
Abstract
Humans are able to perceive unique types of biological motion presented as point-light displays (PLDs). Thirty years ago, Runeson and Frykholm (Human Perception and Performance, 7(4), 733, 1981, Journal of Experimental Psychology: General, 112(4), 585, 1983) studied observers’ perceptions of weights lifted by actors and identified that the kinematic information in a PLD is sufficient for an observer to form an accurate perception of the object weight. However, research has also shown that extrinsic object size characteristics also influence the perception of object weight (Gordon, Forssberg, Johansson, & Westling in Experimental Brain Research, 83(3), 477–482, 1991). This study addresses the relative contributions of these two types of visual information to observers’ perceptions of lifted weight, through an experiment in which participants viewed an actor lifting boxes of various sizes (small, medium, or large) and weights (25, 50, or 75 lb) under four PLD conditions—box-at-rest, moving-box, actor-only, and actor-and-box—and one full-vision video condition, and then provided a weight estimate for each box lifted. The results indicated that lift kinematics and box size contributed independently to weight perception. Interestingly, the most robust weight differentiations were elicited in the conditions in which both types of information were presented concurrently, despite their converse natures. Furthermore, full-vision video presentation, which contained visual information beyond kinematics and object information, elicited the best estimates.
Similar content being viewed by others

The development of optic arrays that present only a movement’s kinematic information has proved valuable in delineating the visual information that underpins the perception of biological motion (Shim & Carlton, 1997; Thomas & Jordan, 2001; see Hodges, Williams, Hayes, & Breslin, 2007, for a review). The simplest example of such an array is found in two equidistant bright spots travelling across a formless background. These are perceived as an invisible moving rod. Likewise, four equidistant spots elicit the perception of a moving square (G. Johansson, 1964; G. Johansson & Jansson, 1968). Similarly, when recordings are made of an actor moving with reflective markers on his or her major joints and the contrast settings of the videos are altered such that only the reflectors appear against a dark background, the result is a dynamic point-light display (PLD), a compelling kinematic impression of a human in motion (Dekeyser, Verfaillie, & Vanrie, 2002; G. Johansson, 1973). The swings, translations, and rotations of the extremities about the reflected joints manifest body displacements with kinematic patterns that are so unique that movements performed by particular actors (Cutting & Kozlowski, 1977; Stevenage, Nixon, & Vince, 2000) of either sex (Kozlowski & Cutting, 1977; Mather & Murdoch, 1994) and under a variety of emotional states (Dittrich, Troscianko, Lea, & Morgan, 1996; Sevdalis & Keller, 2012) can be accurately identified by observers.
Importantly, the PLD also provides a means to explore the degree to which a movement’s visible kinematic information discloses its invisible dynamic properties (Bingham, 1987; Gilden & Proffitt, 1989; Runeson & Frykholm, 1981). For instance, PLD research has identified that sufficient information is contained in movement kinematics for observers to discriminate the weights of objects lifted by an actor (Runeson & Frykholm, 1981), even when the actor feigns the weight of the object that is being lifting (Runeson & Frykholm, 1983). Specifically, the actor’s hip angle, the period of time between the actor establishing a purchase and lifting the object, and lifting velocity contribute to the observer’s ability to detect the true weight of a lifted object (Bingham, 1987; Hamilton & Grafton, 2007; Shim & Carlton, 1997). However, the extrinsic visual characteristics of a lifted object also represent sources of information that can influence the perception of the lifting movement (see R. S. Johansson & Cole, 1994, for a review). Object size, for example, is a powerful determinant of perceived object weight (Flanagan, Bowman, & Johansson, 2006; Flanagan & Wing, 1997; Gordon, Westling, Cole, & Johansson, 1993).
Recently, researchers have started to conduct studies to disentangle the relative contributions of movement kinematics and object characteristics to the accurate perception of intrinsic object characteristics, and in turn, of the forces required to act upon those objects. Prominent in this regard are transcranial magnetic stimulation (TMS) experiments that have highlighted that the somatotopic patterns of primary motor cortex facilitation that occur during the observation of action (Fadiga, Craighero, & Olivier, 2005; Strafella & Paus, 2000) are highly congruent—with a resolution that reflects the level of individual muscles (Alaerts, Swinnen, & Wenderoth, 2009) and the degree of muscular force (Alaerts, Senot, et al., 2010)—to the patterns associated with performing the observed action. Interestingly, through systematic manipulation of participants’ exposure to visual information about movement kinematics and intrinsic object characteristics, Alaerts and colleagues (Alaerts, Swinnen, & Wenderoth, 2010) were able to apply the TMS approach to highlight primary motor cortex patterns that suggest that observers’ perceptions of lifted weight rely more on visual information concerning the lift kinematics than on object characteristics (see also Senot et al., 2011; Shim, Hecht, Lee, Yook, & Kim, 2009).
In the present experiment, we used the PLD method to create stimuli that would further contribute to the line of inquiry concerning the relative impacts of a lifted object’s extrinsic size characteristics and the actor’s movement kinematics to the perception of the observed lifted weight. To do so, participants viewed an actor lifting boxes that varied in both size (small, medium, or large) and weight (25, 50, or 75 lb) across PLD and full-vision video conditions and provided their estimations of the weight of the lifted boxes. Our PLD generation system allowed us to remove point-light markers from the displays systematically, so that we were able to present only the markers associated with the actor and remove those associated with the lifted object, and vice versa. This manipulation allowed us to test the following hypotheses:
-
1.
Participants will be able to differentiate the lifted weights when the movements are presented in degraded arrays that include only the point-light markers associated with the actor (i.e., without interference from the box) (e.g., Runeson & Frykholm, 1983).
-
2.
The addition of kinematic information associated with the lift will improve the differentiation of weight estimates. Specifically, we anticipate better weight differentiation when the observers are presented with the point-light markers associated with the box in motion rather than at rest, and that the differentiation will improve further when the observers are presented with the point-light markers associated with both the box and the actor in motion.
-
3.
Participants will provide estimates of observed weight that reflect the object size when the degraded array presents only the point-light markers associated with the box at rest (i.e., without interference from movement kinematics) (Gordon et al., 1993).
-
4.
The introduction of this incongruent box information (for, e.g., a small box that is heavy or a large box that is light) will negatively impact the differentiation and accuracy of weight estimates. Thus, we expect the participants’ differentiations of weights to be better in response to the PLD condition that presents only the actor point-lights than to the condition that presents both the box and actor point-lights.
An interesting corollary outcome of our stimulus development is that the actor participates in a size–weight illusion protocol (Charpentier, 1891; Murray, Ellis, Bandomir, & Ross, 1999) that provides a unique opportunity to investigate how other nonkinematic and nonobject visual information impacts the accuracy of the observer estimates. The size–weight illusion refers to the phenomenon wherein an actor, when lifting objects of differing volumes and identical weight, perceives the smaller objects as being heavier. The illusion persists even when the actor is aware that the weights are identical, and does not lessen over the course of repeated lifting—even though the motor outputs associated with the lift cease to reflect the actor’s perception of differing weights (Ellis & Lederman, 1993; Flournoy, 1894; Nyssen & Bourdon, 1956). Under these lifting conditions, it is possible that comparisons of the weights estimated under the full-PLD conditions and the full-vision video condition will provide evidence of other information that discloses the actor’s differing perceptions of weight across box sizes of the same weight. That is, for example, the observer may estimate a weight to be heavier because of facial cues associated with the actor’s perception of the weight. This possibility is particularly noteworthy with respect to recent evidence that observer perceptions of lifting movements are more sensitive to information concerning actor effort than to lifted weight (Shim, Carlton, & Kim, 2004). If affective information related to the actor’s perception of the lifted weight impacts the observer perception of the lifted weight, then the observer should be less able to differentiate weights under the full-vision video condition.
Method
Stimulus generation
A naïve actor with considerable weight-lifting experience lifted a series of three boxes that were equal in width (39 cm) and height (18 cm) but that differed in depth (small = 18 cm, medium = 23 cm, large = 25 cm). All three boxes were mounted with a horizontal grasping bar and designed so that their weight could be manipulated through the addition or subtraction of weights. In the lightest condition, the boxes were manipulated such that they each weighed 25 lb. In the middle-weight condition, the boxes were manipulated to weigh 50 lb. In the heavy weight condition, the boxes were manipulated to weigh 75 lb. The actor performed three lifts of each size–weight box combination.
Prior to initiating the lifts, 29 reflective markers were affixed to the actor’s head, shoulders, elbows, wrists, hips, knees, and feet. The third of each of the actor’s lifts was recorded via a VICON motion capture system (VICON Motion Capture Nexus software; VICON Motion Systems, Lake Forest, CA), which captured the displacement of the reflective markers, and an HD camera (HV30 Camcorder, Canon, Japan), which captured video of the lifts in profile. For each lift, the actor bent at the knees, grasped the handle of the box, stood up straight to lift the box to hip level, and lowered it back to its original position (i.e., a deadlift). The actor performed each lift with his feet, hands, and gaze arranged according to markers affixed to the floor, grasping bar, and facing wall, respectively. He was also required to perform his movements in time with a metronome (45 beats/min), which was employed as a soft control against the actor adopting a variety of paces throughout the series of lifts. A chair was placed behind the actor in order to standardize the lift position for each box. The actor was asked to bend, grasp, and lift the box on consecutive beats of the metronome, but was not constrained by this rhythm, nor was he required to finish the lift on the fourth beat.
Although the metronome encouraged the actor to assume similar positions, purchases, postures, and general movement timings from one lift to the next, for the purposes of our manipulation, it was important that we establish kinematic differences between box lifts of different weight. Accordingly, we extracted and compared kinematic variables from the resultant PLDs that have been identified as influencing observers’ perceptions of lifted weight: dwell time, maximum hip angle, and lift velocity (see Shim & Carlton, 1997, for a review). Dwell time represents the period of time between the actor purchasing the box handle and the moment that the box is lifted off the ground. Using a custom code created in MATLAB, a mean dwell time for each box weight was computed in milliseconds. A one-way analysis of variance (ANOVA) did not reveal differences between the dwell times associated with different box weights, F(2, 8) = 1.089, p = .395. However, a review of the means revealed a systematic increase in the dwell period as the box weights increased (25 lb = 27.3 ms, 50 lb = 39.7 ms, 75 lb = 64.0 ms). Hip angle was defined as the angle between the leg and trunk segments and was calculated using the VICON coordinate data. Analysis of the hip angle at the peak box position revealed no differences between box weights, F(2, 8) = 2.553, p = .158, (25 lb = 129.2°, 50 lb = 129.7°, 75 lb = 127°). Lift velocity was determined via the angular velocity (deg/s) about the hip angle. An analysis of these data confirmed that as the box weight increased, the lift velocity decreased (25 lb = 0.72°/s, 50 lb = 0.62°/s, 75 lb = 0.42°/s), F(2, 8) = 7.34, p = .024.
Upon completing three lifts of a particular size–weight box, the actor was presented with another box size of the same weight. Once all three sizes had been lifted three times at a given weight, the actor was asked to declare his perception of the relative weights of the three box sizes. For each weight, the actor indicated that the small box was the heaviest and the large box was the lightest. The order of box size presentation was randomized within weights; however, the weights were presented in descending order, to minimize the impact of fatigue. The actor was not provided with any information regarding the weights of the boxes, nor was he permitted to see any weights being added or taken away from the boxes.
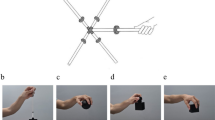
All grids and background reference frames were removed from the VICON recordings to create the PLD stimuli. The static-box and dynamic-box conditions reduced the display to only the four reflective markers that had been affixed to the corners of each box. In the static-box condition, the markers were presented at rest, and in the dynamic-box condition, the markers were presented in motion. In the actor condition, the display was degraded to only the point-light markers associated with the actor’s body. The actor-and-box condition presented all VICON markers against the black background. Finally, the full-video condition was created from the full-vision video captured by the HD camera. Each viewing condition was created from the same lift video for each specific size and weight condition, and all PLDs and videos were presented from the same profile perspective. Each viewing condition is presented in Fig. 1.

The viewing conditions for the (A) full-video, (B) actor-and-box, (C) actor, and (D) dynamic-box and static-box conditions
Participants
The participants were 13 individuals with normal or corrected-to-normal vision, recruited from the McMaster University community (eight males, five females; mean age = 23.1 years). All individuals provided informed consent according to the guidelines set out by the Declaration Helsinki (1954) and by the McMaster University Research Ethics Board prior to participating.
Procedure
Participants viewed the third of each of the actor’s lifts of each box in five viewing blocks (static-box, dynamic-box, actor, actor-and-box, and full-video) and provided weight estimates of the box lifted in each trial presentation. All participants viewed the static-box condition first and the full-video condition last. The dynamic-box, actor, and actor-and-box conditions were presented in a random order. All lifts were presented on a 15-in. AOC LM 760 liquid crystal display computer monitor with a 1,280 × 1,024 pixel resolution setting.
Each block consisted of 27 pseudorandomized trials. A trial consisted of a 3-s preparation period, followed by the presentation of the actual lift. Participants verbally indicated an estimation of the box weight in pounds to the experimenter. Prior to the first lift presentation in each block, and following every third lift presentation, the participant was presented an anchor presentation of the middle-weighted, medium-sized box. This anchor presentation included a caption indicating that the weight of the presented box was 50 lb. This manipulation was designed to assist the participants in calibrating their weight judgments. Each size–weight combination was presented three times in each block and did not appear in more than two consecutive trials. The trial order was balanced such that all nine size–weight combinations followed an anchor presentation at least once.
Dependent measures
Although it has been shown that the weight of lifted objects can be estimated accurately through PLD observation (Runeson & Frykholm, 1981, 1983), in this experiment we were more interested in the participants’ ability to differentiate objects of various weights. Accordingly, the absolute weight estimate for each trial was used as the primary dependent measure for all analyses, rather than an error value that represented the actual accuracy of the estimates.
Analysis
We conducted the following hypothesis-specific analyses:
-
1.
Our first hypothesis was that participants would differentiate the lifted weights accurately when presented with arrays that included only the actor kinematic information. To test this, the weight estimates for the actor condition were compared in a 3 (weight: 25, 50, 75 lb) × 3 (size: small, middle, large) ANOVA.
-
2.
Second, in order to test the hypothesis that the addition of kinematic information associated with the lift would improve the differentiation of weight estimates, we compared weight estimates in a 3 (viewing condition: static-box, dynamic-box, actor-and-box) × 3 (weight: 25, 50, 75 lb) × 3 (size: small, middle, large) ANOVA.
-
3.
We tested the hypothesis that weight estimates would reflect object size when the presented array contained only box size information through a 3 (weight: 25, 50, 75 lb) × 3 (size: small, middle, or large) ANOVA of the weight estimates provided in the static-box condition.
-
4.
Our fourth hypothesis was that this incongruent box information would negatively impact the differentiation of weights estimated on the bases of actor kinematic information. Accordingly, we analyzed the weight estimates in a 2 (viewing condition: actor, actor-and-box) × 3 weight (25, 50, 75 lb) × 3 size (small, middle, large) ANOVA.
We also performed a pair of analyses in order to investigate how additional, nonkinematic and nonbox, information would impact the weight estimates:
-
5.
Weight estimates were compared in a 2 (viewing condition: actor-and-box, full-video) × 3 (weight: 25, 50, 75 lb) × 3 (size: small, middle, large) ANOVA.
-
6.
Furthermore, we employed Pearson’s correlation methodology to determine the relationship between the absolute weight estimate and the true object weight for each viewing condition. The resultant r 2 values reflected the amount of variation in weight perception that was accounted for by the visual information available each condition. These r 2 values were then subjected to a five-viewing-condition (static-box, dynamic-box, actor, actor-and-box, full-video) one-way ANOVA.
Tukey’s HSD post hoc methodology was used to decompose all significant effects (p < .05) involving more than two means.
Results
The results of the first analysis did not yield any significant weight estimation differences in the actor condition (grand mean = 53 ± 11.3 lb). Interestingly, this suggests that the participants were unable to differentiate the weights of lifted objects solely on the bases of kinematic lift information.
The second analysis revealed a significant Viewing Condition × Weight interaction, F(4, 48) = 3.24, p < .019. Post hoc analysis of this interaction revealed that participants differentiated the 25- and 75-lb boxes in the actor-and-box condition, but not in the dynamic-box or static-box conditions (Fig. 2), indicating that lift velocity information independently was not sufficient kinematic information for the generation of appropriate estimates. This analysis also yielded significant Size × Weight, F(4, 48) = 5.91, p < .001, and Size × Viewing Condition, F(4, 48) = 34.07, p < .001, interactions.

Participant mean (± SE) weight estimates (in pounds), plotted as a function of box weight and PLD viewing conditions of increasing kinematic content
The third analysis revealed a significant main effect of box size, F(2, 16) = 148.8, p < .001, in which participants estimated the large box to be heavier than the middle box, which in turn was estimated to be heavier than the small box (Fig. 3). This finding supports the hypothesis that weight estimates reflect box size when the visual presentation does not include any kinematic information.

Participant mean (± SE) weight estimates (in pounds), plotted as a function of box size in the static box-viewing condition
The comparison of actor-condition estimates with actor-and-box estimates did not yield a significant Viewing Condition × Weight interaction (p = .10), suggesting that box size information does not confound the perception of lifted weight. However, the analysis did yield a significant weight main effect, F(2, 24) = 5.83, p < .01, post hoc analysis of which revealed that the heavy box (55.2 ± 3.3 lb) was estimated to be significantly heavier than the light box (48.7 ± 2.9 lb), regardless of the presence of box size information. This finding is particularly relevant, insofar as it offers support for Hypothesis 1, that appropriate perceptions of weight may be gleaned from kinematic lift information.
The comparison of the full-vision video estimates with the actor-and-box PLD estimates revealed significant Viewing Condition × Size, F(2, 24) = 6.27, p < .01, and Size × Weight, F(4, 48) = 11.03, p < .001, interactions. Post hoc decomposition of the Viewing Condition × Size interaction revealed that in the video condition, participants estimated the weight of the small box (45.1 ± 3.0 lb) to be less than the weight of the medium (55.8 ± 4.9 lb) and large (57.4 ± 4.3 lb) boxes, but that no differences emerged between these estimates and any of those associated with the actor-and-box viewing condition (small, 53.0 ± 2.9 lb; middle, 48.7 ± 3.5 lb; large, 53.8 ± 3.7 lb). Post hoc analysis of the Size × Weight interaction revealed no differences between the participants’ weight estimates associated with box sizes in the 25-lb condition (small, 42.2 ± 3.0 lb; middle, 42.3 ± 2.5 lb; large, 45.6 ± 3.1 lb). However, in the 50-lb condition, participants estimated the large box (59.9 ± 2.8 lb) to be heavier than the small (46.7 ± 2.9 lb) and middle-sized (48.9 ± 1.9 lb) boxes, and in the 75-lb condition, participants estimated the middle-sized box (65.4 ± 5.2 lb) to be heavier than the small box (58.3 ± 2.9 lb), with the large-box (61.3 ± 4.6) estimates being intermediate, but not significantly different from either.
Of greatest interest for this analysis, however, was a significant Viewing Condition × Weight interaction, F(2, 24) = 9.35, p < .001. Post hoc decomposition of this analysis indicated that in the video condition, participants were able to differentiate each of the three weights; however, when presented with the PLD information, the participants could only differentiate the heaviest box from the lightest (Fig. 4).

Participant mean (± SE) weight estimates (in pounds), plotted as a function box weight under the full-video and actor-and-box conditions
The analysis of the r 2 values obtained from the Pearson correlations between the absolute weight estimates and the true object weights revealed a significant main effect of viewing condition, F(4, 48) = 20.53, p < .001. The post hoc decomposition of this effect revealed that the visual information associated with the full-video condition accounted for the greatest amount of accuracy in weight estimations, and that no other intermediate differences emerged (Fig. 5).

A plot of the correlations (r 2) between the observers’ mean weight estimates and the object’s actual weight across viewing conditions
Discussion
In this study, the visual information that was available to observers in PLD presentations of an actor lifting boxes of various sizes and weights was manipulated. This was done in order to determine the relative degrees to which kinematic movement information and extrinsic box size information contribute and covary in order to influence observers’ perceptual estimates of lifted box weights. In this regard, a review of our results indicated that kinematic information is a powerful determinant in the generation of movement perceptions that can differentiate the weights of manipulated objects. This finding is in agreement with the results generated by the Alaerts group (Alaerts, Senot, et al., 2010; see also Buckingham, Wong, Tang, Gribble, & Goodale, 2013; Reichelt, Ash, Baugh, Johansson, & Flanagan, 2013). However, in the present work, neither kinematic information about the velocity of the lifted box nor the angular displacements and velocities of the actor’s joints were independently sufficient for observers to make appropriate estimates. It would appear that such perceptions depend on an integration of both the actor’s and object’s kinematics. This finding is particularly interesting when one considers the incongruent way in which box size information serves to influence observed weight perceptions in the absence of kinematic information (i.e., the static-box condition). Overall, it appears that visually available kinematics can work to offset perceptions of object weight based on size information, but that this mechanism requires a minimum amount of kinematic information. The present study suggests that this minimum is in excess of information concerning the object in motion.
The design of this study also permitted the opportunity to investigate the influence that additional nonkinematic and nonobject information has on observer perceptions of lifted weight. In this regard, Shim et al. (2004) demonstrated that extraneous visual information concerning the effort that an actor exerts influences his or her observers’ weight perceptions. Because our stimulus generation protocol required our actor to lift boxes under conditions of the size–weight illusion (Charpentier, 1891; Murray et al., 1999), we were able to test the hypothesis that observers’ perceptions of actor effort impact weight estimations in a manner that offsets the influences associated with actor kinematic or box-size information. Specifically, in each weight category, the actor perceived the smaller box as being the heaviest, and the larger box as being the lightest, and assuming that the actor’s effort reflected his perceptions, we reasoned that the full-vision video would be associated with confounded weight estimates. However, this was clearly not the case. Rather, the additional visual information associated with the video presentation actually led to observer estimates that were better differentiated than those under the PLD conditions. Thus, visual information beyond kinematics and object characteristics contributes to accurate dynamic perceptions. The nature of this information, however, remains uncertain. With regard to how much this information relates to visual aspects of an actor’s effort, we must remain aware of the way that force outputs are mediated in size–weight illusion contexts. An actor’s expectations about an object’s weight can be observed in the initial load phase of the lift. If the predictions about the weight of the box are mistaken, then the lift’s dwell time will be inappropriate, and lift-off will occur either sooner or later than expected, if at all. In either case, this inappropriate force output leads to reflex mediated changes in force loading (Gordon et al., 1991; R. S. Johansson & Westling, 1988; Westling & Johansson, 1984), and over the course of a few lifts, the forces scale to the actual weight of the lifted box, although the illusion still persists (Flanagan & Beltzner, 2000). Thus, we must interpret our data as evidence that any visual information regarding the actor’s true effort is more salient to the observer than are visual cues regarding the actor’s perception of effort.
References
Alaerts, K., Senot, P., Swinnen, S. P., Craighero, L., Wenderoth, N., & Fadiga, L. (2010a). Force requirements of observed object lifting are encoded by the observer’s motor system: A TMS study. European Journal of Neuroscience, 31, 1144–1153.
Alaerts, K., Swinnen, S. P., & Wenderoth, N. (2009). Is the human primary motor cortex activated by muscular or direction-dependent features of observed movements? Cortex, 45, 1148–1155.
Alaerts, K., Swinnen, S. P., & Wenderoth, N. (2010b). Observing how others lift light or heavy objects: Which visual cues mediate the encoding of muscular force in the primary motor cortex? Neuropsychologia, 48, 2082–2090.
Bingham, G. P. (1987). Kinematic form and scaling: Further investigations on the visual perception of lifted weight. Journal of Experimental Psychology. Human Perception and Performance, 13, 155.
Buckingham, G., Wong, J. D., Tang, M., Gribble, P. L., & Goodale, M. A. (2013). Observing object lifting errors modulates cortico-spinal excitability and improves object lifting performance. Cortex. doi:10.1016/j.cortex.2013.07.004
Charpentier, A. (1891). Analyse expérimentale de quelques éléments de la sensation de poids [Experimental study of some aspects of weight perception]. Archives de Physiologie Normales et Pathologiques, 13, 122–135.
Cutting, J. E., & Kozlowski, L. T. (1977). Recognizing friends by their walk: Gait perception without familiarity cues. Bulletin of the Psychonomic Society, 9, 353–356.
Dekeyser, M., Verfaillie, K., & Vanrie, J. (2002). Creating stimuli for the study of biological-motion perception. Behavior Research Methods, Instruments, & Computers, 34, 375–382. doi:10.3758/BF03195465
Dittrich, W. H., Troscianko, T., Lea, S. E., & Morgan, D. (1996). Perception of emotion from dynamic point-light displays represented in dance. Perception, 25, 727–738.
Ellis, R. R., & Lederman, S. J. (1993). The role of haptic versus visual volume cues in the size-weight illusion. Perception & Psychophysics, 53, 315–324.
Fadiga, L., Craighero, L., & Olivier, E. (2005). Human motor cortex excitability during the perception of others’ action. Current Opinion in Neurobiology, 15, 213–218.
Flanagan, J. R., & Beltzner, M. A. (2000). Independence of perceptual and sensorimotor predictions in the size-weight illusion. Nature Neuroscience, 3, 737–741.
Flanagan, J. R., Bowman, M. C., & Johansson, R. S. (2006). Control strategies in object manipulation tasks. Current Opinion in Neurobiology, 16, 650–659.
Flanagan, J. R., & Wing, A. M. (1997). The role of internal models in motion planning and control: Evidence from grip force adjustments during movements of hand-held loads. Journal of Neuroscience, 17, 1519–1528.
Flournoy, T. (1894). De l’influence de la perception visualle des corps sur leur poids apparent [The influence of visual perception on the apparent weight of objects]. L'Année Psychologique, 1, 198–208.
Gilden, D. L., & Proffitt, D. R. (1989). Understanding collision dynamics. Journal of Experimental Psychology. Human Perception and Performance, 15, 372–383. doi:10.1037/0096-1523.15.2.372
Gordon, A. M., Forssberg, H., Johansson, R. S., & Westling, G. (1991). Visual size cues in the programming of manipulative forces during precision grip. Experimental Brain Research, 83, 477–482.
Gordon, A. M., Westling, G., Cole, K. J., & Johansson, R. S. (1993). Memory representations underlying motor commands used during manipulation of common and novel objects. Journal of Neurophysiology, 69, 1789–1796.
Hamilton, A. F. de C., & Grafton, S. T. (2007). The motor hierarchy: From kinematics to goals and intentions. In P. Haggard, Y. Rossetti, & M. Kawato (Eds.), Sensorimotor foundations of higher cognition: Attention and performance XXII (pp. 381–408). Oxford, UK: Oxford University Press.
Hodges, N. J., Williams, A. M., Hayes, S. J., & Breslin, G. (2007). What is modelled during observational learning? Journal of Sports Sciences, 25, 531–545.
Johansson, G. (1964). Perception of motion and changing form: A study of visual perception from continuous transformations of a solid angle of light at the eye. Scandinavian Journal of Psychology, 5, 181–208.
Johansson, G. (1973). Visual perception of biological motion and a model for its analysis. Perception & Psychophysics, 14, 201–211. doi:10.3758/BF03212378
Johansson, R. S., & Cole, K. J. (1994). Grasp stability during manipulative actions. Canadian Journal of Physiology and Pharmacology, 72, 511–524.
Johansson, G., & Jansson, G. (1968). Perceived rotary motion from changes in a straight line. Perception & Psychophysics, 4, 165–170.
Johansson, R. S., & Westling, G. (1988). Coordinated isometric muscle commands adequately and erroneously programmed for the weight during lifting task with precision grip. Experimental Brain Research, 71, 59–71.
Kozlowski, L. T., & Cutting, J. E. (1977). Recognizing the sex of a walker from a dynamic point-light display. Perception & Psychophysics, 21, 575–580. doi:10.3758/BF03198740
Mather, G., & Murdoch, L. (1994). Gender discrimination in biological motion displays based on dynamic cues. Proceedings of the Royal Society B, 258, 273–279.
Murray, D. J., Ellis, R. R., Bandomir, C. A., & Ross, H. E. (1999). Charpentier (1891) on the size–weight illusion. Perception & Psychophysics, 61, 1681–1685.
Nyssen, R., & Bourdon, J. (1956). A new contribution to the experimental study of the size–weight illusion. Acta Psychologica, 12, 157–173. doi:10.1016/0001-6918(56)90016-6
Reichelt, A. F., Ash, A. M., Baugh, L. A., Johansson, R. S., & Flanagan, J. R. (2013). Adaptation of lift forces in object manipulation through action observation. Experimental Brain Research, 1–14. doi:10.1007/s00221-013-3554-9
Runeson, S., & Frykholm, G. (1981). Visual perception of lifted weight. Journal of Experimental Psychology. Human Perception and Performance, 7, 733–740. doi:10.1037/0096-1523.7.4.733
Runeson, S., & Frykholm, G. (1983). Kinematic specification of dynamics as an informational basis for person-and-action perception: Expectation, gender recognition, and deceptive intention. Journal of Experimental Psychology. General, 112, 585–615. doi:10.1037/0096-3445.112.4.585
Senot, P., D’Ausilio, A., Franca, M., Caselli, L., Craighero, L., & Fadiga, L. (2011). Effect of weight-related labels on corticospinal excitability during observation of grasping: A TMS study. Experimental Brain Research, 211, 161–167.
Sevdalis, V., & Keller, P. E. (2012). Perceiving bodies in motion: Expression intensity, empathy, and experience. Experimental Brain Research, 222, 447–453. doi:10.1007/s00221-012-3229-y
Shim, J., & Carlton, L. G. (1997). Perception of kinematic characteristics in the motion of lifted weight. Journal of Motor Behavior, 29, 131–146.
Shim, J., Carlton, L. G., & Kim, J. (2004). Estimation of lifted weight and produced effort through perception of point-light display. Perception, 33, 277–292.
Shim, J., Hecht, H., Lee, J. E., Yook, D. W., & Kim, J. T. (2009). The limits of visual mass perception. Quarterly Journal of Experimental Psychology, 62, 2210–2221.
Stevenage, S. V., Nixon, M. S., & Vince, K. (2000). Visual analysis of gait as a cue to identity. Applied Cognitive Psychology, 13, 513–526.
Strafella, A. P., & Paus, T. (2000). Modulation of cortical excitability during action observation: A transcranial magnetic stimulation study. NeuroReport, 11, 2289–2292.
Thomas, S. M., & Jordan, T. R. (2001). Techniques for the production of point-light and fully illuminated video displays from identical recordings. Behavior Research Methods, Instruments, & Computers, 33, 59–64. doi:10.3758/BF03195347
Westling, G., & Johansson, R. S. (1984). Factors influencing the force control during precision grip. Experimental Brain Research, 53, 277–284.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Rights and permissions
About this article
Cite this article
Grierson, L.E.M., Ohson, S. & Lyons, J. The relative influences of movement kinematics and extrinsic object characteristics on the perception of lifted weight. Atten Percept Psychophys 75, 1906–1913 (2013). https://doi.org/10.3758/s13414-013-0539-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0539-5