
Abstract
Recently, performance magic has become a source of insight into the processes underlying awareness. Magicians have highlighted a set of variables that can create moments of visual attentional suppression, which they call “off-beats.” One of these variables is akin to the phenomenon psychologists know as attentional entrainment. The current experiments, inspired by performance magic, explore the extent to which entrainment can occur across sensory modalities. Across two experiments using a difficult dot probe detection task, we find that the mere presence of an auditory rhythm can bias when visual attention is deployed, speeding responses to stimuli appearing in phase with the rhythm. However, the extent of this cross-modal influence is moderated by factors such as the speed of the entrainers and whether their frequency is increasing or decreasing. In Experiment 1, entrainment occurred for rhythms presented at .67 Hz, but not at 1.5 Hz. In Experiment 2, entrainment only occurred for rhythms that were slowing from 1.5 Hz to .67 Hz, not speeding. The results of these experiments challenge current models of temporal attention.
Similar content being viewed by others

Introduction
Upon the magician’s open palm sits a coin. He taps the coin once, twice, but by the third tap the small metal treasure has seemingly disappeared. The method is simple, but the effect is impressive: Before the magic wand strikes it a third time, the coin is thrown from the open palm into the hand holding the wand (Kaufman, 1989; see Supplementary Materials for video). By virtue of entraining the audience’s attention to the rhythmic tapping, the sleight (which occurs during the attentional “trough” between the second and third beats) goes unnoticed.
In order to develop techniques for deceiving the senses, magicians must have hypotheses about the processes underlying perception. Exploration of these hypotheses has shown promise as a means of advancing the laboratory study of attention and perception (Ekroll & Wagemans, 2016; Quian Quiroga, 2016; Rensink & Kuhn, 2015). Thus far, the most fruitful collaborations between magicians and scientists have been in the domains of spatial attention and inattentional blindness (Barnhart & Goldinger, 2014; Kuhn & Martinez, 2012; Kuhn & Teszka, 2015). Here, we argue that the study of attentional deployment in time provides an ideal springboard for the collaboration between magicians and cognitive scientists. The current experiments, while not directly testing techniques from magical performance, explore ideas that underlie their tactics.
(WMV 5234 kb)
Both magicians and cognitive scientists use the analogy of an attentional spotlight; however, this has led to a conceptualization of attention that is biased toward the visuo-spatial domain at the expense of temporal dimensions (Fernandez-Duque & Johnson, 1999; Levin & Saylor, 2008; Nobre & van Ede, 2017). On some level, magicians are aware that attention can be influenced by variables outside of the visuo-spatial domain. They regularly teach that sleight of hand should occur on the “off-beat,” a moment of attentional suppression, to evade detection (Kurtz, 1998; Lamont & Wiseman, 1999). Use of the term “off-beat” implies (1) that attention fluctuates over time, and (2) that its waxing and waning follows a regular time course, like the beats of a metronome.
One variable that magicians employ to create an off-beat is the instantiation of a rhythm to focus attention at predictable points in time while presumably relaxing attention at moments between beats, the strategy used in the vanishing coin trick (Lamont & Wiseman, 1999). The application of rhythmicity to influence attention is often conflated with other factors, in practice. For example, in a classic treatise on the psychology of magic, Dessoir (1893) noted that,
If we count ‘One! two! three!’ before the disappearance of an object, then the actual disappearance must take place before and not just at the ‘three’; for while the attention of the audience is fixed upon ‘three’ anything taking place at ‘one’ or ‘two’ entirely escapes it. (p. 3618)
This example (and the vanishing coin trick) seem to rely on multiple features of temporal expectation (Nobre & van Ede, 2017). While potentially exploiting rhythmicity, it also clearly relies on a strong association of events happening “on three.” Although explicit in the coin trick, implementation of rhythmic misdirection may not always be intentional on the part of the magician. In many cases, it may be a natural effect of using music or rhythmic patter to accompany the performance of magic, and magicians may unwittingly take advantage of the rhythms that are already present during performance.
While this intuition does not fit comfortably into many popular models of attention (Posner & Rothbart, 2007), it is in line with modern dynamic models that tend to focus on temporal over spatial aspects of attention (Large & Jones, 1999; Olivers & Meeter, 2008). The most notable of these is the Dynamic Attending Model (Large & Jones, 1999), which proposes that internal oscillations (or attending rhythms) can be influenced by rhythms ex vivo, such that the attending rhythms entrain to external sources, optimizing attentional resources in anticipation of future events. Attending rhythms are conceptualized as self-sustaining biological oscillations wherein a brief pulse of energy (generated from the external rhythm) can cause a phase shift, aligning one point in the oscillator’s limit cycle with the recurring environmental stimulus. In behavioral terms, the model suggests that attention is deployed as a series of “pulses” over time, with perceptual readiness tracking these pulses.
Laboratory examinations of attentional entrainment have produced results that support the dynamic attending model. Using a metacontrast masking procedure, Mathewson et al. (2010) found that detection rates for subtle visual targets increased when the targets were presented in phase with a visual, rhythmic entrainer. The behavioral outcome reported by Mathewson et al. has been observed repeatedly across both visual and auditory modalities (Hickok, Farahbod, & Saberi, 2015; Jones, Moynihan, MacKenzie, & Puente, 2002; Landau & Fries, 2012; Lawrance, Harper, Cooke, & Schnupp, 2014; Rohenkohl, Cravo, Wyart, & Nobre, 2012). Attention aligns to environmental rhythms as a means of optimizing perception of future events. While the transient deployment of attention in time can enhance stimulus processing, it also comes with a cost. Stimuli appearing at unpredictable time points (such as the tossing of the coin) are less apt to reach awareness.
Although the effects of attentional entrainment within modalities are well known, comparatively little research has assessed cross-modal entrainment, the anecdotal mechanisms that magicians exploit. The frequent covariation of visual and auditory rhythms in the environment should naturally lead to conditions of cross-modal entrainment, as the signal in one modality is highly predictive of the other (Jack & Thurlow, 1973; MacDonald & McGurk, 1978). Indeed, Escoffier, Sheng, and Schirmer (2010) found that participants were faster to make judgments about images that were presented with synchronous auditory rhythms, relative to asynchronous rhythms or silence, suggesting that the mere presence of auditory rhythms can entrain visual attention. Similarly, Miller, Carlson, and McAuley (2013) observed faster fixation times to dot probes aligned to a rhythm, relative to temporally misaligned probes. More recently, Jones (2015) explored cross-modal entrainment using a task with both spatial and temporal cues. Response times to report the location of a spatial target were independently influenced by spatial cueing and temporal cueing. Regardless of whether targets appeared in the cued location, detection was faster when they aligned with the period of a rhythmic cue preceding onset.
The foregoing cross-modal entrainment experiments all employed stimuli that easily captured attention. Thus, they were unable to examine differences in sensitivity to stimulation. As a consequence, it becomes difficult to assess whether entrainment facilitated stimulus detection or simply the execution of a motor response. Under conditions where visual information is noisy, entrainment should facilitate signal detection (not just preparedness for action) to stimuli appearing in phase with the rhythm. The experiments reported here were designed to assess whether entrainment to regular auditory rhythms leads to concurrent optimization of visual attention at coinciding time points. Furthermore, we assessed whether attention toward the rhythmic stimulus is necessary for entrainment effects to occur. Previous entrainment experiments in a single modality have shown that performance in time can be biased by the mere presence of entraining stimuli (Mathewson, Fabiani, Gratton, Beck, & Lleras, 2010). However, this previous work could not manipulate whether participants were attending to the rhythm because it was inextricably linked to stimuli in the primary task (but see Kizuk & Mathewson, 2017).
In the current experiments, entrainment was examined within simple auditory and visual stimulus monitoring tasks wherein the presentation of a subtle visual stimulus was either aligned or misaligned in time with the regularly occurring rhythm of an auditory stimulus stream. If entrainment operates across sensory modalities, visual perception should be more sensitive in moments when an auditory stimulus onset is expected than in the “off-beats” between auditory stimulus presentations.
Experiment 1: Cross-modal entrainment to auditory rhythms
Experiment 1 examined the effect of cross-modal entrainment on the detection of a subtle stimulus. We actively manipulated (between subjects) whether participants needed to attend to the auditory stream: Participants in the Attend Audio condition had to monitor for an oddball tone, while also reporting dot probes. We expected that, when a rhythm was available to one modality, attention would automatically entrain to that signal (regardless of attentional set) and would facilitate the detection of visual stimuli falling on the beat. This prediction follows from the observed tendency for oscillatory mechanisms in the brain to phase-lock across cortical regions (Lakatos, Karmos, Mehta, Ulbert, & Schroeder, 2008).
Method
Participants
Participants were 111 students recruited from Introductory Psychology courses at Arizona State University, all with normal or corrected-to-normal vision. There were 52 participants in the Attend Audio condition and 59 in the Ignore Audio condition. All volunteered for partial course credit. With a similar experimental design, Miller et al. (2013) observed a large entrainment effect (Cohen’s d = 1.6) with 20 participants, suggesting that the current experiment is adequately powered.
Materials and stimuli
Experiments were programmed using E-Prime 1.2 (Schneider, Eschman, & Zuccolotto, 2002) and data were collected on Gateway computers. Visual stimuli were presented on 16-in. flat-screen CRT monitors with refresh rates at 60 Hz. Responses were collected using PST serial response boxes. Auditory stimuli were delivered via Sennheiser HD280 headphones.
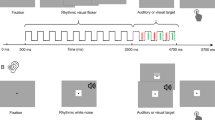
Auditory stimuli consisted of streams of 150-ms tones at 750 or 900 Hz. Although tone files did not ramp up/down, there was no perceivable clicking artifact in the stimuli. In half the trials, 750Hz tones were used as entraining stimuli; 900Hz tones were used in the other half. In trials with 750 Hz entrainers, the 900 Hz tones were oddball stimuli, and vice versa. Entraining tones were presented at one of two rates, manipulated within-subjects. On fast trials, tones were presented every 650 ms (roughly 1.5 Hz). On slow trials, tones were presented every 1,500 ms (.67 Hz). Visual stimuli consisted of three background images created using Adobe Photoshop (see Fig. 1). The images were generated as 1,024 × 768 pixels to fill the computer screen. In each image, the color value for every pixel was selected randomly, creating a field of visual noise. Six dot probe stimuli were created in a similar fashion. Each dot probe was a 30 × 30 pixel square (roughly 3° visual angle), generated using the same random pixel color procedure as the background images. Then, a yellow field with 95 % transparency was overlaid upon the probe so that it could be discriminated from the background noise. Background and dot probe stimuli were randomly sampled from this pool on every trial.

Depictions of the colored noise display before (A) and after (B) dot probe onset. The location of the dot probe is highlighted in panel C. Example stimuli are not to scale
Procedure
All procedures were approved by the Arizona State University Institutional Review Board. After obtaining informed consent, participants completed six practice trials (half fast, half slow) followed by 108 experimental trials. In each trial, participants heard a stream of auditory tones while they monitored a visual field of colored noise for the onset of a transient dot probe. Participants in Attend Audio condition actively monitored the auditory stream to detect an oddball stimulus. Participants in the Ignore Audio condition heard the same auditory sequences, but were not directed to monitor for oddballs. Participants pressed the right-most button on the response box to report detection of dot probes, and those in the Attend Audio condition pressed the left-most response box button upon detecting auditory oddballs.
Each trial lasted 19.5 s (13 tones at the slow rate; 30 tones at the fast rate), but trials were blocked into 36 groups of three (each block at the same entrainment rate) with no explicit boundaries between trials. Thus, participants perceived each trial as lasting 58.5 s. Within each block they encountered one auditory oddball and three visual dot-probes (one per trial). The position of the auditory oddball trial in each block (trial 1, trial 2, or trial 3) was randomized across blocks. Within the auditory oddball trials, the dissimilar tone could appear at one of two positions within the stream, following the first third or preceding the final third of the entraining tones (also selected randomly).
The primary visual attention task was adapted from Klein (1988). On each trial, dot probes appeared overlaid on the background of colored noise in one of nine randomly-selected positions in a 3 × 3 grid measuring 624 × 442 pixels, with a random amount of jitter (up to ±50 pixels) added about the X and Y axes. Dot probes appeared at one of three temporal positions relative to the entraining tones in each trial (counterbalanced across trials): following the first quarter of entraining tones, at the midpoint of the auditory stream, or before the final quarter of entraining tones. Within each block of three trials, the onset of the dot probe was temporally aligned with the onset of an entraining tone on one trial, offset by 25 % of the entraining frequency on one trial, and offset by 50 % of the entraining frequency on one trial (with the order randomized across blocks). Dot probes disappeared 500 ms after their onset regardless of whether participants responded with a button-press, and only one dot probe response was accepted on each trial. No other variables were manipulated or measured.
Results
Eleven participants were excluded from analyses (eight from the Attend Audio condition; three from Ignore Audio condition). Six were excluded from Attend Audio for average rates of oddball detection >2.5 standard deviations below the group mean. The remaining five participants were excluded for detecting dot probes at rates >2.5 standard deviations below their group means. Responses falling outside a 1,500 ms window following dot probe onset were classified as erroneous. This criterion led to the exclusion of 31.5 % of all trials from reaction time (RT) analyses (which included false-alarms occurring prior to the dot-probe onset). High error rates in this experiment (and the following experiments) precluded analysis via repeated-measures ANOVA, as many participants had at least one empty cell, and thus would be excluded by list-wise deletion. Consequently, all analyses reported were carried out through linear mixed-effects modeling (LMM), which regresses over missing values while also accounting for variance that arises from individual differences (Baayen, Davidson, & Bates, 2008). All analyses were carried out using R software (R Core Team, 2017) running the lme4 package (Bates, Maechler, Bolker, & Walker, 2015).
Reaction times
RTs from trials with accurate responses were log-transformed to counteract non-normality and conform with the assumptions of LMM. RTs were analyzed with Subject as a random effect and fixed effects of Audio Condition (attend audio, ignore audio), Tone Frequency (slow, fast), and Dot Probe Phase (on beat, off 25 %, off 50 %; dummy coded). The full model revealed a main effect of Audio Condition (β=-.05, SE=.02, t= -2.89, p= .004): RTs were significantly faster in the Ignore Audio condition than the Attend Audio condition. However, this factor did not interact with any others, and thus the model was simplified to exclude this factor. Figure 2 depicts untransformed RTs, including the partition by Audio Condition, for the sake of comparison. In the simplified model (see Table 1) RTs were significantly slower for dot probes falling 25 % off the beat (β=.01, SE=.007, t=2.39, p=.01) and 50 % off the beat (β=.02, SE=.007, t=2.97, p=.003) in the slow tone frequency condition. However, the model also produced an unexpected Tone Frequency by Dot Probe Phase interaction. In the fast frequency, dot probes appearing 25 % off the beat (β=-.02, SE=.01, t=-2,04, p=.04) and 50 % off the beat (β=-.02, SE=.01, t=-2.34, p=.02) elicited significantly faster RTs than those appearing on the beat.

Untransformed dot probe reaction times as a function of Audio Condition, Tone Frequency, and Dot Probe Phase. Error bars represent standard error of the mean
Accuracy
Probe detection accuracy rates were also analyzed via a LMM with Subject as a random effect and fixed effects of Audio Condition (attend audio, ignore audio), Tone Frequency (slow or fast), and Dot Probe Phase (on beat, off 25 %, off 50 %; dummy coded). However, there was no effect of condition so the model was simplified to exclude this effect. The simpler model (Table 2) revealed a significant main effect of Tone Frequency (β=.29, SE=.01, t=20.00, p<.001), with higher accuracy in the fast condition. In the slow condition, accuracy was significantly reduced for probes presented 25 % off the beat (β=-.04, SE=.01, t=-2.72, p=.006). Accuracy in the slow condition did not differ between probes presented on the beat or off by 50 %. Dot Probe Phase had no impact on accuracy in the fast condition (see Fig. 3).

Accuracy rates as a function of Audio Condition, Tone Frequency, and Dot Probe Phase
Discussion
Experiment 1 produced clear evidence of cross-modal attentional entrainment effects. Participants responded to dot probe onsets faster and with greater accuracy when they were aligned in time with the onset of an auditory stimulus in the rhythmic stream. However, the effects of attentional entrainment were only evident when the entraining rhythm was relatively slow. Lakatos and colleagues (Lakatos, Karmos, Mehta, Ulbert, & Schroeder, 2008; Lakatos, et al., 2005) suggested that the mechanisms underlying attentional entrainment should flexibly adapt to almost any rhythmic stimulus, as entrained neural oscillators modulate both the phase and amplitude of those in other frequency bands. It is possible that the faster entraining rhythm elicited a more vigilant mode of attending, whereas slow rhythms encourage periodic attentional optimization (Schroeder & Lakatos, 2008). The results of Experiment 1 highlight a limitation of the Large and Jones (1999, b) model, which cannot predict differences in entrainment across frequency bands (or within a frequency band, as was the case in Experiment 1).
Experiment 1 also produced a surprising outcome wherein dot probe detection accuracy rebounded for probes presented exactly between beats. Although this outcome was unpredicted, the rebound effect could be attributed to a few different sources. It could reflect the interplay of endogenous and exogenous influences on attentional deployment. Although attention should naturally entrain to the auditory rhythm, endogenous attentional control mechanisms could fight this tendency, attempting to enhance attention at moments when entrainment would push it to its lower limit. However, this hypothesis is relatively intractable, from an experimental standpoint. Perhaps a better explanation is provided by an experiment conducted by Gomez-Ramirez et al. (2011). They replicated and extended the work of Lakatos and colleagues (Lakatos, Karmos, Mehta, Ulbert, & Schroeder, 2008) by examining entrainment to one channel of an audio-visual stream at a rate of .67 Hz. While they observed significant entrainment to the rhythm, as evidenced by EEG amplitude peaks of a .67-Hz component, they observed peaks of a much higher power at the second harmonic, 1.33 Hz. The current experiment used .67-Hz entrainers, so a substantial second harmonic would fall exactly in between beats, and could have produced the observed rebound effect in accuracy rates.
An important outcome from Experiment 1 is that entrainment effects did not differ as a consequence of attentional set. Entrainment effects were still observed when the auditory stimuli required no attention at all, suggesting an automatic tendency to integrate information, however irrelevant, across sensory channels in service of generating predictions for perceptual optimization. Cross-modal entrainment is clearly adaptive within a dynamic (but often redundant) world. However, rhythms in the environment are rarely perfectly consistent, and sometimes change at varying rates (as with a horse beginning its gallop). Large and Jones (1999) took rhythmic variability into account: According to their model, attending rhythms will be able to accurately guide attention despite transient fluctuations around a mean frequency. The model also explicitly allows for entrainment to a rhythm that is broadly changing in frequency, so long as the change is consistent over time.
Currently, there is little evidence to suggest that attention can entrain to a changing rhythm. Furthermore, evidence (Cope, Grube, & Griffiths, 2012) seems to suggest the contrary pattern, that people anticipate future temporal events based almost exclusively on the most recent interval. When participants were asked to detect an out-of-place time interval in a changing rhythm, they were more likely to detect changes that exaggerated the pattern. Early tones were easier to detect in a speeding tempo, and late tones were easier to detect in a slowing tempo. Experiment 2 was designed to explore whether attention cross-modally entrains to a consistently changing rhythm, as is predicted by the Dynamic Attending Model (Large & Jones, 1999).
Experiment 2: Cross-modal entrainment to a changing rhythm
Experiment 2 used the same methodology as Experiment 1 to explore the effect of a changing rhythm on the deployment of attention. Participants were presented with consistently-changing (either speeding or slowing) auditory rhythms and were asked to detect visual targets presented on or off the beat. Although the Dynamic Attending Model (Large & Jones, 1999) predicts that attention will entrain to rhythms that change consistently over time, duration estimation experiments predict the failure of entrainment mechanisms (Cope, Grube, & Griffiths, 2012). If the model is correct, participants should be faster to report dot probes presented in phase with the rhythm, regardless of whether the rhythm is speeding or slowing. Cope et al. provide an alternative prediction. If participants over-rely on the previous interval in predicting tone onsets, probe detection should differ across tempo conditions. Participants in the speeding condition will deploy attention too late, missing stimulus onset if it is aligned with the rhythm, but detecting probes shifted off the rhythm. Conversely, participants in the slowing condition will anticipate the onset too early, but this will have the advantage of preparing them for the eventual onset moments later.
Method
Participants
Participants were recruited from the Psychological Science Department at Carthage College. A total of 52 participants were recruited (80.4 % female), with an average age of 19.7 years. All participants provided informed consent before the experiment and were compensated with course credit. There were 30 participants in the Attend Audio condition and 22 participants in the Ignore Audio condition.
Materials and stimuli
Experiments were programmed using E-Prime 2.0 software (Schneider, Eschman, & Zuccolotto, 2002), and data were collected on Lenovo 64-bit desktop computers with Intel Core i5 processors. Visual stimuli had the same dimensions and visual angles as Experiment 1, but were presented on 24-in. ASUS flat-screen LED monitors with refresh rates at 60 Hz. Responses were collected using PST Chronos response boxes. Auditory stimuli were delivered via headphones.
All stimuli were identical to those used in Experiment 1, but the inter-onset interval (IOI) of auditory stimuli was manipulated. Each trial consisted of 56 tones. Half of the trials contained speeding entrainers and half slowing entrainers. In speeding trials, IOIs reduced from 2,000 to 320 ms (from .5 Hz to 3.125 Hz) in 30-ms increments. Slowing trials consisted of the opposite: IOIs increased from 320 to 2,000 ms in 30-ms increments. Half of trials contained an auditory oddball at positions ¼, ½, or ¾ through the trial (selected randomly). Dot probes onsets could align with tone number 8, 16, 24, 32, 40, or 48, and the probe was presented in each temporal position three times throughout the experiment. For each temporal position, the phase of dot probe onset (on beat, 25 % off, 50 % off) was counterbalanced.
Procedure
All procedures were approved by the IRB at Carthage College. After providing informed consent, participants completed two practice trials (one speeding, one slowing) to acquaint them with the procedure. Participants pressed the rightmost response button when they detected the onset of dot probes. Participants in the Attend Audio condition were instructed to listen for auditory oddballs while monitoring for the dot probes, pressing the leftmost response button when they detected oddballs. Participants in the Ignore Audio condition experienced the same stimuli, but were told they could ignore the tones. There were 32 trials, fully counterbalancing tone rate, dot probe position, and dot probe phase. Throughout the experiment there were three forced, 30-s rest periods. No other variables were manipulated or measured.
Results
Data from three participants were excluded. Two participants in the Attend Audio condition failed to report any auditory oddballs. One participant in the Ignore Audio condition had a probe detection rate >2.5 standard deviations below the group mean.
Reaction times
Button-press responses detected within 1,500 ms of dot-probe onset were considered accurate, excluding 25.2 % of trials wherein responses fell outside this window. Accurate RTs were log transformed. RTs were analyzed in a LMM with Subject entered as a random effect and fixed effects of Audio Condition (attend audio, ignore audio), Entrainer Rate (speeding, slowing), and Dot Probe Phase (on beat, off 25 %, off 50 %; dummy coded). The full model revealed no main effect or interactions involving Audio Condition. Consequently, the model was simplified to exclude this factor. The simplified model (see Table 3) produced a significant effect of Entrainer Rate (β = -.03, SE = .01, t = -2.33, p = .02), with slower RTs elicited by speeding entrainers. However, this main effect was qualified by a reliable Entrainer Rate by Dot Probe Phase interaction (see Fig. 4). In the slowing condition, dot probes appearing 50 % off the beat were detected significantly slower than those appearing on the beat (β = .05, SE = .02, t = 2.98, p = .003), but RTs for probes appearing 25 % off the beat were not substantially slowed. The speeding condition produced the opposite pattern, with slower RTs elicited by probes appearing on the beat.

Untransformed dot probe detection reaction times (RTs) as a function of Entrainer Rate and Dot Probe Phase
Accuracy analyses
Probe detection accuracy was analyzed via a LMM with Subject entered as a random effect and fixed effects of Audio Condition (attend audio, ignore audio), Entrainer Rate (speeding, slowing), and Dot Probe Phase (on beat, off 25 %, off 50 %; dummy coded). There were no significant effects (see Table 4).
Discussion
The Results of Experiment 2 supported predictions derived from Cope et al. (2012), failing to conform with predictions from the Dynamic Attending Model (Large & Jones, 1999). Participants produced faster RTs for dot probes presented on the beat than off by 25 % or 50 % in the slowing condition, yet the opposite pattern appeared in the speeding condition. Cope et al. (2012) suggested that participants rely too heavily on the most recent IOI when evaluating time intervals between stimuli. Our results suggest the same occurs during attentional entrainment to a changing rhythm. Participants in the slowing condition deployed attentional resources too early, but still had resources deployed when the probe appeared later than anticipated. Participants in the speeding condition, on the other hand, deployed attention too late, thus being slower to detect targets on the beat, but fast for those that were delayed. This is the first time that this aspect of the Large and Jones (1999) model has been tested outside the domain of duration estimation, and the results cannot be explained by their theory in its current form.
General discussion
The present experiments were inspired by strategies employed by magicians to manipulate when an audience’s attention is deployed. While the phenomenon of attentional entrainment is well-known to psychologists, magicians almost exclusively exploit cross-modal entrainment, which is less well understood. Experiment 1 probed for cross-modal entrainment effects for a perfectly consistent, rhythmic auditory stimulus, finding the hallmarks of entrainment for tones presented at a slow (.67 Hz) but not fast (1.5 Hz) frequency. Participants were faster and more accurate to detect on-beat dot probes, regardless of whether they needed to attend to the auditory stream. The Large and Jones (1999) Dynamic Attending Model cannot account for variability in entrainment across frequencies, predicting that entrainment mechanisms will be able to adjust to any perceivable frequency.
Experiment 2 extended Experiment 1, examining whether attention can flexibly entrain to a rhythm that is changing in a consistent fashion, a prediction derived directly from Large and Jones (1999). Had we only included slowing entrainers, our outcome would have perfectly conformed to the predictions from the Dynamic Attending Model. However, when entrainers were speeding, the RT pattern flipped, with faster responding off the beat. The overall pattern is better explained by two imperfect mechanisms, working in tandem. The first mechanism is a process of attentional entrainment akin to that described by Large and Jones, wherein neural oscillations attempt to optimally align with coherent rhythms in the world. The second mechanisms adjusts the period of these oscillations to account for changes in the source rhythm, but does so in a liberal fashion. The updating mechanism relies too heavily on the most recent IOI, thus exaggerating the rate of change. This liberal updating leads to early deployment of attention with a slowing rhythm and late deployment with a speeding rhythm. Together, these mechanisms also proffer an explanation for why accelerating tempos are generally harder to detect than decelerating tempos (Repp & Keller, 2004; Jongsma, Meeuwissen, Vos, & Maes, 2007).
The Large and Jones (1999) model is agnostic to the range of frequencies for which entrainment should occur. However, research by Lakatos et al. (2005) suggests that, because oscillatory mechanisms have a nested structure, entrainment should occur for nearly all perceivable frequencies. While the entrainer frequencies used in Experiment 1 differed little from each other, we only found evidence of entrainment for those at the lower end of the spectrum. Further research is needed to assess why this discrepancy occurred. It is possible that the task demands of the fast entrainer condition encouraged participants to shift to a vigilant mode of attending. While the Large and Jones model also cannot account for the findings of Experiment 2, there are clear ways that the model could be revised to conform with the findings. Specifically, the model parameter that allows for adaptation of periodicity could be coupled more loosely with the signal and employ a feature that over-weights the most recent IOI.
The current work was designed to allow analyses both of accuracy and RT. However, in the design, errors could occur for multiple reasons that were not easily differentiated. Since only one response could be collected per trial, an early false alarm effectively nullified the entire trial. Participants may have detected the later probe, but their responses could not be collected. Consequently, analyses were more reliant on the stable collection of accurate RTs than on accuracy rates. Future research could remedy this limitation of the current work.
Attentional entrainment is one of many processes employed to predict the world around us. Information from different sensory modalities can be integrated (however imperfectly) to optimize and economize attention, but this can also leave us susceptible to the sleight of hand employed by magicians. Temporal attention is a domain in which both magicians and scientists have incomplete knowledge, making collaborative exploration potentially fruitful. The current work suggests that cross modal entrainment has a greater impact on RTs than detection for a stimulus that is actively searched for and expected. In the context of a magic show, the secret events may be searched for, but are typically unexpected, potentially increasing the impact of entrainment. The experiments reported here used pure tones as auditory entrainers. However, these were not likely to be the types of stimuli that the auditory cortex evolved to handle, as they do not appear in the natural world. Luo and Poeppel (2007) showed that neural oscillations play an important role in the parsing of speech sounds. Magicians may more effectively exploit entrainment by using rhythmic speech over other forms of rhythmic stimulation. However, for magicians who perform with music, selecting music with a clear, constant rhythm (at an optimal frequency) should have the greatest impact, especially when accompanied by other temporal and spatial attention cues. Moving forward, further exploration of the methods of magicians can, hopefully, highlight more unique quirks in our cognitive systems.
Author Note
This research was supported in part by NICHD Grant R01 HD075800-01 to Stephen D. Goldinger. Thanks to Kyle Mathewson, Gustav Kuhn, Dan Simons, Art Glenberg, Don Homa, and Craig Enders for advice on this project. Data and visual stimuli from these experiments are available at https://osf.io/fdv57/.
References
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59, 390-412. doi:https://doi.org/10.1016/j.jml.2007.12.005
Barnhart, A. S. & Goldinger, S. D. (2014). Blinded by magic: Eye-movements reveal the misdirection of attention. Frontiers in Psychology, 5, 1461. doi:https://doi.org/10.3389/fpsyg.2014.01461
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1-48. doi:https://doi.org/10.18637/jss.v067.i01
Cope, T., Grube, M., & Griffiths, T. (2012). Temporal predictions basedon a gradual change in tempo. Acoustical Society of America, 131, 4013-4022. doi:https://doi.org/10.1121/1.3699266
R Core Team. (2017). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.R-project.org/
Dessoir, M. (1893). The psychology of legerdemain III. The Open Court, 14(293), 3616-3619.
Ekroll, V. & Wagemans, J. (2016). Conjuring deceptions: Fooling the eye or fooling the mind? Trends in Cognitive Sciences, 20, 486-489. doi:https://doi.org/10.1016/j.tics.2016.04.006
Escoffier, N., Sheng, D. Y., & Schirmer, A. (2010). Unattended musical beats enhance visual processing. Acta Psychologica, 135, 12-16. doi:https://doi.org/10.1016/j.actpsy.2010.04.005
Fernandez-Duque, D. & Johnson, M. L. (1999). Attention metaphors: How metaphors guide the cognitive psychology of attention. Cognitive Science, 23, 83-116. doi:https://doi.org/10.1016/S0364-0213(99)80053-6
Gomez-Ramirez, M., Kelly, S. P., Molholm, S., Sehatpour, P., Schwartz, T. H., & Foxe, J. J. (2011). Oscillatory sensory selection mechanisms during intersensory attention to rhythmic auditory and visual inputs: A human electrocorticographic investigation. Journal of Neuroscience, 31, 18556-18567. doi:https://doi.org/10.1523/JNEUROSCI.2164-11.2011
Hickok, G., Farahbod, H., & Saberi, K. (2015). The rhythm of perception: Entrainment to acoustic rhythms induces subsequent perceptual oscillation. Psychological Science, 26, 1006-1013. doi:https://doi.org/10.1177/0956797615576533
Jack, C. E. & Thurlow, W. R. (1973). Effects of degree of visual association and angle of displacement on the "ventriloquism" effect. Perceptual and Motor Skills, 37, 967-979.
Jones, A. (2015). Independent effeccts of bottom-up temporal expectancy and top-down spatial attention. An audiovisual study using rhythmic cueing. Frontiers in Integrative Neuroscience, 8, 96. doi:https://doi.org/10.3389/fnint.2014.00096
Jones, M. R., Moynihan, H., MacKenzie, N., & Puente, J. (2002). Temporal aspects of stimulus-driven attending in dynamic arrays. Psychological Science, 13, 313-319. doi:https://doi.org/10.1111/1467-9280.00458
Jongsma, M., Meeuwissen, E., Vos, P., & Maes, R. (2007). Rhythm perception: Speeding up or slowing down affects different subcomponents of the ERP P3 complex. Biological Psychology, 75, 219-228. doi:https://doi.org/10.1016/j.biopsycho.2007.02.003
Kaufman, R. (1989). Williamson's Wonders. Kaufman and Greenberg.
Kizuk, S. A. & Mathewson, K. E. (2017). Power and phase of alpha oscillations reveal an interaction between spatial and temporal visual attention. Journal of Cognitive Neuroscience, 29, 480-494. doi:https://doi.org/10.1162/jocn_a_01058
Klein, R. (1988). Inhibitory tagging system facilitates visual search. Nature, 334, 430-431. doi:https://doi.org/10.1038/334430a0
Kuhn, G. & Martinez, L. M. (2012). Misdirection -- past, present, and the future. Frontiers in Human Neuroscience, 5, 1-7. doi:https://doi.org/10.3389/fnhum.2011.00172
Kuhn, G. & Teszka, R. (2015). Attention and misdirection: How to use conjuring experience to study attentional processes. In J. M. Fawcett, E. F. Risko, & A. Kingstone, The handbook of attention (pp. 503-525). Cambridge, Massachusetts: MIT Press.
Kurtz, G. (1998). Leading with your head: Psychological and directional keys to the amplification of the magic effect. Montreal: self-published.
Lakatos, P., Karmos, G., Mehta, A. D., Ulbert, I., & Schroeder, C. E. (2008). Entrainment of neuronal oscillations as a mechanism of attentional selection. Science, 320, 110-113. doi:https://doi.org/10.1126/science.1154735
Lakatos, P., Shah, A. S., Knuth, K. H., Ulbert, I., Karmos, G., & Schroeder, C. E. (2005). An oscillatory hierarchy controlling neuronal excitability and stimulus processing in the auditory cortex. Journal of Neurophysiology, 94, 1904-1911. doi:https://doi.org/10.1152/jn.00263.2005
Lamont, P. & Wiseman, R. (1999). Magic in theory: An introduction to the theoretical and psychological elements of conjuring. Hertfordshire: University of Hertfordshire Press.
Landau, A. N. & Fries, P. (2012). Attention samples stimuli rhythmically. Current Biology, 22, 1000-1004. doi:https://doi.org/10.1016/j.cub.2012.03.054
Large, E. W. & Jones, M. R. (1999). The dynamics of attending: How people track time-varying events. Psychological Review, 106, 119-159. doi:https://doi.org/10.1037/0033-295X.106.1.119
Lawrance, E. L., Harper, N. S., Cooke, J. E., & Schnupp, J. W. (2014). Temporal predictability enhances auditory detection. The Journal of the Acoustical Society of America, 135, EL357-EL363. doi:https://doi.org/10.1121/1.4879667
Levin, D. T. & Saylor, M. M. (2008). Shining spotlights, zooming lenses, grabbing hands, and pecking chickens: The ebb and flow of attention during events. In T. F. Shipley, & J. M. Zacks (Eds.), Understanding events (pp. 522-554). New York: Oxford University Press, Inc.
Luo, H. & Poeppel, D. (2007). Phase patterns of neuronal responses reliably discriminate speech in human auditory cortex. Neuron, 54, 1001-1010. doi:https://doi.org/10.1016/j.neuron.2007.06.004
MacDonald, J. & McGurk, H. (1978). Visual influences on speech perception processes. Perception & Psychophysics, 24, 253-257. doi:https://doi.org/10.3758/BF03206096
Mathewson, K. E., Fabiani, M., Gratton, G., Beck, D. M., & Lleras, A. (2010). Rescuing stimuli from invisibility: Inducing a momentary release from visual masking with pre-target entrainment. Cognition, 115, 186-191. doi:https://doi.org/10.1016/j.cognition.2009.11.010
Miller, J. E., Carlson, L. A., & McAuley, J. D. (2013). When what you hear influences when you see: Listening to an auditory rhythm influences the temporal allocation of visual attention. Psychological Science, 24, 11-18. doi:https://doi.org/10.1177/0956797612446707
Nobre, A. D. & van Ede, F. (2017). Anticipated moments: Temporal structure in attention. Nature Reviews Neuroscience, Advance online publication. doi:https://doi.org/10.1038/nrn.2017.141
Olivers, C. N. & Meeter, M. (2008). A boost and bounce theory of temporal attention. Psychological Review, 115, 836-863. doi:https://doi.org/10.1037/a0013395
Posner, M. I. & Rothbart, M. K. (2007). Research on attention networks as a model for the integration of psychological science. Annual Review of Psychology, 58, 1-23. doi:https://doi.org/10.1146/annurev.psych.58.110405.085516
Quian Quiroga, R. (2016). Magic and cognitive neuroscience. Current Biology, 26, R390-R394. doi:https://doi.org/10.1016/j.cub.2016.03.061
Rensink, R. A. & Kuhn, G. (2015). A framework for using magic to study the mind. Frontiers in Psychology, 5, 1508. doi:https://doi.org/10.3389/fpsyg.2014.01508
Repp, B. & Keller, P. (2004). Adaptations to tempo changes in sensorimotor synchronization: Effects of intention, attention, and awareness. The Quarterly Journal of Experimental Psychology, 57A, 499-521. doi:https://doi.org/10.1080/02724980343000369
Rohenkohl, G., Cravo, A. M., Wyart, V., & Nobre, A. C. (2012). Temporal expectation improves the quality of sensory information. Journal of Neuroscience, 32, 8424-8428. doi:https://doi.org/10.1523/JNEUROSCI.0804-12.2012
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime User's Guide. Pittsburgh: Psychology Software Tools Inc.
Schroeder, C. E. & Lakatos, P. (2008). Low-frequency neuronal oscillations as instruments of sensory selection. Trends in Neurosciences, 32, 9-18. doi:https://doi.org/10.1016/j.tins.2008.09.012
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Rights and permissions
About this article

Cite this article
Barnhart, A.S., Ehlert, M.J., Goldinger, S.D. et al. Cross-modal attentional entrainment: Insights from magicians. Atten Percept Psychophys 80, 1240–1249 (2018). https://doi.org/10.3758/s13414-018-1497-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1497-8