinson, Heaton, Lehman, & Stilson, 1980). It learns by testing hypotheses. It learns rules that participants can describe verbally.
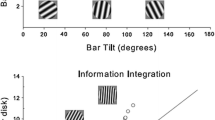
Evidence for implicit and explicit category learning comes from information-integration (II) and rule-based (RB) category-learning tasks (see Fig. 1). Exemplars in these tasks are defined by their values on two perceptual dimensions. For example, each stimulus might be a box of some size (Dimension X) and some density of lit pixels (Dimension Y). In Fig. 1, individual symbols pinpoint the dimensional values of specific Category A and Category B members (gray and black symbols, respectively).

Information-integration and rule-based category tasks illustrated within a 101 × 101 stimulus space. The gray and black symbols, respectively, indicate Category A and Category B stimuli
Figure 1a shows stimuli for an II task. Both dimensions present valid but insufficient category information. To categorize successfully, the participant must integrate the dimensional information (thus, an II task). The cognitive system accomplishes this integration implicitly. Humans cannot explain their solution of an II task verbally, especially when the stimulus dimensions are incommensurate. Note that in the II task, one-dimensional rules are nonoptimal. A vertical or horizontal category boundary (i.e., an X rule or Y rule, respectively) will not separate the two categories appropriately, producing poor performance.
Figure 1b shows an RB category task. Only Dimension X presents useful category information. Low and high values on Dimension X define Category A and Category B members, respectively. A one-dimensional rule is the optimal solution (thus, an RB task). These rules are explicit (held in working memory) and declarative (verbalizable). Note that RB (and II) participants are never shown the map of the stimulus space as in Fig. 1. Instead, they must learn to categorize based on the presentation of single stimuli with attendant feedback.
Figure 1 shows that II and RB tasks are simply rotations of one another through stimulus space. The tasks are matched for category size, within-category exemplar similarity, between-category exemplar dissimilarity, overall category discriminability (d′), and for the proportion correct that an ideal observer can optimally achieve. Therefore, there is no objective, a priori difficulty difference between RB and II tasks. Illustrating this equivalence, Smith et al. (2011) showed that pigeons (Columba livia) learned II and RB tasks equally well and quickly. Probably this result was obtained because pigeons lack an explicit category-learning system that selectively supports rule learning. In contrast, humans do learn RB tasks faster than II tasks because they do deliberately learn explicit rules. Accordingly, the II and RB tasks are balanced and useful mutual controls. Moreover, an RB learning advantage suggests that a particular rule task is indeed supported by explicit category-learning processes.
Empirical goal
There have also been demonstrations that suggest II–RB dissociations in categorization. For example, delaying feedback temporally following category response impairs II learning more than it impairs RB learning (Maddox, Ashby, & Bohil, 2003; Maddox & Ing, 2005). Additionally, participants can self-instruct to learn RB categories under unsupervised conditions when no feedback is available, but they cannot learn II categories in this way (Ashby, Isen, & Turken, 1999; Ashby, Queller, & Berretty, 1999). However, these demonstrations have not been universally persuasive. Cognitive science has an insistent impulse to pursue parsimonious, unitary explanations of performance. This is why theorists long pursued unitary-code theory in the imagery literature and long doubted the idea of multiple, dissociable systems or processes in the memory literature (e.g., Nairne, 1990; Pylyshyn, 1973). In categorization, too, this hope for parsimony has run deep, so that for 20 years the multiple-systems idea has taken hold only slowly, with difficulty (e.g., Nosofsky & Kruschke, 2002). For example, the RB–II accuracy difference in performance has frequently been cast as a difficulty difference confronting a unitary system, even though the objective difficulty of the tasks (without assuming selective attention and rule formation) is equal. Therefore, there is still a need for converging operations, for new dissociative paradigms that broaden the empirical support for a multiple-process theoretical perspective. This is the goal of the present article. In addition, our new paradigm has a distinctive feature that can grant researchers access to new lines of investigation.
Empirical approach
Our goal was to provide a new empirical dissociation between implicit-procedural and explicit-declarative category learning, strengthening the empirical basis for the multiple-process theoretical perspective. We also sought to produce the simplest dissociation of its kind. We wanted our paradigm to scale to constructive research with young children, to children with language delays and learning challenges, and to children with different places along the autistic spectrum. We wanted our dissociative method to scale to any species capable of discrimination learning. This potential reach was the distinctive feature of our paradigm. In contrast, for example, placing a young child or nonhuman primate into an unsupervised category-learning experiment of this type is likely to be quite unsuccessful, because it requires a sophisticated instructional preparation and a mature, self-controlled cognitive orientation by the participant.
To create the simplest and sharpest possible dissociation, we took on the considerable challenge of disabling the implicit-procedural learning system. We did this by disrupting its reinforcement dynamic, disrupting thereby a dominant reinforcement-learning system in the brain. It is helpful to describe that reinforcement dynamic here.
The basal ganglia are important for various kinds of reinforcement-based discrimination learning. In nonhuman primates, for example, extrastriate visual cortex projects directly to the tail of the caudate nucleus—with massive convergence of visual cells onto caudate cells that project on to the premotor cortex (Alexander, DeLong, & Strick, 1986). The caudate is well placed to associate percepts through to actions, perhaps its primary role. Multiple lines of research support that role (Eacott & Gaffan, 1992; Gaffan & Eacott, 1995; Gaffan & Harrison, 1987; McDonald & White, 1993, 1994; Packard et al., 1989; Packard & McGaugh, 1992; Rolls, 1994; Wickens, 1993).
Rewards cause dopamine release into the tail of the caudate nucleus (Hollerman & Schultz, 1998; Schultz, 1992; Wickens, 1993). The dopamine signal can strengthen recently active synapses that were plausibly participatory in reward (Arbuthnott, Ingham, & Wickens, 2000; Calabresi, Pisani, Centonze, & Bernardi, 1996). There is a constraint on this mechanism. If reinforcement lags, and the neural system returns to baseline, there is no record of the contributing synapses and no way to strengthen them. This system cannot access working memory or declarative consciousness in assigning neural credit for rewards. In caudate-mediated discrimination learning, the idea of stimulus–response (SR) bonds is literal, because the caudate links (associates) cortical stimulus representations (its direct inputs) to adaptive responses (its indirect outputs). But for this system to operate, the relevant cortical representation must still be active, and the reinforcement signal must arrive promptly.
Illustrating this dynamic, Yagishita et al. (2014) used optogenetic methods to stimulate sensorimotor inputs and dopaminergic inputs separately, gaining control over their temporal asynchrony. Dopamine failed to promote strengthened synapses if delayed beyond 2.0 s. Remarkably, these authors imaged dendritic spine improvement but only saw it given immediate reinforcement. The delay curve they plotted is like that plotted when humans learn categories at different reinforcement delays (Maddox et al., 2003; Maddox & Ing, 2005). This temporal restriction applies to many associative and instrumental-conditioning phenomena familiar to comparative psychologists (Han et al., 2003; Kryukov, 2012; Raybuck & Lattal, 2014; Smith & Church, 2017), and it has been known for a century (Pavlov, 1927; Thorndike, 1911).
The implication of this work is that implicit-procedural learning could be disabled by eliminating the availability of relevant cortical representations or by delaying the arrival of the reinforcement—or both, as in our approach. Implicit-procedural learning would become impossible, and one could evaluate participants’ capacity to adopt alternative learning processes instead.
We instituted a 1-Back reinforcement regimen as a simple way to arrange this disruption. In this regimen, reinforcement lagged one trial behind the stimulus–response pairs as they occurred, so that reinforcement never related to the present stimulus or response. Participants received feedback for Trial 1 after completing Trial 2, for Trial 2 after completing Trial 3, and so forth. They were instructed on the nature of the feedback they would receive. At feedback, the reinforcement-relevant stimulus was gone and masked by the present stimulus. The reinforcement was delayed outside the tolerance of striatal learning. Our hypothesis was that 1-Back reinforcement would disrupt the associative reinforcement-learning system thoroughly (doubly) by blocking it representationally and temporally, even though participants had full knowledge of the reinforcement regimen.
Predictions
First, 1-Back reinforcement (compared to 0-Back reinforcement) should defeat the reinforcement-based processes underlying II learning. We predicted this learning process would collapse.
Second, 1-Back reinforcement should affect RB learning minimally. RB learners could hold their rule in working memory and evaluate its aptness equally well facing lagged or immediate reinforcement. So RB learning should still succeed under lagged reinforcement.
Third, if 1-Back reinforcement disables II but not RB category learning, II participants facing 1-Back reinforcement might turn—by information-processing necessity—to rules instead. Thus, we predicted that II 1-Back participants would supply their own rule construal of the II task because that was what they still could do—even though such a rule was not much good in the II task.
If confirmed, these predictions would provide an elemental dissociation between RB and II learning and strongly demonstrate that lagged reinforcement disables associative, reinforcement-based learning.
Method
Participants
One hundred and seventy-three Georgia State undergraduates with normal or corrected-to-normal vision participated for course credit. Participants’ data were excluded with cause if they completed fewer than 480 trials (one participant each excluded from the RB 0-Back, II 1-Back, and II 0-Back conditions) or if they showed no learning. No learning was defined as not scoring significantly above chance performance (56.7% correct) in the last half of the trials (15, 16, 13, and six participants were excluded for this reason from the RB 1-Back, RB 0-Back, II 1-Back, and II 0-Back conditions, respectively). Because we are interested in the strategies of category learning used in the last 100 trials, it was important to only include participants who were still actively engaging the task and trying to correctly categorize even at the end. This learning criterion allowed us to exclude participants who either because of a lack of motivation, boredom/fatigue, or difficulty understanding the instructions were no longer trying to make accurate decisions toward the end. Based on previous findings, we used a stopping rule of 30 includable participants per condition. The final sample included 120 participants—30 in each of the four conditions.
Stimuli
The stimuli were unframed rectangles containing green lit pixels, presented on a black background at the right of a 17-in. computer monitor. They were viewed from a distance of about 24 in. The stimulus rectangles varied in size and pixel density. Both dimensions had 101 levels (Levels 0–100). Rectangle width and height (in screen pixels) were calculated as 100 + level and 50 + level/2, respectively. Thus, rectangle size ranged from 100 × 50 (Level 0) to 200 × 100 (Level 100). Pixel density—that is, the proportion of pixel positions within the rectangle that were illuminated—was calculated as 0.05 × 1.018level. Thus, density varied from .05 (Level 0) to .30 (Level 100). Figure 2 shows the stimuli in the four corners of the stimulus space.

Illustration of concrete stimuli within the 101 × 101 stimulus space, showing the maximum variation of rectangle size (left to right) and pixel density (bottom to top)
Category structures
The category structures used were a major-diagonal II structure with size and density relevant and a vertical RB structure with size relevant. The categories were defined by bivariate normal distributions along the stimulus dimensions. Each exemplar was selected as a coordinate pair in the 101 × 101 space, and these abstract levels were transformed into concrete size and density values (see Stimuli, above). Each participant received his or her own sample of randomly selected category exemplars appropriate to the assigned task. To control for statistical outliers, we did not present exemplars whose Mahalanobis distance (e.g., Fukunaga, 1972) from the category mean exceeded 3.0. This ensured well-behaved elliptical stimulus distributions for the categories.
Design and procedure
The experiment included four between-participant conditions created by crossing two category structures (RB, II) with two reinforcement conditions (0-Back, 1-Back). Participants were assigned randomly to a task and reinforcement condition using their participant number in the experiment.
Our crucial manipulation was to disrupt the normal cycle of immediate reinforcement following the response to a stimulus. In our 0-Back reinforcement condition, this cycle was sustained. Participants saw a stimulus, categorized it by making a Category A or Category B response, and then received immediate feedback. In our 1-Back reinforcement condition, this cycle was disrupted. Participants saw a stimulus, categorized it by making a Category A or Category B response, but then received feedback pertaining to the previous trial they had completed (after Trial 2, feedback for Trial 1 was delivered; after Trial 3, feedback for Trial 2 was delivered, etc.).
The feedback was positioned spatially to make clear to which trial the feedback pertained—this was the purpose of alternating Top and Bottom trials. Notice that the 1-Back reinforcement did not concern a presently available stimulus, or the most recently available stimulus/cortical representation, or the most recently completed behavioral response. It concerned a previous stimulus, cortical representation, and response. Associative learning was disrupted representationally. It was also disrupted temporally because the reinforcement given was delayed several seconds beyond the stimulus–response pair to which it belonged.
On each trial, the to-be-categorized rectangle appeared at the computer screen’s far right. Toward the left of the screen were the large-font letters “A” (on the left) and “B” (on the right), along with a participant-controlled cursor midway between them. Participants pressed the “S” or “L” key on the computer keyboard to choose the response “A” or “B,” indicating to which category they thought the stimulus belonged. The response keys corresponded spatially to the “A” and “B” response icons on the screen and they had tape labeling the appropriate keys “A” and “B.” Top and Bottom trials were arrayed across the top and bottom halves of the screen, respectively, for reasons already explained.
In the 0-Back condition, participants received immediate feedback after each trial. After correct responses, they saw, This Top (Bottom) trial was correct +1 Points Total Points N+1. After incorrect responses, they saw, This Top (Bottom) trial was incorrect −1 Points Total Points N-1. In the latter case, they received a brief penalty time-out of 2 s.
In the 1-Back condition, the feedback was displaced spatially and temporally. That is, following a Bottom trial, participants received lagged feedback regarding the previous Top trial. For example, they might see, given a correct response, and presented at the top of the screen in the position for Top trial feedback, This Top trial was correct +1 Points Total Points N+1. Following a Top trial, participants received lagged feedback regarding the previous Bottom trial. For example, they might see, given an incorrect response, and presented at the bottom of the screen in the position for Bottom trial feedback, This Bottom trial was incorrect −1 Points Total Points N-1. Trials continued until the 52-min session ended or the participant completed 480 trials.
Instructions: 1-Back condition
Participants were told that they would categorize pixel boxes varying in size and dot density as Category A or Category B. They were told that A and B boxes would occur equally often, and that they would have to guess at first, but later would learn to respond correctly. They knew that they would gain or lose 1 point for correct and incorrect responses, respectively, and that they would receive a time-out for incorrect responses. They were told that errors would cost them points, and time to earn points, and that it could make their session longer. They were told that on Trial 2 they would receive feedback from their response on Trial 1, and on Trial 3 receive feedback from their response on Trial 2. They were told that their feedback would always lag one trial behind throughout the task. They were told that even though the boxes alternated top and bottom on the screen, this had nothing to do with their Category A or Category B status. This was done to help them keep track of whether the feedback applied to a top or bottom trial.
Instructions: 0-Back condition
The instructions were similar in many respects for the 0-Back participants, except that they were simply told that they would receive feedback on their responses after each trial.
Formal modeling
Following Maddox and Ashby (1993), we fit rule-learning and procedural-learning formal models to each participant’s last 100 categorization responses. The rule-learning model assumes that participants set a criterion on one stimulus dimension. This unidimensional criterion can be visualized as a vertical or horizontal line through the stimulus space of Fig. 1. The modeling specifies the horizontal or vertical line that would best partition the participant’s Category A and Category B responses. The rule-learning model has two free parameters: a perceptual noise variance and a criterion value on the relevant dimension. The procedural-learning model assumes that participants partition the stimulus space consonant with a diagonal decision boundary of some slope and intercept. The modeling lets us specify the line of any slope and intercept that best partitions the participant’s Category A and Category B responses. The procedural-learning model has three free parameters: a perceptual noise variance and the slope and intercept of the decision boundary.
The modeling yields the best fitting decision boundary that summarizes the partition between the categories the participant achieved. This boundary summarizes category performance. However, participants may not learn this boundary, or use this boundary, or have this boundary as any aspect of their category knowledge. In particular, in the case of II learning, participants learn in essence SR associations, the correct response mapping to many category instances. This will produce a category partition that the model captures as a boundary and that we draw in the figures below, but this boundary almost certainly has no role in the person’s II categorization performance, and no place in their II category knowledge.
We estimated the best fitting values for the free parameters in the models using the method of maximum likelihood. The process of model fitting asked which model would have created—with maximum likelihood—the distribution of Category A–B responses the participant produced. The best fitting model was chosen as the one with the smallest Bayesian information criterion (BIC Schwarz, 1978), which is defined as: BIC = r lnN – 2lnL, where r is the number of free parameters, N is the sample size, and L is the likelihood of the model given the data.
Results
Accuracy-based analyses
The proportion of correct responses was examined across twenty-four 20-trial blocks in a general linear model (GLM), with task (RB, II) and reinforcement condition (0-Back, 1-Back) as between-participant factors and trial block as a within-participant factor. The significant task main effect, F(1, 116) = 65.423, p < .001, ηp 2 = .979, confirmed that RB learning was generally stronger than II learning. This is a ubiquitous finding in this cognitive-neuroscience research area because humans’ rule-based processes for category learning are insistent within their cognitive system and privileged in category learning. The significant reinforcement main effect, F(1, 116) = 10.522, p = .002, ηp 2 = .881, confirmed the intuitive result that 0-Back reinforcement generally produced stronger category learning. The significant trial block main effect, F(23, 2668) = 30.535, p < .001, ηp 2 = .208, confirmed that learning occurred.
The crucial result was the three-way interaction among task, reinforcement, and trial block, F(23, 2668) = 3.163, p < .001, ηp 2 = .027. The sense of this result is that 1-Back reinforcement affected learning across trial blocks differently in the RB and II tasks. This difference can be seen in the learning curves represented in Fig. 3.

Average accuracy across blocks for each of the four groups. Dashed lines represent the RB tasks; solid lines the II tasks. Black lines represent 0-Back feedback; gray lines 1-Back feedback. Error bars represent 95% confidence intervals of the means
A careful examination of the learning curves shows very fast learning in the RB task with 0-Back feedback. By Block 4, group performance is at a high level of accuracy, suggesting that most participants have discovered the dimension of importance and found a good decision boundary. With 1-Back feedback, RB task participants are slower to come to this discovery, but by Block 10 they are also at a highly accurate performance level. The slower discovery of the dimension of interest is not surprising. Greater working memory demands are required in the 1-Back condition, and the nature of the feedback can be initially confusing. Examination of the II task condition with 0-Back feedback suggests a much more gradual learning curve that continues to improve slowly through the blocks, though by the end has not reached the very high accuracy seen in both RB tasks. On the other hand, in the II condition with 1-Back feedback, what little learning takes place seems to happen within the first few blocks, and then performance remains largely constant until the end of the blocks.
We further summarized this result in two ways: first by focusing on participants’ performance during their last trial block and second by examining the change in performance between the first block and the last block. In the last block, participants averaged .920, 95% CI [.970, .870]; .900, 95% CI [.965, .835]; .733, 95% CI [.780, .687]; and .653, 95% CI [.699, .608] correct in the RB-0, RB-1, II-0, and II-1 conditions, respectively. When we examined change in accuracy across the experiment (first block subtracted from last block), we saw a similar pattern. Participants’ average change was .300, 95% CI [.368, .232]; .328, 95% CI [.407, .250]; .207, 95% CI [.275, .138]; and .130, 95% CI [.205, .055] in the RB-0, RB-1, II-0, and II-1 conditions, respectively. Taken together, these patterns suggest that 1-Back reinforcement had essentially no cost to final RB learning but a substantial cost to II learning. The modeling analyses reveal the true extent of this cost.
Model-based analyses
We modeled participants’ last 100 trials to determine whether they adopted appropriate decision strategies and whether different reinforcement regimens changed their decision strategies in a theoretically meaningful way.
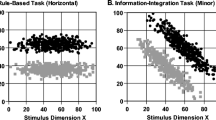
Figure 4a shows modeling results for the RB 0-Back participants. Twenty-three of the 30 decision boundaries were arranged vertically along the midline of the stimulus space’s X dimension. Many participants found the RB task’s adaptive solution—a one-dimensional size rule. Two participants misconstrued the task and performed according to a Y-dimension rule, producing horizontal decision boundaries. Four participants were best fit by a procedural-learning model that produced diagonal decisional boundaries. One participant was modeled as having a random-guessing strategy; for this participant, no definite decision boundary could be drawn.

The decision boundaries that provided the best fits to the last 100 responses of participants in the (a) rule-based (RB) condition with 0-Back reinforcement, (b) RB condition with 1-Back reinforcement, (c) information-integration (II) condition with 0-Back reinforcement, and (d) II condition with 1-Back reinforcement
Figure 4b shows modeling results for the RB 1-Back participants. This panel looks like that in Fig. 4a. Twenty-five of the 30 decision boundaries were vertical, indicating the participant’s appreciation of the task’s appropriate X-dimension rule. Three participants misconstrued the task and performed according to a Y-dimension rule (horizontal decision boundaries). One participant was best fit by a procedural-learning model and showed a diagonal decision boundary. There was one random-guessing participant again (no decision boundary).
Overall, the modeling results of the RB tasks confirmed the performance results. That is, participants were easily and equally able to learn the RB task’s size-rule solution under conditions of 0-Back and 1-Back reinforcement. The lagged reinforcement did not alter the character of their final learning. We confirmed this result statistically by computing chi-square. We used the number of participants who were best fit by the X-dimension rule, the Y-dimension rule, and the procedural-learning model in the RB 0-Back condition as the expected category observations, and the number in each category in the RB 1-Back condition as the observed values. These numbers were not significantly different between the conditions: χ2(2, N = 29) = 2.924, p = .404; w = .318.Footnote 1
Figure 4c shows modeling results for the II 0-Back participants. Eighteen of the participants were best fit by a procedural-learning model that indicated a diagonal decision boundary through the stimulus space. Most of these decision boundaries were organized along the stimulus space’s major diagonal. These participants found a way to integrate the informational signals provided by the two stimulus dimensions toward making appropriate category decisions. However, as is always true in experiments of this kind, some humans insisted on imposing adventitious unidimensional rules onto the II structure. In this case, 12 of the participants were best fit by a rule model that indicated for them either a horizontal or a vertical decision boundary. Humans’ rule-seeking category-learning system is insistent and can be dominant even when the result is suboptimal performance. This “misbehavior” by humans in the II task is another indication of the dissociative aspect of humans’ category learning that is the focus of this research.
Figure 4d shows modeling results for the II 1-Back participants. This panel does not look like that in Fig. 4c. Now, only 10 of the participants were best fit by a procedural-learning model of any slope. From the II 0-Back to the II 1-Back condition, the number of sloped decision boundaries was essentially halved. Now, 19 of the participants were best fit by a rule model, showing an adventitious, inappropriate vertical or horizontal decision boundary. From the II 0-Back to the II 1-Back condition, this inappropriate use of a rule framework essentially doubled. This condition also contained one random-guessing participant (no decision boundary drawn).
In reality, the II-1-Back learning success was far worse than stated. Only two participants, compared to 15 participants in the II 0-Back condition, showed the positively sloped diagonal boundary that would suggest any appreciation of the II task’s true underlying category structure. One may almost say that 1-Back reinforcement switched off true II category learning completely and qualitatively. Instead, participants defaulted to a rule strategy with decision boundaries dividing Dimension X or Dimension Y. The participants may have defaulted to the only categorization strategy that was available to them under 1-Back reinforcement. They had to hold in working memory a description of what they had done on that past trial so that the lagged reinforcement—when it finally came—could still support continuing category learning. As suggested by multiple-process theory, this description apparently had the form of a one-dimensional rule—it certainly did not have the form of an appropriate integrative principle across the dimensions.
Overall, modeling results of the II tasks confirmed the performance results. That is, participants were not easily able or equally able to learn the II task’s appropriate diagonal partition under conditions of 0-Back and 1-Back reinforcement. The lagged reinforcement did alter their pattern of learning. We confirmed this result statistically using a similar analysis to that used for RB participants, χ2(2, N = 29) = 8.306, p = .016; w = .535.
To further quantify this seeming difference in strategy use, we considered the performance accuracy on the modeled trials (the last 100) of only the participants who were best fit by the “correct” strategy model for their condition (RB participants best fit by an X-dimension rule, II participants best fit by a procedural-learning model). We conducted a GLM using categorization task (RB, II) and reinforcement (0-Back, 1-Back) as the independent variables. The significant main effect of task, F (1, 72) = 213.000, p < .001, ηp 2 = .747, confirmed that participants in the RB conditions performed more accurately. The significant reinforcement main effect, F(1, 72) = 23.883, p < .001, ηp 2 = .248, confirmed that 0-Back reinforcement produced stronger category learning. The significant Task × Reinforcement interaction, F(1, 72) = 10.635, p < .001, ηp 2 = .128, suggested that the effect of reinforcement type on accuracy was different depending on whether participants were “correctly” best fit by the procedural learning or the X-dimension rule model. Planned comparisons found that RB performance levels were not statistically different, t(46) = 1.375, p = .173, Cohen’s d = 0.485. As seen in Fig. 4, both 0-Back and 1-Back X-rule participants showed equivalently accurate performance and similarly correct placement of the rule boundary (.968, 95% CI [.978, .957] and .941, 95% CI [.972, .910] for 0-Back and 1-Back, respectively). However, II performance levels were statistically different, t(26) = 5.050, p < .001, Cohen’s d = 1.640. Even for participants best fit by an II model, 1-Back reinforcement significantly impaired their ability to learn the correct decision boundary (.779, 95% CI [.823, .735] and .644, 95% CI [.698, .590] for 0-Back and 1-Back, respectively).
Indeed, the modeling results strengthen the study’s theoretical interpretation beyond the accuracy-based analyses. The .65 accuracy achieved by II 1-Back participants definitely does not signify 65% successful and appropriate II learning. It signifies heavy dependence on adventitious rules, and it signifies heavy dependence on the wrong information-processing strategy for the II task. Really, there was almost no successful II learning in this condition. Implicit-procedural learning was disabled by 1-Back reinforcement.
General discussion
Cognitive science often expresses its preference for unitary codes in knowledge representation and for single, all-explanatory learning/memory systems. It is a central issue whether minds are parsimonious in this way, or whether minds have accumulated many useful, nonparsimonious apps during cognitive evolution. The debate over multiple categorization systems reflects this tension again. Thus, categorization researchers continue to seek strong dissociative paradigms to determine whether multiple, qualitatively different processes are suggested. We introduced a new paradigm here.
We predicted that 1-Back reinforcement would disable associative, reinforcement-driven learning and the II category-learning processes that depend on it. This disabling seems to have been complete.
We predicted that RB participants could hold their provisional category rule in working memory, making it accessible for evaluation under 0-Back or 1-Back reinforcement. RB learning survived 1-Back reinforcement. The dissociation from these two results combined provides new support for a multiple-process conception of human categorization. Different category tasks foster different category-learning processes.
We predicted that participants might fall back, by information-processing necessity, to rule strategies when 1-Back reinforcement disabled implicit-procedural learning. This implicit system cannot bridge between a past stimulus–response pair and future reinforcement. Working memory can, but it has been known since Bruner, Goodnow, and Austin (1956) that humans’ explicit classificatory rules are low-dimensional or one-dimensional. In fact, II 1-Back participants largely turned toward one-dimensional rules.
A broader class of learning paradigms
Our paradigm is complementary to others pursuing a similar theoretical goal—to block the influence of immediate reinforcement and foster the recruitment of explicit-declarative learning processes instead. These complementary tasks lie along a spectrum. Our task here separated the trial from its reinforcement through a one-trial lag. It minimally separated trials from reinforcement, it maximally integrated reinforcement into the steady-state trial environment, and it let reinforcement maximally energize and motivate task participation.
In an intermediate manipulation, Smith et al. (2014) created a trial block of separation. Participants completed a block of trials before feedback. At block’s end, they received all their rewards clustered and then all their penalty time-outs clustered. Feedback was temporally displaced and scrambled out of trial-by-trial order, doubly defeating stimulus–response learning. However, now reinforcement could only sporadically motivate performance. And now, the instructional set communicated to the participant, and their self-control in executing it, carried a heavier burden.
In an extreme manipulation, Ashby, Isen, et al. (1999; Ashby, Queller, et al., 1999) created ultimate separation by eliminating feedback entirely through an unsupervised-learning paradigm. Now, the burden on the communicated instructional set and its self-management was very heavy. No reinforcement helped motivate performance. Nonetheless, this technique powerfully elicited explicit-declarative processes in category learning from adult, cognitively sophisticated humans.
These tasks share a goal and a family resemblance, while differing in how far they distance reinforcement, how well they still let reinforcement energize performance, and how demanding they are that participants receive, accept, and execute an elaborate cognitive set. Using varied means, they all disrupt the temporal contiguity of the reinforcement signal, disable the reinforcement-binding properties, and prompt a transition to alternative, explicit learning processes. In a sense, these paradigms all seek to replace concrete reinforcement with feedback (or self-feedback) that has a purely informational function, so that it supports learning at an explicit level even if it can no longer support learning at an associative level. The crux of all these paradigms is to keep immediate reinforcement at a “safe” methodological and theoretical distance that rules out associative learning. Then, feedback provides food for thought, not fuel for habit formation. Collectively, these paradigms are progressively combining into a persuasive and conclusive dissociative framework within the categorization literature.
Empirical and theoretical extensions
As specific paradigms, these techniques naturally have their different strengths and weaknesses. For example, unsupervised learning is a powerful way to dissociate away associative learning—it eliminates concrete reinforcement entirely. However, it demands sophisticated participants. In contrast, the 1-Back technique would suit other populations. It integrates reinforcement more thoroughly. It energizes performance more encouragingly. It depends less on the experimenter-participant instructional/social contract. Accordingly, the 1-Back technique shows promise for less sophisticated, less verbal populations. For instance, developmentalists could use it to explore the earliest roots of explicit-declarative cognition in children. It is not known at what age children can first supply their own hypotheses and cognitive construals when reinforcement-driven learning is disallowed. Yet this is an important developmental step because self-directed, self-construed learning is an essential human capacity. Young children might not self-sustain interest or effort without ongoing reinforcement (stickers!) such as the 1-Back task would provide.
Our paradigm also has implications for comparative psychology. A problem faced in behavioral research is that animals’ performances might reflect their higher level cognitive processes or their reinforcement-driven behavioral reactions. There is always the possibility that immediate reinforcement is the true underlying engine of behavior and the integrator of stimulus–response (SR) bonds during learning. Moreover, this problem has often been considered inexorable, given the broad belief that immediate reinforcement is indispensable because it is the reason that animals perform and learn. However, our approach shows that simple dissociative paradigms can be developed that transcend reinforcement-driven learning while sustaining interest and motivation. One can then ask whether animals, in that circumstance, have another level and kind of learning that can replace this.
Our paradigm could be applied to any species that is capable of discrimination learning in simple two-response tasks. Therefore, one could also provide to comparative theory a phylogenetic map of explicit-declarative cognition. One could ask which vertebrate lines are capable of engaging in something like explicit-declarative cognition by asking which lines learn successfully under 1-Back reinforcement. This could be related to their known evolutionary histories and to their frontal-cortical development, also tracing the neuroscientific emergence of explicit cognition during cognitive evolution.
Thus, we believe that the present dissociative paradigm—the 1-Back methodology—represents a complementary methodology of interest to cognitive, comparative, and developmental psychologists, and to many biobehavioral researchers, too. Indeed, the empirical power to qualitatively unplug and shut down associative learning, using techniques like 1-Back feedback that require feedback to be interpreted informationally and explicitly, could become a powerful tool in the next epoch of theoretical development in biobehavioral research (Smith & Church, 2017).
Notes
Individuals who best fit the guessing model were not included in the chi-square analyses. This made the analyses more conservative in relation to our hypotheses.
References
Alexander, G. E., DeLong, M. R., & Strick, P. L. (1986). Parallel organization of functionally segregated circuits linking basal ganglia and cortex. Annual Review of Neuroscience, 9, 357–381. doi:https://doi.org/10.1146/annurev.ne.09.030186.002041
Arbuthnott, G. W., Ingham, C. A., & Wickens, J. R. (2000). Dopamine and synaptic plasticity in the neostriatum. Journal of Anatomy, 196, 587–596. doi:https://doi.org/10.1046/j.1469-7580.2000.19640587.x
Ashby, F. G., & Ell, S. W. (2001). The neurobiology of human category learning. Trends in Cognitive Sciences, 5, 204–210. doi:https://doi.org/10.1016/S1364-6613(00)01624-7
Ashby, F. G., & Ennis, J. M. (2006). The role of the basal ganglia in category learning. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 46, pp. 1–36). San Diego: Academic Press.
Ashby, F. G., Isen, A. M., & Turken, A. U. (1999). A neuropsychological theory of positive affect and its influence on cognition. Psychological Review, 106, 529–550. doi:https://doi.org/10.1037/0033-295X.106.3.529
Ashby, F. G., & Maddox, W. T. (2011). Human category learning 2.0 Annals of the New York Academy of Sciences, 1224, 147–161. doi:https://doi.org/10.1111/j.1749-6632.2010.05874.x
Ashby, F. G., Queller, S., & Berretty, P. T. (1999). On the dominance of unidimensional rules in unsupervised categorization. Perception & Psychophysics, 61, 1178–1199. doi:https://doi.org/10.3758/BF03207622
Ashby, F. G., & Valentin, V. V. (2005). Multiple systems of perceptual category learning: Theory and cognitive tests. In H. Cohen & C. Lefebvre (Eds.), Handbook of categorization in cognitive science (pp. 547–572). New York: Elsevier.
Barnes, T. D., Kubota, Y., Hu, D., Jin, D. Z., & Graybiel, A. M. (2005). Activity of striatal neurons reflects dynamic encoding and recoding of procedural memories. Nature, 437, 1158 –1161. doi:https://doi.org/10.1038/nature04053
Blair, M., & Homa, D. (2003). As easy to memorize as they are to classify: The 5-4 categories and the category advantage. Memory & Cognition, 31, 1293–1301. doi:https://doi.org/10.3758/BF03195812
Brooks, L. R. (1978). Nonanalytic concept formation and memory for instances. In E. Rosch & B. B. Lloyd (Eds.), Cognition and categorization (pp. 169–211). Hillsdale: Erlbaum.
Brown, R. G., & Marsden, C. D. (1988). Internal versus external cures and the control of attention in Parkinson’s disease. Brain, 111, 323–345. doi:https://doi.org/10.1093/brain/111.2.323
Bruner, J. S., Goodnow, J. J., & Austin, G. A. (1956). A study of thinking. Oxford: Wiley.
Calabresi, P., Pisani, A., Centonze, D., & Bernardi, G. (1996). Role of Ca2 in striatal LTD and LTP. Seminars in the Neurosciences, 8, 321–328. doi:https://doi.org/10.1006/smns.1996.0039
Cerella, J. (1979). Visual classes and natural categories in the pigeon. Journal of Experimental Psychology: Human Perception and Performance, 5, 68–77. doi:https://doi.org/10.1037/0096-1523.5.1.68
Cook, R. G., & Smith, J. D. (2006). Stages of abstraction and exemplar memorization in pigeons’ category learning. Psychological Science, 17, 1059–1067. doi:https://doi.org/10.1111/j.1467-9280.2006.01833.x
Cools, A. R., van den Bercken, J. H., Horstink, M. W., van Spaendonck, K. P., & Berger, H. J. (1984). Cognitive and motor shifting aptitude disorder in Parkinson’s disease. Journal of Neurological and Neurosurgical Psychology, 47, 443–453. Retrieved from http://jnnp.bmj.com/content/jnnp/47/5/443.full.pdf
Divac, I., Rosvold, H. E., & Szwarcbart, M. K. (1967). Behavioral effects of selective ablation of the caudate nucleus. Journal of Comparative and Physiological Psychology, 63, 184–190. doi:https://doi.org/10.1037/h0024348
Eacott, M. J., & Gaffan, D. (1992). Inferotemporal-frontal disconnection: The uncinate fascicle and visual associative learning in monkeys. European Journal of Neuroscience, 4, 1320–1332. doi:https://doi.org/10.1111/j.1460-9568.1992.tb00157.x
Elliott, R., & Dolan, R. J. (1998). Activation of different anterior cingulate foci in association with hypothesis testing and response selection. NeuroImage, 8, 17–29. doi:https://doi.org/10.1006/nimg.1998.0344
Erickson, M. A., & Kruschke, J. K. (1998). Rules and exemplars in category learning. Journal of Experimental Psychology: General, 127, 107–140. doi:https://doi.org/10.1037//0096-3445.127.2.107
Feldman, J. (2000). Minimization of Boolean complexity in human concept learning. Nature, 407, 630–633. doi:https://doi.org/10.1038/35036586
Filoteo, J. V., Maddox, W. T., Salmon, D. P., & Song, D. D. (2005). Information-integration category learning in patients with striatal dysfunction. Neuropsychology, 19, 212–222. doi:https://doi.org/10.1037/0894-4105.19.2.212
Fukunaga, K. (1972). Introduction to statistical pattern recognition. New York: Academic Press.
Fuster, J. M. (1989). The prefrontal cortex, (2nd ed.). Philadelphia: Lippincott-Raven.
Gaffan, D., & Eacott, M. J. (1995). Visual learning for an auditory secondary reinforcer by macaques is intact after uncinate fascicle section: Indirect evidence for the involvement of the corpus striatum. European Journal of Neuroscience, 7, 1866–1871. doi:https://doi.org/10.1111/j.1460-9568.1995.tb00707.x
Gaffan, D., & Harrison, S. (1987). Amygdalectomy and disconnection in visual learning for auditory secondary reinforcement by monkeys. Journal of Neuroscience, 7, 2285–2292. Retrieved from www.jneurosci.org/content/7/8/2285
Goldman-Rakic, P. S. (1987). Circuitry of the prefrontal cortex and the regulation of behavior by representational knowledge. In F. Plum & V. Mountcastle (Eds.), Handbook of physiology (pp. 373–417). Bethesda: American Physiological Society.
Han, C. J., O’Tuathaigh, C. M., van Trigt, L., Quinn, J. J., Fanselow, M. S., Mongeau, R., …, Anderson, D. J. (2003). Trace but not delay fear conditioning requires attention and the anterior cingulate cortex. Proceedings of the National Academy of Sciences of the United States of America, 100, 13087–13092. doi:https://doi.org/10.1073/pnas.2132313100
Herrnstein, R. J., Loveland, D. H., & Cable, C. (1976). Natural concepts in pigeons. Journal of Experimental Psychology: Animal Behavioral Processes, 2, 285–302. doi:https://doi.org/10.1037/0097-7403.2.4.285
Hollerman, J. R., & Schultz, W. (1998). Dopamine neurons report an error in the temporal prediction of reward during learning. Nature Neuroscience, 1, 304–309. doi:https://doi.org/10.1038/1124
Homa, D., Sterling, S., & Trepel, L. (1981). Limitations of exemplar-based generalization and the abstraction of categorical information. Journal of Experimental Psychology: Human Learning and Memory, 7, 418–439. doi:https://doi.org/10.1037/0278-7393.7.6.418
Knowlton, B. J., Mangels, J. A., & Squire, L. R. (1996). A neostriatal habit learning system in humans. Science, 273, 1399–1402. doi:https://doi.org/10.1126/science.273.5280.1399
Knowlton, B. J., & Squire, L. R. (1993). The learning of categories: Parallel memory systems for item memory and category-level knowledge. Science, 262, 1747–1749. doi:https://doi.org/10.1126/science.8259522
Kolb, B., & Whishaw, I. Q. (1990). Fundamentals of human neuropsychology (3rd ed.). New York: Freeman.
Konorski, J. (1967). Integrative activity of the brain. Chicago: University of Chicago Press.
Kryukov, V. I. (2012). Towards a unified model of Pavlovian conditioning: Short review. Cognitive Neuroscience, 6, 377–398. doi:https://doi.org/10.1007/s11571-012-9195-z
Maddox, W. T., & Ashby, F. G. (1993). Comparing decision bound and exemplar models of categorization. Perception & Psychophysics, 53, 49–70. doi:https://doi.org/10.3758/BF03211715
Maddox, W. T., & Ashby, F. G. (2004). Dissociating explicit and procedural-learning based systems of perceptual category learning. Behavioural Processes, 66, 309–332. doi:https://doi.org/10.1016/j.beproc.2004.03.011
Maddox, W. T., Ashby, F. G., & Bohil, C. J. (2003). Delayed feedback effects on rule-based and information-integration category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 650–662. doi:https://doi.org/10.1037/0278-7393.29.4.650
Maddox, W. T., & Ing, A. D. (2005). Delayed feedback disrupts the procedural-learning system but not the hypothesis testing system in perceptual category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 100–107. doi:https://doi.org/10.1037/0278-7393.31.1.100
McDonald, R. J., & White, N. M. (1993). A triple dissociation of memory systems: Hippocampus, amygdala, and dorsal striatum. Behavioral Neuroscience, 107, 3–22. doi:https://doi.org/10.1037/0735-7044.107.1.3
McDonald, R. J., & White, N. M. (1994). Parallel information processing in the water maze: Evidence for independent memory systems involving dorsal striatum and hippocampus. Behavioral and Neural Biology, 61, 260–270. doi:https://doi.org/10.1016/S0163-1047(05)80009-3
Medin, D. L. (1975). A theory of context in discrimination learning. In G. Bower (Ed.), The psychology of learning and motivation (Vol. 9, pp. 263–314). New York: Academic Press.
Medin, D. L., & Schaffer, M. M. (1978). Context theory of classification learning. Psychological Review, 85, 207–238. doi:https://doi.org/10.1037/0033-295X.85.3.207
Minda, J. P., & Smith, J. D. (2001). Prototypes in category learning: The effects of category size, category structure, and stimulus complexity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 775–799. doi:https://doi.org/10.1037/0278-7393.27.3.775
Mishkin, M., Malamut, B., & Bachevalier, J. (1984). Memories and habits: Two neural systems. In G. Lynch, J. L. McGaugh, & N. M. Weinberger (Eds.), Neurobiology of human learning and memory (pp. 65–88). New York: Guilford Press.
Murphy, G. L. (2003). The big book of concepts. Cambridge: MIT Press.
Nairne, J. S. (1990). A feature model of immediate memory. Memory & Cognition, 18, 251–269. doi:https://doi.org/10.3758/BF03213879
Nomura, E. M., Maddox, W. T., Filoteo, J. V., Ing, A. D., Gitelman, D. R., Parrish, T. B., … Reber, P. J. (2007). Neural correlates of rule-based and information-integration visual category learning. Cerebral Cortex, 17, 37–43. doi:https://doi.org/10.1093/cercor/bhj122
Nosofsky, R. M. (1987). Attention and learning processes in the identification and categorization of integral stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13, 87–108. doi:https://doi.org/10.1037/0278-7393.13.1.87
Nosofsky, R. M., & Johansen, M. K. (2000). Exemplar-based accounts of multiple-system phenomena in perceptual categorization. Psychonomic Bulletin & Review, 7, 375–402. Retrieved from http://psiexp.ss.uci.edu/research/teaching/Nosofsky_Johansen_2000.pdf
Nosofsky, R. M., & Kruschke, J. K. (2002). Single-system models and interference in category learning: Commentary on Waldron and Ashby (2001). Psychonomic Bulletin & Review, 9, 169–174. doi:https://doi.org/10.3758/BF03196274
Nosofsky, R. M., Little, D. R., Donkin, C., & Fific, M. (2011). Short-term memory scanning viewed as exemplar-based categorization. Psychological Review, 118, 280–315. doi:https://doi.org/10.1037/a0022494
O’Doherty, J., Dayan, P., Schultz, J., Deichmann, R., Friston, K., & Dolan, R. J. (2004, April 16). Dissociable roles of ventral and dorsal striatum in instrumental conditioning. Science, 304, 452–454. doi:https://doi.org/10.1126/science.1094285
Packard, M. G., Hirsh, R., & White, N. M. (1989). Differential effects of fornix and caudate nucleus lesions on two radial maze tasks: Evidence for multiple memory systems. Journal of Neuroscience, 9, 1465–1472. Retrieved from www.jneurosci.org/content/jneuro/9/5/1465
Packard, M. G., & McGaugh, J. L. (1992). Double dissociation of fornix and caudate nucleus lesions on acquisition of two water maze tasks: Further evidence for multiple memory systems. Behavioral Neuroscience, 106, 439–446. doi:https://doi.org/10.1037/0735-7044.106.3.439
Pavlov, I. P. (1927). Conditioned reflexes: An investigation of the physiological activity of the cerebral cortex. London: Oxford University Press.
Pearce, J. M. (1994). Discrimination and categorization: Animal learning and cognition. In N. J. Mackintosh (Ed.), Handbook of perception and cognition series (2nd ed., Vol 18, pp. 109–134). San Diego: Academic Press.
Posner, M. I., & Petersen, S. E. (1990). Attention systems in the human brain. Annual Review of Neuroscience, 13, 25–42.
Pylyshyn, Z. W. (1973). What the mind’s eye tells the mind’s brain: A critique of mental imagery. Psychology Bulletin, 80, 1–24. doi:https://doi.org/10.1037/h0034650
Rao, S. M., Bobholz, J. A., Hammeke, T. A., Rosen, A. C., Woodley, S. J., Cunningham, J. M., … Binder, J. R. (1997). Functional MRI evidence for subcortical participation in conceptual reasoning skills. NeuroReport, 27, 1987–1993. doi:https://doi.org/10.1097/00001756-199705260-00038
Raybuck, J. D., & Lattal, K. M. (2014). Bridging the interval: Theory and neurobiology of trace conditioning. Behavioral Processes, 101, 103–111. doi:https://doi.org/10.1016/j.beproc.2013.08.016
Reed, S. K. (1978). Category vs. item learning: Implications for categorization models. Memory & Cognition, 6, 612–621. doi:https://doi.org/10.3758/BF03198251
Robinson, A. L., Heaton, R. K., Lehman, R. A. W., & Stilson, D. W. (1980). The utility of the Wisconsin Card Sorting Test in detecting and localizing frontal lobe lesions. Journal of Consulting and Clinical Psychology, 48, 605–614. doi:https://doi.org/10.1037/0022-006X.48.5.605
Rolls, E. T. (1994). Neurophysiology and cognitive functions of the striatum. Revue Neurologique, 150, 648–660.
Rosch, E., & Mervis, C. B. (1975). Family resemblances: Studies in the internal structure of categories. Cognitive Psychology, 7, 573–605. doi:https://doi.org/10.1016/0010-0285(75)90024-9
Rosseel, Y. (2002). Mixture models of categorization. Journal of Mathematical Psychology, 46, 178–210. doi:https://doi.org/10.1006/jmps.2001.1379
Schultz, W. (1992). Activity of dopamine neurons in the behaving primate. Seminars in Neuroscience, 4, 129–138. doi:https://doi.org/10.1016/1044-5765(92)90011-P
Schwarz, G. (1978). Estimating the dimension of a model. Annals of Statistics, 6, 461–464. doi:https://doi.org/10.1214/aos/1176344136
Seger, C. A., & Cincotta, C. M. (2005). The roles of the caudate nucleus in human classification learning. Journal of Neuroscience, 25, 2941–2951. doi:https://doi.org/10.1523/JNEUROSCI.3401-04.2005
Smith, J. D., Ashby, F. G., Berg, M. E., Murphy, M. S., Spiering, B., Cook, R. G., & Grace, R. C. (2011). Pigeons’ categorization may be exclusively nonanalytic. Psychonomic Bulletin & Review, 18, 414–421. doi:https://doi.org/10.3758/s13423-010-0047-8
Smith, J. D., Beran, M. J., Crossley, M. J., Boomer, J., & Ashby, F. G. (2010). Implicit and explicit category learning by macaques (Macaca mulatta) and humans (Homo sapiens). Journal of Experimental Psychology: Animal Behavior Processes, 36, 54–65. doi:https://doi.org/10.1037/a0015892
Smith, J. D., Boomer, J., Zakrzewski, A. C., Roeder, J. L., Church, B. A., & Ashby, F. G. (2014). Deferred feedback sharply dissociates implicit and explicit category learning. Psychological Science, 25, 447–457. doi:https://doi.org/10.1177/0956797613509112
Smith, J. D., Chapman, W. P., & Redford, J. S. (2010). Stages of category learning in monkeys (Macaca mulatta) and humans (Homo sapiens). Journal of Experimental Psychology: Animal Behavior Processes, 36, 39–53. doi:https://doi.org/10.1037/a0016573
Smith, J. D., & Church, B. A. (2017). Dissociable learning processes in comparative psychology. Psychonomic Bulletin and Review. Advance online publication. doi:https://doi.org/10.3758/s13423-017-1353-1
Smith, J. D., Coutinho, M. V. C., & Couchman, J. J. (2011). The learning of exclusive-or categories by monkeys (Macaca mulatta) and humans (Homo sapiens). Journal of Experimental Psychology: Animal Behavior Processes, 37, 20–29. doi:https://doi.org/10.1037/a0019497
Smith, J. D., & Minda, J. P. (1998). Prototypes in the mist: The early epochs of category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 1411–1436. doi:https://doi.org/10.1037/0278-7393.24.6.1411
Smith, J. D., Murray, M. J., Jr., & Minda, J. P. (1997). Straight talk about linear separability. Journal of Experimental Psychology: Learning, Memory, & Cognition, 23, 659–680. doi:https://doi.org/10.1037/0278-7393.23.3.659
Smith, J. D., Redford, J. S., & Haas, S. M. (2008). Prototype abstraction by monkeys (Macaca mulatta). Journal of Experimental Psychology: General, 137, 390–401. doi:https://doi.org/10.1037/0096-3445.137.2.390
Smith, J. D., Zakrzewski, A. C., Johnson, J. M., & Valleau, J. C. (2016). Ecology, fitness, evolution: New perspectives on categorization. Current Directions in Psychological Science, 25, 266–274. doi:https://doi.org/10.1177/0963721416652393
Thorndike, E. L. (1911). Animal intelligence. New York: Macmillan.
Waldschmidt, J. G., & Ashby, F. G. (2011). Cortical and striatal contributions to automaticity in information-integration categorization. NeuroImage, 56, 1791–1802. doi:https://doi.org/10.1016/j.neuroimage.2011.02.011
Wasserman, E. A., Kiedinger, R. E., & Bhatt, R. S. (1988). Conceptual behavior in pigeons: Categories, subcategories, and pseudocategories. Journal of Experimental Psychology: Animal Behavior Processes, 14, 235–246. doi:https://doi.org/10.1037/0097-7403.14.3.235
Wickens, J. (1993). A theory of the striatum. New York: Pergamon Press.
Yagishita, S., Hayashi-Takagi, A., Ellis-Davies, G. C., Urakubo, H., Ishii, S., & Kasai, H. (2014). A critical time window for dopamine actions on the structural plasticity of dendritic spines. Science, 345, 1616–1620. doi:https://doi.org/10.1126/science.1255514
Yin, H. H., Ostlund, S. B., Knowlton, B. J., & Balleine, B. W. (2005). The role of the dorsomedial striatum in instrumental conditioning. European Journal of Neuroscience, 22, 513–523. doi:https://doi.org/10.1111/j.1460-9568.2005.04218.x
Author note
The preparation of this article was supported by Grants HD-060563 and HD-061455 from NICHD, and Grant BCS-0956993 from the National Science Foundation. We want to thank the research assistants in the Complex Cognition Lab at Georgia State University for their help with data collection. Original data and code is available upon request from the first author.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Smith, J.D., Jamani, S., Boomer, J. et al. One-back reinforcement dissociates implicit-procedural and explicit-declarative category learning. Mem Cogn 46, 261–273 (2018). https://doi.org/10.3758/s13421-017-0762-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-017-0762-8