
Abstract
Holistic processing of visual words (i.e., obligatory encoding of/attending to all letters of a word) could be a marker of expert word recognition. In the present study, we thus examined for the first time whether there is a direct relation between the word-composite effect (i.e., all parts of a visual word are fully processed when observers perform a task on a word part) and fast access to the orthographic lexicon by visual word experts (i.e., fluent adult readers). We adopted an individual differences approach and used the word-frequency effect (i.e., faster recognition of high- than low-frequency words) in an independent lexical decision task as a proxy of fast access to lexical orthographic representations. Fluent readers with larger word-composite effect showed smaller word-frequency effect. This correlation was mainly driven by an association between a larger composite effect and faster lexical decision on low-frequency words, probably because these lexical representations are less stable and integrated/unitized, hence allowing differentiating among fluent readers. We thus showed that holistic processing of visual words is indeed related to higher efficiency in visual word recognition by skilled readers.
Similar content being viewed by others


Introduction
Letters and visual words offer an interesting way to investigate perceptual expertise. This category is too recent in the history of humankind to be entrenched in the human genome (McCandliss, Cohen, & Dehaene, 2003), but most humans have years of practice in visual word recognition: 86% of the adult world population is literate (UNESCO, 2019). Therefore, this artificial, non-natural category provides a unique opportunity to examine how neurocognitive representations change with experience (McCandliss et al., 2003; Wong & Gauthier, 2007).
To unravel the characteristics of perceptual expertise that are either general or specific to various visual categories (e.g., Busey & Vanderkolk, 2005; Richler, Wong, & Gauthier, 2011; A. W. Wong & Gauthier, 2007; Xu, 2005), studies on perceptual expertise have often investigated face recognition (e.g., Farah, Wilson, Drain, & Tanaka, 1998; Maurer, Le Grand, & Mondloch, 2002) or the comparison between faces and non-face categories of expertise. It has been proposed that, rather than visual properties of stimuli (regardless of their resemblance to faces or not), it is the previous intense and continuous experience and task demands (i.e., individuation and fast processing of items composed by highly similar local elements) that drive perceptual expertise (e.g., Baker, Behrmann, & Olson, 2002; Harel, 2016; Wong, Folstein, & Gauthier, 2012b). Holistic processing has been regarded as one of the mechanisms underpinning the ability of the visual system to fulfill the task demand of fast individuation (Diamond & Carey, 1986; Gauthier & Bukach, 2007; Gauthier, Curran, Curby, & Collins, 2003; Rossion, 2013; Wong, Palmeri, & Gauthier, 2009; Young, Hellawell, & Hay, 1987).
Holistic processing has had different definitions in the literature. Two of the most studied definitions involve a perceptual strategy of processing all parts together that becomes automatized with experience and/or due to a history of learned attention to diagnostic parts (Chua, Richler, & Gauthier, 2014; Richler et al., 2012; Richler, Wong, & Gauthier, 2011), and the explicit representation of spatial relationships between features (e.g., Diamond & Carey, 1986; Leder & Bruce, 2000). Rather than undifferentiated wholes, face recognition involves representations of both the local elements (individual face parts) and their configuration (e.g., Farah et al., 1998; Maurer et al., 2002; Tanaka & Farah, 1993; Young et al., 1987). In a similar vein, in visual word recognition, it has long been shown that letter identities are not bypassed and word holistic processing is not just about supra letter features (e.g., Paap, Newsome, & Noel, 1984). Holistic processing can thus be defined as obligatory encoding of/attending to all object parts, which in turn are also encoded and represented independently (Richler & Gauthier, 2014).
In recent years, increased attention has been devoted to visual word recognition under a perceptual expertise framework (e.g., Liu, Chuk, Yeh, & Hsiao, 2016; Ventura, 2014; Wong & Gauthier, 2007). Efficient visual word recognition (i.e., fast access to abstract orthographic representations at the mental lexicon, which then act as a key interface to phonological and conceptual representations) requires fast identification of letters (from a limited set) and of their position within-word (e.g., <GOD> is different than <COD>, although they only differ in a minute horizontal segment of the first letter; <GOD> is different than <DOG>, although both are composed by the same letters), and regardless of the possible multitude of tokens (e.g., <god> and <GOD> are the same word, and, hence, tap into the same abstract orthographic representation, but they do differ in low level, physical elementsFootnote 1; for a recent review, see, e.g., Grainger, 2017). In fact, like other non-face categories of expertise, a compelling bulk of evidence, at both brain and behavioral levels, has suggested the involvement of holistic representations in visual word recognition. However, as detailed below, to the best of our knowledge no study to date has demonstrated a direct relation between holistic processing of visual words and fast access to the orthographic lexicon. This was the general aim of the present study.
At the brain level, a specific region of the left ventral occipitotemporal cortex (vOT), coined the visual word form area (VWFA; Cohen et al., 2002) underpins abstract orthographic representations (e.g., Dehaene et al., 2001, 2004). Indeed, recent fMRI studies (Bouhali, Bézagu, Dehaene, &, 2019; Lerma-Usabiaga, Carreiras, & Paz-Alonso, 2018; White, Palmer, Boynton, & Yeatman, 2019) have shown that the VWFA comprises two functionally distinct orthographic areas: one mesial and posterior that is sensitive to grapheme complexity, word length, and to phonological demands (sublexical processing), and another more lateral and anterior region that is sensitive to lexicality and word frequency (lexical processing). Indeed, the anterior portion of the VWFA contains neurons tightly tuned to whole-word orthographic representations (e.g., Thesen et al., 2012; Vinckier et al., 2007), which differentiate whole words (Strother, Zhou, Coros, & Vilis, 2017), regardless of whether they are fully different (e.g., boat vs. fish) or differ by just one letter (e.g., pole vs. poke; Glezer, Jian, & Riesenhuber, 2009) even if they are homophones (e.g., poll vs. pole; Glezer, Eden, Jiang, Luetje, Napoliello, Kim, & Riesenhuber, 2016). This evidence suggests that this region is the neural underpinning of holistic, lexical (whole-word) orthographic representations (Bouhali et al. 2019; Lerma-Usabiaga et al., 2018; White et al., 2019). It also agrees with evidence showing that neurons of the vOT become selective for whole representations of items of expertise (after training discrimination at the individual level on these multi-component items; e.g., Baker et al., 2002).
At the behavioral level, the expressions of holistic processing previously found for faces, i.e., the inversion (e.g., Thompson, 1980; Yin, 1969), the part-whole (e.g., Tanaka & Farah, 1993), and the composite (e.g., Young, Hellawell, & Hay, 1987) effects, have also been reported in visual word recognition. In the inversion effect, for example, visual word recognition is impaired when words are presented inverted rather than upright (e.g., Carlos, Hirshorn, Durisko, Fiez, & Coutanche, 2019). More important, just like faces, sensitivity to distortions of the spatial relationship between parts (i.e., by replacing one letter for another, or by jittering the letters in a word) is larger in upright than in inverted words (Conway, Brady, & Misra, 2017; Wong, Wong, Lui, Ng, & Ngan, 2019). Additionally, Wong et al. (2019) showed that the word-inversion effect was larger for configural distortions (letter jittering) than for featural ones (line thickness), as happens for faces (Rakover, 2013).
The word superiority effect refers to the better recognition of a target letter presented within a word than alone or within a nonword (Reicher, 1969; Wheeler, 1970). It is regarded as the result of the interaction between whole-word lexical representations (top-down influences) and low-level bottom-up processing at the letter level (e.g., McClelland & Rumelhart, 1981; Rumelhart & McClelland, 1982).
Some authors have questioned the role of lexical representations, suggesting that independent parallel processing of letters is enough to explain visual word recognition (e.g., Pelli, Farell, & Moore, 2003). However, Houpt, Townsend, and Donkin (2014) have shown that letters are processed faster within a word context than predicted by independent parallel processing on each letter separately. This finding is also consistent with statistical learning of chunks, where groups of letters are recognized as a single unit (Orbán, Fiser, Aslin, & Lengyel, 2008), and the multi-letter representations at the VWFA (e.g., Dehaene et al., 2004, Thesen et al., 2012; Vinckier et al., 2007). It also agrees with the idea of holistic processing of words, that is, obligatory encoding of/attending to all letters, which in turn are also encoded and represented independently.
The word-composite effect shows that all parts of a visual word are fully processed even if the task requires decision on a part only. The composite task has been recently adopted to examine holistic processing of visual words in alphabetic and logographic scripts (Chen et al., 2013; Ventura et al., 2017; Wong, Bukach, Hsiao, Greenspon, Ahern, & Duan, 2012a; Wong, Zhiyi, McGugin, & Gauthier, 2011b). This is a perceptual task where reading is not required: participants are asked to perform a same-different matching task on a specific visual part (e.g., the first syllable) of two sequential (dissyllabic) words and not on whole strings (e.g., same-response trialsFootnote 2: LANE - LADY; LANE - LANE; different-response trials: LANE - CONE; LANE - COZY). Two critical components in this task argue for holistic processing of words. First, influence of the irrelevant part (e.g., the right half) on performance over the target part (e.g., the left half), that is, a significant congruency effect: better performance when the irrelevant part is congruent in response to the one induced by the critical part (in same-response trials: e.g., LANE - LANE, as the critical and irrelevant parts are the same; in different-response trials: e.g., LANE – COZY, as both the critical and irrelevant parts induce a different-response) than when incongruent (in same-response trials: e.g., LANE - LADY, because the critical part of the two words is the same but the irrelevant part is different; in different-response trials: LANE - CONE, as the critical part of the words is different but the irrelevant part is the same). Second, the congruency effect is modulated by alignment, that is, it is severely reduced when the two parts of the word are misaligned (e.g., the right part is moved down relative to the left part) rather than aligned, probably because the whole percept is disrupted. This interaction between alignment and congruency is more indicative of holistic processing than by the observation of a congruency effect, which is tainted by other confounds including response compatibility and decisional processes. The only way to ensure that the congruency effect is indeed about holistic processing of whole items is because when the two parts (critical and irrelevant) of the item are misaligned, and, hence, the whole percept is disrupted, there is a reduction of the congruency effect (e.g., Richler & Gauthier, 2014; Richler, Tanaka, et al., 2008). Indeed, fMRI evidence has demonstrated that the extent of misalignment, in terms of rotation, spacing, and displacement, goes out of the limits of perceptual expertise supported by the VWFA (e.g., Cohen et al., 2008; Vinckier et al., 2006). Therefore, this disruption impairs access to whole-word representations. This word-composite effect reflects access to abstract orthographic and lexical representations, given that it is immune to surface features (e.g., same effect for Courier font, aLtErNaTiNg-case, or handwriting font) and it happens for words only, not for pseudowords (Ventura et al., 2017).
There have been some hints of the association between holistic processing and visual word recognition. For example, the word-composite effect is larger in native readers that in non-native ones (Wong et al., 2011a, b, 2012a, b). Conway et al. (2017) also suggested that the word-inversion effect is related to reading skills, given that typical readers showed a larger word-inversion effect than dyslexic (and hence, less efficient) readers. Furthermore, sensitivity to configural distortions indicated by the inversion effect was larger for observers who were readers than non-readers of the script at test (Wong et al., 2019; Experiment 1). Yet, none of these experiments has systematically examined the relation at the individual level between perceptual expertise on visual words (signaled by holistic processing) and fast access to the orthographic lexicon.
A first attempt was recently made by Wong et al. (2019; Experiment 2): the larger the inversion effect by non-native readers, the faster visual word identification in Chinese (in a sequential matching task on displays of three visual words). However, no significant correlation was found for native Chinese readers.
The aim of the present study was to test whether perceptual expertise on visual words, signaled by holistic processing, is indeed correlated with fast access to the orthographic lexicon among fluent, native readers, with the following five considerations.
First, the only study that has hitherto examined individual differences in word holistic processing and reading skills focused exclusively on the inversion effect (Wong et al., 2019). Both the inversion and composite effects have been used as proxy of holistic processing, yet, at least in face recognition, these two effects seem to have different developmental trajectories, different sensitivity to experimental manipulations (e.g., Richler & Gauthier, 2014), and are uncorrelated with each other (Rezlescu et al., 2017). We thus examined holistic processing of visual words with the word-composite effect, as in Ventura et al. (2017).
Second, we adopted an individual differences approach, in contrast to some previous studies on between-group differences (e.g., typical vs. dyslexic readers: Conway et al., 2017; native vs. non-native readers: Wong et al., 2011a, b, 2012a, b). More important, we examined individual differences among skilled adult readers in their native language with the aim of investigating whether the word-composite effect was involved in the continuous accumulation of visual word recognition skills even among experts.
Third, in Wong et al. (2019), visual word recognition was examined with a visual matching task on displays of three words, which might not necessarily tap into efficient access to the orthographic lexicon. Given that we were specifically interested in examining whether holistic processing was related to fast access to a fully developed orthographic lexicon, we examined reading in one of the most often used tasks, that is, lexical decision, on items differing from those used in the composite task.
Fourth, to assess visual word recognition efficiency, instead of lexical decision performance (which could be tainted by general processing speed), we computed an index known to reflect fast access to lexical orthographic representations, that is, the word-frequency effect (i.e., faster recognition of high- than low-frequency words; e.g., Yap, Balota, Sibley, & Ratcliff, 2012). This effect has been shown to be smaller for individuals with large print exposure (i.e., the amount of text that one reads; e.g., Chateau & Jared, 2000; Yap et al., 2012; Tainturier, Tremblay, & Lecours, 1992), possibly because, besides larger vocabulary, these readers have higher efficiency in activating the correct lexical representations. Larger vocabulary would produce larger inter-word competition (Lewellen et al., 1993), but the more efficient access/retrieval of word representations would make up for it. This agrees with simulations in the triangle model (Harm & Seidenberg, 2004; Monaghan, Chang, Wellbourne, & Brysbaert, 2017), which showed that the smaller word-frequency effect is primarily due to reduction in error variance for low-frequency words as a result of print exposure. We thus hypothesized that if holistic processing of visual words is indeed related to efficient access to lexical orthographic representations, then fluent readers with larger word-composite effects would show smaller word-frequency effects, that is, a negative correlation between the size of the word-composite effect and the size of the word-frequency effect. As all participants were fluent readers, and, hence, high-frequency words would have stable and integrated/unitized lexical representations (for a discussion see, e.g., Kinoshita, 2006; Kuperman & Van Dyke, 2013), then the hypothesized correlation between the word-composite effect and efficiency in visual word recognition could be mainly driven by visual recognition of low-frequency words, because their less stable and integrated/unitized lexical representation would allow differentiating fluent readers (see, e.g., Kinoshita, 2006; Kuperman & Van Dyke, 2013).
Finally, reliability of measures can limit both sensitivity of an individual measure and the extent to which it correlates with other measures (e.g., Lowe & Rabbitt, 1998; Yap et al., 2012). Therefore, before conducting the critical correlation analyses, we computed reliability of the measures in the composite task and in lexical decision, to ensure that variability among readers did reflect meaningful differences.
Methods
Participants
Seventy-six Portuguese Psychology students at Universidade de Lisboa, with normal or corrected-to-normal vision and no known history of a reading disorder, participated voluntarily for a course credit, after giving informed consent. Data from ten additional participants were excluded due to error rates above 25% in any of the two tasks. This study was approved by the Deontological Committee of the Faculty of Psychology.
According to G*Power (Version 3.1), this sample size allows detecting a significant correlation of .366 at α = .05 with a power of .91, which was determined by the geometric mean of the correlation coefficients found between holistic processing and recognition performance for faces (inversion: r = .42, part-whole r = .25; Rezlescu et al., 2017), and between configural sensitivity and recognition performance for words (r = -.469; Wong et al., 2019).
Material and procedure
All material was written in the Latin alphabet in European-Portuguese (EP), one of the Romance languages with higher syllabic and morphological complexity. Regarding orthographic consistency (univocal mapping of phonological into orthographic representations), EP is more opaque than other Romance languages, like Spanish or Italian, but less opaque than French (or English; e.g., Soares et al., 2019), and, hence, has an orthography of intermediate depth.
Participants completed two tasks in a counterbalanced order (half performed first the word composite task, the other half the lexical decision task). In both tasks, stimuli were presented on the center of a 17-in. CRT monitor at a viewing distance of ~90 cm; stimuli presentation and data collection were controlled by E-Prime 2.0.
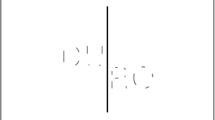
Word composite task. The words, task, and sequence of events were as in Ventura et al. (2017; Experiment 1). As shown in Fig. 1, in each trial, participants had to judge whether the left part (the first consonant.vowel, CV syllable) of the two CV.CVFootnote 3 words was the same or not, regardless of the other, irrelevant part (the second CV), by pressing the “green” or “red” key, respectively, as quickly and accurately as possible. After response or after 2.5 s, whatever came first, another trial began.

Illustration of the composite task with Portuguese words. The left and right word halves were aligned in half of the trials and misaligned in the remaining half for each condition. Each word was presented in Courier font with a 20-point size, at a viewing distance of 90 cm. In the misaligned trials, the right half of the word was moved down by 100 pixels, resulting in the word spanning 3.44° × 1.66°
Participants performed two types of blocks of 96 trials each (four blocks aligned; four misaligned; block- and trial-order randomized), as shown in Fig. 1. In the aligned blocks, the first and second CV syllables of each word were presented aligned, and hence, word form was preserved (size of 3.44° × 1.04°). In misaligned blocks, the right half of the word was moved down by 100 pixels, resulting in the word spanning 3.44° × 1.66°, and disrupting the word-form.
Before the experimental trials, participants were first presented with four examples on paper, for which they received feedback on accuracy. Next, they performed 16 computerized practice trials with different stimuli.
We used the complete version of the composite task (for a meta-analysis and recent review, see Richler & Gauthier, 2014). Thus, within-block, the same number of trials was presented in each of the four conditions resulting from the orthogonal manipulation of response (“same” vs. “different”) and congruency (between the two halves). As previously explained, in “same”-response trials, the first CV was the same in both words (e.g., LA.DY – LA.NE; FA.CE - FA.CEFootnote 4); in “different”-response trials, the first CV was different (e.g., FA.CE - RI.CE; LA.DY - MO.RE). On congruent trials, the irrelevant part leads to the same response as the one induced by the critical part, either a “same” or a “different” response (e.g., FA.CE - FA.CE and LA.DY - MO.RE, respectively). On incongruent trials, the irrelevant part leads to a different, conflictual response relative to the critical part, in same and different response trials (e.g., LA.DY - LA.NE and FA.CE - RI.CE, respectively).
The words comprised the 24 sets of four CV.CV Portuguese words used by Ventura et al. (2017): 12 sets of high-frequency words (ln freq= 9.22) and 12 sets of low-frequency words (Bacelar do Nascimento et al., 2007; ln freq= 3.43), t(22)= 16.91, p < .0001.
Lexical decision task. Task and material were the same as in Lima and Castro (2010). In each trial, participants judged whether the letter string presented on the screen was a real word or not by pressing the “green” or “red” keys, respectively, as quickly and accurately as possible.
Each trial began with a white screen presented for 500 ms, followed by a 500-ms fixation cross, and next by the letter string, presented in lowercase Gill Sans with a 110-point size (item size: 5.66° × 2.12° to 8.53 × 2.75°), which remained on the screen until response or for a maximum of 2.5 s. Presentation of words and pseudowords was intermixed, randomized, and divided into two blocks of trials (blocks with order counterbalanced across participants). Before the experimental trials, participants performed 20 computerized practice trials.
Experimental items (Lima & Castro, 2010; Experiment 2) were 150 Portuguese dissyllabic words and 150 dissyllabic pseudowords, from six sets, varying in length (four, five, and six letters) and frequency (high and low; M = 757.8 and M = 46.8 counts per million; Bacelar do Nascimento et al., 2007). Words from different sets were matched in initial graphemes and phonemes, number of phonemes, and orthographic neighbors. Pseudowords were formed by changing one letter of the second syllable of the original word, while keeping syllable structure and consonant or vowel identity (C replaced by C, and V by V).
Results
Validation of the two tasks
In both tasks, the main dependent variable was the mean reaction time (RT) for correct responses. Trials with RTs 2.5 SD above the grand mean RT for each participant (across conditions) and RTs below 150 ms were discarded (3.1% and 3.6% for the composite and lexical decision tasks, respectively). Accuracy in the holistic composite task was examined with A, a non-parametric sensitivity measure that does not assume normality or equal variances (Zhang & Mueller, 2005), and in the lexical decision task with percentage of correct responses.
Overall, the two tasks showed a pattern of results similar to those in previous studies (Lima & Castro, 2010; Ventura et al., 2017; see Table 1). In the composite task, the congruency effect found on RT was modulated by alignment, as it was larger for aligned than misaligned trials. A was close to perfect overall (>.95 in all conditions), and no differences were observed between high- and low-frequency words. In the lexical decision task, the typical frequency effect was found, with faster and more accurate responses for high-frequency than low-frequency words.
To check if there was sufficient precision and variability in the word-composite and word-frequency effects, before subsequent correlational analyses, the reliability of the measures was computed and is presented in Table 1.
For computing the composite effect, two approaches have been adopted: either a regression approach (e.g., De Gutis et al., 2013) or a subtraction approach (e.g., Ross et al., 2015). In the first, the composite effect is computed by regressing out the congruency effect (difference in performance between congruent and incongruent trials) for the misaligned trials from the congruency effect for the aligned trials. The rationale is that in this way, we would isolate, specifically for an intact word, the holistic processing, i.e., the interference of the irrelevant part on responding to the target word part (De Gutis et al., 2013). However, there is no firm evidence that this approach provides a more reliable measure of holistic processing than a subtraction approach (i.e., based on the difference of scores between the congruency effect for aligned and misaligned items; Ross et al., 2015). Although, and to anticipate the present results, we did obtain the same correlation pattern, regardless of the approach used to compute the word-composite effect, here we present the results using the subtraction approach. Our criterion was that regressing out one of the conditions from the other would remove all of the variance associated with that condition, which would only be appropriate if one assumed that all of the variance in the condition being regressed out is irrelevant to the construct of interest.
The word-frequency effect was computed as the difference in lexical decision performance for low-frequency and high-frequency words, following a subtraction approach, because efficiency in visual word recognition, i.e., access to the orthographic lexicon, affects both high- and low-frequency words. Thus, a regression approach was unwarranted here because regressing out the individual difference for the high-frequency words would also remove individual differences in word-processing efficiency.
The index of reliability, the Guttman’s λ2 for the word-composite effects in RT was .48, and in A was .44. Both are comparable to those previously found for faces in the composite task (De Gutis et al., 2013; .10 to .24; Ross, Richler, & Gauthier, 2015: -.54 to .57; Rezlescu et al., 2017: .28 to .66). For the word-frequency effect, the Guttman’s λ2 in RT was .81, but that in percentage correct was .19. Due to its low reliability, the latter was not used in subsequent correlation analyses.
The maximum possible correlation between the word-composite effect in RT and the word-frequency effect in RT, computed as the geometric mean of their reliabilities, was .62. The maximum possible correlation between the word-composite effect in A and the word-frequency effect in RT was .60. It is thus clear that the measures are reliable enough for finding significant correlations between them.
Correlation between the composite and word-frequency effects
Figure 2 shows the scatterplots of the relationships between: (a) the word-composite effect and the word-frequency effect, and (b) the word-composite effect and lexical decision for low- and high-frequency words,Footnote 5 considering RTs.

Correlation and 95% confidence interval (full and dashed lines, respectively) between the composite effect in reaction time (RT) and the word-frequency effect in RT (top scatterplot), and between the composite effect in RT with the lexical decision RT for low- and high-frequency words (middle and bottom scatterplots)
Across participants, the larger the composite effect, the smaller the frequency effect (r = -.25, p = .027). As hypothesized, this negative correlation was driven more by the larger correlation between the word-composite effect and lexical decision on low-frequency words (r = -.27, p = .02), compared with that on high-frequency words (r = -.16, p = .18). Therefore, a larger composite effect, signaling holistic processing of visual words, was indeed associated with higher efficiency in visual word recognition, and especially for low-frequency words.
The correlations involving the composite effect in A were not significant (ps >.13). While only “yes” trials were considered in the lexical decision task, it should be noted that all correlations between the composite effects and the frequency effect in the “no” trials (where pseudowords were involved) were not significant (all ps > .37).
Discussion
The main finding of the present study is that holistic processing of visual words is associated with efficient access to the orthographic lexicon among adult fluent readers. Specifically, individual differences in the word-composite effect were correlated with those in the word-frequency effect measured in an independent lexical decision task (often used to investigate visual word recognition).
This pattern of results agrees with prior evidence on non-native Chinese readers, for whom Chinese word recognition was correlated with another measure of holistic processing (i.e., the word-inversion effect; Wong et al., 2019; Experiment 2). In this sense, both studies showed that behavioral markers of perceptual expertise on visual words correlated with efficient visual word recognition and reading. Note, however, that Wong et al. (2019; Experiment 2) did not find any significant association between sensitivity to configural information and word recognition by Chinese native readers, that is, skillful readers and experts on Chinese words. This discrepancy with the present results may be caused by composite and inversion effects tapping into different aspects of holistic processing. The composite effect reflects a perceptual strategy of processing all parts together that becomes automatized with experience and/or due to a history of learned attention to diagnostic parts, which can involve inflexible attentional weighting to all parts of the object (Chua, Richler, & Gauthier, 2014; Richler et al., 2012; Richler & Gauthier, 2014; Richler, Wong, & Gauthier, 2011). In contrast, the inversion effect reflects sensitivity to configural information, that is, to the spatial relationships between parts of an object. Indeed, in face recognition, they differ in developmental course and in the experimental manipulations which they are sensitive to (e.g., Richler & Gauthier, 2014), and have small correlation with one another and especially with face recognition skills (Rezlescu et al., 2017). Given the different paradigms used to tap into mechanisms of holistic processing, it is thus critical that future studies on expertise for visual words explore how they relate and to which extent they provide overlapping versus unique explanatory power on visual word recognition efficiency and reading. An interesting possibility, based on the available research (e.g., the present study; Conway et al., 2017; Wong et al., 2019), is that configural sensitivity, as assessed by the word-inversion effect, better predicts differences in reading performance between beginning (or less fluent) readers – that is, non-experts – whereas the composite effect would better explain individual differences among experts on visual words.
By adopting an individual-differences approach here, after ensuring measurement reliability (Yap et al., 2012), we showed that individual differences between adult fluent readers on access to lexical orthographic representations can be detected and do relate to holistic processing of visual words. More important, this correlation cannot be attributed to overall performance, other general (spurious) processes, or efficiency in a loose sense (i.e., observers that are more efficient in one task would also be more efficient in another). The indexes used here for holistic processing (the word-composite effect) and for efficient access to lexical orthographic representations (the word-frequency effect) were not about global performance in the composite and in the lexical decisions tasks, respectively. The word-frequency effect was computed as the difference in lexical decision on low- and high-frequency words, a classical measure of efficient access to the mental lexicon. The word-composite effect was computed with a similar subtraction approach. These two independent indexes were negatively correlated to each other: readers with the smaller word-frequency effect showed the larger word-composite effect. To put it differently, skillful readers (with small word-frequency effects) were the ones that in the composite task were less able to disregard the irrelevant part (second syllable) when judging the critical part (first syllable). Visual words were thus fully processed even when the task required an exclusive decision on a specific part. Holistic processing is about obligatory encoding of/attending to all object parts, which in turn are encoded and represented independently (Richler & Gauthier, 2014). Therefore, we can conclude that readers with more efficient access to lexical orthographic representations are those with a stronger holistic effect, and, hence, who were less efficient in the composite task.
This conclusion agrees with prior indirect evidence. Readers with more exposure to print show smaller word-frequency effects (Chateau & Jared, 2000; Tainturier et al., 1992; Yap et al., 2012), mainly because more efficient orthographic processing leads to more accurate recognition (smaller error variance) of low-frequency words, which usually have lower quality (Harm & Seidenberg, 2004; Monaghan et al., 2017; Yap et al., 2012). Therefore, we also hypothesized that the correlation between the word-composite effect and efficiency in visual word recognition would be mainly driven by recognition of low-frequency words. Indeed, this was our finding, which cannot be due to low measurement reliability (the Guttman’s λ2 was .87 and .75 for high- and for low- frequency words). Rather, it is because low-frequency lexical representations that are usually less stable allow differentiating between experts on visual words (see, e.g., Kinoshita, 2006; Kuperman & Van Dyke, 2013).
The present results agree with previous evidence showing that the representations involved in this effect are abstract, orthographic, and lexical (Ventura et al., 2017). A putative neural underpinning of the word-composite effect is the more lateral and anterior portion of the VWFA, given that this region is sensitive to whole words (regardless of whether they are maximally or minimally different in local components; e.g., pole vs. fish or vs. poll, respectively; Glezer et al., 2009, 2019), is sensitive to lexical properties (e.g., word frequency) but not to sublexical ones (e.g., word length; Bouhali et al., 2019), and is strongly connected to language areas (Lerma-Usabiaga et al., 2018). Indeed, “a more anterior area responded to entire words more holistically” (p. 1093, White et al. 2019). The present study is thus encompassed by recent literature showing the relevance of holistic visual word representations in reading. Whereas the more posterior region of the VWFA that underpins sublexical orthographic representations is involved in phonological reading, the lateral anterior region is sensitive to lexical properties, underpins holistic word representations, and has greater connectivity to language and conceptual neural networks (Bouhali et al., 2019; Lerma-Usabiaga et al., 2019).
Some authors might, however, see an inconsistency in the fact that the composite effect has an abstract/orthographic/lexical locus (because it is unaffected by case mixing as shown in Ventura et al., 2017) and yet it is severely reduced by misalignment of the two halves. Maybe the word-composite effect is not completely immune to visual manipulations, with some being (e.g., misalignment with a large offset between the two halves) more effective than others (case mixing)? In other words, the word-composite effect can have both visual and lexical loci.
In the present study, a smaller word-frequency effect (in lexical decision) was used as proxy of more efficient visual word recognition and fast access to lexical orthographic representations. Other measures can of course be used to evaluate word recognition efficiency and its relation to holistic word processing. It would be particularly interesting to examine if holistic processing would be correlated with other lexical properties (e.g., neighborhood density) that are reliable indexes of efficient access to and integrity of lexical orthographic representations, and with proxies of sublexical processing (e.g., the word length).
Note, however, that the present study has a correlational nature, and, hence, it does not provide evidence on potential causality between holistic processing and efficient visual word recognition. One interesting way to examine whether holistic processing of words in perceptual tasks like the composite task precede or succeed efficient and highly stable lexical orthographic representations would be with a longitudinal study where different reading and holistic processing measures would be tracked at multiple times during reading acquisition and development.
Reading is a means of accessing the language system through vision. The ultimate goal of visual word recognition is reading, which inherently involves an interaction between visual, linguistic, and conceptual systems. Nonetheless, visual word recognition is also perceptual expertise in a non-natural category, and, hence, it presents a special case of visual object recognition (e.g., Grainger, 2017; Harel, 2016; McCandliss et al., 2003; Wong & Gauthier, 2007). Therefore, examining the relationship between visual word recognition and perceptual expertise is relevant for research on both perceptual expertise and in reading. In fact, Grainger and Hannagan (2014; see also, Grainger, 2017) suggest that when learning to read, letters change their status, from individual objects to parts of a multi-component object. This “mid-level vision of reading” (cf. Grainger, 2017) might be more fruitfully investigated when considering perceptual expertise and reading together.
Data are available through the following identifier
DOI 10.17605/OSF.IO/Y4JNT
Notes
Although the critical aspects of expertise are not about physical properties of stimuli per se, it is interesting to note that like the multitude of tokens in visual word recognition that access the same lexical entry (e.g., script vs. cursive), familiar faces also present a wide range of image variability (e.g., in pose; expression) that converge into a single face representation (e.g., Young & Burton, 2018).
The critical part on which observers perform the same-different matching task is underlined; examples are given in English for illustration purposes and for the sake of clarity.
The dot signals a syllable boundary.
Examples are given in English just for the sake of clarity.
Outlier points were identified though visual inspection of the graphs. We thus ran two nonparametric tests (Spearman's rank-order correlation and Kendall's Tau Correlation), which are much less sensitive to outliers, and the pattern of results remained the same.
References
Bacelar do Nascimento, M. F., Casteleiro, J. M., Marques, M. L. G., Barreto, F., Amaro, R., & Veloso, R. (2007). Corlex: Léxico multifuncional computorizado do Português contemporâneo (lmcp_dec.txt).
Baker, Chris I., Behrmann, Marlene, & Olson, Carl R. (2002). Impact of learning on representation of parts and wholes in monkey inferotemporal cortex. Nature Neuroscience, 5(11), 1210-1216. https://doi.org/10.1038/nn960.
Bouhali, F., Bézagu, Z., Dehaene, S., & Cohen, L. (2019). A mesial-to-lateral dissociation for orthographic processing in the visual cortex. Proceedings of the National Academy of Sciences, 201904184. https://doi.org/10.1073/pnas.1904184116.
Busey, T., & Vanderkolk, J. (2005). Behavioral and electrophysiological evidence for configural processing in fingerprint experts. Vision Research, 45, 431-448. https://doi.org/10.1016/j.visres.2004.08.021.
Carlos, B.J., Hirshorn, E.A., Durisko, C., Fiez, J.A., Coutanche, M.N., (2019). Word inversion sensitivity as a marker of visual word form area lateralization: An application of a novel multivariate measure of laterality, NeuroImage, 191:493-502. (2019), https://doi.org/10.1016/j.neuroimage.2019.02.044.
Chateau, D. G., & Jared, D. (2000). Exposure to print and word recognition processes. Memory & Cognition, 28, 143-153. https://doi.org/10.3758/bf03211582.
Chen, H., Bukach, C. M., & Wong, A. C.-N. (2013). Early Electrophysiological Basis of Experience-Associated Holistic Processing of Chinese Characters. PLoS One, 8(4), e61221. https://doi.org/10.1371/journal.pone.0061221
Chua, K. W., Richler, J. J., & Gauthier, I. (2014). Becoming a Lunari or Tayo expert: Learned attention to parts drives holistic processing of faces. Journal of Experimental Psychology: Human Perception and Performance, 40, 1174-1182. https://doi.org/10.1037/a0035895
Cohen, L., Dehaene, S., Vinclier, F., Jobert, A., & Montavont, A. (2008). Reading normal and degraded words: contribution of the dorsal and ventral visual pathways. Neuroimage. 40(1), 353-366. https://doi.org/10.1016/j.neuroimage.2007.11.036.
Cohen, L., Lehericy, S., Chochon, F., Lemer, C., Rivaud, S., & Dehaene, S. (2002). Language-specific tuning of visual cortex? Functional properties of the Visual Word Form Area. Brain, 125(Pt 5), 1054-1069.
Conway, A., Brady, N., & Misra, K. (2017). Holistic word processing in dyslexia. PLoS ONE 12 (11): e0187326. https://doi.org/10.1371/journal.pone.0187326.
DeGutis, J., Wilmer, J., Mercado, R. J., & Cohan, S. (2013). Using regression to measure holistic face processing reveals a strong link with face recognition ability. Cognition, 126(1), 87–100. https://doi.org/10.1016/j.cognition.2012.09.004.
Dehaene, S., Jobert, A., Naccache, L., Ciuciu, P., Poline, J. B., Le Bihan, D., Cohen, L. (2004), Letter binding and invariant recognition of masked words: Behavioral and neuroimaging evidence. Psychological Science 15 (5), 307-313. https://doi.org/10.1111/j.0956-7976.2004.00674.x.
Dehaene, S., Naccache, L., Cohen, L., Bihan, D., LeMangin, J.-F., Poline, J.-B., & Rivière, D. (2001). Cerebral mechanisms of word masking and unconscious repetition priming. Nature Neuroscience, 4(7), 752.
Diamond, R., & Carey, S. (1986). Why faces are and are not special – An effect of expertise. Journal of Experimental Psychology: General, 115, 107–117. https://doi.org/10.1037/0096-3445.115.2.107.
Farah, M. J., Wilson, K. D., Drain, M., and Tanaka, J. N. (1998). What is "special" about face perception? Psychological Review, 105(3), 482-498. https://doi.org/10.1037/0033-295X.105.3.482.
Gauthier, I., & Bukach, C. (2007). Should we reject the expertise hypothesis? Cognition, 103, 322–330. https://doi.org/10.1016/j.cognition.2006.05.003.
Gauthier, I., Curran, T., Curby, K. M., & Collins, D. (2003). Perceptual interference supports a non-modular account of face processing. Nature Neuroscience, 6(4), 428–432. https://doi.org/10.1038/nn1029.
Glezer, L. S., Jiang, X., Luetje, M. M., Napoliello, E. M., Kim, J., Riesenhuber, M., & Eden, G. F. (2019). An fMRI-adaptation study of phonological and orthographic selectivity to written words in adults with poor reading skills. Brain & Language, 191, 1–8. https://doi.org/10.1016/j.bandl.2019.01.002.
Glezer, L. S., Eden, G., Jiang, X., Luetje, M., Napoliello, E., Kim, J., Riesenhuber, M. (2016). Uncovering phonological and orthographic selectivity across the reading network using fMRI-RA. Neuroimage, 138, 248–256. https://doi.org/10.1016/j.neuroimage.2016.05.072.
Glezer, L. S., Jiang, X., & Riesenhuber, M. (2009). Evidence for highly selective neuronal tuning to whole words in the "visual word form area". Neuron, 62(2), 199-204. https://doi.org/10.1016/j.neuron.2009.03.017.
Grainger, J. (2017). Orthographic processing: A "mid-level" vision of reading. Quarterly Journal of Experimental Psychology, 1-72. https://doi.org/10.1080/17470218.2017.1314515.
Grainger, J., & Hannagan, T. (2014). What is special about orthographic processing? Written Language & Literacy,17, 225-242. https://doi.org/10.1075/wll.17.2.03gra.
Harel, A. (2016). What is special about expertise? Visual expertise reveals the interactive nature of real-world object recognition. Neuropsychologia, 83, 88-99. https://doi.org/10.1016/j.neuropsychologia.2015.06.004.
Harm, M. W., & Seidenberg, M. S. (2004). Computing the meaning of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review, 111, 662-720. https://doi.org/10.1037/0033-295X.111.3.662.
Houpt, J. W., Townsend, J. T., & Donkin, C. (2014). A new perspective on visual word processing efficiency. Acta Psychologica, 145, 118-127. https://doi.org/10.1016/j.actpsy.2013.10.013.
Kinoshita, S. (2006). Additive and interactive effects of word frequency and masked repetition in the lexical decision task. Psychonomic Bulletin & Review, 13, 668-673. https://doi.org/10.3758/BF03193979.
Kuperman, V., & Van Dyke, J. A. (2013). Reassessing word frequency as a determinant of word recognition for skilled and unskilled readers. Journal of Experimental Psychology: Human Perception and Performance, 29, 802-823. https://doi.org/10.1037/a0030859.
Leder, H, & Bruce, V. (2000). When inverted faces are recognized: the role of configural information in face recognition. Quarterly Journal of Experimental Psychology, Section A, 53, 513-536.
Lerma-Usabiaga, G., Carreiras, M., & Paz-Alonso, P. M. (2018). Converging evidence for functional and structural segregation within the left ventral occipitotemporal cortex in reading. Proceedings of the National Academy of Sciences, 115(42), E9981-E9990. https://doi.org/10.1073/pnas.1803003115.
Lewellen, M.J, Goldinger, S. D., Pisoni, D. B., Greene, B. (1993). Lexical familiarity and processing efficiency: Individual differences in naming, lexical decision, and semantic categorization. Journal of Experimental Psychology: General, 12, 316-330. https://doi.org/10.1037/0096-3445.122.3.316.
Lima, C. F., & Castro, S. L. (2010). Reading strategies in orthographies of intermediate depth are flexible: Modulation of length effects in Portuguese. European Journal of Cognitive Psychology, 22, 190-215. https://doi.org/10.1080/09541440902750145.
Liu, T., Chuk, T. Y., Yeh, J. H., & Hsiao, J. H. (2016) Transfer of perceptual expertise: the case of simplified and traditional Chinese character recognition. Cognitive Science, 40 (8), 1941-1968. https://doi.org/10.1111/cogs.12307.
Lowe, C., & Rabbitt, P. (1998). Test=re-test reliability of the CANTAB and ISPOCD neuropsychological batteries: Theoretical and practical issues. Neuropsychologia, 36, 915–923.
Maurer, D., Le Grand, R., & Mondloch, C. J. (2002). The many faces of configural processing. Trends in Cognitive Sciences, 6, 255–260. https://doi.org/10.1016/S1364-6613(02)01903-4.
McCandliss, B. D.. Cohen, D., & Dehaene, S.(2003). The visual word form area: expertise for reading in the fusiform gyrus. Trends in Cognitive Sciences 7(7): 293-299.
McClelland, J. L. & D. E. Rumelhart (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review 88 (5): 375-407. https://doi.org/10.1037/0033-295X.88.5.375.
Monaghan, P., Chang, Y-N., Welbourne, S., & Brysbaert, M. (2017). Exploring the relations between word frequency, language exposure, and bilingualism in a computational model of reading. Journal of Memory and Languge, 93, 1-21. https://doi.org/10.1016/j.jml.2016.08.003.
Orbán, G., Fiser, J., Aslin, R. N., & Lengyel (2008). Bayesian learning of visual chunks by human observers. Proceedings of the National Academy of Sciences, 105, 2745-2750. https://doi.org/10.1073/pnas.0708424105.
Paap, K. R., Newsome, S. L., & Noel, R. W. (1984). Word shape's in poor shape for the race to the lexicon. Journal of Experimental Psychology: Human Perception and Performance, 10(3), 413-428. https://doi.org/10.1037//0096-1523.10.3.413
Pelli, D. G.,Farell, B., & Moore, D. C.(2003).The remarkable inefficiency of word recognition. Nature 423,752–756. https://doi.org/10.1038/nature01516.
Rakover, S. S. (2013). Explaining the face-inversion effect: The face-scheme incompatibility (FSI) model. Psychonomic Bulletin and Review, 20(4), 665–692. https://doi.org/10.3758/s13423-013-0388-1.
Reicher, G. M. (1969). Perceptual recognition as a function of the meaningfulness of the stimulus material. Journal of Experimental Psychology., 81, 275-280. https://doi.org/10.1037/h0027768.
Rezlescu, C., Susilo, T., Wilmer, J. B., & Caramazza, A. (2017). The Inversion, Part-Whole, and Composite Effects Reflect Distinct Perceptual Mechanisms With Varied Relationships to Face Recognition. Journal of Experimental Psychology: Human Perception and Performance. https://doi.org/10.1037/xhp0000400.
Richler, J.J. & Gauthier, I. (2014). A meta-analysis and review of holistic processing. Psychological Bulletin, 140(5), 1281-1302. https://doi.org/10.1037/a0037004.
Richler, J.J., Palmeri T. J., and Gauthier, I. (2012). Meanings, mechanisms, and measures of holistic processing. Frontiers in Psychology, 3. https://doi.org/10.3389/fpsyg.2012.00553.
Richler, J. J., Tanaka, J. W., Brown, D. D., & Gauthier, I. (2008). Why does selective attention to parts fail in face processing? Journal of Experimental Psychology: Learning, Memory & Cognition, 34 (6), 1356-1368. https://doi.org/10.1037/a0013080.
Richler, J. J., Wong, Y. K., & Gauthier, I. (2011). Perceptual expertise as a shift from strategic interference to automatic holistic processing. Current Directions in Psychological Science, 20(2), 129-134. https://doi.org/10.1177/0963721411402472.
Ross, D. A., Richler, J. J., & Gauthier, I. (2015). Reliability of composite-task measurements of holistic face processing. Behavior Research Methods, 47(3): 736-743.
Rossion, B. (2013). The composite face illusion: A whole window into our understanding of holistic face perception. Visual Cognition, 21, 139-253. https://doi.org/10.1080/13506285.2013.772929.
Rumelhart, D. E., & McClelland, J. L. (1982). An interactive activation model of context effects in letter perception: II. The contextual enhancement effect and some tests and extensions of the model. Psychological Review, 89(1), 60-94. https://doi.org/10.1037/0033-295X.89.1.60.
Soares, A. P., Lages, A., Silva, A., Comesana, M., Sousa, I., Pinheiro, A. P., & Perea, M. (2019). Psycholinguistic variables in visual word recognition and pronunciation of European Portuguese words: a mega-study approach. Language, Cognition and Neuroscience, 34(6), 689-719. https://doi.org/10.1080/23273798.2019.1578395.
Strother, L., Zhou, Z., Coros, A. K., & Vilis, T. (2017). An fMRI study of visual hemifield integration and cerebral lateralization. Neuropsychologia, 100, 35-43. https://doi.org/10.1016/j.neuropsychologia.2017.04.003.
Tainturier, M.-J., Tremblay, M., & Lecours, A. R. (1992). Educational level and the word-frequency effect: A lexical decision investigation. Brain and Language, 43(3), 460-474. https://doi.org/10.1016/0093-934X(92)90112-R.
Tanaka, J. W., & Farah, M. J. (1993). Parts and wholes in face recognition. Quarterly Journal of Experimental Psychology, Section A, 46, 225–245. https://doi.org/10.1080/14640749308401045.
Thesen, T., McDonald, C. R., Carlson, C., Doyle, W., Cash, S., Sherfey, J., Felsovalyi, O., Barr, W., Devinsky, O., ,Kuzniecky, R., & Halgren, E. (2012). Sequential then interactive processing of letters and words in the left fusiform gyrus. Nature communications, 3, 1284. https://doi.org/10.1038/ncomms2220.
Thompson P, 1980 Margaret Thatcher: a new illusion. Perception, 9, 483-484
UNESCO (2019). Education: Literacy Rate. [Data file] Retrieved from http://data.uis.unesco.org/index.aspx?queryid=166.
Ventura, P. (2014). Let’s face it: reading acquisition, face and word processing. Frontiers in Educational Psychology. 23 July 2014 | doi: https://doi.org/10.3389/fpsyg.2014.00787.
Ventura, P., Fernandes, T., Leite, I., Almeida, V., Casqueiro, I., & Wong, A. (2017). The word-composite effect depends on abstract lexical representations but not surface features like case and font. Frontiers in Perception Science. 8:1036. https://doi.org/10.3389/fpsyg.2017.01036.
Vinckier, F. , Dehaene, S., Jobert, A., Dubus, J. P., Sigman, M., & Cohen, L. (2007). Hierarchical coding of letter strings in the ventral stream: dissecting the inner organization of the visual word-form system. Neuron, 55, 143-156. https://doi.org/10.1016/j.neuron.2007.05.031.
Vinckier, F., Naccache, L., Papeix, C., Forget, J., Hahn-Barma, V., Dehaene, S., & Cohen, L. (2006). “What” and “where” in word reading: ventral coding of written words revealed by parietal atrophy. Journal of Cognitive Neuroscience, 18, 1998–2012. https://doi.org/10.1162/jocn.2006.18.12.1998.
Wheeler, D. D. (1970). Processes in word recognition. Cognitive Psychology, 1, 59-85. https://doi.org/10.1016/0010-0285(70)90005-8.
White, A. L., Palmer, J., Boynton, G. M., & Yeatman, J. D. (2019). Parallel spatial channels converge at a bottleneck in anterior word-selective cortex. Proceedings of the National Academy of Sciences, 116(20), 10087-10096. https://doi.org/10.1073/pnas.1822137116.
Wong, A. C.-N., Bukach, C. M., Hsiao, J., Greenspon, E., Ahern, E., Duan, Y., et al. (2012a). Holistic processing as a hallmark of perceptual expertise for nonface categories including Chinese characters. Journal of Vision, 12, 7. https://doi.org/10.1167/12.13.7.
Wong, A. C.-N., Bukach, C. M., Yuen, C., Yang, L., Leung, S., and Greenspon, E. (2011a). Holistic Processing of Words Modulated by Reading Experience. PLoS One, 6(6), e20753. https://doi.org/10.1371/journal.pone.0020753. https://doi.org/10.1080/13506280600948350.
Wong, A. C.-N. & Gauthier, I. (2007). An analysis of letter expertise in a levels-of-categorization framework. Visual Cognition, 15, 854-879. https://doi.org/10.1080/13506280600948350
Wong, A. C.-N., Palmeri, T. J., Gauthier, I. (2009). Conditions for face-like expertise with objects: Becoming a Ziggerin expert – but which type? Psychological Science, 20, 1108-1117. https://doi.org/10.1111/j.1467-9280.2009.02430.x.
Wong, A. C.-N., Wong, Y. K., Lui, K. F. H., Ng, T. Y. K., & Ngan, V. S. H. (2019). Sensitivity to configural information and expertise in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 45, 82-99. https://doi.org/10.1037/xhp0000590
Wong, A.C.-N., Zhiyi, Q., McGugin, R.N.W. & Gauthier, I. (2011b). Interference in character processing reflects common perceptual expertise across writing systems. Journal of Vision, 11(1):15. https://doi.org/10.1167/11.1.15.
Wong, Y. K., Folstein, J. R., & Gauthier, I. (2012b). The Nature of Experience Determines Object Representations in the Visual System. Journal of Experimental Psychology-General, 141(4), 682-698. https://doi.org/10.1037/a0027822.
Xu, Y. (2005). Revisiting the role of the fusiform face area in visual expertise. Cerebral Cortex, 15(8), 1234-1242. https://doi.org/10.1093/cercor/bhi006.
Yap, M. J., Balota, D. A., Sibley, D. E., & Ratcliff, R. (2012). Individual differences in visual word recognition: Insights from the English Leicon Project. Journal of Experimental Pychology: Human Perception and Performance, 38, 53-79.
Yin, R. K. (1969). Looking at upside-down faces. Journal of Experimental Psychology, 81(1), 141-145. https://doi.org/10.1037/h0027474
Young, A. W., Burton, A. M. (2018). Are we face experts? Trends in Cognitive Sciences, 2, 100–110. https://doi.org/10.1016/j.tics.2017.11.007.
Young, A. W., Hellawell, D., & Hay, D. C. (1987). Configurational information in face perception. Perception, 16, 747–759. https://doi.org/10.1068/p160747.
Zhang, J., & Mueller, S. T. (2005). A note on ROC analysis and non-parametric estimate of sensitivity. Psychometrika, 70, 203–212. https://doi.org/10.1007/s11336-003-1119-8.
Acknowledgements
This work was supported by the Research Center for Psychological Science (CICPSI), Faculdade de Psicologia, Universidade de Lisboa, Lisboa, Portugal and by the research project VOrtEx (PTDC/PSI-GER/28184/2017) funded by FCT, Fundação para a Ciência e a Tecnologia, I.P., Portugal, and European funds -FEDER/POR Lisboa 2020. We would like to thank Kenneth Paap and two anonymous reviewers for the very helpful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ventura, P., Fernandes, T., Pereira, A. et al. Holistic word processing is correlated with efficiency in visual word recognition. Atten Percept Psychophys 82, 2739–2750 (2020). https://doi.org/10.3758/s13414-020-01988-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-020-01988-2