
Abstract
Moral intuitions are a central motivator in human behavior. Recent work highlights the importance of moral intuitions for understanding a wide range of issues ranging from online radicalization to vaccine hesitancy. Extracting and analyzing moral content in messages, narratives, and other forms of public discourse is a critical step toward understanding how the psychological influence of moral judgments unfolds at a global scale. Extant approaches for extracting moral content are limited in their ability to capture the intuitive nature of moral sensibilities, constraining their usefulness for understanding and predicting human moral behavior. Here we introduce the extended Moral Foundations Dictionary (eMFD), a dictionary-based tool for extracting moral content from textual corpora. The eMFD, unlike previous methods, is constructed from text annotations generated by a large sample of human coders. We demonstrate that the eMFD outperforms existing approaches in a variety of domains. We anticipate that the eMFD will contribute to advance the study of moral intuitions and their influence on social, psychological, and communicative processes.
Similar content being viewed by others


Moral intuitions play an instrumental role in a variety of behaviors and decision-making processes, including group formation (Graham, Haidt, & Nosek, 2009); public opinion (Strimling, Vartanova, Jansson, & Eriksson, 2019); voting (Morgan, Skitka, & Wisneski, 2010); persuasion (Feinberg & Willer, 2013, 2015; Luttrell, Philipp-Muller, & Petty, 2019; Wolsko, Areceaga, & Seiden, 2016); selection, valuation, and production of media content (Tamborini & Weber, 2019; Tamborini, 2011); charitable donations (Hoover, Johnson, Boghrati, Graham, & Dehghani, 2018); message diffusion (Brady, Wills, Jost, Tucker, & Van Bavel, 2017); vaccination hesitancy (Amin et al., 2017); and violent protests (Mooijman, Hoover, Lin, Ji, & Dehghani, 2018). Given their motivational relevance, moral intuitions have often become salient frames in public discourse surrounding climate change (Jang and Hart, 2015; Wolsko et al., 2016), stem cell research (Clifford & Jerit, 2013), abortion (Sagi & Dehghani, 2014), and terrorism (Bowman, Lewis, & Tamborini, 2014). Moral frames also feature prominently within culture war debates (Haidt, 2012; Koleva, Graham, Haidt, Iyer, & Ditto, 2012), and are increasingly utilized as rhetorical devices to denounce other political camps (Gentzkow, 2016).
Recent work suggests that morally laden messages play an instrumental role in fomenting moral outrage online (Brady & Crockett, 2018; Brady, Gantman, & Van Bavel, in press; Crockett, 2017; but see Huskey et al., 2018) and that moral framing can exacerbate polarization in political opinions around the globe (e.g., Brady et al., 2017). A growing body of literature suggests that moral words have a unique influence on cognitive processing in individuals. For example, mounting evidence indicates that moral words are more likely to reach perceptual awareness than non-moral words, suggesting that moral cues are an important factor in guiding individuals’ attention (Brady, Gantman, & Van Bavel, 2019; Gantman & van Bavel, 2014, 2016).
Developing an understanding of the widespread social influence of morally relevant messages has been challenging due to the latent, deeply contextual nature of moral intuitions (Garten et al., 2016, 2018; Weber et al., 2018). Extant approaches for the computer-assisted extraction of moral content rely on lists of individual words compiled by small groups of researchers (Graham et al., 2009). More recent efforts expand these word lists using data-driven approaches (e.g., Frimer, Haidt, Graham, Dehghani, & Boghrati, 2017; Garten et al., 2016, 2018; Rezapour, Shah, & Diesner, 2019). Many moral judgments occur not deliberatively, but intuitively, better described as fast, gut-level reactions than slow, careful reflections (Haidt, 2001, 2007; Koenigs et al., 2007; but see May, 2018). As such, automated morality extraction procedures constructed by experts in a deliberative fashion are likely constrained in their ability to capture the words that guide humans’ intuitive judgment of what is morally relevant.
To address limitations in these previous approaches, we introduce the extended Moral Foundations Dictionary (eMFD), a tool for extracting morally relevant information from real-world messages. The eMFD is constructed from a crowd-sourced text-highlighting task (Weber et al., 2018), which allows for simple, spontaneous responses to moral information in text, combined with natural language processing techniques. By relying on crowd-sourced, context-laden annotations of text that trigger moral intuitions rather than on deliberations about isolated words from trained experts, the eMFD is able to outperform previous moral extraction approaches in a number of different validation tests and serves as a more flexible method for studying the social, psychological, and communicative effects of moral intuitions at scale.
In the following sections, we review previous approaches for extracting moral information from text, highlighting the theoretical and practical constraints of these procedures. We then discuss the methodological adjustments to these previous approaches that guide the construction of the eMFD and increase its utility for extracting moral information, focusing on the crowd-sourced annotation task and the textual scoring procedure that we used to generate the eMFD. Thereafter, we provide a collection of validations for the eMFD, subjecting it to a series of theory-driven validation analyses spanning multiple areas of human morality. We conclude with a discussion of the strengths and limitations of the eMFD and point towards novel avenues for its application.
Existing approaches for extracting moral intuitions from texts
The majority of research investigating moral content in text has relied on the pragmatic utility of Moral Foundations Theory (MFT; Haidt, 2007; Graham et al., 2012). MFT suggests that there are five innate, universal moral foundations that exist among individuals across cultures and societies: Care/harm (involving intuitions of sympathy, compassion, and nurturance), Fairness/cheating (including notions of rights and justice), Loyalty/betrayal (supporting moral obligations of patriotism and “us versus them” thinking), Authority/subversion (including concerns about traditions and maintaining social order), and Sanctity/degradation (including moral disgust and spiritual concerns related to the body).
Guided by MFT, dictionary-based approaches for extracting moral content aim to detect “the rate at which keywords [relating to moral foundations] appear in a text” (Grimmer & Stewart, 2013, p. 274). The first dictionary leveraging MFT was introduced by Graham et al. (2009). To construct this dictionary, researchers manually selected words from “thesauruses and conversations with colleagues” (Graham et al., 2009, p. 1039) that they believed best exemplified the upholding or violation of particular moral foundations. The resulting Moral Foundations Dictionary (MFD; Graham, & Haidt, 2012) was first utilized via the Linguistic Inquiry and Word Count software (LIWC; Pennebaker, Francis, & Booth, 2001) to detect differences in moral language usage among sermons of Unitarian and Baptist communities (Graham et al., 2009). The MFD has since been applied across numerous contexts (for an overview, see Supplemental Materials (SM), Table 1).
Although the MFD offers a straightforward wordcount-based method for automatically extracting moral information from text, several concerns have been raised regarding the theoretical validity, practical utility, and scope of the MFD (e.g., Weber et al., 2018; Garten et al., 2018; Sagi & Dehghani, 2014). These concerns can be grouped into three primary categories: First, the MFD is constructed from lists of moral words assembled deliberatively by a small group of experts (Graham et al., 2009), rendering its validity for understanding intuitive moral processes in the general population rather tenuous. Second, the MFD and its successors primarily rely on a “winner take all” strategy for assigning words to moral foundation categories. A particular word belongs only to one foundation (although some words are cross-listed). This constrains certain words’ utility for indicating and understanding the natural variation of moral information and its meaning across diverse contexts. Finally, these approaches treat documents simply as bags of words (BoW; Zhang, Jin, & Zhou, 2010), significantly limiting researchers’ ability to extract and understand the relational structure of moral acts (who, what, to whom, and why).
Experts versus crowds
Although traditional, expert-driven content analysis protocols have long been considered the gold standard, mounting evidence highlights their shortcomings and limitations (see, e.g., Arroyo & Welty, 2015). Most notably, these approaches make two assumptions that have recently been challenged: (1) that there is a “ground truth” as to the moral nature of a particular word, and (2) that “experts” are somehow more reliable or accurate in annotating textual data than are non-experts (Arroyo & Welty, 2015).
Evidence for rejecting both assumptions in the context of moral intuition extraction is plentiful (Weber et al., 2018). First, although moral foundations are universally present across cultures and societies, the relative importance of each of the foundations varies between individuals and groups, driven by socialization and environmental pressures (Graham et al., 2009, 2011; Van Leeuwen, Park, Koenig, & Graham, 2012). This is especially striking given salient concerns regarding the WEIRD (white, educated, industrialized, rich, and democratic) bias of social scientific research (Henrich, Heine, & Norenzayan, 2010). Hence, it is unlikely that there is one correct answer as to whether or not a word is moral, or as to which foundation category it belongs. In contrast, a word’s membership in a particular moral category for a given person is likely highly dependent on the person’s individual moral intuition salience, which is shaped by diverse cultural and social contexts—contexts that are unlikely to be captured by expert-generated word lists.
Concerning the second assumption, Weber et al. (2018) showed over a series of six annotation studies that extensive coder training and expert knowledge does not improve the reliability and validity of moral content codings in text. Instead, moral extraction techniques that treat moral foundations as originally conceptualized, that is, as the products of fast, spontaneous intuitions, lead to higher inter-rater agreement and higher validity than do slow, deliberate annotation procedures preceded by extensive training. Given these findings, it is clear that reliance on word lists constructed by a few experts to “ostensibly [capture] laypeople’s understandings of moral content” (Gray & Keeney, 2015, p. 875) risks tuning the extracted moral signal in text to the moral sensibilities of a few select individuals, thereby excluding broader and more diverse moral intuition systems.
In addition, several recent efforts have demonstrated that highly complex annotation tasks can be broken down into a series of small tasks that can be quickly and easily accomplished by a large number of minimally trained annotators (such as tracing neurons in the retinae of mice, e.g., the EyeWire project, Kim et al., 2014). Importantly, these crowd-sourced projects also demonstrate that any single annotation is not particularly useful. Rather, these annotations are only useful in the aggregate. Applying this logic to the complex task of annotating latent, contextualized moral intuitions in text, we argue that aggregated content annotations by a large crowd of coders reveal a more valid assessment of moral intuitions compared to the judgment of a few persons, even if these individuals are highly trained or knowledgeable (Haselmayer & Jenny, 2014, 2016; Lind, Gruber, & Boomgaarden, 2017). Accordingly, we contend that the detection and classification of latent, morally relevant information in text is a “community-wide and distributed enterprise” (Levy, 2006, p. 99), which, if executed by a large, heterogeneous crowd, is more likely to capture a reliable, inclusive, and thereby valid moral signal.
Data-driven approaches
Recent data-driven approaches have sought to ameliorate the limitations inherent in using small (< 500) word lists created manually by individual experts. These include (a) expanding the number of words in the wordcount dictionary by identifying other words that are semantically similar to the manually selected “moral” words (Frimer et al., 2017; Rezapour et al., 2019), and (b) abandoning simple wordcount-based scoring procedures and instead assessing the semantic similarity of entire documents to manually selected seed words (see, e.g., Araque, Gatti, & Kalimeri, 2019; Garten et al., 2018; 2019; Sagi & Dehghani, 2014). Although these approaches are promising due to their computational efficiency and ability to score especially short texts (e.g., social media posts), their usefulness is less clear for determining which textual stimuli evoke an intuitive moral response among individuals. An understanding of why certain messages are considered morally salient is critical for predicting behavior that results from processing moral information in human communication (Brady et al., in press). In addition, a reliance on semantic similarity to expert-generated words as a means of moral information extraction makes these approaches susceptible to the same assumptions underlying purely expert-generated dictionary approaches: If the manually generated seed words are not indicative of the moral salience of the population, then adding in the words that are semantically similar simply propagates these tenuous assumptions across a larger body of words.
Binary versus continuous word weighting
In light of humans’ varying moral intuition systems and the contextual embeddedness of language, words likely differ in their perceived association with particular moral foundations, in their moral prototypicality and moral relevance (e.g., Gray & Wegner, 2011), and in their valence. In the words of Garten et al. (2018): “A cold beer is good while a cold therapist is probably best avoided” (p. 345). However, previous dictionary-based approaches mostly assign words to moral categories in a discrete, binary fashion (although at times allowing words to be members of multiple foundations). This “winner take all” approach ignores individual differences in moral sensitivities and the contextual embeddedness of language, rendering this approach problematic in situations in which the moral status of a word is contingent upon its context. In view of this, the moral extraction procedure developed herein weights words according to their overall contextual embeddedness, rather than assigning it a context-independent, a priori foundation and valence. By transitioning from discrete, binary, and a priori word assignment towards a multi-foundation, probabilistic, and continuous word weighing, we show that a more ecologically valid moral signal can be extracted from text.
Yet, moral dictionaries are not only used for scoring textual documents (in which the contextual embedding of a word is of primary concern). Researchers may wish to utilize dictionaries to select moral words for use in behavioral tasks to interrogate cognitive components of moral processing (see Lexical Decision Tasks, e.g., Gantman & van Bavel, 2014, 2016) or to derive individual difference measures related to moral processing (see Moral Affect Misattribution Procedures, e.g., Tamborini, Lewis, Prabhu, Grizzard, Hahn, & Wang, 2016a; Tamborini, Prabhu, Lewis, Grizzard, & Eden, 2016b). In these experimental paradigms, words are typically chosen for their representativeness of a particular foundation in isolation rather than for their relationships to foundations across contextual variation. With these applications in mind, we also provide an alternative classification scheme for our dictionary that highlights words that are most indicative of particular foundations, which can then be applied to these sorts of tasks in a principled way.
Bag-of-words versus syntactic dependency parsing
Moral judgments—specifically those concerned with moral violations—are frequently made with reference to dyads or groups of moral actors, their intentions, and the targets of their actions (Gray, Waytz, & Young, 2012; Gray & Wegner, 2011). The majority of previous moral extraction procedures have relied on bag-of-words (BoW) models. These models discard any information about how words in a text syntactically relate to each other, instead treating each word as a discrete unit in isolation from all others. In this sense, just as previous approaches discard the relationship between a word and its geographic neighbors, they also discard the relationship between a word and its syntactic neighbors. Accordingly, BoW models are incapable of parsing the syntactic dependencies that may be relevant for understanding morally relevant information, such as in linking moral attributes and behaviors to their respective moral actors.
A growing body of work shows that humans’ stereotypical cognitive templates of moral agents and targets are shaped by their exposure to morally laden messages (see, e.g., Eden et al., 2014). Additional outcomes of this moral typecasting suggest that the more particular entities are perceived as moral agents, the less they are seen to be targets of moral actions, and vice versa (Gray & Wegner, 2009). Given these findings, it is clear that moral extraction methods that can discern moral agent–target dyads would be a boon for understanding how moral messages motivate social evaluations and behaviors. The moral intuition extraction introduced herein incorporates techniques from syntactic dependency parsing (SDP) in order to extract agents and targets from text, annotating them with relevant moral words as they appear in conjunction with one another. Accordingly, SDP can not only detect who is committing a morally relevant action, but also identify towards whom this behavior is directed.
A case for crowd-sourced moral foundation dictionaries
In light of these considerations and the remaining limitations of extant quantitative models of human morality, we present herein the extended Moral Foundations Dictionary (eMFD), a tool that captures large-scale, intuitive judgments of morally relevant information in text messages. The eMFD ameliorates the shortcomings of previous approaches in three primary ways. First, rather than relying on deliberate and context-free word selection by a few domain experts, we generated moral words from a large set of annotations from an extensively validated, crowd-sourced annotation task (Weber et al., 2018) designed to capture the intuitive judgment of morally relevant content cues across a crowd of annotators. Second, rather than being assigned to discrete categories, words in the eMFD are assigned continuously weighted vectors that capture probabilities of a word belonging to any of the five moral foundations. By doing so, the eMFD provides information on how our crowd-annotators judged the prototypicality of a particular word for any of the five moral foundations. Finally, the eMFD provides basic syntactic dependency parsing, enabling researchers to investigate how moral words within a text are syntactically related to one another and to other entities. The eMFD is released along with eMFDscore,Footnote 1 an open-source, easy-to-use, yet powerful and flexible Python library for preprocessing and analyzing textual documents with the eMFD.
Method
Data, materials, and online resources
The dictionary, code, and analyses of this study are made available under a dedicated GitHub repository.Footnote 2 Likewise, data, supplemental materials, code scripts, and the eMFD in comma-separated value (CSV) format are available on the Open Science Framework.Footnote 3 In the supplemental material (SM), we report additional information on annotations, coders, dictionary statistics, and analysis results.
Crowd-sourced annotation procedure
The annotation procedure used to create the eMFD relies on a web-based, hybrid content annotation platform developed by the authors (see the Moral Narrative Analyzer; MoNA: https://mnl.ucsb.edu/mona/). This system was designed to capture textual annotations and annotator characteristics that have been shown to be predictive of inter-coder reliability in annotating moral information (e.g., moral intuition salience, political orientation). Furthermore, the platform standardizes annotation training and annotation procedures to minimize inconsistencies.
Annotators, training, and highlight procedure
A crowd of 854 annotators was drawn from the general United States population using the crowd-sourcing platform Prolific Academic (PA; https://www.prolific.ac/). Recent evidence indicates that PA’s participant pool is more naïve to research protocols and produces higher-quality annotations compared to alternative platforms such as Amazon’s Mechanical Turk or CrowdFlower (Peer, Brandimarte, Samat, & Acquisti, 2017). Sampling was designed to match annotator characteristics to the US general population in terms of political affiliation and gender, thereby lowering the likelihood of obtaining annotations that reflect the moral intuitions of only a small, homogeneous group (further information on annotators is provided in Section 2 of the SM). Because our annotator sample was slightly skewed to the left in terms of political orientation, we conducted a sensitivity analysis (see SM Section 3) that yielded no significant differences in produced annotations. Each annotator was tasked with annotating fifteen randomly selected news documents from a collection of 2995 articles (see text material below). Moreover, each annotator evaluated five additional documents that were seen by every other annotator.Footnote 4 Five hundred and fifty-seven annotators completed all assigned annotation tasks.
Each annotator underwent an online training explaining the purpose of the study, the basic tenets of MFT, and the annotation procedure (a detailed explanation of the training and annotation task is provided in Section 4 of the SM). Annotators were instructed that they would be annotating news articles, and that for each article they would be (randomly) assigned one of the five moral foundations. Next, using a digital highlighting tool, annotators were instructed to highlight portions of text that they understood to reflect their assigned moral foundation. Upon completing the training procedure, annotators were directed to the annotation interface where they annotated articles one at a time. In previous work, Weber et al. (2018) showed that this annotation model is simplest for users, minimizing training time and time per annotation while emphasizing the intuitive nature of moral judgments, ultimately yielding highest inter-coder reliability.
Text material
A large corpus of news articles was chosen for human annotation. News articles have been shown to contain latent moral cues, discuss a diverse range of topics, and contain enough words to allow for the meaningful annotation of longer word sequences compared to shorter text documents such as tweets (e.g., Bowman et al., 2014; Clifford & Jerit, 2013; Sagi & Dehghani, 2014; Weber et al., 2018). The selected corpus consisted of online newspaper articles drawn between November 2016 and January 2017 from The Washington Post, Reuters, The Huffington Post, The New York Times, Fox News, The Washington Times, CNN, Breitbart, USA Today, and Time.
We utilized the Global Database of Events, Language, and Tone (GDELT; Leetaru and Schrodt, 2013a, b) to acquire Uniform Resource Locators (URLs) of articles from our chosen sources with at least 500 words (for an accessible introduction to GDELT, see Hopp, Schaffer, Fisher, and Weber, 2019b). Various computationally derived metadata measures were also acquired, including the topics discussed in the article. GDELT draws on an extensive list of keywords and subject-verb-object constellations to extract news topics of, for example, climate change, terrorism, social movements, protests, and many others.Footnote 5 Several topics were recorded for subsequent validation analyses (see below). In addition, GDELT provides word frequency scores for each moral foundation as indexed using the original MFD. To increase the moral signal contained in the annotation corpus, articles were excluded from the annotation set if they did not include any words contained in the original MFD. Headlines and article text from those URLs were scraped using a purpose-built Python script, yielding a total of 8276 articles. After applying a combination of text-quality heuristics (e.g., evaluating article publication date, headline and story format, etc.) and random sampling, 2995 articles were selected for annotation. Of these, 1010 articles were annotated by at least one annotator. The remaining 1985 articles were held out for subsequent, out-of-sample validations.
Dictionary construction pipeline
Annotation preprocessing
In total, 63,958 raw annotations (i.e., textual highlights) were produced by the 557 annotators. The content of each of these annotations was extracted along with the moral foundation with which it was highlighted. Annotations were only extracted from documents that were seen by at least two annotators from two different foundations. Here, the rationale was to increase the probability that a given word sequence would be annotated—or not annotated—with a certain moral foundation. Most of the documents were annotated by at least seven annotators who were assigned at least four different moral foundations (see Section 5 of the SM for further descriptives). Furthermore, annotations from the five documents seen by every annotator were also excluded, ensuring that annotations were not biased towards the moral content identified in these five documents. In order to ensure that annotators spent a reasonable time annotating each article, we only considered annotations from annotators that spent at least 45 minutes using the coding platform (a standard cutoff in past research; see Weber et al., 2018). Finally, only annotations that contained a minimum of three words were considered.
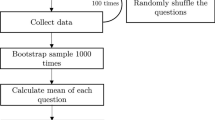
Each annotation was subjected to the following preprocessing steps: (1) tokenization (i.e., splitting annotations into single words), (2) lowercasing all words, (3) removing stop-words (i.e., words without semantic meaning such as “the”), (4) part-of-speech (POS) tagging (i.e., determining whether a token is a noun, verb, number, etc.), and (5) removing any tokens that contained numbers, punctuation, or entities (i.e., persons, organizations, nations, etc.). This filtering resulted in a total set of 991 documents (excluding a total of 19 documents) that were annotated by 510 annotators (excluding 47 annotators), spanning 36,011 preprocessed annotations (excluding 27,947 annotations) that comprised a total of 220,979 words (15,953 unique words). For a high-level overview of the dictionary development pipeline, see Fig. 1.

Development pipeline of the extended Moral Foundations Dictionary. Note. There were seven main steps involved in dictionary construction: (a) First, a large crowd of annotators highlighted content related to the five moral foundations in over 1000 news articles. Each annotator was assigned one foundation per article. (b) These annotations were extracted and categorized based on the foundation with which they were highlighted. (c) Annotations were minimally preprocessed (tokenization, stop word removal, lowercasing, entity recognition, etc.). (d) Preprocessed tokens from each article and each foundation were extracted and stored in a data frame. (e) Foundation probabilities (weights in the eMFD) were calculated by dividing the number of times the word was highlighted with a particular foundation by the number of times that word was seen by an annotator assigned that particular foundation. Words were also assigned VADER sentiment scores, which served as vice/virtue weighting per foundation. (f) The resulting data frame was filtered to remove words that were not highlighted with a particular foundation at least five times and words that were not seen by an annotator at least 10 times. (g) Finally, words were combined into the final dictionary of 3270 words. In this dictionary, each word is assigned a vector with 10 entries (weight and valence for each of the five foundations)
Moral foundation scoring
The aim of the word scoring procedure was to create a dictionary in which each word is assigned a vector of five values (one for each moral foundation). Each of these values ranged from 0 to 1, denoting the probability that a particular word was annotated with a particular moral foundation. To derive these foundation probabilities, we counted the number of times a word was highlighted with a certain foundation and divided this number by the number of times this word was seen by annotators that were assigned this foundation. For example, if the word kill appeared in 400 care–harm annotations and was seen a total of 500 times by annotators assigned the care–harm foundation, then the care–harm entry in the vector assigned to the word kill would be 0.8. This scoring procedure was applied across all words and all moral foundations.
To increase the reliability and moral signal of our dictionary, we applied two filtering steps at the word level. First, we only kept words in the dictionary that appeared in at least five highlights with any one moral foundation. Second, we filtered out words that were not seen at least 10 times within each assigned foundation. We chose these thresholds to maintain a dictionary with appropriate reliability, size, and discrimination across moral foundations (outcomes of other thresholds are provided in Section 6 of the SM). This resulted in a final dictionary with 3270 words.
Vice–virtue scoring
In previous MFDs, each word in the dictionary was placed into a moral foundation virtue or vice category. Words in virtue categories usually describe morally righteous actions, whereas words in vice categories typically are associated with moral violations. In the eMFD we utilized a continuous scoring approach that captures the overall valence of the context within which the word appeared rather than assigning a word to a binary vice or virtue category. To compute the valence of each word, we utilized the Valence Aware Dictionary and sEntiment Reasoner (VADER; Hutto & Gilbert, 2014). For each annotation, a composite valence score—ranging from −1 (most negative) to +1 (most positive)—was computed, denoting the overall sentiment of the annotation. For each word in our dictionary, we obtained the average sentiment score of the annotations in which the word appeared in a foundation-specific fashion. This process resulted in a vector of five sentiment values per word (one per moral foundation). As such, each entry in the sentiment vector denotes the average sentiment of the annotations in which the word appeared for that foundation. This step completes the construction of the extended Moral Foundations Dictionary (eMFD; see Section 7 of the SM for further dictionary descriptives and Section 8 for comparisons of the eMFD to previous MFDs).
Document scoring algorithms
To facilitate the fast and flexible extraction of moral information from text, we developed eMFDscore, an easy-to-use, open-source Python library. eMFDscore lets users score textual documents using the eMFD, the original MFD (Graham et al., 2009), and the MFD2.0 (Frimer et al., 2017). In addition, eMFDscore employs two scoring algorithms depending on the task at hand. The BoW algorithm first preprocesses each textual document by applying tokenization, stop-word removal, and lowercasing. Next, the algorithm compares each word in the article against the specified dictionary for document scoring. When scoring with the eMFD, every time a word match occurs, the algorithm retrieves and stores the five foundation probabilities and the five foundation sentiment scores for that word, resulting in a 10-item vector for each word. After scoring a document, these vectors are averaged, resulting in one 10-item vector per document. When scoring documents with the MFD or MFD2.0, every time a word match occurs, the respective foundation score for that word is increased by 1. After scoring a document, these sums are again averaged.
The second scoring algorithm implemented in eMFDscore relies on syntactic dependency parsing (SDP). This algorithm starts by extracting the syntactical dependencies among words in a sentence, for instance, to determine subject-verb-object constellations. In addition, by combining SDP with named entity recognition (NER), eMFDscore extracts the moral words for which an entity was declared to be either the agent/actor or the patient/target. For example, in the sentence, The United States condemned North Korea for further missile tests, the United States is the agent for the word condemned, whereas North Korea is the target for the word condemned. Furthermore, rather than extracting all words that link to agent–patient dyads, only moral words are retrieved that are part of the eMFD. eMFDscore’s algorithm iterates over each sentence of any given textual input document to extract entities along with their moral agent and moral target identifiers. Subsequently, the average foundation probabilities and average foundation sentiment scores for the detected agent and target words are computed. In turn, these scores can be utilized to assess whether an entity engages in actions that primarily uphold or violate certain moral conduct and, likewise, whether an entity is the target of primarily moral or immoral actions.
Context-dependent versus context-independent dictionaries
In addition to the continuously weighted eMFD, we also provide a version of the eMFD that is tailored for use within behavioral tasks and experimental paradigms.Footnote 6 In this version, each word was assigned to the moral foundation that had the highest foundation probability. We again used VADER to compute the overall positive–negative sentiment of each single word. Words with an overall negative sentiment were placed into the vice category for that foundation, whereas words with an overall positive sentiment were placed into the virtue category for that foundation. Words that could not be assigned a virtue or vice category (i.e., words with neutral sentiment) were dropped, resulting in a dictionary with 689 moral words. Figure 2 illustrates the most highly weighted words per foundation in this context-independent eMFD.

Word clouds showing words with highest foundation probability. Note. Larger words received a higher probability within this foundation
Validations and applications of the eMFD
We conducted several theory-driven analyses to subject the eMFD to different standards of validity (Grimmer & Steward, 2013). These validation analyses are based on an independent set of 1985 online newspaper articles that were withheld from the eMFD annotation task. Previous applications of moral dictionaries have focused primarily on grouping textual documents into moral foundations (Graham et al., 2009), detecting partisan differences in news coverage (Fulgoni et al., 2016), or examining the moral framing of particular topics (Clifford & Jerit, 2013). With these applications in mind, we first contrast distributions of computed moral word scores across the eMFD, the original MFD (Graham et al., 2009), and the MFD2.0 (Frimer et al., 2017) to assess the basic statistical properties of these dictionaries for distinguishing moral foundations across textual documents. Second, we contrast how well each dictionary captures moral framing across partisan news outlets. Third, we triangulate the construct validity of the eMFD by correlating its computed word scores with the presence of particular, morally relevant topics in news articles. Finally, we use the eMFD to predict article sharing, a morally relevant behavioral outcome, showing that the eMFD predicts share counts more accurately than the MFD or MFD2.0.
Word score distributions
To assess the basic statistical properties of the eMFD and previous MFDs, we contrasted the distribution of computed word scores across MFDs (see Fig. 3). Notably, word scores computed by the eMFD largely follow normal distributions across foundations, whereas word scores indexed by the MFD and MFD2.0 tend to be right-skewed.

Box-swarm plots of word scores across Moral Foundations Dictionaries
This is likely due to the binary word count approach of the MFD and MFD2.0, producing negative binomial distributions typical for count data. In contrast, the probabilistic, multi-foundation word scoring of the eMFD appears to capture a more multidimensional moral signal as illustrated by the largely normal distribution of word scores. In addition, when comparing the mean word scores across foundations and dictionaries, the mean moral word scores retrieved by the eMFD are higher than the mean moral word scores of previous MFDs.
Next, we tested whether this result is merely due to the eMFD’s larger size (leading to an increased detection rate of words that are not necessarily moral). To semantically triangulate the eMFD word scores, we first correlated the word scores computed by the eMFD with word scores computed by the MFD and MFD2.0. We find that the strongest correlations appear between equal moral foundations across dictionaries: For example, correlations between the eMFD’s foundations and the MFD2.0’s foundations for care (care.virtue, r = 0.24; care.vice, r = 0.62), fairness (fairness.virtue, r = 0.43; fairness.vice, r = 0.35), loyalty (loyalty.virtue, r = 0.29; loyalty.vice, r = 0.16), authority (authority.virtue, r = 0.46; authority.vice, r = 0.34), and sanctity (sanctity.virtue, r = 0.27; sanctity.vice, r = 0.32) suggest that the eMFD is sharing moral signal extracted by previous MFDs (see SM Section 9.1 for further comparisons).
Partisan news framing
Previous studies have shown that conservatives tend to place greater emphasis on the binding moral foundations including loyalty, authority, and sanctity, whereas liberals are more likely to endorse the individualizing moral foundations of care and fairness (Graham et al., 2009). To test whether the eMFD can capture such differences within news coverage, we contrasted the computed eMFD word scores across Breitbart (far-right), The New York Times (center-left) and The Huffington Post (far-left). As Fig. 4 illustrates, Breitbart emphasizes the loyalty and authority foundations more strongly, while The Huffington Post places greater emphasis on the care and fairness foundations. Likewise, The New York Times appears to adopt a more balanced coverage across foundations. While the MFD and MFD2.0 yield similar patterns, the distinction across partisan news framing is most salient for the eMFD. Hence, in addition to supporting previous research (Graham et al., 2009; Fulgoni et al., 2016), this serves as further evidence that the eMFD is not biased towards a political orientation, but can detect meaningful moral signal across the political spectrum.

Boxplots of word scores across partisan news sources
Note. Vice/virtue scores for MFD and MFD2.0 were summed
Moral foundations across news topics
Next, we examined how word scores obtained using the eMFD correlate with the presence of various topics in each news article. To obtain article topics, we rely on news article metadata provided by GDELT (Leetaru and Schrodt, 2013a, b). For the purpose of this analysis, we focus on 12 morally relevant topics (see SM Section 9.2 for topic descriptions). These include, among others, discussions of armed conflict, terror, rebellions, and protests. Figure 5 illustrates the corresponding heatmap of correlations between eMFD’s computed word scores and GDELT’s identified news topics (heatmaps for MFD and MFD2.0 are provided in Section 9.3 of the SM). Word scores from the eMFD were correlated with semantically related topics. For example, news articles that discuss topics related to care and harm are positively correlated with mentions of words that have higher Care weights (Kill, r = 0.36, n = 815; Wound, r = 0.28, n = 169; Terror, r = 0.26, n = 480; all correlations p < .000). Importantly, observed differences in foundation–topic correlations align with the association intensity of words across particular foundations. For instance, the word killing has a greater association intensity with care–harm than wounding, and hence the correlation between Care and Kill is stronger than the correlation between Care and Wound. Likewise, articles discussing Terror pertain to the presence of other moral foundations, as reflected by the correlation with authority (r = 0.31, n = 480, p < .000) and loyalty (r = 0.29, n = 480, p < .000). In contrast, the binary scoring logic of the MFD and MFD2.0 attribute similar weights to acts of varying moral relevance. For example, previous MFDs show largely similar correlations between the care.vice foundation and the topics of Killing (MFD, r = 0.37, n = 815, p < .000; MFD2.0, r = 0.37, n = 815, p < .000) and Wounding (MFD, r = 0.4, n = 169, p < .000; MFD2.0, r = 0.39, n = 815, p < .000), suggesting that these MFDs are less capable of distinguishing between acts of varying moral relevance and valence. Other noteworthy correlations between eMFD word scores and news topics include the relationship between Fairness and discussions of Legislation (r = 0.33, n = 859, p < .000) and Free Speech (r = 0.12, n = 62, p < .000), Authority and mentions of Protests (r = 0.24, n = 436, p < .000) and Rebellion (r = 0.16, n = 126, p < .000), and the correlations between Loyalty and Religion (r = 0.18, n = 210, p < .000) and Sanctity and Religion (r = 0.20, n = 210, p < .000).

Correlation matrix showing eMFD word scores converge with news article topics
Prediction of news article engagement
Moral cues in news articles and tweets positively predict sharing behavior (Brady et al., 2017, 2019, in press). As such, dictionaries that more accurately extract moral “signal” should more accurately predict share counts of morally loaded articles. As a next validation step, we tested how accurately the eMFD predicts social media share counts of news articles compared to previous MFDs. To obtain the number of times a given news article in the validation set was shared on social media, we utilized the sharedcount.com API, which queries share counts of news article URLs directly from Facebook.
To avoid bias resulting from the power-law distribution of the news article share counts, we excluded articles that did not receive a single share and also excluded the top 10% most shared articles. This resulted in a total of 1607 news articles in the validation set. We also log-transformed the share count variable to produce more normally distributed share counts (see Section 9.5 of the SM for comparisons). Next, we computed multiple linear regressions in which the word scores of the eMFD, the MFD, and the MFD2.0 were utilized as predictors and the log-transformed share counts as outcome variables. As hypothesized, the eMFD led to a fourfold increase in explained variance of share counts (R2adj = 0.029, F(10, 1596) = 5.85, p < .001) compared to the MFD (R2adj = 0.008, F(10, 1569) = 2.27, p = 0.012) and MFD2.0 (R2ad j = 0.007, F(10, 1569) = 2.07, p = 0.024)Footnote 7. Interestingly, the sanctity foundation of the eMFD appears to be an especially strong predictor of share counts (β = 30.59, t = 3.73, p < .001). Upon further qualitative inspection, words with a high sanctity probability in the eMFD relate to sexual violence, racism, and exploitation. One can assume that these topics are likely to elicit moral outrage (Brady & Crockett, 2018; Crockett, 2017), which in turn may motivate audiences to share these messages more than other messages.
Moral agent and target extraction
The majority of moral acts involve an entity engaging in the moral or immoral act (a moral agent), and an entity serving as the target of the moral or immoral behavior (a moral target; Gray & Wegner, 2009). In a final validation analysis, we demonstrate the capability of eMFDscore for extracting morally relevant agent–target relationships. As an example, Fig. 6 illustrates the moral actions of the agent Donald J. Trump (current president of the United States) as well as the moral words wherein Trump is the target. The most frequent moral words associated with Trump as an agent are promised, vowed, threatened, and pledged. Likewise, moral words associated with Trump as a target are voted and support, but also words like criticized, opposed, attacked, or accused. These results serve as a proof of principle demonstrating the usefulness of the eMFD for extracting agent/target information alongside morally relevant words.

Moral agent and moral target networks for Donald J. Trump. Note. The left network depicts the moral words for which Trump was identified as an actor. The right network depicts moral words for which Trump was identified as a target. Larger word size and edge weight indicate a more frequent co-occurrence of that word with Trump. Only words that have a foundation probability of at least 15% in any one foundation are displayed
Discussion
Moral intuitions are important in a wide array of behaviors and have become permanent features of civil discourse (Bowman et al., 2014; Brady et al., 2017; Crockett, 2017; Huskey et al., 2018), political influence (Feinberg, & Willer, 2013, 2015; Luttrell et al., 2019), climate communication (Feinberg, & Willer, 2013; Jang and Hart, 2015), and many other facets of public life. Hence, extracting moral intuitions is critical for developing an understanding of how human moral behavior and communication unfolds at both small and large scales. This is particularly true given recent calls to examine morality in more naturalistic and real-world contexts (Schein, 2020). Previous dictionary-based work in this area relied on manually compiled and data-driven word lists. In contrast, the eMFD is based on a crowd-sourced annotation procedure.
Words in the eMFD were selected in accordance with an intuitive annotation task rather than by relying on deliberate, rule-based word selection. This increased the ecological validity and practical applicability of the moral signal captured by the eMFD. Second, word annotations were produced by a large, heterogeneous crowd of human annotators as opposed to a few trained undergraduate students or “experts” (see Garten et al., 2016, 2018; Mooijman et al., 2018, but see Frimer et al., 2017). Third, words in the eMFD are weighted according to a probabilistic, context-aware, multi-foundation scoring procedure rather than a discrete weighting scheme assigning a word to only one foundation category. Fourth, by releasing the eMFD embedded within the open-sourced, standardized preprocessing and analysis eMFDscore Python package, this project facilitates greater openness and collaboration without reliance on proprietary software or extensive training in natural language processing techniques. In addition, eMFDscore’s morality extraction algorithms are highly flexible, allowing researchers to score textual documents with traditional BoW models, but also with syntactic dependency parsing, enabling the investigation of moral agent/target relationships.
In a series of theoretically informed dictionary validation procedures, we demonstrated the eMFD’s increased utility compared to previous moral dictionaries. First, we showed that the eMFD more accurately predicts the presence of morally relevant article topics compared to previous dictionaries. Second, we showed that the eMFD more effectively detects distinctions between the moral language used by partisan news organizations. Word scores returned by the eMFD confirm that conservative sources place greater emphasis on the binding moral foundations of loyalty, authority, and sanctity, whereas more liberal-leaning sources tend to stress the individualizing foundations of care and fairness, supporting previous research on moral partisan news framing (Fulgoni et al., 2016). Third, we demonstrated that the eMFD more accurately predicts the share counts of morally loaded online newspaper articles. The eMFD produced a better model fit and explained more variance in overall share counts compared to previous approaches. Finally, we demonstrated eMFDscore’s utility for linking moral actions to their respective moral agents and targets.
Limitations and future directions
While the eMFD has many advantages over extant moral extraction procedures, it offers no panacea for moral text mining. First, the eMFD was constructed from human annotations of news articles. As such, it may be less useful for annotating corpora that are far afield in content or structure from news articles. While in previously conducted analyses, we found that the eMFD generalizes well to non-fictional texts such as song lyrics (Hopp, Barel et al., 2019a) or movie scripts (Hopp, Fisher, & Weber, 2020), future research is needed to validate the eMFD’s generalizability across other text domains. We currently plan to advance the eMFD further by complementing it with word scores obtained from annotating other corpora, such as tweets or short stories. Moreover, preliminary evidence suggests the utility of the eMFD for sampling words as experimental stimuli in word rating tasks, including affect misattribution (AMP) and lexical decision task (LDT) procedures (Fisher, Hopp, Prabhu, Tamborini, & Weber, 2019).
In addition, the eMFD—like any wordcount-based dictionary—should be used with caution when scoring especially short text passages (e.g., headlines or tweets), as there is a smaller likelihood of detecting morally relevant words in short messages (but see Brady et al., 2017). Researchers wishing to score shorter messages should consult methods such as those that rely on word embedding. These approaches capitalize on semantic similarities between words to enable scoring of shorter messages that may contain no words that are “moral” at face value (see, e.g., Garten et al., 2018). Furthermore, future work should expand upon our validation analyses and correlate eMFD word scores with other theoretically relevant content and behavioral outcome metrics. Moreover, while our comparisons of news sources revealed only slight differences in partisan moral framing across various moral foundation dictionaries, future studies may analyze op-ed essays in left- and right-leaning newspapers. These op-ed pieces likely contain a richer moral signal and thus may prove more promising to reveal tilts in moral language usage between more conservative and more liberal sources. Likewise, future studies may sample articles from sources emphasizing solidly conservative values (e.g., National Review) and solidly progressive values (e.g., The New Republic).
In addition, future research is needed to scrutinize the scientific utility of the eMFD’s agent–target extraction capabilities. The examination of mediated associations (Arendt & Karadas, 2017) between entities and their moral actions may be a promising starting point here. Likewise, experimental studies may reveal similarities and differences between individuals’ cognitive representation of moral agent–target dyads and their corresponding portrayal in news messages (Scheufele, 2000).
Conclusion
The computational extraction of latent moral information from textual corpora remains a critical but challenging task for psychology, communication, and related fields. In this manuscript, we introduced the extended Moral Foundations Dictionary (eMFD), a new dictionary built from annotations of moral content by a large, diverse crowd. Rather than assigning items to strict categories, this dictionary leverages a vector-based approach wherein words are assigned weights based on their representativeness of particular moral categories. We demonstrated that this dictionary outperforms existing approaches in predicting news article topics, highlighting differences in moral language between liberal and conservative sources, and predicting how often a particular news article would be shared. We have packaged this dictionary, along with tools for minimally preprocessing textual data and parsing semantic dependencies, in an open-source Python library called eMFDScore. We anticipate this dictionary and its associated preprocessing and analysis library to be useful for analyzing large textual corpora and for selecting words to present in experimental investigations of moral information processing.
Open Practices Statement
The dictionary, code, and analyses of this study are made available under a dedicated GitHub repository (https://github.com/medianeuroscience/emfd). Likewise, data, supplemental materials, code scripts, and the eMFD in comma-separated value (CSV) format are available on the Open Science Framework (https://osf.io/vw85e/). In the supplemental material (SM), we report additional information on annotations, coders, dictionary statistics, and analysis results. None of the analyses reported herein was preregistered.
Notes
This set of articles was utilized for separate analyses that are not reported here.
Full model specifications are provided in SM Section 9.4
References
Amin, A. B., Bednarczyk, R. A., Ray, C. E., Melchiori, K. J., Graham, J., Huntsinger, J. R., & Omer, S. B. (2017). Association of moral values with vaccine hesitancy. Nature Human Behaviour, 1(12), 873–880.
Araque, O., Gatti, L., & Kalimeri, K. (2019). MoralStrength: Exploiting a moral lexicon and embedding similarity for moral foundations prediction. arXiv preprint arXiv:1904.08314.
Arendt, F., & Karadas, N. (2017). Content analysis of mediated associations: An automated text-analytic approach. Communication Methods and Measures, 11(2), 105-120.
Aroyo, L., & Welty, C. (2015). Truth is a lie: Crowd truth and the seven myths of human annotation. AI Magazine, 36(1), 15–24.
Bowman, N., Lewis, R. J., & Tamborini, R. (2014). The morality of May 2, 2011: A content analysis of US headlines regarding the death of Osama bin Laden. Mass Communication and Society, 17(5), 639–664.
Brady, W. J., & Crockett, M. J. (2018). How effective is online outrage? Trends in Cognitive Sciences, 23(2), 79–80.
Brady, W. J., Wills, J. A., Jost, J. T., Tucker, J. A., & Van Bavel, J. J. (2017). Emotion shapes the diffusion of moralized content in social networks. Proceedings of the National Academy of Sciences, 114(28), 7313–7318.
Brady, W. J., Gantman, A. P., & Van Bavel, J.J. (2019). Attentional capture helps explain why moral and emotional content go viral. Journal of Experimental Psychology: General.
Brady, W. J., Crockett, M., & Van Bavel, J. J. (in press). The MAD model of moral contagion: The role of motivation, attention and design in the spread of moralized content online. Perspectives on Psychological Science
Clifford, S., & Jerit, J. (2013). How words do the work of politics: Moral foundations theory and the debate over stem cell research. The Journal of Politics, 75(3), 659–671.
Crockett, M. J. (2017). Moral outrage in the digital age. Nature Human Behaviour, 1(11), 769–771.
Eden, A., Tamborini, R., Grizzard, M., Lewis, R., Weber, R., & Prabhu, S. (2014). Repeated exposure to narrative entertainment and the salience of moral intuitions. Journal of Communication, 64(3), 501–520.
Feinberg, M., & Willer, R. (2013). The moral roots of environmental attitudes. Psychological Science, 24(1), 56–62.
Feinberg, M., & Willer, R. (2015). From gulf to bridge: When do moral arguments facilitate political influence?. Personality and Social Psychology Bulletin, 41(12), 1665–1681.
Fisher, J.T., Hopp, F.R., Prabhu, S., Tamborini, R., & Weber, R. (2019). Developing best practices for the implicit measurement of moral foundation salience. Paper accepted at the 105th annual meeting of the National Communication Association (NCA), Baltimore, MD.
Frimer, J., Haidt, J., Graham, J., Dehghani, M., & Boghrati, R. (2017). Moral foundations dictionaries for linguistic analyses, 2.0. Unpublished Manuscript. Retrieved from: www.jeremyfrimer.com/uploads/2/1/2/7/21278832/summary.pdf
Fulgoni, D., Carpenter, J., Ungar, L. H., & Preotiuc-Pietro, D. (2016). An empirical exploration of moral foundations theory in partisan news sources. Proceedings of the Tenth International Conference on Language Resources and Evaluation.
Gantman, A. P., & Van Bavel, J. J. (2014). The moral pop-out effect: Enhanced perceptual awareness of morally relevant stimuli. Cognition, 132(1), 22–29.
Gantman, A. P., & Van Bavel, J. J. (2016). See for yourself: Perception is attuned to morality. Trends in Cognitive Sciences, 20(2), 76–77.
Garten, J., Boghrati, R., Hoover, J., Johnson, K. M., & Dehghani, M. (2016). Morality between the lines: Detecting moral sentiment in text. Proceedings of IJCAI 2016 workshop on Computational Modeling of Attitudes, New York, NY. Retrieved from: http://www.morteza-dehghani.net/wp-content/uploads/morality-lines-detecting.pdf
Garten, J., Hoover, J., Johnson, K. M., Boghrati, R., Iskiwitch, C., & Dehghani, M. (2018). Dictionaries and distributions: Combining expert knowledge and large scale textual data content analysis. Behavior Research Methods, 50(1), 344–361.
Gentzkow, M. (2016). Polarization in 2016. Toulouse Network of Information Technology Whitepaper
Graham, J., & Haidt, J. (2012). The moral foundations dictionary. Available at: http://moralfoundations.org
Graham, J., Haidt, J., & Nosek, B. A. (2009). Liberals and conservatives rely on different sets of moral foundations. Journal of Personality and Social Psychology, 96, 1029–1046.
Graham, J., Nosek, B. A., Haidt, J., Iyer, R., Koleva, S., & Ditto, P. H. (2011). Mapping the moral domain. Journal of Personality and Social Psychology, 101(2), 366–385.
Graham, J., Haidt, J., Koleva, S., Motyl, M., Iyer, R., Wojcik, S., & Ditto, P. H. (2012). Moral foundations theory: The pragmatic validity of moral pluralism. Advances in Experimental Social Psychology, 47, 55–130.
Gray, K., & Keeney, J. E. (2015). Disconfirming moral foundations theory on its own terms: Reply to Graham (2015). Social Psychological and Personality Science, 6(8), 874–877.
Gray, K., & Wegner, D. M. (2009). Moral typecasting: Divergent perceptions of moral agents and moral patients. Journal of Personality and Social Psychology, 96(3), 505–520.
Gray, K., & Wegner, D. M. (2011). Dimensions of moral emotions. Emotion Review, 3(3), 258–260.
Gray, K., Waytz, A., & Young, L. (2012). The moral dyad: A fundamental template unifying moral judgment. Psychological Inquiry, 23(2), 206–215.
Grimmer, J., & Stewart, B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21(3), 267–297.
Haidt, J. (2001). The emotional dog and its rational tail: A social intuitionist approach to moral judgment. Psychological Review, 108(4), 814–834.
Haidt, J. (2007). The new synthesis in moral psychology. Science, 316(5827), 998–1002.
Haidt, J. (2012). The righteous mind: Why good people are divided by politics and religion. New York, NY: Vintage Books
Haselmayer, M., & Jenny, M. (2014). Measuring the tonality of negative campaigning: Combining a dictionary approach with crowd-coding. Paper presented at political context Matters: Content analysis in the social sciences, Mannheim, Germany.
Haselmayer, M., & Jenny, M. (2016). Sentiment analysis of political communication: Combining a dictionary approach with crowdcoding. Quality & Quantity, 1–24.
Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world? Behavioral and Brain Sciences, 33(2–3), 61–83.
Hoover, J., Johnson, K., Boghrati, R., Graham, J., & Dehghani, M. (2018). Moral framing and charitable donation: Integrating exploratory social media analyses and confirmatory experimentation. Collabra: Psychology, 4(1).
Hopp, F. R., Barel, A., Fisher, J., Cornell, D., Lonergan, C., & Weber, R. (2019a). “I believe that morality is gone”: A large-scale inventory of moral foundations in lyrics of popular songs. Paper submitted to the annual meeting of the International Communication Association (ICA), Washington DC, USA.
Hopp, F. R., Schaffer, J., Fisher, J. T., & Weber, R. (2019b). iCoRe: The GDELT interface for the advancement of communication research. Computational Communication Research, 1(1), 13–44.
Hopp, F. R., Fisher, J., & Weber, R. (2020). A computational approach for learning moral conflicts from movie scripts. Paper submitted to the annual meeting of the International Communication Association (ICA), Goldcoast, Queensland, Australia.
Huskey, R., Bowman, N., Eden, A., Grizzard, M., Hahn, L., Lewis, R., Matthews, N., Tamborini, R., Walther, J.B., Weber, R. (2018). Things we know about media and morality. Nature Human Behavior, 2, 315.
Hutto, C. J., & Gilbert, E. (2014). Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Eighth international AAAI conference on weblogs and social media.
Jang, S. M., & Hart, P. S. (2015). Polarized frames on “climate change” and “global warming” across countries and states: Evidence from Twitter big data. Global Environmental Change, 32, 11-17.
Kim, J. S., Greene, M. J., Zlateski, A., Lee, K., Richardson, M., Turaga, S. C., & Seung, H. S. (2014). Space-time wiring specificity supports direction selectivity in the retina. Nature, 509(7500), 331–336.
Koenigs, M., Young, L., Adolphs, R., Tranel, D., Cushman, F., Hauser, M., & Damasio, A. (2007). Damage to the prefrontal cortex increases utilitarian moral judgements. Nature, 446(7138), 908.
Koleva, S., Graham, J., Haidt, J., Iyer, R., & Ditto, P. H. (2012). Tracing the threads: How five moral concerns (especially purity) help explain culture war attitudes. Journal of Research in Personality, 46, 184–194.
Leetaru, K., & Schrodt, P. A. (2013a). Gdelt: Global data on events, location, and tone, 1979–2012. ISA Annual Convention, 2(4), 1–49.
Leetaru, K., & Schrodt, P. A, (2013b). GDELT: Global data on events, location and tone, 1979-2012. Paper presented at the International Studies Association Meeting, San Francisco. CA. Retrieved from http://data.gdeltproject.org/documentation/ISA.2013.GDELT.pdf
Levy, N. (2006). The wisdom of the pack. Philosophical Explorations 9(1):99–103
Lind, F., Gruber, M., & Boomgaarden, H. G. (2017). Content analysis by the crowd: Assessing the usability of crowdsourcing for coding latent constructs. Communication Methods and Measures, 11(3), 191–209.
Luttrell, A., Philipp-Muller, A., & Petty, R. E. (2019). Challenging moral attitudes with moral messages. Psychological Science, 0956797619854706.
May, J. (2018). Regard for reason in the moral mind. Oxford University Press.
Mooijman, M., Hoover, J., Lin, Y., Ji, H., & Dehghani, M. (2018). Moralization in social networks and the emergence of violence during protests. Nature Human Behaviour, 389–396.
Morgan, G. S., Skitka, L. J., & Wisneski, D. C. (2010). Moral and religious convictions and intentions to vote in the 2008 presidential election. Analyses of Social Issues and Public Policy, 10(1), 307–320.
Peer, E., Brandimarte, L., Samat, S., & Acquisti, A. (2017). Beyond the Turk: Alternative platforms for crowdsourcing behavioral research. Journal of Experimental Social Psychology, 70, 153–163.
Pennebaker, J. W., Francis, M. E., & Booth, R. J. (2001). Linguistic inquiry and word count: LIWC 2001. Mahway: Lawrence Erlbaum Associates, 71(2001), 2001.
Rezapour, R., Shah, S. H., & Diesner, J. (2019, June). Enhancing the measurement of social effects by capturing morality. In Proceedings of the Tenth Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (pp. 35-45).
Sagi, E., & Dehghani, M. (2014). Measuring moral rhetoric in text. Social Science Computer Review, 32(2), 132–144.
Schein, C. (2020). The Importance of Context in Moral Judgments. Perspectives on Psychological Science, 15(2), 207–15.
Scheufele, D. A. (2000). Agenda-setting, priming, and framing revisited: Another look at cognitive effects of political communication. Mass Communication & Society, 3, 297–316
Strimling, P., Vartanova, I., Jansson, F., & Eriksson, K. (2019). The connection between moral positions and moral arguments drives opinion change. Nature Human Behaviour, 1.
Tamborini, R. (2011). Moral intuition and media entertainment. Journal of Media Psychology, 23, 39-45. https://doi.org/10.1027/1864-1105/a000031
Tamborini, R., & Weber, R. (2019). Advancing the model of intuitive morality and exemplars. In K. Floyd & R. Weber (Eds.), Communication Science and Biology. New York, NY: Routledge. [page numbers coming soon].
Tamborini, R., Lewis, R. J., Prabhu, S., Grizzard, M., Hahn, L., & Wang, L. (2016a). Media’s influence on the accessibility of altruistic and egoistic motivations. Communication Research Reports, 33(3), 177–187.
Tamborini, R., Prabhu, S., Lewis, R. L., Grizzard, M. & Eden, A. (2016b). The influence of media exposure on the accessibility of moral intuitions. Journal of Media Psychology, 1–12.
Van Leeuwen, F., Park, J. H., Koenig, B. L., & Graham, J. (2012). Regional variation in pathogen prevalence predicts endorsement of group-focused moral concerns. Evolution and Human Behavior, 33(5), 429–437.
Weber, R., Mangus, J. M., Huskey, R., Hopp, F. R., Amir, O., Swanson, R., … Tamborini, R. (2018). Extracting latent moral information from text narratives: Relevance, challenges, and solutions. Communication Methods and Measures, 12(2-3), 119–139.
Wolsko, C., Ariceaga, H., & Seiden, J. (2016). Red, white, and blue enough to be green: Effects of moral framing on climate change attitudes and conservation behaviors. Journal of Experimental Social Psychology, 65, 7–19.
Zhang, Y., Jin, R., & Zhou, Z. H. (2010). Understanding bag-of-words model: a statistical framework. International Journal of Machine Learning and Cybernetics, 1(1–4), 43–52.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hopp, F.R., Fisher, J.T., Cornell, D. et al. The extended Moral Foundations Dictionary (eMFD): Development and applications of a crowd-sourced approach to extracting moral intuitions from text. Behav Res 53, 232–246 (2021). https://doi.org/10.3758/s13428-020-01433-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-020-01433-0