
Abstract
We report an extension of the procedure devised by Weinstein and Shanks (Memory & Cognition 36:1415–1428, 2008) to study false recognition and priming of pictures. Participants viewed scenes with multiple embedded objects (seen items), then studied the names of these objects and the names of other objects (read items). Finally, participants completed a combined direct (recognition) and indirect (identification) memory test that included seen items, read items, and new items. In the direct test, participants recognized pictures of seen and read items more often than new pictures. In the indirect test, participants’ speed at identifying those same pictures was improved for pictures that they had actually studied, and also for falsely recognized pictures whose names they had read. These data provide new evidence that a false-memory induction procedure can elicit memory-like representations that are difficult to distinguish from “true” memories of studied pictures.
Similar content being viewed by others
Plenty of evidence exists that people can be induced to recognize pictures that they have never seen before (e.g., Fazendeiro, Winkielman, Luo, & Lorah, 2005; Hintzman, 1988; Israel & Schacter, 1997; Koutstaal, Verfaellie, & Schacter, 2001; Weinstein & Shanks, 2008, 2010). A question that intrigues many researchers, though, is to what extent this false recognition can be distinguished from true recognition (Schacter & Slotnick, 2004; Stark, Okado, & Loftus, 2010). The question is somewhat complicated by the fact that participants in such studies make recognition errors for multiple reasons. People might, for instance, falsely believe that they saw pictures of unseen items that are perceptually or conceptually related to items that they did see (e.g., Henkel & Franklin, 1998; Koutstaal et al., 2001). Alternatively, they might falsely recognize pictures after being exposed to the names of the pictures (e.g., Weinstein & Shanks, 2008, 2010). In the present study we asked are certain types of false recognition easier than others to discriminate from true recognition?
Attempts have been made to answer this question by examining participants’ introspections regarding the perceptual qualities of true and false memories, either with verbal reports (e.g., Heaps & Nash, 2001; Lampinen, Odegard, & Bullington, 2003; Norman & Schacter, 1997; Schooler, Gerhard, & Loftus, 1986) or rating scales (e.g., Johnson, Suengas, Foley, & Raye, 1988; Mather, Henkel, & Johnson, 1997). Although the results have been mixed, the phenomenological differences between true and false memories appear to be quite subtle. One arguably more sensitive method by which researchers have examined the similarities and differences between true and false recognition is with indirect memory tests.
In a typical perceptual indirect test, participants might be timed as they try to identify stimuli that are revealed incrementally (e.g., Feustel, Shiffrin, & Salasoo, 1983; Stark & McClelland, 2000). These studies consistently show that people can identify stimuli more quickly if they have seen them before (commonly referred to as a priming effect; Jacoby & Dallas, 1981). The types of indirect tests that we are interested in are thus designed to be highly sensitive to the presence of perceptual memory traces; indeed, a change from verbal stimuli in the study phase to pictorial stimuli in the test phase typically eliminates perceptual priming (Hirshman, Snodgrass, Mindes, & Feenan, 1990; Scarborough, Gerard, & Cortese, 1979; Weldon, Roediger, Beitel, & Johnston, 1995). However, some studies have shown that just like genuine memories, false “memories” also display perceptual priming effects. For example, using a word-stem completion task to test memory indirectly, McDermott (1997) found perceptual priming of words that participants had genuinely studied in the experiment, but also of unstudied words that were strongly associated with studied words. Similarly, Gottesman (2011) had participants view objects in scenes and then take a perceptual implicit test that involved judging the distance between two objects. Performance on this task is usually primed by prior perception of the scene, but in this new version of the paradigm, even partial scenes—which excluded the target items—primed responses when the unseen parts of the scene could be easily imagined. In addition, Kherif, Josse, and Price (2011) demonstrated that the left ventral occipito-temporal cortex shows priming effects regardless of visual form (word or picture). More numerous than these studies of perceptual priming, though, are studies that find conceptual priming of unstudied stimuli (e.g., Friese, Supp, Hipp, Engel, & Gruber, 2012; Horner & Henson, 2011)—that is, in which the priming test taps into an item’s meaning rather than its visual or auditory qualities. Findings such as these have led many researchers to conclude that true and false recognition might be based on memory traces with similar perceptual and/or conceptual qualities.
Arguments that the characteristics of false memories can mirror those of true memories are consistent with the predictions of the source monitoring framework (SMF; Johnson, Hashtroudi, & Lindsay, 1993). Source monitoring accounts have been used to explain a variety of memory errors, such as the apparent suggestibility of eyewitness testimony (Lindsay & Johnson, 1989). In particular, the SMF posits that elaborating on internally generated mental images can make them increasingly “memory-like,” and can create confusions between observed and imagined events (e.g., Dodson & Johnson, 1993; Intraub & Hoffman, 1992). Research on source monitoring has demonstrated that false memories do indeed seem to acquire details such as location, shape, and color (e.g., Lampinen, Meier, Arnal, & Leding, 2005; Lyle & Johnson, 2006). These imported details, we might predict, could produce perceptual priming of unseen pictures on an indirect memory test, which would make it difficult to discriminate true from false memories.
One recent study, though, appears to suggest that visual false memories are not accompanied by priming effects as true memories are. In Weinstein and Shanks’s (2008) procedure, participants first studied a set of pictures, then studied a set of words, most of which were the names of objects that they had studied as pictures, but some of which named objects from the same thematic categories as the studied items (e.g., fruit, clothing) but that had not been studied. Subsequently, participants took a combined direct and indirect memory test in which they (1) identified pictures that were gradually revealed, and (2) judged whether they recognized those pictures from the first phase. Some pictures in this test had indeed been shown in the first phase, but the test also included pictures of thematically related objects whose names participants had only read, and new pictures from the same thematic categories. Weinstein and Shanks (2008) found that studying object names increased false alarms on the (direct) recognition test, but did not produce perceptual priming on the (indirect) identification test. This finding led the authors to conclude that false recognition of pictures is not accompanied by facilitation of object identification, in the way that true recognition is. These findings therefore suggest that false recognition of visual stimuli is not based on perceptual memory traces, and that true and false recognition can thus be discriminated on the basis of indirect perceptual memory tests.
Weinstein and Shanks’s (2008) findings seem at odds with predictions of the source monitoring framework, which posits that false memories can acquire perceptual details. However, their data may have been insensitive to priming effects associated with false recognition, for the following reason: Priming should only reasonably occur for pictures that are actually recognized, not for every picture. This statement can apply to both true and false memory. To illustrate: Studying a picture should elicit both correct recognition and priming on a subsequent test. Yet if, for example, the participant looked away when a particular picture was presented, he or she of course should not recognize that picture. Rather, he or she should call that picture “new” during the subsequent recognition test, and we would not expect any facilitation (i.e., priming) when that picture was identified. This same logic also applies to items presented as words during the false-memory induction. For these “read” items, we might predict priming effects for items that were falsely recognized as “old” (i.e., items for which a false memory was formed), but we would not expect to see priming for pictures that were correctly called “new” (i.e., items for which a false memory was not formed). Thus, in order to measure priming for falsely recognized pictures, we would need to conditionalize our reaction time (RT) analyses by recognition response. In Weinstein and Shanks (2008), priming was measured only by item status (pictures whose names were studied, as compared to new pictures) and was not conditionalized by recognition response because of insufficient observations in each cell of the Recognition Response × Item Status interaction.
In this study, we sought to replicate and expand Weinstein and Shanks’s (2008) procedure to allow for sufficient statistical power to analyze identification priming of falsely recognized items. We compared the identification RTs for true recognition to RTs for the two types of false recognition that Weinstein and Shanks’s (2008) procedure elicits: (1) false recognition of pictures that are thematically related to pictures that were truly seen (new pictures) and (2) false recognition of thematically related pictures whose names were also studied (read pictures). We predicted that exposure to picture names would promote false recognition, but more crucially, that this extra exposure would facilitate identification and thus make performance on the indirect test more similar to that of true recognition. Previous research has found that false memories can contain the kinds of details usually associated with true memories; here, we asked whether these properties of false memories can be detected on an indirect test.
Experiment 1
The experiments in this article are similar in design to those described by Weinstein and Shanks (2008), with a three-phase procedure comprising a study phase, false-memory induction, and a test phase. In the present study, we wanted participants to falsely recognize a reasonable number of new pictures, so that identification latencies for these items could be compared to those of items presented in our false-memory induction. Therefore, unlike in Weinstein and Shanks (2008), participants in the present study saw picture stimuli in the context of naturalistic scenes, each of which contained multiple objects with thematic associations. This scene context, we predicted, should increase participants’ tendency to falsely recognize entirely new pictures, as well as increasing ecological validity. Previous studies have used objects in scenes as stimuli to investigate both false recognition (e.g., Miller & Gazzaniga, 1998) and perceptual priming (e.g., VanRullen & Koch, 2003), but none to date have studied these direct and indirect measures together within the context of visual scenes.
Method
Participants and design
A group of 30 Washington University undergraduates participated for course credit. The participants were randomly assigned to one of three counterbalancing conditions. We used a repeated measures design with item type (seen/read/new) as the only manipulated variable; the dependent measures were accuracy on the recognition test and RTs to identify pictures.
Materials
We assembled a stimulus set of 144 color photographs of objects taken primarily from the database created by VanRullen and Koch (2003), but supplemented with images obtained from the Internet. For Experiment 1, only 110 of these pictures were used. Pictures were selected that fit into one of five categories: animals, clothes, electrical appliances, fruits and vegetables, and household objects (plus a sixth category—furniture—that was used in Exp. 2).
We then sourced five “scene” photographs from the Internet, to provide a context for the individual objects. For example, for the “fruits and vegetables” scene, we selected a picture of an empty refrigerator. Using Adobe Photoshop, we created naturalistic scenes by superimposing object pictures onto the relevant background image (Fig. 1 shows an example scene; lists of the objects in each scene can be obtained from the corresponding author). We created two different scenes for each of the five categories, each using the same background image but with a completely different set of embedded objects. For each of these ten scenes, we created three versions for counterbalancing, such that each critical item functioned equally often across participants as a seen item, a read item, and a new item. In each of these counterbalancing versions, seven of the nine objects remained constant (these were fillers), and the remaining two objects differed between versions.

Each participant saw all ten scenes during the study phase of the experiment, but only one version of each scene. Therefore, participants saw 20 critical items during the study phase (i.e., 2 items × 10 scenes). A further 20 critical items appeared as words in the false-memory induction phase that will be described shortly. A final 20 items did not appear until the test phase. The test phase consisted of all 60 critical items.
Procedure
The experiment comprised three phases: The study phase, in which participants viewed scenes; the false-memory induction phase, in which participants studied the names of objects; and the test phase, in which participants identified object pictures and indicated whether they recognized each object.
Study phase
During encoding, participants studied ten scenes (each containing nine items) for 15 s each. Participants were told that each scene would appear on the screen for 15 s, and that the next scene would appear automatically. They were told to study each scene carefully while it was on the screen, and to try to take in every object in the scene. A 5-min distractor task followed, during which participants performed multiplication problems.
False-memory induction phase
Participants were next told that they would be studying the names of objects that they had seen in the scenes. Seventy words appeared sequentially on the screen for 4 s each, and as an orientation task to ensure encoding, participants were asked to indicate the number of vowels in each word presented. In Weinstein and Shanks (2008, Exp. 4), very shallow processing of object words was sufficient to induce false recognition of pictures of those objects. Thus, we expected that vowel counting would similarly elicit false recognition.
Only 50 of the 70 words presented actually referred to objects that had appeared in the scenes, of which 20 were our critical “seen items” and 30 were fillers. The remaining 20 words referred to objects that had not appeared in the scenes, hereafter referred to as “read items.” To make room for the 20 read items, the names of 20 objects that did appear in the scenes were removed from the list; the same 20 words were removed for all participants. Participants made responses by pressing the numerical key corresponding to the number of vowels in each word.
Test phase
Immediately after the false-memory induction phase, participants were presented with pictures of the 60 critical objects sequentially, in a random order. Pictures of seen, imagined, and new objects were each presented in a 300 × 300 pixel square with a white background. The test combined both identification (indirect) and recognition (direct) components. On each trial, participants first attempted to identify a picture as it flashed briefly on the screen. The picture would appear repeatedly, followed immediately by a mask image (see Weinstein & Shanks, 2008, Fig. 1). Each time that the picture appeared, it remained on the screen for a slightly longer duration, whereas the mask followed for a shorter duration; each “picture–mask” presentation cycle spanned 250 ms. On the first cycle, the picture appeared for 16.7 ms (and the mask for 233.3 ms), and this duration increased by 16.7 ms on each presentation, for a total of 14 sequences (3,500 ms in total). Participants pressed “Enter” once they thought that they could identify the object pictured, at which point the picture disappeared, the RT was recorded, and participants typed the object’s name. After this identification—or after 3,500 ms, if participants did not press “Enter”—participants were again shown the object picture on the screen and were asked to indicate without a time limit whether the picture was “old” (i.e., was presented in the study phase) or “new” (i.e., was not presented in the study phase). Responses were made on a 6-point scale from 1 = very sure new to 6 = very sure old. This combined identification and recognition judgment process was repeated for each of the 60 test items.
Results
In the following analysis, we first examined whether the recognition and identification RT data in our scene paradigm replicated those of Weinstein and Shanks (2008), who presented objects in isolation. We then tested our prediction of priming on falsely recognized objects (i.e., pictures incorrectly called “old”). All analyses were significant to p < .05 unless otherwise stated.
Recognition
Following Weinstein and Shanks (2008), responses made on the 6-point scale were classified as “old” or “new” by binning responses 4 – 6 and 1 – 3, respectively. The first row of Table 1 displays the proportion of each item type called “old.” A repeated measures ANOVA on these data found a significant effect of item type, F(2, 58) = 125.16, η 2p = .81. Follow-up paired t tests revealed that the proportion of “hits” to seen items (M = .81, SD = .15) was significantly greater than the proportions of false alarms to read items (M = .35, SD = .18), t(29) = 12.52, d = 2.78, and to new items (M = .27, SD = .15) , t(29) = 13.34, d = 3.61. As we had hoped, the false alarm rate to new items here was considerably higher than that in Weinstein and Shanks (2008; M = .11 across their Exps. 1–3), perhaps due to the context provided by presenting the objects in scenes. Of primary importance was that false alarms to read items were significantly more frequent than were false alarms to new objects, t(29) = 2.37, d = 0.47. In other words, counting the vowels in an object word increased the likelihood of participants falsely recognizing a picture of that object.
Identification
We next analyzed the identification RTs, excluding individual response data for trials that met any of three criteria: (1) the picture was identified incorrectly; (2) identification times were less than 250 ms (i.e., the duration of one picture/mask cycle); and (3) identification times were over 3,500 ms, the entire duration of the identification cycle. For correct picture identification (Exclusion Criterion 1 above), participants had to produce an object name that was sufficiently similar to the depicted object, with misspellings and variants (e.g., “dictionary” instead of “book”) accepted as correct. These three exclusion criteria resulted in the exclusion of 3.7 % of the data points. In the analyses of identification data that follow, we calculated each participant’s median RT for each cell of the experimental design; descriptive and inferential statistics are therefore based on the means of these individual participant-by-condition medians (i.e., the medians averaged across participants). The first row of Table 2 shows RT data for each item type, and a repeated measures ANOVA on these data was significant, F(2, 58) = 7.23, η 2p = .20. Paired-sample t tests showed that seen items (M = 1,320 ms, SD = 242) were identified faster than both read items (M = 1,383 ms, SD = 293), t(29) = 2.47, d = 0.23, and new items (M = 1,415 ms, SD = 301), t(29) = 3.75, d = 0.35. Replicating Weinstein and Shanks’s (2008) results, the difference between identification RTs for read and new pictures did not approach significance, t(29) = 1.26, p = .22, d = 0.11.
Identification RTs for falsely recognized pictures
Our indirect-test results so far replicated those of Weinstein and Shanks (2008) and suggested that studying the name of an object promoted false recognition but did not prime identification. However, as we outlined above, it is possible that we might only detect a significant priming effect when we focused solely on the RT data for items that were judged (correctly or incorrectly) to be “old.”
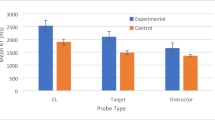
We therefore conducted a repeated measures ANOVA on participants’ RT data for pictures that they called “old.” We excluded the data of one participant who did not respond “old” to at least one picture of each item type (this participant did not respond “old” to any read items). As the left half of Fig. 2 illustrates, this ANOVA revealed significant differences in RTs between item types, F(2, 56) = 8.56, η 2p = .23. Seen items were identified faster than new items, t(28) = 3.15, d = 0.59, but read items, too, were identified faster than new items, t(28) = 3.06, d = 0.57. In other words, there did appear to be a priming effect for read pictures that were falsely identified as “old,” as compared with new pictures that were falsely identified as “old.” Interestingly, RTs for read items called “old” were not significantly greater than RTs for correctly identified seen items, t(28) = 0.55, p = .59; that is, this type of false recognition was impossible to discriminate from true recognition on this implicit test. This analysis thus provides support for the claim that false recognition memory can indeed prime identification.

Identification reaction times (RTs) for pictures that participants classified as “old” in Experiments 1 and 2. The median RT was obtained for each participant/condition, and means of these medians were computed to produce the data points in the figure. Note that this figure represents data from only the participants who recognized at least one picture (Exp. 1) or four pictures (Exp. 2) of each item type. Error bars represent standard errors of the means
An alternative explanation of these findings depends not on the presence of a particular type of memory, but on the mental availability of object words. According to this interpretation, RTs for read items might be faster not because of any visual memory representation for those items, but because seeing an object’s name makes that name come to participants’ minds more readily when the object is shown later on. This is a reasonable account, but one that does not seem to fit our data. If this account were correct, we should expect to see read items being identified faster than new items, irrespective of whether they were called “old” or “new.” However, this was not the case: We saw no systematic differences in identification RTs for items called “new” as a function of item type (seen, M = 1,384 ms, SD = 399; read, M = 1,426 ms, SD = 326; new, M = 1,409 ms, SD = 316), F(2, 50) = 0.33, p = .72. Note that for the analysis on items called “new,” we had to exclude four participants who did not have at least one “new” response for each of the three item types (all four of these participants did not respond “new” to any of the seen items). We also repeated the analysis for items called “old” on this reduced sample (n = 26), and found the same results to those reported above (for the n = 29 sample)Footnote 1.
Experiment 2
In Experiment 1, our false-memory induction increased false recognition but did not prime identification of pictures. In this respect, our results replicate those of Weinstein and Shanks (2008). Extending Weinstein and Shanks’s (2008) findings, though, we did observe a priming effect when our analysis was narrowed only to those items judged to be “old.” This finding raises the interesting possibility that a priming effect does occur for pictures of objects that are falsely recognized after their names are read. To test the reliability of this priming result, in Experiment 2 we replicated Experiment 1, including a greater number of critical items and participants.
Method
Participants and design
A group of 55 Washington University undergraduates participated and received course credit. One participant’s data were excluded from analysis because the participant did not understand the identification task. The design and dependent measures were identical to those of Experiment 1.
Materials
The full set of 144 object pictures described in the Materials section of Experiment 1 was used in this experiment, with the picture categories supplemented with a furniture category. For each of the six scenes, we superimposed eight object pictures onto the relevant background. The main difference from Experiment 1 was that in these scenes, all eight items were “critical”; that is, there were no filler items. Three versions of each scene were created for counterbalancing, and because all items were critical, each of these versions contained a completely different set of eight objects. As in Experiment 1, each critical item functioned equally often across participants as a seen item, a read item, and a new item.
Procedure
For the critical manipulation, all 144 items (24 items × 6 categories) served as critical items. Of these, 48 items appeared in the scenes that participants viewed during the study phase—that is, 8 objects × 6 scenes (seen items); 48 items appeared as words in the false-memory induction phase (read items); and 48 did not appear until the test phase (new items). The test phase consisted of all 144 items. The three phases were otherwise identical to those of Experiment 1, except that the distractor task following the study phase was reduced to 2 min.
Results
Recognition
As in Experiment 1, responses made on the 6-point scale were classified as “old” or “new” by binning responses (4 – 6) and (1 – 3), respectively. The second row of Table 1 presents the proportion of each item type judged to be “old,” and a repeated measures ANOVA on these data revealed a significant main effect of item type, F(1.27, 67.5) = 397.7, η 2p = .88. Follow-up paired t tests showed that participants were more likely to give “old” responses to seen items (M = .79, SD = .15) than to read items (M = .26, SD = .16), t(53) = 18.90, d = 3.42, and to new items (M = .20, SD = .14), t(53) = 22.89, d = 4.07. Crucially, though, they were also more likely to give “old” responses to read items than to new items, t(53) = 4.81, d = 0.40. Replicating the results of Experiment 1, then, counting the vowels in object names in the false-memory induction phase significantly increased false recognition of pictures of those objects.
Identification
Before examining participants’ RT data, we excluded data points using the same criteria as in Experiment 1. This excluded 4.5 % of the data points. The second row of Table 2 shows the averaged median RTs for each item type; a repeated measures ANOVA revealed a significant main effect of item type, F(2, 106) = 28.7, η 2p = .35. Paired t tests showed that seen items (M = 1,268 ms, SD = 286) were identified faster on average than read items (M = 1,353 ms, SD = 241), t(53) = 4.69, d = 0.32, and new items (M = 1,386 ms, SD = 271), t(53) = 8.55, d = 0.42. However, unlike in Experiment 1 and the findings of Weinstein and Shanks (2008), read items were also identified significantly faster than new items, t(53) = 2.06, d = 0.13. The effect size of this comparison was similar to that of Experiment 1, suggesting that increasing the number of stimuli in each condition afforded us sufficient power in this version of the procedure to detect the underlying effect.
Identification RTs for falsely recognized pictures
As in Experiment 1, we conducted an additional analysis of participants’ RT data for items that they called “old.” However, because Experiment 2 was designed specifically to give us more observations in each cell of the design, we chose to exclude from this analysis any participants who failed to provide at least four “old” judgments per item type (as in Weinstein & Shanks, 2008, notes 1 – 3). Doing so left us with 39 participants’ data for analysis, which was still above the sample size used in Experiment 1.
As is illustrated in the right half of Fig. 2, when participants classified an item as “old,” there was a significant effect of item type on RTs, F(2, 76) = 23.77, η 2p = .39. Specifically, seen items were identified faster than new items, t(38) = 7.83, d = 0.63, but, of more importance, read items were also recognized faster than new items, t(38) = 3.19, d = 0.33. These results replicate those of Experiment 1 in showing that when participants falsely recognized pictures of objects, their identification of these items was significantly faster if they had encountered the object word than if they had not. However, unlike in Experiment 1, identification RTs for seen items correctly called “old” were significantly faster than were the RTs for falsely identified read items, t(38) = 3.37, d = 0.31. Again, there was no evidence that the identification priming for read items was driven by word availability rather than memory: No systematic RT differences emerged for items called “new” as a function of item type (seen, M = 1,380 ms, SD = 355; read, M = 1,370 ms, SD = 255; new, M = 1,391 ms, SD = 285), F(2, 90) = 0.26, p = .77. Note that the latter analysis was performed on the data from the 46 participants who had at least four “new” responses for each item type. We also repeated the analyses on the sample of participants who had at least four responses in both the “called old” and “called new” categories (n = 36), and obtained the same results.
Discussion
In two experiments, we showed that a simple procedure involving shallow (largely lexical) processing of object words promoted false recognition of pictures. More importantly, our indirect-test data showed that the false recognition induced by this procedure was accompanied by priming. Indirect memory tests represent one way of comparing the phenomenology of true and false memories, and our data resonate with those of studies that used direct measures—such as introspective reports (Heaps & Nash, 2001) and source attributions of perceptual features (Lyle & Johnson, 2007)—to demonstrate that the two can be equivalent. Our findings are on the whole consistent with Weinstein and Shanks (2008), and extend their findings to the more naturalistic context of visual scenes. Importantly, though, our analyses might reconcile Weinstein and Shanks’s (2008) data with those of studies from the source monitoring literature, as we will discuss shortly.
In both experiments, our perceptual identification task was highly effective at discriminating true recognition from pure associative false recognition: that is, false recognition of new items that were thematically related to the scene contexts. However, when thematically related items were presented to participants in word form during the false-memory induction, subsequent identification latencies for the pictures became faster and more similar to those for true recognition. Put differently, this shallow (largely lexical) processing of items made the indirect task a less useful method for distinguishing true from false recognition: In Experiment 1, there was no significant RT difference between these memories and true memories; in Experiment 2, there remained a significant difference, but it was small.
These findings seem to contradict Weinstein and Shanks’s (2008) conclusion that their participants’ false memories were not driven by perceptual representations. In fact, when the RT data were analyzed contingent on the recognition response, and with sufficient power, the indirect-test data were consistent with the hypothesis that perceptual detail does indeed accompany participants’ false memories. This finding is important, because it corroborates and extends numerous other studies that have investigated the presence of perceptual details in false memories using direct tests (e.g., Lampinen et al., 2005; Lyle & Johnson, 2006). For example, Lyle and Johnson’s (2006) participants saw objects displayed in different locations on a computer screen, and imagined others. The authors found that location information associated with viewed objects was misattributed at test to imagined objects that were perceptually similar (e.g., a cane and a crowbar, which are unrelated semantically but have a similar shape). The authors invoked a reactivation/misattribution process account to explain how imagined objects in their study acquired perceptual details (i.e., location information). According to their explanation, when an imagined object is presented at test, it reactivates a set of perceptual features that actually belong to a perceptually similar viewed object. The key feature (location) is then misattributed to the imagined object. In our study, a similar process may have occurred in the false-memory induction phase. That is, when a previously unseen object was named in the vowel-counting phase, it may have activated perceptual features associated with similar objects that had appeared in the scenes. Perceptual details of these seen objects could then become associated with the unseen object names. In addition to this specific feature importation process involving studied objects, the imagination process could also result in participants importing perceptual features from outside of the study context (Johnson et al., 1988). In the context of studies showing that imagination can result in false memories that are rich in perceptual qualities, our data suggest that the ease of detecting false memories might depend on the extent to which they have been elaborated on, with only minimal elaboration being necessary to make the discrimination task more difficult.
Two further points about our data are important to note. The first is that our results do not rule out the possibility of interdependence between recognition and priming. Participants could be using the ease of identification as a cue to recognition, thus increasing or even creating the relationship between the indirect and direct tests. That is, participants may have an awareness (conscious or otherwise) that previously seen objects would be easier to identify than those that they were seeing for the first time, so that a surprisingly fluent identification would increase the chance of making an “old” judgment on the recognition test. This possibility is supported by studies such as Johnston, Dark, and Jacoby (1985) that have linked fluency to recognition, and in fact this reliance on fluency is an inherent possibility in any recognition study, even one that does not include a separate object identification test. For this reason, we do not believe that the possibility of interdependence affects our claim that elaboration can lead to increased difficulty in distinguishing between true and false memories, as demonstrated by our two experiments.
The second point of note is that throughout this article, we have assumed that the indirect task that we used uniquely targets perceptual processes. This assumption is based on studies that have used a verbal version of the task (Feustel et al., 1983; Stark & McClelland, 2000) and found a lack of cross-form priming. These prior findings led us to argue specifically that perceptual, and not conceptual, information is acquired by false memories in our procedure. However, as this identification task has not been used with pictorial stimuli elsewhere, it is possible that this version of the task is also partially driven by conceptual processes. If this were the case, our results would fit with those of previous studies that have shown cross-form conceptual (or lexical) priming from object names to pictures (e.g., Durso & Johnson, 1979; Horner & Henson, 2011).
Our findings, in conjunction with the previous findings described above, have implications for attempts to distinguish true from false memories in behavioral and brain-imaging studies. The general proposal that elaboration increases the similarity between true and false memories is consistent with data from brain-imaging studies such as Garoff-Eaton, Slotnick, and Schacter (2006), who showed using fMRI that associative false memories had more neural commonalities with true memory than did nonassociative, spontaneous false memories. In the present study, we did not have a “control” condition measuring the false recognition of new items that were unrelated to the visual scenes; including such a condition would likely have required us to use many times more scenes and critical items in order to find sufficient false alarms to these “control” items. For this reason, we have no comparison against which to contrast the RT data for the new but still thematically related pictures. We are therefore unable to say whether—analogously to the semantic associates in McDermott’s (1997) study—the identification of falsely recognized “new” items in these studies might too have been primed, albeit to a lesser extent than the falsely recognized “read” items. Nevertheless, to our knowledge, these experiments provide the first evidence from an indirect task to show that shallow processing can increase the “memory-like” properties of false memories.
Notes
Although it may be tempting to compare RTs for items called “old” and those called “new,” we have avoided doing so due to a potential difference in baseline RTs for these item categories. That is, although the identification response always occurred before the recognition response, that does not necessarily mean that it was made independently of recognition. For example, when items seemed familiar to participants, they might have engaged in recollection during the identification process to determine the source of the familiarity, thus lengthening the identification RT. For this reason, we did not compare RTs for items called “old” with RTs for items called “new,” but instead compared RTs for different item types (seen/read/new) within each of the two types of responses.
References
Dodson, C. S., & Johnson, M. K. (1993). Rate of false source attributions depends on how questions are asked. The American Journal of Psychology, 106, 541–557.
Durso, F. T., & Johnson, M. K. (1979). Facilitation in naming and categorizing repeated pictures and words. Journal of Experimental Psychology: Human Learning and Memory, 5, 449–459.
Fazendeiro, T., Winkielman, P., Luo, C., & Lorah, C. (2005). False recognition across meaning, language, and stimulus format: Conceptual relatedness and the feeling of familiarity. Memory & Cognition, 33, 249–260. doi:10.3758/BF03195314
Feustel, T. C., Shiffrin, R. M., & Salasoo, A. (1983). Episodic and lexical contributions to the repetition effect in word identification. Journal of Experimental Psychology. General, 112, 309–346.
Friese, U., Supp, G. G., Hipp, J. F., Engel, A. K., & Gruber, T. (2012). Oscillatory MEG gamma band activity dissociates perceptual and conceptual aspects of visual object processing: A combined repetition/conceptual priming study. NeuroImage, 59, 861–871. doi:10.1016/j.neuroimage.2011.07.073
Garoff-Eaton, R. J., Slotnick, S. D., & Schacter, D. L. (2006). Not all false memories are created equal: The neural basis of false recognition. Cerebral Cortex, 16, 1645–1652.
Gottesman, C. V. (2011). Mental layout extrapolations prime spatial processing of scenes. Journal of Experimental Psychology. Human Perception and Performance, 37, 382–395.
Heaps, C. M., & Nash, M. (2001). Comparing recollective experience in true and false autobiographical memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 920–930.
Henkel, L. A., & Franklin, N. (1998). Reality monitoring of physically similar and conceptually related objects. Memory & Cognition, 26, 659–673.
Hintzman, D. L. (1988). Judgments of frequency and recognition memory in a multiple-trace memory model. Psychological Review, 95, 528–551. doi:10.1037/0033-295X.95.4.528
Hirshman, E., Snodgrass, J. G., Mindes, J., & Feenan, K. (1990). Conceptual priming in fragment completion. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 634–647.
Horner, A. J., & Henson, R. N. (2011). Stimulus–response bindings code both abstract and specific representations of stimuli: Evidence from a classification priming design that reverses multiple levels of response representations. Memory & Cognition, 39, 1457–1471.
Intraub, H., & Hoffman, J. E. C. (1992). Reading and visual memory: Remembering scenes that were never seen. The American Journal of Psychology, 105, 101–114.
Israel, L., & Schacter, D. L. (1997). Pictorial encoding reduces false recognition of semantic associates. Psychonomic Bulletin & Review, 4, 577–581. doi:10.3758/BF03214352
Jacoby, L. L., & Dallas, M. (1981). On the relationship between autobiographical memory and perceptual learning. Journal of Experimental Psychology. General, 110, 306–340. doi:10.1037/0096-3445.110.3.306
Johnson, M. K., Hashtroudi, S., & Lindsay, D. S. (1993). Source monitoring. Psychological Bulletin, 114, 3–28. doi:10.1037/0033-2909.114.1.3
Johnson, M. K., Suengas, A. G., Foley, M. A., & Raye, C. L. (1988). Phenomenal characteristics of memories for perceived and imagined autobiographical events. Journal of Experimental Psychology. General, 117, 371–376.
Johnston, W. A., Dark, V. J., & Jacoby, L. L. (1985). Perceptual fluency and recognition judgments. Journal of Experimental Psychology: Learning, Memory, and Cognition, 11, 3–11.
Kherif, F., Josse, G., & Price, C. J. (2011). Automatic top-down processing explains common left occipito-temporal responses to visual words and objects. Cerebral Cortex, 21, 103–114.
Koutstaal, W., Verfaellie, M., & Schacter, D. L. (2001). Recognizing identical versus similar categorically related common objects: Further evidence for degraded gist-representations in amnesia. Neuropsychology, 15, 268–289.
Lampinen, J. M., Meier, C. R., Arnal, J. D., & Leding, J. K. (2005). Compelling untruths: Content borrowing and vivid false memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 954–963. doi:10.1037/0278-7393.31.5.954
Lampinen, J. M., Odegard, T. N., & Bullington, J. L. (2003). Qualities of memories for performed and imagined actions. Applied Cognitive Psychology, 17, 881–893. doi:10.1002/acp. 916
Lindsay, D. S., & Johnson, M. K. (1989). The eyewitness suggestibility effect and memory for source. Memory & Cognition, 17, 349–358.
Lyle, K. B., & Johnson, M. K. (2006). Importing perceived features into false memories. Memory, 14, 197–213.
Lyle, K. B., & Johnson, M. K. (2007). Source misattributions may increase the accuracy of source judgments. Memory & Cognition, 35, 1024–1033.
Mather, M., Henkel, L. A., & Johnson, M. K. (1997). Evaluating characteristics of false memories: Remember/know judgments and memory characteristics questionnaire compared. Memory & Cognition, 25, 826–837.
McDermott, K. B. (1997). Priming on perceptual implicit memory tests can be achieved through presentation of associates. Psychonomic Bulletin & Review, 4, 582–586.
Miller, M. B., & Gazzaniga, M. S. (1998). Creating false memories for visual scenes. Neuropsychologia, 36, 513–520.
Norman, K. A., & Schacter, D. L. (1997). False recognition in younger and older adults: Exploring the characteristics of illusory memories. Memory & Cognition, 25, 838–848.
Scarborough, D. L., Gerard, L., & Cortese, C. (1979). Accessing lexical memory: The transfer of word repetition effects across task and modality. Memory & Cognition, 7, 3–12. doi:10.3758/BF03196928
Schacter, D. L., & Slotnick, S. D. (2004). The cognitive neuroscience of memory distortion. Neuron, 44, 1–20.
Schooler, J. W., Gerhard, D., & Loftus, E. F. (1986). Qualities of the unreal. Journal of Experimental Psychology: Learning, Memory, and Cognition, 12, 171–181.
Stark, C. E. L., & McClelland, J. L. (2000). Repetition priming of words, pseudowords, and nonwords. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 945–972.
Stark, C. E. L., Okado, Y., & Loftus, E. F. (2010). Imaging the reconstruction of true and false memories using sensory reactivation and the misinformation paradigms. Learning & Memory, 17, 485–488.
VanRullen, R., & Koch, C. (2003). Competition and selection during visual processing of natural scenes and objects. Journal of Vision, 3(1), 75–85. doi:10.1167/3.1.8
Weinstein, Y., & Shanks, D. R. (2008). Perceptual representations in false recognition and priming of pictures. Memory & Cognition, 36, 1415–1428. doi:10.3758/MC.36.8.1415
Weinstein, Y., & Shanks, D. R. (2010). Rapid induction of false memory for pictures. Memory, 18, 533–542.
Weldon, M. S., Roediger, H. L., III, Beitel, D. A., & Johnston, T. R. (1995). Perceptual and conceptual processes in implicit and explicit tests with picture fragment and word-fragment cues. Journal of Memory and Language, 34, 268–285.
Author note
We thank Keith B. Lyle, Marcia K. Johnson, and an anonymous reviewer for their very helpful comments on the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Weinstein, Y., Nash, R.A. False recognition of objects in visual scenes: Findings from a combined direct and indirect memory test. Mem Cogn 41, 60–68 (2013). https://doi.org/10.3758/s13421-012-0242-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-012-0242-0