
Abstract
The determination of the fundamental parameters of the Standard Model (and its extensions) is often limited by the presence of statistical and theoretical uncertainties. We present several models for the latter uncertainties (random, nuisance, external) in the frequentist framework, and we derive the corresponding p values. In the case of the nuisance approach where theoretical uncertainties are modeled as biases, we highlight the important, but arbitrary, issue of the range of variation chosen for the bias parameters. We introduce the concept of adaptive p value, which is obtained by adjusting the range of variation for the bias according to the significance considered, and which allows us to tackle metrology and exclusion tests with a single and well-defined unified tool, which exhibits interesting frequentist properties. We discuss how the determination of fundamental parameters is impacted by the model chosen for theoretical uncertainties, illustrating several issues with examples from quark flavor physics.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In particle physics, an important part of the data analysis is devoted to the interpretation of the data with respect to the Standard Model (SM) or some of its extensions, with the aim of comparing different alternative models or determining the fundamental parameters of a given underlying theory [1,2,3]. In this activity, the role played by uncertainties is essential, since they constitute the limit for the accurate determination of these parameters, and they can prevent from reaching a definite conclusion when comparing several alternative models. In some cases, these uncertainties are from a statistical origin: they are related to the intrinsic variability of the phenomena observed, they decrease as the sample size increases and they can be modeled using random variables. A large part of the experimental uncertainties belong to this first category. However, another kind of uncertainties occurs when one wants to describe inherent limitations of the analysis process, for instance, uncertainties in the calibration or limits of the models used in the analysis. These uncertainties are very often encountered in theoretical computations, for instance when assessing the size of higher orders in perturbation theory or the validity of extrapolation formulas. Such uncertainties are often called “systematics”, but they should be distinguished from less dangerous sources of systematic uncertainties, usually of experimental origin, that roughly scale with the size of the statistical sample and may be reasonably modeled by random variables [4]. In the following we will thus call them “theoretical” uncertainties: by construction, they lack both an unambiguous definition (leading to various recipes to determine these uncertainties) and a clear interpretation (beyond the fact that they are not from a statistical origin). It is thus a complicated issue to incorporate their effect properly, even in simple situations often encountered in particle physics [5,6,7].Footnote 1
The relative importance of statistical and theoretical uncertainties might be different depending on the problem considered, and the progress made both by experimentalists and theorists. For instance, statistical uncertainties are the main issue in the analysis of electroweak precision observables [11, 12]. On the other hand, in the field of quark flavor physics, theoretical uncertainties play a very important role. Thanks to the B-factories and LHCb, many hadronic processes have been very accurately measured [13, 14], which can provide stringent constraints on the Cabibbo–Kobayashi–Maskawa matrix (in the Standard Model) [15,16,17], and on the scale and structure of New Physics (in SM extensions) [18,19,20,21]. However, the translation between hadronic processes and quark-level transitions requires information on hadronization from strong interaction, encoded in decay constants, form factors, bag parameters... The latter are determined through lattice QCD simulations. The remarkable progress in computing power and in algorithms over the last 20 years has led to a decrease of statistical uncertainties and a dominance of purely theoretical uncertainties (chiral and heavy-quark extrapolations, scale chosen to set the lattice spacing, finite-volume effects, continuum limit...). As an illustration, the determination of the Wolfenstein parameters of the CKM matrix involves many constraints which are now limited by theoretical uncertainties (neutral-meson mixing, leptonic and semileptonic decays, ...) [22].
The purpose of this note is to discuss theoretical uncertainties in more detail in the context of particle physics phenomenology, comparing different models not only from a statistical point of view, but also in relation with the problems encountered in phenomenological analyses where they play a significant role. In Sect. 2, we summarize fundamental notions of statistics used in particle physics, in particular p values and test statistics. In Sect. 3, we list properties that we seek in a good approach for theoretical uncertainties. In Sect. 4, we propose several approaches and in Sect. 5, we compare their properties in the most simple one-dimensional case. In Sect. 6, we consider multi-dimensional cases (propagation of theoretical uncertainties, average of several measurements, fits and pulls), which we illustrate using flavor physics examples related to the determination of the CKM matrix in Sect. 7, before concluding. An appendix is devoted to several issues connected with the treatment of correlations.
2 Statistics concepts for particle physics
We start by briefly recalling frequentist concepts used in particle physics, highlighting the role played by p values in hypothesis testing and how they can be used to define confidence intervals.
2.1 p values
2.1.1 Data fitting and data reduction
First, we would like to illustrate the concepts of data fitting and data reduction in particle physics, starting with a specific example, namely the observation of the time-dependent CP asymmetry in the decay channel \(B^0(t)\) \(\rightarrow J/\psi K_S\) by the BaBar, Belle and LHCb experiments [23,24,25]. Each experiment collects a sample of observed decay times \({t_i}\) corresponding to the B-meson events, where this sample is theoretically known to follow a PDF f. The PDF is parameterized in terms of a few physics parameters, among which we assume the ones of interest are the direct and mixing-induced C and S CP asymmetries. The functional form of this PDF is dictated on very general grounds by the CPT invariance and the formalism of two-state mixing (see, e.g., [26]), and is independent of the particular underlying phenomenological model (e.g. the Standard Model of particle physics). In practice, however, detector effects are required to be modeled by additional parameters that modify the shape of the PDF. We denote by \(\theta \) the set of parameters \(\theta =(C,S,\ldots )\) that are needed to specify the PDF completely. The likelihood for the sample \(\{t_i\}\) is defined by
and can be used as a test statistic to infer constraints on the parameters \(\theta \), and/or construct estimators for them, as will be discussed in more detail below. The combination of different samples/experiments can be done simply by multiplication of the corresponding likelihoods. On the other hand one can choose to work directly in the framework of a specific phenomenological model, by replacing in \(\theta \) the quantities that are predicted by the model in terms of more fundamental parameters: for example in the Standard Model, and neglecting the “penguin” contributions, one has the famous relations \(C=0\), \(S=\sin 2\beta \) where \(\beta \) is one of the angles of the Unitarity Triangle and can be further expressed in terms of the Cabibbo–Kobayashi–Maskawa couplings.
The latter choice of expressing the experimental likelihood in terms of model-dependent parameters such as \(\beta \) has, however, one technical drawback: the full statistical analysis has to be performed for each model one wants to investigate, e.g., the Standard Model, the Minimal Supersymmetric Standard Model, GUT models, ... In addition, building a statistical analysis directly on the initial likelihood requires one to deal with a very large parameter space, depending on the parameters in \(\theta \) that are needed to describe the detector response. One common solution to these technical difficulties is a two-step approach. In the first step, the data are reduced to a set of model- and detector-independentFootnote 2 random variables that contains the same information as the original likelihood (to a good approximation): in our example the likelihood-based estimators \(\hat{C}\) and \(\hat{S}\) of the parameters C and S can play the role of such variables (estimators are functions of the data and thus are random variables). In a second step, one can work in a particular model, e.g., in the Standard Model, to use \(\hat{C}\) and \(\hat{S}\) as inputs to a statistical analysis of the parameter \(\beta \). This two-step procedure gives the same result as if the analysis were done in a single step through the expression of the original likelihood in terms of \(\beta \). This technique is usually chosen if the PDF g of the estimators \(\hat{C}\) and \(\hat{S}\) can be parameterized in a simple way: for example, if the sample size is sufficiently large, then the PDF can often be modeled by a multivariate normal distribution, where the covariance matrix is approximately independent of the mean vector.
Let us now extend the above discussion to a more general case. A sample of random events is \(\{E_i,i=1\ldots n\}\), where each event corresponds to a set of directly measurable quantities (particle energies and momenta, interaction vertices, decay times...). The distribution of these events is described by a PDF, the functional form f of which is supposed to be known. In addition to the event value E, the PDF value depends on some fixed parameters \({\theta }\), hence the notation \(f(E;\theta )\). The likelihood for the sample \(\{E_i\}\) is defined by \( \mathcal L_{\{E_i\}}(\theta ) = \prod _{i=1}^n f(E_i;\theta ). \) We want to interpret the event observation in a given phenomenological scenario that predicts at least some of the parameters \(\theta \) describing the PDF in terms of a set of more fundamental parameters \(\chi \).
To this aim we first reduce the event observation to a set of model- and detector-independent random variables X together with a PDF \(g(X;\chi )\), in such a way that the information that one can get on \(\chi \) from g is equivalent to the information one can get from f, once \(\theta \) is expressed in terms of \(\chi \) consistently with the phenomenological model of interest. Technically, it amounts to identifying a minimal set of variables x depending on \(\theta \) that are independent of both the experimental context and the phenomenological model. One performs an analysis on the sample of events \({E_i}\) to derive estimators \(\hat{x}\) for x. The distribution of these estimators can be described in terms of a PDF that is written in the \(\chi \) parametrization as \(g(X;\chi )\), where we have replaced \(\hat{x}\) by the notation X, to stress that in the following X will be considered as a new random variable, setting aside how it has been constructed from the original data \(\{E_i\}\). Obviously, in our previous example for \(B^0(t)\) \(\rightarrow J/\psi K_S\), \(\{t_i\}\) correspond to \(\{E_i\}\), C ans S to x, and \(\beta \) to \(\chi \).
2.1.2 Model fitting
From now on we work with one or more observable(s) x, with associated random variable X, and an associated PDF \(g(X;\chi )\) depending on purely theoretical parameters \(\chi \). With a slight abuse of notation we include in the symbol g not only the functional form, but also all the needed parameters that are kept fixed and independent of \(\chi \). In particular for a one-dimensional Gaussian PDF we have
where X is a potential value of the observable x and \(x(\chi )\) corresponds to the theoretical prediction of x given \(\chi \). This PDF is obtained from the outcome of an experimental analysis yielding both a central value \(X_0\) and an uncertainty \(\sigma \), where \(\sigma \) is assumed to be independent of the realization \(X_0\) of the observable x and is thus included in the definition of g.
Our aim is to derive constraints on the parameters \(\chi \), from the measurement \(X_0\pm \sigma \) of the observable x. One very general way to perform this task is hypothesis testing, where one wants to quantify how much the data are compatible with the null hypothesis that the true value of \(\chi \), \(\chi _t\), is equal to some fixed value \(\chi \):
In order to interpret the observed data \(X_0\) measured in a given experiment in light of the distribution of the observables X under the null hypothesis \({\mathcal H}_\chi \), one defines a test statistic \(T(X;\chi )\), that is, a scalar function of the data X that measures whether the data are in favor or not of the null hypothesis. We indicated the dependence of T on \(\chi \) explicitly, i.e., the dependence on the null hypothesis \({\mathcal H}_\chi \). The test statistic is generally a definite positive function chosen in a way that large values indicate that the data present evidence against the null hypothesis. By comparing the actual data value \(t=T(X_0;\chi )\) with the sampling distribution of \(T=T(X;\chi )\) under the null hypothesis, one is able to quantify the degree of agreement of the data with the null hypothesis.

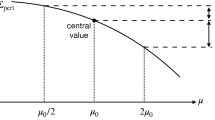
Illustration in the simple case where X is predicted as \(x(\mu )=\mu \). Under the hypothesis \(\mu _t=\mu \), and having measured \(X=0\pm 1\), one can determine the associated p value \(p(0;\mu )\) by examining the distribution of the quadratic test statistic \(T(X;\mu )=(X-\mu )^2\) assuming X is distributed as a Gaussian random variable with central value 0 and width 1. The blue dashed line corresponds to the value of T associated with the hypothesis \(\mu =-1.4\), with a p value obtained by considering the gray area. The red dotted line corresponds to the hypothesis \(\mu =2.5\)
Mathematically it amounts to defining a p value. One calculates the probability to obtain a value for the test statistic at least as large as the one that was actually observed, assuming that the null hypothesis is true. This tail probability is used to define the p value of the test for this particular observation
where the PDF h of the test statistic is obtained from the \(\mathrm{PDF}\) g of the data as
which can be obtained easily from comparing the convolution of \(\frac{\mathrm{d}T}{\mathrm{d}X}h(T)=g(X)\) with a test function of T with the convolution of the r.h.s. of (5) with the same test function. A small value of the p value means that \(T(X_0;\chi )\) belongs to the “large” region, and thus provides evidence against the null hypothesis. This is illustrated for a simple example in Figs. 1 and 2.

On the left for a given observation \(X=0\pm 1\), p value \(p(0;\mu )\) as a function of the value of \(\mu \) being tested. Blue dashed and red dotted lines correspond to \(\mu =-1.4\) and \(\mu =2.5\). A confidence interval for \(\mu \) at 68% CL is obtained by considering the region of \(\mu \) with a p value larger than 0.32, as indicated by the green dotted dashed line and arrows. On the right the same information is expressed in Gaussian units of \(\sigma \), where the 68% CL interval corresponds to the region below the horizontal line of significance 1
From its definition, one sees that \(1-p(X_0;\chi )\) is nothing else but the cumulative distribution function of the PDF h
where \(\theta \) is the Heaviside function. This expression corresponds to the probability for the test statistic to be smaller than a given value \(T(X_0;\chi )\). The p value in Eq. (4) is defined as a function of \(X_0\) and as such, is a random variable.
Through the simple change of variable \(\frac{\mathrm{d}p}{\mathrm{d}T}\frac{\mathrm{d}\mathcal P}{\mathrm{d}p}=\frac{\mathrm{d}\mathcal P}{\mathrm{d}T}\), one obtains that the null distribution (that is, the distribution when the null hypothesis is true) of a p value is uniform, i.e., the distribution of values of the p value is flat between 0 and 1. This uniformity is a fundamental property of p values that is at the core of their various interpretations (hypothesis comparison, determination of confidence intervals...) [1, 2].
In the frequentist approach, one wants to design a procedure to decide whether to accept or reject the null hypothesis \({\mathcal H}_\chi \), by avoiding as much as possible either incorrectly rejecting the null hypothesis (Type-I error) or incorrectly accepting it (Type-II error). The standard frequentist procedure consists in selecting a Type-I error \(\alpha \) and determining a region of sample space that has the probability \(\alpha \) of containing the data under the null hypothesis. If the data fall in this critical region, the hypothesis is rejected. This must be performed before data are known (in contrast to other interpretations, e.g, Fischer’s approach of significance testing [1]). In the simplest case, the critical region is defined by a condition of the form \(T\ge t_\alpha \), where \(t_\alpha \) is a function of \(\alpha \) only, which can be rephrased in terms of p value as \(p\le \alpha \). The interest of the frequentist approach depends therefore on the ability to design p values assessing the rate of Type-I error correctly (its understatement is clearly not desirable, but its overstatement yields often a reduction in the ability to determine the truth of an alternative hypothesis), as well as avoiding too large a Type-II error rate.
A major difficulty arises when the hypothesis to be tested is composite. In the case of numerical hypotheses like (3), one gets compositeness when one is only interested in a subset \(\mu \) of the parameters \(\chi \). The remaining parameters are called nuisance parameters Footnote 3 and will be denoted by \(\nu \), thus \(\chi =(\mu ,\nu )\). In this case the hypothesis \({\mathcal H}_\mu : \mu _t=\mu \) is composite, because determining the distribution of the observables requires the knowledge of the true value \(\nu _t\) in addition to \(\mu \). In this situation, one has to devise a procedure to infer a “p value” for \({\mathcal H}_\mu \) out of p values built for the simple hypotheses where both \(\mu \) and \(\nu \) are fixed. Therefore, in contrast to a simple hypothesis, a composite hypothesis does not allow one to compute the distribution of the data.Footnote 4
At this stage, it is not necessarily guaranteed that the distribution of the p value for \({\mathcal H}_\mu \) is uniform, and one may get different situations:
which may depend on the value of \(\alpha \) considered. Naturally, one would like to design as much as possible an exact p value (exact coverage), or if this is not possible, a (reasonably) conservative one (overcoverage). Such p values will be called “valid” p values. In the case of composite hypotheses, the conservative or liberal nature of a p value may depend not only on \(\alpha \), but also on the structure of the problem and of the procedure used to construct the p value, and it has to be checked explicitly [1, 2].

A \(\alpha \)-CL interval built from a p value with exact coverage has a probability of \(\alpha \) of containing the true value. This is illustrated in the simple case of a quantity X which has a true value \(\mu _t=0\) but is measured with an uncertainty \(\sigma =1\). Each time a measurement is performed, it will yield a different value for \(X_0\) and thus a different p value curve as a function of the hypothesis tested \(\mu _t=\mu \). From each measurement, a 68% CL interval can be determined by considering the part of the curve above the line \(p=0.32\), but this interval may or may not contain the true value \(\mu _t=0\). The curves corresponding to the first case (second case) are indicated with 6 green solid lines (4 blue dotted lines). Asymptotically, if the p value has exact coverage, 68% of these confidence intervals will contain the true value
Once p values are defined, one can build confidence intervals out of them by using the correspondence between acceptance regions of tests and confidence sets. Indeed, if we have an exact p value, and the critical region \(C_\alpha (X)\) is defined as the region where \(p(X;\mu )<\alpha \), the complement of this region turns out to be a confidence set of level \(1-\alpha \), i.e., \(P[\mu \notin C_\alpha (X)]= 1-\alpha \). This justifies the general use of plotting the p value as a function of \(\mu \), and reading the 68 or 95% CL intervals by looking at the ranges where the p value curve is above 0.32 or 0.05. This is illustrated for a simple example in Figs. 2 and 3. Once again, this discussion is affected by issues of compositeness and nuisance parameters, as well as the requirement of checking the coverage of the p value used to define these confidence intervals: an overcovering p value will yield too large confidence intervals, which will prove indeed conservative.
A few words about the notation and the vocabulary are in order at this stage. A p value necessarily refers to a null hypothesis, and when the null hypothesis is purely numerical such as (3) we can consider the p value as a mathematical function of the fundamental parameter \(\mu \). This of course does not imply that \(\mu \) is a random variable (in frequentist statistics, it is always a fixed, but unknown, number). When the p value as a function of \(\mu \) can be described in a simple way by a few parameters, we will often use the notation \(\mu =\mu _0\pm \sigma _\mu \). In this case, one can easily build the p value and derive any desired confidence interval. Even though this notation is similar to the measurement of an observable, we stress that this does not mean that the fundamental parameter \(\mu \) is a random variable, and it should not be seen as the definition of a PDF. In line with this discussion, we will call uncertainties the parameters like \(\sigma \) that can be given a frequentist meaning, e.g., they can be used to define the PDF of a random variable. On the other hand, we will call errors the intermediate quantities such as \(\sigma _\mu \) that can be used to describe the p value of a fundamental parameter, but cannot be given a statistical meaning for this parameter.
2.2 Likelihood-ratio test statistic
Here we consider test statistics that are constructed from the logarithm of the likelihoodFootnote 5
More precisely, one uses tests based on the likelihood ratio in many instances. Its use is justified by the Neyman–Pearson lemma [1, 2, 27] showing that this test has appealing features in a binary model with only two alternatives for \(\chi _t\), corresponding to the two simple hypotheses \({\mathcal H}_{\chi _1}\) and \({\mathcal H}_{\chi _2}\). Indeed one can introduce the likelihood ratio \({\mathcal L}_X(\chi _1)/{\mathcal L}_X(\chi _2)\), define the critical region where this likelihood ratio is smaller than a given \(\alpha \), and decide that one rejects \({\mathcal H}_{\chi _1}\) whenever the observation falls in this critical region. This test is the most powerful test that can be built [1, 2], in the sense that among all the tests with a given Type-I error \(\alpha \) (probability of rejecting \({\mathcal H}_{\chi _1}\) when \({\mathcal H}_{\chi _1}\) is true), the likelihood ratio test has the smallest Type-II error (probability of accepting \({\mathcal H}_{\chi _1}\) when \({\mathcal H}_{\chi _2}\) is true). These two conditions are the two main criteria to determine the performance of a test.
In the case of a composite hypothesis, there is no such clear-cut approach to choose the most powerful test. The maximum likelihood ratio (MLR) is inspired by the Neynman–Pearson lemma, comparing the most plausible configuration under \({\mathcal H}_\mu \) with the most plausible one in general:
Let us emphasize that even though T is constructed not to depend on the nuisance parameters \(\nu \) explicitly, its distribution Eq. (5) a priori depends on them (through the PDF g). Even though the Neyman–Pearson lemma does not apply here, there is empirical evidence that this test is powerful, and in some cases it exhibits good asymptotic properties (easy computation and distribution independent of nuisance parameters) [1, 2].
For the problems considered here, the MLR choice features alluring properties, and in the following we will use test statistics that are derived from this choice. First, if \(g(X;\chi _t)\) is a multi-dimensional Gaussian function, then the quantity \(-2\ln {\mathcal L}_X(\chi _t)\) is the sum of the squares of standard normal random variables, i.e., is distributed as a \(\chi ^2\) with a number of degrees of freedom (\(N_\mathrm{dof}\)) that is given by \(\mathrm{dim}(X)\). Secondly, for linear models, in which the observables X depend linearly on the parameters \(\chi _t\), the MLR Eq. (11) is again a sum of standard normal random variables, and is distributed as a \(\chi ^2\) with \(N_\mathrm{dof}=\mathrm{dimension}(\mu )\). Wilks’ theorem [28] states that this property can be extended to non-Gaussian cases in the asymptotic limit: under regularity conditions and when the sample size tends to infinity, the distribution of Eq. (11) will converge to the same \(\chi ^2\) distribution depending only on the number of parameters tested.
The great virtue of the \(\chi ^2\)-distribution is that it only depends on the number of degrees of freedom, which means in particular that the null-distribution of Eq. (11) is independent of the nuisance parameters \(\nu \), whenever the conditions of the Wilks’ theorem apply. Furthermore the integral (4) can be computed straightforwardly in terms of complete and incomplete \(\varGamma \) functions:
In practice the models we want to analyze, such as the Standard Model, predict nonlinear relations between the observables and the parameters. In this case one has to check whether Wilks’ theorem applies, by considering whether the theoretical equations can be approximately linearized.Footnote 6
3 Comparing approaches to theoretical uncertainties
We have argued before that an appealing test statistic is provided by the likelihood ratio Eq. (11) due to its properties in limit cases (linearized theory, asymptotic limit). These properties rely on the fact that the likelihood ratio can be built as a function of random variables described by measurements involving only statistical uncertainties. However, in flavor physics (as in many other fields in particle physics), there are not only statistical but also theoretical uncertainties. Indeed, as already indicated in the introduction, these phenomenological analyses combine experimental information and theoretical estimates. In the case of flavor physics, the latter come mainly from QCD-based calculations, which are dominated by theoretical uncertainties.
Unfortunately, the very notion of theoretical uncertainty is ill-defined as “anything that is not due to the intrinsic variability of data”. Theoretical uncertainties (model uncertainty) are thus of a different nature with respect to statistical uncertainties (stochastic uncertainty, i.e. variability in the data), but they can only be modeled (except in the somewhat academic case where a bound on the difference between the exact value and the approximately computed one can be proven). The choice of a model for theoretical uncertainties involves not only the study of its mathematical properties and its physical implications in specific cases, but also some personal taste. One can indeed imagine several ways of modeling/treating theoretical uncertainties:
-
one can (contrarily to what has just been said) treat the theoretical uncertainty on the same footing as a statistical uncertainty; in this case, in order to follow a meaningful frequentist procedure, one has to assume that one lives in a world where the repeated calculation of a given quantity leads to a distribution of values around the exact one, with some variability that can be modeled as a PDF (“random-\(\delta \) approach”),
-
one can consider that theoretical uncertainties can be modeled as external parameters, and perform a purely statistical analysis for each point in the theoretical uncertainty parameter space; this leads to an infinite collection of p values that will have to be combined in some arbitrary way, following a model averaging procedure (“external-\(\delta \) approach”),
-
one can take the theoretical uncertainties as fixed asymptotic biases,Footnote 7 treating them as nuisance parameters that have to be varied in a reasonable region (“nuisance-\(\delta \) approach”).
There are some desirable properties for a convincing treatment of theoretical uncertainties:
-
as general as possible, i.e., apply to as many “kinds” of theoretical uncertainties as possible (lattice uncertainties, scale uncertainties) and as many types of physical models as possible,
-
leading to meaningful confidence intervals, in reasonable limit cases: obviously, in the absence of theoretical uncertainties, one must recover the standard result; one may also consider the type of constraint obtained in the absence of statistical uncertainties,
-
exhibiting good coverage properties, as it benchmarks the quality of the statistical approach: the comparison of different models provides interesting information but does not shed light on their respective coverage,
-
associated with a statistically meaningful goodness-of-fit,
-
featuring reasonable asymptotic properties (large samples),
-
yielding the errors as a function of the estimates easily (error propagation), in particular by disentangling the impact of theoretical and statistical contributions,
-
leading to a reasonable procedure to average independent estimates – if possible, it should be equivalent for any analysis to include the independent estimates separately or the average alone (associativity). In addition, one may wonder whether the averaging procedure should be conservative or aggressive (i.e., the average of similar theoretical uncertainties should have a smaller uncertainty or not), and if the procedure should be stationary (the uncertainty of an average should be independent of the central values or not),
-
leading to reasonable results in the case of averages of inconsistent measurements.
Finally a technical requirement is the computing power needed to calculate the best-fit point and confidence intervals for a large parameter space with a large number of constraints. Even though it should not be the sole argument in favor of a model, it should be kept in mind (a very complicated model for theoretical uncertainties would not be particularly interesting if it yields very close results to a much simpler one).
We summarize some of the points mentioned above in Table 1. As it will be seen, it will, however, prove challenging to fulfill all these criteria at the same time, and we will have to make compromises along the way.
4 Illustration of the approaches in the one-dimensional case
4.1 Situation of the problem
We will now discuss the three different approaches and some of their properties in the simplest case, i.e. with a single measurement (for an experimental quantity) or a single theoretical determination (for a theoretical quantity). Following a fairly conventional abuse of language, we will always refer to this piece of information as a “measurement” even though some modeling may be involved in its extraction through data reduction, as discussed in Sect. 2. The main, yet not alone, aim is to model/interpret/exploit a measurement likeFootnote 8
to extract information on the value of the associated fundamental parameter \(\mu \). Without theoretical uncertainty (\(\varDelta =0\)), one would use this measurement to build a PDF
yielding the MLR test statistic
and one can build a p value easily from Eq. (4)
In the presence of a theoretical uncertainty \(\varDelta \), the situation is more complicated, as there is no clear definition of what \(\varDelta \) corresponds to. A possible first step is to introduce a theoretical uncertainty parameter \(\delta \) that describes the shift of the approximate theoretical computation from the exact value, and that is taken to vary in a region that is defined by the value of \(\varDelta \). This leads to the PDF
in such a way that in the limit of an infinite sample size (\(\sigma \rightarrow 0\)), the measured value of X reduces to \(\mu +\delta \). The challenge is to extract some information on \(\mu \), given the fact that the value of \(\delta \) remains unknown.
The steps (to be spelt out below) to achieve this goal are:
-
Take a model corresponding to the interpretation of \(\delta \): random variable, external parameter, fixed bias as a nuisance parameter...
-
Choose a test statistic \(T(X;\mu )\) that is consistent with the model and that discriminates the null hypothesis: Rfit, quadratic, other...
-
Compute, consistently with the model, the p value, which is in general a function of \(\mu \) and \(\delta \).
-
Eliminate the dependence with respect to \(\delta \) by some well-defined procedure.
-
Exploit the resulting p value (coverage, confidence intervals, goodness-of-fit).
Since we focus on Gaussian experimental uncertainties (the generalization to other shapes is formally straightforward but may be technically more complicated), for all approaches that we discuss in this note we take the following PDF:
where, in the limit of an infinite sample size (\(\sigma \rightarrow 0\)), \(\mu \) can be interpreted as the exact value of the parameter of interest, and \(\mu +\delta \) the approximately theoretically computed one. The interpretation of \(\delta \) will differ depending on the approach considered, which we will discuss now.
4.2 The random-\(\delta \) approach
In the random-\(\delta \) approach, \(\delta \) would be related to the variability of theoretical computations, which one can model with some PDF for \(\delta \), such as \({\mathcal N}_{(0,\varDelta )}\) (normal) or \({\mathcal U}_{(-\varDelta ,+\varDelta )}\) (uniform). The natural candidate for the test statistic \(T(X;\mu )\) is the MLR built from the PDF. One considers a model where \(X=s+\delta \) is the sum of two random variables, s being distributed as a Gaussian of mean \(\mu \) and width \(\sigma \), and \(\delta \) as an additional random variable with a distribution depending on \(\varDelta \).
One may often consider for \(\delta \) a variable normally distributed with a mean zero and a width \(\varDelta \) (denoted naive Gaussian or “nG” in the following, corresponding to the most common procedure in the literature of particle physics phenomenology). The resulting PDF for X is then the convolution of two Gaussian PDFs, leading to
to which corresponds the usual quadratic test statistic (obtained from MLR)
recovering the p value that would be obtained when the two uncertainties are added in quadrature
We should stress that considering \(\delta \) as a random variable corresponds to a rather strange frequentist world,Footnote 9 and there is no strong argument that would help to choose the associated PDF (for instance, \(\delta \) could be a variable uniformly distributed over \([-\varDelta ,\varDelta ]\)). However, for a general PDF, the p value has no simple analytic formula and it must be computed numerically from Eq. (4). In the following, we will only consider the case of a Gaussian PDF when we discuss the random-\(\delta \) approach.
4.3 The nuisance-\(\delta \) approach
In the nuisance approach, \(\delta \) is not interpreted as a random variable but as a fixed parameter so that in the limit of an infinite sample size, the estimator does not converge to the true value \(\mu _t\), but to \(\mu _t+\delta \). The distinction between statistical and theoretical uncertainties is thus related to their effect as the sample size increases, statistical uncertainties decreasing while theoretical uncertainties remaining of the same size (see Refs. [29,30,31] for other illustrations in the context of particle physics). One works with the null hypothesis \(\mathcal {H}_{\mu }: \mu _t=\mu \), and one has then to determine which test statistic is to be built.
In the frequentist approach, the choice of the test statistic is arbitrary as long as it models the null hypothesis correctly, i.e., the smaller the value of the test statistic, the better the agreement of the data with the hypothesis. A particularly simple possibility consists in the quadratic statistic already introduced earlier:
where the minimum is not taken over a fixed range, but on the whole space. The great virtue of the quadratic shape is that in linear models it remains quadratic after minimization over any subset of parameters, in contrast with alternative, non-quadratic, test statistics.
The PDF for X is normal, with mean \(\mu +\delta \) and variance \(\sigma ^2\)
Although we choose test statistics for the random-\(\delta \) and nuisance-\(\delta \) of the same form, Eqs. (20) and (22), the different PDFs Eqs. (19) and (23) imply very different constructions for the p values and the resulting statistical outcomes. Indeed, with this PDF for the nuisance-\(\delta \) approach, T is distributed as a rescaled, non-central \(\chi ^2\) distribution with a non-centrality parameter \((\delta /\sigma )^2\) (this non-centrality parameter illustrates that the test statistic is centered around \(\mu \) whereas the distribution of X is centered around \(\mu +\delta \)). \(\delta \) is then a genuine asymptotic bias, implying inconsistency: in the limit of an infinite sample size, the estimator constructed from T is \(\mu \), whereas the true value is \(\mu +\delta \). Using the previous expressions, one can easily compute the cumulative distribution function of this test statistic,
which depends explicitly on \(\delta \) but not on \(\varDelta \) (as indicated before, even if T is built to be independent of nuisance parameters, its PDF depends on them a priori).
To infer the p value one can take the supremum value for \(\delta \) over some interval \(\varOmega \)
The interpretation is the following: if the (unknown) true value of \(\delta \) belongs to \(\varOmega \), then \(p_{\varOmega }\) is a valid p value for \(\mu \), from which one can infer confidence intervals for \(\mu \). This space cannot be the whole space (as one would get \(p=1\) trivially for all values of \(\mu \)), but there is no natural candidate (i.e., coming from the derivation of the test statistic). More specifically, should the interval \(\varOmega \) be kept fixed or should it be rescaled when investigating confidence intervals at different levels (e.g. 68 vs. 95%)?
-
If one wants to keep it fixed, \(\varOmega _r=r[-\varDelta ,\varDelta ]\):
$$\begin{aligned} p_\mathrm{fixed\ \varOmega _r}=\mathrm{Max}_{\delta \in \varOmega _r}[1- \mathrm {CDF}_\delta (\mu )]. \end{aligned}$$(26)One may wonder what the best choice is for r, as the p value gets very large if one works with the reasonable \(r=3\), while the choice \(r=1\) may appear as non-conservative. We will call this treatment the fixed r-nuisance approach.
-
One can then wonder whether one would like to let \(\varOmega \) depend on the value considered for p. In other words, if we are looking at a \(k\,\sigma \) range, we could consider the equivalent range for \(\delta \). This would correspond to
$$\begin{aligned} p_\mathrm{adapt\ \varOmega }=\mathrm{Max}_{\delta \in \varOmega _{k_\sigma ( p)}}[1- \mathrm {CDF}_\delta (\mu )] \end{aligned}$$(27)where \(k_\sigma (p )\) is the “number of sigma” corresponding to p
$$\begin{aligned} k_\sigma (p )^2=\mathrm{Prob}^{-1}(p,N_\mathrm{dof}=1), \end{aligned}$$(28)where the function Prob has been defined in Eq. (12). We will call this treatment the adaptive nuisance approach. The correct interpretation of this p value is: p is a valid p value if the true (unknown) value of \(\delta /\varDelta \) belongs to the “would be” \(1-p\) confidence interval around 0. This is not a standard coverage criterion: one can use adaptive coverage, and adaptively valid p value, to name this new concept. Note that Eqs. (27), (28) constitute a non-algebraic implicit equation that has to be solved by numerical means.
Let us emphasize that the fixed interval is very close to the original ‘Rfit’ method of the CKMfitter group [15, 16] in spirit, but not numerically, as will be shown below by an explicit comparison. In contrast the adaptive choice is more aggressive in the region of \(\delta \) close to zero, but allows this parameter to take large values, provided one is interested in computing small p values accordingly. In this sense, the adaptive approach provides a unified approach to deal with two different issues of importance, namely the metrology of parameters (at 1 or 2\(\sigma \)) and exclusion tests (at 3 or 5\(\sigma \)).
4.4 The external-\(\delta \) approach
In this approach, the parameter \(\delta \) is also considered as a fixed parameter. The idea behind this approach is very simple, and it is close to what experimentalists often do to estimate systematic effects: in a first step one considers that \(\delta \) is a fixed constant, and one performs a standard, purely statistical analysis that leads to a p value that explicitly depends on \(\delta \). If one takes \(X\sim \mathcal {N}_{(\mu +\delta ,\sigma )}\) and T quadratic [either \((X-\mu -\delta )^2/\sigma ^2\) or \((X-\mu -\delta )^2/(\sigma ^2+\varDelta ^2)\)]:Footnote 10
Note that this procedure actually corresponds to the simple null hypothesis \(\mathcal {H}^{(\delta )}_{\mu }: \mu _t=\mu +\delta \) instead of \(\mathcal {H}_{\mu }\): \(\mu _t=\mu \), hence one gets an infinite collection of p values instead of a single one related to the aimed constraint on \(\mu \).
Since \(\delta \) is unknown one has to define a procedure to average all the \(p_\delta (\mu )\) obtained. The simplest possibility is to take the envelope (i.e., the maximum) of \(p_\delta (\mu )\) for \(\delta \) in a definite interval (e.g. \([-\varDelta ,+\varDelta ]\)), leading to
By analogy with the previous case, we will call this treatment the fixed r-external approach for \(\delta \in \varOmega _r\). This is equivalent to the Rfit ansatz used by CKMfitter [15, 16] in the one-dimensional case (but not in higher dimensions), proposed to treat theoretical uncertainties in a different way from statistical uncertainties, treating all values within \([-\varDelta ,\varDelta ]\) on an equal footing. We recall that the Rfit ansatz was obtained starting from a well test statistic, with a flat bottom with a width given by the theoretical error and parabolic walls given by statistical uncertainty.
A related method, called the Scan method, has been developed in the context of flavor physics [32, 33]. It is however slightly different from the case discussed here. First, the test statistic chosen is not the same, since the Scan method uses the likelihood rather than the likelihood ratio, i.e. it relies on the test statistic \(T=-2\log \mathcal{L(\mu ,\nu })\) which is interpreted assuming that T follows a \(\chi ^2\)-law with the corresponding number of degrees of freedom N, including both parameters of interest and nuisance parameters.Footnote 11 Then the \(1-\alpha \) confidence region is then determined by varying nuisance parameters in given intervals (typically \(\varOmega _1\)), but accepting only points where \(T\le T_c\), where \(T_c\) is a critical value so that \(P(T\ge T_c;N|H_0)\ge \alpha \) (generally taken as \(\alpha =0.05\)). This latter condition acts as a test of compatibility between a given choice of nuisance parameters and the data.

Comparison of different treatments of theoretical uncertainties of the measurement \(X=0 \pm \sigma \ (\mathrm{exp}) \pm \varDelta (\mathrm{th})\), with different values of \(\varDelta /\sigma \) (with the normalization \(\sqrt{\varDelta ^2+\sigma ^2}=1\)). The p values have been converted into a significance in Gaussian units of \(\sigma \) following the particle physics conventions. The various approaches are: nG (dotted, red), Rfit or 1-external (dashed, black), fixed 1-nuisance (dotted-dashed, blue), fixed 3-nuisance (dotted-dotted-dashed, purple), adaptive nuisance (solid, green)
5 Comparison of the methods in the one-dimensional case
In the following, we will discuss properties of the different approaches in the case of one dimension. More specifically, we will consider:
-
the random-\(\delta \) approach with a Gaussian random variable, or naive Gaussian (nG), see Sect. 4.2,
-
the nuisance-\(\delta \) approach with quadratic statistic and fixed range, or fixed nuisance, see Sect. 4.3,
-
the nuisance-\(\delta \) approach with quadratic statistic and adaptive range, or adaptive nuisance, see Sect. 4.3,
-
the external-\(\delta \) approach with quadratic statistic and fixed range, equivalent to the Rfit approach in one dimension; see Sect. 4.4.
Note that we will not consider other (nonquadratic) statistics. Finally, we consider
with varying \(\varDelta /\sigma \) as an indication of the relative size of the experimental and theoretical uncertainties.
5.1 p values and confidence intervals
We can follow the discussion of the previous section and plot the results for the p values obtained from the various methods discussed above in Fig. 4, where we compare nG, Rfit, fixed nuisance and adaptive nuisance approaches. From these p values, we can infer confidence intervals at a given significance level and a given value of \(\varDelta /\sigma \), and determine the length of the (symmetric) confidence interval (see Table 2). We notice the following points:
-
By construction, nG always provides the same errors whatever the relative proportion of theoretical and statistical uncertainties, and all the approaches provide the same answer in the limit of no theoretical uncertainty \(\varDelta =0\).
-
By construction, for a given \(n\sigma \) confidence level, the interval provided by the adaptive nuisance approach is identical to the one obtained using the fixed nuisance approach with a \([-n,n]\) interval. This explains why the adaptive nuisance approach yields identical results to the fixed 1-nuisance approach at 1\(\sigma \) (and similarly for the fixed 3-nuisance approach at 3\(\sigma \)). The corresponding curves cannot be distinguished on the upper and central panels of Fig. 5.
-
The adaptive nuisance approach is numerically quite close to the nG method; the maximum difference occurs for \(\varDelta /\sigma =1\) (up to 40% larger error size for 5\(\sigma \) intervals).
-
The p value from the fixed-nuisance approach has a very wide plateau if one works with the ‘reasonable’ range \([-3\varDelta ,+3\varDelta ]\), while the choice of \([-\varDelta ,+\varDelta ]\) might be considered as nonconservative.
-
The 1-external and fixed 1-nuisance approaches are close to each other and less conservative than the adaptive approach, which is expected, but also than nG, for confidence intervals at 3 or 5\(\sigma \) when theory uncertainties dominate.
-
When dominated by theoretical uncertainties (\(\varDelta /\sigma \) large), all approaches provide 3 and 5\(\sigma \) errors smaller than the nG approach, apart from the adaptive nuisance approach.

Comparison of the size of the \((1, 3, 5)\sigma \) errors (upper, central and lower panels, respectively) as a function of \(\varDelta /\sigma \). Different approaches are shown: nG (dotted, red), Rfit or 1-external (dashed, black), fixed 1-nuisance (dotted-dashed, blue), fixed 3-nuisance (dotted-dotted-dashed, purple), adaptive nuisance (solid, green). In the upper panel (\(1\sigma \) confidence level), the adaptive and fixed 1-nuisance approaches yield the same result by construction, and the two curves cannot be distinguished (only the adaptive one is shown). The same situation occurs in the central panel corresponding to 3\(\sigma \) with the adaptive and fixed 3-nuisance approaches
5.2 Significance thresholds
Another way of comparing methods consists in taking the value of \(\mu \) for which the p value corresponds to \(1,3,5 \sigma \) (in significance scale) in a given method, and compute the corresponding p values for the other methods. The results are gathered in Tables 3 and 4. Qualitatively, the comparison of significances can be seen from Fig. 4: if the size of the error is fixed, the different approaches quote different significances for this same error.
In agreement with the previous discussion, we see that fixed 1-nuisance and 1-external yield similar results for 3 and 5\(\sigma \), independently of the relative size of statistical and theoretical effects. Moreover, they are prompter to claim a tension than nG, the most conservative method in this respect being the adaptive nuisance approach.
As a physical illustration of this problem, we can consider the current situation for the anomalous magnetic moment of the muon, namely the difference between the experimental measurement and the theoretical computation in the Standard Model [34]:
This discrepancy has a different significance depending on the model chosen for theoretical uncertainties, which can be computed from the associated p value (under the hypothesis that the true value of \(a_\mu ^\mathrm{SM}-a_\mu ^\mathrm{exp}\) is \(\mu =0\)).Footnote 12 The nG method yields 3.6\(\sigma \), the 1-external approach 3.8\(\sigma \), the 1-nuisance approach 4.0\(\sigma \), and the adaptive nuisance approach 2.7\(\sigma \). The overall pattern is similar to what can be seen from the above tables, with a significance of the discrepancy which depends on the model used for theoretical uncertainties.
5.3 Coverage properties
As indicated in Sect. 2.1.2, p values are interesting objects if they cover exactly or slightly overcover in the domain where they should be used corresponding to a given significance; see Eqs. (7)–(9). If coverage can be ensured for a simple hypothesis [1, 2], this property is far from trivial and should be checked explicitly in the case of composite hypotheses, where compositeness comes from nuisance parameters that can be related to theoretical uncertainties, or other parameters of the problem.
For all methods we study coverage properties in the standard way: one first fixes the true values of the parameters \(\mu \) and \(\delta \) (which are not assumed to be random variables), from which one generates a large sample of toy experiments \(X_i\). Then for each toy experiment one computes the p value at the true value of \(\mu \). The shape of the distribution of p values indicates over, exact or under coverage. More specifically, one can determine \(P(p\ge 1-\alpha )\) for a CL of \(\alpha \): if it is larger (smaller) than \(\alpha \), the method overcovers (undercovers) for this particular CL, i.e. it is conservative (liberal). We emphasize that this property is a priori dependent on the chosen CL.

Distribution of p value (for a fixed total number of events) for different true values \(\delta /\varDelta \) and various relative sizes of statistical and theoretical uncertainties \(\varDelta /\sigma \). The following approaches are shown: nG (dotted, red), Rfit or 1-external (dashed, black), fixed 1-nuisance (dotted-dashed, blue), adaptive nuisance (solid, green). Since the 1-external approach produces clusters of \(p=1\) p values, the coverage values excluding these clusters are also shown, as well as the distribution of p values (dotted-dotted-dashed, grey). Note that the behavior of the 1-external p value around \(p=1\) is smoothened by the graphical representation
In order to compare the different situations, we take \(\sigma ^2+\varDelta ^2=1\) for all methods, and compute for each method the coverage fraction (the number of times the confidence level interval includes the true value of the parameter being extracted) for various confidence levels and for various values of \(\varDelta /\sigma \). Note that the coverage depends also on the true value of \(\delta /\varDelta \) (the normalized bias). The results are gathered in Table 5 and Fig. 6. We also indicate the distribution of p values obtained for the different methods.
One notices in particular that the 1-external approach has a cluster of values for \(p=1\), which is expected due to the presence of a plateau in the p value. This behavior makes the interpretation of the coverage more difficult, and as a comparison, we also include the results when we consider the same distribution with the \(p=1\) values removed. Indeed one could imagine a situation where reasonable coverage values could only be due to the \(p=1\) clustering, while other values of p would systematically undercover: such a behavior would either yield no constraints or too liberal constraints on the parameters depending on the data.
The results are the following:
-
If \(\varOmega \) is fixed and does not contain the true value of \(\delta /\varDelta \) (“unfortunate” case), both external-\(\delta \) and nuisance-\(\delta \) approaches lead to undercoverage; the size of the effect depends on the distance of \(\delta /\varDelta \) with respect to \(\varOmega \). This is also the case for nG.
-
If \(\varOmega \) is fixed and contains the true value of \(\delta /\varDelta \) (“fortunate” case), both the external-\(\delta \) and the nuisance-\(\delta \) approaches overcover. This is also the case for nG.
-
If \(\varOmega \) is adaptive, for a fixed true value of \(\delta \), a p value becomes valid if it is sufficiently small so that the corresponding interval contains \(\delta \). Therefore, for the adaptive nuisance-\(\delta \) approach, there is always a maximum value of CL above which all p values are conservative; this maximum value is given by \(1-\mathrm {Erf}[\delta /(\sqrt{2}\varDelta )]\).
To interpret the pattern of coverage seen above in the external and nuisance approaches, note that one starts with a p value that has exact coverage under the individual simple hypotheses when \(\delta \) is fixed. Therefore, as long as the true value \(\delta \) lies within the range over which one takes the supremum, this procedure yields a conservative envelope. This explains the overcoverage/undercoverage properties for the external-\(\delta \) and nuisance-\(\delta \) approaches given above.
5.4 Conclusions of the uni-dimensional case
It should be stressed that, by construction, all methods are conservative if the true value of the \(\delta \) parameter satisfy the assumption that has been made for the computation of the p value. Therefore coverage properties are not the only criterion to investigate in this situation in order to assess the methods: in particular one has to study the robustness of the p value when the assumption set on the true value of \(\delta \) is not true. The adaptive approach provides a means to deal with a priori unexpected true values of \(\delta \), provided one is interested in a small enough p value, that is, a large enough significance effect. Other considerations (size of confidence intervals, significance thresholds) suggest that the adaptive approach provides an interesting and fairly conservative framework to deal with theoretical uncertainties. We are going to consider the different approaches in the more general multi-dimensional case, putting emphasis on the adaptive nuisance-\(\delta \) approach and the quadratic test statistic.
6 Generalization to multi-dimensional cases
Up to here we only have discussed the simplest example of a single measurement X linearly related to a single model parameter \(\mu \). Obviously the general case is multi-dimensional, where we deal with several observables, depending on several underlying parameters, possibly in a non-linear way, with several measurements involving different sources of theoretical uncertainty. Typical situations correspond to averaging different measurements of the same quantity, and performing fits to extract confidence regions for fundamental parameters from the measurement of observables. In this section we will discuss the case of an arbitrary number of observables in a linear model with an arbitrary number of parameters, where we are particularly interested in a one-dimensional or two-dimensional subset of these parameters.
6.1 General formulas
We start by defining the following quadratic test statistic:
where \(X=(X_i,\ i=1,\ldots ,n)\) is the n-vector of measurements, \(x=(x_i,\ i=1,\ldots ,n)\) is the n-vector of model predictions for the \(X_i\) that depends on \(\chi =(\chi _j,\ j=1,\ldots , n_\chi )\), the \(n_\chi \)-vector of model parameters, \(\tilde{\delta }\) is the m-vector of (dimensionless) theoretical biases, \(W_s\) is the (possibly non-diagonal) \(n\times n\) inverse of the statistical covariance matrix \(C_s\), \(\widetilde{W}_t\) is the inverse of the (possibly non-diagonal) \(m\times m\) theoretical correlation matrix \(\widetilde{C}_t\), \(\varDelta \) is the \(n\times m\)-matrix of theoretical uncertainties \(\varDelta _{i\alpha }\), so that the reduced biases \(\tilde{\delta }_\alpha \) have a range of variation within \([-1,1]\) (this explains the notation with tildes for the reduced quantities rescaled to be dimensionless).
After minimization over the \(\tilde{\delta }_\alpha \), T can be recast into the canonical form,
where
with
The definition of \(\bar{W}\) involves the inverse of matrices that can be singular. This may occur in particular in cases where the statistical uncertainties are negligible and some of the theoretical uncertainties are assumed to be 100% correlated. This requires us to define a generalized inverse, including singular cases, which is described in detail in Appendix A and corresponds to a variation of the approach presented in Ref. [5]. Ambiguities and simplifications that can occur in the definition of T are further discussed in Appendix C. In particular, one can reduce the test statistic to the case \(m=n\) with a diagonal \(\varDelta \) matrix without losing information. In the case where both correlation/covariance matrices are regular, Eq. (36) boils down to \(\bar{W}=[C_s+C_t]^{-1}\) with \(C_t =\varDelta \widetilde{C}_t \varDelta ^T\). This structure is reminiscent of the discussion of theoretical uncertainties as biases and the corresponding weights given in Ref. [29], but it extends it to the case where correlations yield singular matrices.
We will focus here on the case where the model is linear, i.e., the predictions \(x_i\) depend linearly on the parameters \(\chi _j\):
where \(a_{ik}\) and \(b_i\) are constants. We leave the phenomenologically important non-linear case and its approximate linearization for a dedicated discussion in a separate paper [35].
Following the one-dimensional examples in the previous sections, we always assume that the measurements \(X_i\) have Gaussian distributions for the statistical part. We will consider two main cases of interest in our field: averaging measurements and determining confidence intervals for several parameters.
6.2 Averaging measurements
We start by considering the averages of several measurements of a single quantity, each with both statistical and theoretical uncertainties, with possible correlations. We will focus mainly on the nuisance-\(\delta \) approach, starting with two measurements before moving to other possibilities.
6.2.1 Averaging two measurements and the choice of a hypervolume
A first usual issue consists in the case of two uncorrelated measurements \(X_1\pm \sigma _1\pm \varDelta _1\) and \(X_2\pm \sigma _2\pm \varDelta _2\) that we want to combine. The procedure is well defined in the case of purely statistical uncertainties, but it depends obviously on the way theoretical uncertainties are treated. As discussed in Sect. 3, associativity is a particularly appealing property for such a problem as it allows one to replace a series of measurements by its average without loss of information.
Averaging two measurements amounts to combining them in the test statistic. The nuisance-\(\delta \) approach, together with the quadratic statistic Eq. (34), in the absence of correlations yields
with
\(\hat{\mu }\) is a linear combination of Gaussian random variables, and is thus distributed according to a Gaussian p.d.f, with mean \(\mu +\delta _\mu \) and variance \(\sigma _\mu ^2\)
Therefore, \(T-T_\mathrm{min}\) is distributed as a rescaled uni-dimensional non-central \(\chi ^2\) distribution with non-centrality parameter \((\delta _\mu /\sigma _\mu )^2\).
\(\sigma _\mu \) corresponds to the statistical part of the error on \(\mu \). \(\delta _1\) and \(\delta _2\) remain unknown by construction, and the combined theory error can only be obtained once a region of variation is chosen for the \(\delta \)’s (as a generalization of the \([-1,1]\) interval in the one-dimension case). If one maximizes the p value over a rectangle \({\mathcal C}\) (called the “hypercube case” in the following, in reference to its multi-dimensional generalization), \(\delta _\mu \) varies in \(\varDelta _\mu \), with
recovering the proposal in Ref. [29] for the treatment of systematic uncertainties. In this case, \(\delta _1\) and \(\delta _2\) are allowed to be varied separately, without introducing any relation in their values, and can assume both extremal values. On the other hand, if one performs the maximization over a disk (referred to as the “hyperball case” for the same reasons as above) one has the range
In this case, the values of \(\delta _1\) and \(\delta _2\) are somehow related, since they cannot both reach extremal values simultaneously.
Each choice of volume provides an average with different properties. As discussed earlier, associativity is a very desirable property: one can average different observations of the same quantity prior to the full fit, since it gives the same result as keeping all individual inputs. The hyperball choice indeed fulfills associativity. On the other hand, the hypercube case does not: the combination of the inputs 1 and 2 yields the following test statistic: \((w_1+w_2)(\mu -\hat{\mu })^2\), whereas the resulting combination \(\hat{\mu }\pm \sigma _\mu \pm \varDelta _\mu \) has the statistic \((\mu -\hat{\mu })^2/(\sigma _\mu ^2+\varDelta _\mu ^2)\). The two statistics are proportional and hence lead to the same p value, but they are not equivalent when added to other terms in a larger combination.
A comment is also in order concerning the size of the uncertainties for the average. In the case of the hypercube, the resulting linear addition scheme is the only one where the average of different determinations of the same quantity cannot lead to a weighted theoretical uncertainty that is smaller than the smallest uncertainty among all determinations.Footnote 13 In the case of the hyperball, it may occur that the average of different determinations of the same quantity yields a weighted theoretical uncertainty smaller than the smallest uncertainty among all determinations.
Whatever the choice of the volume, a very important and alluring property of our approach is the clean separation between the statistical and theoretical contribution to the uncertainty on the parameter of interest. This is actually a general property that directly follows from the choice of a quadratic statistic, and in the linear case it allows one to perform global fits while keeping a clear distinction between various sources of uncertainty.
6.2.2 Averaging n measurements with biases in a hyperball
We will now consider here the problem of averaging n, possibly correlated, determinations of the same quantity, each individual determination coming with both a Gaussian statistical uncertainty, and a number of different sources of theoretical uncertainty. We focus first on the nuisance-\(\delta \) approach, as it is possible to provide closed analytic expressions in this case. We will first discuss the variation of the biases over a hyperball, before discussing other approaches, which will be illustrated and compared with examples from flavor physics in Sect. 7.
We use the test statistic Eq. (34) for \(\mu \), with \(x(\chi )\) simply replaced by \(\mu U\), where U is the n-vector \((1,\ldots ,1)\). After minimization over the \(\tilde{\delta }_\alpha \), T can be recast into the canonical form
The minimization of Eq. (44) over \(\mu \) leads to an estimator \(\hat{\mu }\) of the average in terms of the measurements \(X_i\)
that allows one to compute the statistical uncertainty \(\sigma _\mu \) in the following way:
The theoretical bias is given by \(\delta _\mu =\sum _{i,\alpha } w_i \varDelta _{i\alpha } \tilde{\delta }_\alpha \). We would like to vary \(\tilde{\delta }_\alpha \) in ranges required to infer the theoretical uncertainty, identifying the combination of biases that is uncorrelated. This is a well-known problem of statistics, and it can easily be achieved in a linear manner by noticing that the relevant combination is \( \varDelta ^T \tilde{C}_t \varDelta \), cf. Eq. (36), and by introducing the Cholesky decomposition for the theoretical correlation matrix \(\widetilde{C}_t=P\cdot P^T\), with P a lower triangular matrix with diagonal positive entries. This yields the expression for the bias,
where \((P^{-1}\tilde{\delta })_\beta \) are uncorrelated biases. If the latter biases are varied over a hyperball, the biases \(\tilde{\delta }\) are varied over a hyperellipsoid elongated along the directions corresponding to strong correlations (see Appendix B for illustrations) and one gets
Known (linear) statistical correlations between two measurements are straightforward to implement, by using the full covariance matrix in the test statistic Eq. (46). On the other hand, in the physical problems considered here (involving hadronic inputs from lattice QCD simulations), it often happens that two a priori independent calculations of the same quantity are statistically correlated, because they use the same (completely or partially) ensemble of gauge configurations. The correlation is not perfect of course, since usually different nonlinear actions are used to perform the computation. However, the accurate calculation of the full covariance matrix is difficult, and in many cases it is not available in the literature. For definiteness, we will assume that if two lattice calculations are statistically correlated, then the (linear) correlation coefficient is one. In such a case the covariance matrix is singular, and its inverse \(W_s\) is ill-defined, as well as all quantities that are defined above in terms of \(W_s\). A similar question arises for fully correlated theoretical uncertainties (coming from the same method), leading to ambiguities in the definition of \(\widetilde{W}_t\). Details of these issues are given in Appendices A and B.
Statistical uncertainties are assumed here to be strictly Gaussian and hence symmetric (see Appendix C for more details of the asymmetric case). In contrast, in the nuisance approach, a theoretical uncertainty that is modeled by a bias parameter \(\delta \) may be asymmetric: that is, the region in which \(\delta \) is varied may depend on the sign of \(\delta \), e.g., \(\delta \in [-\varDelta _-,+\varDelta _+]\) in one dimension with the fixed hypercube approach (\(\varDelta _\pm \ge 0\)). In order to keep the stationarity property that follows from the quadratic statistic, we take the conservative choice \(\varDelta =\mathrm{Max}(\varDelta _+,\varDelta _-)\) in the definition Eq. (34). Let us emphasize that this symmetrization of the test statistic is independent of the range in which \(\delta \) is varied: if theoretical uncertainties are asymmetric, one computes Eqs. (46)–(48) to express the asymmetric combined uncertainties \(\varDelta _{\mu ,\pm }\) in terms of the \(\varDelta _{i\alpha ,\pm }\).
6.2.3 Averages with other approaches
In Sect. 6.2.1, we indicated that other domains can be chosen in principle in order to perform the averages of measurements, for instance a hypercube rather than a hyperball. If we do not try to take into account theoretical correlations in the range of variation, it is quite easy to determine the result for \(\varDelta \)
reminiscent of the formulas derived in Ref. [29]. However, we encountered severe difficulties when trying to include theoretical correlations in the discussion. Similarly to the hyperball case, it would be interesting to consider a linear transformation P of the biases (for instance, the Cholesky decomposition of \(C_t\), but the discussion is more general), so that \((P^{-1}\tilde{\delta })_\beta \) are uncorrelated biases varied within a hypercube. This would lead to \(\tilde{\delta }\) varied within a deformed hypercube, which corresponds to cutting the hypercube by a set of \((\tilde{\delta }_i,\tilde{\delta }_j)\) hyperplanes. It can take a rather complicated convex polygonal shape that is not symmetric along the diagonal in the \((\tilde{\delta }_i,\tilde{\delta }_j)\) plane, leading to the unpleasant feature that the order in which the measurements are considered in the average matters to define the range of variation of the biases (an illustration is given in Appendix B).Footnote 14
As indicated before, this discussion occurs for any linear transformation P and is not limited to the Cholesky decomposition. We have not been able to find other procedures that would avoid these difficulties while paralleling the hypercube case. In the following, we will thus use Eq. (49) even in the presence of theoretical correlations: therefore, the latter will be taken into account in the definition of T through \(\bar{W}\), but not in the definition of the range of variations to compute the error \(\varDelta \). We also notice that the problems that we encounter are somehow due to contradicting expectations concerning the hypercube approach. In Sect. 6.2.1, the hypercube corresponds to values of \(\delta _1\) and \(\delta _2\) left free to vary without relation among them (contrary to the hyperball case). It seems therefore difficult to introduce correlations in this case which was designed to avoid them initially. Our failure to introduce correlations in this case might be related to the fact that the hypercube is somehow designed to avoid such correlations from the start and cannot accommodate them easily.
In the case of the external-\(\delta \) approach, the scan method leads to the same discussion as for the nuisance case, provided that one uses the following statistic: \(T = (X-\mu -\delta )^2/(\sigma ^2+\varDelta ^2)\). This choice is different from Ref. [32] by the normalization (\(\sigma ^2+\varDelta ^2\) rather than \(\sigma ^2\)) in order to take into account of the importance of both uncertainties when combining measurements (damping measurements which are imprecise in one way or the other). As indicated in Sect. 4.4, the difference of normalization of the test statistic does not affect the determination of the p value in the uni-dimensional case, but it has an impact once several determinations are combined. The choice above corresponds to the usual one when \(\varDelta \) is of statistical nature. It gives a reasonable balance when two or more inputs are combined that all come with both statistical and theoretical uncertainties.
A similar discussion holds for the random-\(\delta \) approach. However, if the combined errors \(\sigma _\mu \) and \(\varDelta _\mu \) are the same between the nuisance-\(\delta \) (with hyperball), the random-\(\delta \) and the external-\(\delta \) (with hyperball) approaches, we emphasize that the p value for \(\mu \) built from these errors is different and yields different uncertainties for a given confidence level for each approach, as discussed in Sect. 4.
6.2.4 Other approaches in the literature
There are other approaches available in the literature, often starting from the random-\(\delta \) approach (i.e., modeling all uncertainties as random variables).
The Heavy Flavor Averaging Group [36] choose to perform the average including correlations. In the absence of knowledge on the correlation coefficient between uncertainties of two measurements (typically coming from the same method), they tune the correlation coefficient so that the resulting uncertainty is maximal (which is not \(\rho =1\) in the case where the correlated uncertainties have a different size and are combined assuming a statistical origin; see Appendix A.2). This choice is certainly the most conservative one when there is no knowledge concerning correlations.
The Flavor Lattice Averaging Group [37] follows the proposal in Ref. [38]: they build a covariance matrix where correlated sources of uncertainties are included with 100% correlation, and they perform the average by choosing weights \(w_i\) that are not optimal but are well defined even in the presence of \(\rho =\pm 1\) correlation coefficients. As discussed in Appendix A.2, our approach to singular covariance matrices is similar but more general and guarantees that we recover the weights advocated in Ref. [38] for averages of fully correlated measurements.
Finally, the PDG approach [34] combines all uncertainties in a single covariance matrix. In the case of inconsistent measurements, one may then obtain an average with an uncertainty that may be interpreted as ‘too small’ (notice however that the weighted uncertainty does not increase with the incompatibility of the measurements). This problem occurs quite often in particle physics and cannot be solved by purely statistical considerations (even in the absence of theoretical uncertainties). If the model is assumed to be correct, one may invoke an underestimation of the uncertainties. A (commonly used) recipe in the pure statistical case has been adopted by the Particle Data Group, which consists in computing a factor \(S=\sqrt{\chi ^2/(N_\mathrm{dof}-1)}\) and rescaling all uncertainties by this factor. A drawback of this approach is the lack of associativity: the inconsistency is either removed or kept as it is, depending on whether the average is performed before any further analysis, or inside a global fit. Furthermore since the ultimate goal of statistical analyses is indeed to exclude the null hypothesis (e.g. the Standard Model), it looks counter-intuitive to first wash out possible discrepancies by an ad hoc procedure. Therefore we refrain to define a S factor in the presence of theoretical uncertainties, and we leave the discussion of discrepancies between independent determinations of the same quantity to a case-by-case basis, based on physical (and not statistical) grounds.
In the case of the Rfit approach adopted by the CKMfitter group [15, 16], a specific recipe was chosen to avoid underestimating combined uncertainties in the case of marginally compatible values. The idea is first combine the statistical uncertainties by combining the likelihoods restricted to their statistical part, then assign to this combination the smallest of the individual theoretical uncertainties. This is justified by the following two points: the present state of the art is assumed not to allow one to reach a better theoretical accuracy than the best of all estimates, and this best estimate should not be penalized by less precise methods. In contrast with the plain (or naive) Rfit approach for averages (consisting in just combining Rfit likelihoods without further treatment), this method of combining uncertainties was called educated Rfit and is used by the CKMfitter group for averages [17, 19, 22]. Let us note finally that the calculation of pull values, discussed in Sect. 6.3, is a crucial step for assessing the size of discrepancies.
6.3 Global fit
6.3.1 Estimators and errors
Another prominent example of multi-dimensional problem is the extraction of a constraint on a particular parameter of the model from the measured observables. If the model is linear, Eq. (38), the discussion follows closely that of Sect. 6.2.2. In the case where there is a single parameter of interest \(\mu \), we do not write explicitly the calculations and refer to Sect. 7 for numerical examples.
We start from the test statistic Eq. (34) in the linear case defined in Eq. (38), reducing the number of theoretical biases to the case \(m=n\) as indicated in Appendix C. Following the same discussion as in Sect. 6.2.2, we can minimize with respect to \(\tilde{\delta }_\alpha \), leading to the canonical form,
The minimum of this function is found at the point \(\hat{\chi }_k\) where
so that we have
The minimum \(\hat{\chi }_q\) is thus linearly related to the measured observables \(X_i\) and their statistical properties are closely related. The test statistic for a particular parameter \(\mu =\chi _q\) will lead to \(T(X;\mu )=(\mu -\hat{\chi }_q)^2 \times (a^T\bar{W}a)_{qq}\), so that the discussion of the p value for \(\mu \) follows exactly the discussion for uni-dimensional measurements.Footnote 15
For instance, if the observables \(X_i\) have central values \(X_{i0}\) and variances \(\sigma ^2_{X_i}\), the central value and the variance for \(\hat{\chi }_q\) (corresponding also to the central value and statistical uncertainty for the p value for \(\mu =\chi _q\)), can readily be obtained from
Similar to the previous section, the theoretical uncertainty on \(\mu =\chi _q\) is obtained in the hyperball case as
It remains to determine how to define the theoretical correlation in this framework, denoted \(\kappa _{qr}\) corresponding to the actual parameters of interest. This can be seen as trying to infer a scalar product on the vectors \([w^{(q)}\varDelta P]_i\) from the knowledge of a norm, here \(L^2\). We will thus define the theoretical correlation in the following way:
In Sect. 6.2.2 we encountered difficulties in extending the discussion to the hypercube case. We can define errors varying the biases without correlations in the definition of the hypercube
but we could not determine a way of defining this hypercube taking into account theoretical correlations. Moreover, there is no obvious way to extend the definition of theoretical correlation for the hypercube in a similar way to Eq. (56), as there is no scalar product associated to the \(L^1\)-norm. We will thus not quote theoretical correlations for the hypercube case.
6.4 Goodness-of-fit
We would like also to compute the distribution of \(T_\mathrm{min}\) in presence of biases and extract a goodness-of-fit value. Coming back to the initial problem, we see that \(T_{\min }\) can be written as
where the X are distributed following a multivariate normal distribution, with central value \(a \chi +b+\varDelta \tilde{\delta }\) and correlation matrix \(C_s\). The CDF \(H_{\tilde{\delta }}(t)\) for \(T_\mathrm{min}\) at fixed \(\tilde{\delta }\) can thus be rephrased in the following way: considering a vector Y distributed according to a multivariate normal distribution of covariance \(C_s\) centered around 0, \(H_{\tilde{\delta }}(t)\) is the probability \(P[(Y-a \chi -\varDelta \tilde{\delta })^T M (Y-a \chi -\varDelta \tilde{\delta })\le t]\).
We are able to reexpress this problem as a linear combination of non-central \(\chi ^2\) distributions. Indeed, we can define
with L lower triangular (using the Cholesky decomposition), \(\alpha \) is diagonal and K orthogonal (so that \(\alpha \) are the (positive) eigenvalues of \(L^TML\) and thus of \(MC_s\)). Let us note that \(\alpha \) does depend only on \(C_s\) and \( C_t\), whereas the dependence on the true value of \(\chi \) and \(\tilde{\delta }\) is only present in \(\beta \). The problem is then equivalent to considering a vector Z distributed according to a multivariate normal distribution of covariance identity centered around 0, and computing \(P[(Z-\beta )^T \alpha (Z-\beta )\le t]\). This is the CDF of a linear combination of the form \(\sum _i \alpha _i X_i^2\) corresponding to non-central \(\chi ^2\) distributions.
In the case where \(\alpha \) is proportional to identity, the CDF can be expressed in terms of the generalized Marcum Q-function
with the non-centrality parameter \(\lambda =\sum _i \beta _i^2\). In the general case, the answer can be found in various articles, for instance in Ref. [39], as a linear combination of infinitely many (central or non-central) \(\chi ^2\) distribution functions, and in Ref. [40], where an expansion in terms of Laguerre polynomials is provided for a fast numerical evaluation. We can thus infer the corresponding p value as
where \(\tilde{\delta }\) has to be varied in a hyperball or a hypercube depending on the volume chosen, and \(\chi _q\) are replaced by their estimated values \(\mu _{\chi _q}\).
6.5 Pull parameters
In addition to the general indication given by goodness-of-fit indicators, it is useful to determine the agreement between individual measurements and the model. One way of quantifying this agreement consists in determining the pull of each quantity. Indeed, the agreement between the indirect fit prediction and the direct determination of some observable X is measured by its pull, which can be determined by considering the difference of minimum values of the test statistic including or not the observables [22]. In the absence of non-Gaussian effects or correlations, the pulls are random variables of vanishing mean and unit variance.
The pull of an observable \(X_m\) can be conveniently computed by introducing an additional pull parameter \(p_{X_m}\) in the test statistic \(T(X_0;\chi ,p_{X_m})\)
The pull parameter \(p_{X_m}\) is a dimensionless fit parameter for which one can compute confidence intervals, or errors and uncertainties. Its best-fit value is a random variable that measures the distance of the indirect prediction (determined by the global fit) from the direct measurement, in units of \(\sigma \). The p value for the null hypothesis \(p_{X_m} = 0\) is by definition the pull for \(X_i\). It can be understood as a comparison of the best-fit value of the test statistic reached letting \(p_{X_a}\) free (corresponding to a global fit without the measurement \(X_m\)) with the case setting \(p_{X_m}=0\) (corresponding to a global fit including the measurement \(X_m\)).
As far as the test statistic is concerned, the pull parameter can be treated on the same footing as the parameters \(\chi \), and it can be determined in the same way as in the previous section, first solving the minimization condition \(\partial T/\partial p_{X_m}=0\), and plugging the result for \(p_{X_m}\) into T, leading to the same expression for T as in Eq. (50), but with \(\bar{W}\) replaced by the matrix
which can be solved as before for \(\hat{\chi }\), leading to the expression for \(\hat{p}_{X_m}\)
If the statistical method allows one to separate the statistical and theoretical contributions to the error on \(p_{X_i}\), one can report the values for the errors \(\varDelta _{p_{X_i}}\) and \(\sigma _{p_{X_i}}\) in addition to the pull itself: this gives an indication of how independent from theoretical uncertainties the underlying tested hypothesis is. One can also extend this notion for N parameters, introducing N distinct pull parameters and determining the p value for the null hypothesis where all pull parameters vanish simultaneously.
As an illustration in a simple case, one can compute the pulls associated with the average of n measurements, introducing the modified test statistic compared to Eq. (44):
corresponding to the case with only one parameter \(\chi =\mu \), \(a=U\), \(b=0\). The minimization with respect to both parameters yields an estimator of the pull parameter in this particular case,
allowing a propagation of errors in a similar way to the average of several measurements discussed in Sects. 6.2.1 and 6.2.2. Numerical examples are presented in Sect. 7.
6.6 Conclusions of the multi-dimensional case
We have discussed several situations where a multi-dimensional approach is needed in phenomenology analysis. In addition to the issues already encountered in one dimension, a further arbitrary choice must be performed in the multi-dimensional case for nuisance and external approaches concerning the shape of the volume in which the biases are varied: two simple cases are given by the hypercube and the hyperball, corresponding, respectively, to the well-known linear and quadratic combination of uncertainties. We have then discussed how to average two (or several) measurements, emphasizing the case of the nuisance approach. We have finally illustrated how a fit could be performed in order to determine confidence regions. Beyond the metrology of the model, we can also determine the agreement between model and experiments thanks to the pull parameters associated with each observable.
The uni-dimensional case (stationarity of the quadratic test statistic under minimization, coverage properties) has led us to prefer the adaptive nuisance approach, even though the fixed nuisance approach could also be considered. In the multi-dimensional case, the hyperball in conjunction with the quadratic test statistic allows us to keep associativity when performing averages, so that it is rigorously equivalent from the statistical point of view to keep several measurements of a given observable or to average them in a single value. We have also been able to discuss theoretical correlations using the hyperball case at two different stages: including the correlations among observables in the domain of variations of the biases when computing the errors \(\varDelta \), and providing a meaningful definition for the theoretical correlation among parameters of the fit. We have not found a way to keep these properties in the case of the hypercube. Moreover, choosing the hypercube may favor best-fit configurations where all the biases are at the border of their allowed regions, whereas the hyperball prevents such ‘fine-tuned’ solutions from occurring.
For comparison, in the following we will focus on two nuisance approaches: fixed 1-hypercube and adaptive hyperball with a preference for the latter. The other combinations would yield far too conservative (adaptive hypercube) or too liberal (fixed 1-hyperball) ranges of variations for the biases.
7 CKM-related examples
We will now consider the differences between the various approaches considered using several examples from quark flavor physics. These examples will be only for illustrative purposes, and we refer the reader to other work [15, 16, 22, 35] for a more thorough discussion of the physics and the inputs involved. From the previous discussion, we could consider a large set of approaches for theoretical uncertainties.
We will restrict to a few cases compared to the previous sections. First, we will consider educated Rfit (Rfit with specific treatment of uncertainties for averages), as used by the CKMfitter analyses and described in Sect. 6.2.4, while the naive Rfit approach will only be shown for the sake of comparison and is not understood as an appropriate model. We will also consider two nuisance approaches, namely the adaptive hyperball and the 1-hypercube cases. Our examples will be chosen in the context of CKM fits, and correspond approximately to the situation for Summer 2014 conferences. However, for pedagogical purposes, we have simplified intentionally some of the inputs compared to actual phenomenological analyses performed in flavor physics [35].
7.1 Averaging theory-dominated measurements
We start by illustrating the case of measurements dominated by theoretical uncertainties, which is the case for the lattice determinations. We take the case of \(B_K\), which is needed to discuss \(K\bar{K}\) mixing, and has been the subject of important debates concerning its agreement (or not) with the rest of the global fit. We have selected a particular list of lattice determinations given in Table 6 (top). For each measurement, we have kept the various theoretical uncertainties separate, since their combination (linear or quadratic) depends on the method used. For purposes of illustration, we perform an average over measurements performed with different lattice gauge actions, we symmetrize the results having asymmetric uncertaintiesFootnote 16 and we neglect all correlations. We stress that this is done only for purposes of illustration, and that an extended list of lattice QCD results with asymmetric uncertainties and correlations will be taken into account in forthcoming phenomenological applications [35].
The results for each method are given in Table 6 (middle). The first column corresponds to the outcome of the averaging procedure. In all the approaches considered, we can split statistical and theoretical uncertainties. In the case of naive Rfit, one combines the measurements by adding the well statistic corresponding to each measurement: the resulting test statistic T is a well with a bottom, the width of which can be interpreted as a theoretical uncertainty, whereas the width at \(T_{\min }+1\) determines the statistical uncertainty.Footnote 17 The case of educated Rfit was described in Sect. 6.2.4. The confidence intervals are obtained from the p value determined from the “average” column.
We compute the pulls in the same way in both cases, interpreting the difference of \(T_\mathrm{min}\) with and without the observables as a random variable distributed according to a \(\chi ^2\) law with \(N_\mathrm{dof}=1\). The propagation of uncertainties for the quadratic statistic was detailed in Sects. 6.2.1 and 6.2.2 where the separate extraction of statistical and theoretical uncertainties was described. The tables are obtained by plugging the average into the one-dimensional p value associated with the method, and reading from the p value the corresponding confidence interval at the chosen significance. The associated pulls are given in Table 6 (bottom).
We present the same analysis in the case of the \(D_s\)-meson decay constant \(f_{D_s}\) in Table 7 (with the same caveat concerning the selected inputs, asymmetries and correlations), while graphical comparisons of the different averages in both cases can be seen at \(1 \sigma \) in Fig. 7 (a similar plot at \(3\sigma \) is given in Fig. 12 in Appendix D).
For both quantities \(B_K\) and \(f_{D_s}\) at large confidence level (3\(\sigma \) and above), the most conservative method is the adaptive hyperball nuisance approach, whereas the one leading to the smallest uncertainties is the educated Rfit approach. Below 3\(\sigma \), the 1-hypercube approach is more conservative than the adaptive hyperball nuisance approach, and it becomes less conservative above that threshold. The most important differences are observed at large CL/significance. The statistical uncertainty obtained in the nG approach is by construction identical to the combination in quadrature of the statistical and theoretical uncertainties obtained in the adaptive hyperball approach. However, one can notice that the confidence intervals for high significances in the two approaches are different, with nG being less conservative. The overall very good agreement of lattice determinations means vanishing pulls for Rfit methods (since all the wells have a common bottom with a vanishing \(T_\mathrm{min}\)). For the other methods, the pull parameter has statistical and theoretical errors of similar size in the adaptive hyperball case, whereas theoretical errors tend to dominate in the 1-hypercube method. This yields smaller pulls in the latter approach.
A last illustration, which does not come solely from lattice simulations, is provided by the determination the strong coupling constant \(\alpha _S(M_Z)\). The subject is covered extensively by recent reviews [34, 51], and we stress that we do not claim to provide an accurate alternative average to these reviews which requires a careful assessment of the various determinations and their correlations. As a purely illustrative example, we will focus on the average of determinations from \(e^+e^-\) annihilation under a set of simplistic hypotheses for the separation between statistical and theoretical uncertainties. In order to allow for a closer comparison with Refs. [34, 62], we try to assess correlations this time. We assume that theoretical uncertainties for the same set of observables (\( j \& s\), 3j, T), but from different experiments, are 100% correlated, and the statistical uncertainties for determinations from similar experimental data are 100% correlated (BS-T, DW-T, AFHMS-T).Footnote 18

Top inputs for \(B_K^{\bar{\mathrm{MS}}}(2\mathrm{GeV})\) and the averages resulting from the different models considered here. Bottom same for the lattice determinations of the \(D_s\)-meson decay constant (in MeV). The black range gives the statistical error. For each individual input, the solid red range indicates the \(1\sigma \) interval according to the adaptive hyperball approach (combining theoretical errors in quadratically) and the dashed red range according to the 1-fixed hypercube approach (combining theoretical errors linearly). For average according to the different approaches, the black range corresponds again to the statistical error, whereas the red range corresponds to the \(1\sigma \) interval following the corresponding approach. The comparison between black and red ranges illustrates the relative importance of statistical and theoretical errors. Finally, for illustrative purposes, the vertical purple line gives the arithmetic average of the inputs (same weight for all central values)
We perform the average in the different cases considered, see Table 8 (middle), which are represented graphically in Fig. 8 (a similar plot at \(3\sigma \) is given in Fig. 13 in Appendix D). We notice that the various approaches yield results with similar central values to the nG case. The pulls for individual quantities are mostly around 1\(\sigma \), and they are smaller in the adaptive hyperball approach compared to the nG one, showing better consistency. Refs. [34, 62] take a different approach, “range averaging”, which amounts to considering the spread of the central values for the various determinations, leading to \(\alpha _S(M_Z)=0.1174 \pm 0.0051\) for the determination from \(e^+e^-\) annihilation data considered here [62]. This approach is motivated in Ref. [34] by the complicated pattern of correlations and the limited compatibility between some of the inputs and, more importantly, it does not take into account that the different determinations have different accuracies according to the uncertainties quoted. The approach in Refs. [34, 62] conservatively accounts for the possibility that some uncertainties are underestimated. On the contrary, our averages given in Table 8 and Fig. 8 assume that all the inputs should be taken into account and averaged according to the uncertainties given in the original articles. The difference in the underlying hypotheses for the averages explain the large difference observed between our results and the ones in Refs. [34, 62]. Note, however, that our numerics directly follow from the use of the different averaging methods, and lack the necessary critical assessment of the individual determinations of \(\alpha _S(m_Z)\) performed in Refs. [34, 62].
7.2 Averaging incompatible or barely compatible measurements
Another important issue occurs when one wants to combine barely compatible measurements. This is for instance the case for \(|V_{ub}|\) and \(|V_{cb}|\) from semileptonic decays, where inclusive and exclusive determinations are not in very good agreement. The list of determinations used for illustrative purposes and the results for each method are given in Tables 9 and 10, together with the corresponding graphical comparisons in Fig. 9 (a similar plot at \(3\sigma \) is given in Fig. 14 in Appendix D). Our inputs are slightly different from Ref. [36] for several reasons. The inclusive determination of \(|V_{ub}|\) corresponds to the BLNP approach [64], and we consider the theoretical uncertainties from shape functions (leading and subleading), weak annihilation, and heavy-quark expansion uncertainties on matching and \(m_b\). We use only branching fractions measured for \(B\rightarrow \pi \ell \nu \) and average the unquenched lattice calculations quoted in Ref. [36]. For \(|V_{cb}|\) exclusive we also split the various sources of theoretical uncertainties coming from the determination of the form factors. We assume that there are no correlations among all these uncertainties.
The lack of compatibility between the two types of determination means in particular that the naive Rfit combined likelihood has not flat bottom, and thus no theoretical uncertainty. This behavior was one of the reasons to propose the educated Rfit approach, where the theoretical uncertainty of the combination cannot be smaller than any of the individual measurements.
The same pattern of conservative and aggressive approaches can be observed, with a fairly good agreement at 3\(\sigma \) level (apart from the naive Rfit approach, already discussed). At 5\(\sigma \), the adaptive hyperball proves again rather conservative, even though the theoretical error of the averages are smaller than the 1-hypercube nuisance and the educated Rfit approaches. The analysis of the pulls yields similar conclusions, with discrepancies at the 2\(\sigma \) for \(|V_{ub}|\) and between 2 and 3\(\sigma \) for \(|V_{cb}|\). Once again, theoretical errors for the pull parameters are larger in the 1-hypercube approach than in the adaptive hyperball case. Let us also notice that in both cases, there are only two quantities to combine, so that the two pull parameters are by construction opposite to each other up to an irrelevant scaling factor, leading to the same pull for both quantities.

Determinations of the strong coupling constant at \(M_Z\) through \(e^+e^-\) annihilation, and the averages resulting from the different models considered here. The intervals are given at 1\(\sigma \). See Fig. 7 for the legend
7.3 Averaging quantities dominated by different types of uncertainties
In order to illustrate the role played by statistical and theoretical uncertainties, we consider the question of averaging quantities dominated by one or the other. This happens for instance when one wants to compare a theoretically clean determination with other determination potentially affected by large theoretical uncertainties. This situation occurs in flavor physics for instance when one compares the extraction of \(\sin (2\beta )\) from time-dependent asymmetries in \(b\rightarrow c\bar{c}s\) and \(b\rightarrow q\bar{q}s\) decays (let us recall that, for the CKM global fit, only charmonium input is used for \(\sin (2\beta )\)). The first have a very small penguin pollution, which we will neglect, whereas the latter is significantly affected by such a pollution. The corresponding estimates of \(\sin (2\beta )\) have large theoretical uncertainties, and for illustration we use the computation done in Ref. [63].
The results are collected in Table 11, which were computed neglecting all possible correlations between the different extractions. One can see that the resulting theoretical uncertainty from the combination of the various inputs remains small, so that most of the approaches yield a very similar result for the confidence intervals. The corresponding pulls show a global consistency concerning the observables that deviate by \(1\sigma \).
7.4 Global fits
In order to illustrate the impact of the treatment of theoretical uncertainties, we consider a global fit including mainly observables that come with a theoretical uncertainty. The list of observables is given in Table 12. Their values are motivated by the CKMfitter inputs used in Summer 2014, but they are used only for purposes of illustration.Footnote 19 We consider two fits: Scenario A involves only constraints dominated by theoretical uncertainties whereas Scenario B includes also constraints from the angles (statistically dominated).
As far as the CKM matrix elements are concerned the Standard Model is linear, but it is not linear in all the other fundamental parameters of the Standard Model. For the illustrative purposes of this note, the first step thus consists in determining the minimum of the full (non-linear) \(\chi ^2\), and to linearize the Standard Model formulas for the various observables around this minimum (we choose the inputs of Scenario B to determine this point): this define an exactly linear model, which at this stage should not be used for realistic phenomenology but is useful for the comparison of the methods presented here. One can use the results presented in the previous section in order to determine the p value as a function of each of the parameters of interest. In the case of the nuisance-\(\delta \) approach, we can describe this p value using the same parameters as before, namely a central value, a statistical error and a theoretical error.
We provide the results for the 4 CKM parameters in both scenarios in Tables 13 and 14 (using the same linearized theory described above). We also indicate the profiles of the p values. As before, we observe that the methods give similar results at the 2–3\(\sigma \) level, although the adaptive hyperball method tends to be more conservative than the others.

Top inclusive and exclusive inputs for the CKM matrix element \( \vert V_{ub} \vert \) (times \( 10^{3} \)) and the averages resulting from the different models considered here. Bottom same for the determinations of \( \vert V_{cb} \vert \) (times \( 10^{3} \)) CKM matrix element. The intervals are given at 1\(\sigma \). See Fig. 7 for the legend
8 Conclusion
A problem often encountered in particle physics consists in analyzing data within the Standard Model (or some of its extensions) in order to extract information on the fundamental parameters of the model. An essential role is played here by uncertainties, which can be classified in two categories, statistical and theoretical. If the former can be treated in a rigorous manner within a given statistical framework, the latter must be described through models. The problem is particularly acute in flavor physics, as theoretical uncertainties often play a central role in the determination of underlying parameters, such as the four parameters describing the CKM matrix in the Standard Model.
This article aims at describing and comparing several approaches that can be implemented in a frequentist framework. After recalling some elements of frequentist analysis, we have discussed three different approaches for theoretical uncertainties: the random-\(\delta \) approach treats theoretical uncertainties as random variables, the external-\(\delta \) approach considers them as external parameters leading to an infinity of p values to be combined through model averaging, the nuisance-\(\delta \) describes them through fixed biases which have to be varied over a reasonable region. These approaches have to be combined with particular choices for the test statistic used to compute the p value. We have illustrated these approaches in the one-dimensional case, recovering the Rfit model used by CKMfitter as a particular case of the external-\(\delta \) approach, and discussing the interesting alternative of a quadratic test statistic.
In the case of the nuisance-\(\delta \) approach, one has to decide over which range the bias parameter should be varied. It is possible to compute the p value by taking the supremum of the bias over a fixed range fixed by the size of the theoretical uncertainty to be modeled (fixed nuisance approach). An alluring alternative consists in adjusting the size of the range to the confidence level chosen: the range for a low confidence level can be obtained by varying the bias parameter in a small range, whereas a range for a high confidence level could require a more conservative (and thus larger) range for the bias parameter. We have designed such a scheme, called adaptive nuisance approach. It provides a unified statistical approach to deal with the metrology of the parameters (for low CL ranges) and the exclusion of models (for high CL ranges).
We have determined the p values associated with each approach for a measurement involving both statistical and theoretical uncertainties. We have also studied the size of error bars, the significance of deviations and the coverage properties. In general, the most conservative approaches correspond to a naive Gaussian treatment (belonging to the random-\(\delta \) approach) and the adaptive nuisance approach. The latter is better defined and more conservative than the former in the case where statistical and theoretical approaches are of similar size. Other approaches (fixed nuisance, external) turn out less conservative at large confidence level.
We have then considered extensions to multi-dimensional cases, focusing on the linear case where the quantity of interest is a linear combination of observables. Due to the presence of several bias parameters, one has to make another choice concerning the shape of the space over which the bias parameters are varied. Two simple examples are the hypercube and the hyperball, leading to a linear or quadratic combination of theoretical uncertainties, respectively. The hypercube is more conservative, as it allows for sets of values of the bias parameters that cannot be reached within the hyperball. On the other hand, the hyperball has the great virtue of associativity, so that one can average different measurements of the same quantity or put all of them in a global fit, without changing its outcome. It also allows us to include theoretical correlations easily, both in the range of variation of biases to determine errors and in the definition of theoretical correlations for the outcome of a fit. We have discussed the average of several measurements using the various approaches, including correlations. We considered in detail the case of 100% correlations leading to a non-invertible covariance matrix. We also discussed global fits and pulls in a linearized context. We have then provided several comparisons between the different approaches using examples from flavor physics: averaging theory-dominated measurements, averaging incompatible measurements linear fits to a subset of flavor inputs.
It is now time to determine which choice seems preferable in our case. Random-\(\delta \) has no strong statistical basis: its only advantage consists in its simplicity. External-\(\delta \) is closer in spirit to the determination of systematics as performed by experimentalists, but it starts with an inappropriate null hypothesis and tries to combine an infinite set of p values in a single p value. On the contrary, the nuisance-\(\delta \) approach starts from the beginning with the correct null hypothesis and deals with a single p value.
This choice is independent from another choice, i.e., the range of variation for the parameter \(\delta \). Indeed, when several bias parameters are involved, one may imagine different multi-dimensional spaces for their variations, in particular the hyperball and the hypercube. As said earlier, the hyperball has the interesting property of associativity when performing averages and avoids fine-tuned solutions where all parameters are pushed in a corner of phase space. The hypercube is closer in spirit to the Rfit model (even though the latter is not a bias model), but it cannot avoid fine-tuned situations and it does not seem well suited to deal with theoretical correlations, since it is designed from the start to avoid such correlations.
A third choice consists in determining whether one wants to keep the volume of variation fixed (fixed approach), or to modify it depending on the desired confidence level (adaptive approach). Adaptive hypercube is in principle the most conservative choice but in practice, it gives too large errors, whereas fixed hyperball would give very small errors. Fixed hypercube is more conservative at low confidence levels (large p values), whereas adaptive hyperball is more conservative at large confidence levels (small p values).
This overall discussion leads us to consider the nuisance approach with adaptive hyperball as a promising approach to deal with flavor physics problems, which we will investigate in more phenomenological analyses in forthcoming publications [35].
Notes
The issue of theoretical uncertainties is naturally not the only question that arises in the context of statistical analyses. The statistical framework used to perform these analyses is also a matter of choice, with two main approaches, frequentist and Bayesian, adopted in different settings and for various problems in and beyond high-energy physics [1,2,3, 8,9,10]. In this paper, we choose to focus on the frequentist approach to discuss how to model theoretical uncertainties.
It may happen that the detector and/or background effects have a sizable impact on the fitted quantities \(\hat{C}\) and \(\hat{S}\); this can be viewed as uncertainties in the modeling of the event PDF f. These effects are reported as systematic uncertainties and in particle physics, it is customary to treat them on the same footing as the pure statistical uncertainties. Although we will not try to follow this avenue in the examples discussed here, it would be possible to consider these systematic uncertainties as theoretical uncertainties, to be modeled according to the methods that we describe in the following sections.
“Nuisance” does not mean that these parameters are necessarily unphysical, “pollution” parameters. They can be fundamental constants of Nature, and interesting as such.
We have defined compositeness for numerical hypotheses, since this is our case of interest in the following. More generally, compositeness also occurs in the case of non-numerical hypotheses such as “The Standard Model is true”, for which it is not possible to compute the distribution of data either. Indeed assuming that the Standard Model is true does not imply anything on the value of its fundamental parameters, and thus one cannot compute the distribution of a given observable under this hypothesis.
Strictly speaking, the likelihood is only defined for the actually measured data \(X_0\): \({\mathcal L}_0(\chi )\equiv g(X_0;\chi )\) and thus is only a function of the parameters \(\chi \). Nevertheless it is common practice to use the word “likelihood” for the object \(g(X;\chi )\), considered as a function of both the observables X and the parameters \(\chi \).
More precisely, the asymptotic limit is reached when the model can be linearized for all values of the data that contribute significantly to the integral (4). It corresponds to the situation where the errors on the parameters derived from computing p values are small with respect to the typical parameter scales of the problem.
A bias is defined as the difference between the average of the estimator among a large number of experiments with finite sample size and the true value. An estimator is said to be consistent if it converges to the true value when the size of the sample tends to infinity (e.g., maximum likelihood estimators). Consistency implies that the bias vanishes asymptotically, while inconsistency may stem from theoretical uncertainties.
We discuss how the method can be adapted for asymmetric uncertainties in Appendix C.
The choice of the weight in the denominator of the test statistic will be discussed in the multi-dimensional case in Sect. 6.2.3, but it does not impact the result for the p value in one dimension where it plays only the role of an overall normalization that cancels when computing the p value.
Such a test statistic tends typically to be less sensitive to discrepancies in a global fit than the likelihood ratio. In the presence of quantities having no or little dependence on the scanned parameters, the impact of discrepancies is diluted in the case of the likelihood statistic.
In full generality, one should have kept the different sources of theoretical uncertainties separated, as their combination in a single theoretical uncertainty depends on the precise model used for theoretical uncertainties. We consider here the result of Ref. [34] where all theoretical uncertainties are already combined.
This is true at least for approaches where theoretical errors are modeled by fixed bias parameters: the combined error on the quantity of interest is a weighted sum as in Eq. (42), and the maximal value of this quantity can only be made always larger than each individual contribution if the corners of the hypercube are included in the maximization region.
This problem does not occur in the hyperball case, where the section of the hyperellipsoid by a hyperplane always yields an ellipse symmetric along the diagonal, with an elongation according to the theoretical correlation between the biases.
As discussed in Sect. 4.4, the overall normalization of \(T(X;\mu )\) is irrelevant to derive uni-dimensional p values.
In this section, we will not deal with asymmetric uncertainties, and for illustrative purpose, we symmetrize all uncertainties, statistical and theoretical, following Eq. (C.39).
In general, for naive Rfit, the tails of the resulting test statistic T are neither Gaussian nor symmetric. However, our approximation is valid to a good accuracy for our illustrative purposes and the examples discussed in this section.
In addition, we have made further choices concerning the separation of statistical and theoretical uncertainties based on the following considerations. Ref. [60] discusses the sources of uncertainties (scales, function parameters, b-quark mass) within a fit leading to uncertainties assumed to be of statistical nature, with a further systematic uncertainty coming from the difference between the two different schemes. The systematic uncertainties in Ref. [57] are assumed to be of statistical nature in the absence of any opposite statement. For the first two classes (j & s and 3j) hadronization is taken into account by Monte Carlo methods, while for the last two classes (T and C) analytic analyses are made: in the former (latter) case, the hadronic uncertainties are treated as statistical (theoretical).
In particular, most of the inputs have several sources of theoretical uncertainties, which should be combined together linearly or in quadrature according to the model of theoretical uncertainties chosen. Since we just want to illustrate the difference between the various approaches at the level of the fit, we take as inputs the values obtained in a given framework (Rfit) without recomputing the averages and uncertainties for each approach.
The definition of \(C_s^+\) can be extended for an arbitrary matrix C in the following way. \(\varSigma \) is defined as the diagonal matrix with entries \(\{\sqrt{|C_{11}|},\ldots \sqrt{|C_{NN}|}\}\) (if a diagonal entry is 0, one defines \(\varSigma \) with 1 in the corresponding entry). The matrix \(\varGamma =\varSigma ^{-1}.C.\varSigma ^{-1} \) can be written according to a singular value decomposition \(\varGamma =R.D.S\) with two rotation matrices R and S. Once the generalized inverse \(D^+\) is defined, the corresponding generalized inverse of C is defined as \(C^+=\varSigma ^{-1}.S^T.D^+.R^T.\varSigma ^{-1}\).
One could try to symmetrize the problem, but one would lose the connection with the Cholesky decomposition, with the unpleasant feature that all domains of variation would be identical and thus do not take into account correlations.
References
F. James, Statistical Methods in Experimental Physics (World Scientific, Hackensack, 2006)
G. Cowan, Statistics for Searches at the LHC. doi:10.1007/978-3-319-05362-2_9. arXiv:1307.2487 [hep-ex]
M.G. Kendall, A. Stuart, The Advanced Theory of Statistics (Griffin, London, 1969)
P. Sinervo, eConf C 030908, TUAT004 (2003)
M. Schmelling, arXiv:hep-ex/0006004
W.A. Rolke, A.M. Lopez, J. Conrad, Nucl. Instrum. Methods A 551, 493 (2005). arXiv:physics/0403059
R.D. Cousins, J.T. Linnemann, J. Tucker, Nucl. Instrum. Meth. A 595, 480 (2008)
W.M. Bolstad, J.M. Curran, Introduction to Bayesian Statistics (Wiley, New York, 2016)
G. D’Agostini, Rep. Prog. Phys. 66, 1383 (2003). doi:10.1088/0034-4885/66/9/201. arXiv:physics/0304102
A.J. Bevan, Statistical Data Analysis for the Physical Sciences (Cambridge Press, Cambridge, 2013)
S. Schael et al., ALEPH and DELPHI and L3 and OPAL and LEP Electroweak Collaborations, Phys. Rep. 532, 119 (2013). arXiv:1302.3415 [hep-ex]
M. Baak et al., Gfitter Group Collaboration, Eur. Phys. J. C 74, 3046 (2014). arXiv:1407.3792 [hep-ph]
R. Aaij et al., LHCb Collaboration, Eur. Phys. J. C 73(4), 2373 (2013). arXiv:1208.3355 [hep-ex]
A.J. Bevan et al., BaBar and Belle Collaborations, Eur. Phys. J. C 74, 3026 (2014). arXiv:1406.6311 [hep-ex]
A. Hocker, H. Lacker, S. Laplace, F. Le Diberder, Eur. Phys. J. C 21, 225 (2001). arXiv:hep-ph/0104062
J. Charles et al., CKMfitter Group Collaboration, Eur. Phys. J. C 41, 1 (2005). arXiv:hep-ph/0406184
J. Charles et al., Phys. Rev. D 84, 033005 (2011). arXiv:1106.4041 [hep-ph]
O. Deschamps, S. Descotes-Genon, S. Monteil, V. Niess, S. T’Jampens, V. Tisserand, Phys. Rev. D 82, 073012 (2010). arXiv:0907.5135 [hep-ph]
A. Lenz et al., Phys. Rev. D 83, 036004 (2011). arXiv:1008.1593 [hep-ph]
A. Lenz, U. Nierste, J. Charles, S. Descotes-Genon, H. Lacker, S. Monteil, V. Niess, S. T’Jampens, Phys. Rev. D 86, 033008 (2012). arXiv:1203.0238 [hep-ph]
J. Charles, S. Descotes-Genon, Z. Ligeti, S. Monteil, M. Papucci, K. Trabelsi, Phys. Rev. D 89(3), 033016 (2014). arXiv:1309.2293 [hep-ph]
J. Charles, O. Deschamps, S. Descotes-Genon, H. Lacker, A. Menzel, S. Monteil, V. Niess, J. Ocariz et al., Phys. Rev. D 91(7), 073007 (2015). arXiv:1501.05013 [hep-ph]
B. Aubert et al., BaBar Collaboration, Phys. Rev. D 79, 072009 (2009). doi:10.1103/PhysRevD.79.072009. arXiv:0902.1708 [hep-ex]
I. Adachi et al., Phys. Rev. Lett. 108, 171802 (2012). doi:10.1103/PhysRevLett.108.171802. arXiv:1201.4643 [hep-ex]
R. Aaij et al., LHCb Collaboration, Phys. Rev. Lett. 115(3), 031601 (2015). doi:10.1103/PhysRevLett.115.031601. arXiv:1503.07089 [hep-ex]
I.I.Y. Bigi, V.A. Khoze, N.G. Uraltsev, A.I. Sanda, Adv. Ser. Direct. High Energy Phys. 3, 175 (1989). doi:10.1142/9789814503280_0004
J. Neyman, E.S. Pearson, Philos. Trans. R. Soc. Lond. A 231, 289–337 (1933)
S.S. Wilks, Ann. Math. Stat. 9(1), 60–62 (1938)
F.C. Porter, arXiv:0806.0530 [physics.data-an]
S. Fichet, G. Moreau, Nucl. Phys. B 905, 391 (2016). arXiv:1509.00472 [hep-ph]
S. Fichet, Nucl. Phys. B 911, 623 (2016). arXiv:1603.03061 [hep-ph]
G. . Dubois-Felsmann, D.G. Hitlin, F.C. Porter, G. Eigen, arXiv:hep-ph/0308262
G. Eigen, G. Dubois-Felsmann, D.G. Hitlin, F.C. Porter, Phys. Rev. D 89(3), 033004 (2014). arXiv:1301.5867 [hep-ex]
K.A. Olive et al., Particle Data Group Collaboration, Chin. Phys. C 38, 090001 (2014)
J. Charles et al., Work in progress
Y. Amhis et al., Heavy Flavor Averaging Group (HFAG) Collaboration, arXiv:1412.7515 [hep-ex]
S. Aoki et al., arXiv:1607.00299 [hep-lat]
M. Schmelling, Phys. Scr. 51, 676 (1995)
H. Ruben, Ann. Math. Stat. 33(2), 542–570 (1962)
A. Castaño-Martnez, F. López-Blázquez, TEST 14, 397 (2005)
M. Constantinou et al., ETM Collaboration, Phys. Rev. D 83, 014505 (2011). arXiv:1009.5606 [hep-lat]
J. Laiho, R.S. Van de Water, PoS LATTICE 2011, 293 (2011). arXiv:1112.4861 [hep-lat]
S. Durr, Z. Fodor, C. Hoelbling, S.D. Katz, S. Krieg, T. Kurth, L. Lellouch, T. Lippert et al., Phys. Lett. B 705, 477 (2011). arXiv:1106.3230 [hep-lat]
R. Arthur et al., RBC and UKQCD Collaborations, Phys. Rev. D 87, 094514 (2013). arXiv:1208.4412 [hep-lat]
T. Bae et al., SWME Collaboration, arXiv:1402.0048 [hep-lat]
B. Blossier et al., JHEP 0907, 043 (2009). arXiv:0904.0954 [hep-lat]
C.T.H. Davies, C. McNeile, E. Follana, G.P. Lepage, H. Na, J. Shigemitsu, Phys. Rev. D 82, 114504 (2010). arXiv:1008.4018 [hep-lat]
A. Bazavov et al., Fermilab Lattice and MILC Collaboration, Phys. Rev. D 85, 114506 (2012). arXiv:1112.3051 [hep-lat]
A. Bazavov et al., Fermilab Lattice and MILC Collaborations, Phys. Rev. D 90(7), 074509 (2014). arXiv:1407.3772 [hep-lat]
N. Carrasco, P. Dimopoulos, R. Frezzotti, P. Lami, V. Lubicz, F. Nazzaro, E. Picca, L. Riggio et al., Phys. Rev. D 91(5), 054507 (2015). arXiv:1411.7908 [hep-lat]
D. d’Enterria,P.Z. Skands, arXiv:1512.05194 [hep-ph]
G. Dissertori, A. Gehrmann-De Ridder, T. Gehrmann, E.W.N. Glover, G. Heinrich, G. Luisoni, H. Stenzel, JHEP 0908, 036 (2009). arXiv:0906.3436 [hep-ph]
G. Abbiendi et al., OPAL Collaboration, Eur. Phys. J. C 71, 1733 (2011). arXiv:1101.1470 [hep-ex]
S. Bethke et al., JADE Collaboration, Eur. Phys. J. C 64, 351 (2009). arXiv:0810.1389 [hep-ex]
G. Dissertori, A. Gehrmann-De Ridder, T. Gehrmann, E.W.N. Glover, G. Heinrich, H. Stenzel, Phys. Rev. Lett. 104, 072002 (2010). arXiv:0910.4283 [hep-ph]
J. Schieck et al., JADE Collaboration, Eur. Phys. J. C 73(3), 2332 (2013). arXiv:1205.3714 [hep-ex]
T. Becher, M.D. Schwartz, JHEP 0807, 034 (2008). arXiv:0803.0342 [hep-ph]
R.A. Davison, B.R. Webber, Eur. Phys. J. C 59, 13 (2009). arXiv:0809.3326 [hep-ph]
R. Abbate, M. Fickinger, A.H. Hoang, V. Mateu, I.W. Stewart, Phys. Rev. D 83, 074021 (2011). arXiv:1006.3080 [hep-ph]
T. Gehrmann, G. Luisoni, P.F. Monni, Eur. Phys. J. C 73(1), 2265 (2013). arXiv:1210.6945 [hep-ph]
A.H. Hoang, D.W. Kolodrubetz, V. Mateu, I.W. Stewart, Phys. Rev. D 91(9), 094018 (2015). arXiv:1501.04111 [hep-ph]
S. Bethke, G. Dissertori, G.P. Salam, EPJ Web Conf. 120, 07005 (2016). doi:10.1051/epjconf/201612007005
M. Beneke, Phys. Lett. B 620, 143 (2005). arXiv:hep-ph/0505075
B.O. Lange, M. Neubert, G. Paz, Phys. Rev. D 72, 073006 (2005). arXiv:hep-ph/0504071
Acknowledgements
We would like to thank S. T’Jampens for collaboration at an early stage of this work, as well as all our collaborators from the CKMfitter group for many useful discussions on the statistical issues covered in this article. We would also like to express a special thanks to the Mainz Institute for Theoretical Physics (MITP) for its hospitality and support during the workshop “Fundamental parameters from lattice QCD” where part of this work was presented and discussed. LVS acknowledges financial support from the Labex P2IO (Physique des 2 Infinis et Origines). SDG acknowledges partial support from Contract FPA2014-61478-EXP. This project has received funding from the European Unions Horizon 2020 research and innovation programme under Grant agreements Nos. 690575, 674896 and 692194.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Singular covariance matrices
1.1 Appendix A.1: Inversion of the covariance matrix
In Sect. 6.2.2, we perform the average of N measurements relying on a test statistic involving the inverse of the statistical covariance and the theoretical correlation matrices. In the case where at least two observables are fully correlated, these matrices are singular and they cannot be inverted naively. One must thus determine a generalized inverse for these matrices. For definiteness, we consider the case where only statistical uncertainties are involved. The statistical test reads
where U is a vector containing N times the unit value, \(\bar{W}=C_s^+\) is a generalized inverse of the covariance matrix \(C_s\) (identical to \(C_s^{-1}\) if the matrix \(C_s\) is not singular).
Minimizing T yields
We have to choose a generalized inverse \(C_s^{+}\). We cannot rely on arguments based on the case where \(C_s\) is invertible (for instance taking a correlation \(0<\rho <1\), followed by the limit \(\rho \rightarrow 1\)) since this limit is singular. We can start by constraining the structure of \(C_s^{+}\) due to the particular structure of \(C_s\). We have
where \(\varSigma \) is a diagonal matrix with uncertainties as entries \(\{\sigma _1,\ldots \sigma _n\}\), \(\varGamma \) the correlation matrix with entries between \(-1\) and 1 (and diagonal entries equal to 1), R is an orthogonal matrix, and D is a diagonal matrix with entries in decreasing order,
The entries of D are positive since \(C_s\) is assumed to be positive, with
A generalized inverse for \(C_s\) can be expressed in terms of a generalized inverse for D, if we define
Indeed a generalized inverse for \(C_s\) obeys \(C_sC_s^+C_s=C_s\), which is equivalent to the condition
where d is the \(m\times m\) diagonal matrix with entries \(d_i\), A is an \(m \times (n-m)\) arbitrary matrix and B is an \((n-m)\times (n-m)\) arbitrary matrix. A and B can only depend on \(d_1,\ldots , d_m\), and each choice of A and B corresponds to an admissible generalized inverse.
Under these conditions, we find for the weights and the variance
1.2 Appendix A.2: Choice of a generalized inverse
The most common generalized inverse is the Moore–Penrose pseudoinverse, obtained by adding three other conditions on \(C_s^+\) on top of the definition of a generalized inverse. The condition \(C_s^+C_sC_s^+=C_s^+\) (reflexive generalized inverse) would translate as \(D^+ \cdot D \cdot D^+=D^+\) leading to the condition \(B=A^T \cdot d \cdot A\) in Eq. (A.7), whereas the two other conditions for the Moore–Penrose inverse of \(C_s^+\) do not translate easily on \(D^+\). Unfortunately, we will see in explicit examples that this pseudoinverse gives more weight to measurements with a poor accuracy, and is thus not appropriate in our case.
An alluring alternative to obey Eq. (A.7) consists in considering \(A=0\) and \(B=\lambda \times 1_{(n-m)\times (n-m)}\) proportional to the identity, with \(\lambda \) a real number to be fixed. In this case, the weights read
Let us assume that \(\sigma _a\) becomes much smaller than the other \(\sigma _i\), the weights are dominated by
Since the first (normalization) factor is the same for all the inputs, the dominant weight will be \(w_a\), under the condition that
which is a condition fulfilled for \(0<\lambda \le 1/d_1\). We see that the family of generalized inverses thus definedFootnote 20 has the following properties:
-
they can be computed in a very simple way,
-
for \(0<\lambda \le 1/d_1\), if a determination is much more precise than the others, it will dominate the average.
For \(\lambda =1/d_1\), we call \(C_s^+\) the \(\lambda \)-inverse of \(C_s\). For \(\lambda =0\), we recover the Moore–Penrose pseudoinverse for D, and call this generalized inverse the 0-inverse of \(C_s\). As said earlier, one could also consider the possibility of taking the Moore–Penrose pseudoinverse of \(C_s\) directly. We will illustrate these three possibilities with a few simple examples.
1.3 Appendix A.3: Examples
1.3.1 Appendix A.3.1: Two measurements
In the case of two uncorrelated measurements, there is no problem with inversion, and we get for all methods
For partially correlated measurements (\(|\rho |<1\)), the same inversion can be performed, leading to
and the expression for the uncertainty
In each case, we indicate the limit where \(\sigma _1\) becomes much smaller than \(\sigma _2\) with the \(\sim \) symbol, i.e., one measurement is much more accurate than the other. A comment is in order with respect to the HFAG approach at this stage. As noticed in Ref. [36], the maximal uncertainty is \(\min (\sigma _1^2,\sigma _2^2)\) and corresponds to the correlation coefficient \(\rho =\min (\sigma _1/\sigma _2,\sigma _2/\sigma _1)\) (it is not \(\rho =1\)).
In the case of two fully correlated measurements, we have
with \(d_1=2\), \(d_2=0\). The \(\lambda \)-inverse for \(C_s\) yields
where we indicated the limit when \(\sigma _1\rightarrow 0\). The 0-inverse yields
and the Moore–Penrose pseudoinverse yields
1.3.2 Appendix A.3.2: n fully correlated measurements
We have a correlation matrix \(\tilde{C}_s\) with unit entries everywhere. This yields \(d_1=n\), \(d_{i>1}=0\). The \(\lambda \)-inverse yields
where we indicated the limit when \(\sigma _1\rightarrow 0\). The 0-inverse yields
The Moore–Penrose pseudoinverse yields
We can actually show that in this situation, the choice of the \(\lambda \)-inverse is optimal in the family of generalized inverses defined in Appendix A.2. Indeed, there is only one non-vanishing eigenvalue \(d_1=n\), leading to
which is minimal for the maximal value \(\lambda =1/d_1\), corresponding to the \(\lambda \)-inverse.
1.3.3 Appendix A.3.3.: Two fully correlated measurements with an uncorrelated measurement
Let us consider
with \(d_1=2\), \(d_2=1\), \(d_3=0\).
The \(\lambda \)-inverse for \(C_s\) yields
The 0-inverse for \(C_s\) yields
The Moore–Penrose pseudoinverse yields
1.4 Appendix A.4: Choice of the inverse
In the above examples, the \(\lambda \)-inverse yields interesting results for the generalized inverse in cases that are likely to be useful. In the limit where one measurement becomes very accurate, it dominates the average. In this situation, other generalized inverses of the same family, like the 0-inverse, yield results of the same order, but larger, for the combined uncertainty, whereas the Moore–Penrose pseudoinverse yields a combined uncertainty dominated by the least precise measurements. For 100% correlated uncertainties, the \(\lambda \)-inverse recovers Schmelling’s proposal [38] used by the Flavor Lattice Averaging Group [37], and it does not run into the danger of underestimating the resulting uncertainty as discussed by the Heavy Flavor Averaging Group [36].
For these reasons, we choose the \(\lambda \)-inverse to compute both the inverse statistical covariance matrix and the inverse theoretical correlation matrix when these matrices are singular (the regular case being trivial).
Appendix B: Varying the biases in the presence of theoretical correlations
1.1 Appendix B.1: Range of variations for the biases
Another issue consists in implementing correlations for the biases describing theoretical uncertainties. Some differences occur compared to statistical uncertainties, since different models are used in both cases (random variables versus biases). As described in Sect. 6.2.2, once the weights \(w_i\) are determined, the theoretical uncertainty is given by \(\delta _\mu =\sum _i w_i \varDelta _{i\alpha } \tilde{\delta }_\alpha \), which requires one to determine the range of variation for the normalized biases \(\tilde{\delta }_\alpha \). We want to describe their variation starting from variations of uncorrelated variables. This can be achieved through a linear transformation by introducing the Cholesky decomposition for the theoretical correlation matrix \(C_t=P\cdot P^T\) with P a lower triangular matrix with diagonal positive entries. We obtain the expression for the theoretical uncertainty
where \((P^{-1}\tilde{\delta })_j\) are uncorrelated biases varied in a hyperball, leading to
There is an ambiguity in the definition of P when \(C_t\) is only semi-definite positive (which occurs when \(C_t\) is singular due to 100% correlations, and exhibits not only positive but also vanishing eigenvalues). We define then P by computing \(P(\epsilon )\) for the shifted matrix \(C_t + \epsilon \times 1_{m\times m}\) and defining \(P=\lim _{\epsilon \rightarrow 0^+}P(\epsilon )\). This limit is not singular, and it allows one to define the limit of two measurements fully correlated theoretically as a smooth limit of the general case with a partial correlation.
One should emphasize that in the case of a singular correlation matrix \(C_t\) for theoretical uncertainties, we may have to treat this singularity at two different stages: first when we build the test statistic involving \(\bar{W}\) (depending on the structure of the statistical and theoretical correlation matrices), second when we consider the domain of variation for the parameters \(\tilde{\delta }\). We stress that we used different procedures in both cases (\(\lambda \)-inverse for \(\bar{W}\), Cholesky decomposition for \(\tilde{\delta }\)), which involves some arbitrariness, but reproduces desirable properties for the combined uncertainties and domains of variation of the biases in this singular limit.

Ranges of variation for \(\tilde{\delta }_1\) and \(\tilde{\delta }_2\) for \(\rho =0,0.2,0.5,0.9,1\), going from light (yellow) to dark (red). The variation over a hyperball (left) or a hypercube (right) is considered
In the case of a hypercube, we may want to follow the same procedure and define
The question mark indicates that this definition is only tentative, and will not actually be used. Indeed, as discussed in Sect. 6.2.3 and illustrated in the following sections, this definition has the rather unpleasant feature that the ranges of variations depend on the order of the inputs used, and we have not been able to identify an alternative choice for the range of variations that would avoid this problem, which does not occur in the hyperball case. These difficulties could be somehow expected from the properties of the hypercube case discussed in Sect. 6.2.1. Indeed, in the case of two measurements, the hypercube corresponds to values of \(\delta _1\) and \(\delta _2\) left free to vary without relation among them (contrary to the hyperball case). It seems therefore difficult to introduce correlations in this case which was designed to avoid them initially. Our failure to introduce correlations in this case might be related to the fact that the hypercube is somehow designed to avoid such correlations from the start and cannot accommodate them easily.
We thus propose the alternative definition, ignoring theoretical correlations to determine the range of variations for the biases

Ranges of variation for \(\tilde{\delta }_1,\tilde{\delta }_2,\tilde{\delta }_3\) with \(\rho _{12}=0.4,\rho _{13}=0.7,\rho _{23}=0\). The variation over a hyperball (top) or a hypercube (bottom) with correlations is considered. Neglecting correlations would yield discs (top) and squares (bottom)
1.2 Appendix B.2: Averaging measurements with theoretical correlations
If we take two measurements \(X_1\pm \sigma _1 \pm \varDelta _1\) and \(X_2\pm \sigma _2\pm \varDelta _2\) with \(\sigma _1\) and \(\sigma _2\) uncorrelated, but \(\varDelta _1\) and \(\varDelta _2\) correlated with a correlation \(\rho \), one gets the Cholesky decomposition
so that the variations for the two (normalized) biases \(\tilde{\delta }_1\) and \(\tilde{\delta }_2\) are given by
where \(d_1\) and \(d_2\) are varied in a hyperball or a hypercube following Eqs. (B.28) and (B.29), respectively. Equation (B.30) would correspond to neglecting correlations and setting \(\rho =0\) in Eq. (B.32).
In the case of a hypercube with correlations, \(\tilde{\delta }_1,\tilde{\delta }_2\) are varied in a parallelogram with two sides parallel to the \(\tilde{\delta }_2\) axis, whereas they are varied in a tilted ellipse in the hyperball case, as can be seen in Fig. 10. In both cases, the limiting case where \(\rho \rightarrow \pm 1\) corresponds to \(\tilde{\delta }_1\) and \(\tilde{\delta }_2\) varied along a diagonal line, meeting our expectations for fully correlated theoretical uncertainties. We see that this treatment yields a symmetric domain for \(\tilde{\delta }_1\) and \(\tilde{\delta }_2\) in the hyperball case, but not in the hypercube case, which means that the two uncertainties are not treated in a symmetric way.Footnote 21 As indicated before, Eq. (B.30) corresponds to the hypercube with \(\rho =0\), i.e., a square domain for \(\tilde{\delta }_1\) and \(\tilde{\delta }_2\).
One can easily extend the same procedure to a larger number of correlated theoretical uncertainties. As indicated above, the hyperball with correlations yields domains of variations which are symmetric for any pair \((\tilde{\delta }_k,\tilde{\delta }_l)\) whereas the hypercube with correlations does not. This means that the range of variation chosen for the biases will depend on the order of the inputs: a mere reshuffling of the inputs will yield different ranges of variations for the biases and (in general) different outcomes for averages and fits. In addition, we should emphasize that a total correlation \((C_t)_{k,l}=0\) between two biases does not have the same impact for the domain of variation in the \((\tilde{\delta }_k,\tilde{\delta }_l)\) plane in both approaches: in the hyperball case, one obtains an undeformed disk, whereas the hypercube case yields a complicated convex polytope depending on the other elements of the correlation matrix (see Fig. 11 in the case of three biases) (a symmetrization of the Cholesky decomposition in the form \(P+P^T\) or a different choice of linear transformation would yield similar results).
These features lead us to neglect correlations in the hypercube range of variations, whereas we keep them when considering the hyperball case. We thus discard Eq. (B.29) and consider only Eqs. (B.28) and (B.30) in our analyses.
Appendix C: Definition of the test statistic in n dimensions
1.1 Appendix C.1: Ambiguities in the definition of a 100% theoretical correlation
In Eq. (34), one may be uncertain about the case where a theoretical uncertainty is fully correlated between two observables. Let us imagine that we have two quantities \(X_1=X_{10}\pm \sigma _1 \pm \varDelta _1\) and \(X_2=X_{20}\pm \sigma _2 \pm \varDelta _2\) with the two theoretical uncertainties being fully correlated. We can imagine describing the theoretical uncertainties either via \(m=2\) parameters fully correlated through \(\widetilde{C}_t\):
or as \(m=1\) parameter intervening in the two quantities via \(\varDelta \)
We can see in the above discussion that the only relevant combination of \(\varDelta \) and \(\widetilde{C}_t\) is actually \(\varDelta P\), whether in the definition of \(\bar{W}\) that involves \(\varDelta \widetilde{C}_t \varDelta ^T=(\varDelta P) (\varDelta P)^T\), or in the discussion of the theoretical uncertainty \(\varDelta _\mu \). We have
leading to the same \(\varDelta \widetilde{C}_t \varDelta ^T\) and showing that only one uncorrelated bias parameter is needed in both cases, even though we started from a different number of bias parameters. The discussion can be extended to an arbitrary number of fully correlated theoretical uncertainties. Obviously, for partial correlations, only \(\widetilde{C}_t\) can be used with an unchanged number of bias parameters.
1.2 Appendix C.2: Reducing the problem to one bias parameter per observable
We can define a reduced version of the problem Eq. (34), with only n bias parameters rather than m. We have to determine an equivalent problem
where \(\bar{W}'_t\) and \(\varDelta '\) are \(n\times n\) matrices, and \(\varDelta '\) is diagonal. From what was discussed before, we see that we will obtain the same result for the weights \(w^{(q)}\), the variances and the correlations, if we ensure that \(\varDelta P=\varDelta ' P'\).
This can be achieved by defining \(\varDelta '\) and the correlation matrix \(\widetilde{C}'_t\) using
\(\widetilde{C}_t\) is positive semi-definite, which means that \(\varDelta \widetilde{C}_t \varDelta ^T\) will also be. The diagonal elements of a positive semi-definite matrix are positive, and therefore, one can define \(\varDelta '\) so that \(\widetilde{C}'_t\) has 1 as a diagonal.
It could occur that \(\varDelta \widetilde{C}_t \varDelta ^T\) has 0 on the diagonal for some \(k^{th}\) entry. But since \(\varDelta \widetilde{C}_t \varDelta ^T\) is positive semi-definite, one can prove that the corresponding row and column then vanish, meaning that the corresponding bias parameter does not actually occur in the reduced problem. In such a case, one can define \(\varDelta '_k=0\) and \(C'_t\) vanishing on the \(k^{th}\) row and column, and \(C'_{t,kk}=1\) (this is the case for instance if there is no theoretical uncertainty for some of the observables).
Moreover, one can check that \(\widetilde{C}'\) is indeed a correlation matrix by defining the scalar product \((x,y)=x^T \varDelta \widetilde{C}_t \varDelta ^T y\). We can apply the Cauchy–Schwartz inequality to the basis vectors \(u^{(i)}\) defined so that \(u^{(i)}_j=\delta _{ij}\) (i.e., only one non-vanishing component):
so that \(|\widetilde{C}'_{t,ij}|\le 1\) and \(\widetilde{C}'_{t,ii}= 1\), with the appropriate structure of a correlation matrix.
Finally, the Cholesky decomposition of \(\widetilde{C}'_t\) corresponds to \(P'=(\varDelta ')^{-1}\varDelta P\). Therefore, the determination of the theoretical uncertainties for \(\varDelta _\mu \) remains indeed the same with the new set of biases.
We have thus reduced the problem of n measurements and m theoretical biases to the case with n measurements, each of them having with a single bias parameter, with correlations among the biases. Without loss of generality we can consider that \(\varDelta \) is diagonal and \(m=n\).

Top inputs for \(B_K^{\bar{\mathrm{MS}}}(2\mathrm{GeV})\) and the averages resulting from the different models considered here. Bottom same for the lattice determinations of the \(D_s\)-meson decay constant (in MeV). The black range gives the statistical error. For each individual input, the solid yellow range indicates the 3\(\sigma \) interval according to the adaptive hyperball approach, whereas the interval corresponding to the 1-fixed hypercube approach is given by the vertical lines in the middle of the solid yellow intervals. For average according to the different approaches, the black range corresponds again to the 3\(\sigma \) statistical error, whereas the yellow range corresponds to the 3\(\sigma \) interval following the corresponding approach. The comparison between black and yellow ranges illustrates the relative importance of statistical and theoretical errors. Finally, for illustrative purposes, the vertical purple line gives the arithmetic average of the inputs (same weight for all central values)

Determinations of the strong coupling constant at \(M_Z\) through \(e^+e^-\) annihilation, and the averages resulting from the different models considered. The intervals are given at 3\(\sigma \). See Fig. 12 for the legend

Top inclusive and exclusive inputs for the CKM matrix element \( \vert V_{ub} \vert \) (times \( 10^{3} \)) and the averages resulting from the different models considered here. Bottom same for the determinations of \( \vert V_{cb} \vert \) (times \( 10^{3} \)) CKM matrix element. The intervals are given at 3\(\sigma \). See Fig. 12 for the legend
Appendix D: Asymmetric uncertainties
In this article, statistical uncertainties are assumed to be strictly Gaussian and hence symmetric. In practice, if asymmetric uncertainties are quoted, we symmetrize in the following manner:
This is also the case for the theoretical uncertainties in the random-\(\delta \) approach.
In contrast, it is perfectly possible to have asymmetric theoretical uncertainties in the nuisance-\(\delta \) or external-\(\delta \) approaches described above. A theoretical uncertainty that is modeled by a bias parameter \(\delta \) may be asymmetric: that is, the region in which \(\delta \) is varied may depends on the sign of \(\delta \), e.g. \(\delta \in [-\varDelta _-,+\varDelta _+]\) in one dimension (\(\varDelta _\pm \ge 0\)).
In the case of a quadratic test statistic, we want to keep the stationarity property stemming from the symmetric quadratic shape, by using a test statistic Eq. (22) with \((\varDelta _++\varDelta _-)/2\) or Max\((\varDelta _+,\varDelta _-)\) in the definition, the second possibility being more conservative and our preferred choice in the following. As indicated in Sect. 6.2.2, this is independent of the range of variation \(\varOmega \) chosen, which will be kept asymmetric, e.g., \([-\varDelta _-,\varDelta _+]\) in the fixed nuisance approach.
In the case of the Rfit approach [15, 16], we can use the fact that the well test statistic has a shape that is independent of the central value chosen, as long as the position of the flat bottom remains unchanged. One can thus shift the central value by an arbitrary quantity if one remains at the bottom of the well. It is thus completely equivalent to take asymmetric theoretical ranges or to take symmetric theoretical ranges following Eq. (C.39) where \(\sigma _\pm \) is replaced by \(\varDelta _\pm \).
Appendix D: 3-\(\sigma \) intervals for CKM-related examples
We collect here the intervals at 3\(\sigma \) for the various approaches applied to the CKM examples discussed in Sect. 7. Figures 12, 13 and 14 are the 3-\(\sigma \) equivalents of Figs. 7, 8 and 9 showing 1\(\sigma \) intervals. The comparison between the two series of plot shows how the intervals evolve with the confidence level. In particular, the adaptive hyperball approach appears more (less) conservative than the 1-hypercube approach at high (low) significance. This change of hierarchy explains why we choose a different convention to plot the 1\(\sigma \) (dashed horizontal line) and 3\(\sigma \) (vertical lines in the middle of the solid intervals) intervals for the 1-hypercube approach in Figs. 7, 8, 9 on one hand and Figs. 12, 13, 14 on the other hand.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Charles, J., Descotes–Genon, S., Niess, V. et al. Modeling theoretical uncertainties in phenomenological analyses for particle physics. Eur. Phys. J. C 77, 214 (2017). https://doi.org/10.1140/epjc/s10052-017-4767-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-017-4767-z