
Abstract
Attention is biased towards learned predictors of reward. The influence of reward history on attentional capture has been shown to be context-specific: When particular stimulus features are associated with reward, these features only capture attention when viewed in the context in which they were rewarded. Selection history can also bias attention, such that prior target features gain priority independently of reward history. The contextual specificity of this influence of selection history on attention has not been examined. In the present study, we demonstrate that the consequences of repetitive selection on attention robustly generalize across context, such that prior target features capture attention even in contexts in which they were never seen previously. Our findings suggest that the learning underlying attention driven by outcome-independent selection history differs qualitatively from the learning underlying value-driven attention, consistent with a distinction between associative and reinforcement learning mechanisms.
Similar content being viewed by others

Introduction
Given the capacity limitations of the brain's perceptual system, stimuli compete for representation at later stages of cognitive processing (Desimone & Duncan, 1995). By orienting attention selectively to certain stimuli, an organism is able to exert some measure of control over the degree to which different stimuli are represented. Although attention can be directed to stimuli endogenously (e.g., Posner, 1980; Wolfe, Cave, & Franzel, 1989), attention can also be automatically drawn to stimuli via multiple orienting mechanisms. Two of the most well-studied mechanisms are salience-driven attention, in which feature contrast directs the orienting of attention (e.g., Theeuwes, 1992, 2010), and contingent attentional capture, in which attention is automatically directed to stimuli that possess a currently task-relevant feature (e.g., Folk, Remington, & Johnston, 1992). More recently, the role of learning history in the control of attention has generated substantial research interest (e.g., Awh. Belopolsky, & Theeuwes, 2012; Failing & Theeuwes, 2018).
One powerful determinant of attentional orienting is reward history (e.g., Anderson, 2013, 2016; Anderson, Laurent, & Yantis, 2011; Della Libera & Chelazzi, 2009; Hickey, Chelazzi, & Theeuwes, 2010). Stimuli previously associated with reward automatically capture attention even if physically non-salient and explicitly task-irrelevant (e.g., Anderson et al., 2011; Anderson & Halpern, 2017). Another powerful determinant is outcome-independent selection history: With sufficient training, even in the absence of reward, features that consistently define a searched-for target will come to automatically draw attention (e.g., Kyllingsbaek, Schneider, & Bundesen, 2001; Kyllingsbaek, Van Lommel, Sorensen, & Bundesen, 2014; Lin, Lu, & He, 2016; Qu, Hillyard, & Ding, 2017; Shiffrin & Schneider, 1977). The similarities and differences between the influence of reward history and selection history on the control of attention have been scarcely studied.
One possibility is that reward history and outcome-independent selection history influence the attention system via a common underlying mechanism. Selection history is often invoked as a conceptual umbrella encompassing multiple learning experiences (Awh et al., 2012; see also Lin et al., 2016; Sha & Jiang, 2016; Stankevich & Geng, 2014), and concrete distinctions between different components of selection history are lacking. Concerning outcome-independent selection history, one prominent hypothesis is that correct task performance functions as an internal reward, which shapes responses in the perceptual system to the features that predicted it (e.g., Roelfsema & van Ooyen, 2005; Roelfsema, van Ooyen, & Watanabe, 2010; Sasaki, Nanez, & Watanabe, 2010; Seitz, Lefebvre, Watanabe, & Jolicoeur, 2005; Seitz & Watanabe, 2005). To the degree that such internal rewards modulate attention in the same sort of way that the receipt of extrinsic rewards do, outcome-independent selection history could be thought of as reflecting a less robust form of value-driven attention that merely requires more protracted training to produce a selection bias.
On the other hand, it has been suggested that reward and outcome-independent selection history might influence attention via dissociable learning mechanisms. The influence of extrinsic rewards on attention is clearly associative in nature, reflecting Pavlovian learning mechanisms (e.g., Bucker & Theeuwes, 2017; Le Pelley, Pearson, Griffiths, & Beeskey, 2015; Sali et al., 2014). Even when a reward cue has never served as a target, it will come to bias attention when its presence predicts high reward (e.g., Le Pelley et al., 2015). Reasoning from the fact that depressed individuals show blunted attentional capture by reward cues (Anderson, Leal, Hall, Yassa, & Yantis, 2014, Anderson, Chiu, DiBartolo, & Leal, 2017) but intact and robust attentional capture resulting from outcome-independent selection history (Anderson et al., 2017), Anderson et al. (2017) hypothesized that outcome-independent selection history may result specifically from reinforcement learning mechanisms whereby repetitive orienting responses become habitual and stimulus-triggered. By this account, the learning mechanisms underlying value-driven attention and attention driven by outcome-independent selection history are qualitatively different. This speculation remains unsubstantiated, and in the present study we test one of the predictions that arises from it.
The influence of learning on the control of attention is not limited to learning that is linked to stimulus features, but also extends to contextual information. Visual search is more efficient when the particular arrangement of stimuli in a search array has been repeated previously, even though participants are not explicitly aware of these repetitions (e.g., Chun & Jiang, 1998, 2003). Most importantly for the purposes of the present study, contextual information can play a powerful role in modulating attentional capture. When a stimulus feature is predictive of reward in one context but not in another, attentional capture by this feature will be selective to the context in which it was rewarded (Anderson, 2015a, 2015b). The degree to which attention prioritizes orienting on the basis of the physical salience of stimuli (i.e., singleton detection mode) can also be biased by prior search history in a context-specific manner, where context predicts the difficulty of the search task (Cosman & Vecera, 2013). The role of context in attentional capture driven by outcome-independent selection history has not been examined.
If value-driven attentional capture and attentional capture driven by outcome-independent selection history reflect a common mechanism of attentional control, they should be similarly subject to contextual modulation. However, to the degree that outcome-independent selection history reflects a habitual stimulus-triggered orienting response built up through repetition, it need not be specific to a particular context, particularly when the context does not predict any outcome of selection. In the present study, we provide a test of whether attentional capture by former target-defining features is similarly context-specific.
In this study, participants searched for red and green targets over three identical training sessions. Participants were simply instructed to search for both colors, as in prior studies (e.g., Anderson et al., 2011, 2017); however, the target color on a given trial was fully predicted by an otherwise task-irrelevant background scene. Participants were not explicitly informed of any relationship between context and the search task, only that the search array would appear overlaid on a background. Then, in a subsequent test phase performed on a different day, participants completed a second task in which they searched for a shape-defined target (additional singleton task, see Theeuwes, 1992). On a subset of trials, one of the non-targets was rendered in the color of a former target from training. Participants were instructed to simply ignore color and focus on identifying the unique shape. The same context scenes were presented in the background, which were now fully uncorrelated with both targets and non-targets. Of interest was the degree to which former target colors would automatically capture attention as distractors when presented in the context in which they were previously searched verus the context in which they never appeared as targets.
Experiment 1
Method
Participants
Forty-two participants (18–22 years of age, mean = 18.8 years, 28 female) were recruited from the Texas A&M University community. Participants were compensated with course credit. All participants reported normal or corrected-to-normal visual acuity and normal color vision, and provided written informed consent. All procedures were approved by the Texas A&M University Institutional Review Board and conformed to the principles outlined in the Declaration of Helsinki. The sample size was informed by a power analysis. The effect size for attentional capture by a trained stimulus (distractor present vs. absent) was conservatively set at dz = 0.45 based on prior studies of value-driven attention (e.g., Anderson, 2015b; Anderson et al., 2011, 2014; Anderson & Halpern, 2017). Setting desired power β > 0.80 with α = 0.05 yielded a minimum required sample size of 41 (G*Power; http://www.gpower.hhu.de/). Data collection was stopped the week that the desired sample size was obtained.
Apparatus
A Dell OptiPlex equipped with Matlab software and Psychophysics Toolbox extensions (Brainard, 1997) was used to present the stimuli on a Dell P2717H monitor. The participants viewed the monitor from a distance of approximately 70 cm in a dimly lit room. Manual responses were entered using a standard keyboard.
Training phase
Stimuli
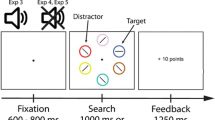
Each trial consisted of the presentation of a context scene upon which a fixation display and a search array were subsequently presented (Fig. 1A). The context scene consisted of a black-and-white picture of a forest or city street (as in Anderson, 2015b), which remained on-screen throughout the fixation display and search array. The fixation display contained a white fixation cross (0.7° x 0.7° visual angle) presented in the center of the screen, and the search array consisted of the fixation cross surrounded by six colored circles (each 2.5° x 2.5°) presented along an imaginary circle with a radius of 5°. The fixation cross and each colored circle were presented within a black box to increase contrast with the background scene. All stimuli were presented on a gray background.

Sequence and time course of trial events. (A) The target was defined as a red or green circle, and participants reported the identity of the line segment inside of the target (vertical or horizontal) with a key press. Each target color was only ever presented against one of the two background scenes (forest or city street). (B) During the test phase, the target was defined as the unique shape. On half of the trials, one of the non-target items – the distractor – was rendered in the color of a former target from training, presented equally often on each background scene
The target was defined as the red or green circle, exactly one of which was presented on each trial. The color of each nontarget circle was drawn from the set {blue, cyan, pink, orange, yellow, white} without replacement. Inside the target circle, a white bar was oriented either vertically or horizontally, and inside each of the nontarget circles, a white bar was tilted at 45° to the left or to the right (randomly determined for each nontarget). A feedback display, which consisted of the words "Incorrect" or "Too Slow" centrally presented against the context scene was immediately presented after the search array in the event of an incorrect response or no response, respectively.
Design
The target appeared in each of the six possible locations equally often. For one background scene (counterbalanced across participants), the target was always red, while for the other background scene it was always green. The background scene was the forest on half of the trials and the city street on the other half. Trials were presented in a random order.
Procedure
The training phase consisted of 720 trials on each of three consecutive sessions. Sessions were run on consecutive days.Footnote 1 Each trial began with the presentation of the background scene for 1,500 ms, after which the fixation cross appeared and remained on-screen for a randomly varying interval of 400, 500, or 600 ms. The search array then appeared and remained on screen until a response was made or 1,000 ms had elapsed, after which the trial timed out. If the response was not correct, the feedback display was presented for 1,000 ms, and each trial was followed by a blank 1,000-ms inter-trial interval.
Participants made a forced-choice target identification by pressing the "z" and the "m" keys for the vertically and horizontally orientated bars within the targets, respectively. On the first day of training, participants were provided with interactive instructions that included practice trials with and without the timeout limit (36 in total).
Test phase
Stimuli
Each trial consisted of the presentation of a context scene upon which a fixation display and a search array were subsequently presented (Fig. 1B). The six shapes comprising the search array now consisted of either a diamond among circles or a circle among diamonds, and the target was defined as the unique shape. The task was again to report the orientation of the bar contained within the target, using the same orientation-to-response mapping. On a subset of the trials, one of the non-target shapes was rendered in the color of a target from the training phase (referred to as the former-target distractor); the target shape was never the color of a target from the training phase. The target and non-targets other than the former-target distractor were drawn, randomly without replacement on each trial, from the same set of colors used to define nontargets during training.
Design
Target identity, target location, distractor identity, and distractor location were fully crossed and counterbalanced separately within each context, and trials were presented in a random order. The context was the forest and city street equally often. Former target distractors were presented on 50% of the trials within each context, half of which were the color previously experienced in that context (color-context match) and half of which were the color never experienced in that context (color-context mismatch).
Procedure
Participants were instructed to ignore the color of the shapes and to focus on identifying the oriented bar within the unique shape using the same orientation-to-response mapping. The test phase consisted of 480 trials, which were preceded by interactive instructions that included practice (distractor-absent) trials with and without the timeout limit (32 in total). Trials timed out after 1,500 ms in the test phase, but otherwise the timing and order of events was the same as in the training phase. Participants completed the test phase the day after the third session of the training phase.
Data analysis
Only correct responses were included in all analyses of response time (RT), and RTs more than three SDs above or below the mean of their respective condition for each participant were trimmed. In the test phase, distractor-present trials were categorized based on whether the distractor color matched the target color previously experienced in that context (match or mismatch). Note that both distractor colors and both contexts are represented in each distractor condition; what differs is the specific pairings of color and context based on the contingencies experienced during training. Data for one participant were replaced (with data from a new participant) due to accuracy that fell below 2.5 SD of the group mean (replacing this participant did not change any of the results). To quantify the evidence for or against the null hypothesis, JZS Bayes Factors were computed for each individual comparison, and BF > 3 was taken to reflect strong evidence in favor of the respective outcome (Rouder, Speckman, Sun, Morey, & Iverson, 2009).
Results
Training phase
RT differed across the three training sessions, F(2,82) = 73.95, p < 0.001, η2p = 0.643, improving with experience (Fig. 2A). Accuracy also differed across the three training sessions, F(2,82) = 16.60, p < 0.001, η2p = 0.288, also improving with experience (Fig. 2B).

Behavioral data. (A) Response time by training session. (B) Accuracy by training session. (C) Response time by distractor condition in the test phase. Error bars reflect the within-subjects SEM. **p<0.005 ***p<0.001
Test phase
RT differed by distractor condition, F(2,82) = 9.89, p < 0.001, η2p = 0.194 (Fig. 2C). Planned comparisons revealed that both the context-matching distractor, t(41) = 4.76, p < 0.001, d = 0.73 (BF10 = 881.10), and the context-mismatching distractor, t(41) = 3.36, p = 0.002, d = 0.52 (BF10 = 18.83), slowed responses compared to distractor-absent trials. Performance did not differ between the two distractor conditions, t(41) = 1.03, p = 0.310 (BF01 = 3.66). Compared to the results of Anderson (2015b), which used the same context manipulation where context predicted reward, attentional capture by context-mismatching distractors was significantly greater in the present study than it was in this prior study, t(70) = 2.49, p = 0.015, d = 0.59 (BF10 = 3.30). There was no effect of distractor condition on accuracy, F(2,82) = 1.72, p = 0.186 (absent: 93.2%, context-mismatching: 92.3%, context-matching 92.7%).
Experiment 2
The results of Experiment 1 are consistent with the generalization of learned attentional bias across contexts. However, it could be argued that participants failed to learn anything about the context or did not even process contextual information during training, precluding any influence of context on performance. Although the same context manipulation gave rise to context-specific attentional bias using a shorter training procedure with reward feedback (Anderson, 2015b), which would suggest an ability to learn from the context manipulation, this alternative possibility cannot be explicitly ruled out by Experiment 1. Therefore, we conducted a second experiment in which participants completed a single session of training using the same contingencies. We probed awareness of the (fully predictive) relationship between context and target color, along with the degree to which performance was affected when the context-target relationship was reversed in a test phase.
Methods
Participants
Twenty-four participants (18–22 years of age, mean = 19.2 years, ten female) were recruited from the Texas A&M University community. Participants were compensated with course credit. All reported normal or corrected-to-normal visual acuity and normal color vision, and provided written informed consent. All procedures were approved by the Texas A&M University Institutional Review Board and conformed to the principles outlined in the Declaration of Helsinki.
Apparatus
The apparatus was identical to that used in Experiment 1.
Stimuli, design, and procedure
The stimuli, design, and procedure were identical to the first session of the training phase of Experiment 1, with the following exceptions. The training phase now lasted for 528 trials. At the conclusion of training, participants were given the following prompt without warning: "So far, each target color has appeared much more frequently against a particular background. Click on the pairing that you think you have seen more frequently." The options included "Red-Forest/Green-City" and "Green-Forest/Red-City," and each option was shown with a pair of corresponding example images appearing in a white box, one on the left and one on the right side of the screen. The experiment waited for participants to click on one of the two options (two-alternative forced-choice). Following this prompt, participants completed another 96 trials, during which each target color appeared equally often against each background. Participants were not informed of this change in the task contingencies. We compared performance (accuracy and RT) between context-matching and context-mismatching targets during this final 96-trial test phase.
Results
Seventy-five percent of participants reported the correct context-target combination, which was significantly higher than what would be expected from guessing (binomial test: p = 0.011), indicating that the task contingencies were learned. When these contingencies changed unannounced in the test phase, performance was unaffected: participants were neither faster, t(23) = -0.64, p = 0.527 (BF01 = 3.86), nor more accurate, t(23) = 0.48, p = 0.633 (BF01 = 4.19) in the context-matching (mean RT = 595 ms, SD = 43 ms, and mean accuracy = 86.8%, SD = 9.7%) compared to the context-mismatching condition (mean RT = 592 ms, SD = 45 ms, and mean accuracy = 86.1%, SD = 8.3%).
Discussion
The findings of the present study demonstrate that the influence of outcome-independent selection history on the control of attention robustly generalizes across context. In Experiment 1, participants repeatedly oriented towards red and green targets over three training sessions, but each color target was only ever encountered in one particular task context. When red and green distractors were encountered in a subsequent test phase in which color was irrelevant, these color distractors captured attention even when appearing in the context in which they were never previously found. This contrasts with the influence of reward history on attention, which is specific to the context in which a particular stimulus feature predicted reward (Anderson 2015a, 2015b). Experiment 2 confirmed that participants were sensitive to the context manipulation, accurately reporting the relationship between the background and the target color, while again showing no influence of context on subsequent task performance. Such awareness was evident in spite of the fact that training was overall shorter than in Experiment 1, providing what is likely a conservative estimate of the degree of awareness evident following multiple days of training.
Our findings are inconsistent with the hypothesis that reward history and outcome-independent selection history influence attention via a common mechanism, and more generally argue against a unitary model of selection history's effect on attention (cf., Awh et al., 2012; Failing & Theeuwes, 2018; Lin et al., 2016; Sha & Jiang, 2016; Stankevich & Geng, 2014). If correct task performance functions in an analogous fashion to extrinsic reward in the shaping of attention, the corresponding learning should be similarly context specific. That is, given that the influence of reward on attention is context-specific and the "reward" for correctly identifying each color stimulus was only ever experienced in one of two contexts in the present study, a similar degree of context specificity would be expected under the common mechanism hypothesis.
Instead, our findings are consistent with the idea that the learning mechanisms underlying attentional capture driven by outcome-independent selection history differ qualitatively from those underlying value-driven attentional capture. We propose that, while the effects of reward history on attention reflect Pavlovian learning (e.g., Bucker & Theeuwes, 2017; Le Pelley et al., 2015; Sali et al., 2014), outcome-independent selection history influences attention via reinforcement learning. Repeated selection of a target links the orienting response to the stimulus, such that orienting to it becomes a habitual response that is triggered by the stimulus itself (see Anderson et al., 2017). Such stimulus-response learning takes longer to develop into a habit than it takes for predictive relationships between stimuli and reward to be learned, accounting for the asymmetric training required to observe the respective biases. The proposed account provides a better explanation than asymmetric degrees of an otherwise common reward representation, which should be similarly subject to contextual dependencies in learning.
Our findings raise a broader question concerning the diversity of mechanisms by which learning history shapes attentional selection. For example, aversive conditioning is also known to bias attention to punishment-predictive stimuli (e.g., Anderson & Britton, 2019; Schmidt, Belopolsky & Theeuwes, 2015; Wang, Yu, & Zhou, 2013). It is unclear to what degree attentional biases driven by aversive conditioning are similar to and distinguishable from attentional biases driven by reward history and outcome-independent selection history. Our findings challenge the notion of a unitary mechanism of attentional control governed by selection history, and highlight the need to compare and contrast different components of selection history's influence on the attention system.
Open Practices Statement
The reported experiment was not preregistered. The data have not been uploaded to a repository, but all raw data are available from the corresponding author upon request.
Notes
Two participants initially missed one training session, which was rescheduled on a different day: one completed the second session on the morning of the third day and the third session in the evening of the third day (then completing the test phase as originally scheduled), while the other completed the third session on the fourth day and the test phase on an extra (fifth) day.
References
Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3):7, 1-16.
Anderson, B. A. (2015a). Value-driven attentional capture is modulated by spatial context. Visual Cognition, 23, 67-81.
Anderson, B. A. (2015b). Value-driven attentional priority is context specific. Psychonomic Bulletin and Review, 22, 750-756.
Anderson, B. A. (2016). The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences, 1369, 24-39.
Anderson, B. A., & Britton, M. K. (2019). On the automaticity of attentional orienting to threatening stimuli. Emotion.
Anderson, B. A., Chiu, M., DiBartolo, M. M., & Leal, S. L. (2017). On the distinction between value-driven attention and selection history: Evidence from individuals with depressive symptoms. Psychonomic Bulletin and Review, 24, 1636-1642.
Anderson, B. A., & Halpern, M. (2017). On the value-dependence of value-driven attentional capture. Attention, Perception, and Psychophysics, 79, 1001-1011.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences, USA, 108, 10367-10371.
Anderson, B. A., Leal, S. L., Hall, M. G., Yassa, M. A., & Yantis, S. (2014). The attribution of value-based attentional priority in individuals with depressive symptoms. Cognitive, Affective, and Behavioral Neuroscience, 14, 1221-1227.
Awh, E. Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437-443.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Bucker, B., & Theeuwes, J. (2017). Pavlovian reward learning underlies value driven attentional capture. Attention, Perception, and Psychophysics, 79, 415-428.
Chun, M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28-71.
Chun, M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 224-234.
Cosman, J. D., & Vecera, S. P. (2013). Context-dependent control over attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 39, 836-848.
Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychological Science, 20, 778-784.
Desimone, R., Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18, 193-222.
Failing, M., & Theeuwes, J. (2018). Selection history: How reward modulates selectivity of visual attention. Psychonomic Bulletin and Review, 25, 514-538.
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18, 1030-1044.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010). Reward changes salience in human vision via the anterior cingulate. Journal of Neuroscience, 30, 11096-11103.
Kyllingsbaek, S., Schneider, W. X., & Bundesen, C. (2001). Automatic attraction of attention to former targets in visual displays of letters. Perception and Psychophysics, 63, 85-98.
Kyllingsbaek, S., Van Lommel, S., Sorensen, T. A., & Bundesen, C. (2014). Automatic attraction of visual attention by supraletter features of former target strings. Frontiers in Psychology, 5:1383, 1-7.
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158-171.
Lin, Z., Lu, Z.-H., & He, S. (2016). Decomposing experience-driven attention: opposite attentional effects of previously predictive cues. Attention, Perception, and Psychophysics, 78, 2185-2198.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32, 3-25.
Qu, Z., Hillyard, S. A., & Ding, Y. (2017). Perceptual learning induces persistent attentional capture by nonsalient shapes. Cerebral Cortex, 27, 1512-1523.
Roelfsema, P. R., & van Ooyen, A. (2005). Attention-gated reinforcement learning of internal representations for classification. Neural Computation, 17, 2176-2214.
Roelfsema, P. R., van Ooyen, A., & Watanabe, T. (2010). Perceptual learning rules based on reinforcers and attention. Trends in Cognitive Sciences, 14, 64-71.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin and Review, 16, 225-237.
Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance, 40, 1654-1664.
Sasaki, Y., Nanez, J. E., & Watanabe, T. (2010). Advances in visual perceptual learning and plasticity. Nature Reviews Neuroscience, 11, 53-60.
Schmidt, L. J., Belopolsky, A. V., & Theeuwes, J. (2015). Attentional capture by signals of threat. Cognition and Emotion, 29, 687-694.
Seitz, A., Lefebvre, C., Watanabe, T., & Jolicoeur, P. (2005). Requirement for high-level processing in subliminal learning. Current Biology, 15, R753-R755.
Seitz, A., & Watanabe, T. (2005). A unified model for perceptual learning. Trends in Cognitive Sciences, 9, 329-334.
Sha, L. Z., & Jiang, Y. V. (2016). Components of reward-driven attentional capture. Attention, Perception, and Psychophysics, 78, 403-414.
Shiffrin, R. M., & Schneider, W. (1977). Controlled and automatic human information processing II: Perceptual learning, automatic attending, and general theory. Psychological Review, 84, 127-190.
Stankevich, B. A., & Geng, J. J. (2014). Reward associations and spatial probabilities produce additive effects on attentional selection. Attention, Perception, and Psychophysics, 76, 2315-2325.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception and Psychophysics, 51, 599-606.
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 135, 77-99.
Wang, L., Yu, H., & Zhou, X. (2013). Interaction between value and perceptual salience in value-driven attentional capture. Journal of Vision, 13(3:5), 1-13.
Wolfe, J. M., Cave, K. R., Franzel, S. L. (1989). Guided Search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception and Performance, 15, 419-433.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Anderson, B.A., Britton, M.K. Selection history in context: Evidence for the role of reinforcement learning in biasing attention. Atten Percept Psychophys 81, 2666–2672 (2019). https://doi.org/10.3758/s13414-019-01817-1
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01817-1