
Abstract
Human volitional orienting is typically assessed using Posner’s endogenous cuing task. As a volitional process, the literature has long emphasized the role of neocortical structures in this higher cognitive function. Based on recent data, we explored the possibility that subcortical channels may have a functional role in volitional orienting as measured by a Posner cuing task in which a nonspatial feature of a centrally presented cue is predictively related to the location of the target. In addition, we have compared this typical cuing task to a "purer" version, which does not involve the probability manipulation. A sensitive behavioral method was used to probe the contribution of monocular channels (mostly subcortical) in the two types of endogenous orienting tasks. In both tasks, a spatially informative cue and its ensuing target were presented to the same or different eyes at varying cue-target intervals. In the typically used endogenous task, the onset of facilitation was apparent earlier when the cue and target were presented to the same eye. In contrast, in the "pure" task no difference was found between the two eye-of-origin conditions. These data support the notion that endogenous facilitation, as measured in the typical Posner cuing task, involves lower monocular regions. Hence, in the typical endogenous task, which was developed to explore "volitional" orienting, a simple associative learning mechanism might elicit monocular, rapid orienting responses. Notably, the typical volitional orienting paradigm might be contaminated by simple contingency benefits and thus may not provide a pure measure of volitional processes.
Similar content being viewed by others


Introduction
The typical methods for examining reflexive and volitional orienting are two versions of Posner’s cuing task (Klein, 2005; Posner, 1980). In the exogenous (reflexive) task, a nonpredictive, peripheral cue is presented before the appearance of a target. The target could appear at the cued location (valid condition) or at the opposite location (invalid condition). The typical pattern of results is an early facilitatory effect (faster reaction time for the valid compared with the invalid condition), followed by inhibition of return (IOR; Posner & Cohen, 1984). In a typical version of Posner's endogenous task, participants are presented with a central, informative cue (e.g., a central arrow; colour patch), which is followed by a peripheral target. Importantly, the cue is informative regarding the location of the upcoming peripheral target (e.g., in 80% of the trials the cue predicts target's location). As the interval between the cue and the target (stimulus onset asynchrony; SOA) increases, the common pattern of results is a developing facilitatory effect at the predicted (valid) location that is not followed by IOR.
Several differences between reflexive and volitional orienting have been demonstrated (for a review, see Klein, 2009, pp. 245-248). Endogenous facilitation is slower to develop—approximately 200 ms SOA (Remington & Pierce, 1984) than reflexive facilitation, which can be observed as early as 50 ms SOA (Shepherd & Müller, 1989). There also are differences in the level of automaticity; reflexive orienting is considered to be more automatic than volitional orienting (Carrasco, Loula, & Ho, 2006; Hein, Rolke, & Ulrich, 2006; Jonides, 1981; Yeshurun & Carrasco, 1998). In addition, reflexive attention is almost certainly phylogenetically older than volitional attention (Carrasco, 2011; Gabay, Leibovich, Ben-Simon, Henik, & Segev, 2013). Finally, and most pertinent to the current study, numerous studies have suggested that volitional orienting is highly connected to neocortical regions (e.g., frontal-pariatel regions; Corbetta & Shulman, 2002; Robinson, Bowman, & Kertzman, 1995; Zackon, Casson, Zafar, Stelmach, & Racette, 1999; Andersen, Snyder, Bradley, & Xing, 1997; Kincade, Abrams, Astafiev, Shulman, & Corbetta, 2005; Peelen, Heslenfeld, & Theeuwes, 2004; Voytko et al., 1994; Yantis et al., 2002), whereas reflexive orienting also involves subcortical regions, such as the superior colliculus (Dorris, Klein, Everling, & Munoz, 2002; Gabay et al., 2013; Sapir, Soroker, Berger, & Henik, 1999; Self & Roelfsema, 2010).
Alternative viewpoint
Brain mechanisms are highly sensitive to regularities and can learn different types of sequences and statistical regularities even implicitly and incidentally (Chun & Jiang, 1998; Courville, Daw, & Touretzky, 2006; Gallistel & Gibbon, 2000; Goujon & Fagot, 2013). As discussed, to measure "volitional" orienting, many studies have used a probability manipulation, which is a basic feature of Posner's endogenous cuing task. In this task, in addition to the experimental instructions (which instruct participants to shift attention to the predicted location), symbolic cues inform the participants where the target is most likely to appear (Posner, 1980). This probabilistic association between a cue characteristic (e.g., shape of the arrow or a color of the cue) and the target's location might be acquired through a low-level learning mechanism. The question remaining is whether common endogenous orienting tasks truly and exclusively elicit a "volitional" mechanism? Another possibility, which needs to be explored, is that a simple associative learning mechanism also might be involved in the facilitated responding to targets presented at validly cued location in an endogenous cueing paradigm.
Associative learning depends on acquiring the contingency between a property of the cue and the target’s location (e.g., target appears at the cued location at 80% of the trials; for a review, see Gallistel & Gibbon, 2000). Accordingly, across trials, the regularity between events, such as the target's location and the preceding cue's color, could be learned, and such an association might shorten responses to targets at the validly cued location. Something akin to this was demonstrated in studies that examined spatial attention (in which statistical learning mechanism influences attentional allocation; Chun & Jiang, 1998; Geng & Behrmann, 2002), even without any voluntary intention to learn.
In addition, contrary to most of the literature, some data imply that neocortical regions are not exclusively responsible for volitional orienting and that subcortical regions also might be involved in the typical endogenous orienting tasks (Katyal & Ress, 2014; McAlonan, Cavanaugh, & Wurtz, 2008; Saban, Sekely, Klein, & Gabay, 2017a; Saban, Sekely, Klein, & Gabay, 2017b). For example, and most pertinent to the current study, consider these two very recent findings. First, in a study examining human's participants, it was demonstrated that the onset of endogenous orienting was apparent earlier when both cue and target were presented to the same monocular channel (vs. different channels), indicating that subcortical regions in humans play a functional role in endogenous orienting (Saban et al., 2017a). Second, when subjected to Posner’s endogenous orienting task, the archer fish (an evolutionarily older species) demonstrated a human-like endogenous facilitation and IOR, a pattern of results that commonly emerges in exogenous orienting tasks (Saban et al., 2017b). Hence, there is some basis to surmise the involvement of subcortical mechanisms when orienting is explored using the typical endogenous orienting task.
Therefore, the current study was designed to explore the possibility that a simple learning mechanism, which might functionally involve monocular (subcortical) regions, is influencing the pattern of results observed in the typical "volitional" endogenous orienting task. To examine this possibility, we compared the typical endogenous orienting task to a similar one without the involvement of statistical contingencies between cues' visual properties and targets' locations. In both versions an arbitrarily selected, nonspatial feature of a central cue (its color) was used to signal which target location should be attended endogenously. In addition, for each task, we have measured whether there is a functional contribution of monocular visual channels.
How to probe behaviorally the contribution of subcortical visual channels?
Visual input from the two eyes is separated in the early stages of the visual processing stream. That is, visual information once received by the retina, is monocularly segregated until it reaches binocular extrastriate regions (Horton, Dagi, McCrane, & de Monasterio, 1990; Menon, Ogawa, Strupp, & Ugurbil, 1997). Hence, two inputs from different eyes can be integrated mostly after the convergence of binocularly driven neurons in the neocortex. Using a stereoscope, one can control the visual information presented to each eye separately, and therefore can examine the involvement of monocular channels (mostly subcortical) in a specific cognitive process. This device has been used to explore the involvement of subcortical structures in many cognitive processes (Batson, Beer, Seitz, & Watanabe, 2011; Gabay & Behrmann, 2014; Gabay & Behrmann, 2014; Karni & Sagi, 1991; Saban, Gabay, & Kalanthroff, 2017; Saban et al., 2017a; Self & Roelfsema, 2010). In the context of Posner’s endogenous cuing paradigm, the stereoscope allows us to manipulate the cue's and target's eye-of-origin and therefore provides a useful tool for isolating the involvement of monocular versus binocular (mostly cortical) visual channels in endogenous orienting.
In the current study, we applied this method and logic in a typical implementation of the endogenous orienting task. Importantly, we also applied it in a version of this task that does not involve statistical contingencies between cues and targets. In both versions, a central cue was presented before the appearance of the peripheral target. A simple target detection task was used, and participants were explicitly instructed to attend one of the two possible target locations according to the cue's color (e.g., if the cue is red the participants were instructed to attend the upper location). In the typical task, the central cue predicted at which location the peripheral target would appear. In the "pure" endogenous task, the cue was not predictive. Using the stereoscope, for each of the tasks employed, the eye to which the endogenous cue and target were presented was manipulated. In the same eye condition, cue and target were presented to the same eye, and in the different eyes condition, they were presented to different eyes. In the “typical” condition, we would expect to replicate our previous finding that facilitation begins earlier with same than different eye delivery of the cue and target. In addition, if in the “pure” condition, we have eliminated the contribution of low-level learning mechanisms, then in that condition we would not expect a difference between the same eye and the different eye conditions.
Methods
Participants
A total of 48 (25 performed the pure task and 23 the typical task) participants volunteered to participate in exchange for payment or course credit. The mean age was 22.9, and the standard deviation was 3.9 (39 females). All participants had normal or corrected-to-normal vision. The sample size in this study is sufficient, because studies have long employed the endogenous version of Posner's cuing task and consistently found the endogenous facilitation effect with much smaller sample size (e.g., 13 subjects in Shepherd & Müller, 1989; 16 subjects in Berger, Henik, & Rafal, 2005). The study was approved by University of Haifa ethics committee.
Stimulus and apparatus
Stimulus presentation was performed using a HP Z200 computer, operating with Windows 7 system. Stimuli were displayed on a Samsung LCD monitor (model S24C650PL) with a recommended resolution of 1680X1050. Responses were made using DELL Hebrew-English Extended Keyboard (model RT7D50 SK-8115). The computer monitor was positioned 57 cm in front a stereoscope (model ScreenScope LCD SA200LCD), blocking the participant’s direct view of the monitor. The monitor presentation was divided into two halves (each half was presented to a different eye) and consisted of two rectangles (6°X17.8°) placed 10.3° from the center of the screen and 20.6° from each other. Each rectangle contained three squares (2.8° each side) in a vertical alignment. The upper and lower squares were placed at 5.8° from the center of the screen, and the central square was placed at its center. A central fixation cross comprised two lines (0.7° each), centered within the central squares. Cues consisted of red or green colors filling in the central square. An asterisk target (0.7°) was then presented, centered within one of the peripheral squares. Except for the cues, all stimuli were white figures against a black background.
Procedure
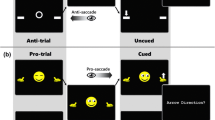
Typical experimental trials are depicted in Figure 1. Each trial began with a fixation cross appearing for 500 ms. Two hundred ms after fixation disappeared, the central cue was presented for 100 ms. After a variable SOA of 100, 300, or 500 ms, the target appeared for 3,000 ms or until a response was detected. In the pure group, participants were instructed to focus their eyes at the center of the screen throughout the experiment but to pay attention volitionally up or down depending on color of the cue. Each color was associated with a specific location, but the target appeared in the instructed location in 50% of the trials. In contrast, in the typical group, each color was associated with a specific location, and the target appeared at the predicted location in 80% of the trials. Participants were informed about the cues' predictability. In both groups, the target appeared at the instructed location (valid trial) or at the opposite location (invalid trial). The cue and target were presented to the left or right eye with equal probability. Four possible target locations varied equally and randomly: left eye-up, left eye-down, right eye-up, and right eye-down. Participants were instructed to respond to target appearance by pressing the space bar of a keyboard with their dominant hand as fast as possible. After manual response, an intertrial interval of 1,000 ms was introduced. Each participant has 16 practice trials before the experiment began. In the typical task, each participant completed 480 experimental trials divided into four blocks. For each of the two eye-of-origin conditions, subjects performed 64 valid and 16 invalid trials for each one of the three SOAs. In the pure task, each participant completed a total of 192 experimental trials divided into 4 blocks. For each of the two eye-of-origin conditions, subjects performed 16 valid and 16 invalid trials for each of the three SOAs. In 7.7% of the trials, no target appeared (i.e., catch trials), and the participant was instructed not to respond. Catch trials were dispersed randomly across the trials. All instructions were automated and were presented on the screen. The different experimental conditions were presented randomly.

Typical task in which a green cue predicts a target at the upper square while a red cue, predicts a target at the lower square. Note that in the pure task the visual presentation is exactly the same. (A) A typical Valid, Different−eye condition trial in which the cue (green square) is presented to the right eye (right column) and the target is presented to the right eye (right column), at the upper square. (B) A typical Valid, Same−eye condition trial in which the cue (green square) is presented to the right eye (right column) and the target is presented to the left eye (left column), at the upper square. The middle columns represent the participant's fused perception.
Results
Trials in which RT was longer than 2,500 ms or shorter than 100 ms were excluded from the analyses (<1.5%). Participants responded in catch trials on less than 1% of the trials and did not respond to target appearance on less than 1% of trials. For each task (typical, pure), we performed a three-way analysis of variance (ANOVA), with eye-of-origin (same-eye, different-eye), SOA (100 ms, 300 ms, or 500 ms), and validity (valid, invalid) as a within-subject factors and RT as the dependent variable. See Table 1 for a detailed presentation of RTs for the different conditions. Figure 2 presents RT as a function of eye-of-origin, SOA, and validity for each task separately.

(A) The upper panels show the pattern of results in the Typical task, and the lower panels (B) show pattern of results in the Pure task. For both tasks, RT as a function of SOA and validity depicted for each eye-of-origin condition. Ninety-five percent confidence intervals are shown in the error bars. The two functions have been slightly offset horizontally to allow visualization of the error bars. *p < 0.05.
Typical Task
In the typical task, replicating previous findings, the main effects of SOA and validity were significant [F(2, 44) = 49.67, MSE = 1,549, p < 0.001, η2 = 0.69; F(1, 22) = 7.60, MSE = 1,769, p = 0.011, η2 = 0.26, respectively]. In contrast, the main effect of eye-of-origin was not significantFootnote 1 [F(1, 22) = 0.38, MSE = 894, p > 0.250]. The SOA x validity, SOA x eye-of-origin, and eye-of-origin x validity interactions were not significant [F(2, 44) = 2.16, MSE = 735, p = 0.126; F(2, 44) = 2.26, MSE = 942, p = 0.116; F(1, 22) = 0.499, MSE = 780, p > 0.250, respectively]. Most importantly, the three-way interaction between SOA x validity x eye-of-origin was significant [F(2, 44) = 4.32, MSE = 553, p = 0.019, η2 = 0.16].
To further investigate the three-way interaction, we examined the simple two-way interaction between SOA and validity for each eye-of-origin condition separately. When the cue and target were presented to different eyes, the SOA x validity interaction was significant [F(2, 44) = 5.21, MSE = 754, p = 0.009, η2 = 0.19], indicating a significant validity effect only at the last SOA [F(1, 22) = 1.01, MSE = 924, p > 0.250; F(1, 22) = 2.362, MSE = 1416, p = 0.138; F(1, 22) = 9.04, MSE = 907, p = 0.006, for the 100 ms, 300 ms, and 500 ms SOAs, respectively]. In contrast, when the cue and target were presented to the same eye, the SOA x validity interaction was not significant [F(2, 44) = 0.10, MSE = 534, p > 0.250], and the validity effects were significant at all SOAs [F(1, 22) = 5.25, MSE = 769, p = 0.031; F(1, 22) = 5.12, MSE = 478, p = 0.033; F(1, 22) = 4.50, MSE = 628, p = 0.045, for the 100 ms, 300 ms, and 500 ms SOAs, respectively].
Pure Task
Replicating previous findings, the main effects of SOA and validity were significant [F(2, 48) = 32.29, MSE = 2414, p < 0.001, η2 = 0.57; F(1, 24) = 9.90, MSE = 2,632, p = 0.004, η2 = 0.29, respectively]. In contrast, the main effect of eye-of-origin was not significant [F(1, 24) = 0.26, MSE = 1,223, p > 0.250]. The SOA x validity, SOA x eye-of-origin, and eye-of-origin x validity interactions, were not significant [F(2, 48) = 1.64, MSE = 1094, p = 0.203; F(2, 48) = 0.18, MSE = 1,012, p > 0.250; F(1, 24) = 0.12, MSE = 1,016, p > 0.250, respectively]. In contrast to the typical task, the three-way interaction between SOA x validity x eye-of-origin was not significant [F(2, 48) = 0.02, MSE = 1,111, p > 0.250].
Although the SOA x validity x eye-of-origin interaction was not significant, to compare the pattern of results to that observed in the typical task, we examined the simple two-way interaction between SOA and validity for each eye-of-origin condition separately. When the cue and target were presented to different eyes, the SOA x validity interaction was not significant [F(2, 48) = 1.20, MSE = 828, p > 0.250], and further analyses revealed a significant validity effects only at the last two SOAs [F(1, 24) = 1.02, MSE = 630, p > 0.250; F(1, 24) = 4.49, MSE = 1,236, p = 0.04; F(1, 24) = 4.46, MSE = 1,518, p = 0.04, for the 100 ms, 300 ms, and 500 ms SOAs, respectively].
When the cue and target were presented to the same eye, the SOA x validity interaction also was not significant [F(2, 48) = 0.60, p > 0.250], and further analyses revealed a significant validity effects at the last two SOAs [F(1, 24) = 1.03, MSE = 1,509, p > 0.250; F(1, 24) = 4.46, MSE = 1,045, p = 0.028; F(1, 24) = 4.41, MSE = 2,120, p = 0.046, for the 100 ms, 300 ms, and 500 ms SOAs, respectively].
Discussion
The current results provide novel insights for those interested in endogenous orienting. Replicating our previous findings, in the typical task—used to measure "volitional" orienting—facilitation was found as early as 100 ms after cue onset but only in the same-eye condition. In the "pure" task, which in contrast to the current typical task does not contain statistical regularities between the cue's color and the target's location, no difference was found between the two eye-of-origin conditions and facilitation was not observed until 300 ms after cue onset. In line with the previous literature, in both tasks, once facilitation emerged, it was maintained throughout the longer SOAs in both eye-of-origin conditions.
As previously demonstrated, volitional and reflexive processes (i.e., endogenous and exogenous attentional effects) can simultaneously co-exist and under some conditions may influence performance in an additive manner (Berger, Henik, & Rafal, 2005; Berlucchi, Chelazzi, & Tassinari, 2000; Chica, Lupianez, & Bartolomeo, 2006). Several reflexive processes could initiate a rapid attentional orienting as a result of what have been typically termed an "endogenous" cue. Central cues, such as arrows and gaze cues, can produce orienting responses even when they are not predictive of target's location (Friesen & Kingstone, 1998; Kingstone, Friesen, & Gazzaniga, 2000; Pratt & Hommel, 2003; Ristic, Friesen, & Kingstone, 2002; Ristic & Kingstone, 2006). Such findings suggest that these types of cue possess a reflexive property, which has been hypothesized to elicit automatically attentional orienting because of a lifetime of associating their spatial properties with the location of important information in our environment.Footnote 2 In contrast, in the typical cuing task of the current study, the association between the cue's nonspatial and arbitrarily selected property (color) and the target's location is specific to the experimental context and is learned through exposure to the task. The instruction to orient attention endogenously in response to the cue's color might have elicited some amount of true voluntary orienting, just as it did in the “pure” condition. We believe that this volitional orienting takes place in parallel with associative learning due to the statistical regularities (i.e., the correlation between a cue property and the target's location) present in the typical condition.
When a property of the cue (e.g., shape or color) is correlated, by numerous trials, with the location of the target, an associative learning process could be initiated by this contingency and result in more rapid responses to targets presented at the cued location. Such a learning process should develop as the experiment proceeds.Footnote 3 As mentioned, volitional orienting in response to informative central cues is generally thought to take approximately 200 ms to reach its full magnitude (Remington & Pierce, 1984). There are, however, studies that used larger number of trials than is typically used in this literature, between 3,500 (Shepherd & Müller, 1989) and ~6,500 trials (Cheal & Lyon, 1991). These studies have found substantial cueing effects with SOAs of 50 ms or less. Our interpretation is that when a property of the cue (e.g., shape or color) is correlated with the location of the target, simple learning mechanisms may kick in such that an orienting response becomes conditioned to the cues' property. This may masquerade as and/or co-exist with voluntary orienting. Such associated orienting responses are, like reflexive orienting, initiated rapidly in response to the appearance of the cue.
The involvement of an additional associative learning process only in the typical endogenous task should result in a greater facilitation effect in the 100 ms SOA in the same-eye condition of the typical task compared with the facilitation effect in the different-eye condition of the pure task. Yet, when examining this difference specifically, it did not reach significance in the current study. This might be explained by individual differences between the two experimental groups (typical vs. pure task). Regardless, as indicated earlier, the finding of a validity-effect modulation as a function of SOA and eye-of-origin condition only in the typical task strengthens the conclusion that different processes are involved in the two tasks.
In the current experimental design, a central color cue was associated with peripheral target's location. Due to neural plasticity, we propose that that monocular neurons started to associate the two spatiotemporal events by their spatiotemporal receptive fields. This explanation is in line with previous findings demonstrating perceptual learning in monocular channels (Karni & Sagi, 1991). Hence, monocular channel’s receptive fields are likely to associate two spatiotemporal events in the same eye, and this would lead to the observed same-eye cueing advantage. That is, when the same monocular channel (mostly subcortical) is presented with both the cue and the target, the associative learning mechanism can kick in and initiates a rapid orienting response to the appearance of the endogenous cue.
Implication for the study of volitional orienting processes
The current study has important implications for our conceptual understanding of volitional orienting processes. In contrast to the common perspective, "endogenous" orienting might not be equivalent to "volitional" orienting. The common tasks, which are suggested to manipulate volitional orienting in humans, usually manipulate attention by influencing the cue predictability. As suggested by the present study and our work with the archer fish, the contingency between the cue and the target location can produce an associative learning process that can masquerade as volitional orienting in these tasks. The pattern of results supports the possibility that volitional and reflexive processes may contribute jointly to behavior and, therefore, that in the typical Posner task cuing effects might be a combination of the associative learning effect and the intention to follow the instructions. This account is in accordance with a recent study, which suggests that implicit learning of cue-target contingencies can influence attentional effects (Risko & Stolz, 2010). We suggest that simple associative learning is contaminating tasks that are commonly used to measure "volitional" orienting even when participants do not have a lifetime of experience that links a spatial property of the cue with the location of task-relevant information. Hence, a reconceptualization of the way volitional processes are defined and measured is needed.
Notes
To preclude perceptual differences explanations the main effect of eye-of-origin, across all conditions, was not significant both in the pure and in the typical tasks.
If cuing in response to uninformative gaze and arrow cues is reflexive because of a lifetime of learning, then we would expect these forms of cuing to show an eye of origin difference like the one we have reported here. We offer this as one suggestion for future research, and we thank an anonymous reviewer for leading us to have this thought.
Converging evidence for this proposed learning process in the “typical” condition was found when dividing the data into 4 blocks. Comparing between the two eye-of-origin conditions in the averaged first and second SOAs, revealed that in the first block (the beginning of the experiment) of the typical task, no difference (p > 0.1) was found. In contrast, in the last (4th) block, a significant difference was found between the eye-of-origin conditions (F(1, 22) = 7.03, MSE = 2,635, p < 0.05).
References
Andersen, R. A., Snyder, L. H., Bradley, D. C., & Xing, J. (1997). Multimodal representation of space in the posterior parietal cortex and its use in planning movements. Annual Review of Neuroscience, 20(1), 303-330.
Batson, M. A., Beer, A. L., Seitz, A. R., & Watanabe, T. (2011). Spatial shifts of audio-visual interactions by perceptual learning are specific to the trained orientation and eye. Seeing and Perceiving, 24(6), 579–94. https://doi.org/10.1163/187847611X603738
Berger, A., Henik, A., & Rafal, R. (2005). Competition between endogenous and exogenous orienting of visual attention. Journal of Experimental Psychology. General, 134(2), 207–221. https://doi.org/10.1037/0096-3445.134.2.207
Berlucchi, G., Chelazzi, L., & Tassinari, G. (2000). Volitional covert orienting to a peripheral cue does not suppress cue-induced inhibition of return. Journal of Cognitive Neuroscience, 12(4), 648–663.
Carrasco, M. (2011). Visual attention: The past 25 years. Vision Research, 51(13), 1484–1525. https://doi.org/10.1016/j.visres.2011.04.012
Carrasco, M., Loula, F., & Ho, Y.-X. (2006). How attention enhances spatial resolution: Evidence from selective adaptation to spatial frequency. Perception & Psychophysics, 68(6), 1004–1012. https://doi.org/10.3758/BF03193361
Cheal, M., & Lyon, D. R. (1991). Central and peripheral precuing of forced-choice discrimination. The Quarterly Journal of Experimental Psychology, 43(4), 859-880.
Chica, A. B., Lupianez, J., & Bartolomeo, P. (2006). Dissociating inhibition of return from endogenous orienting of spatial attention: Evidence from detection and discrimination tasks. Cognitive Neuropsychology, 23(7), 1015–1034. https://doi.org/10.1080/02643290600588277.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing : Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 71(36), 28–71.
Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature reviews. Neuroscience, 3(3), 201.
Courville, A. C., Daw, N. D., & Touretzky, D. S. (2006). Bayesian theories of conditioning in a changing world. Trends Cogn Sci 10(7). https://doi.org/10.1016/j.tics.2006.05.004
Dorris, M. C., Klein, R. M., Everling, S., & Munoz, D. P. (2002). Contribution of the primate superior colliculus to inhibition of return. Journal of Cognitive Neuroscience, 14(8), 1256–1263. https://doi.org/10.1162/089892902760807249
Friesen, C. K., & Kingstone, A. (1998). The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychonomic Bulletin & Review, 5(3), 490–495. https://doi.org/10.3758/BF03208827
Gabay, S., & Behrmann, M. (2014). Attentional dynamics mediated by subcortical mechanisms. Attention, Perception & Psychophysics, (July), 2375–2388. https://doi.org/10.3758/s13414-014-0725-0
Gabay, S., Leibovich, T., Ben-Simon, A., Henik, A., & Segev, R. (2013). Inhibition of return in the archer fish. Nature Communications, 4, 1657. https://doi.org/10.1038/ncomms2644
Gallistel, C. R., & Gibbon, J. (2000). Time, rate, and conditioning. Psychological Review, 107(2), 289–344. https://doi.org/10.1037/0033-295X.107.2.289
Geng, J. J., & Behrmann, M. (2002). Probability Cuing of Target Location Facilitates Visual Search Implicitly in Normal Participants and Patients with Hemispatial Neglect. Psychological Science, 13(6), 520–525. https://doi.org/10.1111/1467-9280.00491
Goujon, A., & Fagot, J. (2013). Learning of spatial statistics in nonhuman primates : Contextual cueing in baboons (Papio papio). Behavioural Brain Research, 247, 101–109. https://doi.org/10.1016/j.bbr.2013.03.004
Hein, E., Rolke, B., & Ulrich, R. (2006). Visual attention and temporal discrimination: Differential effects of automatic and voluntary cueing. Visual Cognition, 13(1), 29–50. https://doi.org/10.1080/13506280500143524
Horton, J. C., Dagi, L. R., McCrane, E. P., & de Monasterio, F. M. (1990). Arrangement of ocular dominance columns in human visual cortex. Archives of Ophthalmology, 108(7), 1025-1031.
Jonides, J. (1981). Voluntary versus automatic control over the mind's eye. Attention and performance, 9, 187-203.
Karni, A., & Sagi, D. (1991). Where practice makes perfect in texture discrimination: Evidence for primary visual cortex plasticity. Proceedings of the National Academy of Sciences, 88(11), 4966-4970.
Katyal, S., & Ress, D. (2014). Endogenous attention signals evoked by threshold contrast detection in human superior colliculus. The Journal of Neuroscience : The Official Journal of the Society for Neuroscience, 34(3), 892–900. https://doi.org/10.1523/JNEUROSCI.3026-13.2014
Kincade, J. M., Abrams, R. A., Astafiev, S. V., Shulman, G. L., & Corbetta, M. (2005). An event-related functional magnetic resonance imaging study of voluntary and stimulus-driven orienting of attention. Journal of Neuroscience, 25(18), 4593-4604.
Kingstone, A., Friesen, C. K., & Gazzaniga, M. S. (2000). Reflexive Joint Attention Depends on Lateralized Cortical Connections. Psychological Science, 11(2), 159–166. https://doi.org/10.1111/1467-9280.00232
Klein, R. M. (2005). On the role of endogenous orienting in the inhibitory aftermath of exogenous orienting. In U. Mayr, E. Awh, & S. W. Keele (Eds.), Developing individuality in the human brain: A tribute to Michael I. Posner (pp. 45–64). Washington: American Psychological Association.
Klein, R. M. (2009). On the control of attention. Canadian Journal of Experimental Psychology, 63, 240-252.
McAlonan, K., Cavanaugh, J., & Wurtz, R. H. (2008). Guarding the gateway to cortex with attention in visual thalamus. Nature, 456(7220), 391–394. https://doi.org/10.1038/nature07382
Menon, R. S., Ogawa, S., Strupp, J. P., & Uǧurbil, K. (1997). Ocular dominance in human V1 demonstrated by functional magnetic resonance imaging. Journal of Neurophysiology, 77(5), 2780-2787.
Peelen, M. V., Heslenfeld, D. J., & Theeuwes, J. (2004). Endogenous and exogenous attention shifts are mediated by the same large-scale neural network. NeuroImage, 22(2), 822-830.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32(1), 3–25. https://doi.org/10.1080/00335558008248231
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. Attention and Performance: Control of Language Processes, 531–556. https://doi.org/10.1162/jocn.1991.3.4.335
Pratt, J., & Hommel, B. (2003). Symbolic control of visual attention: The role of working memory and attentional control settings. Journal of Experimental Psychology. Human Perception and Performance, 29(5), 835–845. https://doi.org/10.1037/0096-1523.29.5.835.
Remington, R., & Pierce, L. (1984). Moving attention: Evidence for time-invariant shifts of visual selective attention. Perception & Psychophysics, 35(4), 393–399. https://doi.org/10.3758/BF03206344
Risko, E. F., & Stolz, J. A. (2010). The proportion valid effect in covert orienting: Strategic control or implicit learning?. Consciousness and Cognition, 19(1), 432–442.
Ristic, J., Friesen, C. K., & Kingstone, A. (2002). Are eyes special? It depends on how you look at it. Psychonomic Bulletin & Review, 9(3), 507–513. https://doi.org/10.3758/BF03196306
Ristic, J., & Kingstone, A. (2006). Attention to arrows: Pointing to a new direction. Quarterly Journal of Experimental Psychology, 59(11), 1921–30. https://doi.org/10.1080/17470210500416367
Robinson, D. L., Bowman, E. M., & Kertzman, C. (1995). Covert orienting of attention in macaques. II. Contributions of parietal cortex. Journal of Neurophysiology, 74(2), 698-712.
Saban, W., Gabay, S., & Kalanthroff, E. (2017). More than just channeling: The role of subcortical mechanisms in executive functions–Evidence from the Stroop task. Acta Psychologica. https://doi.org/10.1016/j.actpsy.2017.03.001https://doi.org/10.1016/j.actpsy.2017.03.001.
Saban, W., Sekely, L., Klein, R. M., & Gabay, S. (2017a). Monocular channels have a Functional Role in Endogenous Orienting. (in press)
Saban, W., Sekely, L., Klein, R. M., & Gabay, S. (2017b). Endogenous orienting in the archer fish. Proceedings of the National Academy of Sciences, 114(29), 7577–7581. https://doi.org/10.1073/pnas.1700574114
Sapir, A., Soroker, N., Berger, A., & Henik, A. (1999). Inhibition of return in spatial attention: Direct evidence for collicular generation. Nature Neuroscience, 2(12), 1053–1054. https://doi.org/10.1038/15977
Self, M. W., & Roelfsema, P. R. (2010). A monocular, unconscious form of visual attention. Journal of Vision, 10(2010), 17.1-23. https://doi.org/10.1167/10.4.17
Shepherd, M., & Müller, H. J. (1989). Movement versus focusing of visual attention. Perception & Psychophysics, 46(2), 146–154. https://doi.org/10.3758/BF03204974.
Voytko, M. L., Olton, D. S., Richardson, R. T., Gorman, L. K., Tobin, J. R., & Price, D. L. (1994). Basal forebrain lesions in monkeys disrupt attention but not learning and memory [published erratum appears in J Neurosci 1995 Mar; 15 (3): following table of contents]. Journal of Neuroscience, 14(1), 167-186.
Yantis, S., Schwarzbach, J., Serences, J. T., Carlson, R. L., Steinmetz, M. A., Pekar, J. J., & Courtney, S. M. (2002). Transient neural activity in human parietal cortex during spatial attention shifts. Nature Neuroscience, 5(10), 995.
Yeshurun, Y., & Carrasco, M. (1998). Attention improves or impairs visual performance by enhancing spatial resolution, 6–9.
Zackon, D. H., Casson, E. J., Zafar, A., Stelmach, L., & Racette, L. (1999). The temporal order judgment paradigm: subcortical attentional contribution under exogenous and endogenouscueing conditions. Neuropsychologia, 37(5), 511-520.
Acknowledgements
This research was supported by the Israel Science Foundation (Grant No. 1124/14) to SG. The authors thank Shalev Shahar for help with the experiments. All authors declare no conflict of interest pertaining to the present manuscript.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Saban, W., Klein, R.M. & Gabay, S. Probabilistic versus “Pure” Volitional Orienting: a Monocular Difference. Atten Percept Psychophys 80, 669–676 (2018). https://doi.org/10.3758/s13414-017-1473-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-017-1473-8