
Abstract
The aim of the present study was to examine the anticipatory nature of pattern perception in sport by using static and moving basketball patterns across three different display types. Participants of differing skill levels were included in order to determine whether the effects would be moderated by the knowledge and experience of the observer in the same manner reported previously for simple images. The results from a pattern recognition task showed that both expert and recreational participants were more likely to anticipate the next likely state of a pattern when it was presented as a moving video, but only the experts appeared to have the depth of understanding required to elicit the same anticipatory encoding for patterns presented as schematic images. The results extend those reported in previous research and provide further evidence of an anticipatory encoding in pattern perception for images containing complex, interrelated patterns.
Similar content being viewed by others


The visual system has been shown to possess the capability to predict forthcoming events and fill the gaps in sensory data by adding information that has not yet been perceived but is nonetheless likely to occur (Didierjean & Marmèche, 2005; Freyd & Finke, 1984; Hubbard, 2005). For example, when observers are briefly shown a static image of a moving object and then asked to specify the object’s exact location after the image has been removed, the object is invariably misplaced and deemed to be farther along its trajectory than was actually shown (Finke, Freyd, & Shyi, 1986; Futterweit & Beilin, 1994). This extrapolation of the temporal features is typically referred to as “representational momentum” (Freyd, 1987; Freyd & Finke, 1984; Intraub, 2002). It has been suggested that this phenomenon occurs because observers anticipate the trajectory of the object and remember that object by integrating its predicted motion with perceptions of its implied acceleration and velocity (Didierjean & Marmèche, 2005; Finke et al., 1986).
This anticipatory process may also be moderated by the observer’s expectations, personal experience, and knowledge base. For example, studies have shown that knowledge of friction or gravity, or an understanding of the object’s conceptual context or specific features, can affect the mental representation of the object’s trajectory (Hubbard, 1994, 1995; Reed & Vinson, 1996; Vinson & Reed, 2002). Reed and Vinson found that the magnitude of the representational momentum effect was significantly greater when participants were shown diagrams of implied motion for a rocket rather than diagrams depicting implied motion for a church steeple. The researchers concluded that prior knowledge of the object’s typical movement properties was retrieved from long-term memory, which differentially influenced the participant’s expectations of the representational motion of the object. Other studies have shown that the effect is removed entirely if the observer cannot reasonably expect the object to continue moving along a relatively predictable pathway (Kerzel, 2002). These studies suggest that the observer must possess at least a basic understanding of the object’s previous movement characteristics, combined with a fundamental knowledge of the object’s typical physical properties, for representational momentum to occur.
A study by Didierjean and Marmèche (2005) further explored the mediating effects of knowledge by applying a pattern recognition paradigm using participants of varying skill levels from the sport of basketball. From the results of previous research (e.g., Freyd, 1983; Freyd & Finke, 1984; Reed & Vinson, 1996; Vinson & Reed, 2002), the authors predicted that individuals with extensive experience in the sport would be more likely to apply their knowledge of strategic expectations, and this would bias their perceptions of the image, causing them to encode the pattern with more anticipatory features. A short-term recognition task (Experiment 1) was used where participants of differing skill levels were shown pairs of schematic representations of basketball game patterns and asked to determine whether the second pattern was the same as or different from the first. It was predicted that the expert players would anticipate the temporal evolution of the first pattern in each pair and store this “next likely state” in memory, rather than the actual pattern that was presented. Therefore, when the second pattern in the pair was in fact the next likely state of the first, the experts would have greater difficulty in accurately differentiating between the two than when those same patterns were shown in the reverse order. The increased difficulty was expected to result in slower and less accurate responses, but only when the patterns were presented in the normal chronological order in which they would ordinarily occur in a game. The results supported these predictions and showed that expert players were slower and less accurate than lesser skilled players at differentiating the second configuration from the first, but only when the second configuration was the next likely state of the first, rather than a possible previous state. The opposite was observed for lesser skilled participants.
The study by Didierjean and Marmèche (2005) is one of the few to investigate the effects of an anticipatory encoding with complex patterns containing a number of interrelated elements. It also extends previous research by further highlighting the influence of expertise on representational momentum. The results suggest that expert knowledge contains information about the successive stages of a game and that this knowledge is utilised in the very early stages of visual perception (Didierjean & Marmèche, 2005). Thus, for an expert sports performer, who has developed a detailed understanding of the structures and patterns of play that typically occur in his or her domain of expertise, the ability to rapidly assess a visual display and make a predictive judgement as to what is likely to occur next may be significantly influenced by both the extent of their knowledge and the anticipatory nature of the memory trace.
One of the limitations of Didierjean and Marmèche’s (2005) study, and of a number of other studies investigating representational momentum (e.g., Freyd & Finke, 1984; Freyd & Pantzer, 1995; for an exception, see Thornton & Hayes, 2004), is the use of a static display to represent what would ordinarily be a more complex and dynamic environment. Schematic images may accurately represent the spatial locations of objects, but they remove, or at least severely diminish, many of the dynamic display features that are typically present in the natural setting. For example, research has shown that the effects of representational momentum can be reduced if the stimulus does not portray the necessary qualities of a moveable or animated object or creature (Freyd, 1992; Freyd & Miller, 1992; Hubbard, 2005; Nagai & Yagi, 2001; Reed & Vinson, 1996). Freyd and Miller found a greater forward displacement for a drawing of an abstract creature when the creature moved in the direction of its apparent head, as compared to when it moved in the opposite direction. Other studies have found inconsistent results concerning the extent of the forward displacement when objects are depicted as a static sketch or a computer-generated drawing (Freyd & Pantzer, 1995; Hubbard, 2005). Halpern and Kelly (1993) failed to find consistent differences in forward displacement between animate (i.e., a fox or rhinoceros) or inanimate (i.e., a truck or motorcycle) objects when both were depicted as static sketches. Thus, even though a static drawing can be used as a referent for an object, the perception of realistic motion is substantially reduced to a point where observers can sometimes have greater difficulty extracting reliable information to predict future motion (Hubbard, 2005).
Thornton and Hayes (2004) attempted to address this limitation by examining representational momentum in moving video scenes containing much richer displays that more closely replicated the typical features encountered in everyday situations. In a series of four experiments, participants were shown a moving image followed immediately by a probe image. The probe could be from an earlier or a later temporal location within the moving sequence, and participants were required to make a same–different judgement by indicating whether the probe image was the same as or different from the stopping point of the moving video. The results of all experiments showed that the forward shifts reported in previous research for static images were also observed for more complex, dynamic displays depicting realistic motion. Of particular relevance to the present study, the research also showed that a forward memory shift can occur even when observers are shown a real-world scene containing a number of unrelated individuals moving about in a relatively crowded environment (people moving in a department store, railway station, school entrance, or town square). These results extend previous research by showing that anticipation may be a general feature of visual perception that is not isolated to simple, static images, but instead occurs in everyday, real-world environments that are inherently dynamic (Freyd, 1987; Thornton & Hayes, 2004). Moreover, given that the participants were members of the general community, presumably with no specific level of expertise, the results suggest that even a basic understanding of the typical characteristics of human motion in a crowded environment is sufficient to induce a forward memory shift. A natural next step is to examine experienced individuals from a more specific domain to determine whether these results are moderated by the level of expertise of the observer, in the same manner shown in other research using simple images (e.g., Reed & Vinson, 1996).
Another avenue of investigation that has received limited attention in the literature is the notion of positive transfer of representational momentum in pattern perception (for an example of a study examining the transfer of representational momentum in automobile driving, see Blättler, Ferrari, Didierjean, van Elslande, & Marmèche, 2010). Studies have shown that some degree of pattern perception skill may transfer between sports that share similar organisational, structural, and tactical features (Abernethy, Baker, & Côté, 2005; Allard & Starkes, 1991). For example, Smeeton, Ward, and Williams (2004) used a recognition paradigm to investigate the transfer of pattern perception skills across soccer, field hockey, and volleyball players. Their methodology was similar to that of previous recognition studies, with participants from each of the three sports completing an initial memorisation phase, where they were presented with patterns from their preferred sport as well as from each of the other sports, before completing a recognition test where they were required to differentiate between previously viewed and new patterns. Given that the soccer and hockey patterns shared a number of common relational, structural, and tactical similarities, it was predicted that the recognition performance would be greater between these sports than in volleyball, which has far less commonality. The results provided additional support for positive transfer, with the soccer and hockey players performing equally well on both the soccer and field hockey tests. In contrast, the volleyball players performed better on the volleyball tasks but failed to transfer this ability to the patterns from the other two sports. While this avenue of research has a number of practical and theoretical implications, it has rarely been specifically applied to the phenomenon of representational momentum.
The purpose of the present study was to compare the recognition performance of participants of differing levels of expertise (experts, recreational players, novices, and soccer players) when viewing static images and moving patterns containing a number of interrelated elements from a complex basketball scene. A direct comparison of static and moving images is pertinent, particularly given that these conditions may be represented as two distinct mechanisms (Kourtzi & Nakayama, 2002; see also DeLucia & Maldia, 2006). In addition, it is important to determine whether the forward memory shift reported by Thornton and Hayes (2004) for complex, moving scenes is moderated by the knowledge and experience of the observer in the same manner previously shown for simple images. In the present study, pairs of patterns were extracted from an actual basketball game, and these comprised much richer displays of complex static and moving basketball patterns than those used previously. It was predicted that the expert participants would encode the patterns as an anticipatory trace, and would therefore suffer a greater performance decrement when differentiating between pairs of patterns if the second configuration was the next likely state of the first (chronological order), rather than a possible previous state (reverse order). Given that the visual displays were extracted from a specific domain, the recognition performance of lesser skilled (recreational players) and novice participants was less likely to be affected by representational momentum because these individuals were unlikely to encode the patterns with the same anticipatory features used by the expert participants. However, because some degree of representational momentum has been shown to occur in everyday scenes depicting crowds of people (Thornton & Hayes, 2004), the lesser-skilled groups might still be able to predict some level of player movement if the players in the patterns moved along a consistent pathway that was a continuation of their existing movement, rather than moving in a direction that was consistent with basketball-specific game play. A group comprising highly skilled soccer players was also included to examine whether representational momentum would transfer between team sports.
Method
Participants
A total of 46 male participants were recruited and allocated into one of four groups including an “expert group” (n = 12), a “recreational group” (n = 12), a “soccer group” (n = 10), and a “novice group” (n = 12). The experts were either current or former regional-, national-, or international-level basketball players with an average of 20.8 years of playing experience. The recreational group were current or former amateur basketball players with an average of 10.6 years of playing experience in lower-level competitions. The soccer group comprised highly skilled soccer players competing at a state level with an average of 12.1 years of playing experience and limited basketball experience (only 1 participant reported any prior basketball experience, and he had only played for 1.5 years). The novice group had an extremely limited amount of basketball playing experience and a limited amount of invasion-team-sport experience. The study received ethical approval, and all participants provided informed written consent before taking part in the experiment.
Materials
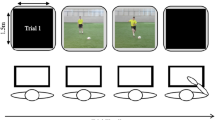
A total of 120 pairs of structured basketball patterns were created. Forty “moving video” pairs were created from video footage of an actual five-on-five game involving skilled basketball players. The footage was filmed from an elevated perspective from the centreline of a standard basketball court. Another 40 pairs were matching still images (“static videos”) created from the final frame of the video footage used for the moving pairs. The final 40 pairs were matching schematic representations (“static schematics”) of the configurations used in the static and moving pairs. For the schematic pairs, the offensive players were depicted as an “O” while defenders were displayed as an “X.” The player holding the ball was shown as an “O” that was completely filled in black. Two additional patterns from each of the three display conditions were also created and shown to participants prior to testing to familiarise them with the task.
To create the static schematic and static video pairs, one image was extracted at a particular point in time (e.g., C1), and a second image was extracted a further 240 ms into the future (i.e., C1+1). The second image was a situation that was the next actual progression of the first image. A similar procedure was used to create the moving pairs, except that during testing, only the first image in each pair was a moving video and the second image was always a static slide. The final frame of the video was at a temporal location identical to the one depicted by the matched static schematic and static video images. For all display types, the order in which the two images were displayed during testing was varied, with some shown in chronological order (e.g., C1 → C1+1), some shown in the reverse order (e.g., C1+1 → C1), and some remaining the same (e.g., C1 → C1 or C1+1 → C1+1).
Three separate tests were created using 40 pairs of patterns that were composed entirely of static schematic diagrams, static videos, or moving videos. The 40 pairs in each test comprised 20 pairs of “same” patterns, with 10 of these showing pairs of the initial stages (e.g., C1 → C1, C2 → C2, . . . , C10 → C10) and 10 showing the next likely progression (i.e., C1+1 → C1+1, C2+1 → C2+1, . . . , C10+1 → C10+1). The remaining 20 pairs comprised 20 “different” patterns, with 10 of these showing pairs in the normal chronological order of a game (e.g., C1 → C1+1, C2 → C2+1, . . . , C10 → C10+1) and 10 showing pairs in the reverse order (i.e., C1+1 → C1, C2+1 → C2, . . . , C10+1 → C10). The pairs were displayed in a random order, and display durations were standardised across conditions.
Procedure
All patterns from a given display type were presented as an individual test block. The next block of patterns was then presented after a short break. The presentation of each of the different display conditions was counterbalanced within each experimental group to minimise any order effects. No feedback was provided during the test regarding the accuracy of responses. The total test time was approximately 60 min.
Familiarisation phase
Participants were shown two examples of each of the different types of images to familiarise them with the task. The meanings of the symbols used in the schematic patterns were also explained.
Comparison task
In each of the three test conditions, participants were shown pairs of patterns projected onto a large screen (1.43 m high and 1.92 m wide). The first pattern in each pair was presented for 5 s and then removed from view. A white screen then appeared for 1 s, before the second pattern in the pair was presented for 5 s and then removed from view. Participants were asked to indicate whether the second pattern was the same as the first by pressing one of two buttons on a computer keyboard. Participants were informed that they could respond from the moment the second image appeared on screen and could also respond after the image had disappeared from view (the image appeared for 5 s and the next pair of patterns appeared after a 5-s intertrial interval, so this gave a maximum of 10 s in which to respond). To reduce the possibility of confounding the results with a speed–accuracy trade-off, there was no emphasis placed on the speed of the response: Participants were told that the 10-s intervals that separated the test trials were more than sufficient to make their response.
Data analysis
The main dependent measure of interest was accuracy of response. Speed of response was not emphasised in the procedure, so it was not included in the results. The “same” configuration pairs were analysed using a two-way (Skill x Display) ANOVA with repeated measures on the last factor. The chronological and reverse-order pairs were directly compared using a three-way (Skill x Order x Display) ANOVA with repeated measures on the last two factors. The between-group variable was skill level (expert, recreational, novice, and soccer group), while the within-group variables were order (chronological and reverse) and display type (static schematic, static video, and moving video). A Greenhouse–Geisser correction was applied for violations of sphericity, and α was set at .05.
Results
The accuracy results for all three types of stimuli in the three viewing orders are displayed in Figs. 1, 2 and 3. For “same” configuration pairs, there was a significant main effect of display [F(1.70, 71.54) = 26.41, MSE = 91.36, p < .001, ηp² = .39], showing that the accuracy for the static videos (M = 91.62) was significantly higher than that for the static schematics (M = 82.24) and moving videos (M = 78.64). There was also a significant main effect of skill [F(3, 42) = 3.05, MSE = 205.70, p = .04, ηp² = .18], but this was no longer significant once Bonferroni corrections were applied. The Skill x Display interaction was not significant [F(5.11, 71.54) = 0.99, MSE = 91.36, p = .43, ηp² = .07].

Mean accuracy percentages for static schematic pairs for each configuration order and across skill levels. Error bars show standard errors

Mean accuracy percentages for static video pairs for each configuration order and across skill levels. Error bars show standard errors

Mean accuracy percentages for moving video pairs for each configuration order and across skill levels. Error bars show standard errors
For “different” configurations, there was a significant main effect of display type [F(2, 84) = 73.97, MSE = 309.08, p < .001, ηp² = .64], with the moving videos eliciting the lowest overall accuracy scores (M = 56.59), followed by the static videos (M = 80.36) and then the static schematics (M = 86.54). There was also a significant main effect of order [F(1, 42) = 15.95, MSE = 142.42, p < .001, ηp² = .28], with participants scoring significantly higher for reverse-order pairs (M = 77.38) than for pairs presented in a chronological order (M = 71.62). The skill main effect was not significant [F(3, 42) = 0.41, MSE = 919.88, p = .75, ηp² = .03]. A significant Order x Display interaction [F(2, 84) = 10.33, MSE = 109.44, p < .001, ηp² = .20] was followed up using paired t tests with α adjusted to p = .017 using a Bonferroni correction. The analyses revealed a significant difference between the chronological (M = 49.86) and reverse-order pairs (M = 64.11), but only when the patterns were presented as moving videos. Finally, the Skill x Order x Display interaction was significant [F(6, 84) = 2.67, MSE = 109.44, p = .02, ηp² = .16].
Follow-up analyses for the three-way interaction were conducted using two-way (Order x Display) ANOVAs for each of the four skill levels. There was a significant Order x Display interaction for the expert [F(2, 22) = 22.91, MSE = 53.53, p < .001, ηp² = .68] and recreational groups [F(2, 22) = 7.58, MSE = 101.39, p = .003, ηp² = .41], but no significant interaction was present for the novice [F(2, 22) = 0.86, MSE = 143.41, p = .44, ηp² = .07] or soccer groups [F(2, 18) = 0.01, MSE = 146.11, p = .99, ηp² = .001]. Paired t tests (with α adjusted to p = .008) revealed that the experts were significantly more accurate at differentiating reverse-order pairs than chronologically ordered pairs for both the static schematic [t(11) = –3.56, p = .004, r = .73] and moving video display conditions [t(11) = –7.04, p < .001, r = .90]. This result is consistent with an anticipatory encoding of the patterns. The same difference existed for the recreational group, but only for the moving video condition, although with Bonferroni corrections this result was on the borderline of statistical significance [t(11) = –3.26, p = .008, r = .70].
Discussion
The purpose of the present study was to examine representational momentum using static and moving images across three different display types (static schematics, static videos, and moving videos) showing complex basketball patterns containing a number of interrelated elements. Participants of differing skill levels were included in order to determine whether the effects would be moderated by the knowledge and experience of the observer in the same manner shown previously for static schematic displays. A group comprising highly skilled soccer players was also included in order to examine whether the anticipatory effects associated with representational momentum would transfer to another team sport.
The results showed that when participants were required to differentiate between pairs of patterns presented in quick succession, expert performers were significantly less accurate when differentiating between pairs that were displayed in the normal order in which they would occur in a game (chronological order), rather than in reverse order, but only when the first image in the pair was presented as a static schematic or a moving video extracted from an actual basketball game. These results support the notion of a representational momentum effect for pattern perception and suggest that when experts are provided with either a schematic or a moving pattern from their domain of expertise, they anticipate the next likely state of the pattern and encode it as an anticipatory trace, thus making it difficult to accurately differentiate between pairs of patterns when the second pattern is in fact the next likely state of the first (chronological order), rather than a possible previous state (reverse order). The results for the recreational basketball group, while on the borderline of statistical significance, also exhibited the predicted difference between chronological and reverse-order pairs, but this only occurred for the moving video patterns: There were no significant effects for the static schematic or static video conditions.
Didierjean and Marmèche (2005) also found that recreational basketball players did not exhibit the representational momentum effect when the patterns were displayed as static schematic images. The results from the present study support this finding but show that the effect may still occur in recreational players when the patterns are displayed as more realistic, moving images. It seems that the moving video displays contained sufficient information that, when combined with the players’ understanding of the typical action–effect principles of game play, elicited an anticipatory response in both expert and recreational-level players. A number of previous studies examining the implied motion of simple objects have shown that the forward displacement of an object increases as the object’s implied velocity also increases (Finke et al., 1986; Freyd & Finke, 1985; see also Hubbard & Bharucha, 1988, for an example of apparent-motion effects). Similarly, Gilis, Helsen, Catteeuw, and Wagemans (2008) found that the magnitude of the error in offside situations was significantly greater when experienced soccer referees assessed the final location of a moving defender, as compared to when the defender was static. It is possible that the moving video condition created a similar phenomenon in the presnt study, increasing the magnitude of the anticipatory encoding to a point where it became manifest in the results.
One of the key questions to consider is why the static video condition did not induce a level of anticipatory encoding similar to the one shown for the other display types. If representational momentum exists in expert participants when viewing impoverished schematic displays, then surely a static video image would contain even more information, thus inducing a similar effect. Secondly, if the recreational participants had sufficient knowledge to encode the moving patterns with an anticipatory trace, why did they not utilise that same knowledge when encoding the static video and static schematic patterns? These points may best be explained by considering the typical display modalities employed by elite-level basketball coaches. One of the most ubiquitous means of describing player movement is to depict players on a whiteboard as schematic images (i.e., Xs and Os). During this process, coaches often describe the subsequent movements of the Xs and Os either by translating the icons to new locations in the diagram or by drawing arrows and lines. Although this provides a basic indication of the next likely state of the pattern, there are obviously no actual movements, so it becomes imperative for the players to be able to extract meaning and infer the appropriate movement characteristics to the pattern. Over a 20-year career, expert basketball players are likely to have acquired the necessary volume of exposure to schematic patterns, thereby developing the depth of understanding required to elicit an anticipatory encoding. However, at a recreational level, while some exposure to schematic patterns may still occur, the volume is unlikely to be anywhere near that of the experts. In short, the moving video condition contained sufficiently realistic, dynamic information to induce an anticipatory encoding of the patterns for both expert and recreational-level players but when those patterns were presented as schematic images, only the expert players had the experience and depth of understanding to be able to extract meaning and imply movement. Similarly, expert and recreational players are much less likely to be exposed to a static video image throughout their playing careers. So, rather than drawing upon the same action–effect principles that were used for the other display types, it seems that the expert and recreational participants may have used a different set of heuristics to complete the static video task, and this failed to induce the same anticipatory response shown in the other display types.
The results also showed that the novice participants did not exhibit the same anticipatory encoding of the patterns that was evident in the expert and recreational groups. Previous research has shown that a basic knowledge of the potential impact of force, friction, or gravity is sufficient for representational momentum to occur (Hubbard, 1994, 1995; Reed & Vinson, 1996; Vinson & Reed, 2002). Other studies have shown that a basic understanding of human motion is sufficient to allow an untrained observer to predict the actions of another individual (Chatterjee, Freyd, & Shiffrar, 1996; Freyd, 1983). Similarly, previous research by Thornton and Hayes (2004) showed that novice observers tended to anticipate the movement of individuals in a complex crowd scene, presumably because they were able to utilise their basic understanding of the principles of human movement. However, the present results suggest that when the images are complex patterns from a specific domain of expertise (in this instance, basketball), a generic understanding of human motion is not sufficient to elicit the anticipatory response, even when the display contains more realistic images. Instead, based on the results of the expert and recreational participants, it seems that the observer must possess a detailed understanding of the interrelationships amongst the players within the pattern before representational momentum can occur. There is also evidence from other studies that actual participation within the sport may develop control-type knowledge of the typical action–effect contingencies within the environment (Jordan & Knoblich, 2004), and this could produce larger forward memory shifts, relative to individuals with no direct experience in the domain (Jordan & Hunsinger, 2008).
The inclusion of the group of soccer players was designed to examine whether the representational momentum effect would transfer between other team sports. It was predicted that the soccer players would be able to transfer some components of their pattern perception skills to the sport of basketball. The results failed to reveal a definitive skill-related effect of representational momentum for the soccer group, suggesting that the transfer of pattern perception skill may not necessarily include an anticipatory component. It is possible that the two sports simply lack sufficient structural, relational, and tactical similarities to facilitate positive transfer between them. Moreover, if control-type knowledge of the typical action–effect contingencies influences the extent of the anticipatory encoding (Jordan & Hunsinger, 2008; Jordan & Knoblich, 2004), it is also possible that representational momentum may not transfer unless the observer has acquired a certain level of playing experience in the domain of interest. Therefore, the soccer players may have failed to demonstrate the effect simply because they lacked sufficient knowledge and firsthand experience of the typical dynamics of motion of a basketball pattern to be able to accurately predict the next likely state in the sequence. Research by Blättler et al. (2010) using an automobile-driving task also failed to find any evidence of positive transfer in representational momentum. Additional research may need to be conducted to further explore this area and confirm these findings.
In summary, the results from the present study extend previous research by showing that both expert and recreational basketball players are able to predict the evolution of a complex pattern from their domain when images are presented as moving videos, but only experts have the depth of understanding required to elicit the same anticipatory encoding for patterns presented as schematic images. Further research in this area should be directed towards an examination of the visual search characteristics of the participants across the different skill levels. Previous research has shown that when observers are required to visually track a moving object that vanishes from view at some point along its trajectory, the eye tends to overshoot the object’s final position (Kerzel, 2000; Kerzel, Jordan, & Müsseler, 2001). Due to the forward shift in the eye movement, the judgement of final position is typically displaced in the direction of motion (Kerzel, 2000; Kerzel et al., 2001). Thus, if experienced individuals are better able to track moving objects from their domain, it is possible that the forward memory shifts are at least partially influenced by eye movements.
References
Abernethy, B., Baker, J., & Côté, J. (2005). Transfer of pattern recall skills may contribute to the development of sport expertise. Applied Cognitive Psychology, 19, 705–718.
Allard, F., & Starkes, J. L. (1991). Motor-skill experts in sports, dance, and other domains. In K. A. Ericsson & J. Smith (Eds.), Toward a general theory of expertise: Prospects and limits (pp. 126–152). Cambridge: Cambridge University Press.
Blättler, C., Ferrari, V., Didierjean, A., van Elslande, P., & Marmèche, E. (2010). Can expertise modulate representational momentum? Visual Cognition, 18, 1253–1273.
Chatterjee, S. H., Freyd, J. J., & Shiffrar, M. (1996). Configural processing in the perception of apparent biological motion. Journal of Experimental Psychology: Human Perception and Performance, 22, 916–929.
DeLucia, P. R., & Maldia, M. M. (2006). Visual memory for moving scenes. The Quarterly Journal of Experimental Psychology, 59, 340–360.
Didierjean, A., & Marmèche, E. (2005). Anticipatory representation of visual basketball scenes by novice and expert players. Visual Cognition, 12, 265–283.
Finke, R. A., Freyd, J. J., & Shyi, G. C.-W. (1986). Implied velocity and acceleration induce transformations of visual memory. Journal of Experimental Psychology: General, 115, 175–188.
Freyd, J. J. (1983). The mental representation of movement when static stimuli are viewed. Perception & Psychophysics, 33, 575–581.
Freyd, J. J. (1987). Dynamic mental representations. Psychological Review, 94, 427–438.
Freyd, J. J. (1992). Dynamic representations guiding adaptive behaviour. In F. Macar, V. Pouthas, & W. J. Friedman (Eds.), Time, action, and cognition: Towards bridging the gap (pp. 309–323). Dordrecht: Kluwer.
Freyd, J. J., & Finke, R. A. (1984). Representational momentum. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 126–132.
Freyd, J. J., & Finke, R. A. (1985). A velocity effect for representational momentum. Bulletin of the Psychonomic Society, 23, 443–446.
Freyd, J. J., & Miller, G. F. (1992, November). Creature motion. Paper presented at the 33rd Annual Meeting of the Psychonomic Society, St. Louis, Missouri.
Freyd, J. J., & Pantzer, T. M. (1995). Static patterns moving in the mind. In S. M. Smith, T. B. Ward, & R. A. Finke (Eds.), The creative cognition approach (pp. 181–204). Cambridge, MA: MIT Press.
Futterweit, L. R., & Beilin, H. (1994). Recognition memory for movement in photographs: A developmental study. Journal of Experimental Child Psychology, 57, 163–179.
Gilis, B., Helsen, W., Catteeuw, P., & Wagemans, J. (2008). Offside decisions by expert assistant referees in Association Football: Perception and recall of spatial positions in complex dynamic events. Journal of Experimental Psychology: Applied, 14, 21–35.
Halpern, A. R., & Kelly, M. H. (1993). Memory biases in left versus right implied motion. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19, 471–484.
Hubbard, T. L. (1994). Judged displacement: A modular process? The American Journal of Psychology, 107, 359–373.
Hubbard, T. L. (1995). Environmental invariants in the representation of motion: Implied dynamics and representational momentum, gravity, friction, and centripetal force. Psychonomic Bulletin & Review, 2, 322–338.
Hubbard, T. L. (2005). Representational momentum and related displacements: A review of the findings. Psychonomic Bulletin & Review, 12, 822–851.
Hubbard, T. L., & Bharucha, J. J. (1988). Judged displacement in apparent vertical and horizontal motion. Perception & Psychophysics, 44, 211–221.
Intraub, H. (2002). Anticipatory spatial representation of natural scenes: Momentum without movement? Visual Cognition, 9, 93–119.
Jordan, J. S., & Hunsinger, M. (2008). Learned patterns of action–effect anticipation contribute to the spatial displacement of continuously moving stimuli. Journal of Experimental Psychology: Human Perception and Performance, 34, 113–124.
Jordan, J. S., & Knoblich, G. (2004). Spatial perception and control. Psychonomic Bulletin & Review, 11, 54–59.
Kerzel, D. (2000). Eye movements and visible persistence explain the mislocalization of the final position of a moving target. Vision Research, 40, 3703–3715.
Kerzel, D. (2002). A matter of design: No representational momentum without predictability. Visual Cognition, 9, 66–80.
Kerzel, D., Jordan, J. S., & Müsseler, J. (2001). The role of perception in the mislocalization of the final position of a moving target. Journal of Experimental Psychology: Human Perception and Performance, 27, 829–840.
Kourtzi, Z., & Nakayama, K. (2002). Distinct mechanisms for the representation of moving and static objects. Visual Cognition, 9, 248–264.
Nagai, M., & Yagi, A. (2001). The pointedness effect on representational momentum. Memory & Cognition, 29, 91–99.
Reed, C. L., & Vinson, N. G. (1996). Conceptual effects on representational momentum. Journal of Experimental Psychology: Human Perception and Performance, 22, 839–850.
Smeeton, N. J., Ward, P., & Williams, A. M. (2004). Do pattern recognition skills transfer across sports? A preliminary analysis. Journal of Sports Sciences, 22, 205–213.
Thornton, I. M., & Hayes, A. E. (2004). Anticipating action in complex scenes. Visual Cognition, 11, 341–370.
Vinson, N. G., & Reed, C. L. (2002). Sources of object-specific effects in representational momentum. Visual Cognition, 9, 41–65.
Author information
Authors and Affiliations
Corresponding author
Additional information
Appreciation is expressed to the Australian Sports Commission for funding this project, and also to Colin Mackintosh for his technical assistance.
Rights and permissions
About this article
Cite this article
Gorman, A.D., Abernethy, B. & Farrow, D. Investigating the anticipatory nature of pattern perception in sport. Mem Cogn 39, 894–901 (2011). https://doi.org/10.3758/s13421-010-0067-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-010-0067-7