
Abstract
Sudden visual changes attract our gaze, and related eye movement control requires attentional resources. Attention is a limited resource that is also involved in working memory—for instance, memory encoding. As a consequence, theory suggests that gaze capture could impair the buildup of memory respresentations due to an attentional resource bottleneck. Here we developed an experimental design combining a serial memory task (verbal or spatial) and concurrent gaze capture by a distractor (of high or low similarity to the relevant item). The results cannot be explained by a general resource bottleneck. Specifically, we observed that capture by the low-similar distractor resulted in delayed and reduced saccade rates to relevant items in both memory tasks. However, while spatial memory performance decreased, verbal memory remained unaffected. In contrast, the high-similar distractor led to capture and memory loss for both tasks. Our results lend support to the view that gaze capture leads to activation of irrelevant representations in working memory that compete for selection at recall. Activation of irrelevant spatial representations distracts spatial recall, whereas activation of irrelevant verbal features impairs verbal memory performance.
Similar content being viewed by others


Oculomotor capture is a very basic mechanism (Kramer, Gonzales de Sather, & Cassavaugh, 2005; Kramer, Hahn, Irwin, & Theeuwes, 2000) triggered by changes in the environment. But different visual changes attract the gaze with varying reliability. The sudden onset of a new object captures the gaze (Theeuwes, Kramer, Hahn, & Irwin, 1998), but a sudden color change does not (Irwin, Colcombe, Kramer, & Hahn, 2000), or does so to a much smaller degree (Colcombe et al., 2003). Perceptual factors—for instance, luminance or salience (Foulsham & Underwood, 2009; Kramer et al., 2000) or the distance between distractor and target (Edelman & Xu, 2009; Walker, Deubel, Schneider, & Findlay, 1997)—modulate this effect. Importantly, capture by an irrelevant distractor occurs in less than 30 % of trials (Colcombe et al., 2003, Kramer et al., 2000), demonstrating that such capture can be controlled for in most trials. Control is preferable to capture, because capture should create costs for ongoing processing of relevant information. Our study tests this prediction in an eyetracking experiment. We chose a design implementing capture during memory encoding of verbal or spatial visual items for immediate serial recall.
A prediction of the costs of oculomotor capture can be derived from the potentially overlapping roles of visual attention in working memory models and in models of saccade generation. First, eye movement control and attention are closely coupled, but the relationship is rather asymmetric. Whereas it is possible to focus on a specific location in the visual field but to attend a different location (Posner, 1980), moving the eyes to a specific location implies moving attention to that location prior to the execution of the eye movement (Deubel & Schneider, 1996; Hoffman & Subramaniam, 1995; Kowler, Anderson, Dosher, & Blaser, 1995). That is, eye movements can only be executed when attention has shifted as well (Shepherd, Findlay, & Hockey, 1986). This is not only true for voluntary planned saccades—for instance, in studies in which a saccade is directed to the response target of a detection or discrimination task (Deubel & Schneider, 1996; Hoffman & Subramaniam, 1995; Kowler et al., 1995); the coupling of attentional shift and eye movements has been demonstrated for reflexive saccades, as well—for instance, when gaze is captured by an onset stimulus (Bisley & Goldberg, 2003; Peterson, Kramer, & Irwin, 2004).
Second, attention is an integral part of working memory models (e.g., Baddeley, 2003; Barrouillet, Bernardin, & Camos, 2004; Cowan, 1995; Engle, Kane, & Tuholsky, 1999; Oberauer, 2002) and of mathematical models of short-term memory (e.g., Brown, Neath, & Chater, 2007; Neath, 2000; Page & Norris, 2003). In such models, attention serves as a limited resource to keep information available (memory maintenance), to select information either from the environment (memory encoding) or from memory (memory retrieval), and to manipulate and update memory representations. Empirical evidence for the link between spatial attention and memory is manifold (e.g., Awh, Vogel, & Oh, 2006) and has been demonstrated for different memory processes. With regard to memory encoding, it has been shown that attending to spatial regions facilitates the processing of objects located in those regions (Posner, 1980) and benefits the transfer of object information into working memory (Schmidt, Vogel, Woodman, & Luck, 2002). With regard to memory maintenance, it has been demonstrated that the processing of stimuli occurring at the location of previously encoded objects is prioritized (Awh, Jonides, & Reuter-Lorenz, 1998). Finally, the looking-at-nothing phenomenon sheds some light on the coupling of attention and memory during retrieval (D. C. Richardson & Spivey, 2000): In this paradigm, participants have to remember auditorily presented facts while irrelevant objects occur visually on a screen. During retrieval, participants prefer to look at the location of the previously presented irrelevant object, indicating that attending to this location cues retrieval for the auditorily presented facts. Moreover, several studies have demonstrated, through the use of attentional blink or dual-task designs (Downing, 2000; Downing & Dodds, 2004; Houtkamp & Roelfsema, 2006; Oh & Kim, 2004; Olivers, Meijer, & Theeuwes, 2006; Pashler & Shiu, 1999; Soto, Heinke, Humphreys, & Blanco, 2005; Woodman & Luck, 2007; Woodman, Luck, & Schall, 2007), that activated memory representations guide, prioritize, and facilitate attentional selection.
In our experiment, we investigated the relation between attention and memory encoding. Whereas most of the abovementioned studies demonstrated the impact of activated memory representations on attentional processing, we were interested in the effect of attentional processing on memory performance. Given that attention as a limited resource is related to both memory encoding and eye movement control, capturing the gaze (and, hence, attention) should impair memory encoding. Memory encoding includes several processes, such as stimulus identification—which might depend on foveal processing—but also consolidation into short-term memory—which might be less dependent on foveal processing. Capturing the gaze removes some of the attentional resource from the resource pool, which otherwise would facilitate processing of relevant information. If fewer attentional resources remain for memory encoding and maintenance because of attentional capture, memory performance will decrease. Such a prediction can be derived from current models of working memory (e.g., Cowan, 1995; Engle et al., 1999). For instance, in the working memory model of Cowan (1999), memory representations are held in a highly activated state—in the focus of attention. Note that this focus is not identical to a visual focus, but rather is an abstract component referring to a small subset of mental representations kept available for ongoing processing. If the focus is captured by irrelevant information, already encoded memory representations are forced out of the focus, thereby losing their activation benefit. If the focus lingers with the irrelevant information, new relevant information cannot enter the focus. As a result, memory performance would be impaired.
However, it could be argued that the costs of oculomotor capture might be far from dramatic. Sudden onsets trigger saccades in a reflexive way (for an overview of saccadic control, see Pierrot-Deseilligny, Rivaud, Gaymard, Müri, & Vermersch, 1995). Reflexive (or exogenous) saccades are initiated faster than voluntary (or endogenous) saccades (Walker, Walker, Husain, & Kennard, 2000), and require less control of motor execution (Pashler, Carrier, & Hoffman, 1993; Stuyven, Van der Goten, Vandierendonck, Claeys, & Crevits, 2000). In addition, redirecting the gaze voluntarily to relevant information might not hamper the cognitive system as well: Corrective saccades to a position-changing target have been demonstrated to be executed rather quickly (Deubel, Wolf, & Hauske, 1982), as have corrective saccades from a concurrently presented distractor to the response target (Irwin et al., 2000; Theeuwes et al., 1998). Distraction by oculomotor capture thus might be negligible in the context of memory encoding for two reasons: (a) Reflexive saccades might not draw much on attentional resources, or (b) attentional capture and subsequent disengagement are fast, and may not block the resource bottleneck for long.
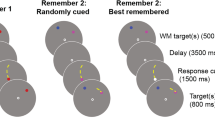
The goal of our present experiment was to test whether gaze capture during memory encoding is associated with costs on memory performance (because of overlapping resources between saccadic control and working memory) or is not (because saccadic control is reflexive and does not draw on attentional resources, because attentional disengagement is fast, or finally, because there might be no resource sharing between saccadic control and working memory representations). We used serial recall of digits or digit locations as either a verbal or a spatial memory task. The choice of serial recall for this study might not be intuitive, because it has been argued that serial information can be maintained by fairly automatic processes (e.g., Baddeley, 2003). However, arguably, even in such a framework encoding and retrieval of serial information would require some attentional control. We made use of serial recall because of its relevance for understanding human cognition (see, e.g., J. T. E. Richardson, 2007). A further advantage of serial recall is that the processes of memory performance between task domains—for example, verbal and spatial—are rather compatible when using reconstruction of serial order (e.g., Guérard & Tremblay, 2008). In addition, there has been much progress in understanding and modeling performance of this task quantitatively, with attention implemented as an available resource (e.g., Neath, 2000; Page & Norris, 2003). We decided on a comparison of verbal and spatial recall in order to differentiate between (a) a general resource overlap between saccade programming and working memory, and (b) a domain-specific bottleneck—for instance, of (spatial) saccade programming and spatial memory representations. The latter assumption can be derived from studies demonstrating interference between spatial encoding (Postle, Idzikowski, Della Sala, Logie, & Baddeley, 2006) or spatial maintenance (Pearson & Sahraie, 2003) and voluntary eye movements. In our study, items were presented successively in a five-by-five grid. Concurrently with the relevant items, we presented a distractor object. The distractor was repeatedly presented at one and the same position, but changed its position a few times throughout the experiment. Behaviorally, it has been demonstrated that a change of distractor position results in memory impairment in a spatial but not in a verbal task (Lange, 2005). To further maximize the probability and effectiveness of capture, we manipulated distractor–target similarity on both perceptual and categorical levels. For instance, it has been demonstrated that the probability of oculomotor capture or the time needed to disengage the gaze from focusing on the distractor is affected by distractor–target similarity (Born, Kerzel, & Theeuwes, 2011; Ludwig & Gilchrist, 2003). In our experiment, the distractor was either a triangle (low similarity) or an irrelevant digit (high similarity). The task is illustrated in Fig. 1, where we have neglected the timing of events for clarity: Distractor onset was 200 ms before the onset of the relevant item, to better dissociate eye activity based on the presentation of the distractor versus the relevant item. One item cycle is depicted in Fig. 2.

Example of a trial sequence (A) of six to-be-remembered digit locations (spatial task) with a concurrent distractor that changed position unpredictably at Serial Position 4 within the trial (change condition). Note that in the majority of trials, the distractor remained in the same position throughout a trial (control condition). In the spatial task each trial sequence consisted of six items, and in the verbal task, of eight items, in order to adjust the difficulty between the tasks (see the Materials section). Answers were given by moving a mouse pointer in the display and indicating by mouse clicks the selections in serial order. The display for verbal recall was a number pad (B), and that for spatial recall was a five-by-five grid with potential to-be-selected fields highlighted (C)

Timing of one item cycle. One item cycle was defined by the distractor onset, at time stamp 0, followed by item onset at 200 ms and by the offset of both at 1,000 ms, with an empty matrix visible until the end of the cycle, at 1,200 ms
Method
Participants
A group of 32 adults with a mean age of 22 years (ranging from 18 to 30) participated for course credits or for an honorarium of €28 in this four-session experiment. Three of the participants were male and 29 were female, and all had normal or corrected-to-normal vision.
Apparatus
The data were collected in two labs, each equipped with a 22-in. monitor (resolution 1,280 × 1,024, refresh rate 85 Hz), an eyetracker (EyeLink 1000, SR Research), and two Windows PCs, one collecting the recorded eye movement data, and the other controlling the experimental procedure via Python, using the Vision Egg toolbox (Straw, 2008). A forehead-and-chin rest supported the participant’s head. In one room, the distance between the monitor and the chin rest was 60 cm, and in the other room the distance was 50 cm. This difference did not affect the results in a systematic way.
Materials
The memory items consisted of digits, randomly sampled from the digits 0 to 9, but excluding 5, which served as the distractor of high similarity to the relevant items (digit size: 1.3 × 0.9 cm, height × width). A circular frame (1.85-cm diameter) surrounded each digit. The line and font colors were white on a black background. The distractor of low similarity was a green triangle (1.5 × 1.5 cm). Items were presented in a five-by-five grid (12.1 × 11.8 cm, height × width). The verbal task consisted of eight digits per trial, the spatial task of six items. Using different list lengths is a standard procedure (see, e.g., Reuter-Lorenz et al., 2000) to compensate for the fact that the memory spans for spatial memory are generally smaller than those for verbal memory (e.g., Orsini et al., 1987). Indeed, we succeeded in equating difficulty between the tasks, as measured by correct performance in control trials without a distractor (mean accuracies and standard deviations: spatial, M = 72.33 %, SD = 11.77; verbal, M = 70.61 %, SD = 15.96), t < 1, p = .525, η 2 = .013.
The distractor occurred in 15 preselected fields in the five-by-five grid. The succession of these 15 fields during the experiment was fixed, but the starting position within the sequence varied randomly for each participant and session. By numbering the 25 fields from left to right and from top to bottom, the order of the 15 preselected fields can be reported as Locations 6, 19, 3, 17, 15, 7, 23, 9, 16, 24, 8, 20, 11, 4, and 18. The chosen preselection excluded any repetition of distractor position during the session while at the same time maximizing the distance between each two successive positions.
The positions of the memory list items were sampled randomly, with the following exception: In trials in which the distractor changed its position, we took special care to equate the spatial relations between the distractor and the memory item before and after the change. We prearranged the position of the memory item in the item cycle associated with the positional change of the distractor as well as in the previous item cycle (see Fig. 3 for an example). The rationale of the prearrangement was to maximize the chance for distraction and capture. The two successive relevant positions were located far apart, and the direct scanpath between the two relevant items always crossed the scanpath of the distractor movement. When the eyes were located at the prechange item, the distance to the postchange distractor location was always shorter than the distance to the postchange item location.

Illustration of the spatial relation between relevant items and distractors at a positional change. In this example, the triangle distractor moved from Position 6 to 19, and the associated memory items moved from Position 24 to 2 (for the position or field numbers, see the Materials section)
Verbal recall was collected via a visualized standard phone pad, arranged in 3 × 3 digits, plus the 0 at the bottom (edge length of the pad: 12.1 × 11.8 cm, height × width). The digits in the pad measured 0.6 × 0.4 cm. For spatial recall, a grid appeared with eight fields highlighted simultaneously by filled white circles (1.85-cm diameter), six of them covering the positions of the presented items, one covering the final distractor position, and the other position being randomly drawn (see Fig. 1).
The fixation object (to test measurement accuracy in the beginning of each trial) was a red square (0.3 × 0.3 cm), located centrally in one of the 25 fields of the grid. In trials without a distractor, the fixation object occurred at the center position of the grid; in trials with a distractor, the fixation object occurred at the distractor position.
Design
Task and distractor conditions were blocked per session in order to maximize top-down control of the task set. The two task types (verbal and spatial) were combined with the two distractor types (triangle and digit), resulting in four different task–distractor pairings, one pairing for each session. The serial order of the four pairings was balanced between participants by a complex Latin square design, balancing out serial order effects (e.g., dependent on the serial position within a sequence) as well as sequential order effects (e.g., consecutive positions). Each session contained 66 experimental trials: one block of 12 trials without a distractor (preceded by three practice trials), followed by four blocks of 12 trials with a distractor (the first of these blocks was also preceded by three practice trials). The block without a distractor was implemented to check for basic performance differences between the tasks (see the Materials section above). In each block with a distractor, the distractor changed its position on two trials. These two critical trials were separated by four or six trials. The change in distractor position was associated with the 4th, 5th, or 6th target item in the verbal task, or with the 3rd, 4th, or 5th target item in the spatial task, balanced across the session. This difference between the tasks took into account that the list lengths between tasks had to be adjusted. The serial position of the change was selected from the inner serial positions (to preclude specific effects of primacy or recency). There were, overall, 40 trials for each distractor–task pairing with an unchanging distractor position, and eight trials with a change of distractor position.
Procedure
In the beginning of each session, participants received written instructions about the experimental procedure. They were informed about the specific task–distractor pairing in the beginning of each session. In the verbal task, they had to serially recall digit identities, in the spatial task, digit locations had to be recalled. Importantly, the participants were explicitly informed that the digit 5 would never occur in the memory list throughout the experiment.
Each session started with the calibration procedure, using a standard nine-point pattern distributed across the whole screen. Each trial started with a recheck of the accuracy of calibration by means of a fixation check. This fixation check would fail when the deviation between the intended and actual fixations was larger than a half-field of the grid. A specific fixational object (see the Materials section) indicated the location of the intended fixation. The calibration was repeated after every fifth trial or if the fixation check failed twice in a row. Before each new calibration, a photograph (of flowers or of landscapes) was presented on screen for 4 s to offer short breaks and relax the eyes. Besides the calibration procedure and the fixation check, the participants were free to move their eyes without any restriction.
Participants initiated the fixation check at the beginning of each trial by pressing the space bar, at which point the five-by-five grid occurred with the fixation object. If the fixation check was passed, the five-by-five grid remained, and the trial started with presentation of the first memory item (no-distractor trials) or of the distractor (distractor trials). The memory item was displayed and remained on the screen for 800 ms, with an interitem interval of 400 ms. In distractor trials, the distractor appeared 200 ms earlier than the memory item and remained on screen for 1,000 ms, with an interdistractor interval of 200 ms. Both stimuli disappeared together. The timing of one item cycle in distractor trials is depicted in Fig. 2. Immediately after the last item cycle, the recall display occurred on the screen, and participants were to recall the items in their presentation order. The participants were asked to move the mouse pointer to each recalled digit or position field successively and to confirm their selection by a mouse click. Correction of answers was not possible, and participants had to guess if they did not remember. The participants received feedback about their correct performance after each trial.
Participants had to identify the critical items and reconstruct the order of the memory list by selecting each item successively via a mouse click. In both tasks, all memory items (which had appeared in the memory task) and two additional, lure items (which had not appeared in the memory task) were presented simultaneously at recall. This design combined memory for order and memory for items. Therefore, two different error types were possible: (a) an order error, in the case the participant chose the wrong serial position for the memory item, or (b) an item error, on which the participant chose one extralist lure instead of a memory item. In the spatial task, one of the lure positions was the distractor position (in change trials, the new distractor position), the other was selected randomly from the remaining grid positions. In the verbal task with the high-similar distractor, one lure digit was the distractor digit 5, and the other lure was the remaining digit (out of ten). The verbal task with the low-similar distractor did not include the distractor (the green triangle) as a lure for logical reasons, but again the digit 5—which was no distractor in the critical session—was one of the lure items. By using this design, the probability of making an order or an item error was adjusted between tasks. In the case of an item error, there was a 50 % chance to choose the distractor, with the exception of the triangle distractor in the verbal task.
Data treatment
We report a change-locked analysis of performance with three serial positions: the first locked to the item cycle in which the distractor changed its location to a new position (Ch), as well as one item cycle before (Ch–1) and one cycle after (Ch + 1) the change. Trials in which the distractor remained in its position served as controls: We selected performance at the corresponding serial positions (before, at, and after the change) and calculated the mean across all control trials. The data were analyzed using paired t tests or repeated measures analyses of variance (ANOVAs), and the alpha level was set to .05 (two-tailed).
Accuracy
We followed a strict serial position criteria and calculated the proportion of correct items per trial.
Categorization of saccades
Eye movement data were categorized into saccades and fixational eye movements, using the velocity-based algorithm of Engbert and Mergenthaler (2006). We included trials on which participants blinked, but set those coordinates to not-a-number. As a result, the algorithm excluded the blinking period. Saccades with amplitudes smaller than 0.6 cm (20 pix = 0.6º/0.7º of viewing angle at a 60-/50-cm viewing distance), shorter than 10 ms, or faster than the mean peak velocity of detected saccades plus the tenfold standard deviation were ignored (main proportion of microsaccades).
Fixation position
We calculated the median of the x- and y-coordinates during the fixational epoch in order to specify the position of a fixation. A fixation was defined as matching a field in the grid when it was placed somewhere within that field. The field spanned a rectangular area with a 2.4-cm edge length, whereas the item spanned a circular area with a 1.85-cm diameter centralized within the rectangular field.
Saccade rates
We analyzed saccade rates in order to compare oculomotor capture between conditions. This was advantageous for two reasons: First, the low number of trials in which the distractor changed its position made the comparison of mean capture probabilities and saccadic response times (RTs) between conditions difficult. Second, and more importantly, saccade rates provided us with additional information about the temporal dynamics of eye movement patterns.
Saccade rates depict the mean number of saccades across a time interval (here, 100 ms). We locked saccade rates to the onset of the distractor (time stamp 0 in Fig. 2). For instance, a peak in saccade rates of 0.8 saccades/100 ms at time stamp 400 ms (e.g., Fig. 4A) could be translated into a mean of 0.8 saccades (across all participants) generated between 350 and 450 ms after distractor onset. We compared the saccade rates for the prechange, change, and postchange item cycles and differentiated between saccades according to the saccade goal: either item or distractor. For simplicity, we excluded saccades targeting other positions. Rates were estimated by applying a causal filter (Dayan & Abbott, 2001, pp. 9–14) with a smoothing kernel of the form

Low-similar distractors: Saccade rates for the serial positions before the change (prechange position, Ch–1), at the change (Ch), and after the change (postchange position, Ch + 1), dissociated for the saccade target (distractor or relevant item). Error areas show the 95 % confidence intervals
where α = 1/20 (see Engbert, 2006, for details). We estimated rates first for individual participants and plotted the averages with 95 % confidence intervals.
To compare saccade rates statistically, we calculated the mean individual probabilities of a saccade for several critical time windows. These critical time windows were selected post-hoc, analogously to other established methods in which dynamic behavior is analyzed statistically, such as event-related potentials in neuroscience methods. The purpose of such an analysis was to evaluate statistically the critical intervals in which effects were predicted to occur. Because of this procedure, the time in which no saccades were triggered did not contribute to the analysis and could not diminish effects. Importantly, the post-hoc definition of the critical time windows was not arbitrary but was strongly related to the events. The first window was between 100 and 300 ms and refers to saccades related to the distractor (with the distractor onset at time stamp 0, and related saccades around 200 ms later), and the second window between 300 and 500 ms, referring to saccades to the relevant item (with the item onset at time stamp 200 and related saccades around time stamp 400). We noted that, for some task–distractor combinations, the saccades to the relevant item were delayed, and we thus included two smaller time windows for statistical support of that observation: from 300 to 450 ms and from 450 to 600 ms.
Results
Capture of the gaze: Eye movement behavior
We first report results for the low-similar distractor (green triangle). Figure 4 depicts saccade rates for the first 600 ms of the item cycle, splitting saccades toward the item or the low-similar distractor for the three critical serial positions (Ch–1, Ch, and Ch + 1) during verbal (upper panel) and spatial (lower panel) encoding. The results in the left- and rightmost panels are clear (Figs. 4A and 4B, Figs. 4E and 4F, respectively): The functions are superimposed for change and control trials. Saccade rates related to the item peaked around 400 ms—that is, 200 ms after item onset. The functions for saccades toward the distractor are flat, showing sufficient inhibition of saccades by the distractor onset. The middle panels (Figs. 4C and 4D) differ from the other panels in two respects. First, for the early time window of 100 to 300 ms, saccade rates to the distractor increased in comparison to the control trials, peaking around 200–260 ms after distractor onset: t(31) = 7.93, p < .001, η2 = .671, for the verbal task, and t(31) = 5.50, p < .001, η2 = .494, for the spatial task. Second, saccade rates to the relevant item decreased in comparison to the control trials in the temporal window of 300 and 450 ms: t(31) = 4.85, p < .001, η2 = .432, for the verbal task, and t(31) = 7.67, p < .001, η2 = .655, for the spatial task. However, they then increased relative to control between 450 and 600 ms: t(31) = 5.97, p < .001, η2 = .535, for the verbal task, and t(31) = 3.85, p < .01, η2 = .324, for the spatial task. Both the decrease and the increase were due to a shift of the peak, which was around 450 ms. It is clear from Figs. 4C and 4D that the change of distractor position captured the gaze toward the distractor, whereas saccade rates toward the item were overall diminished and delayed.
Interestingly, a comparison of all three critical item cycles demonstrates that the gaze was captured in the item cycle of the distractor change only—that is, the first time when the distractor occurred at the new position (Figs. 4C and 4D). In the item cycle after the change—for instance, when the distractor was presented the second time at the new position—oculomotor control has already returned to optimal: The distractor no longer captured the gaze (see Figs. 4E and 4F). This indicates that the visual change automatically triggered capture, whereas the unchanged distractor position might not have elicited any mismatch signal at all. Capture was highly specific to the cycle with the distractor change. Alternatively, one might argue that the distractor needed to be inhibited, and that the memory representation of the new distractor position at Ch + 1 had been built fast and were reliable, to potentially aid in distractor inhibition.
These results clearly demonstrate oculomotor capture by the low-similar distractor for both task–distractor combinations. Baseline differences in saccade rates between the tasks (see, e.g., Figs. 4A and 4B, or saccade rates to the control items) make it difficult to compare the magnitudes of capture between the tasks. However, the similarity between the patterns in the verbal and spatial tasks is striking: Gaze was distinctly captured by the positional change of the distractor. In that case, saccades toward the memory items were delayed and the rate was reduced. Gaze was sufficiently controlled only one item cycle after the change, and generally when the distractor occurred repeatedly at the same position.
We will now turn to the results for the high-similar distractor, where a different pattern emerged (see Fig. 5). Again, in the prechange trial the saccade rates related to the distractor were flat and saccade rates to the memory item were superimposed for control and change trials, with a peak around 400 ms (Figs. 5A and 5B). This implicates sufficient gaze control: The distractor was ignored, so the eyes fixated on the memory item. But when the distractor changed its position, this regular pattern was disturbed (Figs. 5C and 5D): The distractor captured the gaze, with an increase in saccade rates between control and change trials: t(31) = 10.47, p < .001, η2 = .779, for the verbal task, and t(31) = 5.50, p < .001, η2 = .446, for the spatial task. In addition, saccade rates toward the memory item dropped dramatically: t(31) = 17.09, p < .001, η2 = .904, for the verbal task, and t(31) = 9.80, p < .001, η2 = .756, for the spatial task (both tests were conducted for the time window 300–500 ms, control vs. change trials). The strong conflict for oculomotor control carried over to the postchange cycle (Figs. 5E and 5F): Saccades toward the memory item were still slightly reduced, with t(31) = 5.01, p < .001, η2 = .447, for the verbal task, and t(31) = 4.22, p < .001, η2 = .365, for the spatial task.

High-similar distractors: Saccade rates for the serial positions before the change (Ch–1), at the change (Ch), and after the change (Ch + 1), dissociated for the saccade target (distractor or relevant item). Error areas show the 95 % confidence intervals
Overall, the effect of the position-changing distractor on gaze control was more pronounced for the high-similar distractors than for the low-similar distractors. Oculomotor control can be differentiated into engagement (e.g., capture) and disengagement (from capture) (Born et al., 2011; Ludwig & Gilchrist, 2003). Figures 4 and 5 indicate that similarity had an effect on both processes: the probability of capture (saccade rates toward the distractor), as well as engagement with distractor processing. The later assumption is based on the observation that saccade rates toward the memory item were delayed for the low-similar distractor, indicating redirection of attention from the distractor to the memory item within few hundred milliseconds. In contrast, saccade rates toward the memory item dropped to zero when the high-similar distractor changed position. Attentional engagement with the distractor might have precluded sufficient encoding of the memory item (see the supplementary materials for further analyses). Encoding involves at least two components: stimulus identification and short-term consolidation into memory. The missing saccade rates to the memory item indicate that already stimulus identification was hindered, or at least the memory item was not attended overtly. Note that our experimental procedure was chosen to preclude a simple problem of foveal selection. The presentation time of 800 ms for the memory item was rather long and, generally, would have allowed for the planning and execution of two saccades, one to the distractor and another, subsequently, to the memory item.
The consistency of the patterns in the verbal and the spatial tasks are striking. Gaze capture by the low-similar distractor delayed and reduced saccade rates toward the memory item. This effect was limited to the change cycle only. Gaze capture by the high-similar distractor, however, wiped out saccades toward the relevant item, and this effect carried over to the next item cycle. The conclusion is that attentional engagement with a distractor affected the saccadic reaction to the relevant item, and that the time course of this engagement was governed by the similarity between the distractor and the memory item. The factor Task did not seem to have any impact.
Inspection of Figs. 4 and 5 indicates that saccade rates toward the distractor increased with the similarity between distractor and target. If gaze capture by the similar distractor was more pronounced in the first place, this capture would eventually hinder directing the gaze toward the target item. To test for differences in capture, we compared the saccade rates toward the distractor at change between the two distractor types for each task separately. Whereas saccade rates toward the two distractor types indeed did differ in the verbal task, t(31) = 3.50, p < .01, η2 = .293, there was no such effect in the spatial task, t(31) = 1.43, p > .10, η2 = .062. These diverging results between tasks make any easy relation between (increased) gaze capture by the distractor and (decreased) goal-driven saccade rates toward the target item unlikely.
Capture of the mind: Memory performance
The key research question of this study was how gaze capture is related to memory encoding. If gaze capture draws on the same attentional resources as memory encoding, memory performance should be impaired in all four cases. If engagement with the distractor, or a lack of engagement with the relevant item, is operative, then memory performance should be impaired solely—or more pronouncedly—in the case of a high-similar distractor. Surprisingly, this simple relation did not hold. Four repeated measures ANOVAs, each a two-factor design with Item Position as one factor (Ch–1, Ch, or Ch + 1) and Change Condition (control vs. change) as the other confirmed what Fig. 6 indicates: Even though the gaze was captured by the low-similar distractor in the verbal task, memory performance (Fig. 6A) was not at all affected by this capture, F < 1. In contrast, spatial task performance (Fig. 6B) decreased when the distractor changed its position, F(1, 31) = 8.82, p < .01, η2 = .221, and this impairment did not vary with serial position, F(2, 62) = 2.17, p = .123, η2 = .065. Clearly, oculomotor capture alone cannot explain memory performance. A second observation has to be pointed out: Whereas the gaze was rather unaffected for the pre- and postchange positions, spatial memory performance decreased for those items as well, indicating retro- and proactive effects of gaze capture. This leaves us with two important conclusions. First, capture of the gaze is not simply equated with capture of the mind. Second, oculomotor control does not draw on the same resources that are involved in working memory encoding. Gaze capture did not affect verbal memory performance, so no general resource conflict was demonstrated.

Mean accuracy, locked to the serial positions that were associated with the change (Ch), the prechange (Ch–1), and the postchange (Ch + 1) items. Accuracies in trials in which the distractor changed its position are compared to those in matched control trials with a distractor that did not change position. Error bars represent 95 % confidence intervals, adjusted for between-subjects variability in a within-subjects design, as suggested by Bakeman and McArthur (1996)
How can the task-specific effect be explained? One easy way to do so would be to assume that oculomotor capture interferes particularly with spatial but not with verbal encoding, resulting in task-specific interference. Such an assumption finds support from studies demonstrating interference between (auditory) spatial encoding and concurrent eye movements (Postle et al., 2006) or between maintenance of spatial information and eye movements in a retention interval (Pearson & Sahraie, 2003). But this simple explanation has to be dismissed for our study: Memory impairment (see Figs. 6C and 6D) was substantial for the high-similar distractor in both tasks: verbal, F(1, 31) = 51.38, p < .001, η2 = .624, and spatial, F(1, 31) = 78.31, p < .001, η2 = .716. The effect varied with item position for the verbal task, F(2, 62) = 14.26, p < .001, η2 = .315, as well as for the spatial task, F(2, 62) = 6.92, p < .01, η2 = .182. Figure 6 indicates that performance was particularly affected for the item that was temporarily associated with the positional change of the distractor, but retro- and proactive effects showed up as well.
Neither a general resource conflict of oculomotor control with memory performance nor a task-specific effect of oculomotor control on spatial memory encoding can explain the effect of a gaze-capturing distractor on memory performance. Apparently, there is no simple relation between oculomotor and memory control. One further hypothesis, not discussed so far, needs to be tested: Due to the strong coupling between gaze and attention, a stimulus that has captured the gaze will gain some attention, and as a consequence will be processed to some extent. Working memory models assume a capacity limitation between processed and stored information in working memory (e.g., Cowan, 1999), demonstrated, for instance, by similarity-based interference between processed and stored features (e.g., Oberauer & Lange, 2008). Consequently, gaze capture and distractor processing might create interference with the ongoing memory encoding of the relevant item.
Our design included one peculiarity: Whereas processing of the position of any distractor might create interference for spatial memory, processing of distractor identity would create interference only if there was some stimulus-specific overlap. The representation of the distractor digit 5 could thus create interference in the serial recall of digits, but it was less likely for the mental representation of a green triangle to cause interference in verbal memory. One reason for memory impairment by interference is that item representations compete at recall and are confused (e.g., Lange & Oberauer, 2005). Irrelevant digits can be confused with relevant digits, but for logical reasons, a green triangle cannot be confused with a digit. Analyzing error types could reveal whether the distractor information was processed and therefore caused interference due to intrusions. Our recall procedure allowed us to analyze intrusion errors, because all correct items plus two additional items were highlighted for recall selection. One of the additional items was the distractor (the digit 5 or the distractor position), and the other was an item that did not occur in the memory list. If participants did not remember the items in the list, there was a 50 % chance of choosing either the distractor (a distractor intrusion [DI]) or the alternative item (an alternative intrusion [AI]) erroneously for recall, which would result in comparable guessing probabilities for the two intrusion errors.
The main error category in serial recall is order errors (e.g., Bjork & Healy, 1974). Consistently, Table 1 shows that about 20 % to 30 % of all answers were order errors at the three critical serial positions of before, during, and after the change. Distractors intruded in a range of 0.16 % to 12.50 % of trials across all conditions, and intrusions of the alternative item occurred between 1.56 % and 9.38 % of the time. All error types showed increased rates in the change condition in comparison to the control trials. But, whereas distractor intrusions in particular increased dramatically (the increase during a change cycle ranged from 103.13 % to 2,559.57 %; six of nine tests were significant), alternative intrusion errors (increase between 3.80 % and 184.44 %; two of nine tests were significant) and order errors (increase between 3.49 % and 75.19 %; five of nine tests were significant) increased only moderately. Hence, whereas memory impairment cannot exclusively be explained by distractor intrusions, such intrusions contributed notably to the memory impairment. The processing of distractor information—indicated by oculomotor capture—left a clear mark in the recall output sequence, demonstrating a strong relation between attended and memorized items. Attending the distractor particularly affected the serial position that was associated with the change, but distractor representations also intruded for the pre- and postchange positions, indicating retro- and proactive interference.
In summary, gaze control for distractor onsets was reliable as long as the distractor did not change its position for some time. Gaze capture was initiated by a sudden change of the distractor position. The efficiency of oculomotor control after gaze capture (e.g., distractor disengagement) depends on distractor–target similarity. But memory impairment was related to the overlap of the representations activated by gaze capture and memory encoding. This overlap resulted in interference between distractor and target features.
Discussion
A position-changing visual distractor hampers concurrent memory encoding. The sources of this distraction are threefold: The gaze is captured by the distractor in a bottom-up manner in both tasks (verbal or spatial) and for both distractor types (similar or dissimilar). Shifting the gaze to the relevant memory item depends on distractor type only, but neither gaze capture nor disengagement can predict the impairment in memory performance. Performance decreased in the spatial task for both distractor types, but in the verbal task only for the high-similar distractor. This complex pattern is best explained by similarity-based interference between the distractor features and memory items. The spatial coordinates of the distractor interfered with ongoing spatial encoding, and the verbal features of the digit distractor hampered verbal memory performance. Hence, attentional capture has to be differentiated into capture of the gaze and capture of the mind.
The differentiation into capture of the gaze and capture of the mind is at odds with the predictions we derived from the theoretical links between eye movement control, attention, and memory. When an irrelevant stimulus captures the gaze, it captures attention (Bisley & Goldberg, 2003). Attention serves as a gatekeeper for memory (Awh et al., 2006): For instance, allocation of attention supports memory encoding. As such, attention is capacity limited, as is demonstrated by the attentional blink paradigm (Shapiro, Arnell, & Raymond, 1997), in which processing of one target impairs processing of a secondary target when both are presented in close temporal succession. The attentional gatekeeper with limited capacity operates as a bottleneck for processing (e.g., Cowan, 1999). The hypothesis was derived that attentional capture—as indicated by gaze capture—should impair concurrent memory encoding. This straightforward prediction did not hold, even though many studies have demonstrated a strong coupling between attention and memory (e.g., Downing, 2000; Oh & Kim, 2004; Olivers et al., 2006; Pashler & Shiu, 1999; Soto et al., 2005; Woodman et al., 2007). How can our results be reconciled with an assumed overlap between attention and memory? Importantly, there are two roles of attention: allocation of resources and selection of information for ongoing processes (Chun & Turk-Browne, 2007). The distinction between resource and selection is crucial for our study. Gaze capture by a low-similar distractor did not impair verbal memory, and thus, gaze capture per se did not draw on the resources needed for memory encoding. In the case of free resources, the question of which of the many options to choose for further processing still remains. The selection of the task-relevant object was more difficult when a high-similar distractor attracted the gaze. This had consequences for memory performance: Relevant and irrelevant representations were confused, so a distractor that attracted the gaze left a clear mark in memory. Hence, our results contribute to and extend the general finding of overlap between attention and memory.
Our results can also be reconciled with mathematical models of serial recall (e.g., Neath, 2000) and are consistent with activation models of attention (e.g., Desimone & Duncan, 1995). Our prediction of a resource-limited bottleneck was derived from the assumption that attention serves as a general resource to build up memory representations (e.g., Neath, 2000; Page & Norris, 2003). Processing of irrelevant information draws upon the attentional resources, dampening the representations of relevant items. As a result, errors should occur. But such an effect of dampening does not account for the particular increase of intrusion errors found in our study. Notably, one model assumes a specific mechanism that would establish the basis for intrusion errors: The mechanism is called feature adoption, in which representations of relevant items adopt features from irrelevant items (Neath, 2000). This process occurs particularly between representations that are in close temporal relation. Feature adoption should be particularly destructive if the adopted features are relevant for the task—for instance, if irrelevant location information is adopted during spatial recall, or an irrelevant digit identity during digit recall. Hence, feature adoption would be a very suitable mechanism to explain our results of gaze capture in memory performance. Similarly, in the biased-competition model of visual attention, Desimone and Duncan (1995) assumed that information competes for representation and processing. The close temporal relation of distractor and to-be-encoded items, as well as high similarity between the stimuli, increases competition. Distractor intrusions at memory retrieval are manifestations of the competition of neural mechanisms related to the processing of voluntarily and involuntarily attended information. The finding of interference between voluntarily and involuntarily attended information is not trivial, since these attentional control mechanisms rely on different neural networks (Corbetta & Shulman, 2002). It is thus conceivable that memory retrieval could clearly differentiate between representations activated either voluntarily or involuntarily. The high rate of distractor intrusions demonstrates that this is not the case.
The results of our study not only are compatible with existing approaches but reveal several new findings. First, our data suggest that a general resource bottleneck is not what hinders memory encoding when the gaze is captured. Rather, highly specific similarity-based interference and selection difficulties can account for the results. Second, we demonstrated interference between involuntary saccades (exogenous attention shifts) and spatial memory. Earlier evidence had been limited to interference between voluntarily controlled saccades (Pearson & Sahraie, 2003; Postle et al., 2006) or endogenous attention shifts (Awh & Jonides, 2001) and spatial memory. We showed that reflexive saccades can have dramatic consequences upon memory representations, even though reflexive saccades draw less on cognitive resources than voluntary saccades do (Stuyven et al., 2000). Third, we demonstrated distraction of verbal encoding by gaze capture, so distraction by gaze capture is not restricted to spatial memory (as shown, e.g., by Postle et al., 2006). Instead, memory performance is hampered as long as irrelevant and relevant features overlap. Fourth, we chose a new design of presenting distractor and memory items sequentially. It is well established that simultaneous presentation results in competition between planning a saccade to the target and to a distractor (Godijn & Theeuwes, 2002; Walker et al., 1997). In our study, the distractor was presented 200 ms before the memory item, and the memory item was presented for 800 ms, leaving some time for cognitive control of distraction and encoding of the relevant features. For instance, in the case of a low-similar distractor, the saccade rates toward the memory item were still pronounced, demonstrating cognitive control in the face of distraction. Such gaze control mechanisms indicate that the locus of competition might not only be selection at encoding, but rather the selection of the correct memory representation at recall. Our results are well in line with the finding that spatial working memory representations and a spatial map to program eye movements interact (Belopolsky & Theeuwes, 2009; McPeek, Han, & Keller, 2003; Van der Stigchel & Theeuwes, 2006). Consequently, it has been suggested that there is only one representational system for spatial memory and for guiding the gaze (McPeek, Maljkovic, & Nakayama, 1999; Theeuwes, Belopolsky, & Olivers, 2009).
What do our results contribute to the debate on the interaction between top-down and bottom-up processes during gaze capture? Gaze guidance can be affected by attentional capture in two ways: (a) directly by gaze capture, and (b) by the time needed to disengage from distractor processing, such as slowed saccadic RTs toward the target item and increased RTs for the identification of target stimuli (e.g., Irwin et al., 2000; Kramer et al., 2000; Theeuwes, Kramer, Hahn, Irwin, & Zelinsky, 1999). A distractor with abrupt onset occurs at a position that had not been occupied by a stimulus before—as in our study. Such a distractor captures attention in a bottom-up way (Irwin et al., 2000; Kramer et al., 2000; Theeuwes et al., 1999). However, it has been demonstrated that the probabilities of both capture and disengagement can be modulated by top-down control. For instance, a distractor that is visually similar to a search target (e.g., sharing the same color) in a visual search paradigm attracts the gaze more than does a dissimilar distractor (Ludwig & Gilchrist, 2002, 2003). Likewise, the similar distractor increases the time needed for disengagement, relative to a dissimilar distractor (Born et al., 2011). Both effects can be dissociated, indicating that disengagement does not depend on how strong capture was in the first place (Born et al., 2011). Our results tentatively support this dissociation: Whereas the saccade rates toward the distractor increased only modestly for the high-similar as compared to the low-similar distractor (with a significant increase in the verbal task only), saccade rates to the memory item were affected dramatically by the similarity between the distractor and the memory item.
Further evidence for some top-down impact can be observed when comparing gaze control for the postchange cycles between distractor types. If a simple change of distractor position induced a mismatch signal, which in turn caused an orienting response, the gaze would be captured during the change cycle only. In the change cycle, the distractor was presented at a different position than before. In the postchange cycle, however, the distractor remained at the same position as in the previous cycle; the new distractor position was kept constant. But, in case of a high-similar distractor, saccade rates to the memory item were still reduced, showing that the effect of gaze distraction carried over to the postchange cycle. This finding might be interpreted as a learning process, with active inhibition of a saccade toward the distractor, as long as the distractor occurred at an expected position. Expectations were built up by consecutive displays and were broken by the unannounced change of the distractor position.
Can we be certain that the decrease in memory performance was solely attributable to similarity-based interference between the relevant and irrelevant representations? No, we cannot rule out the possibility that further processes contributed to the distraction effect. For instance, spatial rehearsal can be dissociated into motor-based and attention-based processes (Awh & Jonides, 2001). As motor control and attention were not decoupled in our design, we cannot differentiate between these two components. It is conceivable that the motor activity itself caused some interference in the spatial task. Our data were too sparse to compare memory impairment by distractor change between trials in which the gaze was captured and other trials in which the gaze was not captured. A related study (Guérard & Tremblay, 2011) investigated the impact of eye movements with a constantly position-changing distractor in a sandwich condition: The presentation of to-be-remembered dot positions alternated with the presentation of distractor dots. The distractors occurred at different positions throughout a trial. The remembered dot location shifted toward the subsequent distractor location, indicating retroactive interference of the distractor location with the remembered location information. This effect occurred with and without eye movements toward the distractor and did not differ, indicating that motor activity itself did not necessarily increase interference. In addition, in a very subtle analysis, Bays and Husain (2008) demonstrated a small effect of eye movements on displacement judgments in a recognition task. However, the shape of the response functions did not differ between trials with and without eye movements, but did change dramatically when set size in the recognition task was increased. This indicates very clearly that eye movements do not impose costs within the capacity limitations for spatial memory for increasing numbers of items, and the potential costs of eye movements alone are rather small.
In summary, we demonstrated interactions between attended distractor features and memorized item features. As such, our results contribute to the finding that attention and memory are based on the same representational format. Conflicts arise not from a general processing bottleneck, but from a selection problem leading to confusion of the relevant and irrelevant representations.
References
Awh, E., & Jonides, J. (2001). Overlapping mechanisms of attention and spatial working memory. Trends in Cognitive Sciences, 5, 119–126. doi:10.1016/S1364-6613(00)01593-X
Awh, E., Jonides, J., & Reuter-Lorenz, P. A. (1998). Rehearsal in spatial working memory. Journal of Experimental Psychology: Human Perception and Performance, 24, 780–790. doi:10.1037/0096-1523.24.3.780
Awh, E., Vogel, E. K., & Oh, S.-H. (2006). Interactions between attention and working memory. Neuroscience, 139, 210–208.
Baddeley, A. D. (2003). Working memory: Looking back and looking forward. Nature Reviews Neuroscience, 4, 829–839. doi:10.1038/nrn1201
Bakeman, R., & McArthur, D. (1996). Picturing repeated measures: Comments on Loftus, Morrison, and others. Behavior Research Methods, Instruments, & Computers, 28, 584–589. doi:10.3758/BF03200546
Barrouillet, P., Bernardin, S., & Camos, V. (2004). Time constraints and resource sharing in adults’ working memory spans. Journal of Experimental Psychology: General, 133, 83–100. doi:10.1037/0096-3445.133.1.83
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321, 851–854. doi:10.1126/science.1158023
Belopolsky, A. V., & Theeuwes, J. (2009). Inhibition of saccadic eye movements to locations in spatial working memory. Attention, Perception, & Psychophysics, 71, 620–631. doi:10.3758/APP.71.3.620
Bisley, J. W., & Goldberg, M. E. (2003). Neuronal activity in the lateral intraparietal area and spatial attention. Science, 299, 81–86. doi:10.1126/science.1077395
Bjork, E. L., & Healy, A. (1974). Short-term order and item retention. Journal of Verbal Learning and Verbal Behavior, 13, 80–97.
Born, S., Kerzel, D., & Theeuwes, J. (2011). Evidence for a dissociation between the control of oculomotor capture and disengagement. Experimental Brain Research, 208, 621–631.
Brown, G. D. A., Neath, I., & Chater, N. (2007). A temporal ratio model of memory. Psychological Review, 114, 539–576. doi:10.1037/0033-295X.114.3.539
Chun, M. M., & Turk-Browne, N. B. (2007). Interactions between attention and memory. Current Opinion in Neurobiology, 17, 177–184.
Colcombe, A. M., Kramer, A. F., Irwin, D. E., Peterson, M. S., Colcombe, S., & Hahn, S. (2003). Age-related effects of attentional and oculomotor capture by onsets and color singletons as a function of experience. Acta Psychologica, 113, 205–225. doi:10.1016/S0001-6918(03)00019-2
Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience, 3, 201–215.
Cowan, N. (1995). Attention and memory: An integrated framework. New York, NY: Oxford University Press.
Cowan, N. (1999). An embedded-processes model of working memory. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 62–101). Cambridge, U.K.: Cambridge University Press.
Dayan, P., & Abbott, L. F. (2001). Theoretical neuroscience: Computational and mathematical modeling of neural systems. Cambridge, MA: MIT Press.
Desimone, R., & Duncan, J. (1995) Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18, 193–222. doi:10.1146/annurev.ne.18.030195.001205
Deubel, H., & Schneider, W. X. (1996). Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research, 36, 1827–1837. doi:10.1016/0042-6989(95)00294-4
Deubel, H., Wolf, W., & Hauske, G. (1982). Corrective saccades: Effect of shifting the saccade goal. Vision Research, 22, 353–364.
Downing, P. E. (2000). Interactions between visual working memory and selective attention. Psychological Science, 11, 467–473. doi:10.1111/1467-9280.00290
Downing, P. E., & Dodds, C. M. (2004). Competition in visual working memory for control of search. Visual Cognition, 11, 689–703.
Edelman, J. A., & Xu, K. Z. (2009). Inhibition of voluntary saccadic eye movement commands by abrupt visual onsets. Journal of Neurophysiology, 101, 1222–1234. doi:10.1152/jn.90708.2008
Engbert, R. (2006). Microsaccades: A microcosm for research on oculomotor control, attention, and visual perception. Progress in Brain Research, 154, 177–192.
Engbert, R., & Mergenthaler, K. (2006). Microsaccades are triggered by low retinal image slip. Proceedings of the National Academy of Sciences, 103, 7192–7197.
Engle, R. W., Kane, M. J., & Tuholski, S. W. (1999). Individual differences in working memory capacity and what they tell us about controlled attention, general fluid intelligence, and functions of the prefrontal cortex. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 102–134). Cambridge, U.K.: Cambridge University Press.
Foulsham, T., & Underwood, G. (2009). Does conspicuity enhance distraction? Saliency and eye landing position when searching for objects. Quarterly Journal of Experimental Psychology, 62, 1088–1098. doi:10.1080/17470210802602433
Godijn, R., & Theeuwes, J. (2002). Programming of endogenous and exogenous saccades: Evidence for a competitive integration model. Journal of Experimental Psychology: Human Perception and Performance, 28, 1039–1054. doi:10.1037/0096-1523.28.5.1039
Guérard, K., & Tremblay, S. (2008). Revisiting evidence for modularity and functional equivalence across verbal and spatial domains in memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 556–569. doi:10.1037/0278-7393.34.3.556
Guérard, K., & Tremblay, S. (2011). When distractor and to-be-remembered items compete for the control of action: A new perspective on serial memory for spatial information. Journal of Experimental Psychology: Human Perception and Performance, 37, 834–843. doi:10.1037/a0020561
Hoffman, J. E., & Subramaniam, B. (1995). The role of visual attention in saccadic eye movements. Perception & Psychophysics, 57, 787–795. doi:10.3758/BF03206794
Houtkamp, R., & Roelfsema, P. R. (2006). The effect of items in working memory on the deployment of attention and the eyes during visual search. Journal of Experimental Psychology: Human Perception and Performance, 32, 423–442. doi:10.1037/0096-1523.32.2.423
Irwin, D. E., Colcombe, A. M., Kramer, A. F., & Hahn, S. (2000). Attentional and oculomotor capture by onset, luminance and color singletons. Vision Research, 40, 1443–1453.
Kowler, E., Anderson, E., Dosher, B., & Blaser, E. (1995). The role of attention in the programming of saccades. Vision Research, 35, 1897–1916. doi:10.1016/0042-6989(94)00279-U
Kramer, A. F., Gonzalez de Sather, J. C. M., & Cassavaugh, N. D. (2005). Development of attentional and oculomotor control. Developmental Psychology, 41, 760–772. doi:10.1037/0012-1649.41.5.760
Kramer, A. F., Hahn, S., Irwin, D. E., & Theeuwes, J. (2000). Age differences in the control of looking behavior: Do you know where your eyes have been? Psychological Science, 11, 210–217. doi:10.1111/1467-9280.00243
Lange, E. B. (2005). Disruption of attention by irrelevant stimuli in serial recall. Journal of Memory and Language, 53, 513–531. doi:10.1016/j.jml.2005.07.002
Lange, E. B., & Oberauer, K. (2005). Overwriting of phonemic features in serial recall. Memory, 13, 333–339.
Ludwig, C. J. H., & Gilchrist, I. D. (2002). Stimulus-driven and goal-driven control over visual selection. Journal of Experimental Psychology: Human Perception and Performance, 28, 902–912. doi:10.1037/0096-1523.28.4.902
Ludwig, C. J. H., & Gilchrist, I. D. (2003). Goal-driven modulation of oculomotor capture. Perception & Psychophysics, 65, 1243–1251. doi:10.3758/BF03194849
McPeek, R. M., Han, J. H., & Keller, E. L. (2003). Competition between saccade goals in the superior colliculus produces saccade curvature. Journal of Neurophysiology, 89, 2577–2590.
McPeek, R. M., Maljkovic, V., & Nakayama, K. (1999). Saccades require focal attention and are facilitated by a short-term memory system. Vision Research, 39, 1555–156.
Neath, I. (2000). Modeling the effects of irrelevant speech on memory. Psychonomic Bulletin & Review, 7, 403–423. doi:10.3758/BF03214356
Oberauer, K. (2002). Access to information in working memory: Exploring the focus of attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 411–421. doi:10.1037/0278-7393.28.3.411
Oberauer, K., & Lange, E. (2008). Interference in verbal working memory: Distinguishing similarity-based confusion, feature overwriting, and feature migration. Journal of Memory and Language, 58, 730–745.
Oh, S.-H., & Kim, M.-S. (2004). The role of spatial working memory in visual search efficiency. Psychonomic Bulletin & Review, 11, 275–281. doi:10.3758/BF03196570
Olivers, C. N. L., Meijer, F., & Theeuwes, J. (2006). Feature-based memory-driven attentional capture: Visual working memory content affects visual attention. Journal of Experimental Psychology: Human Perception and Performance, 32,1243–1265. doi:10.1037/0096-1523.32.5.1243
Orsini, A., Grossi, D., Capitani, E., Laiacona, M., Papagno, C., & Vallar, G. (1987). Verbal and spatial immediate memory span: Normative data from 1355 adults and 1112 children. Italian Journal of Neurological Sciences, 8, 539–548.
Page, M. P. A., & Norris, D. G. (2003). The irrelevant sound effect: What needs modeling, and a tentative model. Quarterly Journal of Experimental Psychology, 56A, 1289–1300.
Pashler, H., Carrier, M., & Hoffman, J. (1993). Saccadic eye movements and dual-task interference. Quarterly Journal of Experimental Psychology, 46A, 51–82.
Pashler, H., & Shiu, L.-P. (1999). Do images involuntarily trigger search? A test of Pillsbury’s hypothesis. Psychonomic Bulletin & Review, 6, 445–448. doi:10.3758/BF03210833
Pearson, D. G., & Sahraie, A. (2003). Oculomotor control and the maintenance of spatially and temporally distributed events in visuo-spatial working memory. Quarterly Journal of Experimental Psychology, 56A, 1089–1111.
Peterson, M. S., Kramer, A. F., & Irwin, D. E. (2004). Covert shifts of attention precede involuntary eye movements. Perception & Psychophysics, 66, 398–405. doi:10.3758/BF03194888
Pierrot-Deseilligny, C., Rivaud, S., Gaymard, B., Müri, R., & Vermersch, A. I. (1995). Cortical control of saccades. Annals of Neurology, 37, 557–567.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32, 3–25. doi:10.1080/00335558008248231
Postle, B. R., Idzikowski, C., Della Sala, S., Logie, R. H., & Baddeley, A. D. (2006). The selective disruption of spatial working memory by eye movements. Quarterly Journal of Experimental Psychology, 59, 100–120. doi:10.1080/17470210500151410
Reuter-Lorenz, P. A., Jonides, J., Smith, E. E., Hartley, A., Miller, A., Marshuetz, C., & Koppe, R. A. (2000). Age differences in the frontal lateralization of verbal and spatial working memory revealed by PET. Journal of Cognitive Neuroscience, 12, 174–187.
Richardson, D. C., & Spivey, M. J. (2000). Representation, space and Hollywood Squares: Looking at things that aren’t there anymore. Cognition, 76, 269–295. doi:10.1016/S0010-0277(00)00084-6
Richardson, J. T. E. (2007). Measures of short-term memory: A historical review. Cortex, 43, 635–650. doi:10.1016/S0010-9452(08)70493-3
Schmidt, B. K., Vogel, E. K., Woodman, G. F., & Luck, S. J. (2002). Voluntary and automatic attentional control of visual working memory. Perception & Psychophysics, 64, 754–763. doi:10.3758/BF03194742
Shapiro, K. L., Arnell, K. M., & Raymond, J. E. (1997). The attentional blink. Trends in Cognitive Sciences, 1, 291–296. doi:10.1016/S1364-6613(97)01094-2
Shepherd, M., Findlay, J. M., & Hockey, R. J. (1986). The relationship between eye movements and spatial attention. Quarterly Journal of Experimental Psychology, 38A, 475–491.
Soto, D., Heinke, D., Humphreys, G. W., & Blanco, M. J. (2005). Early, involuntary top-down guidance of attention from working memory. Journal of Experimental Psychology: Human Perception and Performance, 31, 248–261. doi:10.1037/0096-1523.31.2.248
Straw, L. (2008). Vision egg: An open-source library for realtime visual stimulus generation. Frontiers in Neuroinformatics, 2, 4:1–10. doi:10.3389/neuro.11.004.2008
Stuyven, E., Van der Goten, K., Vandierendonck, A., Claeys, K., & Crevits, L. (2000). The effect of cognitive load on saccadic eye movements. Acta Psychologica, 104, 69–85. doi:10.1016/S0001-6918(99)00054-2
Theeuwes, J., Belopolsky, A., & Olivers, C. N. L. (2009). Interactions between working memory, attention and eye movements. Acta Psychologica, 132, 106–114. doi:10.1016/j.actpsy.2009.01.005
Theeuwes, J., Kramer, A. F., Hahn, S., & Irwin, D. E. (1998). Our eyes do not always go where we want them to go: Capture of the eyes by new objects. Psychological Science, 9, 379–385. doi:10.1111/1467-9280.00071
Theeuwes, J., Kramer, A. F., Hahn, S., Irwin, D. E., & Zelinsky, G. J. (1999). Influence of attentional capture on oculomotor control. Journal of Experimental Psychology: Human Perception and Performance, 25, 1595–1608. doi:10.1037/0096-1523.25.6.1595
Van der Stigchel, S., & Theeuwes, J. (2006). Our eyes deviate away from a location where a distractor is expected to appear. Experimental Brain Research, 169, 338–349.
Walker, R., Deubel, H., Schneider, W. X., & Findlay, J. M. (1997). Effect of remote distractors on saccade programming: evidence for an extended fixation zone. Journal of Neurophysiology, 78, 1108–1119.
Walker, R., Walker, D. G., Husain, M., & Kennard, C. (2000). Control of voluntary and reflexive saccades. Experimental Brain Research, 130, 540–544.
Woodman, G. F., & Luck, S. J. (2007). Do the contents of visual memory automatically influence attentional selection during visual search? Journal of Experimental Psychology: Human Perception and Performance, 33, 363–377. doi:10.1037/0096-1523.33.2.363
Woodman, G. F., Luck, S. J., & Schall, J. D. (2007). The role of working memory representations in the control of attention. Cerebral Cortex, 17(Suppl.), i118–i124. doi:10.1093/cercor/bhm065
Author Note
Elke B. Lange and Ralf Engbert, Experimental and Biological Psychology, University of Potsdam, Germany, Christian Starzynski, Department of Neurology, University of Heidelberg, Germany. We thank Petra Schienman for data collection. Correspondence concerning this article should be addressed to Elke.Lange@uni-potsdam.de.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(PDF 255 kb)
Rights and permissions
About this article
Cite this article
Lange, E.B., Starzynski, C. & Engbert, R. Capture of the gaze does not capture the mind. Atten Percept Psychophys 74, 1168–1182 (2012). https://doi.org/10.3758/s13414-012-0318-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-012-0318-8