
Abstract
The memory for the vanishing location of a horizontally moving target is usually displaced forward in the direction of motion (representational momentum) and downward in the direction of gravity (representational gravity). Moreover, this downward displacement has been shown to increase with time (representational trajectory). However, the degree to which different kinematic events change the temporal profile of these displacements remains to be determined. The present article attempts to fill this gap. In the first experiment, we replicate the finding that representational momentum for downward-moving targets is bigger than for upward motions, showing, moreover, that it increases rapidly during the first 300 ms, stabilizing afterward. This temporal profile, but not the increased error for descending targets, is shown to be disrupted when eye movements are not allowed. In the second experiment, we show that the downward drift with time emerges even for static targets. Finally, in the third experiment, we report an increased error for upward-moving targets, as compared with downward movements, when the display is compatible with a downward ego-motion by including vection cues. Thus, the errors in the direction of gravity are compatible with the perceived event and do not merely reflect a retinotopic bias. Overall, these results provide further evidence for an internal model of gravity in the visual representational system.
Similar content being viewed by others
Over the last few decades, the role of gravity in structuring our perception of space has come to be a major focus of several research lines. From the classical studies on the subjective visual vertical (see, e.g., Haji-Khamneh & Harris, 2010; Mittelstaedt, 1983, 1986) to the timing of interceptive actions of falling objects (McIntyre, Zago, Berthoz & Lacquaniti, 2001) and time to contact (Baurès & Hecht, 2011), as well as the gravito-inertial force resolution (equivalence principle; all linear accelerometers respond to both linear acceleration and gravity) in the vestibular system (Angelaki, Shaikh, Green & Dickman, 2004; Hess & Angelaki, 1999; Merfeld, 1995; Merfeld, Zupan & Peterka, 1999), the idea that gravity has been internalized in our perceptual apparatus has been a leading hypothesis upon which a wealth of knowledge has been built. For the most part, these and other approaches share the common assumption that humans possess an internal model of gravity, used to update and complement sensorial inputs in order to maintain reliable estimates of the spatial environment. An internal model is thought to be a general neural process that explicitly mimics the relationship between physical variables in order to provide estimates of physical quantities of both body sensors and environment (Grush, 2005; Poon & Merfeld, 2005; Snyder, 1999; Tin & Poon, 2005). The notion of internal analogues of physical variables has been similarly emphasized by Shepard (2001) in his concept of second-order isomorphism, on the basis of which spatial mislocalizations have been interpreted, such as representational momentum and representational gravity (see below; Hubbard, 2005). The aim of the present article is to provide further understanding of the role of an internal model of gravity in these phenomena.
Representational momentum and gravity
When people are instructed to remember and indicate the vanishing location of a moving target, their spatial memory is displaced forward, in the direction of motion, and downward, in the direction of gravity (for a review, see Hubbard, 2005). These errors of spatial localization have been taken as evidence for internal analogues of momentum and gravity, respectively, and have been thought to reflect mental extrapolations that seek to supplant neural delays (see, e.g., Kerzel & Gegenfurtner, 2003).
Representational momentum was first reported in 1984 by Freyd and Finke. These authors presented to observers a rectangle in a sequence of positions that implied a rotation motion. After the sequence was presented, a similar rectangle was shown in either the same or a different orientation than the last one in the inducing sequence, and the observers were asked to provide a same–different judgment. Results showed that people were prone to accept as same a rectangle that was actually further rotated in the direction of the implied motion. Further experiments showed that this bias in spatial judgments increased in magnitude with increases in the implied velocity of the target (Freyd & Finke, 1985), that it emerged even for static images as long as they implied motion (e.g., a boy jumping from a wall; Freyd, 1983), that it was sensitive to high-level information such as the identity of the target (e.g., a rocket moving upward leads to bigger mnesic displacements in the direction of motion than does a building; Reed & Vinson, 1996), and that the remembered position was further increased when the target was shown moving in the direction of gravity (Nagai, Kazai & Yagi, 2002).
In 1988, Hubbard and Bharucha were able to replicate the phenomenon with a behavioral localization task wherein observers were shown a target moving horizontally at a constant velocity. Upon its disappearance, they had to indicate with a computer mouse the location onscreen where the target had vanished (akin to the method of adjustment). Given that both the horizontal and vertical coordinates of the participants’ response were measured, it was possible to analyze spatial errors in both those axes. The obtained results, which have been since replicated (e.g., De Sá Teixeira, Hecht & Oliveira, 2013; Hubbard, 1990, 2001), showed not only that people made an error in the direction of motion, but also that the remembered location was displaced downward in the direction of gravity. Moreover, it was reported that representational momentum (the error along the movement axis) was significantly bigger for descending than for ascending targets (Hubbard, 2001; Hubbard & Bharucha, 1988); that is, when a target was shown moving downward toward the gravity pull, the memory for its last position was displaced in that direction by a greater amount than for targets moving upward (i.e., against gravity). Both these outcomes (downward displacement with horizontally moving targets and increased representational momentum for descending objects) were taken together as reflecting a mental analogue of gravity (representational gravity; Hubbard, 2005).
However, these views were not without critics. On the one hand, it is known that spatial location judgments are biased toward the fovea (foveal bias; Kerzel, 2002; Müsseler, van der Heijden, Mahmud, Deubel & Ertsey, 1999; Sheth & Shimojo, 2001). On the other hand, given a smoothly moving object, the oculomotor system engages a type of eye movement known as smooth pursuit (SP), wherein the gaze smoothly follows the target with a gain close to 1 (cf., e.g., Land & Tatler, 2009). Upon a sudden disappearance of a smoothly tracked object, the gaze overshoots its vanishing location and keeps moving in the same direction for 300–500 ms (Mitrani & Dimitrov, 1978; Pola & Wyatt, 1997). Jointly, foveal bias and ocular overshoot would account for the reported mislocalizations, as was argued by Kerzel and further supported by experimental evidence (Kerzel, 2000, 2002, 2003; but see Ashida, 2004, and Kerzel & Gegenfurtner, 2003). Despite the discussion that ensued regarding the degree to which low-level perceptual phenomena could fully explain representational momentum and the degree to which oculomotor behavior per se could be an epiphenomenon of the same representational structures (see, e.g., Kerzel, 2006, and Hubbard, 2006, for a reply), the fact still remains that the question cannot be solved without ascertaining the role played by the oculomotor system.
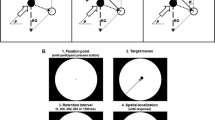
In this sense, and given that the terms representational momentum and representational gravity are theory compromised, a neutral nomenclature has been adopted in the literature, as suggested by Hubbard (e.g., 2005). This notation holds for behavioral localization tasks (as opposed to same–different judgments) and capitalizes on the fact that one can separately measure the localization errors along the axis of motion and the axis orthogonal to motion. The former has been coined M-displacement, and the latter O-displacement, with M and O standing for motion axis and orthogonal axis, respectively. Note that the target’s kinematics, not the world or the participant’s body, provides the reference frame. Depending on the motion direction, either M- or O-displacements can be aligned with the world vertically or horizontally (see Fig. 1). Usually, negative M-displacements refer to locations contrary to the direction of motion, and positive values to locations in the direction of motion (that is, beyond the target’s vanishing position). For O-displacements, negative values usually signal a displacement downward for horizontally and leftward for vertically moving targets, the inverse being true for positive values.

Measurement of the spatial mislocalizations. The black circles represent the objective vanishing location of the targets, with the gray arrows referring to its motion directions. The white dashed circles depict the usually found remembered vanishing locations. The full lines and the dashed lines represent, respectively, the M- and O-displacement axes, with reference to the direction of positive and negative values
Recently, we showed, by imposing temporal intervals between stimulus presentation and participants’ response (for a similar method, see Freyd & Johnson, 1987; Kerzel, 2000), that the O-displacement of a horizontally moving target drifts steadily downward with time at a rate of about 0.22 º/s (De Sá Teixeira et al., 2013). We refer to this as representational trajectory: the evolution of both M- and O-displacements along time. It was thus possible to characterize the dynamics for the spatial memory, obtaining an analogue of a projectile trajectory. We surmised that representational trajectory reflects the inner mechanics of the visual representational system. Moreover, we have shown that even though constraining eye movements critically affects representational momentum, it does not modulate representational gravity (despite the fact that, when left unconstrained, gaze mimics the downward drift found for spatial memory; see also Kerzel, Jordan & Müsseler, 2001). Notwithstanding, it is still to be seen whether a similar pattern can be disclosed for other kinematic events.
The present experiments
The main purpose of this study was to ascertain the degree to which representational gravity and representational trajectory would generalize to events other than horizontally moving targets and, if they did, to characterize their dynamic properties. The first experiment explored representational trajectory with vertically moving targets. In the second experiment, we investigated whether target motion is at all necessary for the downward drift by presenting observers with static objects. Finally, in the third experiment, we presented observers with vertically moving targets with and without vection. When the whole visual field moves coherently in a certain direction, people can experience the feeling of ego-motion in the opposite direction (vection). By manipulating the presence or absence of vection, we sought to determine whether the downward mnesic displacement is retinotopically based or whether it is sensitive to the implied dynamics of the visual display.
Three main parameters are relevant for the present purposes: (1) the magnitude and direction of the spatial displacements (representational momentum), (2) the comparison between the displacements with upward- and downward-moving targets (given a moving target; representational gravity), and (3) the temporal evolution of the displacements (representational trajectory). It is important to note that these three parameters are independent of each other. For instance, one can fail to obtain representational momentum (spatial displacement opposite to the direction of motion) but still find a significant asymmetry between upward- and downward-moving targets (representational gravity). The joint role played by an internal model of gravity, the oculomotor system, and foveal bias can be clarified by establishing which parameters are and which are not affected across the experimental manipulations.
Experiment 1: Representational trajectory for vertically moving targets
The main goal of this first experiment was to characterize a representational trajectory for vertically moving targets. These events have the particularity that the target’s movement and, therefore, M-displacement and SP eye movements all unfold along the gravity axis. This provides an opportunity to explore their joint role. Previously, Hubbard (1990; Hubbard & Bharucha, 1988) reported a bigger displacement forward for descending than for ascending targets. By imposing systematic temporal intervals between stimulus presentation and participants’ responses (see De Sá Teixeira et al., 2013), we sought to ascertain whether this asymmetry possesses a temporal evolution and, if so, its dynamic profile and the role played by oculomotor factors, by both measuring eye movements and constraining them.
We hypothesized that descending targets would lead to larger displacements in the direction of motion, as compared with ascending targets, irrespective of oculomotor constraints. Also, we hypothesized that without constraining eye movements, the remembered vanishing locations would drift downward with time for descending targets and, possibly, for ascending targets. Finally, when constraining eye movements, we expected to find either no temporal evolution of the spatial localizations or a drift toward the gaze direction (Sheth & Shimojo, 2001), which would signal a conflict between an internal model of gravity and foveal bias.
Method
Participants
Eighteen students at the University of Coimbra (15 females, 3 males) participated in the experiment in exchange for partial course credit. Their ages ranged from 18 to 29 years (M = 21.3, SD = 4.3). All participants had normal or corrected-to-normal vision and were unaware of the purposes of the experiment.
Stimuli and design
A set of animations were used as stimuli. Each animation depicted a black circle—the target—30 pixels (px) in diameter (≈0.9º) moving upward or downward at a constant velocity of 470 px/s (≈14.3 º/s) on an otherwise white background. Each target appeared already in motion at a position about 384 px (≈11.7º) above (for descending paths) or below (for ascending paths) the center of the screen. The target vanished after covering a fixed distance of 470 px (14.3º)—that is, 86 px (2.6º) beyond the center of the screen (so as to keep constant the vanishing location onscreen; see De Sá Teixeira & Oliveira, 2011). The vertical trajectory of the targets was always centered onscreen. A black fixation dot 5 px in diameter (0.15º) was shown 40 px (1.2º) to the left or to the right of the trajectory of the target and centered vertically on the screen. That is, the fixation dot was always 86 px behind (vertically) the vanishing location of the target with respect to its motion direction. The fixation dot disappeared 0, 150, 300, 450, or 600 ms after the target vanished. The experiment followed a 2 (task; see below) × 2 (direction of motion) × 2 (location of fixation point) × 5 (retention intervals) full factorial design, with six replications.
Apparatus and procedure
The experiment was run on a personal computer equipped with a flat screen, with a resolution of 1,280 × 1,024 px (physical size of 33.7 × 27 cm; 37.2 × 30.2º) and a refresh rate of 60 Hz. The participants sat in front of the screen, with head movements constrained by a chinrest, such that their cyclopean eye was aligned with the center of the screen and at a fixed distance of 50 cm. An eyetracker (Arrington Research, ViewPoint PC-60) was mounted on the chinrest, and eye movements were recorded (glint-pupil vector method at 30 Hz) using the same computer. Each participant completed two tasks in a counterbalanced order. For one task, the participants were instructed to keep their gaze on the fixation dot as long as it was present on the screen (henceforth referred to as constrained eye movement (CM) task). For the other, they were free to follow the target with their gaze (smooth pursuit task, or SP), although the fixation point was present as well. Except for the eye movement instructions, both tasks were exactly the same. Each trial started with the presentation of the fixation point until the participants acknowledged that they were ready to initiate the next trial by pressing the left button of an optical mouse. The animation started immediately afterward. Contingent with the vanishing of the fixation dot, a cross-shaped cursor, controllable with the mouse, appeared randomly in an area of 400 × 400 px around the center of the screen. The participants were required to indicate, as precisely as possible, the remembered location on the screen where the target had vanished, referring to its geometrical center, by positioning the cursor on the desired position and confirming each response by pressing the left button of the mouse. Prior to each task, the participants completed four practice trials randomly chosen from the experimental set. The whole session lasted for about 50 min, including instructions, the debriefing, and an intertask pause.
Results
For each trial, both the horizontal (O-displacement) and vertical (M-displacement) arithmetic differences (see Fig. 1, vertical motion pictograms) between the participant's response and the location of the target on the last frame of the animations was calculated and averaged across replications. A preliminary analysis revealed that the location of the fixation dot affected only O-displacement, and solely in the CM task. Since this result can be fully accounted for by a foveal bias (Kerzel, 2002; Müsseler et al., 1999), no further analysis was performed on the O-displacement, and the M-displacements were averaged across the two locations of the fixation point. Moreover, an ANOVA performed over the entire data set with task as a repeated measures factor revealed a main effect of the eye movement instructions, F(1, 17) = 198.07, p < .001, partial η 2 = .92, as well as significant interactions between task and motion direction, F(1, 17) = 8.5, p = .01, partial η 2 = .33, and between task and location of the fixation dot, F(1, 17) = 4.9, p = .041, partial η 2 = .22. The results were hence subjected to two repeated measures ANOVAs, one for each task.
Smooth pursuit task
Figure 2a depicts the mean M-displacements as a function of retention times (abscissa) for both downward- and upward-moving targets (line parameter). It can be seen that descending targets resulted in an overall bigger displacement (M = 7.97, SD = 4.48) in the direction of motion, as compared with ascending targets, F(1, 17) = 30, p < .001, partial η 2 = .64, where M-displacement was negative (that is, in a direction opposite to target’s motion; M = −13.76, SD = 3.94). Moreover, retention time had a significant effect, F(4, 68) = 3.07, p = .02, partial η 2 = .15. For descending targets, M-displacement in the direction of motion increased with time, stabilizing at about 10 px after 300 ms (thus evolving at a rate of about 33.3 px/s, or 1 º/s, during the first 300 ms). For ascending targets, the negative M-displacement first increased slightly until 300 ms, decreasing for longer times. These trends were captured in a significant interaction between retention time and direction, F(4, 68) = 2.6, p = .044, partial η 2 = .13.

M-displacement as a function of time (abscissa) for downward-moving (full lines) and upward-moving (dashed lines) targets in the smooth pursuit (SP) task (a) and the constrained eye movement (CM) task (b) in Experiment 1. Note that in the CM task, during stimulus presentation, the gaze was directed at −86 pixels on the ordinate axis
Constrained eye movements task
For the CM task, trials where participants failed to follow the fixation instruction were excluded—that is, whenever gaze fell outside a region of interest of 30 px around the fixation location during stimulus presentation and retention. These cases amounted to less than 3 % of the total amount of trials. Figure 2b shows the mean results for the remaining data. It can be seen that, different from the SP task, overall M-displacements were negative (that is, contrary to the direction of motion and toward the location of the gaze, located at −86 px). The difference between ascending (M = −35.9, SD = 2.8) and descending (M = −23.4, SD = 3.9) targets was likewise significant, F(1, 17) = 12.73, p = .002, partial η 2 = .43, with downward-moving targets resulting in a bigger displacement in the direction of motion. Retention time was marginally significant, F(4, 68) = 2.43, p = .056, partial η 2 = .13, with no evidence of an interaction with direction of motion, F(4, 68) < 1. In general, this trend seems to reflect simply a drift toward gaze location (foveal bias).
Eye movement data
For the CM task, and after the retention interval, participants typically made a saccade toward the remembered vanishing location, preceded on some trials by a saccade to the location of the cursor.
In the SP task, participants smoothly pursued the target while it was present. The mean vertical location of gaze (in degrees of visual angle, with 0 being the objective vanishing location of the target) is plotted in Fig. 3 against time (with 0 being the moment when the target vanished) for the 0-, 150-, 300-, 450-, and 600-ms retention intervals (panels a, c, e, g, and i, respectively) and for the downward-moving (continuous lines) and upward-moving (dashed lines) targets. It can be seen that participants’ eyes kept moving in the same direction and at the same velocity as the target after its disappearance, stabilizing at a fixed location after about 300 ms (at almost 2º beyond the vanishing location). Importantly, this trend was observed with no differences for both the ascending and descending targets. It thus seems that the gaze location during the retention intervals does not in any way mimic what was found for the behavior localization measures (M-displacement; Fig. 2a).

Mean vertical gaze locations for the smooth pursuit task for the downward-moving (continuous lines) and upward-moving (dashed lines) targets in Experiment 1. The left column depicts the gaze location from 200 ms before the vanishing of the target until the end of each retention interval (row panels; for the 0-ms condition, the gaze locations during the first 50 ms of the response stage are also plotted). Both time (abscissa) and gaze location were scaled so that 0 corresponded to the point in space and time when the target vanished. The right column depicts the mean vertical gaze location after the end of the retention intervals and until a response was given. The abscissa represents time normalized to response times such that 1 refers to the moment when a response was given. The gaze locations below 0.3 of normalized time are not shown, due to the presence of saccades to the random location of the mouse cursor
Panels b, d, f, h, and j of Fig. 3 present the mean vertical location of the gaze against the time until response (normalized time, with 1 being the moment when a response was provided) after the 0-, 150-, 300-, 450-, and 600-ms retention intervals, respectively. In contrast to what was observed during the retention intervals, the gaze location for descending targets during response tends to increase (beyond the target’s vanishing location), while for ascending targets the gaze location decreases toward the objective vanishing location. These outcomes clearly suggest that the differences in the behavioral localization measures between the downward- and upward-moving targets are reflected in the gaze behavior only when the response is being given. Note, however, that despite the congruent trends between the behavior localizations and the gaze location during response, they do not exactly correspond; for instance, while the mean M-displacement for ascending targets was negative, signaling a remembered location behind the vanishing position, the mean gaze location did not drift below that same position. This difference cannot, however, be ruled out as due to the effective spatial-temporal resolution of the eyetracker.
Discussion
The obtained results replicate previous findings that descending targets produce larger displacements in the direction of motion than do ascending ones (Hubbard, 1990, 2001; Hubbard & Bharucha, 1988), although the magnitudes of the spatial displacements found in the present study are somewhat smaller than those reported by Hubbard and Bharucha (1988, Experiment 1). This may be due to the presence of the fixation dot in our study, which was located behind the vanishing positions. It is known that the mere presence of a fixation dot can lead to spatial biases, most probably due to attentional mechanisms directed toward that cued location (see Sheth & Shimojo, 2001). Importantly, with constrained eye movements, larger displacements for downward-moving targets were likewise observed, despite the fact that the remembered vanishing location of the target was displaced toward the fixation position, 86 pixels behind the vanishing locations (foveal bias; e.g., Kerzel, 2002; Müsseler et al., 1999). One can thus safely assume that oculomotor behavior does not, by itself, account for the effects of gravity. This point is further supported by the gaze patterns disclosed when participants were free to move their eyes (SP condition). The SP eye movements were shown to overshoot the vanishing location of the target by similar amounts, irrespective of the direction of motion (downward or upward). It thus seems that, in the presence of the moving target, SP eye movements are not altered as a function of whether the tracking is made toward or against gravity. Eye movement behavior does, however, change differently for downward- or upward-moving targets during the positioning of the cursor in the remembered vanishing location—that is, while the participants are providing their responses. Overall, these outcomes lend support to the hypothesis that during the representational process, oculomotor behavior mimics the representational mechanics recruited while this task is performed. Since no external visual stimulus (besides the cursor controlled by the participant) was present during the response stage, we surmise that this pattern was driven internally. Oculomotor behavior, along with the spatial mislocalizations, thus seems to be an epiphenomenon of the internal model of gravity (see also De Sá Teixeira et al., 2013).
With regard to representational trajectory, the remembered vanishing location for the descending targets increased downward with time until a plateau was reached at about 300 ms, for the SP condition. Conversely, for ascending targets, the remembered vanishing location shifted little with time, except for a small tendency to increase upward during the first 300 ms and to decrease downward for longer times. It is important to emphasize that the target’s motion direction and the pull of gravity were aligned in our stimuli. In this sense, the representational trajectory for descending targets (which move toward the gravity pull) closely resembles the temporal evolution profile of the displacements in the direction of motion for horizontally moving targets (Kerzel, 2000; see also De Sá Teixeira et al., 2013; Freyd & Johnson, 1987). The significance of this finding is further reinforced by the fact that, for ascending targets (which move against the gravity pull), a disparate representational trajectory was found instead, apparently unveiling the conflict between the target’s own motion direction and the gravity vector. This picture is profoundly affected when participants’ eye movements are constrained. When such is the case, no dynamic change of the remembered vanishing location is found (except for a slight drift toward the fixation location; for a similar result, see Sheth & Shimojo, 2001), and a foveal bias dominates instead.
It might be argued that, since participants necessarily take some time to indicate the remembered vanishing locations, this additional temporal interval could change the disclosed dynamic profile. In fact, an analysis of the response times revealed that participants responded faster with longer retention intervals, F(4, 68) = 3.94, p = .006, partial η 2 = .18. This trend makes sense, since with longer retention delays, people would have more time to plan the intended location. Importantly, this trend did not compromise the monotonicity of the downward drift but slightly increased its rate. Thus, our estimate of 1 º/s might be conservative. However, by exploring the correlations between spatial localizations and response times, we found no evidence that the mislocalizations changed differentially when people took more time to respond. This null finding suggests that the localizations were made toward the spatial position intended when the motor response was initiated.
Taken together, these results support the hypothesis that an internal model of gravity is involved in the mnesic spatial updating of the vanishing location of a moving target. Given the role that eye movements seem to have in this task, gaze does not seem to be an explanatory factor for the observed pattern but, instead, acts either as an epiphenomenon, when left unconstrained, or as a conflicting factor that masks representational trajectory when constrained and due to the dominance of a foveal bias.
Experiment 2: Representational trajectory for static targets
The outcomes of Experiment 1 supported an internalized model of gravity in the visual representation system. These conclusions add to previous research in representational gravity: In general, the memory for the location of a moving target drifts downward with time for both horizontally (cf. De Sá Teixeira et al., 2013) and vertically moving targets (Experiment 1, and modulated by the target’s movement direction).
Given the apparent ubiquity of this temporal profile for the mnesic location of a target, one can question whether movement is necessary at all to trigger the internal model of gravity thought to be responsible for these displacements. Previously, Hubbard and Ruppel (2000, Experiment 4) reported that the remembered location of statically presented targets is significantly displaced downward in the direction of gravity. This outcome was taken as evidence for representational gravity. However, it is still to be determined whether the spatial memory for static targets presents a temporal evolution in any way similar to a representational trajectory. The aim of the present experiment was to appraise this possibility. Our main hypothesis was that the remembered location of stationary targets would drift downward in the direction of gravity as increasing time intervals were imposed after stimulus presentation.
Method
Participants
Twenty new participants (18 females, 2 males) volunteered for the experiment. Their ages ranged from 18 to 28 years old (M = 19.5, SD = 3.3). All of them had normal or corrected-to-normal vision and were unaware of the purposes of the experiment.
Stimuli and design
A black circle 30 px in diameter (≈0.9º) was used as the target, shown on an otherwise white background. No fixation point or any other visual element was present onscreen besides the target. The experiment followed a repeated measures design with seven retention intervals and 20 replications.
Apparatus and procedure
The experiment was run on a personal computer equipped with a flat screen, with a resolution of 1,280 × 1,024 px (physical size of 33.7 × 27 cm; 37.2 × 30.2º) and a refresh rate of 60 Hz and with an optical mouse. The participants sat about 50 cm from the screen with no eye or head constraints but were instructed to maintain a steady posture during the task. On each trial, the target was shown for 150 ms at a random position within an area of 200 × 200 px centered on the screen. A plus-shaped cursor (+), controllable with the mouse, appeared at the center of the screen 0, 100, 200, 300, 400, 500, or 600 ms after the stimulus disappearance.. The participant was required to move the cursor to the remembered location of the target, as precisely as possible, referring to its geometrical center, and to confirm the desired position by pressing the left button of the mouse. A random interstimulus interval of between 1 and 3 s preceded the start of the next trial. The task lasted between 10 and 15 min, including instructions and debriefing.
Results
Since M- and O-displacements are errors relative to the direction of motion (see Experiment 1 and Fig. 1), they bear no meaning for static targets. Therefore, the horizontal and vertical errors between the target’s objective position and the location indicated by the participants were measured instead, henceforth referred to as H- and V-displacements, respectively. H-displacement, the arithmetic difference between each target’s horizontal location onscreen and the corresponding position indicated by each participant was calculated so that negative numbers referred to responses displaced leftward and positive numbers to displacements rightward. Likewise, for V-displacement, the vertical differences between the target’s objective location and the position indicated by the participant were calculated so that negative numbers reflect displacements downward and positive numbers displacements upward. The data thus obtained were subjected to two ANOVAs, one for each component (V and H), with retention time as the repeated measures factor.
Retention time significantly affected V-displacement, F(6, 144) = 3, p = .009, partial η 2 = .137, but not H-displacement, F(6, 144) < 1. Overall, with longer retention intervals, V-displacement increased downward, as reflected by a significant linear component, F(1, 24) = 5.792, p = .001, partial η 2 = .45.
To further explore this effect, targets’ objective locations were separated into the upper or lower half of the screen (above or below the screen’s midpoint, respectively; for an effect of height in the picture plane with vertically moving targets, see Hubbard, 2001), and the V-displacement data were subjected to a repeated measures factorial ANOVA with screen section (upper and lower) and retention times as factors. The factors of screen section, F(1, 19) = 6.34, p = 021, partial η 2 = .25, and retention time, F(6, 114) = 3, p = .009, partial η 2 = .14, and an interaction between both variables, F(6, 114) = 2.19, p = .049, partial η 2 = .1, were significant. Figure 4 plots the mean V-displacements as a function of retention time for the targets located in the upper half (white circles and dashed line) and the lower half (black circles and continuous line). It can be seen that the displacements for targets shown in the upper half decrease steadily with time. In contrast, targets presented in the lower half seem to drift downward only up until 300 ms.

Mean V-displacements in Experiment 2 as a function of retention time (abscissa) for targets shown above (upper half: white circles and dashed line) or below (lower half: black circles and continuous line) the screen’s midpoint
The slope of the best linear fit between retention time and V-displacement was calculated on an individual basis for targets located in the upper and lower sections of the screen, and the mean values were subjected to 2 one-sample t-tests. The mean slope for the upper section (M = −7.3 px/s, SD = 0.0074) was shown to be significantly different from 0, t(19) = −4.39, p < .001, two-tailed, d = 0.98, but not the mean slope for targets in the lower section (M = −2.5 px/s, SD = 0.008), t(19) = −1.37, p = .187, two-tailed. Separate fits to the times below and above 300 ms for targets presented in the lower section of the screen showed, however, that the mean individual slopes were negative and significantly different from zero, t(19) = −2.439, p = .025, two-tailed, d = 0.56, until 300 ms (M = −14 px/s, SD = 0.025), but not for longer times, t(19) = 1.48, p = .155. The memory for the location of the target thus drifted downward at a rate of about 7.3 px/s (0.21 º/s) when the target was shown above the screen’s midpoint and during at least 600 ms and at about 14 px/s (0.4 º/s) for targets shown in the lower half for the first 300 ms, stabilizing afterward.
Discussion
Overall, the memory for the location of a static target was shown to drift downward with time. This trend was modulated by the height on the screen where the target was shown, with the memory for targets presented in the upper half of the monitor leading to a steady downward drift of about 7.3 px/s, or 0.21 º/s. In contrast, targets presented in the lower half showed only a tendency to drift downward during the first 300 ms at a rate of about 14 px/s, or 0.4 º/s, stabilizing for longer times.
As in Experiment 1, participants showed a proneness to respond faster with longer retention times, F(6, 144) = 26.17, p < .001, partial η 2 = .52. However, we once again found no evidence of a correlation between response times and magnitude of V-displacement. This suggests again that the motor behavior is being directed toward the intended location at the time of response initiation. Thus, the decrease of response times with increases in retention interval would lead to an increase in the rate of downward drift, which might thus be underestimated, if anything.
The inclusion of retention intervals allowed us to probe the dynamics of the remembered locations of the targets. The results further support previous evidence for the involvement of an internal model of gravity in the visual representation. Importantly, the rate of the downward drift found in the present experiment—in degrees of visual angle, between 0.4 and 0.21 º/s—is close to, albeit somewhat higher than, the rate we found in the O-displacement for horizontally moving targets (about 0.22 º/s for ranges of retention intervals below 300 ms; cf. De Sá Teixeira et al., 2013, Experiment 3a). In sum, the remembered spatial location of visually shown objects drifts steadily downward with time, irrespective of their kinematics or lack thereof; this trend is surmised to reflect an internal model of gravity.
Experiment 3: Disentangling perceived dynamics and retinotopic coordinates in representational trajectory
Until now, the memory for the last seen position of visually presented targets has been shown to steadily drift downward in the direction of gravity for horizontally moving targets (assessed by the time course of O-displacement; De Sá Teixeira et al., 2013), descending targets (Experiment 1), and static targets (Experiment 2). For vertical movements, the memory for the position of descending targets drifts downward at a rate of about 1 º/s during the first 300 ms, stabilizing afterward. No temporal profile is evident for ascending movements. A target’s perceived kinematics (due to representational momentum) seems thus to either conflict with or be fostered by the gravitational pull (for ascending or descending targets, respectively). For the remaining instances (static or horizontally moving targets), representational trajectory seems to evolve at a constant rate of at least 0.21 º/s, for times up to 600 ms.
Although it seems warranted that dynamic characteristics reflect an internal neural model of gravity, the processing level at which such a model operates is still to be ascertained. It might be the case that internalized gravity leads to a systematic displacement in retinotopic coordinates, thus reflecting a perceptual downward bias. That the found downward displacements emerge irrespective of the target’s kinematics is certainly compatible with that assertion.
The aim of the next experiment was to explore this issue by taking advantage of the fact that objects in the environment move upward in the visual field when the observer moves downward and vice versa. Previous studies have shown the reliability of measuring spatial displacements (usually representational momentum) with ego-motion displays (see, e.g., Amorim et al., 2000; Blättler, Ferrari, Didierjean & Marmèche, 2011). On the other hand, studies on spatial updating and path integration (e.g., Farrell & Robertson, 1998; Klier & Angelaki, 2008; Rieser, 1989; Wan, Wang & Crowell, 2009) have shown that people are reasonably accurate at keeping track of objects in their environment as they move around.
For our study, and in order to elicit impressions of ascending or descending ego-motion, we capitalized on vection cues. When the visual environment moves uniformly in a given direction (optical flow), the observer may experience illusions of self-motion in the opposite direction (vection; see Fischer & Kornmüller, 1930). Optical flow seems to strongly activate both the dorsal medial superior temporal (e.g., Duffy & Wurtz, 1991a, 1991b; Orban, Lagae, Raiguel, Xiao & Maes, 1995) and the ventral intraparietal (e.g., Zhang & Britten, 2010; Zhang, Heuer & Britten, 2004) cortical areas, known to be also tuned to vestibular stimulation (Chen, Henry, DeAngelis & Angelaki, 2007; Gu, Angelaki & DeAngelis, 2008; Takahashi et al., 2007; but see also Chen, DeAngelis & Angelaki, 2011).
Despite previous claims that stimulation in the retinal periphery, but not foveal stimulation, is required for vection (Brandt, Dichgans & Koenig, 1973; Johansson, 1977), subsequent studies showed that motion in the center of the visual field could be as effective as in the periphery, as long as the optic flow was perceived as background (cf., e.g., Telford & Frost, 1993; Telford, Spratley & Frost, 1992), or simply by constraining eye movements with the presentation of a fixation dot (e.g., Tarita-Nistor, González, Spigelman & Steinbach, 2006; the presence of the fixation dot might, by itself, induce observers to perceive the motion displays as background, thus fostering the impression of vection; Telford & Frost, 1993). Notwithstanding, and overall, the wider the visual field, the more compelling the resultant self-motion impression.
In the following experiment, by presenting ascending or descending targets either with or without vection cues, we sought to determine whether the downward displacement depends only on the retinotopic path and vanishing location of the target or whether it is responsive to the implied dynamics of the event (a target moving downward as seen by a static observer, as opposed to a static object in the environment as seen by an observer moving upward). Eye movements were constrained (as in the CM condition in Experiment 1) in order to maximize the impression of ego-motion (cf. Tarita-Nistor et al., 2006). We hypothesized that, in accordance with Experiment 1, the remembered vanishing locations would drift toward the gaze with time but that the asymmetry between ascending and descending targets would be reversed when the target was accompanied by vection.
Method
Participants
Thirty-five students at the University of Coimbra (30 females, 5 males) participated in the experiment in exchange for partial course credits. Their ages ranged from 18 to 35 years (M = 19.7, SD = 3.7). All participants had normal or corrected-to-normal vision and were unaware of the purposes of the experiment. No participant had known vestibular deficits.
Stimuli and design
A set of animations were used as stimuli. These depicted a black circle (target) 30 px in diameter (≈ 1.15º), traveling upward or downward at a constant velocity of 375 px/s (14.25 º/s). The target’s trajectory was always centered horizontally. Each animation included randomly distributed gray (RGB: 127, 127, 127) blobs, with an average size of 20 px and on an otherwise white background, which filled the entire screen. There were two different sets of animations (see Fig. 5a): In one of those, the target moved over the static gray blobs background (target-only condition); in the other set, both the target and the gray blobs background moved together at the same velocity and in the same direction (target-plus-vection condition). Each animation lasted about 7.8 s, with the target emerging from the upper or lower edge of the screen (for downward and upward motion directions, respectively) either in the last 1.86 s, disappearing after covering 700 pixels (100 pixels or 3.8º after the screen’s midpoint), or in the last 1.73 s, vanishing after covering a distance of 650 pixels (50 pixels or 1.9º after crossing the screen’s midpoint). That is, prior to the emergence of the target in the visual field, participants were exposed to 6 s of vection (on the target-plus-vection trials) or the static background (for target-only trials). This duration was found to be, in preliminary studies, compelling enough to induce self-motion but still sufficiently short to keep the experimental session within reasonable durations. Immediately after the vanishing of the target, a retention interval of 0, 200, 400, 600, 800, or 1,000 ms was imposed. The choice of a wider range of times was motivated by preliminary results that suggested that the temporal dynamics of the displacements might evolve differently for times longer than 600 ms with these displays. During all retention intervals except 0 ms, a neutral gray screen, resulting from the average brightness of the blobs background, was shown in order to minimize afterimages in the target-only condition. During the entire animation, a 5-px black fixation dot, centered vertically and 40 pixels (1.55º) to the left or to the right of the target’s motion trajectory, was shown over the background. The fixation dot was always shown behind the vanishing location of the target (50 or 100 px vertically) with respect to its motion direction. A total of 96 animations were thus obtained, each presented 4 times, resulting in a 2 (motion type: target only, target + vection) × 2 (motion direction) × 2 (covered distance: 650 or 700 px) × 2 (fixation dot location: leftward or rightward) × 6 (retention interval) factorial design, with each stimulus being presented 4 times per participant.

a Stimuli used in Experiment 3. The black arrows refer to the motion of the target (black circle), and gray arrows to the motion of the blobs on the background. b Experimental apparatus and participants’ posture
Apparatus and procedure
The experiment was run on a personal computer equipped with a flat screen with a resolution of 1,920 × 1,200 px (physical size of 52 × 32 cm; 66.1 × 43.6º) with a refresh rate of 60 Hz and a 1.8-in. trackball (Adesso iMouse T1). The visual field was restricted with a black shroud so that no other extraneous visual stimulation besides the screen was shown (see Fig. 5b). Also, and since the experimental room had no sound isolation, participants wore an earmuff that prevented potential acoustic spatial cues (e.g., from the corridor and/or the street outside). Participants sat in front of the screen, with head movements constrained by a chinrest, such that their cyclopean eye was aligned with the center of the screen and at a fixed distance of 40 cm. Participants were instructed to keep their gaze on the fixation dot as long as it was present on the screen and were told that they might feel a sensation of ego-motion on some of the trials. Eye movements were not monitored, since previous experiments had shown that participants do follow this instruction reasonably well (see Experiment 1 and De Sá Teixeira et al., 2013, Experiment 3). Each trial started with the presentation of the fixation point on the blobs background until the participants acknowledged that they were ready to start the trial by pressing the left button of the trackball. For the target-only conditions, the background was kept static and, 6 s later, the target emerged from the bottom or top (for upward or downward directions) edge of the screen. For the vection conditions, the blobs background started to move upward or downward, and, 6 s later, the target emerged, respectively, from the bottom or top edge of the screen, moving together with the background until reaching the vanishing location. Upon the end of the retention interval, the entire screen turned white, the fixation dot disappeared, and a plus-shaped cursor, controllable with the trackball, appeared on a random location inside a 400 × 400 px area centered on the screen. Participants were instructed to locate the vanishing location of the target as precisely as possible and referring to its geometrical center, by moving the cursor to the appropriate position and confirming the response by pressing the left button of the trackball. The next trial started immediately afterward. Before the experiment, each participant was allowed to complete eight practice trials. The entire experimental session lasted about 50 min, including instructions and the debriefing.
Results
During debriefing, all but 2 participants reported that the target plus vection stimuli elicited self-motion sensations, with the majority (about 80 %) reporting a vivid impression. The 2 participants who reported no vection-like sensations referred, instead, to an apparent motion of the fixation dot. Notwithstanding, their behavioral results were in all respects like the ones for the remaining participants, and deletion of their data did not change the global outcomes. Therefore, their data were included in the analyses.
Both M- and O-displacements were calculated as in Experiment 1. Similarly, O-displacement was shown to be modulated only by the location of the fixation dot, and thus, no further analyses were performed on this measure.
As for M-displacement, a repeated measures factorial ANOVA revealed a significant effect of retention interval, F(5, 170) = 3.95, p = .002, partial η 2 = .1, with only a marginally significant interaction with the presence/absence of vection, F(5, 170) = 2.25, p = .052, partial η 2 = .06. Overall, with longer retention intervals, the displacement increased in the direction of motion when it was accompanied by vection. Direction of target’s motion (upward vs. downward) was not significant, F(1, 34) < 1, but it did interact with the presence/absence of vection, F(1, 34) = 7.05, p = .012, partial η 2 = .17. A close inspection of the results revealed that targets moving downward without vection lead to a bigger displacement in the direction of motion, as compared with upward-moving targets. Conversely, when target and vection motion was shown, upward-moving targets resulted in a bigger displacement in the direction of motion, as compared with downward motion (see Fig. 6). No other main effect or interaction reached the statistical significance level.

Mean M-displacements in pixels for the downward (black circles and continuous lines) and the upward (white circles and dashed lines) moving targets with (b) or without (a) vection as a function of the retention intervals (in milliseconds; abscissa) in Experiment 3. Note that, during stimuli presentation, the gaze was focused behind the vanishing location (−50 or −100 px on the ordinate, depending on the covered distance)
Figure 6 shows the outcomes of Experiment 3. Mean M-displacement is plotted for both downward-moving (black circles and continuous lines) and upward-moving (white circles and dashed lines) targets as a function of retention time. Panel a depicts the results for target motion alone, while panel b refers to target plus vection. Note that, overall, the displacements were negative, signaling a foveal bias (compare with the CM condition in Experiment 1). It can be clearly seen that motion direction had an opposite effect depending on the presence or absence of vection. Note that when both target and background move upward (vection), the stimulation is compatible with a downward motion of the observer, the inverse being true for target plus vection moving downward.
Discussion
On the premise that our stimuli effectively induced vection, the inversion of the effect of motion direction when it was present strongly suggests that the bigger downward displacement is sensitive to the interpretation of the motion pattern presented to the observer. That is, both a target moving alone downward and an observer “moving” downward (with the visual field moving upward in the retinotopic frame of reference) result in a bigger displacement of the remembered target location in the direction of perceived motion. This pattern thus seems to emerge for dynamic events in general, as long as they unfold toward the gravitational pull.
Some known visual phenomena can, however, qualify this conclusion. First and foremost, it could be hypothesized that, due to the sustained presentation of vertical visual flow for 6 s, a motion aftereffect (MAE) results and is present by the time participants are required to provide their answers. MAEs are rendered visible when a static image is presented to observers previously subjected to prolonged motion stimulation; in such cases, the static target seems to move in the opposite direction (see Anstis, Verstraten & Mather, 1998; Mather & Harris, 1998). On the one hand, our stimuli might not have been long enough to result in a significant MAE (Anstis et al., 1998, refer to adaptation periods of at least 15–20 s, but periods as long as 60 s have been used; e.g., Mather, 1980). On the other hand, and as far as we know, MAE strength does not depend on motion direction and, thus, cannot account for the difference between ascending and descending targets.
It could also be hypothesized that target plus vection results in a stronger coherent motion signal than does the target-only condition (see, e.g., Edwards & Badcock, 1998). We surmise that if such were the case, the overall displacements in the vection stimuli would be significantly higher (which was not the case) and would still not account for the difference between downward- and upward-moving targets, since the ensuing prediction would include no anisotropy. Motion signal strength—that is, more things moving coherently in a certain direction—might, however, explain the time course disclosed for the target-plus-vection condition. Contrary to the findings of Experiment 1 (CM condition), the memory for the location of the target when accompanied with vection further increased in the direction of motion with increasing retention intervals. This trend was not observed in the target-only condition. It is possible that strengthened motion stimulation supersedes the previous finding of a drift toward the fixation point due to a foveal bias. Conversely, it could be hypothesized that an ego-motion momentum possesses more inertia in the representation of movement (see, e.g., Amorim et al., 2000, for a similar account). Our present data do not allow disentangling between these two alternatives.
The employed design did not measure the perceived strength of vection impressions on a trial basis, although all participants were queried in this respect during the debriefing, and referring to the overall impression. On the basis of these reports, our stimuli were efficient in inducing sensations of ego-motion. Building on this assumption, our results provide evidence that the internalized model of gravity responds to the implied dynamics of the visual cues, rather than to the shown retinotopic kinematics. At the very least, the obtained outcomes disprove the hypothesis that the downward displacements are due to a perceptual bias to systematically locate targets below their objective vanishing locations.
Be that as it may, the outcomes of this experiment open the prospect to further inquiries regarding the role of representational gravity and visually induced self-motion. Future studies should build upon this result by varying the magnitude of vection (e.g., by presenting peripheral stimulation) and the relative velocities of target and background and by correlating measures of self-motion (see, e.g., Carpenter-Smith, Futamura & Parker, 1995).
General discussion and conclusion
Across three experiments, we replicated previous findings where the memory for the spatial position of a target is displaced downward in the direction of gravity (Hubbard, 1990, 2001).This trend does not critically depend on the target’s kinematics or lack thereof. Moreover, we extended these findings by showing that, even though the spatial memory is biased toward the location of the fovea (Kerzel, 2002), eye movements do not account for the systematic downward displacement in memory. Instead, oculomotor behavior seems to be an epiphenomenon of the representational process. This point is further reinforced by the temporal profile of the downward displacement, which extends our previous report (De Sá Teixeira et al., 2013). For descending targets, the downward displacement increases rapidly at a rate of about 1 º/s during the first 300 ms, stabilizing afterward; for ascending targets, in contrast, the memory for their last location changes little with time. As for static targets, the spatial memory tends to drift steadily downward at a rate of about 0.21 º/s during at least the first 600 ms when the target is shown above the screen’s midpoint; a similar trend has been previously reported for the downward drift of horizontally moving targets (about 0.22 º/s; cf. De Sá Teixeira et al., 2013). When, on the other hand, a static target is shown below the screen’s center, its spatial memory drifts downward at a rate of about 0.4 º/s, stabilizing after 300 ms. Finally, the outcomes of our third experiment suggest that the downward displacement is not purely a retinotopic downward bias but is, instead, sensitive to the implied dynamics of the kinematic stimulation; both an object moving downward and a perceived descending motion of the observer lead to bigger displacements than does an object or an observer moving upward, against gravity.
Taken together, these results provide important clues as to the representational mechanics of an internal model of gravity. As one of the most ubiquitous environmental constraints, gravity plays a paramount role in structuring our environment and our spatial perception of it. While keeping track of the spatial locations of ourselves and the objects around us, our visual representational system takes into account an internalized estimate of gravity, its effects, and, importantly, how events should unfold in the near future. This is indirectly reflected in small dynamic biases in the remembered location of moving objects. The results reported here further strengthen this view and highlight how the temporal dynamics may reveal the boundaries of the mechanics of an internal model of gravity.
References
Amorim, M. A., Lang, W., Lindinger, G., Mayer, D., Deecke, L., & Berthoz, A. (2000). Modulation of spatial orientation by mental imagery: A MEG study of representational momentum. Journal of Cognitive Neuroscience, 12, 569–582.
Angelaki, D. E., Shaikh, A. G., Green, A. M., & Dickman, J. D. (2004). Neurons compute internal models of the physical laws of motion. Nature, 430, 560–564.
Anstis, S., Verstraten, F., & Mather, G. (1998). The motion after-effect. Trends in Cognitive Sciences, 2, 111–117.
Ashida, H. (2004). Action-specific extrapolation of target motion in human visual system. Neuropsychologia, 42, 1515–1524.
Baurès, R., & Hecht, H. (2011). The effect of body posture on long-range time-to-contact estimation. Perception, 40, 674–681.
Blättler, C., Ferrari, V., Didierjean, A., & Marmèche, E. (2011). Representational momentum in aviation. Journal of Experimental Psychology: Human Perception and Performance, 37, 1569–1577.
Brandt, T., Dichgans, J., & Koenig, E. (1973). Differential effects of central versus peripheral vision on egocentric and exocentric motion perception. Experimental Brain Research, 16, 476–491.
Carpenter-Smith, T. R., Futamura, R. G., & Parker, D. E. (1995). Inertial acceleration as a measure of linear vection: An alternative to magnitude estimation. Perception and Psychophysics, 57, 35–42.
Chen, A., DeAngelis, G. C., & Angelaki, D. E. (2011). A comparison of vestibular spatiotemporal tuning in macaque parietoinsular vestibular cortex, ventral intraparietal area, and medial superior temporal area. Journal of Neuroscience, 31, 3082–3094.
Chen, A., Henry, E., DeAngelis, G. C., & Angelaki, D. E. (2007). Comparison of responses to three-dimensional rotation and translation in the ventral intraparietal (VIP) and medial superior temporal (MST) areas of rhesus monkey. Society of Neuroscience Abstracts, 33, 715–719.
De Sá Teixeira, N. A, Hecht, H., & Oliveira, A. M. (2013). The representational dynamics of remembered projectile locations. Journal of Experimental Psychology: Human Perception and Performance, 39, 1690–1699.
De Sá Teixeira, N. A., & Oliveira, A. M. (2011). Disambiguating the effects of target travelled distance and target vanishing point upon representational momentum. Journal of Cognitive Psychology, 23, 650–658.
Duffy, C. J., & Wurtz, R. H. (1991a). Sensitivity of MST neurons to optic flow stimuli. I. A continuum of response selectivity to large field stimuli. Journal of Neurophysiology, 65, 1329–1345.
Duffy, C. J., & Wurtz, R. H. (1991b). Sensitivity of MST neurons to optic flow stimuli. II. Mechanisms of response selectivity revealed by small-field stimuli. Journal of Neurophysiology, 65, 1346–1359.
Edwards, M., & Badcock, D. R. (1998). Discrimination of global-motion signal strength. Vision Research, 38, 3051–3056.
Farrell, M. J., & Robertson, I. H. (1998). Mental rotation and automatic updating of body-centered spatial relationships. Journal of Experimental Psychology: Learning, Memory, & Cognition, 24, 227–233.
Fischer, M. H., & Kornmüller, A. E. (1930). Optokinetisch ausgelöste Bewegungswahrnehmung und optokinetischer Nystagmus [Optokinetically induced motion perception and optokinetic nystagmus]. Journal für Psychologie und Neurologie, 273–308.
Freyd, J. J. (1983). The mental representation of movement when static stimuli are viewed. Perception & Psychophysics, 33, 575–581.
Freyd, J. J., & Finke, R. A. (1984). Representational momentum. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 126–132.
Freyd, J. J., & Finke, R. A. (1985). A velocity effect for representational momentum. Bulletin of the Psychonomic Society, 23, 443–446.
Freyd, J. J., & Johnson, J. Q. (1987). Probing the time course of representational momentum. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13, 259–269.
Grush, R. (2005). Internal models and the construction of time: Generalizing from state estimation to trajectory estimation to address temporal features of perception, including temporal illusions. Journal of Neural Engineering, 2, S209–S218.
Gu, Y., Angelaki, D. E., & DeAngelis, G. C. (2008). Neural correlates of multisensory cue integration in macaque MSTd. Nature Neuroscience, 11, 1201–1210.
Haji-Khamneh, B., & Harris, L. R. (2010). How different types of scenes affect the subjective visual vertical (SVV) and the perceptual upright (PU). Vision Research, 50, 1720–1727.
Hess, B. J., & Angelaki, D. E. (1999). Oculomotor control of primary eye position discriminates between translation and tilt. Journal of Neurophysiology, 81, 394–398.
Hubbard, T. L. (1990). Cognitive representation of linear motion: Possible direction and gravity effects in judged displacement. Memory & Cognition, 18, 299–309.
Hubbard, T. L. (2001). The effect of height in the picture plane on the forward displacement of ascending and descending targets. Canadian Journal of Experimental Psychology, 55, 325–330.
Hubbard, T. L. (2005). Representational momentum and related displacements in spatial memory: A review of the findings. Psychonomic Bulletin & Review, 12, 822–851.
Hubbard, T. L. (2006). Computational theory and cognition in representational momentum and related types of displacement: A reply to Kerzel. Psychonomic Bulletin and Review, 13, 174–177.
Hubbard, T. L., & Bharucha, J. J. (1988). Judged displacement in apparent vertical and horizontal motion. Perception & Psychophysics, 44, 211–221.
Hubbard, T. L., & Ruppel, S. E. (2000). Spatial memory averaging, the landmark attraction effect, and representational gravity. Psychological Research, 64, 41–55.
Johansson, G. (1977). Studies on the visual perception of locomotion. Perception, 6, 365–376.
Kerzel, D. (2000). Eye movements and visible persistence explain the mislocalization of the final position of a moving target. Vision Research, 40, 3703–3715.
Kerzel, D. (2002). Memory for the position of stationary targets: Disentangling foveal bias and memory averaging. Vision Research, 42, 159–167.
Kerzel, D. (2003). Centripetal force draws the eyes, not memory of the target, toward the center. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 458–466.
Kerzel, D. (2006). Why eye movements and perceptual factors have to be controlled in studies on “representational momentum”. Psychonomic Bulletin & Review, 13, 166–173.6.
Kerzel, D., & Gegenfurtner, K. R. (2003). Neuronal processing delays are compensated in the sensorimotor branch of the visual system. Current Biology, 13, 1975–1978.
Kerzel, D., Jordan, J. S., & Müsseler, J. (2001). The role of perception in the mislocalization of the final position of a moving target. Journal of Experimental Psychology: Human Perception and Performance, 27, 829–840.
Klier, E. M., & Angelaki, D. E. (2008). Spatial updating and the maintenance of visual constancy. Neuroscience, 156, 801–818.
Land, M., & Tatler, B. (2009). Looking and Acting. Oxford: University Press.
Mather, G. (1980). The movement aftereffect and a distribution-shift model for coding the direction of visual movement. Perception, 9, 379–392.
Mather, G., & Harris, J. (1998). Theoretical models of the motion aftereffect. In G. Mather, F. Verstraten, & S. Anstis (Eds.), The motion aftereffect: A modern perspective (pp. 157–184). Cambridge: The MIT Press.
McIntyre, J., Zago, M., Berthoz, A., & Lacquaniti, F. (2001). Does the brain model Newton’s laws? Nature Neuroscience, 4, 693–694.
Merfeld, D. M. (1995). Modelling the vestibule-ocular reflex of the squirrel monkey during eccentric rotation and roll tilt. Experimental Brain Research, 106, 123–134.
Merfeld, D. M., Zupan, L., & Peterka, R. J. (1999). Humans use internal models to estimate gravity and linear acceleration. Nature, 398, 615–618.
Mitrani, L., & Dimitrov, G. (1978). Pursuit eye movements of a disappearing moving target. Vision Research, 18, 537–539.
Mittelstaedt, H. (1983). A new solution to the problem of the subjective vertical. Naturwissenschaften, 70, 272–281.
Mittelstaedt, H. (1986). The subjective vertical as a function of visual and extraretinal cues. Acta Psychologica, 63, 63–85.
Müsseler, J., van der Heijden, A. H. C., Mahmud, S. H., Deubel, H., & Ertsey, S. (1999). Relative mislocalization of briefly presented stimuli in the retinal periphery. Perception & Psychophysics, 61, 1646–1661.
Nagai, M., Kazai, K., & Yagi, A. (2002). Larger forward memory displacement in the direction of gravity. Visual Cognition, 9, 28–40.
Orban, G. A., Lagae, L., Raiguel, S., Xiao, D., & Maes, H. (1995). The speed tuning of medial superior temporal (MST) cell responses to optic-flow components. Perception, 24, 269–285.
Pola, J., & Wyatt, H. J. (1997). Offset dynamics of human smooth pursuit eye movements: effects of target presence and subject attention. Vision Research, 37, 2579–2595.
Poon, C.-S., & Merfeld, D. M. (2005). Internal models: the state of the art, Journal of Neural Engineering, 2, editorial.
Reed, C. L., & Vinson, N. G. (1996). Conceptual effects on representational momentum. Journal of Experimental Psychology: Human Perception and Performance, 22, 839–850.
Rieser, J. J. (1989). Access to knowledge of spatial structure at novel points of observation. Journal of Experimental Psychology: Learning, Memory, & Cognition, 15, 1157–1165.
Shepard, R. N. (2001). Perceptual-cognitive universals as reflections of the world. Behavioral Brain Sciences, 24, 581–601.
Sheth, B. R., & Shimojo, S. (2001). Compression of space in visual memory. Vision Research, 41, 329–341.
Snyder, L. (1999). This way up: illusions and the internal models in the vestibular system. Nature Neuroscience, 2, 396–398.
Takahashi, K., Gu, Y., May, P. J., Newlands, S. D., DeAngelis, G. C., & Angelaki, D. E. (2007). Multimodal coding of three-dimensional rotation and translation in area MSTd: Comparison of visual and vestibular selectivity. Journal of Neuroscience, 27, 9742–9756.
Tarita-Nistor, L., González, E. G., Spigelman, A. J., & Steinbach, M. J. (2006). Linear vection as a function of stimulus eccentricity, visual angle, and fixation. Journal of Vestibular Reserch, 16, 265–272.
Telford, L., & Frost, B. J. (1993). Factors affecting the onset and magnitude of linear vection. Perception & Psychophysics, 53, 682–692.
Telford, L., Spratley, J., & Frost, B. J. (1992). Linear vection in the central visual field facilitated by kinetic depth cues. Perception, 21, 337–349.
Tin, C., & Poon, C.-S. (2005). Internal models in sensorimotor integration: Perspectives from adaptive control theory. Journal of Neural Engineering, 2, S147–S163.
Wan, X. I., Wang, R. F., & Crowell, J. A. (2009). Spatial updating in superimposed real and virtual environments. Attention, Perception, & Psychophysics, 71, 42–51.
Zhang, T., & Britten, K. H. (2010). The responses of VIP neurons are sufficiently sensitive to support heading judgments. Journal of Neurophysiology, 103, 1865–1873.
Zhang, T., Heuer, H. W., & Britten, K. H. (2004). Parietal area VIP neuronal responses to heading stimuli are encoded in head-centered coordinates. Neuron, 42, 993–1001.
Acknowledgements
This work was supported by Grant SFRH/BPD/84118/2012, Portuguese Foundation for Science and Technology (FCT).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
De Sá Teixeira, N., Hecht, H. Can representational trajectory reveal the nature of an internal model of gravity?. Atten Percept Psychophys 76, 1106–1120 (2014). https://doi.org/10.3758/s13414-014-0626-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0626-2