
Abstract
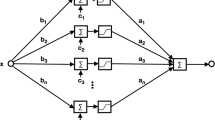
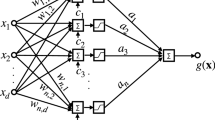
There have been various studies on approximation ability of feedforward neural networks (FNNs). Most of the existing studies are, however, only concerned with density or upper bound estimation on how a multivariate function can be approximated by an FNN, and consequently, the essential approximation ability of an FNN cannot be revealed. In this paper, by establishing both upper and lower bound estimations on approximation order, the essential approximation ability (namely, the essential approximation order) of a class of FNNs is clarified in terms of the modulus of smoothness of functions to be approximated. The involved FNNs can not only approximate any continuous or integrable functions defined on a compact set arbitrarily well, but also provide an explicit lower bound on the number of hidden units required. By making use of multivariate approximation tools, it is shown that when the functions to be approximated are Lipschitzian with order up to 2, the approximation speed of the FNNs is uniquely determined by modulus of smoothness of the functions.
Similar content being viewed by others

References
Cardaliaguet, P., Euvrard, G., Approximation of a function and its derivatives with a neural network, Neural Networks, 1992, 5: 207–220.
Chen, T. P., Chen, H., Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical system, IEEE Transaction on Neural Networks, 1995, 6: 911–917.
Chen, T. P., Approximation problems in system identification with neural networks, Science in China, Series A, 1994, 24(1): 1–7.
Chui, C. K., Li, X., Approximation by ridge functions and neural networks with one hidden layer, J. Approx. Theory, 1992, 70: 131–141.
Chui, C. K., Li, X., Neural networks with one hidden layer, In: Multivariate Approximation: From CAGD to Wavelets (J. Jetter, F. I. Utreras, eds), pp. 77–89, Singapore: World Scientific Press, 1993.
Cybenko, G., Approximation by superpositions of sigmoidal function, Math.of Control Signals, and System, 1989, 2: 303–314.
Funahashi, K. I., On the approximate realization of continuous mappings by neural networks, Neural Networks, 1989, 2: 183–192.
Gallant, A. R., White, H., On learning the derivatives of an unknown mapping with multilayer feedforward networks, Neural Networks, 1992, 5: 129–138.
Hornik, K., Stinchombe, M., White, H., Multilayer feedforward networks are universal approximation, Neural Networks, 1989, 2: 359–366.
Hornik, K., Stinchombe, M., White, H., Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks, Neural Networks, 1990, 3: 551–560.
Leshno, M., Lin, V. Y., Pinks, A., et al., Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural Networks, 1993, 6: 861–867.
Mhaskar, H. N., Micchelli, C. A., Approximation by superposition of a sigmoidal function, Advances in Applied Mathematics, 1992, 13: 350–373.
Attali, J. G., Pages, G., Approximation of functions by a multilayer perceptron: a new apprach, Neural Networks, 1997, 10: 1069–1081.
Chen, X. H., White, H., Improved rates and asymptotic normality for nonparametric neural network estimators, IEEE Trans. on Information Theory, 1999, 45:682–691.
Kurkova, V., Kainen, P. C., Kreinovich, V., Estimates of the number of hidden units and variation with respect to half-space, Neural Networks, 1997, 10: 1068–1078.
Maiorov, V., Meir, R. S., Approximation bounds for smooth functions inC(R d) by neural and mixture networks, IEEE Trans. on Neural Networks, 1998, 9: 969–978
Suzuki Shin, Constructive function approximation by three-layer artificial neural networks, Neural Networks, 1998, 11: 1049–1058.
Ditzian, Z., Totik, V., Moduli of Smoothness, New York: Springer-Verlag, 1987.
Berens, H., Xu, Y., K-moduli, moduli of smoothness, and Bernstein polynomials on a simplex, Indian Math (NS), 1991, 2: 411–421.
Cao, F. L., Xiong, J. Y., Steckin-Marchaud-type inequality in connection withL p approximation for multivariate Bernstein-Durrmeyer operator, Chinese J. Contemporary Mathematics, 2001, 22(2): 137–142.
Mhaskar, H. N., Micchelli, C. A., Degree of approximation by neural networks with a single hidden layer, Advances in Applied Mathematics, 1995, 16: 151–183.
Derriennic, M. M., On multivariate approximation by Bernstein-type polynomials, J. Approx. Theory, 1985, 45: 155–166.
Berens, H., Schmid, H. J., Xu, Y., Bernstein-Durrmeyer operators on a simplex, J. Approx. Theory, 1992, 68: 247–261.
Li, X., Simultaneous approximations of multivariate functions and their derivatives by neural networks with one hidden layer, Neuocomputing, 1996, 12: 327–343.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Xu, Z., Cao, F. The essential order of approximation for neural networks. Sci China Ser F 47, 97–112 (2004). https://doi.org/10.1360/02yf0221
Received:
Issue Date:
DOI: https://doi.org/10.1360/02yf0221