
Abstract
Here we show real-time multiple gas identification on a mobile platform through the use of an array of nanomechanical membrane-type surface stress sensors (MSS). Commercially available hardware is used to integrate the MSS array into a portable unit with wireless capability. This unit transmits data to a consumer mobile tablet where data is displayed and processed in real-time. To achieve real-time processing with the limited computational power of commercial mobile hardware, a machine learning algorithm known as Random Forest is implemented. We demonstrate the real-time identification capability of the device by measuring the vapours of water, ethanol, isopropanol, and ambient air.
Similar content being viewed by others


1Correspondence
1.1 Hardware implementation
The basis of our platform is a membrane-type surface stress sensor (MSS) that involves piezoresistors laid out in a full Wheatstone bridge configuration as described in previous papers [1],[2] (Figure 1a). The MSS has a theoretical detection limit of ~0.1 m N/m. By varying the properties of the coated polymer over each individual membrane such as its hydrophobicity and functional groups, differences in polymer-gas affinity can be utilized for identification of a wide range of VOC analytes.

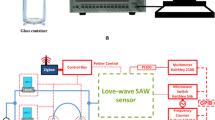
System components and operation. a) Image of MSS in a four sensor array configuration. Each MSS is coated with a different polymer exhibiting different gas interaction properties. b) The enclosure containing the MSS sensor array chip and its electrical connections. c) Components in the device and the directions of information and gas flow between them. Information about the sample arrives at the tablet for analysis.
Two piezoelectric micropumps (Bartels Microtechnik mp6) flowed sample gases and ambient air over the MSS chip near their maximum rate of 0.3 m L/s[3]. A commercially available analog to digital converter with a resolution of 632 nV (ADS1258 EVM) measured the differential output voltage of the MSS with a bias voltage of -1.0 V. An Arduino Mega 2560 received this data via a Serial Peripheral Interface (SPI) to the analog-to-digital converter. The Arduino Mega 2560 also controlled the micropump switching. A custom breakout board mounted the MSS chip, which was then encased in a 3D-printed enclosure designed to maximize gas flow over the polymer receptor layers (Figure 1b). The Arduino Mega then sent the data to a consumer tablet (Google Nexus 7) over WiFi, using an Arduino WiFi shield.
1.2 Data processing
Random Forests [4] allow short characterization times of arbitrary input; characterization time is tunable through the size of the Forest. Each Forest can be tailored to complete its task on hardware of arbitrary speeds while maintaining a real-time analysis. Once generated offline, this machine learning algorithm can be moved to a target platform for quick, real-time analysis. Classification of data using a Random Forest simply involves traversal of many decision trees, which can be multithreaded easily for fast computation on multi-core processors. While this approach is sometimes coupled with Principle Component Analysis (PCA) to determine better candidates for predictors [5], the device is capable of identifying the chosen samples without requiring the full dataset in contrast to PCA. Voltage variations as a result of sample flowing through the device form unique curves when measured over time. These curves have several identifying characteristics, which can be extracted quickly by splitting the input into several windows, obtaining the difference of their averages, and using these as predictors for the Random Forest analysis.
The Random Forest was trained on sample data collected with the device using Scikit-learn [6] with Python 3.2. Converting the Forest into a custom, portable file format allows a consumer handheld tablet to predict outcomes with the CPU to be the only limiting factor in prediction speed.
1.3 Verification
The device was verified by identifying between ethanol, isopropanol, water, and ambient air. A training set consisting of 196 sample/purge cycles (48 cycles per sample type, and 52 for ambient air) was used to train a 100 tree Random Forest. Though the ADS1258 measured at a rate of 460 samples per second (SPS) per channel, data transmission was limited to 4800 bytes every 2 seconds (approximately 400 samples per second per channel) due to problems inherent within the Arduino WiFi module [7]. This caused the signal to appear discontinuous (Figure 2).

Sample ethanol data. An example of measured data during read cycles. Ethanol was pumped to the MSS on the first four segments (Sample point 0 to 1196) and ambient air was pumped to the MSS on the latter four segments to purge the absorbed ethanol vapour.
The training data was found to be easy to differentiate as a series of slopes in a voltage vs time series. Since the signal was divided evenly into eight segments per purge/sample cycle, the slopes between the averages of each segment indicated the general trend of the curve. Using these slopes as predictors for the Random Forest allowed the algorithm to identify sample gases with a high degree of accuracy (Additional files 1, 2).
The data classification technique traditionally performs well at avoiding overfitting of training data [4]. Using the out-of-bag estimator built-in to our Random Forest creation library, the Forest scored approximately 0.939, representing a 93.9% accuracy in predicting outcomes from inputs for which the Forest was not trained. The training set used to grow the Random Forest had a high amount of variability in its input (Figure 3), forcing the Forest to identify a corresponding sample from a wide variety of input data.

Training data channel response. An overlay of all input data used as the training dataset. Each graph (a-d) corresponds to the data for one channel (1-4) on the MSS chip, while the colours correspond to the analytes used.
1.4 Conclusion
We have demonstrated that the combination of an advanced algorithm (Random Forest) and the optimized nanomechanical sensor (MSS) can achieve real-time gas identification with commerical off-the-shelf hardware. Since the peripheral electronic components can be miniaturized by the introduction of application specific integrated circuits (ASIC) or field programmable gate arrays (FPGA), the present demonstration indicates the feasibility of integrating a real-time nanomechanical olfactory system into virtually any type of mobile platforms such as smartphones. Future developments towards real world applications will include a larger dataset with proper selection of parameters from output signals, effective receptor layers, and optimization of system components including the chamber and pumps.
Additional files
References
Yoshikawa G, Akiyama T, Gautsch S, Vettiger P, Rohrer H: Nanomechanical membrane-type surface stress sensor. Nano Lett 2011,11(3):1044–1048. doi:10.1021/nl103901a doi:10.1021/nl103901a 10.1021/nl103901a
Yoshikawa G, Akiyama T, Loizeau F, Shiba K, Gautsch S, Nakayama T, Vettiger P, Aono M: Two dimensional array of piezoresistive nanomechanical membrane-type surface stress sensor (MSS) with improved sensitivity. Sensors 2012,12(11):15873–15887. doi:10.3390/s121115873 doi:10.3390/s121115873 10.3390/s121115873
Operating manual micropump Mp6/mp6-pp and controller. , [http://www.micro-components.com/image/pdf/EN_Manual%20mp6_mp6-pp_15052013.pdf].
Breiman L: Random forests. Mach Learn 2001,45(1):5–32. doi:10.1023/A:1010933404324 doi:10.1023/A:1010933404324 10.1023/A:1010933404324
Haindl M, Kittler J, Roli F (eds.): Multiple Classifier Systems. Lecture Notes in Computer Science, Vol. 4472, Berlin, Heidelberg: Springer; 2007. doi:10.1007/978–3-540–72523–7.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E: Scikit-learn: Machine learning in Python. J Mach Learn Res 2011, 12: 2825–2830.
Notes regarding behaviour of arduino wifi shield as a TCP client. , [http://mssystems.emscom.net/helpdesk/knowledgebase.php?article=51].
Acknowledgements
The authors express gratitude to Dr. Heinrich Rohrer, Dr. Terunobu Akiyama, Dr. Frederic Loizeau, Dr. Sebastian Gautsch, Dr. Peter Vettiger, Dr. Kota Shiba, Mr. Cory J. Y. Lee, Mr. Mayuran Saravanapavanantham, and Mr. Max Palumbo for their indispensable contributions to the development of the MSS platform and related devices, and Prof. Masakazu Aono, Dr. Tomonobu Nakayama, and Prof. Nico F. de Rooij for their help and support. This work was supported by WPI Research Center Initiative for Materials Nanoarchitectonics (MANA); the Grant-in-Aid for Young Scientist (A) 23685017 (2011), MEXT, Japan; Research Foundation for Opto-Science and Technology (REFOST); TEPCO Memorial Foundation; and Japan Science and Technology Agency (JST).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
RJSG contributed to the construction of the device, polymer coating of the chip, hardware design, and drafted the manuscript. FN contributed to the construction of the device, hardware design, and performed all programming involved. GY managed the study, contributed to the hardware design, and helped to draft the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
40485_2014_9_MOESM1_ESM.png
Additional file 1:Android screenshots. Four screenshots of the Google Nexus 7 analyzing different samples. Each sample shows a distinct pattern in its voltage measurements, and the Random Forest prediction is displayed beneath each graph. (PNG 545 KB)
40485_2014_9_MOESM2_ESM.zip
Additional file 2:Receiver operating characteristic (ROC) curve. ROC analysis of the generated Forest. Graph was generated using PyLab by using out-of-bag error estimates per predictor to determine the sensitivity/specificity response. The area under the water, ethanol, isopropanol, and ambient air curves are 0.9908, 0.9956, 0.9914, and 0.9900 respectively. (ZIP 146 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite this article
S Guerrero, R.J., Nguyen, F. & Yoshikawa, G. Real-time gas identification on mobile platforms using a nanomechanical membrane-type surface stress sensor. EPJ Techn Instrum 1, 9 (2014). https://doi.org/10.1140/epjti/s40485-014-0009-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjti/s40485-014-0009-z