
Abstract
In visual search of natural scenes, differentiation of briefly fixated but task-irrelevant distractor items from incidental memory is often comparable to explicit memorization. However, many characteristics of incidental memory remain unclear, including the capacity for its conscious retrieval. Here, we examined incidental memory for faces in either upright or inverted orientation using Rapid Serial Visual Presentation (RSVP). Subjects were instructed to detect a target face in a sequence of 8–15 faces cropped from natural scene photographs (Experiment 1). If the target face was identified within a brief time window, the subject proceeded to an incidental memory task. Here, subjects used incidental memory to discriminate between a probe face (a distractor in the RSVP stream) and a novel, foil face. In Experiment 2 we reduced scene-related semantic coherency by intermixing faces from multiple scenes and contrasted incidental memory with explicit memory, a condition where subjects actively memorized each face from the sequence without searching for a target. In both experiments, we measured objective performance (Type 1 AUC) and metacognitive accuracy (Type 2 AUC), revealing sustained and consciously accessible incidental memory for upright and inverted faces. In novel analyses of face categories, we examined whether accuracy or metacognitive judgments are affected by shared semantic features (i.e., similarity in gender, race, age). Similarity enhanced the accuracy of incidental memory discriminations but did not influence metacognition. We conclude that incidental memory is sustained and consciously accessible, is not reliant on scene contexts, and is not enhanced by explicit memorization.
Similar content being viewed by others


Introduction
Our ability to recognize previously viewed pictures is remarkable. When tasked with memorizing large image sets, memory capacities consistently measure in the thousands, persist for great lengths of time, and exhibit remarkable specificity of content (Brady, Konkle, Alvarez, & Oliva, 2008; Konkle, Brady, Alvarez, & Oliva, 2010; Standing, 1973). However, in the bustling unpredictability of everyday life it is rarely the case that we benefit from the foresight and time for explicit memorization. Rather, critical decisions often rely on us accessing our incidental memory for items viewed for moments in time and outside the focus of our primary behavioral goals.
The study of incidental memory can be traced back to at least the 1930s (Silverman & Cason, 1934). Its interest in more contemporary research was sparked by the finding that implicit learning of contextual cues can guide spatial attention during visual search (Chun & Jiang, 1998, 2003). This, in turn, inspired comparisons between incidental and explicit encoding of visual scenes that revealed recognition memory capacity was sustained irrespective of memorization procedure (Castelhano & Henderson, 2005; Williams, Henderson, & Zacks, 2005). These studies concluded that the mere perception of a scene was sufficient to form detailed representations in long-term memory. However, the precise relationship between incidental memory and consciousness remains elusive. For example, if one assumes a strong association between working memory and consciousness (Baars & Franklin, 2003; Baddeley, 2003), one might expect that incidental memory should be strongly limited in sustained conscious access due to the severe capacity restrictions of these memory systems (Luck & Vogel, 1997; Simons & Levin, 1997).
In a previous study, we explored the relationship between incidental memory and consciousness (Kaunitz, Rowe, & Tsuchiya, 2016). We demonstrated reliable discrimination of upright distractor faces that had been briefly fixated but rejected as a target during an attention-demanding visual search. In that study, we tracked subjects’ fixations while they moved their eyes to find a target face in a crowd scene as quickly as possible. If subjects found the target within a narrow time window (3–5 s), they performed an incidental memory task, discriminating between a previously unseen, foil face cropped from the original photograph and a probe face that had been fixated but rejected during the preceding visual search. We found that incidental memories for upright faces exhibit impressive capacity and clarity. These memories extend to at least seven intervening faces, are robust to the masking qualities of saccadic eye-movements, and, critically, are associated with above-chance metacognitive accuracy. Metacognitive accuracy is a marker of conscious access that highlights the functional quality of incidental memory (Matthews, Schröder, Kaunitz, van Boxtel, & Tsuchiya, 2018; Nelson, 1996). In contrast, when the same procedure was applied to inverted scenes, incidental memory for inverted, distractor faces was limited to between three and five items, within the traditional limits associated with visual short-term memory (Luck & Vogel, 1997). A critical differentiation between our previous study of incidental memory (Kaunitz et al., 2016) and those that demonstrate massive capacity for explicit memory (Brady et al., 2008; Konkle et al., 2010; Standing, 1973) was our use of the visual search paradigm. Subjects freely scanned each photograph trying to find a target face (which was never the target for the memory task). While this procedure is a natural reflection of how we might use incidental memory in everyday life, two specific features of visual search might limit us from generalizing the claim that incidental memory has sustained conscious access: (1) the self-directed nature of visual search, and (2) the semantic coherency of natural scenes.
First, visual search with overt eye movements is an inherently self-directed, active process, and benefits from preattentive processing as well as the processing associated with selective attention and conscious agency. The link between selective attention and visual working memory is documented so frequently that some have proposed they share cognitive mechanisms (Awh & Jonides, 2001; Awh, Vogel, & Oh, 2006; Gazzaley & Nobre, 2012; Theeuwes, Belopolsky, & Olivers, 2009; Woodman & Luck, 2004). These proposals extend more broadly to arguments that equate working memory with consciousness (Baars & Franklin, 2003; Baddeley, 2003). Given this, it is plausible that the self-directed nature of overt visual search reinforces incidental memories and might underlie their metacognitive access.
Second, visual search is supported by the semantic coherency of natural scenes. Humans can recognize the gist of a novel image with a single glance (Oliva & Torralba, 2006). While the precise depth of the image representation is debated, growing evidence suggests that human subjects accumulate information within a visual scene in long-term memory across fixational eye movements (Henderson, 2005; Hollingworth & Henderson, 2002). As a consequence, they form a detailed representation of the scene and gain enhanced recognition both for objects explicitly memorized from natural scenes as well as those incidentally viewed (Beck, Peterson, Boot, Vomela, & Kramer, 2006; Castelhano & Henderson, 2005). Given this, it is plausible that the semantic coherency of natural scenes might enhance the capacity of incidental memories during visual search.
While the distinction between incidental and explicit memory has been explored in considerable depth for visual search (Beck et al., 2006; Castelhano & Henderson, 2005; Varakin, Frye, & Mayfield, 2012; Varakin & Hale, 2014), it has only rarely been studied in passive, eye-movement constrained tasks. Early studies that projected items in sequence, obviating eye-movements, found that incidental memory discrimination was comparable to explicit memorization only when certain categories of stimuli were used such as faces or familiar objects (Bird, 1976; Bower & Karlin, 1974; Cohen, 1973). Similarly, a more recent study found that distractors related to the target of search by category or color were associated with enhanced incidental memory performance (Williams, 2010). While this body of work raises a possibility that stimulus categories might influence incidental memory, to what extent this is true for rapidly presented stimuli remains an open question.
Indeed, in these studies that removed visual search, stimuli were unmasked and presented up to several seconds at a time. And, while subjects were not informed that their incidental memory would be tested, to limit this sense of anticipation it was necessary that encoding and testing of items was separated by indistinct passages of time and hundreds of other stimuli. Likewise, those studies that demonstrate massive capacity for explicit memory also displayed stimuli for 3–10 s per image (Brady et al., 2008; Konkle et al., 2010; Standing, 1973; Standing, Conezio, & Haber, 1970). Presentation intervals such as these encourage rehearsal, rendering these studies of long-term rather than short-term memory.
Furthermore, previous studies have failed to characterize to what extent different memory types are supported by conscious access. Accurate metacognitive judgment about incidental memory (i.e., if you know you remember it) rules out the possibility that incidental memory is purely implicit (see a related argument on visual sensory memory in (Vandenbroucke et al., 2014)). Such evidence implies that incidental memory serves a functional role in everyday life through voluntary conscious access. Despite its potential importance, there have been no studies, to our knowledge, that characterize the degree of conscious access to incidental memory and examine whether this changes when subjects employ explicit memorization.
Our paper addresses these topics, examining performance and metacognitive access of incidental and explicit memory for rapidly presented upright and inverted faces at fixation. We examined faces due to their uniform size, high subcategory variability, and susceptibility to configural disruption as a result of the face inversion effect (Freire, Lee, & Symons, 2000) but return to the question of generalizability in the General discussion. We conducted our investigation in two parts: Firstly, with the behavioral results of psychophysical experiments and secondly, by examining the influence of stimulus categories on memory performance and metacognitive access.
In two experiments, we used the Rapid Serial Visual Presentation (RSVP) paradigm to control eye movements and precise stimulus timing. We tested incidental memory using a dual-task design to maximize the number of trials for behavioral and category analysis. Subjects searched for a target face as their primary task and, if the target face was successfully identified, discriminated between a novel, foil face and probe face that appeared as a distractor in the preceding sequence. Subjects could anticipate this test of incidental memory because it followed on every (correct) trial but attention to this task was partial at most since we enforced a brief time window (740 ms) for the primary task (ensuring it was difficult) and displayed a startling feedback screen in the case of target misses or errors (ensuring participants were motivated to perform the primary task optimally). In Experiment 1, we contrasted incidental memory for faces in upright and inverted orientation without self-directed visual search. Faces were drawn from a single crowd-scene photograph per trial. In Experiment 2, we intermixed faces from multiple crowd photographs to further reduce the influence of scene-related, semantic coherency. We then contrasted incidental memory with an explicit memory condition where target search was removed and subjects were told to remember all faces from the trial.
In our category analysis section we examined how trial-by-trial correctness and confidence are impacted by semantic features of faces. Specifically, we examined the impact of similarity, characterized here by stimuli sharing categories (e.g., gender, race, age). We achieved this first at the level of item (e.g., target and probe faces both being the same gender) and second at the level of sequence (e.g., the probe face being a different race from the majority of faces in the trial).
General method
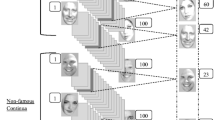
Both experiments included faces cropped from natural, crowd-scene photographs used in Kaunitz et al. ( 2016). We employed the RSVP paradigm to control eye movements. This paradigm presents rapid sequences of visual information at a central fixation (Potter, 1976; Spence & Witkowski, 2013). The difference between experiments was the arrangement of face stimuli and task instructions. In Experiment 1, each trial included faces from a single, crowd-scene photograph in either upright or inverted orientation (Fig. 1a). Because all faces within a trial came from the same scene, we describe this stimulus condition as within-scene. In many cases, in a given photograph, there was a noticeable and strong correlation in facial features among the faces. For example, if a photo was from an elementary school graduation in an Asian country, the faces were almost exclusively populated by young, Asian faces. In Experiment 2, to limit the influence of semantic coherency and contextual cues we used across-scene stimuli. We achieved this by including faces from multiple photographs per trial, contrasting upright (Exp. 2a: Fig. 1b) and inverted faces (Exp. 2b: Fig. 1c) as a between-subjects factor.

Task design for all experiments. In the incidental memory condition (top row in a, b, and c), subjects identified a target face amongst a rapid-stream of eight to 15 distractor faces. Subjects were required to detect the target face within a 740 ms time window and received a startling feedback screen if they made a detection error or miss. If the target was successfully identified, subjects proceeded to the secondary Probe Task. Subjects selected between a probe face that had been presented but rejected during the stream and a novel foil face that had not been presented before and did not appear in subsequent trials. Subjects registered their decision and confidence with a single 8AFC mouse-click. The probe and target were separated by varying lags (n-1, n-3, n-5, or n-7); all figures in a, b, and c show examples of n-5 trials. In the explicit memory condition (b, c), subjects tried to remember all faces in the sequence and proceeded directly to the Probe Task. In the within-scene condition (a) faces were selected from one crowd photograph. In the across-scene condition (b, c) faces were selected from many photographs. Task-relevant faces (i.e., targets, probes, and foils) were only seen in a single trial per experiment.
Our incidental memory condition employed a dual-task design. Subjects searched for a target face as their primary task, requiring as fast and accurate a response as possible (see Target task below). Provided the primary task was successful, subjects then discriminated probe faces as a secondary task. We enforced task priority by allowing only a short time window for target detection and giving feedback on the primary but not the secondary task. Responses to probe faces served as a test for incidental memory (see Probe task). In Experiments 2a and 2b, we included an explicit memory condition. This was achieved by removing the Target Task and instructing subjects to remember all faces from the trial. On these trials, no target face was shown. Instead, subjects actively memorized each face and discriminated between the probe and previously unseen, foil face.
Subjects
Thirty-four subjects with normal or corrected-to-normal vision completed the experiments (18 males and 16 females, ages 19–31 years). For statistical power we collected data from 12 subjects per experiment. Subject numbers were based on our previous study (Kaunitz et al., 2016). There, a large effect size (d >0.8) was obtained when examining the difference between upright and inverted conditions even with small sample sizes (N < 4). Subjects were recruited from the staff and student body of Monash University. Each subject received $20 per 1-h session. The present study received ethical approval; and subjects gave informed, written consent in accordance with the Monash University Human Research Ethics Committee.
The same 12 subjects participated in both upright and inverted versions of Experiment 1 (Fig. 1a, b), with six subjects completing the upright version first. For Experiment 2, 12 subjects completed both the incidental and explicit memory tasks in upright orientation (Exp. 2a: Fig. 1c,d), with six subjects performing the explicit memory version first. Two subjects who had taken part in Experiment 1 also completed Experiment 2a. A final 12 new subjects were recruited to complete the incidental and explicit memory tasks in inverted orientation (Exp. 2b: Fig. 1e, f), with six subjects performing the explicit version first.
Apparatus
All experiments were performed on a MacBook Pro laptop connected to a 22-in. SMI monitor located approximately 60 cm from the subject. The monitor was set with its refresh rate at 60 Hz and its screen resolution at 1,680 x 1,050 pixels. All experiments were programmed and conducted using the Psychophysics toolbox extension (Psychtoolbox-3) for MATLAB (Brainard, 1997).
Face stimuli were adapted from Kaunitz et al. (Kaunitz et al., 2016). These were 200 photographs of crowds (graduation ceremonies, bleachers, etc.) that were downloaded from the internet, gray-scaled, and rescaled into 1,100 x 768 pixels. Among 200 photos, we manually selected 160 of them that had many high-resolution unobstructed faces. All task-relevant faces (Target, Probe, and Foil) were individually cropped from the original photograph into 101 x 101 pixel squares. Task-irrelevant distractor faces were taken from the same set of 160 photos as the task-relevant faces.
Among all available faces, we selected faces that were largely unobstructed and predominantly forward facing with key features associated with visual classification (i.e., eyes, nose, mouth) visible. In some cropped face stimuli, facial features of another person could be seen but the central face dominated. Overall, we selected 4,225 faces from an initial pool of 5,006 in the 160 photos.
Procedure
Our RSVP paradigm proceeded as follows (see Fig. 1a). First, a randomly selected image of a target face was displayed for 3,000 ms. Second, a sequence of 8–15 faces was presented with each image displayed for 200 ms and followed by another one after an 80-ms blank interstimulus interval (ISI). These parameters (i.e., 200 and 80 ms) approximate the fixation and saccade duration during visual search (Kaunitz et al., 2016).
Subjects completed two sessions, with each session comprised of four blocks. Each block of 40 trials was followed by a short break. Task-relevant faces (i.e., targets, probes, and foils) were only presented on a single trial across an entire experiment. The remaining task-irrelevant faces appeared only once within a session of 160 trials (approximately 2,400 faces total) but could reappear between sessions. Thus some untested distractors used in the first session were presented in the second (approximately 20% of task-irrelevant faces). Counterbalancing of temporal positions of the probe (n-1, n-3, n-5, and n-7) and sequence length (8–15) was performed within each block. In total, subjects completed 320 trials per experiment.
Target task
Subjects were asked to click the left mouse button as fast and accurately as possible, when the target face image appeared in the RSVP sequence. To ensure sufficient attentive focus on this primary task, we imposed a narrow time window of 740 ms starting from 100 ms after the onset of the target. This time window included the target presentation, two subsequent faces, and three ISIs. We regarded mouse clicks that occurred within the target time window as “hit” and before as “false alarm” (only 137 instances of a < 100-ms response were registered across all experiments). If no click were recorded by the end of the window, we regarded the trials as “miss.”
As an extra reinforcement for the primary task, we employed a startling feedback screen if subjects made a target detection error. Upon false alarms or misses, subjects received feedback in the form of a full-screen flashing alert that cycled between yellow, red, and black at 12 Hz for approximately 500 ms. This reminded subjects that the target detection task had to be prioritized and discouraged subjects from devoting undue attention to the probe task. We did not collect a response to the probe task if subjects made a target-detection error. Instead, subjects skipped the probe task and continued to the next trial.
Probe task
If the target was successfully identified within the time window, subjects proceeded to the probe task; a test of incidental memory. This task involved discriminating between a previously unseen “foil” face image and a “probe” face image that was displayed during the sequence leading up to the target. The probe was the face displayed either n-1, n-3, n-5, or n-7 faces prior to the target in the incidental memory condition and relative to the final face in the trial sequence in the explicit memory condition.
On the response screen, the probe and foil face images were displayed centrally with their presentation side (i.e., left or right) randomized in each trial. A response square surrounded the probe and foil faces. The response square comprised of eight evenly split segments, four each for the probe and foil (Fig. 1), which corresponded to four confidence levels. This response screen allowed subjects to register their 2AFC discrimination report as well as confidence in this decision with a single mouse click. Prior to the experiment, and during practice, subjects were verbally instructed to express their confidence on a scale from a complete guess (rating 1) to certainty (rating 4). Verbal descriptors for judgments of 2 or 3 were not made explicit; however, the experimenter encouraged subjects to fix these confidence criterions across the two sessions and use all four confidence levels. The labels “sure” and “not sure” were displayed at the top and bottom of the screen to remind subjects of the confidence scale.
Behavioral analysis
Methods
Objective performance: Type 1 AUC
We adopted signal detection theory to estimate subjects’ objective discrimination accuracy and calculate Type 1 performance (Kaunitz et al., 2016; Macmillan & Creelman, 2004; Matthews et al., 2018). To construct a Type 1 receiver operating characteristics (ROC) curve, we regarded a trial in which the probe face was presented on the left side of the response square as a signal-present trial and classified the response as a hit or miss. If the probe face appeared on the right side of the response square it was regarded as signal-absent and classified as a correct rejection or false alarm. We shifted the criterion in seven steps to obtain a seven-inflection ROC curve. For signal-present trials at the first inflection, if subjects chose a face on the left side with the highest confidence (4) we classified the response as a hit and as a miss otherwise. Likewise for signal-absent trials, if subjects chose a face on the left with the highest confidence the response was classified as a false alarm and as a correct rejection otherwise. We shifted the criterion at the second inflection, if subjects chose a face on the left side with confidence ratings of 4 or 3 they were classified as hits and false alarms. We repeated this procedure until confidence ratings from 4 to 1 on the left and 1 to 3 on the right were classified as hits and false alarms. Thus, the proportion of hits and false alarms was computed for seven possible criteria resulting in a ROC curve with seven inflection points. The area under this seven-inflection ROC curve (Type 1 AUC) was then computed to provide a non-parametric estimate of objective accuracy (Kaunitz et al., 2016; Matthews et al., 2018).
Metacognitive accuracy: Type 2 AUC
To examine whether subjects identified the probe using information accessible to consciousness, we used Type 2 signal detection to assess metacognitive accuracy. We first categorized trials as correct or incorrect. Correct responses were those where subjects made a signal-present response for a signal-present trial or a signal-absent response for a signal-absent trial, regardless of the level of confidence. Otherwise, we regarded that trial as incorrect.
Trials were then classified according to confidence using the procedure above to shift the criterion in three steps and construct a three-inflection ROC curve. First, we regarded a correct trial (regardless of the side of the probe face) with confidence rating of 4 as a (metacognitive) hit and a miss otherwise. Likewise, we regarded an incorrect trial with confidence 4 as a false alarm and correct rejection otherwise. For the second criterion, correct trials with confidence of 4 or 3 were classified as hits and incorrect trials with confidence of 4 or 3 as false alarms. In the third criterion, these conventions were applied to confidence ratings of 4, 3, or 2. The proportion of hits and false alarms was computed for three possible criteria resulting in a ROC curve with three inflection points. The area under this three-inflection ROC curve (Type 2 AUC) was then adopted as a non-parametric estimate of metacognitive accuracy (Kaunitz et al., 2016; Matthews et al., 2018).
Linear mixed effect modeling
We used linear mixed effect (LME) analysis in MATLAB to examine the effects of various factors on objective and subjective AUCs. In Experiment 1, Type 1 AUC and Type 2 AUC were each modeled as dependent variables with the fixed effects of image orientation and temporal lag of the probe relative to the target (i.e., n-1, n-3, n-5, or n-7). In Experiment 2, LME analysis was conducted separately for upright and inverted orientation. Type 1 AUC and Type 2 AUC were each modeled as a function of the fixed effects of memory condition (incidental or explicit) and probe lag (relative to the target for the incidental memory condition or the final face in the sequence for the explicit memory condition). As a significance test, we performed likelihood ratio tests between full models containing both factors and reduced models excluding each factor of interest. In all models, random intercepts were defined for each subject with random slopes for each fixed effect (Barr, Levy, Scheepers, & Tily, 2013). Examination of residual plots did not reveal any deviations from homoscedasticity or normality.
To examine the relationship between confidence, correctness, and our factors of interest we used all trials from each experiment without averaging over block or stream length. Confidence rating was modeled as a function of orientation (in Experiment 1) or memory condition (in Experiment 2) along with probe lag, correctness, and their interactions. Interaction effects were tested by examining full models including interaction against simplified models with additive effects only. In the case of significant interactions, we subset data by each factor level and performed likelihood ratio tests between full models that included the factor of interest and a null model that excluded that factor.
Results
Objective performance (Type 1 AUC)
We discarded trials in which the target face was not correctly identified (see General methods). In Experiment 1, this yielded an average of 80.7% (SEM=2.4%) valid trials in the upright condition and 73.1% (SEM=2.8%) in the inverted condition. In the incidental memory condition of Experiment 2, an average of 88.3% (SEM=1.8%) trials were valid in the upright faces (Experiment 2a) and 83.9% (SEM=1.7%) in the inverted faces (Experiment 2b).
Results with Type 1 AUC are summarized in Fig. 2. In Experiment 1 (Fig. 2a), objective performance (Type 1 AUC) for probe faces presented in upright orientation (M=.69, SEM=.02) was significantly greater than inverted orientation (M=.60, SEM=.02) revealed by a main effect of face orientation in our likelihood ratio analysis (χ2(1)=16.5, p<.001). Similarly, we observed a significant main effect of probe lag (χ2(3)=12.4, p=.01). Tukey-Kramer adjusted post hoc comparisons confirmed that for both upright and inverted faces, probe discrimination was significantly greater at n-1 lag than the other lags (all p<.01). No significant differences were observed between the other lags (all p>.25). Two-tailed t-tests with Holm-Bonferroni correction were used to compare Type 1 AUC performance against chance (AUC > 0.5) at each probe lag for both upright and inverted orientation. Performance remained significantly greater than chance in all instances.

Objective performance (Type 1 AUC) as a function of orientation, probe lag, and memory condition for Experiments 1 and 2. Upright triangles with solid lines reflect trials with upright faces (Exp. 1 and Exp. 2a). Inverted triangles with dotted lines represent trials with inverted faces (Exp. 1 and Exp. 2b). Error bars are 95% confidence intervals
In Experiment 2a (Fig. 2 in red), which used upright faces, likelihood ratio tests revealed a significant interaction between memory condition (explicit vs. implicit) and probe lag position (χ2(3)=9.1, p=.03). Subsetting by each probe lag revealed that objective performance did not differ significantly between memory conditions in any but the n-7 lag (χ2(1)=4.7, p=.03) suggesting that explicit and incidental memory strategies were broadly equivalent for probe discrimination. The main effect of lag was highly significant when subsetting by each memory condition (both p<.001). Type 1 AUC remained significantly greater than chance in all cases (all p<.001).
In Experiment 2b (Fig. 2 in blue), which used inverted faces, the interaction between memory condition and probe lag did not reach significance (χ2(3)=3.8, p>.25) and objective performance did not differ significantly between the memory conditions (χ2(1)=3.5, p=.06). In contrast, the main effect of lag was highly significant (χ2(3)=24.8, p<.001) with performance significantly greater than chance in all cases (all p<.01).
Confidence
Results of confidence rating are summarized in Fig. 3. In Experiment 1 (Fig. 3a and d), likelihood ratio tests revealed that confidence levels were significantly influenced by probe lag (χ2(3)=13.4, p<.01) and correctness of the response (χ2(1)=15.8, p<.001) (in Fig. 3, filled symbols for correct and empty symbols for incorrect trials). However, they were not influenced by face orientation (χ2(1)=.1, p>.25) (in Fig. 3, upper (a, b, c) and lower (d, e, f) panels show the results for upright and inverted faces, respectively). The interaction between orientation and correctness was significant (χ2(1)=6.0, p=.01), with confidence ratings being more separated between correct and incorrect responses in the upright condition versus the inverted condition. Further, the interaction between lag and correctness was also significant (χ2(3)=8.9, p=.03), with confidence ratings being more separated between correct and incorrect responses for shorter lags. In contrast, the interactions between orientation and lag (χ2(3)=7.6, p=.05) and the 3-way interaction (χ2(6)=8.9, p=.18) did not reach significance.

Confidence as a function of face orientation, probe lag, memory condition, and correctness for Experiments 1 and 2. Filled triangles reflect correct discrimination and unfilled triangles incorrect discrimination. Upright triangles and solid lines represent trials with upright faces, while inverted triangles and dotted lines reflect trials with inverted faces. Error bars are 95% confidence intervals.
In Experiment 2a (Fig. 3b and c) with upright faces, we observed significant main effects of lag (χ2(3)=13.9, p<.01) and correctness (χ2(1)=20.9, p<.001) but not memory condition (χ2(1)=.6, p>.25). A significant interaction between lag and correctness was observed (χ2(3)=11.7, p<.01) such that shorter lags were associated with greater separation between correct and incorrect responses. To examine the nature of the interaction, we subset data by correctness or lag. For each lag we observed a significant main effect of correctness (all p<.001) such that correct judgments were associated with higher confidence. In contrast, subsetting by correct and incorrect judgments revealed a significant main effect of lag for correct judgments (χ2(3)=87.6, p<.001) but not incorrect judgments (χ2(3)=3.7, p>.25). The remaining 2-way interactions and the 3-way interaction did not reach significance (all p>.25).
We observed the same pattern of results for Experiment 2b (Fig. 3e and f) with inverted faces; significant main effects of lag (χ2(3)=17.9, p<.001) and correctness (χ2(1)=25.0, p<.001) but not memory condition (χ2(1)=.01, p>.25). The interaction between lag and correctness was significant (χ2(3)=10.9, p=.01), which comes from a significant main effect of correctness such that correct judgments were associated with higher confidence at each lag (all p<.001). Subsetting by correctness, lag had a significant effect on confidence ratings for correct judgments (χ2(3)=45.9, p<.001) but not incorrect judgments (χ2(3)=2.4, p>.25). The remaining interactions did not reach significance (all p>.07).
Overall, confidence ratings were higher for correct than incorrect trials, implying accurate metacognition, through all probe lags. Interestingly, more recent faces were rated more confidently only in the context of correct discrimination.
Metacognitive accuracy: Type 2 AUC
Results of metacognitive accuracy are summarized in Fig. 4. In Experiment 1, metacognitive accuracy was above chance (i.e., Type 2 AUC = 0.5) for all probe lags and face orientations (each p<.05) except n-3 lag for inverted faces (t(11)=1.6, p=.13). We observed no main effects of orientation or probe lag nor any interaction (all p>.15) which suggests metacognitive accuracy was broadly equivalent between the conditions.

Metacognitive accuracy (Type 2 AUC) as a function of face orientation, probe lag, and memory condition for Experiments 1 and 2. Upright triangles with solid lines represent upright face trials (Exp.1 and Exp. 2a). Inverted triangles and dotted lines are inverted face trials (Exp. 1 and Exp. 2b). Error bars are 95% confidence intervals
In Experiment 2a and 2b we observed similar results; metacognitive accuracy was significantly greater than chance for all probe lags, face orientations and memory conditions (all p<.05). No main effect of memory condition was found for either upright or inverted faces (χ2(1)=0.7, p>.25 and χ2(1)=2.0, p=.16 respectively). The main effect of lag was not significant for upright faces (χ2(3)=6.7, p=.08), however, it did reach significance for inverted faces (χ2(3)=8.7, p=.03). Tukey-Kramer adjusted post hoc comparisons for inverted faces pooling across memory conditions confirmed that metacognitive accuracy at n-1 lag was significantly greater than n-5 (p=.02) but the remaining contrasts did not reach significance (all p>.05).
Summary of behavioral analysis
In Experiment 1, we built upon our previous study (Kaunitz et al., 2016) using the RSVP paradigm to remove the influence of self-directed visual search and overt eye movements. On each trial, faces were presented from a single, crowd scene photograph and face orientation was contrasted within-subjects. Our findings confirm that a large capacity of conscious, incidental memory for faces is not reliant on overt visual search.
In Experiment 2 we further removed the influence of semantic coherency by intermixing faces across scenes. Objective performance (Fig. 2a, b), confidence (Fig. 3a, b, d, e), and metacognitive accuracy (Fig. 4a, b) did not differ markedly between Experiments 1 and 2, despite differences in semantic coherency. Thus we conclude that semantic coherency among faces is not critical for incidental memory. Although face inversion was associated with a minor cost to objective performance (see Fig. 2), both objective performance and metacognitive accuracy remained significantly greater than chance for almost all probe lags in both upright (Exp. 2a) and inverted (Exp. 2b) orientation.
The second purpose of Experiment 2 was contrasting incidental memory with explicit memorization. Whether subjects were instructed to remember all faces from a given trial (explicit memory) or were engaged in a concurrent target detection task (incidental memory) made almost no difference for their capacity to discriminate probe faces. Objective performance, confidence, and metacognitive accuracy were broadly equivalent between memory conditions.
Category analysis
How is it possible that incidental memory is so similar to explicit memory in RSVP, as shown in Experiment 2? Williams (2010) examined this question in a series of experiments on long-term memory. Objects were presented in sequence at a central fixation and subjects either tried to memorize all of the objects or to search for a specific target (by counting its occurence). After presentation of 2 x 32 trial sequences (384 unique objects displayed twice for a total of 768 stimulus presentations), a series of 2AFC discrimination tests were performed. These tests were either unprompted or announced to the subject ahead of time. In their study, knowledge that a test would follow had no effect on memory. However, a secondary finding from this study was that searching for specific targets (e.g., a white car) impaired the memory of distractors unrelated to that target (e.g., a red door). Conversely, searching for a target did not affect memory for distractors that shared a category with the search target. Putting aside questions of face expertise (see General discussion) in the following analysis, we tested if our finding of equivalent performance between incidental and explicit memory may be partly explained by effects of similarity and dissimilarity between faces. A related consideration is the influence of similarity between the probe face and the sequence of distractor faces on each trial. In visual search, target discrimination can be predicted purely as a function of shared semantic features between targets and distractors in the scene (Mohan & Arun, 2012). Likewise, target stimuli (such as objects) in RSVP are known to receive enhanced encoding if preceded by semantically related items (Harris, Benito, & Dux, 2010; Maki, Frigen, & Paulson, 1997). Given this, it is possible that successful probe discrimination may be partly explained by similarity between the probe and the sequence of distractors on each trial.
We performed a category analysis to examine the influence of similarity on trial-by-trial correctness and confidence. First, we considered item effects; how probe discrimination is influenced when the target of search, probes, and foils either share or do not share semantic features (e.g., the target and probe being the same gender). Second, we considered sequence effects; how probe discrimination is influenced by the number of items in the preceding sequence that are similar or dissimilar to the probe or foil.
Methods
Ratings
Independent raters categorized each of the 4,225 faces used in our behavioral experiments. Categories included perceived gender (female; male; other), race (Asian; Black; White), and age (youth; adult; senior). A low-level feature of each face was also rated, size (small; medium; large), reflecting the scale of the face relative to the image. These categories were selected due to their visual salience.
A custom script was programmed in MATLAB to expedite the rating procedure. Each face was displayed in randomised order on a gray background. Raters were tasked with categorizing a single feature at a time (e.g., gender) and input their rating using the number keys 0, 1, or 2. Once a rating was made, the sequence progressed. In case of typographical errors, pressing the backspace key displayed the preceding face in the sequence. Raters were encouraged to prioritise the speed of categorization rather than accuracy, reflecting the implicit categorizations subjects might make in our experiments. Inter-rater reliability was high across all four categories; gender (94.6%, three raters), race (91.5%, two raters), age (79.6%, two raters), and size (82.1%, two raters). To obtain average ratings for the ordinal categories age and size we computed a mean rating between raters (disagreement results in scores that differ by 0.5 as in Fig. 5a). For gender we used the mode of the three raters and for race we subset those with rating disagreement into a fourth level: “mixed race”.

Effects of item dissimilarity on accuracy of probe discrimination. (a-c) Mean probe accuracy as a function of dissimilarity (i.e., a dissimilarity score of 0 reflects categorically identical stimuli) for cumulative difference between the (a) target-probe, (b) target-foil, and (c) probe-foil. Error bars reflect standard error of the mean between-subjects. Lines are predicted response accuracy according to GLME models with their 95% confidence interval indicated by the shaded region. (d-f) Bars reflect the fixed effect estimates for each category (gender, race, age, and size) in the discrete model of dissimilarity on trial-by-trial correctness. Significance is determined by likelihood ratio tests (*=p<.05, **=p<.01, ***=p<.001)
Modeling item and sequence effects
We operationally defined our item level effect as the influence on probe task performance due to dissimilarity between the target and probe face categories. For our nominal categories gender and race, difference could vary from 0 to 1. The age and size categories were ordinal so varied from 0 to 2 (i.e., a senior target face vs. a youth probe face was a difference of 2). This method was repeated for dissimilarity between the target and foil as well as probe and foil.
We defined our sequence level effect as the influence on probe task performance due to statistics accumulated across the sequence of faces in each trial. For that purpose, we computed the negative log likelihood of each category in the trial. Specifically, we counted the appearances of a particular category (n) and the total number of faces in a given trial (N), then took the negative natural log of this value (-loge(n/N)); which we call surprise. Surprise varied from 0 (that is, n=N and -loge(1) = 0: a case where all the faces in the trial are in the same category and perfectly expected) to approximately 3 (that is, n/N=1/15, -loge(1/15) = 2.7: a case where a face had a unique category in the trial and was highly unexpected). We computed surprise for the probe and the foil for each category in each trial.
See Supplemental Fig. 1 for an example of face category rating plus dissimilarity and surprise analysis.
Mixed effect modeling
Item and sequence effects on trial-by-trial correctness were examined using generalized mixed effect modeling. This was achieved with binomial logistic regression within the LME4 package in R (Bates, Mächler, Bolker, & Walker, 2015). Trial-by-trial confidence ratings were first subset by correctness and then examined using linear mixed effect modeling also in R.
Since the item effect dissimilarity was characterized as the difference between targets, probes or foils, we performed the analysis on valid trials only (i.e., the trials with a correct target detection within the time window; 12,508 trials in total). We did not analyze the trials from the explicit memory condition in Experiment 2 because there was no target in this condition. As the dependent variables (DVs), we used trial-by-trial correctness or confidence rating subset by accuracy. Two models were computed for each DV; a cumulative model to test effects of overall dissimilarity between targets, probes, and foils, and a discrete model to test the significance of each category independently. In the cumulative model, the unweighted sum of dissimilarity for all categories was computed to determine overall dissimilarity between target versus probe, target versus foil, plus probe versus foil (three fixed effects in total: see Supplemental Fig. 1). In the discrete model, dissimilarity in gender, race, age, and size between the target versus probe, target versus foil, as well as the probe versus foil were included (12 fixed effects in total).We computed the sequence effect surprise for the probe and foil using all valid trials of the incidental memory condition and all trials in the explicit memory condition (20,188 in total). Trial-by-trial correctness and confidence subset by accuracy were each modeled using cumulative and discrete models. Random intercepts were included per subject for both dissimilarity and surprise effects. Assumptions of multicollinearity were not violated for the above analyses as measured by variance inflation factors. Significance was determined using likelihood ratio tests against models excluding each factor of interest.
Results
Item dissimilarity effect
For trial-by-trial correctness in our cumulative model, we observed a significant negative correlation with target-probe dissimilarity (Fig. 5a: χ2(1)=37.7, p<.001), a significant positive correlation with target-foil dissimilarity (Fig. 5b: χ2(1)=26.1, p<.001), and a weaker positive correlation with probe-foil dissimilarity (Fig. 5c: χ2(1)=4.6, p=.03). No interactions were observed (all p>.25). These results imply that a probe was more likely to be selected if it was a similar category to the target, dissimilar to the foil, or if the foil itself was dissimilar to the target.
For our discrete model of trial-by-trial correctness, significant negative correlations were found for target-probe dissimilarity (Fig. 5d): gender (χ2(1)=16.8, p<.001), race (χ2(1)=22.1, p<.001), and age (χ2(1)=4.1, p=.04). Significant positive effects for target-foil dissimilarities were also found (Fig. 5e): race (χ2(1)=30.9, p<.001) and size (χ2(1)=7.6, p=.01). No significant effects of discrete probe-foil dissimilarity were observed (Fig. 5f). These results imply that a probe face was more likely to be selected if it was a similar gender, race, or age to the target face. Conversely, a probe face was less likely to be selected if the target and foil face were a similar race or size.
For response confidence subset by accuracy in our cumulative model, no significant effects of target-probe dissimilarity were found for either correct or incorrect discriminations, (Fig. 6a: each p>.25). Likewise, no significant effects of target-foil dissimilarity were observed (Fig. 6b: each p>.25). However, we observed a significant positive effect of probe-foil dissimilarity for correct judgments (Fig. 6c: χ2(1)=5.5, p=.02). This result implies that when subjects correctly selected the probe, their confidence in that choice was higher on average if the probe and foil face were dissimilar.

Effects of item dissimilarity on confidence in discrimination subsetting by response accuracy. (a-c) Mean confidence subset by accuracy (filled=correct, empty=incorrect) as a function of dissimilarity for cumulative difference between (a) target-probe, (b) target-foil, and (c) probe-foil. Error bars reflect standard error of the mean between subjects. Lines are predicted confidence according to LME models, with their 95% confidence interval indicated by the shaded region. (d-f) Bars reflect the fixed effect estimates for each category (gender, race, age, and size) in the discrete models of dissimilarity on confidence for correct and incorrect trials (filled and empty respectively). Significance is determined by likelihood ratio tests (*=p<.05, **=p<.01, ***=p<.001)
Our discrete model of confidence subset by accuracy elucidated this result. No effect was significant for target-probe or target-foil dissimilarity (all p>.05, Fig. 6d and e). Significant positive correlations of probe-foil dissimilarity were observed for race when correct (χ2(1)=6.6, p=.01) but also when incorrect (χ2(1)=4.1, p=.04) and for gender for correct responses (χ2(1)=6.5, p=.01). These results imply that when subjects correctly selected the probe, their confidence in that choice was higher on average if the probe and foil faces were a different gender. Moreover, independent of response accuracy, subjects’ confidence in their choice was higher on average if the probe and foil faces were a different race.
Sequence surprise effect
For trial-by-trial correctness in our cumulative model, we found significant negative correlation with probe surprise (Fig. 7a: χ2(1)=31.7, p<.001) and positive correlation with foil surprise (Fig. 7b: χ2(1)=52.7, p<.001). These results imply that a probe face was less likely to be selected if it was dissimilar to many faces in the trial sequence surrounding it (i.e., the probe was surprising). Conversely, the probe face was more likely to be selected if the foil face was surprising.

Effects of surprise on trial-by-trial correctness. (a, b) Mean probe accuracy as a function of binned cumulative surprise for the (a) probe, and (b) foil. Error bars reflect standard error of the mean between subjects. Lines are predicted accuracy from each GLME model with their 95% confidence interval shaded. (c,d) Bars reflect the fixed effect estimates for each category (gender, race, age, and size) in the discrete models of surprise on trial-by-trial correctness. Significance is determined by likelihood ratio tests (*=p<.05, **=p<.01, ***=p<.001)
For trial-by-trial correctness in our discrete model, we found significant negative correlations with probe surprise (Fig. 7c) in gender (χ2(1)=22.2, p<.001), race (χ2(1)=11.0, p<.001), and size (χ2(1)=7.2, p<.01) and positive correlations with foil surprise (Fig. 7d) in gender (χ2(1)=25.1, p<.001), race (χ2(1)=27.1, p<.001), and size (χ2(1)=16.7, p<.001). These results imply that a probe face was less likely to be selected if its gender, race, or size was surprising. Conversely, a probe face was more likely to be selected if the gender, race, or size of the foil face was surprising.
For confidence subset by accuracy in our cumulative model, we found a significant negative correlation with foil surprise (Fig. 8b) for incorrect trials (χ2(1)=10.3, p=.001) but not for correct trials, and no significant effects for probe surprise (Fig. 8a and b, all p>.25). These results imply that when subjects’ probe response was incorrect (i.e., they selected the foil), their confidence in that choice was lower on average if the foil was surprising.

Effects of surprise on trial-by-trial confidence subset by accuracy. (a, b) Mean confidence subset by accuracy (filled=correct, empty=incorrect) as a function of binned cumulative surprise for the (a) probe, and (b) foil. Error bars reflect standard error of the mean between subjects. Lines are predicted confidence by the LME models with their 95% confidence interval shaded. (c,d) Bars reflect the fixed effect estimates for each category (gender, race, age, and size) in the discrete models of surprise on trial-by-trial confidence subset by accuracy (filled=correct, empty=incorrect). Significance is determined by likelihood ratio tests (*=p<.05, **=p<.01, ***=p<.001)
In our discrete model of confidence subset by accuracy, we found significant negative correlation with probe surprise for gender in correct trials (Fig. 8c: χ2(1)=5.3, p=.02) and with foil surprise (Fig. 8d) for gender (χ2(1)=8.8, p<.01) and race (χ2(1)=4.1, p=.04) in incorrect trials. These results imply that when subjects’ probe response was correct, their confidence in that choice was lower on average if the gender of the probe was surprising. Conversely, when subjects’ probe response was incorrect (i.e., they selected the foil), their confidence in that choice was lower on average if the gender or race of the foil was surprising.
General discussion
We reveal that incidental memory for rapidly presented faces is consciously accessible and sustained, while not dependent on overt visual search or the semantic coherency of features within a single photograph. Across two experiments, we used RSVP to minimize overt eye movements and contextual whole-scene cues, plus limited stimulus viewing times by presenting stimuli for only 200 ms. Although the incidental memory test could be anticipated, we required that subjects engage their attention in a demanding target detection task (Fig. 1) and only analyzed incidental memory when target detection was successful. We tested memory performance and metacognitive accuracy for incidentally viewed probe items and, in the same subjects, contrasted this with an explicit memory condition where subjects actively memorized each item using full attention. To get insight into what mechanisms support memory, our category analysis examined how trial-by-trial accuracy and confidence is affected by faces sharing semantic features (i.e., gender, race, age, size). We examined the influence of similarity between the probe, target, and foil faces (the item effect) and the influence of similarity between the probe (or the foil) and the sequence of distractor faces that surround it (the sequence effect).
Our key results were: (1) subjects exhibit sustained objective memory and metacognitive access for upright and inverted faces seen for the first time and presented for only 200 ms up to seven items prior to an unrelated target; (2) in terms of measures of performance, confidence, and metacognitive accuracy, incidental memory and explicit memorization were broadly equivalent (Figs. 2, 3, and 4); and, (3) that trial-by-trial accuracy is strongly influenced by both item and sequence effects (Figs. 5 and 7), but these same effects have very little or no influence on trial-by-trial confidence ratings (Figs. 6 and 8).
Sustained conscious memory for incidental probes in RSVP
The act of self-directed, visual search involves two processes that reinforce incidental memory. First, incidental memory during active eye movements might be enhanced by overlapping neural mechanism for overt attention and working memory (Awh & Jonides, 2001; Awh et al., 2006; Gazzaley & Nobre, 2012). Second, incidental memory during visual search for an object in a scene can also be enhanced through semantic coherence of that scene, which is known to improve detection speed and recognition both for targets and incidentally-viewed objects (Beck et al., 2006; Castelhano & Heaven, 2010; Castelhano & Henderson, 2005). Given this, it was conceivable that the remarkable capacity and metacognitive access observed for incidentally-viewed probes in our previous visual search study was contingent on the act of visual search itself (Kaunitz et al., 2016). However, even when we eliminated overt eye movements using RSVP and minimized the influence of within-scene contextual cues, we still demonstrate that short-term incidental memory is sustained and consciously accessible.
There was one major difference between the results of our studies. Previously we found that incidental memory for inverted scenes had a limited capacity, while here we found sustained incidental memory for inverted faces (although upright faces had an advantage). Inversion of faces is known to disrupt the locations that people fixate upon them (Barton, Radcliffe, Cherkasova, Edelman, & Intriligator, 2006; Hills, Cooper, & Pake, 2013; Hills, Sullivan, & Pake, 2012). Although inversion of scenes (rather than faces) is much less studied, recent research has demonstrated that scene inversion disrupts subjects’ capacity to foveate targets and expected target locations (Koehler & Eckstein, 2015). Given this, we surmise that fixations were not optimized for inverted scenes in our previous study (Kaunitz et al., 2016) while it was optimized in our RSVP design (due to the fixed location of stimulus presentation), which may explain the discordance in incidental memory for inverted faces. Moreover, our current study examined the effects of orientation and lag position within-subjects. This design is especially important for analyzing confidence ratings and metacognitive accuracy as these measures are vulnerable to individual differences (Fleming, Weil, Nagy, Dolan, & Rees, 2010; Song et al., 2011).
What is the likelihood that our results generalize for stimuli other than faces? Incidental memory has been demonstrated for a range of objects in long-term memory and visual search (Castelhano & Henderson, 2005; Williams, 2010). The finding that short-term incidental memory capacity is sustained for upright and even inverted faces suggests incidental memory does not rely on holistic processing and might generalize beyond faces. In extending this paradigm to other categories of stimuli, the possibility remains that examining memory for one type of object might induce effects that would not be found otherwise. One such example is recognition-induced forgetting (Maxcey & Woodman, 2014). Here, when different visual stimuli are encoded into long-term memory, practice with a particular subset of those items impairs memory for related but unpracticed items when compared to unrelated baseline stimuli from the same encoding period. Recognition-induced forgetting has been demonstrated for race categories in faces such that rehearsing white faces impairs recognition for unrehearsed white faces but not those in the baseline group (black faces) (Rugo, Tamler, Woodman, & Maxcey, 2017). Future research might examine these factors in short-term incidental memory by balancing categories across the stimulus set. Moreover, these studies might employ our metacognitive measures to examine whether effects such as recognition-induced forgetting are consciously accessible.
Incidental and explicit memorization are broadly equivalent in RSVP
Incidental and explicit memorization instructions have been explored using the visual search paradigm. These studies find that explicit memorization guides spatial attention but makes little difference for recognition from long-term memory (Castelhano & Henderson, 2005; Varakin et al., 2012; Varakin & Hale, 2014) and only marginally improves recognition in tests of short-term memory (Beck et al., 2006). Our study here extends these results to a situation where eye movements are constrained and stimuli are only briefly presented (200 ms). In this situation, our measures of performance and metacognitive accuracy were broadly equivalent in the same subjects between memorization conditions (Figs. 2, 3, and 4). In particular, our finding of above-chance metacognitive accuracy suggests these representations are accessible to consciousness without explicit attentional amplification.
One caveat to this claim is our subjects were aware that their memory for incidental probes might be tested. This is quite unlike previous studies of incidental, long-term memory that presented subjects with an unexpected memory test after all stimuli had been viewed and contrasted performance with an intentional memory experiment where different subjects were informed that memory tests would follow (Bird, 1976; Castelhano & Henderson, 2005; Williams, 2010). While the above studies have certain advantages (e.g., removing the anticipation of a memory test), this design severely limits the number of test trials and examines memory conditions between-subjects. In contrast, our RSVP design generated a very large set of within-subject data which allowed us to perform detailed analysis of the categories of targets, probes and distractors plus account for individual differences in performance, confidence ratings, and metacognitive accuracy. Though subjects in our design could anticipate questions about probe items, they could not direct full attention to these items because we imposed a short time window for target detection and provided startling feedback if subjects made target detection errors. Further, we only analyzed incidental probe memory on trials where subjects correctly detected the target. Thus, our results can be taken to reveal the nature of incidental, short-term memory for items that are anticipated, at most, but not explicitly memorized. Future research employing our design might further reduce this sense of anticipation by only testing incidental memory on a limited subset of trials.
Shared semantic features affect trial-by-trial accuracy but not confidence
Semantic features related to the target of visual search are known to guide saccades (Pomplun, 2006; Shen, Reingold, Pomplun, & Williams, 2003; Wu, Wick, & Pomplun, 2014) and improve accuracy for the rapid categorization of natural scenes (Fabre-Thorpe, 2011). The influence of semantic features have also been found when eye movements are constrained; recognition is enhanced for objects that share categories with a target (Bower & Karlin, 1974; Williams, 2010). Given this, it was possible that searching for a specific target face in our incidental memory task might enhance the encoding of probe faces from similar categories. This is an important consideration because a corresponding effect on metacognitive accuracy raises a possibility that semantic association may also enhance sustained conscious access to incidental memory.
Our item effect category analysis supports the claim that searching for a specific target improves recognition. Probes or foils that shared categories with the target (e.g., gender or race) were selected as a response alternative more frequently (Fig. 5). However, this item effect had very little to no impact on trial-by-trial confidence ratings (Fig. 6). Were metacognitive judgments supported by similarity with a target, we would expect confidence to be enhanced in the case of similarity and diminished in the case of dissimilarity. With respect to the cognitive structure of incidental memory and its relationship to consciousness, this result implies that it may not be necessary to consciously reflect on certain stimulus features for them to be encoded, processed, and then accurately retrieved by declarative conscious access. This position is supported by recent evidence that metacognitive conscious access is possible for certain complex stimuli with little or even no selective attention (Matthews et al., 2018). Thus, we conclude that sustained conscious access to incidental memory is not related to those mechanisms that drive semantic association and likely arises as a natural product of perception.
Relatedly, it is possible that trial sequences dominated by a particular category of face may reinforce the encoding of probes from that category. This point is informed by behavioral and neuroscientific studies that demonstrate enhanced processing of target faces if they are preceded by semantically related faces; an effect tied to associative priming (Schweinberger, Pfütze, & Sommer, 1995; Vladeanu, Lewis, & Ellis, 2006). Our sequence effect category analysis revealed that the categories of faces presented in a trial does influence performance. Specifically, trial-by-trial correctness is affected by how surprising a probe or foil is relative to the sequence of faces that precede it; correctness is lower for surprising probes and higher when the foil is surprising (Fig. 7).
This result supports the claim that trial sequences dominated by particular categories can associatively prime incidental memory for items of a related category. However, this sequence effect had very little impact on trial-by-trial confidence ratings (Fig. 8). Only in the case of incorrect judgments (i.e., selecting a foil) were subjects’ confidence ratings lower as a function of surprise (e.g., a male foil preceded by a sequence of predominantly female faces; see Fig. 8b,d). Were metacognitive judgments biased by associative priming from trial sequences, we would expect the effects observed for trial-by-trial correctness to correspond with confidence ratings but this was not the case. Thus, we conclude that shared semantic features in a trial sequence have little, if any, influence on sustained conscious access to faces.
Conclusion
Using RSVP we reveal that incidental memory for upright and inverted faces is sustained and consciously accessible independent from self-directed visual search, explicit memorization, or the influences of semantic priming from targets and distractors.
It is appealing to think that our subjective efforts to attend and memorize the world are an important feature in us remembering it. Indeed, some researchers have suggested that short-term memory is strongly dependent or even subsumed by attentional mechanisms (Awh & Jonides, 2001; Awh et al., 2006; Gazzaley & Nobre, 2012). However, our findings build on evidence from visual long-term memory (Varakin et al., 2012; Varakin & Hale, 2014) that the mere act of perception may be enough to form sustained and consciously accessible memories with no or little attentional amplification (Block, 2011; Lamme, 2016). Attentional amplification might prove important for the massive capacities of visual long-term memory (Brady et al., 2008; Konkle et al., 2010; Standing, 1973) but in elucidating the mechanics of conscious experience, future research might be best served prioritizing the remarkable properties of perception.
Change history
21 February 2019
In this issue, there is an error in the citation information on the opening page of each article HTML. The year of publication should be 2019 instead of 2001. The Publisher regrets this error.
References
Awh, E., & Jonides, J. (2001). Overlapping mechanisms of attention and spatial working memory. Trends in Cognitive Sciences, 5(3), 119–126.
Awh, E., Vogel, E. K., & Oh, S.-H. (2006). Interactions between attention and working memory. Neuroscience , 139(1), 201–208.
Baars, B. J., & Franklin, S. (2003). How conscious experience and working memory interact. Trends in Cognitive Sciences, 7(4), 166–172.
Baddeley, A. (2003). Working memory: Looking back and looking forward. Nature Reviews. Neuroscience, 4(10), 829–839.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68(3). https://doi.org/10.1016/j.jml.2012.11.001
Barton, J. J. S., Radcliffe, N., Cherkasova, M. V., Edelman, J., & Intriligator, J. M. (2006). Information processing during face recognition: The effects of familiarity, inversion, and morphing on scanning fixations. Perception, 35(8), 1089–1105.
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software, 67(1). https://doi.org/10.18637/jss.v067.i01
Beck, M. R., Peterson, M. S., Boot, W. R., Vomela, M., & Kramer, A. F. (2006). Explicit memory for rejected distractors during visual search. Visual Cognition, 14(2), 150–174.
Bird, J. E. (1976). Effects of intentional and incidental instructions on picture recognition. Perceptual and Motor Skills, 42(2), 555–561.
Block, N. (2011). Perceptual consciousness overflows cognitive access. Trends in Cognitive Sciences, 15(12), 567–575.
Bower, G. H., & Karlin, M. B. (1974). Depth of processing pictures of faces and recognition memory. Journal of Experimental Psychology, 103(4), 751–757.
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences of the United States of America, 105(38), 14325–14329.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10(4), 433–436.
Castelhano, M., & Heaven, C. (2010). The relative contribution of scene context and target features to visual search in scenes. Attention, Perception & Psychophysics, 72(5), 1283–1297.
Castelhano, M., & Henderson, J. (2005). Incidental visual memory for objects in scenes. Visual Cognition, 12(6), 1017–1040.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36(1), 28–71.
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 29(2), 224–234.
Cohen, G. (1973). How are pictures registered in memory? The Quarterly Journal of Experimental Psychology, 25(4), 557–564.
Fabre-Thorpe, M. (2011). The characteristics and limits of rapid visual categorization. Frontiers in Psychology, 2, 243.
Fleming, S. M., Weil, R. S., Nagy, Z., Dolan, R. J., & Rees, G. (2010). Relating introspective accuracy to individual differences in brain structure. Science, 329(5998), 1541–1543.
Freire, A., Lee, K., & Symons, L. A. (2000). The face-inversion effect as a deficit in the encoding of configural information: Direct evidence. Perception, 29(2), 159–170.
Gazzaley, A., & Nobre, A. C. (2012). Top-down modulation: Bridging selective attention and working memory. Trends in Cognitive Sciences, 16(2), 129–135.
Harris, I. M., Benito, C. T., & Dux, P. E. (2010). Priming from distractors in rapid serial visual presentation is modulated by image properties and attention. Journal of Experimental Psychology. Human Perception and Performance, 36(6), 1595–1608.
Henderson, J. (2005). Introduction to real-world scene perception. Visual Cognition, 12(6), 849–851.
Hills, P. J., Cooper, R. E., & Pake, J. M. (2013). First fixations in face processing: The more diagnostic they are the smaller the face-inversion effect. Acta Psychologica, 142(2), 211–219.
Hills, P. J., Sullivan, A. J., & Pake, J. M. (2012). Aberrant first fixations when looking at inverted faces in various poses: The result of the centre-of-gravity effect? British Journal of Psychology , 103(4), 520–538.
Hollingworth, A., & Henderson, J. M. (2002). Accurate visual memory for previously attended objects in natural scenes. Journal of Experimental Psychology. Human Perception and Performance, 28(1), 113–136.
Kaunitz, L. N., Rowe, E. G., & Tsuchiya, N. (2016). Large capacity of conscious access for incidental memories in natural scenes. Psychological Science, 27(9), 1266–1277.
Koehler, K., & Eckstein, M. P. (2015). Scene inversion slows the rejection of false positives through saccade exploration during search. In D. C. Noelle, R. Dale, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.), Proceedings of the 37th Annual Meeting of the Cognitive Science Society (pp. 1141–1146). Austin, TX: Cognitive Science Society.
Konkle, T., Brady, T. F., Alvarez, G. A., & Oliva, A. (2010). Scene memory is more detailed than you think: The role of categories in visual long-term memory. Psychological Science, 21(11), 1551–1556.
Lamme, V. (2016). The crack of dawn: Perceptual functions and neural mechanisms that mark the transition from unconscious processing to conscious vision. In T. Metzinger & J. W. Windt (Eds.), Open MIND. Frankfurt am Main: MIND Group.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390(6657), 279–281.
Macmillan, N. A., & Creelman, C. D. (2004). Detection theory: A user’s guide. New York: Psychology Press.
Maki, W. S., Frigen, K., & Paulson, K. (1997). Associative priming by targets and distractors during rapid serial visual presentation: Does word meaning survive the attentional blink? Journal of Experimental Psychology. Human Perception and Performance, 23(4), 1014–1034.
Matthews, J., Schröder, P., Kaunitz, L., van Boxtel, J. J. A., & Tsuchiya, N. (2018). Conscious access in the near absence of attention: Critical extensions on the dual-task paradigm. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 373(1755). https://doi.org/10.1098/rstb.2017.0352
Maxcey, A. M., & Woodman, G. F. (2014). Forgetting induced by recognition of visual images. Visual Cognition, 22(6), 789–808.
Mohan, K., & Arun, S. P. (2012). Similarity relations in visual search predict rapid visual categorization. Journal of Vision, 12(11), 19.
Nelson, T. O. (1996). Consciousness and metacognition. The American Psychologist, 51(2), 102.
Oliva, A., & Torralba, A. (2006). Building the gist of a scene: The role of global image features in recognition. Progress in Brain Research, 155, 23–36.
Pomplun, M. (2006). Saccadic selectivity in complex visual search displays. Vision Research, 46(12), 1886–1900.
Potter, M. C. (1976). Short-term conceptual memory for pictures. Journal of Experimental Psychology: Human Learning and Memory, 2(5), 509–522.
Rugo, K. F., Tamler, K. N., Woodman, G. F., & Maxcey, A. M. (2017). Recognition-induced forgetting of faces in visual long-term memory. Attention, Perception & Psychophysics, 79(7), 1878–1885.
Schweinberger, S. R., Pfütze, E.-M., & Sommer, W. (1995). Repetition priming and associative priming of face recognition: Evidence from event-related potentials. Journal of Experimental Psychology. Learning, Memory, and Cognition, 21(3), 722–736.
Shen, J., Reingold, E. M., Pomplun, M., & Williams, D. E. (2003). Saccadic selectivity during visual search. In J. Hyönä, R. Radach, & H. Deubel (Eds.), The mind’s eye: Cognitive and applied aspects of eye movement research (pp. 65–88). Amsterdam: Elsevier Science Publishers.
Silverman, A., & Cason, H. (1934). Incidental memory for pleasant, unpleasant, and indifferent words. The American Journal of Psychology, 46(2), 315–320.
Simons, D. J., & Levin, D. T. (1997). Change blindness. Trends in Cognitive Sciences, 1(7), 261–267.
Song, C., Kanai, R., Fleming, S. M., Weil, R. S., Schwarzkopf, D. S., & Rees, G. (2011). Relating inter-individual differences in metacognitive performance on different perceptual tasks. Consciousness and Cognition, 20(4), 1787–1792.
Spence, R., & Witkowski, M. (2013). Rapid serial visual presentation: Design for cognition. Springer.
Standing, L. (1973). Learning 10000 pictures. The Quarterly Journal of Experimental Psychology, 25(2), 207–222.
Standing, L., Conezio, J., & Haber, R. N. (1970). Perception and memory for pictures: Single-trial learning of 2500 visual stimuli. Psychonomic Science, 19(2), 73–74.
Theeuwes, J., Belopolsky, A., & Olivers, C. N. L. (2009). Interactions between working memory, attention and eye movements. Acta Psychologica, 132(2), 106–114.
Vandenbroucke, A. R. E., Sligte, I. G., Barrett, A. B., Seth, A. K., Fahrenfort, J. J., & Lamme, V. A. F. (2014). Accurate metacognition for visual sensory memory representations. Psychological Science, 25(4), 861–873.
Varakin, D. A., Frye, K. M., & Mayfield, B. (2012). Intentional memory instructions do not improve visual memory. International Journal of Brain and Cognitive Sciences, 1(3), 18–25.
Varakin, D. A., & Hale, J. (2014). Intentional memory instructions direct attention but do not enhance visual memory. SAGE Open, 4(4), 2158244014553588.
Vladeanu, M., Lewis, M., & Ellis, H. (2006). Associative priming in faces: Semantic relatedness or simple co-occurrence? Memory & Cognition, 34(5), 1091–1101.
Williams, C. C. (2010). Incidental and intentional visual memory: What memories are and are not affected by encoding tasks? Visual Cognition, 18(9), 1348–1367.
Williams, C. C., Henderson, J. M., & Zacks, R. T. (2005). Incidental visual memory for targets and distractors in visual search. Perception & Psychophysics, 67(5), 816–827.
Woodman, G. F., & Luck, S. J. (2004). Visual search is slowed when visuospatial working memory is occupied. Psychonomic Bulletin & Review, 11(2), 269–274.
Wu, C.-C., Wick, F. A., & Pomplun, M. (2014). Guidance of visual attention by semantic information in real-world scenes. Frontiers in Psychology, 5, 54.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Supplemental Fig. 1
(DOCX 161 KB)
Rights and permissions
About this article

Cite this article
Matthews, J., Wu, J., Corneille, V. et al. Sustained conscious access to incidental memories in RSVP. Atten Percept Psychophys 81, 188–204 (2019). https://doi.org/10.3758/s13414-018-1600-1
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1600-1