
Abstract
In humans, a distinction can be made between implicit or procedural learning (involving stimulus-response associations) and explicit or declarative learning (involving verbalizable rules) that is relatively easy to make in verbal humans. According to several investigators, it is also possible to make such a distinction in nonverbal animals. One way is by training them on a conditional discrimination task (e.g., matching-to-sample) in which reinforcement for correct choice on the current trial is delayed until after a choice is made on the next trial – a method known as the 1-back procedure. According to Smith, Jackson, and Church ( Journal of Comparative Psychology, 134(4), 423–434, 2020), the delay between the sample-correct-comparison response on one trial and reinforcement obtained on the next trial is too long for implicit (associative) learning. Thus, according to this theory, learning must be explicit. In the present experiments we trained pigeons using the 1-back procedure. In Experiment 1, pigeons were trained on red/green 1-back matching using a non-correction procedure. Some of the pigeons showed significant learning. When a correction procedure was introduced, all the pigeons showed evidence of learning. In Experiment 2, new pigeons learned red/green 1-back matching with the correction procedure. In Experiment 3, new pigeons learned symbolic 1-back matching with yellow and blue conditional stimuli and red/green choice stimuli. Thus, pigeons can learn using 1-back reinforcement. Although it would appear that the pigeons acquired this task explicitly, we believe that this procedure does not adequately distinguish between implicit and explicit learning.
Similar content being viewed by others

Introduction
In human learning a distinction can be made between implicit and explicit learning. Implicit learning is said to underlie human procedural and habit learning (e.g., Mishkin, Malamut, & Bachevalier, 1984) and instrumental conditioning (e.g., Ashby & Ennis, 2006; Barnes, Kubota, Hu, Jin, & Graybiel, 2005). Implicit learning is said to originate in brain regions such as the basal ganglia (Smith, Jamani, Boomer, & Church, 2018). Implicit learning is responsible for the kind associative learning characterized by Pavlovian and instrumental conditioning. Implicit learning is typically slow to develop, and it is thought to rely on temporally contiguous reinforcement (Smith et al., 2018).
Explicit or declarative learning is associated with the prefrontal cortex, the anterior cingulate gyrus, the head of the caudate nucleus, and the hippocampus (Ashby & Maddox, 2011; Ashby & Valentin, 2017). It is assumed to use executive attention and working memory in support of hypothesis testing and rule formation (Smith & Church, 2018). It is capable of learning rules that usually can be described verbally. Smith and Church (2018) have reported that these two kinds of learning can be dissociated by defining the boundary conditions between associative learning and higher-level cognition.
One approach to this dissociation has been the use of a categorical discrimination procedure. Most discrimination procedures involve sorting stimuli into two categories. If one uses stimuli that fall along a continuum, there will be stimuli that fall close to the boundary between the two categories and are difficult to categorize. If, under these conditions, one allows an animal a third category, defined as “uncertain,” use of this third category is presumed to involve explicit learning or metacognition because the animal must consider whether it has enough information to make the categorical response or not. The idea is subjects would use this third uncertain category explicitly when the stimuli are close to the boundary conditions that define the two nominal categories. With humans as subjects, one assumes that they would rather avoid making an incorrect sorting response and instead choose the uncertain response by “skipping” to the next trial. But how to encourage nonhuman animals to use the uncertain response? With animals there is a clear reward for correctly sorting stimuli into the two defined categories but none for incorrect sorting. What should be the outcome when an animal makes the uncertain response? To motivate the animal to use the uncertain response, the outcome should be better than the outcome for getting it wrong or there would be no incentive for choosing the uncertain response. In fact, it should be better than the 50% chance of getting it correct by chance. Thus, depending on the study, animals are typically given some kind of reward for choosing the uncertain response. Those outcomes vary from avoiding an aversive timeout for being incorrect and getting an easy-to-categorize stimulus next (e.g., Couchman, Coutinho, Beran, & Smith, 2010; Smith et al., 1995; Smith, Shields, Schull, & Washburn, 1997) to obtaining a small reward (rather than nothing for being incorrect or a more valuable reward for being correct; Foote & Crystal, 2007; Hampton, 2001).
An associative account of choice of the uncertain response would suggest that when the category discrimination is easy, choice of the appropriate category would result in a high probability of receiving the more rewarding outcome, thus avoiding the uncertain response. When the category discrimination is difficult (i.e., in the middle region of the continuum), the animal has a choice of a 50% chance of a high valued reinforcer for making the categorical response or a 100% chance of a lower valued reinforcer for making the uncertain response. As long as the uncertain response has more value than a 50% chance of reinforcement for making the categorical response (near the boundary of the two categorical responses), the animal should choose the uncertain response. Smith and Church (2018) suggest that such an associative account stretches the associative account beyond reason and the cognitive account is more parsimonious. But Crystal and Foote (2009), Jozefowiez, Staddon, and Cerutti (2009), Le Pelley (2012), and even Smith, Beran, Couchman, and Coutinho (2008) provide very reasonable, simple behavioral economic models that explain these results without the need to posit an explicit metacognitive account.
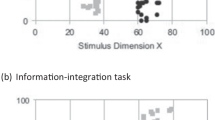
Another presumed source of evidence for a nonverbal distinction between implicit and explicit learning comes from performance on rule-based category-learning tasks, as compared to information-integration tasks. In rule-based category tasks, stimuli are varied along two dimensions but only one dimension is relevant. Thus, a simple (explicit) rule can be generated. In information-integration tasks, two dimensions are both relevant in such a way that no simple category rule can be applied (imagine a plot with one dimension on the abscissa, the other on the ordinate, and the boundary between them on the diagonal). As there is no simple rule one can use to categorize the stimuli involved in the information-integration task, humans learn the rule-based task faster than the information-integration task (Smith et al., 2018). Furthermore, humans can describe the rule they are using. Pigeons, on the other hand, appear to learn the two tasks equally well, suggesting that they are not using explicit rule-based learning (Smith et al., 2011). As Le Pelley, Newell, and Nosofsky (2019) have suggested, however, the information-integration task is also more difficult than the rule-based task and task difficulty may be responsible for the difference in learning. When Le Pelley et al. compared a rule-based task involving a conjunction rule (a simple combination of both length of line and angle of line, e.g., high values on both dimensions) they found similar accuracy on the rule-based and information-integration tasks (see also Wills et al., 2019). Thus, the difference between rule-based and information-integration tasks may not be a good way to distinguish between implicit and explicit learning, even in humans.
Recently, Smith, Jackson, and Church (2020) proposed that because implicit learning relies on temporally contiguous reinforcement, one should be able to interfere with implicit learning by delaying feedback following a response. In humans, delaying response feedback has been found to impair implicit category learning more than explicit category learning (Maddox, Ashby, & Bohil, 2003). It has been proposed that the mechanism responsible for the effect of delay on the implicit system has to do with the neural connections to reward centers in the brain (Arbuthnott, Ingham, & Wickens, 2000; Calabresi, Pisani, Centonze, & Bernardi, 1996). Smith et al. (2020) suggest that if reinforcement lags, it should not be possible to strengthen the synapses that contribute to implicit learning. They argue that, for the implicit system to function, the relevant cortical representation must still be active, and the signal for reinforcement must arrive promptly (within about 2 s).
Following this logic, to rule out implicit learning, Smith et al. (2006) trained a monkey on a spare-dense discrimination that included an uncertain response; however, the differential feedback was not given on each trial, rather the consequences of each block of four trials were provided only after completion of the four trials. Thus, the monkey had no way of knowing to which trial to assign the feedback. Smith et al. found that when stimuli were presented that were difficult to categorize, the monkey tended to use the uncertain response, in spite of the fact that the feedback was delayed until after all four trials in the block had been completed.
Another procedure that involved the delayed feedback was used by Smith et al. (2020). In an experiment with humans, subjects received feedback on Trial 1 only after completing Trial 2, and on Trial 2 only after completing Trial 3, and so forth. Interestingly, the participants were told that they would receive feedback that was appropriate for the preceding trial. Smith et al. called this delayed reinforcement task a 1-back procedure; however, it should not be confused with the N-back procedure used in working-memory research with humans (e.g., Kirchner, 1958).
Comparing acquisition on rule-based and information-integration tasks, Smith et al. (2018) varied whether reinforcement occurred immediately for a correct response (0-back) or was delayed by one trial (1-back). The results indicated that both factors had an important effect on learning. Subjects learned the discrimination well when the discrimination was rule-based, whereas they did not learn it as well when the discrimination was based on information-integration. Also, subjects for whom feedback occurred immediately learned faster than those for whom feedback was delayed by one trial.
Smith et al. (2018) concluded that 1-back reinforcement disabled associative, reinforcement-driven learning and the processes that depend on it. That is, it disrupted the temporal contiguity of the reinforcement signal, disabled the reinforcement-binding properties, and prompted a transition to alternative, explicit learning processes. They proposed that this procedure kept “immediate reinforcement at a ‘safe’ methodological and theoretical distance that rules out associative learning.” Or did it just make the task that much more difficult (Le Pelley et al., 2019)?
If Smith et al. (2018) are correct, the 1-back procedure can be used to determine if non-human (nonverbal) animals are capable of explicit learning. Smith et al. (2020) conducted such an experiment with macaque monkeys. They used a conditional discrimination in which in the presence of one stimulus, Response A was correct, but in the presence of a different stimulus, Response B was correct (a conditional discrimination task). Critically, however, the feedback (a distinctive sound and pellet) that subjects received depended on their response on the preceding trial. Interestingly, in Experiment 1, the feedback that was provided included the conditional stimulus from the preceding trial, as well as the response alternative selected. Furthermore, the location of the conditional stimulus alternated from trial to trial, thus its location served as an additional cue. This procedure may have encouraged a Pavlovian association between the conditional stimulus, the response alternative, and reinforcement. In a follow-up experiment, they repeated the experiment without the response alternative as an added cue associated with reinforcement. In both experiments the monkeys showed significant evidence of learning (see also Smith et al., 2014).
Smith et al. (2020) suggest that the 1-back procedure is a dissociative paradigm that is grounded in the inability of neurons to maintain working memory for more than a couple of seconds and thus can transcend reinforcement-driven learning, while still sustaining interest and motivation. According to the authors, these results suggest that the monkeys were using explicit learning. The argument that learning the 1-back task should not be possible without explicit learning depends on the assumption that implicit learning is not possible when feedback is delayed by several seconds.
Traditional Pavlovian conditioning research has found that good conditioning is supported only when the interval between the conditioned stimulus and the unconditioned stimulus is relatively brief (Hull, 1943), and some have argued that the need for a hippocampus to demonstrate trace conditioning indicates that any delay between the offset of the conditioned stimulus and the onset of the unconditioned stimulus suggests a declarative or explicit learning process (Woodruff-Pak & Disterhoft, 2007). However, there are cases in which good conditioning has been found with very long intervals. In acquired taste aversion, for example, intervals as long as several hours can be demonstrated (Riley & Baril, 1976). Even in instrumental procedures such as the delayed conditional discrimination in which the conditioned stimulus is turned off up to 60 s prior to the onset of the choice stimuli, there is evidence that with sufficient training pigeons can show better than chance accuracy (Grant, 1976). Furthermore, in a delayed alternation task, there is evidence that rats can use the outcome of one trial (reinforced or nonreinforced) as a cue to whether reinforcement will be provided on the next trial, even when the time between trials is as long as 20 min (Capaldi, 1971). Thus, if pigeons can learn this task, either they are showing evidence of explicit learning or Smith et al.’s assumption that implicit learning cannot bridge the delay between trials is incorrect.
Pigeons are generally thought to be implicit learners. They generally learn conditional discriminations and similar tasks slowly rather than all or none (as one might expect with explicit learning). According to Smith et al.’s argument, however, if pigeons can learn a 1-back conditional discrimination, it would suggest that they too are capable of explicit learning. Whether Smith et al.’s reasoning is correct or not, it would be instructive to know if pigeons are capable of learning the 1-back task.
Experiment 1
The purpose of Experiment 1 was to determine if pigeons can learn the 1-back task. The pigeons were trained on a conditional discrimination (matching-to-sample) involving the 1-back procedure. In the 1-back procedure, after the choice response on Trial N, the pigeon received the outcome, a reinforcer or its absence, determined by its response on Trial N-1.
Method
Subjects
The subjects were six unsexed White Carneau pigeons. The pigeons had previously taken part in an unrelated experiment involving a simultaneous color discrimination. The pigeons were maintained at 85% of their free-feeding weight throughout the experiment. They were individually housed in wire cages with free access to water and grit in a temperature-controlled colony room, on a 12:12-h light:dark cycle. The pigeons were cared for in accordance with University of Kentucky Animal Care Guidelines.
Apparatus
The experiment was conducted in a BRS/LVE (Laurel, MD, USA) sound-attenuating standard operant test chamber with inside measurements 35 cm high, 30 cm long, and 35 cm across the response panel. There were three horizontally aligned response keys 25 cm above the floor on the response panel. The rectangular response keys (2.5 cm high x 3.0 cm wide) were separated from each other by 1.0 cm, and behind each key was a 12-stimulus in-line projector (Industrial Electronics Engineering, Van Nuys, CA, USA). The left, right, and center keys could project red and green hues (Kodak Wratten Filter Nos. 26 and 38). In each chamber, the bottom of the center-mounted feeder was 9.5 cm from the floor. Reinforcement consisted of 1.5-s access to Purina Pro Grains. A microcomputer in an adjacent room controlled the experiment.
Procedure
As the pigeons had previous experience pecking red and green hues on the response keys, they were placed on the matching-to-sample task with red and green samples. At the start of each trial a red or a green sample stimulus appeared on the center key. After responding to the sample with ten pecks, red and green comparison stimuli were presented, one on the left, the other on the right. A single peck to one of the comparison stimuli terminated the trial. There was no reinforcement provided on the first trial. The comparison peck merely terminated the trial. On all succeeding trials, the response on the previous trial determined reinforcement on the current trial, regardless of the response on the current trial (see Fig. 1). Trials were separated by a 5-s intertrial interval. The appearance of the red and green samples was counterbalanced over trials as was the location of the red and green comparison stimuli (left and right). The four trial types were presented randomly with the constraint that there was an equal number of each trial type in each session. There were 96 trials in each session. Sessions were conducted 6 days a week.

Experiment 1, Phase 1: 1-back matching-to-sample procedure: Reinforcement was either provided or not, depending on the pigeon’s choice on the preceding trial. On Trial 1, neither choice was reinforced. On Trial 2, if the choice of Trial 1 was correct, reinforcement was provided, independent of the pigeon’s choice on Trial 2. On Trial 3, if the choice on Trial 2 was incorrect, neither choice was reinforced, independent of the pigeon’s choice on Trial 2. Trials were separated by 5-s intertrial intervals
Phase 1 consisted of 30 sessions of training with a non-correction procedure. In Phase 2, a modified correction procedure was introduced – if the pigeon made an error, following the intertrial interval, the trial repeated and continued to do so, until a correct response was made, for a maximum of five repeats. Only trials on which the pigeon was correct on the first attempt were counted as correct. Because of the 1-back contingency, reinforcement was not provided for corrected trials. When a correct response was made on a corrected trial, reinforcement was provided on the following trial, whether a correct response was made on the following trial or not. The purpose of Phase 2 was to extinguish strong comparison position preferences that developed in several pigeons during Phase 1. There were 96 completed trials in each Phase 2 session. Phase 2 consisted of 40 sessions of training.
Results
In Phase 1, as noted, three of the six pigeons showed strong position preferences. Mean 1-back matching accuracy for those three pigeons over the last five sessions of training was 42.7%, 49.0%, and 50.0% correct. The other three pigeons showed evidence of learning. Mean 1-back matching accuracy for those three pigeons over the last five sessions of training was 74.0%, 70.8%, and 89.6% correct. Accuracy for each pigeon during Phase 1 as a function of sessions of training is shown in Fig. 2. Overall, mean 1-back matching accuracy for the six pigeons was 63.0% correct. Overall, a single-sample t-test performed on the data from the pooled last five sessions of Phase 1 training indicated that the pigeons’ accuracy on the 1-back task was not significantly greater than 50%, t(5) = 1.89, p = .12, Cohen’s d = 1.69, for the three pigeons that showed an indication of learning, a binomial test performed on accuracy on the last training session indicated there was significant learning, p < .001, for each of the three pigeons.

Experiment 1, Phase 1: 1-back matching-to-sample training with non-correction in which reinforcement on the current trial depended on the pigeon’s accuracy on the preceding trial
In Phase 2, when the correction procedure was introduced, the three pigeons that showed little indication of acquiring the task, now showed clear evidence of learning. Over the last five sessions of Phase 2, the pigeons’ accuracy averaged 82.9% (accuracy ranged from 72.7% to 96.9% correct). Mean accuracy during Phase 2 as a function of sessions of training is shown in Fig. 3. A single-sample t-test performed on the pooled data from the last five sessions of Phase 1 training indicated that the pigeons’ accuracy on the 1-back task was significantly greater than 50%, t(5) = 8.95, p < .001, Cohen’s d = 8.01.

Experiment 1, Phase 2: 1-back matching-to-sample training with correction in which reinforcement on the current trial depended on the pigeon’s accuracy on the preceding trial. Error bars = ±1 standard error of the mean
Discussion
The results of Experiment 1 suggest that pigeons can acquire the 1-back matching task. Although some pigeons had strong position preferences that may have made it difficult for them to learn, when a correction procedure was introduced, all the pigeons showed some evidence of learning.
Results
Mean 1-back matching accuracy over the last five sessions of training in Experiment 2 was 82.9% correct. Only one of the eight pigeons failed to show significant acquisition of the task. Mean accuracy during Experiment 2 as a function of sessions of training is shown in Fig. 4. A single-sample t-test performed on the pooled data from the last five sessions of Phase 1 training indicated that the pigeons’ accuracy on the 1-back task was significantly greater than 50%, t(7) = 5.53, p = .0009, Cohen’s d = 4.18.

Experiment 2: 1-Back matching-to-sample training with correction in which reinforcement on the current trial depended on the pigeon’s accuracy on the preceding trial. Error bars = ±1 standard error of the mean
Experiment 3
To what extent did acquisition of the matching 1-back task in Experiments 1 and 2 depend on the “sameness” relation between the sample and the correct comparison stimulus? Several experiments with pigeons suggest that pigeons can use the sameness relation following matching training in a transfer of training design (Zentall & Hogan, 1975, 1976). There is also evidence that pigeons use the sameness relation between the sample and the incorrect comparison in acquiring mismatching (Zentall, Andrews, & Case, 2018; Zentall, Edwards, Moore, & Hogan, 1981). When pigeons must choose the comparison that does not match the sample, it appears that they learn to avoid the comparison that matches the sample. Could the matching relation between the sample and either the correct or incorrect comparison have played a role in the acquisition of the 1-back matching task?
In the 1-back experiments by Smith et al. (2018), there was an arbitrary (non-sameness) relation between the conditional stimuli and the choice stimuli. Thus, it may be important to determine if pigeons can acquire the 1-back task in the absence of a sameness relation between the sample and the correct comparison stimulus.
In Experiment 3, there was an arbitrary relation between the sample and the correct comparison stimulus. In Experiment 3, the samples were yellow and blue colors, while the comparisons were red and green.
Method
Subjects and apparatus
The 11 subjects in Experiment 3 were similar to those in Experiments 1 and 2. The apparatus was the same as that used in Experiments 1 and 2.
Procedure
The procedure was the same as in Experiment 2 with the exception that yellow and blue samples replaced the red and green samples used in Experiments 1 and 2. For six of the pigeons the red comparison stimulus was correct when the sample was yellow and the green comparison stimulus was correct when the sample was blue. For the remaining pigeons the red comparison stimulus was correct when the sample was blue, and the green comparison stimulus was correct when the sample was yellow. The pigeons were trained on this 1-back conditional-discrimination for 24 sessions.
Results
In Experiment 3, the pigeons quickly acquired the 1-back symbolic matching task. Mean accuracy during Experiment 3 as a function of sessions of training is shown in Fig. 5. Mean matching 1-back accuracy over the last five sessions of training in Experiment 3 was 73.5% correct. A single-sample t-test performed on the pooled data from the last five sessions of training indicated that the pigeons’ accuracy was significantly greater than 50%, t(10) = 4.75, p < .001, Cohen’s d = 3.00.

Experiment 3: 1-Back conditional-discrimination training with correction in which reinforcement on the current trial depended on the pigeon’s accuracy on the preceding trial. Error bars = ±1 standard error of the mean
General discussion
The results of the present experiments indicate that pigeons can learn the 1-back task. Thus, according to Smith et al. (2018), they are capable of explicit learning because working memory for the events on the preceding trial (as well as the intervening events from the current trial) should be inadequate to bridge the delay and interference required for implicit learning. However, that conclusion requires the assumption that the 1-back procedure disables the striatal system, and that the striatal system is necessary for implicit-procedural learning (Yagishita et al., 2014). That is, no other systems are involved in learning this task. As noted earlier, however, there is considerable evidence that animals can learn associatively with long delays between stimulus presentation and the response and outcome (Capaldi, 1971; Grant, 1976; Riley & Baril, 1976).
In humans there is a dissociation between implicit and explicit learning. In explicit learning, acquisition is generally sudden, and the rule(s) can be explicitly described by subjects. Implicit learning is generally slow, and typically, subjects are not able to state the decision rule(s). Pigeons learn the 1-back task slowly. That suggests that they might be learning the task implicitly. Although the choice response on the current trial is unrelated to the reinforcer (or its absence) that follows, the events from the preceding trial may still be represented in short-term memory and the accumulated trace of the events on the preceding trial may be sufficient to promote learning. It remains to be seen what humans would do with such a task if they were not told the explicit rule.
Alternatively, could the correction procedure used have done more than eliminate spatial or comparison-specific choice? The purpose of the correction procedure was to eliminate spatial and stimulus biases. In so doing, it may have resulted in a tendency to choose the originally unbiased side and stimulus. But with the 1-back procedure, that response would not have been reinforced. Instead, reinforcement would have followed whatever response was made on the following trial, whether correct or not. In any case, the three pigeons that learned the 1-back task in Experiment 1, Phase 1 did so with a non-correction procedure.
There is another possible explanation for acquisition of the 1-back task. What if the pigeons happened, by chance, to match the sample on two consecutive trials? By chance, that would occur 25% of the time. If so, on the second trial, the pigeon would receive a reinforcer for its correct choice on the first trial, but it might associate the reinforcer received with its response on the second trial.
There are two reasons that we believe that adventitious reinforcement of a matching response on two consecutive trials does not account for learning the 1-back task. First, it is just as likely that matching occurred on the first trial and mismatching occurred on the second trial. In that case the pigeon would associate the reinforcer that it received on the second trial with its mismatching response on the second trial. Thus, there is a 50% chance that the pigeon would learn the wrong response. Even on a nonreinforced corrected trial, it does not matter what response is made, reinforcement follows.
Second, when pigeons learn standard matching-to-sample (0-back), they are generally very good at it. That is, they generally reach accuracy better than 90% correct (see, e.g., Zentall & Hogan, 1974). In the current 1-back experiments, however, group accuracy plateaued between 72.6% and 82.9% correct. Had the pigeons inadvertently been associating reinforcement on the current trial with matching on the current trial, once learning began, it should have resulted in accuracy above 90% correct. That is, once a pigeon was matching correctly, reinforcement would be provided on the current trial for the correct matching response on the preceding trial, but the reinforcer might be associated with the current trial. If this were to occur, matching accuracy would be more accurate. Thus, it is unlikely that the pigeons learned to match based on the outcome of the current trial but rather on their choice on the preceding trial.
How would such an implicit process work? An analogy can be drawn between such implicit learning and the mechanical process involved in the measurement of an event-related evoked potential in humans (Misulis & Fakhoury, 2001). Presentation of a visual or auditory stimulus can, in principle, be detected on an electroencephalogram, but because its amplitude tends to be very small, recordings are averaged over a large number of presentations, such that the background activity averages out the noise and the signal remains. The same can be said for reinforcement or its absence with the 1-back procedure. The stimulus events and response on the current trial can be thought of as noise, with the events on the preceding trial as the signal. The events on the preceding trial are the only events that are correlated with the outcome on the current trial, thus they receive an increment of implicit associative strength.
The fact that the pigeons generally acquired the 1-back task gradually, and mainly to a moderate level of accuracy, suggests that the task was learned implicitly. Thus, in spite of the fact that acquisition of the 1-back task is presumed to rule out implicit learning because of the long delay between the behavior and reinforcement (Smith et al., 2020), the results of the present experiments with pigeons suggest that the pigeons learned it implicitly. The same argument can be made for the results of Smith et al. (2006) in which the monkey received feedback only after a block of four trials. In that case, although the feedback was not specific to each of the preceding trials, it was correlated with average response. That is, it is possible that the pigeons in the present experiment and the monkeys in Smith et al. (2006, 2020) learned that matching produced more overall reinforcement, without learning about the relationship between the outcome of Trial N and what they did on Trial N-1.
A different approach to memory for episodes that occurred in the recent past was developed by Panoz-Brown et al. (2018). They trained rats on a trial-unique series of odors and then tested them in two different contexts, one that signaled choice of the second from the last odor would be correct, the other that signaled choice of the fourth from the last odor would be correct. A high degree of accuracy on this task, even when a long delay occurred between initial experience with the odor and the test, suggests that the rats were using a replay of their episodic memory to perform this task. Whether these results can be interpreted as evidence for explicit learning by a nonhuman animal is not clear but it is certainly a reasonable candidate.
Roberts, McMillan, Musolino, and Cole (2012) have explored another form of metacognition known as information seeking in which animals select an alternative that provides information about the outcome of the trial over an uninformative alternative, even if the two alternatives are equally associated with reinforcement (see also Stagner & Zentall, 2010). When this occurs in rats, dogs, and pigeons, Roberts et al. have explained this preference for information in terms of second-order sign tracking, a form of associative learning, rather than a form of metacognition indicative of explicit learning (see also Castro & Wasserman, 2013).
Evidence from the present experiments together with research using the uncertain response, and studies comparing acquisition of rule-based with information-integration tasks make an interesting argument for the distinction between implicit and explicit learning processes. In each case, however, a reasonable associative mechanism can be presented, which suggests that for non-human animals, implicit learning is likely a more parsimonious explanation. Evidence that pigeons can learn a task explicitly must await further research that better rules out implicit learning.
References
Arbuthnott, G. W., Ingham, C. A., & Wickens, J. R. (2000). Dopamine and synaptic plasticity in the neostriatum. Journal of Anatomy, 196, 587–596
Ashby, F. G., & Ennis, J. M. (2006). The role of the basal ganglia in category learning. In: B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 46, pp. 1–36). Academic Press
Ashby, F. G., & Maddox, W. T. (2011). Human category learning 2.0. Annals of the New York Academy of Sciences, 1224, 147–161
Ashby, F. G., & Valentin, V. V. (2017). Multiple systems of perceptual category learning: Theory and cognitive tests. In H. Cohen & C. Lefebvre (Eds.), Handbook of categorization in cognitive science (pp. 157–188). Academic Press
Barnes, T. D., Kubota, Y., Hu, D., Jin, D. Z., & Graybiel, A. M. (2005). Activity of striatal neurons reflects dynamic encoding and recoding of procedural memories. Nature, 437, 1158 –1161
Calabresi, P., Pisani, A., Centonze, D., & Bernardi, G. (1996). Role of Ca2 in striatal LTD and LTP. Seminars in the Neurosciences, 8, 321–328
Capaldi, E. J. (1971). Memory and learning: a sequential viewpoint. In: W. K. Honig and H. James (Eds.), Animal Memory. Academic
Castro, L., & Wasserman, E. A. (2013). Information-seeking behavior: exploring metacognitive control in pigeons. Animal Cognition, 16, 241–254
Couchman, J. J., Coutinho, M. V. C., Beran, M. J., & Smith, J. D. (2010). Beyond stimulus cues and reinforcement signals: A new approach to animal metacognition. Journal of Comparative Psychology, 124, 356–368
Crystal, J. D., & Foote, A. L. (2009). Metacognition in animals. Comparative Cognition & Behavior Reviews, 4, 1-16
Foote, A. L., & Crystal, J. D. (2007). Metacognition in the rat. Current Biology, 17, 551-555
Grant, D. S. (1976). Effect of sample presentation time on long-delay matching in the pigeon. Learning and Motivation, 7, 580-590
Hampton, R. R. (2001). Rhesus monkeys know when they remember. Proceedings of the National Academy of Sciences of the United States of America, 98, 5359–5362
Hull, C. L. (1943). Principles of behavior. Appleton-Century-Crofts
Jozefowiez, J., Staddon, J. E. R., & Cerutti, D. T. (2009). Metacognition in animals: how do we know that they know? Comparative Cognition & Behavior Reviews, 4, 29-39
Kirchner, W. K. (1958). Age differences in short-term retention of rapidly changing information. Journal of Experimental Psychology, 55, 352-358
Le Pelley, M. E. (2012). Metacognitive monkeys or associative animals? Simple reinforcement learning explains uncertainty in nonhuman animals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 686-708
Le Pelley, M. E., Newell, B. R., & Nosofsky, R. M. (2019). Deferred feedback does not dissociate implicit and explicit category learning systems: Commentary on Smith et al. (2014). Psychological Science, 30, 1403-1409
Maddox, W. T., Ashby, F. G., & Bohil, C. J. (2003). Delayed feedback effects on rule-based and information-integration category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 650–662
Mishkin, M., Malamut, B., & Bachevalier, J. (1984). Memories and habits: Two neural systems. In G. Lynch, J. L. McGaugh, & N. M. Weinberger (Eds.), Neurobiology of human learning and memory (pp. 65–88). Guilford Press
Misulis, K. E., & Fakhoury, T. (2001). Spehlmann's Evoked Potential Primer. Butterworth-Heinemann
Panoz-Brown, D. Lyer, V., Carey, L. M., Sluka, C. M., Rajic, G., Kestenman, J., Gentry, M., Brotherridge, S., Somekh, I., Corbin, H. E., Tucker, K. G., Almeida, B., Hex, S. B., Garcia, K. D., Hohmann, A. G., & Crystal, J. D. (2018). Replay of episodic memories in the rat. Current Biology, 28, 1628-1634
Riley, A. L., & Baril, L. (1976). Conditioned taste aversions: A bibliography. Animal Learning & Behavior, 4, 1S-13S
Roberts, W. A., McMillan, N., Musolino, E., & Cole, M. (2012). Information seeking in animals: Metacognition? Comparative Cognition & Behavior Reviews, 7, 85-109
Smith, J. D., Beran, M. J., Redford, J. S., & Washburn, D. A. (2006). Dissociating uncertainty responses and reinforcement signals in the comparative study of uncertainty monitoring. Journal of Experimental Psychology: General, 135, 282–297
Smith, J. D., Ashby, F. G., Berg, M. E., Murphy, M. S., Spiering, B., Cook, R. G., & Grace, R. C. (2011). Pigeons’ categorization may be exclusively nonanalytic. Psychonomic Bulletin & Review, 18, 414–421
Smith, J. D., Beran, M. J., Couchman, J. J., & Coutinho, M. V. C. (2008). The comparative study of metacognition: Sharper paradigms, safer inferences. Psychonomic Bulletin & Review, 15, 679-691
Smith, J. D., Boomer, J., Zakrzewski, A. C., Roeder, J. L., Church, B. A., & Ashby, F. G. (2014). Deferred feedback sharply dissociates implicit and explicit category learning. Psychological Science, 25, 447–457. https://doi.org/10.1177/0956797613509112.
Smith, J. D., & Church, B. A. (2018). Dissociable learning processes in comparative psychology. Psychonomic Bulletin and Review, 25, 1565–1584. https://doi.org/10.3758/s13423-017-1353-1.
Smith, J. D., Jackson, B. N., & Church, B. A. (2020). Monkeys (Macaca mulatta) learn two-choice discriminations under displaced reinforcement. Journal of Comparative Psychology, 134(4), 423–434. https://doi.org/10.1037/com0000227.
Smith, J. D., Jamani, S., Boomer, J. & Church, B. A. (2018). One-back reinforcement dissociates implicit-procedural and explicit-declarative category learning. Memory and Cognition, 46, 261-273
Smith, J. D., Schull, J., Strote, J., McGee, K., Egnor, R., & Erb, L. (1995). The uncertain response in the bottlenosed dolphin (Tursiops truncatus). Journal of Experimental Psychology: General, 124, 391–408
Smith, J. D., Shields, W. E., Schull, J., & Washburn, D. A. (1997). The uncertain response in humans and animals. Cognition, 62, 75–97
Stagner, J. P., & Zentall, T. R. (2010). Suboptimal choice behavior by pigeons. Psychonomic Bulletin & Review, 17, 412-416
Wills, A. J. et al., (2019). Dissociable learning processes, associative theory, and testimonial reviews: A comment on Smith and Church (2018). Psychonomic Bulletin & Review, 26, 1988-1993
Woodruff-Pak, D. S., & Disterhoft, J. F. (2007). Where is the trace in trace conditioning? Trends in Neurosciences, 31, 105-112
Yagishita, S. et al. (2014). A critical time window for dopamine actions on the structural plasticity of dendritic spines. Science, 345, 1616–1620
Zentall, T. R., Andrews, D. M., & Case, J. P. (2018). Sameness may be a natural concept that does not require learning. Psychological Science, 29, 1185-1189
Zentall, T. R., Edwards, C. A., Moore, B. S., & Hogan, D. E. (1981). Identity: The basis for both matching and oddity learning in pigeons. Journal of Experimental Psychology: Animal Behavior Processes, 7, 70-86
Zentall, T. R., & Hogan, D. E. (1974). Abstract concept learning in the pigeon. Journal of Experimental Psychology, 102, 393-398
Zentall, T. R., & Hogan, D. E. (1975). Concept learning in the pigeon: Transfer of matching and nonmatching to new stimuli. American Journal of Psychology, 88, 233-244
Zentall, T. R., & Hogan, D. E. (1976). Pigeons can learn identity, difference, or both. Science, 191, 408-409
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Practices Statement
The experiments reported in this article were not formally preregistered. Requests for the data or materials can be sent via email to the last author at zentall@uky.edu.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nosarzewska, A., Peng, D.N. & Zentall, T.R. Pigeons acquire the 1-back task: Implications for implicit versus explicit learning?. Learn Behav 49, 363–372 (2021). https://doi.org/10.3758/s13420-021-00468-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13420-021-00468-3