
Abstract
Distractor-based retrieval of event files was assessed with a sequential priming experiment using a four-choice identification task. Pictures or sounds of four different animals (frog, chicken, lamb, singing bird) had to be categorized by pressing one of four keys. On each trial, a target and a distractor stimulus were presented simultaneously in different modalities. The relevant modality switched randomly between trials. Distractor repetition effects were modulated by the response relation between the prime and probe: Repeating the prime distractor in the probe produced facilitation if the response repeated, but not if a different response had to be given in the prime and probe. Repeating the prime distractor in the probe led to an automatic retrieval of the prime response. Importantly, this distractor-based response retrieval effect also emerged for those sequences in which the modality of the repeated distractor was switched between the prime and probe. This cross-modal priming effect indicates that distractors were integrated into event files on a conceptual level and that response retrieval processes were mediated by conceptual codes of the distractor stimuli.
Similar content being viewed by others

For the efficient control of behavior, it is assumed that stimulus features and response features are integrated into stimulus–response (S–R) episodes, or event files (Hommel, 1998). Object files and event files are memory entries that are automatically retrieved when people encounter stimuli that match any feature of previous episodes. This episodic retrieval process is a core feature of automatization in perception and action (Logan, 1988; Treisman, 1992). Retrieving a previous episode can facilitate perception and action in the case of a complete match between the previous and current episodes, but it can also impair the perception of novel stimuli and interfere with responding if the previous episode contains a mismatch with some of the features or response requirements of the current situation (Denkinger & Koutstaal, 2009; Hommel, 1998, 2004; Treisman, 1992). Furthermore, the binding of stimuli and responses is not restricted to stimulus features that are relevant for the selection of an action. Recent studies have found that even irrelevant or distracting elements of a situation can become associated with a response given to another object, a phenomenon that has been labeled distractor–response binding (e.g., Frings, 2010; Frings, Rothermund, & Wentura, 2007; Hommel, 2005; Mayr & Buchner, 2006; Mayr, Buchner, & Dentale, 2009; Rothermund, Wentura, & De Houwer, 2005). Distractor–response binding is typically tested with a paradigm where a prime target is presented before a probe target, each one being presented simultaneously with a distractor. In a condition, the distractor for the prime is identical with the one for the probe; that is, the same distractor is presented repeatedly within one trial. Repeating the same distractor can facilitate the retrieval of the response to the prime when participants respond to the probe, thus modulating the effect of the prime presentation on the response to the probe.
Previous studies concerned with the retrieval of S–R episodes typically repeated perceptual features (or the physical stimuli themselves) from one display to another to analyze whether repeated elements from a previous episode would retrieve the particular memory entry including the previous response. The same holds true for studies showing the binding of responses to targets and distractor stimuli. As a result, the binding of features and responses could be completely explained due to direct links between perception and action (Hommel, Müsseler, Aschersleben, & Prinz, 2001).
In the present study, however, we analyzed whether conceptual representations of irrelevant stimulus elements are automatically created and become integrated into S–R episodes. In this case, repeating the distractor at a merely conceptual level should lead to a retrieval of the previous event file. Specifically, we wanted to test whether distractor–response bindings occur even if only the conceptual distractor features are repeated from the prime to the probe, whereas the perceptual distractor features change. Finding distractor–response binding effects under such circumstances would imply that episodic retrieval can operate on the level of conceptual distractor representations.
As far as looking at the literature on object files (cf. Kahneman & Treisman, 1984; Kahneman, Treisman, & Gibbs, 1992), it seemed plausible enough that such a conceptual or semantic binding exists. In particular, Gordon and Irwin (1996, 2000; see also Henderson, 1994) showed that repetition of a concept from prime to probe (e.g., the word FISH is presented in the prime, whereas the picture of a fish is shown in the probe) lead to object-specific facilitation effects; in turn, it was argued that the representations of stimuli in object files consist not only of perceptual features, but also of identity or conceptual features. In the same vein, research on cross-modal congruency showed that hearing the irrelevant sound of a dog will facilitate identifying the picture of a dog (Chen & Spence, 2010; see also Chen & Spence, 2011; Laurienti, Kraft, Maldjian, Burdette, & Wallace, 2004). This finding suggests that irrelevant stimuli presented in a different modality than the target are processed up to a conceptual level and can then facilitate responding to the target. Finally, in the literature on the negative priming effect (see Fox, 1995, for a review), it has been established that ignoring a distractor leads to cost effects if this stimulus is presented as the target on the next trial, even if it is presented in a different visual form (word vs. picture; Tipper & Driver, 1988) or in a different modality (audition vs. vision; Buchner, Zabal, & Mayr, 2003).
Taken together, these findings suggest that even distractor stimuli are represented on a conceptual level. The core question of our study is whether the conceptual features of distracters also become integrated into S–R episodes and are thus bound to the representation of the response that is given to the target. In this case, repetition of the distractor identity—without repeating its physical features—should lead to the retrieval of the response that was previously encoded together with the distractor. Demonstrating an integration of conceptual stimulus representations into event files would extend the range of current accounts of binding that typically refer to a binding of purely perceptual features (Hommel et al., 2001).
In order to investigate conceptual distractor–response bindings, we randomly switched the modality (sounds vs. pictures) of target and distractor stimuli on a trial-by-trial basis in a sequential priming paradigm. In such a paradigm, distractor–response binding effects are reflected in an interaction of distractor repetition effects with response relation (Frings et al., 2007; Rothermund et al., 2005). Repeating the distractor from the prime to the probe should facilitate responding in the case of a response repetition between the prime and probe, because the retrieved prime response is compatible to the to-be-executed probe response. In the case of a response change between a prime and a probe display, a distractor repetition should impede responding to the probe target (as compared with a response repetition trial) because the retrieved prime response is then incompatible with the to-be-executed probe response. Due to the possible influence of distractor inhibition (e.g., Frings, Wentura, & Wühr, 2012; Houghton & Tipper, 1994), an interpretation of main effects of distractor repetitions within the response repetition and response change conditions is hardly possible, since these effects are confounded with an inhibition-based main effect of distractor repetitions (Giesen, Frings, & Rothermund, 2012). Instead, the decisive effect that indicates processes of distractor–response binding and retrieval is the interaction of distractor relation and response relation that is orthogonal to the main effect of distractor repetitions.
Of crucial interest for the present study is the question of whether distractor binding effects survive a modality switch. In particular, retrieval of distractor–response episodes may be restricted to those cases in which a distractor is repeated in the probe that is physically identical to the prime distractor, evoking identical perceptual representations; yet, if binding effects are conceptually mediated, episodic retrieval of prime responses should also occur if the distractor is presented in a different modality on the prime and probe trials.
Experiment 1
Method
Participants
Thirty-nine students (29 women) from Saarland University participated in the experiment; they were paid 6 € for participation. The median age was 22 years, with a range of 18–37 years. The data of 3 participants were replaced; 2 of them had average reaction times (RTs) that were outliers when compared with the RT distribution of the sample (Tukey, 1977). The data of one further participant were excluded due to his extreme probe error rate (> 14 %). None of the participants reported any hearing impairment. All had normal or corrected-to-normal vision.
Design
Essentially, the design comprised three within-subjects factors—namely, response relation (repetition vs. change), distractor relation (repetition vs. change), and distractor modality (repetition vs. switch).
Materials
The experiment was conducted using the E-Prime software (E-Prime 1.1). Instructions, fixation marker, and visual stimuli were shown in white on a black background on a standard CRT screen. The auditory stimuli were four digitized animal sounds easily identifiable as lamb, frog, chicken, and singing bird. The sounds had a duration of 300 ms and were presented via headphones (Terratec Headset Master 5.1 USB). The software Audacity was used to adapt the sounds for presentation. The intensity of each sound was calibrated by a pilot observation by two persons; all sounds were presented at a comfortable level and perceived as being equal in loudness. The visual stimuli were four white line drawings on a black background of the same animals (lamb, frog, chicken, and singing bird). They were 4.5–7.4 cm wide and had a vertical extension of 5.3–7.0 cm. The viewing distance to the screen was about 60 cm.
Procedure
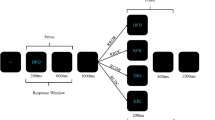
Participants were tested individually in soundproof chambers. Instructions were given on the screen and summarized by the experimenter. Participants were instructed to place the middle and index fingers of both hands on the D, F, J, and K keys of the computer keyboard. The D key corresponded to the sound and picture of the lamb, F corresponded to frog, J to chicken, and K to singing bird. In each prime and each probe presentation, one picture and one sound (one as the target and the other as the distractor) were simultaneously presented over the headphones and the screen. Before stimulus onset, a cue word (“picture” or “sound”) appeared in the center of the screen for 300 ms. This cue indicated in which modality the target would be presented in the following picture–sound pair. Participants had to ignore the distractor and had to identify the target by pressing the corresponding key. That is, participants had to attend to the picture and ignore the sound, or they were supposed to attend to the sound and ignore the picture. For example, if the word “picture” appeared followed by a picture of a bird simultaneously presented with the sound of a frog, participants were supposed to press the key K for singing bird and ignore the frog sound. Participants were instructed to react as quickly and correctly as possible. A single prime–probe sequence included the following events (cf. Fig. 1): After the participant pressed the space bar to start the sequence, the word “picture” or “sound” was displayed in the middle of the screen for 300 ms to inform whether the target would be presented in the visual or auditory modality. A plus sign then appeared for 200 ms in the middle of the screen as a fixation marker. Participants were instructed to look at the plus sign whenever it was presented. Then the prime stimuli, one picture and one sound, were presented. Participants reacted to the prime target by pressing the corresponding key. After the response to the prime, the fixation marker reappeared for 500 ms, before another cue (the word “picture” or “sound”) indicated in which modality the probe target would appear (300 ms). After a further 200 ms during which the fixation marker was shown, the probe stimuli were presented. After the response to the probe, an asterisk appeared in the middle of the screen, signaling that the next trial could be started.

Sequence of events in Experiment 1. The example depicts a prime–probe sequence with a visual prime target and an auditory probe target
On response repetition (RR) trials, the same animal was presented as the target in the prime and the probe. On response change (RC) trials, the target animal varied between prime and probe. Orthogonally to the response relation, the distractor relation was varied. On distractor repetition (DR) trials, the animal presented as the distractor was the same in the prime and the probe, whereas on distractor change (DC) trials, different animals were presented as distractors in the prime and the probe. In turn, four different conditions were conducted. On RR–DR trials, the same animal was presented as the prime and the probe target, whereas a second animal was presented both as the prime and the probe distractor. On RR–DC trials, the prime target was repeated as the probe target animal, while the distractor animal changed from prime to probe. On RC–DR trials, the probe target animal differed from the prime target animal, while the prime distractor animal was repeated as the probe distractor. Finally, on RC–DC trials, no animal was repeatedly presented in the prime and probe.
Modality repetition or switch between prime and probe was varied orthogonal to response and distractor repetition. Modality repetition/switch was varied randomly from trial to trial. Furthermore, distractors were presented as a picture on half of the trials and as a sound on the other half. The target was always presented in the other modality. All stimuli were presented equally often as visual or auditory targets.
An experimental session consisted of two practice blocks with 32 prime–probe sequences each and an experimental block with 192 prime–probe sequences. The four trial types (RR–DR, RR–DC, RC–DR, and RC–DC) were realized on 48 trials each. Each animal was presented equally often as the probe target. On each trial, the remaining three animals were randomly assigned to the roles of probe distractor, prime target, and prime distractor. A session lasted for about 50 min.
Results
Only trials with correct answers to the prime and the probe were considered. For each participant, four individual RT distributions were calculated, one for each condition of response and distractor repetition. RTs that were more than 1.5 interquartile ranges above the third quartile of the respective RT distribution (Tukey, 1977), and those below 200 ms were excluded from the analysis. Due to these constraints, 15.5 % of all trials were discarded (probe error rate was 5.5 %, prime error rate was 6.4 %). Mean RTs and error rates for probe displays are depicted in Table 1.
We first checked in a 2 (response relation: RR vs. RC) × 2 (distractor relation: DR vs. DC) × 2 (relation of distractor modality in prime and probe: repetition vs. switch) × 2 (distractor modality in the prime: vision vs. audition) ANOVA whether distractor modality modulated the binding effect or the influence of a modality switch on the binding effect. In particular, distractor modality in the prime did not modulate the binding effect, F(1, 35) = 0.08, p = .781, η p 2 = .002, nor did it modulate the influence of modality switches on binding, F(1, 35) = 0.07, p = .794, η p 2 = .002; that is, binding effects were the same for visual and auditory prime distractors, and the effect of modality switches on visual and auditory binding was also the same. We therefore collapsed data across visual and auditory distractor conditions.
Then a 2 (response relation: RR vs. RC) × 2 (distractor relation: DR vs. DC) × 2 (distractor modality in prime and probe: repetition vs. switch) ANOVA was conducted. All main effects reached significance: F(1, 35) = 111.23, p < .001, η p 2 = .76, for response relation; F(1, 35) = 34.40, p < .001, η p 2 = .50, for distractor relation; and F(1, 35) = 7.73, p = .009, η p 2 = .18 , for distractor modality. Repeating the prime response in the probe (740 ms) was faster than responding with a different key (839 ms), and reactions on probe trials with repeated distractors (778 ms) were faster than reactions on trials on which a different distractor was presented in the probe (801 ms). Reactions were also faster if the distractor (and target) modality was repeated from prime to probe (721 ms) than if distractors (and targets) were presented in different modalities in the prime and probe (867 ms). Importantly, the interaction of response relation and distractor relation was significant, F(1, 35) = 137.40, p < .001, η p 2 = .80, indicating that repeating the distractor facilitated responding in the probe in cases of response repetition sequences, F(1, 35) = 12.09, p = .001, η p 2 = .26, but not if a different response had to be given in the probe, F(1, 35) = 1.47, p = .233, η p 2 = .04. Moreover, the three-way interaction was not significant, F < 1, showing that repeating or switching the modality of the distractor from prime to probe did not influence the interaction of response relation and distractor relation.
To investigate whether distractor-based response retrieval effects survive a modality switch, a separate ANOVA was conducted within the distractor modality switch condition. In this analysis, the critical response relation × distractor relation interaction reached significance, F(1, 35) = 4.31, p = .045, η p 2 = .11 (cf. Fig. 2, left panel). A separate ANOVA for modality repetitions condition confirmed the standard distractor-based response retrieval effect within the modality repetition condition, F(1, 35) = 8.71, p = .006, η p 2 = .20.

Reaction times (RTs) and error rates (% Errors) as a function of response repetition and distractor repetition only for trials with a conceptual repetition of the distractor (i.e., modality switch from the prime to the probe), Experiment 1. Error bars depict the standard errors of the means
The same ANOVA on error rates revealed significant main effects for response relation, F(1, 35) = 9.33, p = .004, η p 2 = .21, and for distractor modality relation, F(1, 35) = 30.59, p < .001, η p 2 = .47, indicating fewer errors both for response repetition sequences and for sequences in which the modality of distractors (and targets) was repeated. The interaction of distractor modality relation and response relation was significant, F(1, 35) = 16.03, p < .001, η p 2 = .31, showing that participants made exceptionally few errors in response repetition conditions in which the prime and probe distractors (and targets) were presented in the same modality. In addition, the three-way interaction, F(1, 35) = 4.65, p = .038, η p 2 = .12, was significant. Yet, note that this interaction was of the ordinal type; that is, the response relation × distractor repetition interaction was significant if the distractor modality changed between prime and probe, F(1, 35) = 4.62, p = .039, η p 2 = .12, (cf. Fig. 2, right panel). Somewhat unexpectedly, the interaction was not significant within the distractor modality repetition condition, F(1, 35) < 1. This null effect is probably due to the very low level of errors in this condition.
Discussion
Experiment 1 demonstrated that distractor–response binding could be obtained even if the distractor modality switched from prime to probe. This result suggests that distractor-based retrieval of S–R episodes can be conceptually mediated. Before we discuss the implications of this finding, one possible confound of Experiment 1 must be considered. In particular, in Experiment 1, a distractor modality switch always implied a switch in target modality, whereas in the distractor modality repetition condition, the target modality was also repeated.
One might speculate that this is not problematic, for the following reasons. If anything, switching the target modality, as well as the distractor modality, in the modality switch condition should work against our hypothesis: According to theories of event-file retrieval (e.g., Hommel, 1998), a complete switch between two displays (as in the case of target and distractor both switching modalities) should hamper binding and retrieval effects. In addition, it should be noted that although distractor modality switches and target modality switches were indeed confounded in our experiment, this was not critical for our hypothesis, because we were specifically interested in testing distractor-based retrieval effects within the distractor modality switch condition, rather than in the comparison of the modality switch and nonswitch conditions. Nevertheless, we replicated the experiment with Experiment 2, in which the target modality always remained constant between the prime and probe, whereas the distractor modality switch was orthogonally varied to all other factors.
Experiment 2
Method
Participants
Fifty-eight students (46 women) from the University of Trier participated in the experiment; they received partial course credit for participation. The median age was 21 years, with a range of 18–28 years. None of the participants reported any hearing impairment. All had normal or corrected-to-normal vision.
Design
Essentially, the design comprised three within-subjects factors—namely, response relation (repetition vs. change), distractor relation (repetition vs. change), and distractor modality (repetition vs. switch).
Materials
The experiment was conducted using the E-Prime software (E-Prime 2.0). Instructions and fixation marker were shown in white on black background on a standard LCD screen. The cues were a red or green dot with a diameter of 2.5 cm or a click on the left or the right ear with a duration of 20 ms. The remaining stimuli were the same as in Experiment 1, with the exception that the visual stimuli were presented either in red or in green color and the sounds were presented to either the left or the right ear.
Procedure
The procedure was the same as in Experiment 1, with the following exceptions. In each prime and each probe presentation, two animals were presented simultaneously. Each animal could be presented in either the visual or the auditory modality. A visual or auditory cue was presented 500 ms before stimulus onset. This cue indicated in which color or at which ear the target would appear in the following prime or probe. At the same time, the cue modality also indicated the target modality. For example, if the cue was a red dot, on the following prime or probe participants had to identify the animal that was visually presented in red and ignore the distractor animal that could be presented either visually in green or auditorily to the left or the right ear. All visual stimuli were presented in the center of the screen and overlapped if both the target and distractor were presented visually. The target modality could change from one prime–probe sequence to the next but never changed between prime and probe. In contrast, the distractor modality could also switch between prime and probe displays. Participants were instructed to react as quickly and as correctly as possible. A single prime–probe sequence included the following events. After the participant started the sequence by pressing the space bar, the visual or auditory cue appeared in the middle of the screen for 300 ms or at one ear for 20 ms. The cue onset was followed by a 300-ms interval, and then a plus sign appeared in the middle of the screen for 200 ms as a fixation mark. Participants were instructed to look at the plus sign whenever it was presented. Next, the prime stimuli were presented until participants reacted to the prime target by pressing the corresponding key. After the response to the prime, the fixation marker reappeared for 500 ms, before another cue indicated the color in which or the ear to which the probe target would be presented. As on the prime, 300 ms after probe cue onset, the fixation mark appeared for 200 ms. Then the probe stimuli were presented until participants responded. After the response to the probe, an asterisk appeared in the middle of the screen, signaling that the next trial could be started.
The four conditions RR–DR, RR–DC, RC–DR, and RC–DC were constructed as in Experiment 1. Distractor modality repetition or switch between prime and probe was varied orthogonally to response and distractor repetition. Modality repetition/switch was varied randomly from trial to trial. Orthogonally, targets were presented visually (50 % red and 50 % green) on half of the trials and auditorily (50 % to the left and 50 % to the right ear) on the other half.
An experimental session consisted of two practice blocks with 32 prime–probe sequences each and an experimental block with 640 prime–probe sequences. Four breaks were scheduled within the experimental block. The four trial types (RR–DR, RR–DC, RC–DR, and RC–DC) were realized on 160 trials each. A session lasted for about 90 min.
Results
Only trials with correct answers to the prime and the probe were considered. RTs that were more than 1.5 interquartile ranges above the third quartile of the RT distribution of the participant (Tukey, 1977) and those below 200 ms were excluded from the analysis. Due to these constraints, 21.6 % of all trials were discarded (probe error rate was 4.9 %, prime error rate was 11.7 %). Mean RTs and error rates for probe displays are depicted in Table 2.
As in Experiment 1, we first tested with a 2 (response relation: RR vs. RC) × 2 (distractor relation: DR vs. DC) × 2 (relation of distractor modality in prime and probe: repetition vs. switch) × 2 (distractor modality in the prime: vision vs. audition) ANOVA whether distractor modality modulated the binding effect or the influence of a modality switch on the binding effect. In particular, distractor modality in the prime did not modulate the binding effect, F(1, 57) = 2.43, p = .125, η p 2 = .04, nor did it modulate the influence of modality switches on binding, F(1, 57) = 0.15, p = .703, η p 2 = .003; that is, binding effects were the same for visual and auditory prime distractors, and the effect of modality switches on visual and auditory binding was also the same. We therefore collapsed data across visual and auditory distractor conditions.
In a 2 (response relation: RR vs. RC) × 2 (distractor relation: DR vs. DC) × 2 (distractor modality in prime and probe: repetition vs. switch) ANOVA, the main effects of response relation and of distractor modality were significant: F(1, 57) = 420.50, p < .001, η p 2 = .88, for response relation, and F(1, 57) = 173.52, p < .001, η p 2 = .75, for distractor modality. Repeating the prime response in the probe (651 ms) was faster than responding with a different key (890 ms), and reactions were faster if the distractor modality was repeated from the prime to probe (738 ms) than if distractors were presented in different modalities in the prime and probe (782 ms). The interaction of response relation and distractor relation was significant, F(1, 57) = 14.25, p < .001, η p 2 = .20, indicating a general effect of distractor–response binding. Importantly, the three-way interaction was not significant, F < 1; that is, repeating or switching the modality of the distractor from prime to probe did not influence the interaction of response relation and distractor relation. In fact, separate analyses revealed significant effects for the critical response-relation × distractor-relation interaction both for repeated, F(1, 57) = 10.22, p = .002, η p 2 = .15, and for switched, F(1, 57) = 6.21, p = .016, η p 2 = .10, distractor modalities. For the sake of completeness, the distractor modality × response relation, F(1, 57) 33.23, p < .001, η p 2 = .37, and distractor modality × distractor relation, F(1, 57) = 11.07, p = .002, η p 2 = .16, interactions were also significant.
The same ANOVA on error rates revealed significant main effects for response relation, F(1, 57) = 207.67, p < .001, η p 2 = .79, and for distractor modality relation, F(1, 57) = 8.35, p = .005, η p 2 = .13, indicating fewer errors both for response repetition sequences and for sequences in which the modality of distractors was repeated. None of the other effects reached significance.
Discussion
Experiment 2 fully replicated the main result from Experiment 1: Distractor–response binding was significant even if the distractor switched modality from prime to probe. This remained true in Experiment 2, in which the target modality did not switch from prime to probe. In addition, as in Experiment 1, distractor–response binding effects were not significantly different between trials with or without a distractor modality switch; that is, distractor modality did not modulate the distractor–response binding effect.
General discussion
The most important finding concerns the level of representation on which binding took place in our experiments. In previous studies, binding of stimuli and response into S–R episodes referred to the integration of perceptual stimulus features with the response codes. In the present study, we observed that even if a repeated distractor switches modality (e.g., the picture of a chicken in the prime, then the sound of a chicken in the probe), it retrieves the previous S–R episode including the response to the target. This finding cannot be explained in terms of purely perceptual distractor representations: The distractor stimuli did not have any commonality in terms of physical stimulus features. The finding thus provides unambiguous evidence for a nonperceptual mediation of the distractor-based retrieval effect. Apparently, conceptual representations of the distractors were activated and were integrated with response codes into S–R episodes. Reactivating the conceptual code of the distractor with a stimulus that was presented in a different modality then led to a retrieval of the previous event file, suggesting a conceptual or semantic mediation of the retrieval effect.
This result deserves a closer look to decipher its meaning. First, we have to assume that even distractors are processed up to a conceptual representation level. As was outlined in the introduction, this assumption is plausible (Chen & Spence, 2010; Gordon & Irwin, 2000). Second, we have to assume that in addition to the perceptual features, the conceptual or semantic features of the distractor become integrated with the other features of the prime episode (including the response code). Third, we assume the same processes in the probe display; that is, again the distractor is processed up to a conceptual representation, and when a part of the conceptual representation of the prime display is repeated in the probe display, it will retrieve the last S–R episode into which it was integrated. Thereby, our results effectively extend distractor–response binding (and S–R binding mechanisms in general) to the integration of a semantic or conceptual representation level, whereas previous studies analyzing distractor–response binding yielded evidence only for binding and retrieval of direct links between perceptual and response features.
These findings of an activation and integration of conceptual stimulus codes fit nicely with recent findings suggesting that cognitive response representations also reflect abstract conceptual codes and semantic meaning, rather than being represented in terms of simple motor codes. Responses have been shown to be represented as action effects, as means to reach specific goals, in terms of approaching versus avoiding objects or as producing or preventing positive and negative outcomes, respectively (e.g., Eder & Rothermund, 2008; Hommel et al., 2001; Markman & Brendl, 2005). Apparently, then, binding processes at the conceptual or semantic levels seem to be the rule rather than an exception.
Notably, the present results also indicated effects of distractor inhibition. An average benefit in probe RTs and probe errors for distractor repetition was found. This positive priming effect of distractor-to-distractor repetitions is exactly what an inhibition account would predict (Frings & Wühr, 2007; Giesen et al., 2012; Houghton & Tipper, 1994): On probe presentation, the repeated distractor stimulus still suffers from inhibition; consequently, a repeated distractor interferes less with the processing of the target stimulus than does a new distractor. The benefit demonstrated with repeated distractors (independently of their modality) on both response repetition and response change trials indicates a general inhibition of distractor stimuli in the present study. However, an inhibition of the distractor stimulus cannot account for the finding that distractor repetition benefits (i.e., shorter RTs and smaller error rates if the distractor was repeated than if the distractor was changed) were larger on response repetition trials than on response change trials (i.e., the interaction effect of response relation and distractor relation). Instead, an inhibition theory assumes distractor repetition benefits to be independent of the response relation between the prime and probe. The difference in distractor repetition effects for response repetition and response change trials clearly indicates processes of distractor–response binding and retrieval that are independent of modality switches between the prime and probe.
Yet it should be noted that the finding of cross-modal distractor priming indicating a conceptual mediation of the distractor-based retrieval effects reported in our study might not reflect a general phenomenon but might have been due to certain features of the task that was used in our study. In the task we used, distracters and targets were drawn from the same set of stimuli, and each stimulus was uniquely assigned to a specific response. These task features strongly encourage a verbal identification of the stimuli, which helps to identify the correct response. Such semantic tagging might be a necessary requirement for obtaining conceptually mediated effects, which might not occur with other tasks in which distractors are not part of the target set or responses have to be generated on the basis of target features that are unrelated to the nominal identity of the presented stimuli (i.e., using a categorization task instead of an identification task). We thus want to explicitly emphasize that our findings should not be taken to indicate that conceptual code activation is a ubiquitous phenomenon or that all kinds of binding and retrieval processes are conceptually mediated. Nor do our findings suggest that binding processes cannot be based on perceptual codes. The sole aim of our study was to demonstrate that a conceptual mediation of S–R binding and retrieval effects is possible, whereas previous accounts focused on the binding of perceptual features rather than on stimulus identities. Taken together, one could conclude that even if verbal tagging was used to some degree by the participants, our data show that distractor–response binding did not occur only at the perceptual level.
Despite this qualification, the finding of a conceptual mediation of event file retrieval is noteworthy and theoretically important for the following reasons. (1) Our results show that if conceptual codes are activated, they become automatically integrated into event files, separately from perceptual codes of the stimuli. (2) Activation of conceptual codes can lead to the retrieval of a previous episode that contains the same conceptual code, even if the conceptual code of the previous episode was activated on the basis of a completely different physical stimulus. (3) Activation of conceptual codes probably is a conditionally automatic (in the sense of task dependent; cf. Moors & De Houwer, 2006) process, because such an activation also occurred for irrelevant distractor stimuli that should be ignored and that were presented in a sensory modality that was different from the target stimuli. It should be noted, however, that each participant had to identify word and auditory stimuli throughout the experiment, which might have contributed to the fact that even stimuli of the irrelevant modality were conceptually represented; this might not be the case if target stimuli are always presented in the same modality.
Finally, one might also argue that activating the perceptual features of a stimulus in one modality (e.g., visual features) might simply coactivate perceptual features belonging to the same semantic stimulus representation in another modality (e.g., auditory features); that is, presenting the picture of a chicken will activate the memory entry of the concept chicken, including perceptual features in other modalities. From this perspective, repeating, say, a previously visual distractor in audition would not be different from repeating the same distractor in vision, because all perceptual features of the concept are always activated. In this case, the binding and retrieval effects might not be conceptually mediated, because the findings could also be explained in terms of an integration of multiple perceptual features (although the activation of the not-presented features would even then be conceptually mediated). Yet even then, our data still provide an intriguing pattern in that distractor-based S–R retrieval is not confined to the particular distractor that was presented when the response was made but transfers to the mental representation of the distractor in general.
In sum, our data underline the generality of the S–R retrieval mechanism, particularly for irrelevant features or objects of an episode. It seems that a retrieval of event files can be mediated by perceptual features (e.g., Frings et al., 2007; Frings & Rothermund, 2011; Hommel, 2004; Mayr & Buchner, 2006), by word entries in a lexicon (Giesen & Rothermund, 2011; Rothermund et al., 2005), by location information (Frings & Moeller, 2010), and also by conceptual representations of irrelevant stimuli—as evidenced by the results of the present study.
References
Buchner, A., Zabal, A., & Mayr, S. (2003). Auditory, visual, and cross-modal negative priming. Psychonomic Bulletin & Review, 10, 917–923.
Chen, Y.-C., & Spence, C. (2010). When hearing the bark helps to identify the dog: Semantically-congruent sounds modulate the identification of masked pictures. Cognition, 114, 389–404.
Chen, Y.-C., & Spence, C. (2011). Crossmodal semantic priming by naturalistic sounds and spoken words enhances visual sensitivity. Journal of Experimental Psychology. Human Perception and Performance, 37, 1554–1568.
Denkinger, B., & Koutstaal, W. (2009). Perceive-decide-act, perceive-decide-act: The benefits and costs of previous decisions in object priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 742–756.
Eder, A. B., & Rothermund, K. (2008). When do motor behaviors (mis)match affective stimuli? An evaluative coding view of approach and avoidance reactions. Journal of Experimental Psychology. General, 137, 262–281.
Fox, E. (1995). Negative priming from ignored distractors in visual selection: A review. Psychonomic Bulletin and Review, 2, 145–173.
Frings, C. (2010). On the decay of distractor-response episodes. Experimental Psychology, 58, 125–131.
Frings, C., & Moeller, B. (2010). Binding targets’ responses to distractors’ locations: Distractor response bindings in a location priming task. Attention, Perception, & Psychophysics, 72, 2176–2183.
Frings, C., & Rothermund, K. (2011). To be or not to be…included in an event file: Integration and retrieval of distractors in stimulus-response episodes is influenced by perceptual grouping. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 1209–1227.
Frings, C., & Wühr, P. (2007). On distractor repetition benefits in the negative-priming paradigm. Visual Cognition, 15, 166–178.
Frings, C., Rothermund, K., & Wentura, D. (2007). Distractor repetitions retrieve previous responses to targets. Quarterly Journal of Experimental Psychology, 60, 1367–1377.
Frings, C., Wentura, D., & Wühr, P. (2012). On the fate of distractor representations. Journal of Experimental Psychology: Human Perception & Performance, 38, 570–575.
Giesen, C., Frings, C., & Rothermund, K. (2012). Investigating the interplay of top-down and bottom-up control of behavior: Differences in the strength of inhibition do not affect distractor-response bindings. Memory & Cognition, 40, 373–387.
Giesen, C., & Rothermund, K. (2011). Affective matching moderates S-R binding. Cognition & Emotion, 25, 342–350.
Gordon, R. D., & Irwin, D. E. (1996). What is an object file? Evidence from priming studies. Perception & Psychophysics, 58, 1260–1277.
Gordon, R. D., & Irwin, D. E. (2000). The role of physical and conceptual properties in preserving object continuity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 136–150.
Henderson, J. M. (1994). Two representational systems in dynamic visual identification. Journal of Experimental Psychology. General, 123, 410–426.
Hommel, B. (1998). Event files: Evidence for automatic integration of stimulus-response episodes. Visual Cognition, 5, 183–216.
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8, 494–500.
Hommel, B. (2005). How much attention does an event file need? Journal of Experimental Psychology. Human Perception and Performance, 31, 1067–1082.
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The Theory of Event Coding (TEC): A framework for perception and action planning. The Behavioral and Brain Sciences, 24, 849–937.
Houghton, G., & Tipper, S. P. (1994). A model of inhibitory mechanisms in selective attention. In D. Dagenbach & T. H. Carr (Eds.), Inhibitory processes in attention, memory, and language (pp. 53–112). San Diego, CA: Academic Press.
Kahneman, D., & Treisman, A. (1984). Changing views of attention and automaticity. In R. Parasuraman, R. Davies & J. Beatty (Eds.), Varieties of attention (pp. 29–61). San Diego, CA: Academic Press.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24, 175–219.
Laurienti, P., Kraft, R., Maldjian, J., Burdette, J., & Wallace, M. (2004). Semantic congruence is a critical factor in multisensory behavioral performance. Experimental Brain Research, 158, 405–414.
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95, 492–527.
Markman, A. B., & Brendl, C. M. (2005). Constraining theories of embodied cognition. Psychological Science, 16, 6–10.
Mayr, S., & Buchner, A. (2006). Evidence for episodic retrieval of inadequate prime responses in auditory negative priming. Journal of Experimental Psychology. Human Perception and Performance, 32, 932–943.
Mayr, S., Buchner, A., & Dentale, S. (2009). Prime retrieval of motor responses in negative priming. Journal of Experimental Psychology. Human Perception and Performance, 2, 408–423.
Moors, A., & De Houwer, J. (2006). Automaticity: A theoretical and conceptual analysis. Psychological Bulletin, 132, 297–326.
Rothermund, K., Wentura, D., & De Houwer, J. (2005). Retrieval of incidental stimulus-response associations as a source of negative priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 482–495.
Tipper, S. P., & Driver, J. (1988). Negative priming between pictures and words in a selective attention task: Evidence for semantic processing of ignored stimuli. Memory & Cognition, 16, 64–70.
Treisman, A. (1992). Perceiving and re-perceiving objects. American Psychologist, 47, 862–875.
Tukey, J. (1977). Exploratory data analysis. Reading, MA: Addison-Wesley.
Author notes
Christian Frings and Birte Moeller, Campus I, Institut für Psychologie, Universität Trier, D-54286 Trier, Germany, and Klaus Rothermund, Friedrich-Schiller-Universität Jena, Jena, Germany.
The research reported in this article was supported by a grant from the Deutsche Forschungsgemeinschaft to Christian Frings (FR 2133/1-2). We thank Simon Grondin, Tsuyoshi Kuroda, and two anonymous reviewers for their helpful comments on a previous version of the manuscript.
Correspondence concerning this article may be addressed to Christian Frings, University of Trier, Department of Psychology, Campus I, D-54286 Trier, Germany (Email: chfrings@uni-trier.de).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Frings, C., Moeller, B. & Rothermund, K. Retrieval of event files can be conceptually mediated. Atten Percept Psychophys 75, 700–709 (2013). https://doi.org/10.3758/s13414-013-0431-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0431-3