
Abstract
We investigated whether attentional set is available at the beginning of a trial or whether it develops gradually within a trial. Thus, we manipulated the time from the onset of a trial to a target and observers’ search strategy. We also observed the effect of the presence or absence of distractors as an index of the temporal development of attentional set. Participants identified a target letter embedded in a stream of rapidly presented nontargets while ignoring peripheral distractors. Baseline accuracy when no peripheral distractor was presented increased as the target appeared later in the stream, suggesting attentional awakening. Identification accuracy was impaired by the presence of peripheral distractors (i.e., attentional capture) early in the stream only when observers adopted the feature search mode. The magnitude of attentional capture increased over the course of the first 1,000 ms of a trial under the singleton detection and feature search modes. These results suggest that singleton detection mode requires time for a bottom-up signal to be effective in capturing attention, whereas the feature search mode does not require such a warm-up period to be effective and is available from the beginning of viewing the stream.
Similar content being viewed by others

Deployment of attention, a primary cognitive function, reflects the ability to allocate limited processing resources to a specific region or object among the many in our complex environment. This process is necessary because of the limited cognitive resources available for simultaneous processing. Cognitive psychology research has revealed that attention can be deployed in at least three major ways based on the type of control (Awh, Belopolsky, & Theeuwes, 2012; Lamy, Leber, & Egeth, 2012; Wright & Ward, 2008). Specifically, attention is allocated to a task-relevant item/region in accordance with the current behavioral goal under top-down control (Lamy, Leber, & Egeth, 2004; Einhäuser, Rutishauser, & Koch, 2008), whereas attention is allocated to a region containing a salient item under bottom-up control (Theeuwes, 1992, 2010) regardless of the observer’s knowledge about the current task. Recent studies have suggested that selection and reward histories can be categorized as a third source of attentional control (Awh et al., 2012; Hickey, Chelazzi, & Theeuwes, 2011; Maljkovic & Nakayama, 1994).
A phenomenon known as attentional capture has been investigated extensively, because it is useful in helping to clarify the relative contributions of the factors involved in the deployment of attention. For example, if an observer’s visual-search performance is impaired by the presence of a salient task-irrelevant distractor, such impairment represents attentional capture (Franconeri, Hollingworth, & Simons, 2005; Theeuwes, 1992, 2010; Yantis, 1993; Yantis & Jonides, 1984, 1990). That is, deployment of focused attention is assumed to be governed by stimulus salience in a bottom-up way; thus, attention is oriented initially to the most salient item regardless of task demands/observer goals. In this view, deployment of attention relies exclusively on the salience of the stimulus display. However, another line of studies has demonstrated that deployment of attention can be modulated by the observer’s attentional set. Specifically, an observer’s performance during visual searching is impaired only when targets are preceded by distractors carrying task-relevant features (Du & Abrams, 2008; Folk, Leber, & Egeth, 2002; Serences, Shomstein, Leber, Golay, Egeth, & Yantis, 2005).
Several aspects of the spatial and temporal properties of attentional capture have been identified in investigating the relative contributions of the factors affecting the control of attentional deployment. Researchers have demonstrated that attentional focus plays a critical role in determining the presence or absence of attentional capture. If the focus of attention is spread widely, attentional capture occurs within that focus in a stimulus-driven way (Theeuwes, 2004; Belopolsky, Zwaan, Theeuwes, & Kramer, 2007). In contrast, if attention is focused narrowly, salient stimuli fail to capture attention (Theeuwes, 1991). A decisive conclusion regarding this issue has not yet been reached (Lamy, Leber, & Egeth, 2012, for a review). This is probably due to the use of a wide range of procedures. For example, Kawahara and Kihara (2011) found that different mechanisms may separately underlie the temporal and spatial capture phenomena. Thus, to simplify the discussion, the present study focused on temporal attentional capture.
Three major findings related to the temporal aspect of attention are the focus of the present study. First, attentional capture takes time to emerge and dissipate. The detrimental effects of peripherally presented distractors on the accuracy of identifying a target embedded among a centrally presented rapid sequence of nontargets (Folk et al., 2002; Du & Abrams, 2008) occur not with distractors presented simultaneously but with those presented at least 80–200 ms prior to the target (Folk et al., 2002; Ghorashi, Zuvic, Visser, & Di Lollo, 2003). Second, the relative contributions of stimulus-driven and goal-directed control of attention switch within a trial. Specifically, van Zoest and Donk (2005; Donk & van Zoest, 2008) found that stimulus salience determines where attention was allocated during the early stage of a visual search, whereas no effects of salience were found during later processing. Third, the history of selection as a consequence of visual searches involving salient items yields inter-trial effects. For example, a visual search for the same feature becomes more efficient during successive pop-out search trials even when observers voluntarily search for different features (pop-out priming; Maljkovic & Nakayama, 1994; Kristjánsson & Campana, 2010).
Importantly, these studies have revealed the temporal impacts of critical distractors on the perception/recognition of targets that appear after distracting events. Therefore, the time that elapses from trial onset was outside the scope of these studies, and researchers have not questioned what was happening before the critical distractors appeared. The present study focuses on the effects of time on attentional capture from the onset of a trial to the onset of a distractor. This question arises from the discovery that deployment of attention develops gradually after the start of a trial, even when the observers know the defining feature of the target in advance (Ariga & Yokosawa, 2008). This temporal deployment of attention suggests that attentional readiness develops over time. Specifically, the accuracy of identifying a color/luminance-oddball target embedded in a rapid succession of nontarget items improves progressively and reaches an asymptote approximately 800 ms after beginning the sequence presentation. This gradual development of attention is referred as to attentional awakening. In this case, no critical item was presented before the target appeared; thus, the improvement was attributed to the time required for the visual system to prepare attention for optimal distribution over the sequential presentation.
Converging evidence about the effects of time on attention suggests the possibility that attentional set is also affected by the time that elapses from trial onset. In the present study, we combined attentional awakening (Ariga & Yokosawa, 2008) and attentional capture procedures (Folk et al., 2002; Leber & Egeth, 2006) to examine the impact of time on the selection of visual items by attentional set through the progress of a trial. To this end, we systematically manipulated the serial position of a target to measure attentional awakening, and the similarity of the target and distractors to measure attentional capture. If the availability of attentional set was unaffected by the time from trial onset, no interaction between attentional awakening and attentional capture would be observed. In other words, the accuracy of target identification would be lower under the distractor condition than under the distractor-absent condition regardless of when the target appeared during the central stream. Additionally, gradual improvement in general accuracy would be observed as the time before the target appears elapses from stream onset. In contrast, if it requires time for attentional set to become available, the magnitude of attentional capture, defined as differences in accuracy between the presence and absence of distractor conditions, would increase gradually as the central sequence progresses. Experiments 1 and 3 were designed to measure the temporal development of the singleton detection mode. The feature search mode was tested in Experiment 2.
Experiment 1
Observers were instructed to adopt the singleton detection mode to identify an oddly colored target letter among gray nontarget letters while ignoring preceding peripheral distractors. Attentional capture is demonstrated as improperly identifying a target when peripheral distractors appear relative to when no such distractors are presented (Folk et al., 2002). If the availability of the search mode is unaffected by time until the target appeared, no interaction would be expected between the two phenomena. In this case, the accuracy of identifying the target would be expected to improve as the target is presented later in the sequence (attentional awakening), regardless of the presence or absence of peripheral distractors. Additionally, the accuracies of identifying a target should be impaired when distractors are present, relative to when no such distractors are presented (attentional capture). Alternatively, if it takes time for attentional set to be available to detect a singleton, the effect of the presence or absence of the distractor would be expected to interact with the serial position of the target. That is, the accuracy of identifying the target would improve as the target appeared later in the sequence when no distractor was presented (attentional awakening), whereas accuracy would be expected to be much lower when distractors are presented (attentional capture) and the gradual improvement would be eliminated.
Methods
Observers
Sixteen undergraduate students (12 males, 4 females) from the subject pool of the National Institute of Advanced Industrial Science and Technology (AIST, Tsukuba, Japan) participated for payment. All subjects (age range: 19–30 years) reported normal or corrected-to-normal visual acuity and normal color vision.
Apparatus and stimuli
The stimuli were the same as those used in a typical temporal letter-search task with peripheral distractors (Folk et al., 2002; Leber & Egeth, 2006). The stimuli were generated using MATLAB and the Psychophysics Toolbox (Brainard, 1997; Pelli, 1997) and were displayed on a computer monitor at a viewing distance of approximately 60 cm. Responses were collected via a keyboard connected to the computer. A plus sign was presented as a fixation point in the center of the screen. The central stimulus sequence consisted of letters replaced from the English alphabet selected randomly, excluding I, O, Q, and Z, with the constraint that the selected letter was not one of the two immediately preceding items. The letters subtended a visual angle of approximately 1.0° in height and width (stroke = 0.1°). Target letter color was chosen from among blue, orange, magenta, yellow, and red. The red target was replaced with the green target for half of the observers. Nontargets were gray. The distractor consisted of four number signs (i.e., #) of the same height as the letters, presented 5.2° above, below, to the right of, and to the left of the letters. One of the number signs was red or green, and the remaining items were gray. All stimuli were presented on a black background.
Procedure
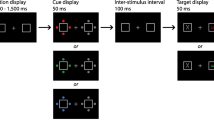
The factors of distractor type (absent, same, or different) and target serial position (6, 7, 8, 9, 12, 13, 14, 15, 24, 25, 26, or 27) were combined factorially, resulting in 576 experimental trials. Each trial started with a 500-ms fixation display when observers pressed the space bar. The central fixation cross was replaced with a rapid sequence of 30 letters following a 500-ms blank interval (Fig. 1). Target color was assigned randomly from five possible colors (blue, orange, magenta, yellow, and red were used for half of the observers; green was used instead of red for the other half). As a result, observers were forced to adopt the singleton detection mode, because they were not informed of target color on every trial. The target was chosen randomly from the letters, and the nontargets were chosen from the remaining letters without selecting the same letter in successive frames. The temporal position of the target was varied from 6th to 9th, from 12th to 15th, and from 24th to 27th equally. Each item was presented for 43 ms, followed by a blank interval of 43 ms before the next item was presented, resulting in 86 ms of stimulus onset asynchrony. Following the study by Folk et al. (2002), a distractor frame, when present, preceded the target frame by 172 ms. The location of the oddly colored distractor (singleton) was determined randomly from trial to trial.

Panels A and B show the sequences of events under the distractor-absent and distractor-present conditions in Experiment 1, respectively
The various relationships between the target and distractor resulted in three conditions. Under the same-color condition, the color of the odd item in the distractor frame could be the same as the target color. Under the different-color condition, the color of the singleton distractor differed from the target color. That is, the singleton distractor was green for the group of participants who searched for red as one of possible target colors (red was used instead of green as the singleton distractor for the other half). No distractor was presented under the distractor-absent condition, serving as a control. Observers were required to ignore the distractors and identify the target letter by pressing a corresponding key on the keyboard after all stimuli were presented. When an incorrect response was made, an alarm sounded through headphones. The same number of trials (48 trials) was assigned for each of the three conditions, and trials were administered in random order during the experimental session. Observers participated in 24 practice trials before the start of experimental trials. They took a short break after every 48 trials.
We integrated four successive target positions into a subset (bin) before analyzing the data to increase power of the analysis, following Ariga and Yokosawa (2008). Thus, the identification scores for the target appearing in the sixth to ninth target frames were integrated into bin 1. Similarly, those at the twelfth to fifteenth target frames and those at the twenty-fourth to twenty-seventh target frames were integrated into bins 2 and 3, respectively.
Results
Results from the red- and green-target groups were combined, because no main effect or interaction was detected in a preliminary analysis. We conducted analysis of variance (ANOVA) with distractor type (distractor-absent, same, or different) and bin (1, 2, or 3). Figure 2 shows the mean percentages of correct responses for each condition. The results revealed a significant main effect of distractor type [F(2, 30) = 4.80, p = 0.016, ηp 2 = 0.24] and a significant interaction between these factors [F(4, 60) = 6.23, p = 0.0003, ηp 2 = 0.29]. The main effect of bin tended to be significant [F(2, 30) = 3.21, p = 0.055, ηp 2 = 0.18]. Simple effects analyses yielded significant effects of bin under all distractor conditions [distractor-absent: F(2, 30) = 6.27, p = 0.01, ηp 2 = 0.29; same: F(2, 30) = 3.52, p = 0.04, ηp 2 = 0.19; different: F(2, 30) = 5.99, p = 0.01, ηp 2 = 0.29]. Ryan–Einot–Gabriel–Welsch multiple range tests (SAS, 2015) revealed that the accuracy of bin 1 was significantly lower than that of bins 2 [t(90) = 2.88, p = 0.005] and 3 [t(90) = 2.71, p = 0.01], but there was no difference between bins 2 and 3 [t(90) = 0.17, p = 0.87] in the absence of distractors. The accuracy of bin 3 was significantly lower than that of bins 1 [t(90) = 2.48, p = 0.01] and 2 [t(90) = 2.82, p = 0.01], but there was no significant difference between bins 1 and 2 [t(90) = 0.34, p = 0.74] under the same-color condition. The accuracy of bin 3 was significantly lower than that of bin 1 [t(90) = 3.10, p = 0.003], but there was no difference between bins 1 and 2 [t(90) = 1.19, p = 0.24] or between 2 and 3 [t(90) = 1.92, p = 0.06] under the different-color condition. To assess the occurrence of attentional capture, we conducted simple effects analyses and found significant differences in distractor type in bins 2 and 3 [bin 2: F(2, 30) = 4.61, p = 0.02, ηp 2 = 0.24; bin 3: F(2, 30) = 7.22, p = .002, ηp 2 = 0.33]. We used Ryan–Einot–Gabriel– Welsch multiple range tests (SAS, 2015) for the analyses. The test revealed that the accuracy of the distractor-absent condition was significantly higher than those of the same- and different-color conditions in bins 2 [same: t(90) = 2.51, p = 0.01; different: t(90) = 2.80, p = 0.01] and 3 [same: t(90) = 3.88, p = 0.0002; different: t (90) = 3.71, p = 0.0004]. However, no such difference was found under the same- and different-color conditions in bins 2 and 3 [bin 2: t(90) = 0.29, p = 0.77; bin 3: t(90) = 0.18, p = 0.86].

Mean percentages of correct target identification under each distractor type (absent, same, or different) in Experiment 1. Error bars indicate standard errors of the means in both panels
Discussion
In this experiment, we examined whether it takes time for the top-down set under the singleton detection mode to be available. If the top-down set becomes available gradually during a target search, attentional capture would be modulated by the temporal position of the target frame. In contrast, if the top-down set is available from trial onset, attentional capture would be expected to be unaffected by the temporal position of the target frame, and thus, no interaction would occur between the temporal bin and the presence of distractors. Before discussing this prediction, we note that robust attentional capture was demonstrated. When a target was presented in bin 2 or 3, target identification was impaired under the same- and different-color conditions relative to the distractor-absent condition. The result that attention was captured regardless of whether the target and distractor colors were the same indicates that the observers adopted a singleton detection mode, consistent with the results of the study by Folk et al. (2002).
Importantly, however, no attentional capture was observed when the target was presented in the earliest bin. The result that the magnitude of attentional capture was affected by the temporal position of the target supports the prediction of an interaction between attentional awakening and attentional capture. Accuracy of target identification improved gradually as the central stream progressed when no distractor was presented, indicating that attentional awakening occurred. In contrast, no such improvement was observed under the same- and different-color conditions. Rather, the accuracy of target identification was decreased as time elapsed from trial onset. These results suggest that the observers were unable to ignore the distractor that matched the top-down set when the distractor appeared at later temporal positions in the stream.
The result that the magnitude of attentional capture was affected by the temporal position of the target frame is consistent with the view that it takes time for the top-down set to become available. Observers cannot prepare for a singleton against uniform nontargets at the beginning of a trial, because a few initial items of the stream needed to be viewed to create a baseline for detecting an oddball item. Given that this was the case, an interesting prediction ensues: if observers adopt a top-down set under the feature search mode in which they search for a specific feature (e.g., red) consistently through an experimental block, there would be no need for calibration to the uniform color on every trial. Therefore, we predicted that attentional capture would be observed even at the shortest temporal bin.
Experiment 2
Experiment 1 revealed that the interaction between attentional awakening and attentional capture was observed under the singleton detection mode. This result suggests that using the top-down set to detect an oddball item requires time. In other words, these results suggest that attentional set in the singleton detection mode for detecting an oddball is not ready at the beginning of a trial. Therefore, in this experiment, we investigated whether the same rule applies to the top-down set for a specific feature, i.e., the feature search mode. By presenting a target of a specific color (e.g., red) among nontarget letters of various colors (e.g., blue, purple, gray, etc.), we required observers to adopt the feature search mode. If no interaction was observed between attentional awakening and attentional capture, it would mean that the top-down set for a specific color can be prepared before initiating the central stimulus sequence. In contrast, if an interaction between the two phenomena occurred, this would indicate that the top-down set also requires time to be fully available, as with the singleton detection mode.
Method
Seventeen undergraduate and graduate Chukyo University students (5 males, 12 females) participated as observers for pay or course credit. All (age range: 18–24 years) reported normal or corrected-to-normal visual acuity and normal color vision.
The apparatus, stimuli, and procedure were identical to those used in Experiment 1 except the following. We presented a red-colored target letter among heterogeneous-colored nontarget letters so that observers would adopt the feature search mode. The nontarget letter color was chosen from green, gray, blue, or purple, with the constraint that successive colors differed from each other. The color of the distractor was red for the same-color condition and green for the different-color condition. The luminance of all stimuli was 27 cd/m2. The same-color distractor (i.e., a distractor of the same color as the target in the present trial) was presented in one-third of the trials, and the different-color distractor in another third of the trials. No distractor was included in the remaining one-third of the trials.
Result
Figure 3 shows the mean percentage of correct responses for each condition. An ANOVA with distractor type (distractor-absent, same, or different) and bin (1, 2, or 3) as within-subject factors indicated main effects of distractor type and bin [F(2, 32) = 12.13, p = 0.0001, η p 2 = 0.43 and F(2, 32) = 4.58, p = 0.018, η p 2 = 0.22, respectively]. A significant interaction was detected between distractor type and bin [F(4, 64) = 2.65, p = 0.041, η p 2 = 0.14]. Simple effects analyses yielded a significant effect of bin under the distractor-absent condition [F(2, 32) = 5.05, p = 0.01, ηp 2 = 0.24]. There was a barely significant simple effect of bin under the different-color condition [F(2, 32) = 3.23, p = 0.05, ηp 2 = 0.17]. The improved accuracy under the distractor-absent condition was confirmed by multiple range tests; the accuracy of bin 1 was significantly lower than those of bins 2 and 3 [bin 2: t(96) = 2.81, p = 0.01; bin 3: t(96) = 2.62, p = 0.01], but there was no difference between bins 2 and 3 [t(96) = 0.19, p = 0.85]. Next, we investigated whether attentional capture occurred across bins. Simple effects analyses yielded significant effects of distractor type in all bins [bin 1: F(2, 32) = 5.26, p = .01, ηp 2 = .25; bin 2: F(2, 32) = 10.57, p = .0003, ηp 2 = .40; bin 3: F(2, 32) = 13.57, p < .0001, ηp 2 = .46]. Multiple range tests revealed significant differences between the same-color and distractor-absent conditions [bin 1: t(96) = 2.45, p = 0.02; bin 2: t(96) = 3.93, p = 0.0002; bin 3: t(96) = 5.05, p = 0.000002] and between the same-color and different-color conditions [bin 1: t(96) = 2.92, p = 0.004; bin 2: t(96) = 4.07, p = 0.0001; bin 3: t(96) = 4.07, p = 0.0001] in all bins. However, no difference in accuracy was observed between the distractor-absent and different-color conditions [bin 1: t(96) = 0.46, p = 0.65; bin 2: t(96) = 1.44, p = 0.86; bin 3: t(96) = 0.98, p = 0.33].

Mean percentages of correct target identification under each distractor type (absent, same, or different) in Experiment 2. Error bars indicate standard errors of the means in both panels
Discussion
This experiment was conducted to examine the time required for the top-down set to be available when observers adopted the feature search mode. The results indicated that target identification accuracies under the same-color condition were lower than those under the distractor-absent condition. However, no such impairment was observed under the different-color condition. These results suggest that when observers adopted the feature search mode, they could ignore the distractor defined by a task-irrelevant color. Target identification accuracies improved gradually when no distractor was presented, suggesting that attentional awakening occurred under the feature search mode. Accuracies reached an asymptote in bin 2 when a distractor preceded a target, which was identical to the outcome in Experiment 1, in which observers adopted the singleton detection mode. This result suggests that attentional readiness develops gradually regardless of the search strategy adopted by the observer.
Importantly, attentional capture occurred in the first bin, suggesting the possibility that the top-down set is already available at the beginning of a trial. Nevertheless, the magnitude of attentional capture increased gradually afterward, resulting in the interaction between attentional awakening and attentional capture. These results suggest that the top-down set of the feature search mode is prepared at the beginning of a trial but that its availability improves over the first 1000 ms during a visual search trial for a target defined by a specific color.
The finding that attentional capture was evident at the earliest temporal bin in Experiment 2 contrasts sharply with the results of Experiment 1 in that no evidence of attentional capture was found in the same temporal bin. These results were consistent with the hypothesis that the singleton detection mode requires time for the bottom-up signal to become effective in capturing attention, whereas the feature search mode does not require such a warm-up period to be effective, but becomes effective immediately from the beginning of viewing the stream.
However, there is an alternative explanation. The presence or absence of attentional capture at the earliest temporal bin may not be due to a difference in the attentional set. Rather, the level of task difficulty may play an important role. Specifically, the accuracy was lower under the feature search mode (Experiment 2) than under the singleton detection mode (Experiment 1). It could be argued that the more difficult the task was, then the greater might have been the arousal required in Experiment 2. Thus, participants in Experiment 2 may have enthusiastically applied attentional set, resulting in a stronger effect of attentional capture even at the earliest temporal bin. If this was the case, making the task more difficult would lead to attentional capture that emerges at the very first temporal bin even under the singleton detection mode. Thus, in Experiment 3, we replicated Experiment 1 with a slight modification in which more intense backward masking was introduced to reduce the general accuracy level. We also included the same condition as Experiment 1 (without such masking) for comparison.
Experiment 3
In this experiment, we reduced general accuracy by inserting another nontarget letter to increase masking power immediately after target presentation (Di Lollo, 1980). This manipulation was expected to lower the accuracy more when a mask-distractor was present than when it was absent. If the level of accuracy was the key to the difference in the time required for attentional capture to emerge (i.e., attentional capture was found under feature search mode, whereas no such capture occurred under the singleton detection mode), we should observe a capture effect at the earliest temporal bin only under the strong masking condition in Experiment 3.
Methods
The apparatus, stimuli, and procedure were identical to those used in Experiment 1 with the following exception. We introduced an additional mask as a new factor, resulting in a three-factor mixed design: distractor (absent, same, or different) × additional mask (mask present or mask absent) × serial position of the target (6, 7, 14, 15, 26, or 27), resulting in 648 experimental trials. The target frame appeared in the 6th and 7th frames for bin 1, the 14th and 15th frames for bin 2, and the 26th and 27th frames for bin 3. Under the mask condition, a randomly selected gray letter, whose identity differed from that of the immediately following nontarget letter, was inserted as an additional mask, with no blank interval between the target and the subsequent nontarget letter (SOA = 43 ms, ISI = 0 ms). A new sample of 16 undergraduate students (9 males, 7 females, age range: 19–25 years), who reported normal or corrected-to-normal visual acuity and normal color vision, were recruited from the AIST subject pool for payment.
Results and discussion
Figure 4 shows the mean percentages of correct responses for each condition. Because there was no effect of distractor color on identification accuracy, we combined distractor types (same and different color) for the analysis. An ANOVA with distractor type (distractor absent or distractor present), additional mask (mask present or mask absent), and bin (1, 2, or 3) as within-subject factors indicated main effects of distractor type, the additional mask, and bin [F(1, 15) = 5.58, p = 0.032, ηp 2 = 0.27; F(1, 15) = 161.44, p < 0.0001, ηp 2 = 0.92; and F(2, 30) = 5.19, p = 0.012, ηp 2 = 0.26, respectively]. The interaction between distractor type and bin was significant [F(2, 30) = 10.44, p = 0.0004, ηp 2 = 0.41]. Simple effect analysis indicated that when the target appeared in the last two bins, accuracy was higher under the distractor-absent condition than under the distractor-present condition [bin 2: F(1, 15) = 5.42, p = 0.03, ηp 2 = 0.27; bin 3: F(1, 15) = 10.44, p = 0.001, ηp 2 = 0.41]. There was a simple main effect of bin under the distractor-absent condition [F(2, 30) = 19.65, p < 0.0001, ηp 2 = 0.57]. Multiple comparisons indicated that the accuracy of bin 1 was lower than that of bins 2 [t(60) = 2.81, p = 0.01] and 3 [t(60) = 5.54, p = 0.0000007], and the accuracy of bin 3 was higher than that of bin 2 [t(60) = 2.73, p = 0.01]. Importantly, the three-way interaction was not statistically significant [F(2, 30) = 0.08, p = 0.93, ηp 2 = 0.01].

Mean percentages of correct target identification under each distractor type (distractor absent, distractor present, mask-distractor absent, or mask-distractor present) in Experiment 3. Error bars indicate standard errors of the means
These results were virtually identical to those of Experiment 1, as seen in the results under the mask-absent condition, indicating the robustness of the interaction between attentional awakening and attentional capture. Importantly, even when the additional mask was introduced and general performance decreased, the pattern of the interaction remained. No attentional capture was found at the earliest bin; the capture effect was found only in bins 2 and 3 in the present experiment in which the singleton detection mode was involved. These results rule out the explanation that the interaction observed in Experiment 1 was due to a difference in task difficulty. Rather, the present results suggest that the interaction reflects a different temporal top-down control framework during attentional awaking and attentional capture.
General discussion
In the present study, our question was whether attentional set can be fully available at the beginning of a trial or whether it develops within a trial. We examined the temporal characteristics of attentional set during the search for a singleton or a target defined by a specific color. We manipulated the observers’ search strategy, the temporal position of the target, and the presence or absence of distractors to investigate involvement of the top-down effect in the interaction. Our primary prediction was that the magnitude of attentional capture would increase with temporal distance of the target from the onset of the sequential visual presentation if the top-down set became available gradually over the period.
Our results were consistent with this prediction. Attentional capture increased as the target appeared at a later temporal position in the sequential visual presentation regardless of search strategy. Our results were inconsistent with the view that a top-down set is fully available before the start of the trial based on advanced knowledge about the target. Rather, the results indicate that the top-down set became available gradually during target search. That is, the observer found it difficult to ignore the distractor due to enhanced availability of the set as time elapsed from the onset of the stream, resulting in increased attentional capture. By manipulating the temporal position of the target frame, we found that attentional capture occurred at the first temporal bin (i.e., 500–800 ms) only under the feature search mode. The magnitude of attentional capture increased up to bin 2 under both search modes. In other words, the time required to establish availability was 1000–1300 ms. Additionally, the magnitude of attentional capture at bin 3 was comparable to that at bin 2 under both search modes, suggesting that the top-down set can be maintained for >2,000 ms regardless of search strategy.
No attentional capture occurred early during monitoring of the rapid visual presentation stream when observers adopted the singleton detection mode, but occurred later as the stream progressed (Experiment 1). Similar results were observed in Experiment 3. These results suggest that the availability of the top-down set was insufficient in bin 1 and that the distractor did not interfere with identifying the target. However, attentional capture occurred even earlier in the sequence when the observers adopted the feature search mode, suggesting that the attentional set for a specific feature value is available at the beginning of every trial. This difference in the temporal characteristics of attentional capture demonstrates an intriguing contrast with the prevalent view that attentional allocation based on stimulus salience engages faster/earlier than attentional allocation based on knowledge about the task (Godijn & Theeuwes, 2002; Horowitz, Wolfe, Alvarez, Cohen, & Kuzmova, 2009; Ludwig & Gilchrist, 2003; McSorley, Haggard, & Walker, 2006; van Zoest & Donk, 2005). For example, van Zoest and Donk (2005) demonstrated that attentional allocation to a color singleton distractor occurred in <250 ms when observers were required to move their eyes to a target singleton of an oddly tilted line against uniformly tilted background lines. Their results suggest that stimulus salience dominates allocation of attention early in a visual search trial, but is short lived. Thus, the attentional capture effect due to reliance on singleton detection should have been in evidence at a shorter temporal bin in the present study. In fact, no such trend in the early stage was observed; rather, the results indicate that the feature search mode was available at the early stage of a trial. Such an inconsistency could be explained three ways.
First, the temporal profiles of attentional capture under the singleton detection mode may differ across various visual search task types. Specifically, van Zoest and Donk (2005) presented all stimuli simultaneously in a wide area of the search display (i.e., spatial search task), whereas we presented individual stimuli sequentially at the same spatial location (i.e., temporal search task). Kawahara and Kihara (2011) concluded that two different mechanisms may underlie the two different types of attentional capture (i.e., spatial search and temporal search tasks) by showing no correlation between spatial and temporal capture under the singleton detection mode. Therefore, if the same issue applies to the present results, different temporal scales may be required for attentional set to be available under the singleton detection mode across two different search tasks.
Second, in the present circumstance, identifying the target may be an inter-trial benefit only under the feature search mode. Specifically, target color was changed randomly across trials under the singleton detection mode. Therefore, even if a target was identified successfully during trial N under the singleton detection mode and short-term representation of the target would presumably be maintained in memory as a target color for some time, it would not be useful when the target color during trial N+1 differed. The visual system needs to be recalibrated with nontarget colors to detect a singleton. Consequently, it takes some time for attentional set to be ready; thus, we failed to observe attentional capture in bin 1. However, the target color was consistent throughout the entire experimental block under the feature search mode. Therefore, the inter-trial priming effect (Maljkovic & Nakayama, 1994; Kristjánsson & Campana, 2010) would be maximal in this circumstance and would help the subject to be ready for optimal attentional set at the beginning of a trial. Taken together, our results suggest that past trial experience affects improvement in the availability of top-down set.
Third, it is possible that the singleton detection mode requires time for the visual system to create a baseline for detecting an oddball item among uniformly colored items. Observers cannot prepare for a singleton against uniform nontargets at the start of a trial because they need to monitor a few initial items of the uniformly colored stream for calibration. This calibration builds a baseline for detecting a bottom-up signal of sufficient magnitude to match the top-down set. In contrast, observers under the feature search mode do not need to create baselines because they know the feature defining the target at a start of a trial, and thus task-relevant items (i.e., the target and distractor) could match the top-down set without such a baseline.
Experiment 3 replicated the results pattern of Experiment 1. We included this experiment to increase the task difficulty in order to address the concern that the presence or absence of attentional capture at the earliest bin was due not to the difference in search strategies but to a difference in task difficulty. The same results patterns were observed in Experiments 1 and 3, even when general performance was reduced by inserting an additional mask. The results indicate that the null finding regarding attentional capture at the shortest temporal bin was not due to low task difficulty. Rather, the results support the idea that the singleton detection mode requires time to be effective compared with the feature search mode.
Finally, the target identification accuracies improved gradually regardless of observers’ strategies in the absence of distractor. This gradual improvement, attentional awakening, has been explained in terms of the time required for the visual system to prepare attention for optimal distribution over the central stream. In the study by Ariga and Yokosawa (2008), observers adopted the singleton detection mode to detect an oddball item among nontargets of homogeneous color. With this procedure, it is possible that the time required for the singleton detection mode to become effective could cause attentional awakening. However, a gradual improvement in accuracy also was found under the feature search mode. Thus, the occurrence of attentional awakening was caused not by the time required to prepare the singleton detection mode but by the development of attentional readiness or other effects, such as attentional capture by the onset of the stream.
Such an improvement in accuracy was not found under the distractor condition in the present study. Thus, one might argue that the temporal effect of top-down set found in the present study is unrelated to attentional capture. However, the presence of a distractor that matches the top-down attentional set prevented the improvement of accuracy under the distractor condition. As a result, an interaction between accuracy of the distractor-absent and that of the distractor conditions was found, providing the enhanced capture effect. This suggests that the lack of change in performance under the distractor condition reflects the temporal effect of the top-down set.
References
Ariga, A., & Yokosawa, K. (2008). Attentional awakening: Gradual modulation of temporal attention in rapid serial visual presentation. Psychological Research, 129, 192–202. doi:10.1007/s00426-006-0100-4
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437–443. doi:10.1016/j.tics.2012.06.010
Belopolsky, A. V., Zwaan, L., Theeuwes, J., & Kramer, A. F. (2007). The size of attentional window modulates attentional capture by color singletons. Psychonomic Bulletin and Review, 14, 934–938. doi:10.1037/a0033775
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Di Lollo, V. (1980). Temporal integration in visual memory. Journal of Experimental Psychology: General, 109, 75–97. doi:10.1037/0096-3445.109.1.75
Donk, M., & van Zoest, W. (2008). Effects of salience are short-lived. Psychological Science, 19, 733–739. doi:10.1111/j.1467-9280.2008.02149.x
Du, F., & Abrams, R. A. (2008). Synergy of stimulus-driven salience and goal-directed prioritization: Evidence from the spatial blink. Perception & Psychophysics, 70, 1489–1503. doi:10.3758/PP.70.8.1489
Einhäuser, W., Rutishauser, U., & Koch, C. (2008). Task-demands can immediately reverse the effects of sensory-driven saliency in complex visual stimuli. Journal of Vision, 8, 1–19. doi:10.1167/8.2.2
Folk, C. L., Leber, A. B., & Egeth, H. E. (2002). Made you blink! Contingent attentional capture produces a spatial blink. Perception & Psychophysics, 64, 741–753. doi:10.3758/BF03194741
Franconeri, S. L., Hollingworth, A., & Simons, D. J. (2005). Do new objects capture attention? Psychological Science, 16, 275–281. doi:10.1111/j.0956-7976.2005.01528.x
Ghorashi, S. M. S., Zuvic, S. M., Visser, T. A. W., & Di Lollo, V. (2003). Focal distraction: Spatial shifts of attention are not required for contingent capture. Journal of Experimental Psychology: Human Perception and Performance, 29, 78–91. doi:10.1037/0096-1523.29.1.78
Godijn, R., & Theeuwes, J. (2002). Programming of exogenous and endogenous saccades: Evidence for a competitive integration model. Journal of Experimental Psychology: Human Perception and Performance, 28, 1039–1054. doi:10.1037/0096-1523.28.5.1039
Hickey, C., Chelazzi, L., & Theeuwes, J. (2011). Reward has a residual impact on target selection in visual search, but not on the suppression of distractors. Visual Cognition, 19, 117–128. doi:10.1080/13506285.2010.503946. Publisher's version is subscribed content and only accessible when you have been registered to it's source as a subscribed user.
Horowitz, T. S., Wolfe, J. M., Alvarez, G. A., Cohen, M. A., & Kuzmova, Y. I. (2009). The speed of free will. The Quarterly Journal of Experimental Psychology, 62, 2262–2288. doi:10.1080/17470210902732155
Kawahara, J., & Kihara, K. (2011). No commonality between attentional capture and attentional blink. Quarterly Journal of Experimental Psychology, 64, 991–1008. doi:10.1080/17470218.2010.524304
Kristjánsson, Á., & Campana, G. (2010). Where perception meets memory: A review of repetition priming in visual search tasks. Attention, Perception, & Psychophysics, 72, 5–18. doi:10.3758/APP.72.1.5
Lamy, D., Leber, A., & Egeth, E. H. (2004). Effects of task relevance and stimulus-driven salience in feature-search mode. Journal of Experimental Psychology: Human Perception and Performance, 30, 1019–1031. doi:10.1037/0096-1523.30.6.1019
Lamy, D., Leber, A. B., & Egeth, H. E. (2012). Selective Attention. In A. F. Healy & R. W. Proctor (Eds.), Experimental psychology. Volume 4 in I.B. Weiner (Editor-in-Chief), handbook of psychology. New York: Wiley.
Leber, A. B., & Egeth, H. E. (2006). Attention on autopilot: Past experience and attentional set. Visual Cognition, 14, 565–583. doi:10.1080/13506280500193438
Ludwig, C. J. H., & Gilchrist, I. D. (2003). Target similarity affects saccade curvature away from irrelevant onsets. Experimental Brain Research, 152, 60–69. doi:10.1007/s00221-003-1520-7
Maljkovic, V., & Nakayama, K. (1994). Priming of pop-out: I. Role of features. Memory & Cognition, 22, 657–672. doi:10.3758/BF03209251
McSorley, E., Haggard, P., & Walker, R. (2006). Time course of oculomotor inhibition revealed by saccade trajectory modulation. Journal of Neurophysiology, 96, 1420–1424. doi:10.1152/jn.00315.2006
Pelli, D. G. (1997). The VideoToolbox software for visual psycho- physics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Serences, J. T., Shomstein, S., Leber, A. B., Golay, X., Egeth, H. E., & Yantis, S. (2005). Coordination of voluntary and stimulus-driven attentional control in human cortex. Psychological Science, 16, 114–122. doi:10.1111/j.0956-7976.2005.00791.x
Theeuwes, J. (1991). Exogenous and endogenous control of attention: The effect of visual onsets and offsets. Perception & Psychophysics, 49, 83–90. doi:10.3758/BF03211619
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606. doi:10.3758/BF03211656
Theeuwes, J. (2004). Top-down search strategies cannot override attentional capture. Psychonomic Bulletin & Review, 11, 65–70. doi:10.3758/BF03206462
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 123, 77–99. doi:10.1016/j.actpsy.2010.02.006
van Zoest, W., & Donk, M. (2005). The effects of salience on saccadic target selection. Visual Cognition, 2, 353–375. doi:10.1080/13506280444000229
Wright, R. D., & Ward, L. M. (2008). Orienting of attention. USA: Oxford University Press.
Yantis, S. (1993). Stimulus-driven attentional capture. Current Directions in Psychological Science, 2, 156–161. doi:10.1111/1467-8721.ep10768973
Yantis, S., & Jonides, J. (1984). Abrupt visual onsets and selective attention: Evidence from visual search. Journal of Experimental Psychology: Human Perception and Performance, 10, 601–621. doi:10.1037/0096-1523.10.5.601
Yantis, S., & Jonides, J. (1990). Abrupt visual onsets and selective attention: Voluntary vs. automatic allocation. Journal of Experimental Psychology: Human Perception and Performance, 16, 121–134. doi:10.1037/0096-1523.16.1.121
Author information
Authors and Affiliations
Corresponding author
Additional information
This study has been supported by Grants-in-Aid for Scientific Research from the Japan Society for the Promotion of Science (25380993) to TI and (26285168) to JK.
Rights and permissions
About this article

Cite this article
Inukai, T., Shimomura, T. & Kawahara, J.I. Attentional capture during attentional awakening. Atten Percept Psychophys 78, 159–167 (2016). https://doi.org/10.3758/s13414-015-0985-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-015-0985-3