
Abstract
A detailed study of pseudorapidity densities and multiplicity distributions of primary charged particles produced in proton–proton collisions, at \(\sqrt{s} =\) 0.9, 2.36, 2.76, 7 and 8 TeV, in the pseudorapidity range \(|\eta |<2\), was carried out using the ALICE detector. Measurements were obtained for three event classes: inelastic, non-single diffractive and events with at least one charged particle in the pseudorapidity interval \(|\eta |<1\). The use of an improved track-counting algorithm combined with ALICE’s measurements of diffractive processes allows a higher precision compared to our previous publications. A KNO scaling study was performed in the pseudorapidity intervals \(|\eta |<\) 0.5, 1.0 and 1.5. The data are compared to other experimental results and to models as implemented in Monte Carlo event generators PHOJET and recent tunes of PYTHIA6, PYTHIA8 and EPOS.
Similar content being viewed by others

1 Introduction
The multiplicity of emitted charged particles is one of the most basic characteristics of high-energy hadron collisions and has been the subject of longstanding experimental and theoretical studies, which have shaped the understanding of the strong interaction. Following on from earlier ALICE studies of global properties of proton–proton (pp) collisions [1,2,3,4,5,6,7,8], this publication presents a comprehensive set of measurements of the pseudorapidity density (\({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\)) of primaryFootnote 1 charged particles and of their multiplicity distributions over the energy range covered by the LHC, from 0.9 to 8 TeV. The pseudorapidity density of primary charged particles was studied over the pseudorapidity range \(|\eta |<2\), and their multiplicity distributions in three intervals: \(|\eta |<0.5\), 1.0 and 1.5. Results are given for three conventional event classes: (a) inelastic (INEL) events, (b) non-single diffractive (NSD) events and (c) events with at least one charged particle in \(|\eta |<1\) (INEL0).
At LHC energies, particle production is still dominated by soft processes but receives significant contributions from hard scattering, thus multiplicity and other global event properties measurements allow to explore both components. As these properties are used as input in Glauber inspired models [9,10,11,12], such studies are also contributing to a better modelling of Pb–Pb collisions. Already at 8 TeV, high multiplicity proton–proton collisions provide energy densities comparable, for instance, to energy densities in Au–Au central collisions at RHIC, allowing a comparison of nuclear matter properties in strongly interacting systems with similar energy densities but with volumes orders of magnitude smaller.
It is worth noting that, already at \(\sqrt{s} = 2.36\) TeV, hadron collision models tuned to pre-LHC data failed to reproduce basic characteristics of proton–proton collisions at the LHC, such as pseudorapidity density of charged particles, multiplicity distributions, particle composition, strangeness content, transverse momentum distributions and sphericity (see for instance [2,3,4, 13]). Therefore, a more precise measurement of charged-particle multiplicity distributions and a study of their energy dependence contribute to a better understanding of particle production mechanisms and serve to improve models. In turn, a better simulation of collision properties improves the determination of the detector response and background estimates of underlying event properties relevant to the study of high-\(p_{\mathrm {T}}\) phenomena.
In the Regge theory [14,15,16], one of the most successful models for describing soft hadronic interactions, the asymptotic behaviour of cross-sections for elastic scattering and multiple production of hadrons is determined by the properties of the Pomeron, the t-channel right-most pole, in the elastic scattering amplitude. In QCD, the Pomeron, which has vacuum quantum numbers, is usually related to gluonic exchanges in the t-channel. The experimentally observed increase of the total cross-section with increasing collision energy made it necessary to consider a Pomeron as a Regge trajectory with \(t = 0\) intercept: \(\alpha _{P}(0) = 1 + \Delta > 1\) [14]. The energy dependence of the particle (pseudo-)rapidity density provides information about the Pomeron trajectory intercept parameter, \(\Delta \). If interactions between Pomerons are neglected, the inclusive particle production cross-section, \(\sigma _{\mathrm {Incl.}}\), is determined only by the contribution of the single (cut-)Pomeron exchange diagram. In this approximation, \({\mathrm {d} \sigma _{\mathrm {Incl.}}}/{\mathrm {d}y}\ ({\sim } {\mathrm {d} \sigma _{\mathrm {Incl.}}}/{\mathrm {d}\eta })\) at mid-rapidity is proportional to \(s^{\Delta }\) [17]. Thus, the energy dependence of the inclusive cross-section gives more reliable information about the value of \(\Delta \) than the energy dependence of the total interaction cross-section, for which contributions from multi-Pomeron exchanges strongly modify the energy dependence of the single Pomeron exchange diagram. In the same approximation, the energy dependence of the particle (pseudo-)rapidity density in the central rapidity region is given by \({\mathrm {d} N}/{\mathrm {d}y}\propto {s^{\Delta }}/{\sigma _{\mathrm {Int.}}}\), where \(\sigma _{\mathrm {Int.}}\) is the interaction cross-section (see for instance [18,19,20,21]). Up to LHC energies, \(\sigma _{\mathrm {Int.}}\) is well represented by a power law of s. However, for reasons of unitarity [22], it is expected that this power law should be broken at sufficiently high energy, although well above LHC energies. Therefore, the energy dependence of the particle (pseudo-) rapidity density in the central region at LHC, \({\mathrm {d} N}/{\mathrm {d}y} \approx {\mathrm {d} N}/{\mathrm {d}\eta }\), should follow the same power law trend. In this publication, this relationship is explored further for three event classes and using 5 ALICE data points.
It was more than 40 years ago that Polyakov [23] and then Koba et al. [24] proposed that the probability distribution of producing n particles in a collision, P(n), when expressed as a function of the average multiplicity, \(\langle n\rangle \), should reach an asymptotic shape at sufficiently high energy
where \(\Psi \) is a function supposed to describe the energy-invariant shape of the multiplicity distribution. Such scaling behaviour is a property of particle multiplicity distributions known today as Koba–Nielsen–Olesen (KNO) scaling.
One well identified mechanism for KNO scaling violation is the increasing probability of multi-parton scattering with increasing \(\sqrt{s}\). Moreover, since the topologies and multiplicities of diffractive and non-diffractive (ND) events are different, their KNO behavior may be different. Even if KNO scaling were to be valid for each, it might not be valid for their sum. Nevertheless, KNO scaling is expected to be violated for both diffractive and non-diffractive processes [25, 26] at sufficiently high collision energies and the LHC provides the best opportunity to study the extent of these scaling violations.
Indeed, deviation from KNO scaling was already observed long ago at ISR energies (proton–proton collisions at \(\sqrt{s}\) from 30.4 to 62.2 GeV), in the full phase space, for inelastic events [27]. On the other hand, for NSD collisions, scaling was still found to be present [27], suggesting that diffractive processes might also play a role in KNO scaling violations. In e\(^+\)e\(^-\) collisions, at \(\sqrt{s}\) from 5 to 34 GeV, KNO scaling was found to hold within \({\pm } 20\)% [28]. In proton–antiproton collisions at the CERN collider (\(\sqrt{s} = 200,\) 546 and 900 GeV), KNO scaling was found to be violated for NSD collisions in full phase space [29,30,31]. Nevertheless, for NSD collisions, in limited central pseudorapidity intervals, KNO scaling was still found to hold up to 900 GeV, and at \(\sqrt{s} = 546\) GeV, KNO scaling was found to hold in the pseudorapidity interval \(|\eta |< 3.5\) [32, 33]. In NSD proton–proton collisions at the LHC, at \(\sqrt{s} = 2.36\) and 7 TeV and in \(|\eta |<0.5\), ALICE [2] and CMS [34] observed no significant deviation from KNO scaling.
This publication presents a study of KNO scaling, at \(\sqrt{s}\) from 0.9 to 8 TeV, in three pseudorapidity intervals (\(|\eta |< 0.5,\) 1.0 and 1.5) and for a higher multiplicity reach compared to previous ALICE publications, quantified with KNO variables (moments) [24] as well as with the parameters of Negative Binomial Distributions (NBD) used to fit measured multiplicity distributions.
With respect to previous ALICE publications, the analysis reported here makes use of improved tracking and track-counting algorithms; better knowledge and improved simulation of diffraction processes; an expanded pseudorapidity range for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) studies and better statistical precision at \(\sqrt{s} = 0.9\) and 7 TeV, extending by a factor of 2 the previously published multiplicity distribution reach. Results at \(\sqrt{s} = 2.76\) and 8 TeV are presented for the first time in this publication.
Previous measurements of both \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) and multiplicity distributions from CMS [35, 36] and UA5 [29] allow a direct comparison to our data. Others by ATLAS [37] and LHCb [38] use different definitions (\(\eta \) and \(p_{\mathrm {T}}\) ranges) making direct comparison impossible.
This publication is organized as follows: Sect. 2 describes the ALICE sub-detectors relevant to this study; Sect. 3 provides the details of the experimental conditions and of the collection of data; Sect. 4 explains the event selection; Sect. 5 describes the track selection criteria and the three track counting algorithms; Sects. 6 and 7 report the analyses for the measurement of the pseudorapidity density and of multiplicity distributions, respectively; Sect. 8 discusses systematic uncertainties; Sect. 9 presents the multiplicity measurements, NBD fits of the multiplicity distributions, KNO scaling and q-moment studies. Finally, in Sect. 10, the results are summarized and conclusions are given.
2 ALICE subdetectors
The ALICE detector is fully described in [39]. Only the main properties of subdetectors used in this analysis are summarized here. Charged-particle tracking and momentum measurement are based on data recorded with the Inner Tracking System (ITS) combined with the Time Projection Chamber (TPC) [40], all located in the central barrel of the ALICE detector and operated inside a large solenoid magnet providing a uniform 0.5 T magnetic field parallel to the beam line.
The V0 detector [41] consists of two scintillator hodoscopes, each one placed at either side of the interaction region, at \(z = 3.3\) m (V0A) and at \(z = -0.9\) m (V0C) (z is the coordinate along the beam line, with its origin at the centre of the ALICE barrel detectors), covering the pseudorapidity ranges \(2.8< \eta < 5.1\) and \(-3.7< \eta < -1.7\), respectively. The time resolution of each hodoscope is better than 0.5 ns.
The ITS is composed of high resolution silicon tracking detectors, arranged in six cylindrical layers at radial distances to the beam line from 3.9 to 43 cm. Three different technologies are employed. For the two innermost layers, silicon pixels (SPD [42]) are used, covering pseudorapidity ranges \(|\eta | < 2\) and \(|\eta | < 1.4\), respectively. The SPD is followed by two Silicon Drift Detector layers (SDD, [43]). The Silicon Strip Detector (SSD, [44]) constitutes the two outmost layers consisting of double-sided silicon micro-strip sensors. The intrinsic spatial resolution (\(\sigma _{r\varphi } \times \sigma _z\)) of the ITS subdetectors is: \(12\times 100~\upmu {\mathrm {m}}^2\) for SPD, \(35\times 25~\upmu {\mathrm {m}}^2\) for SDD, and \(20\times 830~\upmu {\mathrm {m}}^2\) for SSD, where \(\varphi \) is the azimuthal angle and r the distance to the beam line. The ITS sensors were aligned using survey measurements, cosmic muons and collision data [45]. The estimated alignment accuracy is 8 \(\upmu \)m for SPD and 15 \(\upmu \)m for SSD in the most precise coordinate (\(r \varphi \)). For the SDD, the intrinsic space point resolution is \(\sigma _z = 30~\upmu {\mathrm {m}}\) in the z direction and \(\sigma _{r\varphi } = 40\) to 60 \(\upmu \)m, depending on the sensor, along \(r \varphi \) (drift). Because of some anomalous drift field distributions, in the reconstruction, a systematic uncertainty up to 50 \(\upmu \)m in z and 500 \(\upmu \)m in \(r \varphi \) was added to account for differences between data and simulation. The ITS resolution in the determination of the transverse impact parameter measured with respect to the primary vertex is typically 70 \(\upmu \)m for tracks with \(p_{\mathrm {T}} = 1\) GeV/c, including the contribution from the primary vertex position resolution.
The SPD and the V0 scintillator hodoscopes provided triggers for collecting data.
The TPC [40] is a large cylindrical drift detector with a central high voltage membrane at \(z = 0\), maintained at \(+\)100 kV and two readout planes at the end-caps. The material budget between the interaction point and the active volume of the TPC corresponds to 11% of a radiation length, when averaged over \(|\eta | < 0.8\).
The TPC and the ITS were aligned relative to each other within a few hundred micrometers using cosmic-ray and proton collision data [45].
The momentum measurement is not explicitly used in this study, however, the simulation of the detector response is sensitive to the particle momentum spectrum. Since event generators used in Monte Carlo simulations do not reproduce the observed momentum distributions, the difference between data and Monte Carlo simulation is taken into account when evaluating systematic errors. For momenta lower than 2 GeV/c, representing the bulk of the data, the \(p_{\mathrm {T}}\) resolution for tracks measured in the TPC and in the ITS, is about 0.80% at \(p_{\mathrm {T}} = 1\) GeV/c, it increases to 0.85% at \(p_{\mathrm {T}} = 2\) GeV/c and to 3% at \(p_{\mathrm {T}} = 0.1\) GeV/c.
Charged-particle multiplicities were measured using information from the TPC in \(|\eta | < 0.9\) and from the ITS in \(|\eta | < 1.3\). At larger pseudorapidities, the SPD alone was used to expand the range of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements to \(|\eta | < 2.0\).
3 Experimental conditions and data collection
3.1 Proton beam characteristics
Data were selected during LHC collision periods at a luminosity low enough to allow the minimum bias trigger rate not to exceed 1 kHz. At \(\sqrt{s} = 0.9\) TeV, the number of protons per colliding bunch varied from \(9\times 10^9\) to \(3.4\times 10^{11}\), while the number of colliding bunches was either 1 or 8. At \(\sqrt{s} = 2.76\) TeV, the number of protons per colliding bunch varied from \(5\times 10^{12}\) to \(7\times 10^{12}\), while the number of colliding bunches was either 48 or 64. At \(\sqrt{s} = 7\) TeV, the number of protons per colliding bunch varied from \(8.6\times 10^9\) to \(1.4\times 10^{12}\), resulting in a luminosity between \(10^{27}\) and \(10^{30}\) cm\(^{-2}\) s\(^{-1}\). There were up to 36 bunches per beam colliding at the ALICE interaction point. When needed, the luminosity was kept below 10\(^{30}\) cm\(^{-2}\) s\(^{-1}\) by a transverse displacement of the beams with respect to one another. At \(\sqrt{s} = 8\) TeV, there were 3 proton bunches colliding at the ALICE interaction point each containing about \(1.6\times 10^{11}\) protons.
Data used for this study were collected at low beam currents, so that beam-induced backgrounds (beam-gas or beam-halo events) were low and could be removed offline using V0 and SPD detector information, as discussed in Sect. 4.1.
3.2 Triggers
The ALICE trigger system is described in [46]. Data were collected with a minimum bias trigger, \({\mathrm{MB}_{\mathrm{{OR}}}} \), requiring a hit in the SPD or in either one of the V0 hodoscopes; i.e. essentially at least one charged particle anywhere in the 8 units of pseudorapidity covered by these detectors. Triggers were required to be in time coincidence with a bunch crossing the ALICE interaction point. Control triggers, taken for various combinations of beam and empty-beam buckets, were used to measure beam-induced and accidental backgrounds.
3.3 Characteristics of data samples used in this study
General characteristics of the data samples used are given in Table 1.
The data at \(\sqrt{s} = 0.9\) TeV were collected in May 2010, with one polarity of the ALICE solenoid magnet (solenoid magnet field pointing in the positive z direction).
The first LHC data above Tevatron energy were collected in 2009, at \(\sqrt{s} = 2.36\) TeV, in a run with unstable LHC beams, during which only the SPD was turned on. Therefore, in this case, the charged-particle multiplicity was measured using exclusively the SPD information. In this publication, the previously published results at \(\sqrt{s} = 2.36\) TeV [2] are used for comparison.
Proton-proton data were collected at \(\sqrt{s} = 2.76\) TeV, an energy that matches the nucleon-nucleon centre-of-mass energy in the first Pb–Pb collisions provided by the LHC, in 2011.
Data at \(\sqrt{s} = 7\) TeV were collected in 2010. About 20% of the data were taken with a magnet polarity opposite (solenoid field pointing in the negative z direction) to that of \(\sqrt{s} = 0.9\) TeV data. A sample of \(12.3\times 10^6\) events, collected without magnetic field, was used to check some of the systematic biases in track reconstruction.
At \(\sqrt{s} = 8\) TeV only a subset of runs was collected with the \({\mathrm{MB}_{\mathrm{{OR}}}} \)as a minimum bias trigger in 2012, 10 were selected for this analysis.
At 0.9 and 7 TeV, data samples are substantially larger than those available in previous ALICE publications on charged-particle multiplicities [1,2,3]. For the charged-particle multiplicity analysis, the event sample at \(\sqrt{s} = 0.9\) and 7 TeV increased by a factor of 50 and 2000, respectively, giving significant extension of the multiplicity reach and better statistical precision. The precision of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) is not substantially limited by event sample size. However, the large number of runs available made it possible to study run-to-run fluctuations of the \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements over long periods of time, thus providing a monitoring of the uniformity of the data quality.
4 Event selection
4.1 Background rejection
4.1.1 Beam background
The main sources of event background are beam gas and beam halo collisions. Such events were removed by requiring that the timing signals from the V0 hodoscopes, if present, be compatible with the arrival time of particles produced in collision events. In addition, because of the different topology of beam background events, the ratio between the number of SPD clusters and the number of SPD trackletsFootnote 2 is much higher in beam background events, therefore a cut on this ratio was applied. The remaining fraction of beam background events in the data, estimated by analysing special triggers taken with non-colliding bunches or empty beam buckets, does not exceed 10\(^{-4}\) for all centre-of-mass energies. The track beam background is mostly significant in the last \(\eta \) bins (\(|\eta | \approx 2\)) where it reaches \(4\times 10^{-3}\) in the worst case.
4.1.2 Event pileup
The other type of potential event background comes from multiple collision overlap. For the data used in this publication, the proton bunch spacing was 50 ns or longer, the luminosity did not exceed \(10^{30}\) cm\(^{-2}\) s\(^{-1}\), and the probability to have collisions from different bunch crossings in the 300 ns integration time of the SPD was negligible. However, multiple collisions in the same bunch crossing, also referred to as event pileup or overlap, have to be considered in case their vertices are not distinguishable. In order to avoid or minimize corrections for event pileup, runs with a low number of interactions per bunch crossing, \(\mu \le 0.061\), were selected resulting in an average \(\mu \), \(\langle \mu \rangle \le 0.04\), for all data samples (Table 1). This corresponds to at most 2% probability of more than one interaction per event.
The identification of pileup events relies on multiple vertex reconstruction in the SPD, with algorithms using three basic parameters: (a) The distance of closest approach (DCA) to the main vertex for a SPD tracklet to be included in the search for an additional interaction: DCA > 1 mm; (b) The distance between an additional vertex and the main vertex, \(\Delta z > 8\) mm; (c) The number of SPD tracklets (\(N_{\mathrm{trk}}\)) used to determine an additional vertex (number of contributors to the vertex): \(N_{\mathrm{trk}} \ge 3\).
With this choice of parameters, and with the relatively broad z vertex distribution at the LHC (\({\mathrm {FWHM}}\ge 12\) cm), typically only 10 to 15% of multiple collisions are missed, and the fraction of fake multiple collisions due to SPD vertex splitting from a single interaction is low (typically a few times \(10^{-5}\)).
The pileup detection efficiency was studied both by overlapping two Monte Carlo proton–proton collisions and by measuring pileup in the data. The pileup fraction, estimated from identified pileup events in the data, is found to be consistent with what is expected from the \(\mu \) values derived from trigger information (Table 1).
In multiplicity measurements, pileup affects the data mainly when two vertices are not distinguishable. When they are distinguishable, the multiplicity is taken from the vertex with the highest number of tracks. The small bias induced by choosing systematically the highest multiplicity vertex is negligible in our low pileup data samples.
Comparing \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements, for different runs, no correlation is found between \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) values at \(\eta = 0\) and \(\mu \) values. Comparing data with and without identified pileup rejection, the change in \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) values is smaller than 0.5%, which is smaller than systematic uncertainties. Note that the requirements for track association to the main vertex reject a further fraction of the tracks coming from the 10 to 15% of unidentified pileup collisions. The conclusion is that event pileup corrections to \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) are negligible in these low pileup data samples.
For multiplicity distributions, even though data were selected with a low pileup probability, it is important to verify that the pileup does not distort the distributions, as the relative pileup fraction increases with multiplicity. The fraction of pileup events, which the ALICE pileup detection algorithm identifies after the event selection, is about \(10^{-2}\), with no significant differences between the four centre-of-mass energies. Moreover, tight DCA cuts allow tracks originating from the main vertex to be distinguished from those coming from a pileup vertex even when the vertices are closer than 0.8 cm in z. This was confirmed by simulating events, where two Monte Carlo pp collisions were superimposed, demonstrating that only 5% of the events passing the selection had extra tracks from the secondary vertex. In 90% of such cases, the distance along the beam line between the two vertices was \(\Delta z < 0.5\) cm. In the data samples with a pileup fraction of order \({\mu }/{2} \le 0.02\), the residual average fractions of events with pileup is at most 0.4%. Furthermore, the simulation shows that the pileup that does affect the multiplicity of an event is rather broadly distributed across events with different multiplicity, but becomes significant only outside the multiplicity range studied here. The multiplicity at which the pileup contribution reaches 10% of the measured multiplicity at \(\sqrt{s} = 7\) TeV is \(N_{\mathrm {ch}}= 105,\) 170 and 310, for \(|\eta | <0.5,\) 1.0, and 1.5, respectively, which is beyond multiplicity ranges covered in this publication.
Therefore, no pileup corrections were applied. Other background contributions from cosmic muons or electronics noise are also negligible.
4.2 Offline trigger requirement
Both for the INEL and INEL0 normalizations, the online \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger was used. However, for the NSD analysis, a subset of the total sample was selected offline by requiring a coincidence (\({\mathrm{MB}_{\mathrm{{AND}}}} \)) between the two V0 hodoscope arrays. This corresponds to the detection of at least one charged particle in both hemispheres, in the V0 hodoscope arrays separated by 4.5 units of pseudorapidity, a topology that tends to suppress single-diffraction (SD) events; therefore, model dependent corrections and associated systematic errors are minimized.
4.3 Vertex requirement
The position of the interaction vertex is obtained either by correlating hits in the two silicon-pixel layers (SPD vertex), or from the distribution of the impact parameters of reconstructed global tracksFootnote 3 (global track vertex) [39, 40, 45, 47, 48]. The next step in the event selection consists of requiring the existence of a reconstructed vertex.
Two SPD vertex algorithms were used: a three-dimensional vertexer (3D-vertexer) that reconstructs the x, y and z positions of the vertex, or a one-dimensional vertexer (1D-vertexer) that reconstructs the z position of the vertex. The vertex position resolution achieved depends on the track multiplicity. For the 3D-vertexer it is typically 0.3 mm both in the longitudinal (z) direction and in the plane perpendicular to the beam direction. The 1D-vertexer resolution in the z direction is on average 30 \(\mu \)m. If the 3D-vertexer algorithm does not find a vertex (typically 47% of the cases at \(\sqrt{s} = 7\) TeV), then the simpler 1D-vertexer is used to determine the z position of the vertex, and the x and y coordinates are taken from the average x and y vertex positions of the run. The 3D-vertexer efficiency is strongly multiplicity dependent. As the bulk of the events have a low multiplicity, this explains the relatively low average vertex finding efficiency. For the z coordinate, if no reliable vertex is found (typically 14% of the cases), either because the 1D-vertexer did not find a vertex or the 1D-vertex quality was not sufficient (the dispersion of the difference of azimuthal angles between the two hits, one in each SPD layer, of tracklets contributing to the vertex is required to be smaller than 0.02 rad), the event is rejected. For the global track vertex, the resolution is typically 0.1 mm in the longitudinal (z) direction and 0.05 mm in the direction transverse to the beam line.

For a data sample of events fulfilling the \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger selection, at \(\sqrt{s} = 7\) TeV, the distribution of the quantity \({\mathrm {d}^2N_{\mathrm {ch}}}/{\mathrm {d}\eta \,\mathrm {d}z}\) is plotted for tracklets, in the plane pseudorapidity (\(\eta \)) vs. z position of the SPD vertex (\(z_\mathrm{vtx}\)), showing the dependence of the \(\eta \) acceptance on \(z_\mathrm{vtx}\)
Both SPD and global track vertices have to be present and consistent by requiring that the difference between the two z positions be smaller than 0.5 cm. If not, in 3 to 4% of the cases, the event is rejected. The cut was chosen to be compatible with DCA\(_z\) cut applied to tracks to ensure that we combine tracklets and tracks from the same collision (see Sect. 5.2). This condition removes mainly non-Gaussian tails in the columns of the detector response matrixFootnote 4 at low multiplicity, coming from the fact that SPD and track vertices, when separated, tend to have different multiplicities associated to them. In the data, this requirement also removes 80% of pileup events with well-separated vertices.
The \(\eta \) acceptance is correlated with the vertex z position (\(z_\mathrm{vtx}\)) (Fig. 1). For multiplicity distribution measurements, in order for tracks to remain within the acceptance of the SPD in the \(\eta \) versus \(z_\mathrm{vtx}\) plane, the following requirements were imposed on the vertex position along the z axis: \(|z_\mathrm{vtx}|<\) 10, 5.5 and 1.5 cm for \(|\eta |<\) 0.5, 1 and 1.5, respectively. In the measurement of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), the requirement on the vertex was relaxed to \(|z_\mathrm{vtx}|<\) 30 cm, in order to allow extending the \(\eta \) range to \(|\eta | < 2\).
4.4 Event selection efficiency
As described in [49], PYTHIA6 [50,51,52] and PHOJET [53, 54] event generators used by ALICE were adjusted to reproduce the measured diffraction cross-sections and the shapes of the diffracted mass (\(M_X\)) distributions extracted from the Kaidalov–Poghosyan model [55]. These modified versions of event generators are referred to as “tuned for diffraction”. Typically, \({\sigma _{\mathrm {SD}}}/{\sigma _{\mathrm {\text {INEL}}}} \approx 0.20\), where \(\sigma _{\mathrm {INEL}}\) is the inelastic cross-section, \(\sigma _{\mathrm {SD}}\) is the SD cross-section for \(M_X<\) 200 GeV/\(c^2\), and \({\sigma _{\mathrm {DD}}}/{\sigma _{\mathrm {\text {INEL}}}} \approx 0.11\), where \(\sigma _{\mathrm {DD}}\) is the double diffraction cross-section for \(\Delta \eta > 3\) (\(\Delta \eta \) is the size of the particle gap in the pseudorapidity distribution). These fractions have insignificant energy dependence between 0.9 and 7 TeV [49], and the values at 7 TeV were used for 8 TeV data.
Table 1 shows the number of events selected at each centre-of-mass energy prior to the \(z_\mathrm{vtx}\) requirement. Selection efficiencies using criteria defined above in this section, were estimated for INEL, NSD and SD events (classified at generator level by event generator flags) as a function of the number of generated charged particles (shown on Fig. 2 for the case \(|\eta | < 1\) and the various centre-of-mass energies considered). The particular selection is designated by the offline trigger used to construct it, \({\mathrm{MB}_{\mathrm{{OR}}}} \)or \({\mathrm{MB}_{\mathrm{{AND}}}} \). Note that for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurement selection efficiencies are defined in a separate way (see Sect. 6.1). At \(\sqrt{s} \ge 7\) TeV the INEL event selection efficiency based on the \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger reaches 100% for a charged-particle multiplicity above 8.
For SD events, the efficiency of the \({\mathrm{MB}_{\mathrm{{AND}}}} \)selection reduces significantly when going to higher energies (Fig. 2), because the Lorentz boost of the diffracted system increases with increasing centre-of-mass energies. This implies that in the normalization to the NSD event class, corrections for the remaining SD contribution become smaller when going to higher energies. The \({\mathrm{MB}_{\mathrm{{AND}}}} \)trigger selects 84%, 86%, 87% and 87% of the \({\mathrm{MB}_{\mathrm{{OR}}}} \)triggers, and 13%, 4%, 1% and 1% of the SD events satisfy the \({\mathrm{MB}_{\mathrm{{AND}}}} \)selection, at \(\sqrt{s} =\) 0.9, 2.76, 7 and 8 TeV, respectively.

Charged-particle multiplicity (\(N_{\mathrm {ch}}=\) number of primary charged particles generated in \(|\eta | < 1\)) dependence of the efficiency of the event selection described in Sect. 4, obtained as the average between PYTHIA6 Perugia0 and PHOJET, both tuned for single diffraction defined for \(M_X < 200\) GeV/\(c^2\) (see [49]). Efficiencies are given for INEL events with \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger (open circles), NSD events with \({\mathrm{MB}_{\mathrm{{AND}}}} \)trigger (open squares), and SD events with \({\mathrm{MB}_{\mathrm{{AND}}}} \)trigger (open diamonds), at \(\sqrt{s} = \) 0.9 TeV (top left), 2.76 TeV (top right), 7 TeV (bottom left) and 8 TeV (bottom right). Error bars correspond to the difference between the two event generators and statistical uncertainty added in quadrature (non-negligible only for the SD events selection efficiency)
5 Track selection and multiplicity algorithms
5.1 Track quality requirements
The following criteria were used to select reconstructed tracks associated to the main event vertex:
-
for tracks reconstructed from both ITS and TPC information (global tracks), the selection requires at least 70 pad hit clusters in the TPC, a good track quality (\({\chi ^2}/{\mathrm {dof}} < 4\)), a distance of closest approach (DCA) along the z direction (DCA\(_z\)) < 0.5 cm, and a \(p_{\mathrm {T}}\)-dependent transverse DCA (DCA\(_\mathrm {T}\)) requirement, which corresponds to a 7 sigma selection. DCA\(_\mathrm {T}\) conditions are relaxed by a factor 1.5 for tracks lacking SPD hits.
-
for tracks reconstructed with ITS information only (ITS-only tracks) the number of ITS hit clusters associated to the track must be larger than 3, among the 6 layers of the ITS, and \({\chi ^2}/{\mathrm {dof}} < 2.5\). The DCA\(_z\) and DCA\(_\mathrm {T}\) requirements are the same as for global tracks.
-
for SPD tracklets, the association to the vertex is ensured through a \(\chi ^2\) requirement. Using the SPD vertex as the origin, differences in azimuthal (\(\Delta \varphi = \varphi _2 - \varphi _1\), bending plane) and polar (\(\Delta \theta = \theta _2 - \theta _1\), non-bending direction) angles are calculated between hits in the inner (layer 1) and in the outer (layer 2) SPD layers. Hit combinations, called tracklets, are selected with the following condition
$$\begin{aligned} \chi ^2 \equiv \frac{\left( \Delta \varphi \right) ^2}{\sigma ^2_{\varphi }} + \frac{1}{\sin ^2 \left( \frac{\theta _1 + \theta _2}{2} \right) }\times \frac{\left( \Delta \theta \right) ^2}{\sigma ^2_{\theta }} < 1.6 \end{aligned}$$(2)where \(\sigma _{\varphi } = 0.08\) rad, \(\sigma _{\theta } = 0.025\) rad and the \(\sin ^2\) factor takes into account the \(\theta \) dependence of \(\Delta \theta \). The \(\chi ^2\) value 1.6 was chosen to lie well within the part of the \(\chi ^2\) distribution of the data correctly reproduced by the simulation. The cut imposed on the difference in azimuthal angles rejects charged particles with a transverse momentum below 30 MeV/c; however, the effective transverse-momentum cut-off is determined mostly by particle absorption in the material and is approximately 50 MeV/c, in \(|\eta | < 1\). If more than one hit in an SPD layer matches a hit in the other layer, only the hit combination with the smallest \(\chi ^2\) value is used.
Some of the SPD elements had to be turned off, resulting in lower efficiency in some regions of the \(\eta \) versus azimuthal angle plane. In order to reach the best possible precision in the measurement of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), fiducial cuts were applied to both tracks and tracklets, excluding azimuthal regions where the tracking efficiency corrections are relatively large. These fiducial cuts vary with data taking periods, following the evolution of the SPD acceptance. At \(\sqrt{s} =\) 0.9, 2.76, 7, and 8 TeV, the fractions of the acceptance removed were 64%, 68%, 65%, and 35%, respectively. Some of the SPD elements could be recovered before collecting 8 TeV data, explaining the improvement.
For multiplicity distribution studies, fiducial cuts were not applied because they increase statistical uncertainty, hence limiting the high multiplicity reach.
5.2 Track counting algorithms
In previous ALICE publications [1,2,3], the charged-particle multiplicity was measured in \(|\eta | < 1.3\) using only SPD tracklets built from SPD pixel hits. In order to extend the pseudorapidity range to \(|\eta | < \) 2, an improved tracklet algorithm, initially used in [56], was introduced to take into account the \(\theta \) dependence of the uncertainty in the \(\chi ^2\) (Eq. (2)). With this improvement, the efficiency for detecting SPD tracklets became uniform as a function of pseudorapidity and z position of the vertex, which allowed vertices further away from the nominal interaction point along the beam direction to be used, thereby extending significantly the pseudorapidity range.
To be less sensitive to the SPD acceptance, track counting algorithms were developed, that make use of tracking information from other ALICE detectors, the SDD, the SSD and the TPC. Each track is counted as primary if it fulfills the transverse DCA requirements listed in Sect. 5.1 and it is not associated to a secondary vertex identified by a dedicated algorithm [47] tuned to tag \(\gamma \)-conversions, K\(^0\) and \(\Lambda \) decays.
Three multiplicity estimators were developed by ALICE using three different samples of tracks:
-
SPD tracklets, with \(|\eta |<2\) (referred to as Tracklet algorithm).Footnote 5 The Tracklet algorithm stores, for each tracklet, references to ITS or global track candidates using at least one of its pixel clusters.
-
ITS-only tracks, with \(|\eta | < 1.3\), obtained using all hit clusters in this detector, plus tracklets (\(|\eta |<2\)) built out of SPD pixel clusters not matched to any ITS track (referred to as ITS\(+\) algorithm).
-
TPC tracks, with \(|\eta | < 0.9\), matched to hits in the ITS, plus ITS-only tracks (up to \(|\eta |<1.3\)) built out of silicon hit clusters not matched to any TPC track, plus tracklets (\(|\eta |<2\)) built out of SPD pixel clusters not matched to any ITS or TPC track (referred to as ITSTPC\(+\) algorithm).

Graphical representation of the detector response matrices obtained with PYTHIA6 CSC [50] combined with a simulation of the ALICE detector, at \(\sqrt{s} = 7\) TeV, for three pseudorapidity intervals (\(|\eta | < 0.5, 1.0,\) and 1.5 from left to right, respectively), and for the three track counting algorithms, Tracklet, ITS\(+\) and ITSTPC\(+\), from top to bottom, respectively. Horizontal axes show generated primary charged-particle multiplicities and vertical axes measured multiplicities
In order to keep away from the edges of the detectors, where the acceptance is less precisely known, ITS and TPC tracks used in this study are limited to \(|\eta | < 1.3\) and \(|\eta | < 0.9\), respectively.
Properties of the three track counting algorithms are compared in Fig. 3, showing that, going from Tracklet to ITS\(+\) and to ITSTPC\(+\) algorithms, the detector response matrix becomes narrower and has a topology closer to that of a diagonal matrix. When going from \(|\eta | < 0.5\) to \(|\eta | < 1.5\), the response matrix becomes broader and has a less diagonal topology, as geometrical acceptance effects become more important, and dominated by the SPD with significant inefficiency due to some missing modules. Note that by restricting the azimuthal angle to good regions of the SPD, the difference between algorithms in \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements is of order \(\pm 1\)% in the central region (Fig. 4). However, the result with the Tracklet algorithm is not sensitive to this cut, and, as it is needed to measure multiplicities beyond \(|\eta | = 1.3\), it is used alone for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurement. For multiplicity distribution measurements all three algorithms are used without the \(\varphi \) region restrictions with a corresponding systematic uncertainty contribution.

The three multiplicity algorithms are compared, after full correction, (left) without and (right) with fiducial cuts in azimuthal angles. Ratios of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements with different algorithms are shown: ITSTPC\(+\) over Tracklet (black circles) and ITS\(+\) over Tracklet (red squares)
In the pseudorapidity region \(|\eta | < 0.9\), the TPC accounts for 90% of the tracks, the ITS complement 9% and the SPD complement 1%. These fractions vary with the \(\eta \) range. Outside \(|\eta | < 1.3\), SPD tracklets are the only contribution. The small fluctuations between points in \(|\eta | > 1.3\) come from the slightly different number of events used for averaging between algorithms, after efficiency corrections in each \(\eta \) bin.
6 Pseudorapidity density of primary charged particles: analysis
Raw \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) distributions have to be corrected for detector and trigger acceptance and efficiency, and for contamination from daughters of strange particles. Note that this section only describes the particularities of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurement, unless specifically stated otherwise. For charged particle multiplicity distribution measurement see Sect. 7.
6.1 Acceptance and efficiency corrections
Three types of corrections have to be applied to the raw data: (a) a track-to-particle correction to take into account the difference between measured tracks and “true” charged primary particles. This correction mainly depends on acceptance effects and on detector and reconstruction efficiencies; (b) corrections for the bias coming from the vertex reconstruction requirement, at both track and event levels (vertex reconstruction correction). This bias exists on both the number of tracks and the events used, since events without a reconstructed vertex are not selected, and tracks from those events therefore do not contribute; (c) corrections at both track and event levels, to take into account the bias due to the \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger required for INEL and INEL0 event classes or the \({\mathrm{MB}_{\mathrm{{AND}}}} \)offline selection for the NSD event class.
In practice, the number of tracks is corrected as a function of \(\eta \) and \(z_\mathrm{vtx}\) and the number of events is corrected as a function of reconstructed track multiplicity and \(z_\mathrm{vtx}\). The number of events without trigger or without reconstructed vertex is estimated from the simulation and included in the corrected number of events. Finally, the quantity \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), averaged over all events, is obtained for each \(\eta \) bin. The range of \(z_\mathrm{vtx}\) contributing to the multiplicity varies with \(\eta \) (Fig. 1). For instance, at \(\eta = 2\), tracks originate mostly from vertices in the range: \(-30~\hbox {cm}< z_\mathrm{vtx} < -5\) cm. Therefore, for each \(\eta \) bin, a \(z_\mathrm{vtx}\) acceptance correction is applied. See [57] for details of the procedure.
6.2 Strangeness correction
Since ALICE’s definition of primary charged particles excludes particles originating from the weak decays of strange particles, data have to be corrected for cases when daughter particles of such decays pass the track selection. Current Monte Carlo event generators have a strangeness content which differs from data by a factor approaching 2. Therefore, the strangeness content in the Monte Carlo simulation was normalized to data using ALICE’s K\(^0\) and \(\Lambda \) measurements in \(|\eta | < 0.9\) [4], that were extrapolated to \(|\eta |\le 2\) using the shape from simulation. The ratios of strangeness contents between data and Monte Carlo generators are slightly centre-of-mass energy dependent. For \(\sqrt{s}\) varying from 0.9 to 8 TeV they increase from 1.6 to 1.85 according to PYTHIA6, and from 1.4 to 1.6 according to PHOJET. The uncertainty on these ratios coming from the uncertainty in ALICE measurements of strange particle production [4], is estimated to be 5%. The strangeness contamination is slightly \(\eta \) dependent, and varies from 1.7% at \(\eta = 0\) to 2.5% at \(\eta = 2\) at \(\sqrt{s} = 7\) TeV. The strangeness correction is about 1%, has no significant \(\eta \) variation in \(|\eta | < 2\) and no significant energy dependence between \(\sqrt{s} = 0.9\) and 8 TeV. This correction is explained in more detail in the Sect. 8.1.3, where the corresponding systematic uncertainty is discussed.
6.3 Event class normalization
The final correction applied to the data is the normalization to one of the three event classes defined in this study: NSD, INEL and INEL0. In the normalization to NSD, corrections have to be made for the fraction of SD events remaining in the selection and for the fraction of double-diffraction (DD) events not included in the selection. In the normalization of results to the INEL event class, corrections have to be made for the fraction of single- and double-diffractive events not included in the selection. The INEL0 class is of interest because it minimizes diffractive corrections. In addition, ALICE measurements of SD and DD cross-sections [49] reduced the systematic uncertainties coming from diffraction. Corrections for higher order diffractive processes associated with events with two or more pseudorapidity gaps (regions devoid of particles) are neglected in the normalization to INEL, NSD and INEL0 classes, as their contribution to inelastic collisions is expected to be smaller than 1% [14, 55]. Furthermore, such events tend to have a high trigger efficiency, which makes corresponding corrections even smaller.
To normalize measurements to a given event class, trigger biases must be corrected for, both at event and track levels. For the INEL and INEL0 classes, the correction is straightforward using the \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger efficiency (Table 2).
For the NSD event class, contamination of the event sample by SD events must be taken into account. The measured quantity may be re-written as:
where \(( \sum N_\mathrm{trk}^{\mathrm {Class}} )_{\mathrm {Trigger}}\) is the number of tracks aggregated over all events \(( N_\mathrm{ev}^{\mathrm {Class}})_{\mathrm {Trigger}}\) of a given class (superscript) selected with a given trigger type (subscript outside the parentheses). Given that \(( N_\mathrm{ev}^{\mathrm {SD}})_{{\mathrm{MB}_{\mathrm{{AND}}}}} \propto \varepsilon ^{\mathrm {SD}}_{{\mathrm{MB}_{\mathrm{{AND}}}}}\sigma ^{\mathrm {SD}}\) and \(( N_\mathrm{ev}^{\mathrm {NSD}})_{{\mathrm{MB}_{\mathrm{{AND}}}}} \propto \varepsilon ^{\mathrm {NSD}}_{{\mathrm{MB}_{\mathrm{{AND}}}}}\sigma ^{\mathrm {NSD}}\), where \(\varepsilon \) and \(\sigma \) are efficiencies and cross-sections, respectively, for SD or NSD events [49], one obtains:
The coefficient in front of the single diffraction term in Eq. (4), varies from 0.04 at \(\sqrt{s} = 0.9\) TeV to 0.003 at \(\sqrt{s} = 8\) TeV. As the single diffraction term is not measured, but corresponds to a relatively small correction, this term was calculated using the simulation. The corresponding uncertainty was estimated by varying the single diffraction term conservatively between extreme cases, assuming either no SD, or assuming that all events are from SD. The last step consists of correcting for the \({\mathrm{MB}_{\mathrm{{AND}}}} \)trigger efficiency to obtain the desired quantity, \({1}/{( N^{\mathrm {NSD}}_\mathrm{ev} )_{{\mathrm{MB}_{\mathrm{{AND}}}}}} {\mathrm {d} (\sum N_\mathrm{trk}^{\mathrm {NSD}})_{{\mathrm{MB}_{\mathrm{{AND}}}}}}/{\mathrm {d}\eta }\).
The DD event content of the \({\mathrm{MB}_{\mathrm{{OR}}}} \)and \({\mathrm{MB}_{\mathrm{{AND}}}} \)data samples, is small, of the order of 5.5 and 4.5%, respectively. These fractions do not vary significantly between 0.9 and 8 TeV. The corrections for DD efficiency are included in the general efficiency correction. For the INEL and INEL0 event classes, the \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger efficiency for DD events as a function of multiplicity is the same as for the other inelastic events. The \({\mathrm{MB}_{\mathrm{{AND}}}} \)selection, which is used for the NSD event sample, has an efficiency for DD events that is lower than that of the other inelastic events. However, we checked in the simulation that the average efficiency correction for the NSD event class gives the same result as separate efficiency corrections implemented for DD and ND events.
7 Multiplicity distributions of primary charged particles: analysis
7.1 Unfolding multiplicity distributions
The data samples used in these measurements are described in Table 1. The next step in the analysis consists of correcting the raw distributions for detector acceptance and efficiencies, using an unfolding method.
The unfolding procedure follows the same approach as in [2], i.e. the corrected distribution is constructed by finding the vector U, which minimizes a \(\chi ^2\) given by
where M represents the raw multiplicity distribution vector with uncertainty vector s, U the unfolded multiplicity distribution vector, and R the detector response matrix. Indices m and t run from 0 to the maximum number of multiplicity bins, in raw and corrected distributions respectively. The regularization term \(\beta \times F(U)\) is used to decrease the sensitivity of the unfolding to statistical fluctuations. For F(U) a usual Tikhonov-type of function [58] was used, which has a smoothing effect on the unfolded distribution
where N is the number of unfolded multiplicity bins, evaluated with the help of the response matrix, from the maximum raw multiplicity.
The weight \(\beta \) (Table 3) was chosen to minimize the mean squared error [58]. The solution is found to be stable over a broad range of \(\beta \) values (\(\pm 50\)%), and the correct minimum was ensured in each case by scanning \(\beta \) over few orders of magnitude. The particular values of optimal weights depend on many features of the unfolding problem, such as distribution size, a pattern of fluctuations in the input raw data, properties of the response matrix and the regularization term. The most obvious dependence was eliminated by factorizing N in Eq. (6).
For each generated multiplicity bin \(N^\mathrm{gen} = t\), the response matrix column \(R_{mt}\) consists of the distribution of the probability to measure multiplicity \(N_{\mathrm {ch}}= m\). To extend the response matrix to the highest multiplicities encountered in this study, beyond the reach of the available simulation, probability distributions were parameterized and extrapolated towards high multiplicities (Fig. 5). In the low-\(N^\mathrm{gen}\) region (\(N^\mathrm{gen}<\) 10 to 20, depending on the \(\eta \) range) the response matrix was taken directly from the simulation. In the large \(N^\mathrm{gen}\) region (\(N^\mathrm{gen} \ge \) 10 to 20), the column \(R_{mt}\) is well described by a Gaussian distribution and mean values follow a linear trend (Fig. 5). Widths were parameterized using two different functions, a Padé function and a power law
\(C_0\), \(C_1\), \(C_2\), \(C_3\) and \(\gamma \) are constants to be fitted. These functions have different asymptotic behaviours (Fig. 5), however, using either function makes a difference only for multiplicities above 100 (in \(|\eta |<1.5\)).

Example of Gaussian parameterization of the response matrix, at \(\sqrt{s} =\) 7 TeV, for \(|\eta | <1\): (left) parameterization of the mean values, with a linear function (red dashed line); (right) parameterization of the widths, with a Padé function (red solid line) and a power law function (blue dashed line). The bottom parts of the figures show the ratios between data and fits
The switch to parameterization occurs at \(N^\mathrm{gen} = \) 10, 15 and 20, for \(|\eta |<\) 0.5, 1 and 1.5, respectively, for all energies. These values ensure that using the parameterized response matrix introduces no distortions in the low multiplicity region.
The range of multiplicities in the final unfolded distribution was further restricted by requiring that the bias (an estimate of how far is the result from the true solution [58]) is less than 10% in each bin. As unfolding is performed for each correction scenario (see Sect. 8.2 on systematic uncertainties), in the end the multiplicity range is limited by the unfolding resulting in the shortest range. The quality of the unfolding was verified by comparing the raw distribution M to the product \(R \otimes U\).
7.2 Event class normalization
After the unfolding step, distributions have to be corrected for event selection efficiency (including trigger efficiency and vertex reconstruction efficiency).
For the INEL and INEL0 event classes this is straightforward, given that
where \(\varepsilon _t\) is the selection efficiency for true multiplicity t. Thus the unfolded distribution can be normalized to the inelastic event class by dividing the contents of each multiplicity bin by the corresponding efficiency.
For the NSD event class the procedure is different as the unfolded distribution, \(U^{*}\), includes a contamination by SD events
where upper indices denote the event class. The overall fraction of SD in inelastic collisions (\(\alpha _t\)) was measured by the ALICE Collaboration [49]
The desired unfolded distribution normalized to the NSD event class is obtained by combining Eqs. (10) and (11)
8 Study of systematic uncertainties
8.1 Common sources of systematic uncertainties
8.1.1 Material budget
The material budget in the ALICE central barrel was checked in the range \(|\eta | < 0.9\), by comparing measured and simulated gamma conversion maps. The conclusion is that, in this pseudorapidity range, the material budget is known with a precision of 5% [48]. The corresponding systematic uncertainty was obtained by varying the material budget in the simulation, conservatively over the whole pseudorapidity range by \(\pm 10\)%, which induces a variation of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) of \(\pm 0.2\)% for all event classes. For multiplicity distributions, the \(\eta \) range considered does not exceed \(\pm 1.5\), making the effect of the higher material budget uncertainty outside \(|\eta | < 0.9\) relatively small. The systematic uncertainty from material budget is negligible compared to other sources of uncertainty.
8.1.2 Magnetic field
The magnetic field map was measured and simulated with finite precision. To check the sensitivity of the detector response to the precision of the simulation of the ALICE solenoidal magnetic field, data samples collected at \(\sqrt{s} = 7\) TeV with opposite polarities were compared. The differences in \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) values are consistent with observed fluctuations between runs within the data-taking period at this energy. Therefore, the contribution from systematic uncertainties associated with the magnetic field are smaller than, or of the order of, the run-to-run fluctuations, and have been neglected.
8.1.3 Strangeness correction and particle composition
The main sources of uncertainty associated to the correction for strange particles originate from: (a) the difference (\({\le } 5\)%) in K\(^0\) and \(\Lambda \) detection efficiency between data and simulation [4]; (b) the difference in \(p_{\mathrm {T}}\) distributions of strange particles in data compared to simulation, which implies a difference in the fractions of daughter particles meeting the vertex association condition; and (c) the uncertainty in the simulation of the strange particle content.
For \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements, the systematic uncertainty from strangeness correction is found to have a small \(\eta \) variation, it is slightly larger at \(\eta = 0\) compared to \(|\eta | = 2\). These uncertainties have a small energy dependence, they increase slightly with increasing \(\sqrt{s}\), from 0.14% at \(\sqrt{s} =\) 0.9 TeV to 0.16% at \(\sqrt{s} =\) 8 TeV. The uncertainties at \(\eta = 0\) are listed in Table 4.
For multiplicity distributions, the strangeness contamination was studied with the Monte-Carlo simulation by evaluating the survival probability of strange particle decay products for the track selection used in the analysis. The probability that a track from strange particle decay passes the track requirements is less than 0.1% on average, leading to a negligible contribution to the uncertainty on multiplicity distributions.
The particle composition affects the efficiency estimate, because different particle species have different efficiencies and effective \(p_{\mathrm {T}}\) cut off. The influence of the uncertainty in particle composition was estimated by varying, in the simulation, the relative fractions of charged kaons and protons with respect to charged pions by ±30%, which covers conservatively the uncertainties in the measured particle composition at the LHC [59], and found to range, for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), between 0.1% for the INEL events class and 0.2% for the NSD and INEL0 event classes (Table 4). The effect is negligible for multiplicity distributions.
8.1.4 Detector simulation
The systematic uncertainty related to the limited precision with which the detector performance is simulated was evaluated by varying the threshold on parameters used to select the various types of tracks, over a range obtained from the observed difference in the distributions of these parameters between simulation and data. For \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) measurements based on tracklets, the \(\chi ^2\) cut was varied between 1.3 and 4. The spread of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) values over the range of z-positions of the vertex covered by a given \(\eta \) bin was used as a measure of the bias introduced by the z-dependence of the tracklet reconstruction efficiency. The corresponding uncertainty ranges from 0.6 to 1.1% depending on the data sample (Table 4).
Since for multiplicity distribution measurements all three track-counting algorithms are used, track parameters were also varied for global tracks, and for ITS-only tracks (details may be found in [48]):
-
for global tracks, the minimum number of TPC clusters was varied between 60 and 80 and the \(\chi ^2\) cut between 3 and 5.
-
for ITS-only tracks, the \(\chi ^2\) cut was varied between 2 and 3.
The uncertainty on the DCA distribution is not considered here, as it is included implicitly in the uncertainty on the strangeness content, which affects the DCA distribution.
We find that, in the case of multiplicity distributions, uncertainties in the detector simulation are negligible compared to other sources of uncertainties.
8.1.5 Model dependence
The remaining SD fraction in the sample selected with the \({\mathrm{MB}_{\mathrm{{AND}}}} \)trigger in view of the normalization to the NSD event class is 3%, 1% and negligible at \(\sqrt{s} =\) 0.9, 2.76 and \(\ge \) 7 TeV, respectively. Uncertainties coming from diffraction contributions are included in the trigger efficiency uncertainties (Table 2) obtained in [49], for \(\sqrt{s} \le 7\) TeV. At \(\sqrt{s} = 8\) TeV, the efficiency values were taken to be the same as for \(\sqrt{s} = 7\) TeV. In addition, the model uncertainties at \(\sqrt{s} =\) 0.9, 2.76, 7 and 8 TeV were obtained from the difference between PYTHIA6 Perugia0 and PHOJET. A test of the efficiency evaluation was obtained by comparing simulated \({\mathrm{MB}_{\mathrm{{AND}}}} \)to \({\mathrm{MB}_{\mathrm{{OR}}}} \)trigger efficiency ratios to the measured values. Excellent agreement was found at all energies [49].
For multiplicity distributions, the systematic uncertainty from the model dependence is included in both efficiency correction and \(p_{\mathrm {T}}\) dependence uncertainties, as different event generators and tunes are used to estimate independently efficiencies and response matrices (see Sect. 8.2).
8.1.6 \(p_{\mathrm {T}}\) dependence
None of the MC generators used in the detector simulation reproduces correctly the \(p_{\mathrm {T}}\) distribution of charged particles observed in the data [60, 61]. This introduces an uncertainty in the determination of the detector response, as it is integrated over transverse momenta, and the probability of detecting a particle decreases with decreasing \(p_{\mathrm {T}}\). This affects in particular, together with the uncertainty on the material budget and the magnetic field, extrapolations of measurements to \(p_{\mathrm {T}} = 0\).
In order to study \(p_{\mathrm {T}}\) spectrum effects, two different tunes of the PYTHIA6 event generator were used, ATLAS CSC and Perugia0, which give an average \(p_{\mathrm {T}}\) versus charged-particle multiplicity respectively below and above the data (Fig. 6 (left)), for most of the multiplicity range (\(N_{\mathrm {ch}}> 2\)). The difference between measurements obtained with response matrices corresponding to each of these Monte Carlo generators, is used as the corresponding systematic error contribution. Figure 6 (right) shows that this procedure introduces an uncertainty which is weakly dependent on \(\eta \), and amounts to ±0.3%, when averaged over \(|\eta | \le 2\).
For undetected particles, below a threshold of about 50 MeV/c, a value chosen to coincide with a track detection efficiency of 50%, the corresponding systematic uncertainty is obtained by varying their fraction by a conservative amount (−50 and \(+\)100%). (The fraction of the \(p_{\mathrm {T}}\) spectrum below 50 MeV/c is about 1% of the total, for both PYTHIA6 and PHOJET.) The resulting systematic uncertainty on \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) is \(\eta \) dependent, and found to range from \(-0.5\) and \(+1.0\)%, at \(\eta = 0\), to \(-0.75\) and \(+\)1.5%, at \(|\eta | = 2\).
The systematic uncertainty induced on \(\mathrm {P}\left( N_{\mathrm {ch}}\right) \) by the difference in \(p_{\mathrm {T}}\) between data and simulation is slightly sensitive to the tune of PYTHIA6 considered: for instance, at \(N_{\mathrm {ch}}= 90\), varying the \(p_{\mathrm {T}}\) spectrum below 50 MeV/c by −50 and \(+\)100% induces a change of −5 and \(+\)9%, respectively for the ATLAS CSC tune and of −4 and \(+\)8%, respectively, for the Perugia0 tune.

(left) At \(\sqrt{s} = 7\) TeV, average raw \(p_{\mathrm {T}}\) vs. raw charged track multiplicity in \(|\eta | <1\), for data (black circles), PYTHIA6 Perugia0 (blue dashed line) and ATLAS-CSC (red dotted line). The bottom part of the figure shows the ratios of the two simulated distributions to the data; (right) Comparison of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) evaluations, as a function of \(\eta \), using correction maps obtained with a PYTHIA6 Perugia0 (blue dashed line), b PYTHIA6 ATLAS-CSC (red dotted line) and c the average between a and b; The bottom part of the figure shows the ratios of corrected distributions from a and b to the average
8.2 Systematic uncertainties in unfolding of multiplicity distributions
8.2.1 Uncertainty evaluation
The results of the unfolding procedure and unfolding uncertainty estimate were cross-checked, in standard ways:
-
changing the regularization term by either varying \(\beta \) or the function F(U);
-
using two alternative unfolding procedures: Bayesian [62] and singular value decomposition [63].
The changes in unfolded distributions due to variations of the different elements used in the unfolding procedure, each having their own systematic uncertainty, were studied by considering all possible combinations: counting algorithm (3 cases), event generator used for efficiency correction (2 cases: PYTHIA6 and PHOJET tuned for diffraction), event generator used for the response matrix (2 cases PYTHIA6 CSC and PYTHIA6 Perugia0), low \(p_{\mathrm {T}}\) spectrum extrapolation below 50 MeV/c (3 cases: varying the integral below 50 MeV/c by \(-50\), 0 and \(+100\)%), response matrix parameterization (2 cases: Power law, and Padé), which correspond to 72 separate measurements that are correlated as a result of the unfolding procedure. To take these correlations into account, for a given energy and a given \(\eta \) range, the systematic uncertainty from all the sources considered was estimated as the overall spread between the resulting distributions. The average between these distributions (center of the band covered by the 72 curves) was used as the measurement. The total uncertainty originating from the unfolding procedure (evaluated for each multiplicity bin as a linear sum of the unfolding bias [58] and the unfolded distribution covariance calculated from the statistical uncertainty of the raw distribution) was added linearly to the systematic uncertainty defined as half the size of the band. This takes into account the fact that the unfolded distributions come from the same raw multiplicity histogram, hence the raw data statistical fluctuations are propagated to each of the unfolded distributions in a similar way and affect the spread of distributions uniformly. The resulting systematic uncertainty is expected to be highly correlated with multiplicity.
The systematic uncertainties from material budget, tracklet and track selection, detector alignment (evaluated by changing the geometry within alignment uncertainties), particle composition, strangeness corrections are found to be negligible. Among the non-negligible contributions to multiplicity distribution systematic uncertainties, the contribution from selection efficiency (Table 5) can be evaluated separately as it is a multiplicative correction. All the other contributions, from the uncertainty on \(\langle p_{\mathrm {T}} \rangle \), the extrapolation down to \(p_{\mathrm {T}} = 0\), the counting algorithms, and the model dependence including the contribution from diffraction, are all mixed together through the procedure described above. For NSD and INEL event classes, the diffraction contribution is mainly significant in the zero multiplicity bin, which is absent for the INEL0 event class.
8.2.2 Bin-to-bin correlations in systematic uncertainty
Due to specific nature of the correction procedure, the final multiplicity distributions contain bin-to-bin correlations coming from various sources with different properties. These sources can be categorized by their effect:
-
statistical correlations, resulting from the propagation of the raw distribution statistical uncertainties through unfolding process, their characteristics largely depend on the response matrix structure;
-
fully correlated shift of the distribution as a result of the uncertainty in normalization;
-
long-range correlations in systematic uncertainties as a result of multiplicity scale change (that is determined by the position of the response matrix bulk relative to the diagonal, see Sect. 7.1) in the unfolded distribution.
We found that first category correlations (statistical) are negligible compared to the last category (scaling), while the second category correlations can be easily factorized for fitting the multiplicity distribution. The three main sources of correlated uncertainty, falling into the third category, are the change of counting algorithm, the change of event generator tune used to produce the response matrix (see Fig. 6) and the variation of \(p_{\mathrm {T}} \) distribution under the detection threshold. In order to evaluate the effect on the final distributions we construct 18 intermediate distributions corresponding to all possible combinations of counting algorithm, event generator tunes and variations of \(p_{\mathrm {T}} \) spectra. All other sources of systematics are included (except the uncertainty corresponding to bin \(N_{\mathrm {ch}}= 0\) renormalization, as it is not applied) with the same procedure described for the final distribution previously in this section. These 18 distributions are then treated independently in Sect. 9.5 to evaluate the effect of correlated uncertainties on NBD fits.
8.3 Summary of systematic uncertainties
8.3.1 Pseudorapidity density
The various contributions to systematic uncertainties in \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) are summarized in Table 4 for the three event classes and the four centre-of-mass energies studied in this publication. For the INEL0 event class, a precision of 1.5% is achieved, as the sensitivity to diffraction is negligible and the \(\eta \) range is reduced in the definition of this event class.
In the \(\eta \) range covered in this study (\(|\eta |<2\)), we find that systematic uncertainties show essentially no \(\eta \) variation (Fig. 7), and are therefore strongly correlated bin-to-bin.
8.3.2 Multiplicity distributions
The efficiency uncertainties (Table 5) are only relevant at low multiplicity. For multiplicities above 8 to 9, the efficiency reaches 100% and the corresponding systematic uncertainty becomes negligible. Therefore, efficiency uncertainties are only given for a few characteristic low multiplicities. The total systematic uncertainties vary with multiplicity, therefore they are given in Table 6 only for a few characteristic values of the multiplicity.
8.3.3 Consistency checks
In the measurement of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), statistical errors are negligible. Therefore, the study of run-to-run fluctuations (measured RMS of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) results in different runs) provides a check that all run dependent corrections are properly handled.
For the INEL and NSD event classes, contributions from run-to-run fluctuations are significantly smaller than the total systematic error (Fig. 7). For the INEL0 event class, for which the precision is highest, the relative importance of run-to-run fluctuations is larger than for the INEL and NSD event classes (Fig. 7), but reaches at most 5% of the total systematic uncertainty.
As data correction procedures are significantly different between \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) and multiplicity distribution measurements, a test was performed to verify the consistency of the two measurements. At the four centre-of-mass energies and for the three pseudorapidity intervals used in this study, integrals of the multiplicity distributions were found to be consistent with the direct measurements of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), within errors.

Total relative systematic uncertainty on \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) (thick black lines), as a function of pseudorapidity, compared to run-to-run fluctuations (thin red dashed lines) at \(\sqrt{s} = 0.9\) TeV (top row), 2.76 TeV (second row), 7 TeV (third row) and 8 TeV (bottom row), for the INEL, NSD and INEL0 event classes, as indicated
9 Experimental results
9.1 Pseudorapidity density of primary charged particles: measurements
In their common \(\eta \) range, \(|\eta | < 0.9\), the three track counting algorithms discussed in Sect. 5.2 achieve a similar precision of 1%, and were found to give consistent results. The main difference is that for ITS+ and ITSTPC+, there is a detector calibration contribution to systematics for the TPC and the SDD, not present for the SPD. To achieve the largest possible \(\eta \) range, in the measurement of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) versus \(\eta \), the Tracklet algorithm is used alone.
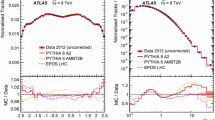
The measurement at \(\sqrt{s} = 0.9\) TeV is shown in Fig. 8 compared with previous results. At \(|\eta | > 0.9\) the measurement for the INEL event class is slightly lower than in ALICE’s previous publication [2]. The difference comes mainly from: (a) the tuning of the MC generators for diffraction, as larger pseudorapidities are more sensitive to SD; (b) the subtraction of particles coming from the decay of strange particles was improved, using ALICE’s measurement of strangeness [4]; and (c) the improvement of the \(\eta \) dependence of the Tracklet algorithm.
The discrepancy with UA5 for the INEL event class at large \(\eta \) could perhaps be related to the fact that UA5 used a \({1}/{M_X}\) variation of the single-diffractive cross section (see [55]). Note also that UA5 data seem to be internally inconsistent (see discussion in [64]). The measurement at \(\sqrt{s} = 2.76\) TeV is shown in Fig. 9 top, and found to be consistent with the ALICE measurement at \(\sqrt{s} = 2.36\) TeV [2], as expected because of the small change in center-of-mass energy. The new measurements of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), at \(\sqrt{s} = 7\) TeV (Fig. 9 middle), show agreement both with the previous ALICE results for INEL0 [3], and with CMS NSD data [35]. The measurements of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\sqrt{s} = 8\) TeV (Fig. 9 bottom) show the 3% increase with respect to the 7 TeV data, which corresponds to what is obtained in the extrapolation from lower energy data. Comparisons of the \(\eta \) distributions at the four centre-of-mass energies (Fig. 10), for the three events classes, show no significant change of shape and a smooth increase of the charged-particle density with increasing energy.
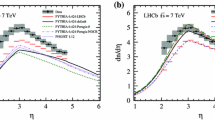
The data for the INEL event class at \(\sqrt{s} =\) 0.9 and 7 TeV were compared to simulations with current event generators (Fig. 11). At \(\sqrt{s} =\) 0.9 TeV, EPOS LHC [65] and PYTHIA8 4C [66, 67] are consistent with the data. PHOJET overestimates the data, while PYTHIA6 Perugia0 and Perugia 2011 underestimate the data. At \(\sqrt{s} = 7\) TeV, EPOS LHC, PHOJET and PYTHIA6 Perugia 2011 are consistent with the data. PYTHIA8 4C overestimates the data, while PYTHIA6 Perugia0 underestimates the data. Note that PYTHIA6 Perugia 2011, PYTHIA8 4C and EPOS LHC were tuned using LHC data.

\({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) vs. \(\eta \) at \(\sqrt{s} = 0.9\) TeV, for the three normalizations defined in the text, and a comparison with ALICE previous measurements [2, 3], UA5 [68] and CMS [35]. Note that to avoid overlap of data points on the figure, the INEL0 data were displaced vertically, and for these data the scale is to be read off the right-hand side vertical axis. Systematic uncertainties on previous data are shown as error bars (except for UA5, with coloured bands), while they are shown as grey bands for the data from this publication

\({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) vs. \(\eta \) measurements: \(\sqrt{s} = 2.76\) TeV compared with \(\sqrt{s} = 2.36\) TeV taken from ALICE [2] (top); \(\sqrt{s}=7\) TeV and comparison with CMS [35] and ALICE [3] data (middle); \(\sqrt{s} = 8\) TeV (bottom). Systematic uncertainties are shown as error bars for the previous data and as grey bands for the data from this publication. The scale is to be read off the right-hand side axis for INEL0

Comparison of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) vs. \(\eta \) measurements between the various centre-of-mass energies considered in this study: INEL (left), NSD (middle), and INEL0 (right). The lower parts of the figures show the ratios of data at energies indicated to the data at 0.9 TeV, with corresponding colours. Systematic uncertainties are indicated as coloured bands

Comparison with models of ALICE measurements of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) versus \(\eta \) for the INEL event class, at \(\sqrt{s} = 0.9\) (left) and 7 TeV (right): ALICE data (black circles with grey band), PYTHIA6 tune Perugia0 [50] (red continuous line), PHOJET [53] (blue dot-dashed line), PYTHIA6 tune Perugia 2011 [50] (pink dashed line), PYTHIA8 4C [66, 67] (green dashed line), EPOS LHC [65] (long dashed light blue line). The lower parts of the figures show ratios of data to simulation. Systematic uncertainties on ratios are indicated by coloured bands
9.2 Energy dependence of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\)
The traditional definition for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) is an integral of the data over the pseudorapidity range \(|\eta | < 0.5\)
The results of the measurements of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) are given in Table 7. The energy dependence of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) is of interest not only because it provides information about the basic properties of pp collisions, but also because it is related to the average energy density achieved in the interaction of protons, and constitutes a reference for the comparison with heavy ion collisions. At mid-rapidity, \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) can be parameterized as \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\sim s^{\delta }\). Combining the ALICE data with other data at the LHC and at lower energies, we obtain \(\delta = 0.102 \pm 0.003\), \(0.114 \pm 0.003\) and \(0.114 \pm 0.0015\),Footnote 6 for the INEL, NSD and INEL0 event classes, respectively, to be compared to \(\delta \simeq 0.15\) for central Pb–Pb collisions [56]. This is clear evidence that the particle pseudorapidity density increases faster with energy in Pb–Pb collisions than in pp collisions. Fits are shown on Fig. 12 and Table 8 gives extrapolations to centre-of-mass energies of 13 and 14 TeV (LHC design energy). While this paper was being prepared, the first measurement at 13 TeV by CMS appeared [69], resulting in \(\left. {\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\right| _{|\eta |<0.5} = 5.49\pm 0.01\ \text {(stat)}\pm 0.17\ \text {(syst)}\) for inelastic events, which is consistent with our extrapolation of \(5.30\pm 0.24\). Over the LHC energy range, from 0.9 to 14 TeV, while the centre-of-mass energy increases by a factor 15.5, extrapolation of present data for \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) shows an increase by factors \(1.75\pm 0.03\), \(1.87\pm 0.03\) and \(1.87\pm 0.01\), respectively for the three event classes. The multiplicity increase is similar for NSD and INEL0 classes but slightly lower for the INEL class.

Charged-particle pseudorapidity density in the pseudorapidity region \(|\eta | < 0.5\) (\({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) calculated as the integral of the data over \(|\eta | < 0.5\)) for INEL, NSD, and INEL0 collisions, as a function of the centre-of-mass energy. Lines indicate fits with a power-law dependence on \(\sqrt{s}\). Grey bands represent the one standard deviation range. Data points at the same energy have been shifted horizontally for visibility. The LHC nominal centre-of-mass energy is indicated by a vertical line. Data other than from ALICE used in this figure are taken from references [27, 35, 68, 70,71,72,73,74,75,76,77]
9.3 Multiplicity distributions of primary charged particles: measurements
The results of ALICE measurements of multiplicity distributions of charged primary particles are displayed as probability distributions (\(\mathrm {P}\left( N_{\mathrm {ch}}\right) \)) in Figs. 13 (INEL), 14 (NSD) and 15 (INEL0). For the first two event classes the measurements were obtained in three pseudorapidity intervals \(|\eta |<\) 0.5, 1 and 1.5, and for INEL0 in \(|\eta | < 1\). At \(\sqrt{s} = 7\) TeV, \(\mathrm {P}\left( N_{\mathrm {ch}}\right) \) varies over 6 to 7 orders of magnitude and the multiplicity range reaches up to 160 in \(|\eta | < 1.5\) for both INEL and NSD event classes. In \(|\eta | < 0.5\) and \(|\eta | < 1\), the observed multiplicity reaches 10 times the mean multiplicity. It is expected that the average energy density in proton collisions at the LHC, at \(\sqrt{s} = 14\) TeV, is about 5 to 15 times smaller than energy densities reached in gold ions at RHIC [78]. Therefore, in proton–proton collisions of multiplicity exceeding 10 times the average multiplicity, energy densities should overlap with those of heavy ion collisions at RHIC, allowing to compare properties of systems with very different collision volumes (two to three orders of magnitude) but the same energy density. Future runs of the LHC should allow extending much further the range of multiplicities probed so far.
The high-multiplicity tail of the distribution increases as expected with increasing energy (Fig. 16). This behaviour is studied quantitatively in Sect. 9.6 on KNO scaling and q-moment analysis.
The measurements presented in this publication are consistent with previous ALICE data, for INEL [2] at \(\sqrt{s} = 0.9\) TeV and INEL0 [3] at \(\sqrt{s} = 7\) TeV, in the multiplicity range where they overlap (Fig. 17). The wavy structure already observed by ALICE in [2, 3], for multiplicities above \(N_{\mathrm {ch}}= 25\), and previously by UA5 [29], is still hardly significant, and it is not present in the raw data. This feature was also observed in a study of CMS data [79]. However, applying the same procedure to Monte Carlo data produces similar structures in the unfolded distribution, while no oscillation was present at particle level. We conclude that this structure is an unfolding procedure artifact. The period of the structure is related to response matrix width.

Measured multiplicity distributions in three pseudorapidity ranges for INEL events. The dashed and solid lines show the single and double NBD fits (see Sect. 9.5). Shaded areas represent statistical and systematic uncertainties combined: a data at \(\sqrt{s} = 0.9\) TeV (top left); b data at \(\sqrt{s} = 2.76\) TeV (top right); c data at \(\sqrt{s} = 7\) TeV (bottom left); d data at \(\sqrt{s} = 8\) TeV (bottom right). Ratios of data to the fits are also shown, with shaded areas representing combined systematic and statistical uncertainties

Measured multiplicity distributions in three pseudorapidity ranges for NSD events. The dashed and solid lines show the single and double NBD fits (see Sect. 9.5). Shaded areas represent statistical and systematic uncertainties combined: a data at \(\sqrt{s} = 0.9\) TeV (top left); b data at \(\sqrt{s} = 2.76\) TeV (top right); c data at \(\sqrt{s} = 7\) TeV (bottom left); d data at \(\sqrt{s} = 8\) TeV (bottom right). Ratios of data to the fits are also shown, with shaded areas representing combined systematic and statistical uncertainties

Measured multiplicity distributions in three pseudorapidity ranges for INEL0 events. The dashed and solid lines show the single and double NBD fits (see Sect. 9.5). Shaded areas represent statistical and systematic uncertainties combined: a data at \(\sqrt{s} = 0.9\) TeV (top left); b data at \(\sqrt{s} = 2.76\) TeV (top right); c data at \(\sqrt{s} = 7\) TeV (bottom left); d data at \(\sqrt{s} = 8\) TeV (bottom right). Ratios of data to the fits are also shown, with shaded areas representing combined systematic and statistical uncertainties

Evolution of measured multiplicity distributions as a function of centre-of-mass energy (from 0.9 to 8 TeV), for INEL and NSD event classes and for \(|\eta | < 0.5\) (top row) and \(|\eta | < 1.5\) (bottom row)
9.4 Comparison of multiplicity distributions with other experiments and models
CMS data are available for the NSD normalization only. At \(\sqrt{s} =\) 0.9 and 7 TeV, in the three pseudorapidity intervals where they could be compared, the ALICE multiplicity measurements are generally in agreement with CMS data [36] (Fig. 17). However, at \(\sqrt{s} = 0.9\) TeV, above \(N_{\mathrm {ch}}\approx 40\) in \(|\eta | < 1\) and above \(N_{\mathrm {ch}}\approx 50\) in \(|\eta |< 1.5\), the ALICE multiplicity distributions tend to be higher than CMS data. The difference is not significant in each isolated bin, however the general trend seems to be different. As the bin-to-bin correlations in CMS’s results are unknown, it is very difficult to obtain reliable unbiased quantitative comparison. A possible source of the discrepancy is the different treatment of single-diffractive events in the two analyses making the NSD event sample definitions not strictly compatible. More precisely, there was no diffraction tuning in the simulations used by CMS and, moreover, ALICE’s criteria for events to be considered single-diffractive (see [49]) include a fixed cut on diffractive mass that differs from the value that CMS used. This explanation is supported by the fact that the difference is insignificant at \(\sqrt{s} = 7\) TeV, where single-diffractive contribution is negligible. The comparison with CMS data is further discussed in the Sect. 9.5, where NBD fits to the data are reported.
Measured multiplicity distributions are compared to models (Fig. 18), for two energies, the lowest one (\(\sqrt{s} = 0.9\) TeV), and the energy at which there is the largest event sample (\(\sqrt{s} = 7\) TeV), for the INEL event class, in the pseudorapidity range \(|\eta | < 1\).
At \(\sqrt{s} = 0.9\) TeV, PYTHIA6 Perugia0 fails to reproduce the data. PYTHIA6 Perugia 2011, PYTHIA8 4C and EPOS LHC underestimate the multiplicity distribution at high multiplicities (\(N_{\mathrm {ch}}\gtrsim 25\)). PHOJET provides the best match to the data over the observed multiplicity range, up to \(N_{\mathrm {ch}}\approx 60\).
At \(\sqrt{s} = 7\) TeV, both PYTHIA6 Perugia0 and PHOJET fail to reproduce the data. They severely underestimate the high multiplicity part of the distribution. PYTHIA6 Perugia 2011, EPOS LHC and PYTHIA8 4C give a reasonable fit of the low multiplicity region but underestimate the data above \(N_{\mathrm {ch}}\approx \) 60.

Comparison with ALICE previous publications [2, 3], for the INEL event class, at \(\sqrt{s} = 0.9\) TeV (top left) and the INEL0 event class at \(\sqrt{s} = 7\) TeV (top right); in both cases, ratios between ALICE new data and ALICE previous data are also shown. The total uncertainties are shown as error bars for the previous data and as a band for the present measurement. For the NSD event class, comparison with ALICE previous publication [2] and with CMS data at \(\sqrt{s} = 0.9\) TeV [36] (bottom left), and comparison with CMS data at \(\sqrt{s} = 7\) TeV [36] (bottom right); ratios of the NBD fits of ALICE data taken without errors to CMS data, for the various \(\eta \) intervals (indicated on the figure), are also shown. Error bars represent the contributions of the CMS errors to the ratios, the bands represent the ALICE total uncertainty assigned to the ratio of 1

Comparison with models of measured multiplicity distributions for the INEL event class in the pseudorapidity range \(|\eta | < 1.0\): ALICE data (black circles with grey bands), PYTHIA6 [50] tune Perugia0 (red continuous line), PHOJET [53] (blue dot-dashed line), PYTHIA6 Perugia 2011 (pink dashed line), PYTHIA8 4C [66, 67] (green dashed line), and EPOS LHC [65] (long dashed light blue line). The shaded areas represent total uncertainties: comparison at 0.9 (left) and at 7 TeV (right). The ratios between measured values and model calculations are shown in the lower parts of the figures with the same convention
9.5 Parameterization of multiplicity distributions with NBDs
Single Negative Binomial Distributions (NBD) have been traditionally used to parameterize particle multiplicity distributions in hadron collisions
where \(\langle n \rangle \) is the average multiplicity and the variance is given by
The parameter k is related to the two-particle correlation function, in the pseudorapidity interval considered [80]. In the limit \(k\rightarrow \infty \), the NBD becomes a Poisson distribution.
In previous ALICE data, for the NSD event class, no strong deviation from a single NBD fit was observed at \(\sqrt{s} =\) 0.9 and 2.36 TeV, for \(|\eta | \le 1\), while a hint of a substructure appears at \(|\eta | < 1.3\) [2]. At \(\sqrt{s} = 7\) TeV, for the INEL0 event class, the single NBD fit slightly underestimated the data at low multiplicity (\(N_{\mathrm {ch}}< 5\)), and slightly overestimated the data at high multiplicities (\(N_{\mathrm {ch}}> 55\)) [3].
In the present data, for all event classes, already at \(\sqrt{s} = 0.9\) TeV, there is a hint that single NBD fits start diverging from the data at the higher multiplicity, for \(|\eta |<\) 0.5 and 1.0. More significant departure from single NBD starts at \(\sqrt{s} = 2.76\) TeV. The values of \({\chi ^2}/{\mathrm {dof}}\) reflect this, as they are rather high and increase further with increasing centre-of-mass energies.
The appearance of substructures in multiplicity distributions attributed to the occurrence of several sources in the process of particle production [81,82,83,84], can be parameterized by fitting the data with two NBDs. Indeed, a much better fit to the data is obtained by using a weighted sum of two NBD functions
This type of function, however, is not meant to describe the value P(0) for INEL and NSD distributions, which occurs when the \(\eta \) acceptance is limited, therefore the bin \(n = 0\) was excluded from the fit and an overall normalization factor (\(\lambda \)) was introduced, as a free parameter, to account for this. At \(\sqrt{s} = 7\) TeV, P. Gosh et al. in [79] perform a similar fit for CMS data, however without using an overall scale factor (\(\lambda \)) and with no account for the effect of bin-to-bin correlations.
As was described in Sect. 8.2.2, 18 multiplicity distributions, corresponding to main sources of correlated uncertainty, were fitted independently. For each of these distributions systematic uncertainties corresponding to the non-leading sources were found to have negligible correlations, as expected. Thus these residual systematic uncertainties were added to the diagonals of the statistical covariance matrices for these distributions, that were produced in the unfolding procedure. In Tables 9, 10 and 11 we present the central values of the fit parameters, i.e. center of the maximum spread of each parameter between the 18 independent fits. Half of the spread is used to estimate the systematic uncertainty of the parameters (the statistical uncertainty being negligible). However these estimates should be treated with caution due to the significant correlations between parameters. The multiplicity distributions for each of the 18 cases differ by their slope and intersect at low-to-middle values of multiplicity (\(N_{\mathrm {ch}}\approx 10\) to 30 depending on \(\eta \) window and energy). There is no single point of intersection for a given set, but rather a small interval. Therefore extreme cases were selected as the curves with highest and lowest values at high multiplicities (and consequently lowest and highest values at low multiplicity). To indicate the change in shape of the parametrization allowed by the correlations present in systematic uncertainties, the parameters for these extreme cases are given in Tables 9, 10 and 11 as well.
The shape evolution is quantified by the parameter \(\langle n\rangle _2\), which tends to increase with increasing \(\eta \) range and with increasing centre-of-mass energy. The observed relation \(\langle n\rangle _2 \approx 3\times \langle n\rangle _1\), is consistent with the analysis of CMS data reported in [79], despite the fact that the scaling parameter \(\lambda \) was not used in their fit function.
In the bins \(\left| \eta \right| < 1\) and \(\left| \eta \right| < 1.5\), the CMS NSD data at \(\sqrt{s} = 0.9\) TeV (Fig. 17) showed a different trend at high multiplicity as compared to the ALICE data (Sect. 9.4). We have made our own fit of CMS data excluding the bin \(N_{\mathrm {ch}}= 0\) (Table 12) and using the overall scaling parameter (\(\lambda \)). As we cannot take into account correlations within CMS data, we compare these fits with fits of our final distributions, ignoring the correlations. We find that the relative weight of the second NBD component in the CMS data is smaller than in the ALICE data, while other parameters are compatible within their respective uncertainties. This confirms the different trends observed in distribution tails.
In conclusion, a double-NBD function provides a precise description of the entire set of multiplicity distributions measured in this experiment.
9.6 KNO studies
The KNO variable \({N_{\mathrm {ch}}}/{\langle N_{\mathrm {ch}}\rangle }\) provides another way to study the evolution of the shape of multiplicity distributions with varying centre-of-mass energies and varying pseudorapidity intervals. This study is carried out for the NSD event class only so that SD events, which may have a different behaviour, are not included in the data samples.
The quantities of interest are derived from the original set of 72 multiplicity distributions and the resulting spread is used to estimate the various uncertainties presented in this section.
9.6.1 Evolution of the shape of multiplicity distributions with \(\sqrt{s}\)
The KNO test in the range 0.9 to 8 TeV is limited by the multiplicity reach at 0.9 TeV. KNO-scaled distributions and their ratios were obtained for each of the available combinations of corrections with the same procedure used for multiplicity distribution measurements (averaging the 72 cases listed in Sect. 8.2 and using the spread as a measure of the systematic uncertainty). Bin to bin correlations were ignored when comparing KNO distributions and q-moments at various centre-of-mass energies. Consequently, the relative errors obtained on the ratios are somewhat overestimated. Ratios between the two highest energies and 0.9 TeV exceed the value 2 at \({N_{\mathrm {ch}}}/{\langle N_{\mathrm {ch}}\rangle }\) larger than 5.5, 5 and 4.5, for \(|\eta | < 0.5\), \(|\eta | < 1\) and \(|\eta | < 1.5\), respectively (Fig. 19). This confirms that KNO scaling violation increases with increasing pseudorapidity intervals. The shape of the KNO scaling violation reflects the fact that the high-multiplicity tail of the distribution increases faster with increasing energy and with increasing pseudorapidity interval than the low (\(N_{\mathrm {ch}}\le 20\)) multiplicity part as already noted in Sect. 9.5.

KNO-scaled distribution \(\langle N_{\mathrm {ch}}\rangle \mathrm {P}\left( N_{\mathrm {ch}}\right) \) versus the KNO variable \({N_{\mathrm {ch}}}/{\langle N_{\mathrm {ch}}\rangle }\) at \(\sqrt{s} =\) 0.9, 2.76, 7 and 8 TeV, for three pseudorapidity intervals: \(|\eta | < 0.5\) (top), 1.0 (middle) and 1.5 (bottom). In each case, ratios to the distribution at \(\sqrt{s} = 0.9\) TeV are shown, on the right-hand side parts of the figures. As \({N_{\mathrm {ch}}}/{\langle N_{\mathrm {ch}}\rangle }\) takes different values at different centre-of-mass energies, ratios were obtained by interpolating the KNO-scaled distributions, and uncertainties were taken from the nearest data point. Bands represent the total uncertainties
9.6.2 Quantitative KNO study with normalized q-moments
Multiplicity distributions may be characterized by their normalized q-moments defined as
where q is a positive integer studied here for values 2, 3, 4 and 5, for NSD events (Fig. 20; Table 13). For the three pseudorapidity intervals studied here (\(|\eta | < 0.5,\) 1 and 1.5), \(C_2\) remains constant over the energy range, \(C_3\) shows a small increase with increasing energy for the two largest \(\eta \) intervals, \(C_4\) and \(C_5\) show an increase with increasing energy, which becomes stronger for larger \(\eta \) intervals. These new data are in agreement with UA5 [29], CMS [36] and ALICE’s previous results [2, 3] in all cases where a comparison was possible (Fig. 20).

Centre-of-mass energy dependence of the q-moments (\(q = 2\) to 4, left-hand scale, and \(q = 5\), right-hand scale) of the multiplicity distributions for NSD events in three different pseudorapidity intervals (\(|\eta | < 1.5\) top, \(|\eta | < 1.0\) middle and \(|\eta | < 0.5\) bottom). ALICE data (black) are compared to UA5 [29] (red) for \(|\eta | < 0.5\) and \(|\eta | < 1\), at \(\sqrt{s} = 0.9\) TeV, and with CMS [36] (blue) at \(\sqrt{s} =\) 0.9 and 7 TeV for \(|\eta | < 0.5\). The error bars represent the combined statistical and systematic uncertainties. The data at 0.9 and 7 TeV are slightly displaced horizontally for visibility
10 Discussion of results and conclusion
The ALICE Collaboration has carried out a detailed study of pseudorapidity densities and multiplicity distributions of primary charged particles produced in proton–proton collisions, at \(\sqrt{s} =\) 0.9, 2.36, 2.76, 7 and 8 TeV, in the pseudorapidity range \(|\eta | < 2\). A large increase of event sample size compared to previous ALICE publications, combined with improved measurement techniques, was used to study the evolution of charged-particle multiplicities over the whole centre-of-mass energy range covered so far by the LHC. The data at the highest energy appear as a smooth continuation of lower energy data, both in shape and in magnitude.
The pseudorapidity density of charged particles, \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\), was measured as a function of pseudorapidity in the range \(|\eta | \le 2\). The relative precision achieved at \(\eta = 0\) for \(\sqrt{s} = 7\) TeV is 5.5, 2.6 and 1.3% for INEL, NSD and INEL0 event classes, respectively.
The power law parameterization of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\), \(s^{\delta }\), provides a good description of the data from ISR to LHC energies: \(\delta = 0.102 \pm 0.003\), \(0.114 \pm 0.003\) and \(0.114 \pm 0.001\), for the INEL, NSD and INEL0 event classes, respectively, to be compared to \(\delta \simeq 0.15\) for Pb–Pb collisions [56]. The ALICE Collaboration has shown clearly that the particle pseudorapidity density increases faster with energy in Pb–Pb collisions than in pp collisions. The extrapolation of \({\mathrm {d} N_{\mathrm {ch}}}/{\mathrm {d}\eta }\) at \(\eta = 0\) to the nominal LHC energy (\(\sqrt{s} = 14\) TeV) is obtained with a precision of 4.6%, 3.0% and 1.3% for INEL, NSD and INEL0 event classes, respectively.
Multiplicity distributions of primary charged particles were measured in three pseudorapidity ranges: \(|\eta | < 0.5\), \(|\eta | < 1.0\) and \(|\eta | < 1.5\). At \(\sqrt{s} = 7\) TeV, \(N_{\mathrm {ch}}\) reaches about 70, 120 and 150, in \(|\eta |<\) 0.5, 1.0 and 1.5, respectively, with the present statistics. These correspond to multiplicity densities 8 to 10 times the average multiplicity density. Based on the Bjorken formula [85], a characteristic collision energy density can be estimated, which increases by the same factor. For a qualitative estimate, assuming that the average energy density in pp collisions at \(\sqrt{s} = 7\) TeV is of the order of 1 GeV/fm\(^3\) (see for example [78]), a density of 10 GeV/fm\(^3\) should be reached with high multiplicity pp collisions, similar to the energy density of Au–Au central collisions at RHIC [86]. When LHC runs at its nominal centre-of-mass energy of 14 TeV, high multiplicity proton–proton collisions will provide further direct comparisons of nuclear matter properties for interacting systems with similar energy densities but very different volumes.
At LHC energies, above 2 TeV, multiplicity distributions can no longer be represented by a single NBD, but a double NBD gives a good representation of the data. The deviation from single NBD is already visible in the tail of the distributions at \(\sqrt{s} = 0.9\) TeV, but becomes increasingly large as the centre-of-mass energy increases.
A test of KNO scaling between \(\sqrt{s} = 0.9\) and 8 TeV confirms that KNO scaling violation increases with increasing \(\sqrt{s}\) and, at a given centre-of-mass energy, with increasing width of pseudorapidity intervals.
Comparisons with models in the pseudorapidity range \(|\eta | \le 1\) show that none of the event generators considered is able to describe all properties of charged particle production up to \(\sqrt{s} = 8\) TeV. PYTHIA6 Perugia 2011, PYTHIA8 4C and EPOS LHC describe the pseudorapidity densities fairly well at \(\sqrt{s} =\) 7 TeV, as well as the multiplicity distributions, but not above \(N_{\mathrm {ch}}\sim 60\). The fact that PYTHIA6 Perugia 2011, PYTHIA8 4C and EPOS LHC are in reasonable agreement with the data presented in this publication can probably be attributed to the fact that these generators were adjusted using the first LHC data.
Studies of charged-particle production are refining the understanding of global properties of proton–proton collisions at the LHC. It was already demonstrated that, as with lower energy data, there is a strong correlation between multiplicity and mean transverse momentum \(\langle p_{\mathrm {T}} \rangle \) [87]. However, there is also evidence [4] that the high multiplicity events have a topology more spherical than expected from current event generators PYTHIA6, PYTHIA8 and PHOJET, suggesting that single hard-parton collisions may not be the only contributors to high multiplicity events. The general picture that emerges from this study is that, from \(\sqrt{s} = 0.9\) to 8 TeV, multiplicity distributions and charged particle pseudorapidity densities follow a smooth evolution.
Notes
Primary particles are defined as prompt particles produced in the collision including all decay products, except those from weak decays of light flavour hadrons and muons.
A tracklet is a short track segments in the SPD, compatible with the event vertex.
Tracks reconstructed in the TPC and matched to ITS clusters (see Sect. 5.1 and references therein).
The response matrix is a 2-dimensional matrix obtained from the simulation giving the correspondence between generated and observed multiplicities. A response matrix column consists of the digitized distribution of the probability to measure a given multiplicity for a given generated multiplicity.
Potentially \(|\eta |\lesssim 3\) can be reached using event vertices displaced from the detector center at distances \(|z_\mathrm{vtx}| \gtrsim 30\) cm (see Fig. 1), however the sample size of such events is too small.
The uncertainty on \(\delta \) was obtained, assuming that the data errors are independent at different centre-of-mass energies, which is not strictly the case.
References
ALICE Collaboration, K. Aamodt et al., First proton–proton collisions at the LHC as observed with the ALICE detector: measurement of the charged particle pseudorapidity density at \(\sqrt{s} = 900\) GeV. Eur. Phys. J. C 65, 111–125 (2010). doi:10.1140/epjc/s10052-009-1227-4. arXiv:0911.5430 [hep-ex]
ALICE Collaboration, K. Aamodt et al., Charged-particle multiplicity measurement in proton–proton collisions at \(\sqrt{s}=0.9\) and 2.36 TeV with ALICE at LHC. Eur. Phys. J. C 68, 89–108 (2010). doi:10.1140/epjc/s10052-010-1339-x. arXiv:1004.3034 [hep-ex]
ALICE Collaboration, K. Aamodt et al., Charged-particle multiplicity measurement in proton–proton collisions at \(\sqrt{s}=7\) TeV with ALICE at LHC. Eur. Phys. J. C 68, 345–354 (2010). doi:10.1140/epjc/s10052-010-1350-2. arXiv:1004.3514 [hep-ex]
ALICE Collaboration, K. Aamodt et al., Strange particle production in proton–proton collisions at \(\sqrt{s} = 0.9\) TeV with ALICE at the LHC. Eur. Phys. J. C 71, 1594 (2011). doi:10.1140/epjc/s10052-011-1594-5. arXiv:1012.3257 [hep-ex]
ALICE Collaboration, B. Abelev et al., Production of charged pions, kaons and protons at large transverse momenta in pp and PbPb collisions at \(\sqrt{s_{\rm NN}} =2.76\) TeV. Phys. Lett. B 736, 196–207 (2014). arXiv:1401.1250 [nucl-ex]
ALICE Collaboration, B. Abelev et al., Multi-strange baryon production in \(pp\) collisions at \(\sqrt{s} = 7\) TeV with ALICE. Phys. Lett. B 712, 309–318 (2012). doi:10.1016/j.physletb.2012.05.011. arXiv:1204.0282 [nucl-ex]
ALICE Collaboration, B. Abelev et al., Production of \(K^*(892)^0\) and \(\phi (1020)\) in \(pp\) collisions at \(\sqrt{s}=7\) TeV. Eur. Phys. J. C 72, 2183 (2012). doi:10.1140/epjc/s10052-012-2183-y. arXiv:1208.5717 [hep-ex]
ALICE Collaboration, J. Adam et al., Measurement of pion, kaon and proton production in proton–proton collisions at \(\sqrt{s} = 7\) TeV. Eur. Phys. J. C 75(5), 226 (2015). arXiv:1504.00024 [nucl-ex]
R. Glauber, Cross-sections in deuterium at high-energies. Phys. Rev. 100, 242–248 (1955)
R. Glauber, Lectures in Theoretical Physics, vol. 1 (W.E. Britten and L.G. Dunham, New York, 1959)
R.J. Glauber, Quantum optics and heavy ion physics. Nucl. Phys. A 774, 3–13 (2006). doi:10.1016/j.nuclphysa.2006.06.009. arXiv:nucl-th/0604021 [nucl-th]
ALICE Collaboration, B. Abelev et al., Centrality determination of Pb–Pb collisions at \(\sqrt{s_{NN}} = 2.76\) TeV with ALICE. Phys. Rev. C 88(4), 044909 (2013). doi:10.1103/PhysRevC.88.044909. arXiv:1301.4361 [nucl-ex]
ALICE Collaboration, B. Abelev et al., Transverse sphericity of primary charged particles in minimum bias proton–proton collisions at \(\sqrt{s}=0.9\), 2.76 and 7 TeV. Eur. Phys. J. C 72, 2124 (2012). arXiv:1205.3963 [hep-ex]
P. Collins, An Introduction to Regge Theory and High-Energy Physics (Cambridge University Press, Cambridge, 1977)
V.N. Gribov, The Theory of Complex Angular Momenta. Gribov Lectures on Theoretical Physics (Cambridge University Press, Cambridge, 2003)
V. Gribov, Strong Interactions of Hadrons at High Energies. Gribov Lectures on Theoretical Physics, Cambridge Monographs on Particle Physics, Nuclear Physics and Cosmology, vol. 27. (Cambridge University Press, Cambridge, 2009)
V. Abramowsky, V. Gribov, O. Kancheli, AGK cutting rules. Sov. J. Nucl. Phys. 18(308), 21 (1974)
A. Kaidalov, The quark-gluon structure of the Pomeron and the rise of inclusive spectra at high-energies. Phys. Lett. B 116, 459 (1982). doi:10.1016/0370-2693(82)90168-X
A. Kaidalov, M. Poghosyan, Predictions of quark-gluon string model for pp at LHC. Eur. Phys. J. C 67, 397–404 (2010). doi:10.1140/epjc/s10052-010-1301-y. arXiv:0910.2050 [hep-ph]
A. Kaidalov, L. Ponomarev, K. Ter-Martirosian, Total cross-sections and diffractive scattering in a theory of interacting Pomerons with \(\alpha _p (0)>1\). Sov. J. Nucl. Phys. 44, 468 (1986)
A. Capella, E. Ferreiro, Charged multiplicities in pp and AA collisions at LHC. Eur. Phys. J. C 72, 1936 (2012). doi:10.1140/epjc/s10052-012-1936-y. arXiv:1110.6839 [hep-ph]
M. Froissart, Asymptotic behavior and subtractions in the Mandelstam representation. Phys. Rev. 123, 1053–1057 (1961). doi:10.1103/PhysRev.123.1053
A. Polyakov, A similarity hypothesis in the strong interactions. 1. Multiple hadron production in e\(^+\) e\(^-\) annihilation. Sov. Phys. JETP 32, 296 (1971)
Z. Koba, H.B. Nielsen, P. Olesen, Scaling of multiplicity distributions in high-energy hadron collisions. Nucl. Phys. B 40, 317–334 (1972). doi:10.1016/0550-3213(72)90551-2
V. Abramovskii, O. Kancheli, Regge branching and distribution of hadron multiplicity at high energies. Pisma Zh. Eksp. Teor. Fiz. 15, 559–563 (1972)
A. Kaidalov, K. Ter-Martirosian, Pomeron as quark-gluon strings and multiple hadron production at SPS collider energies. Phys. Lett. B 117, 247–251 (1982). doi:10.1016/0370-2693(82)90556-1
Ames-Bologna-CERN-Dortmund-Heidelberg-Warsaw Collaboration, A. Breakstone et al., Charged multiplicity distribution in p p interactions at ISR energies. Phys. Rev. D 30, 528 (1984). doi:10.1103/PhysRevD.30.528
TASSO Collaboration, M. Althoff et al., Jet production and fragmentation in e\(^+\) e\(^-\) annihilation at 12-GeV to 43-GeV. Z. Phys. C 22, 307–340 (1984). doi:10.1007/BF01547419
UA5 Collaboration, R. Ansorge et al., Charged-particle multiplicity distributions at 200 GeV and 900 GeV center-of-mass energy. Z. Phys. C 43, 357 (1989). doi:10.1007/BF01506531
T. Chou, C.N. Yang, Remarks on multiplicity fluctuations and KNO scaling in \({\bar{\rm{p}}} {\rm{p}}\) collider experiments. Phys. Lett. B 116, 301 (1982). doi:10.1016/0370-2693(82)90348-3
UA5 Collaboration, K. Alpgard et al., Charged particle multiplicities at the CERN SPS collider. Phys. Lett. B 107, 315 (1981). doi:10.1016/0370-2693(81)90838-8
UA1 Collaboration, G. Arnison et al., Charged particle multiplicity distributions in proton anti-proton collisions at 540 GeV center-of-mass energy. Phys. Lett. B 123, 108 (1983). doi:10.1016/0370-2693(83)90969-3
C. Kam, Y. Lim, K. Phua, On approximate KNO scaling at \({\bar{\rm{p}}}{\rm{p}}\) collider. Z. Phys. C 26, 381–383 (1984). doi:10.1007/BF01452563
CMS Collaboration, R. Rougny, Charged particle multiplicities at \(\sqrt{s} = 0.9\) TeV, 2.36 TeV, and 7 TeV with the CMS detector at LHC. PoS ICHEP2010, 358 (2010)
CMS Collaboration, V. Khachatryan et al., Transverse-momentum and pseudorapidity distributions of charged hadrons in \(pp\) collisions at \(\sqrt{s}=7\) TeV. Phys. Rev. Lett. 105, 022002 (2010). arXiv:1005.3299 [hep-ex]
CMS Collaboration, V. Khachatryan et al., Charged particle multiplicities in pp interactions at \(\sqrt{s}=0.9\), 2.36, and 7 TeV. JHEP 1101, 079 (2011). doi:10.1140/epjc/s10052-009-1227-4. arXiv:1011.5531 [hep-ex]
ATLAS Collaboration, G. Aad et al., Charged-particle multiplicities in pp interactions measured with the ATLAS detector at the LHC. New J. Phys. 13, 053033 (2011). doi:10.1088/1367-2630/13/5/053033. arXiv:1012.5104 [hep-ex]
LHCb Collaboration, R. Aaij, B. Adeva et al., Measurement of charged particle multiplicities and densities in pp collisions at \(\sqrt{s}=7\) TeV in the forward region. Eur. Phys. J. C 74(5) (2014). doi:10.1140/epjc/s10052-014-2888-1
ALICE Collaboration, K. Aamodt et al., The ALICE experiment at the CERN LHC. JINST 3, S08002 (2008). doi:10.1088/1748-0221/3/08/S08002
J. Alme, Y. Andres, H. Appelshauser, S. Bablok, N. Bialas et al., The ALICE TPC, a large 3-dimensional tracking device with fast readout for ultra-high multiplicity events. Nucl. Instrum. Methods A 622, 316–367 (2010). doi:10.1016/j.nima.2010.04.042. arXiv:1001.1950 [physics.ins-det]
ALICE Collaboration, E. Abbas et al., Performance of the ALICE VZERO system. JINST 8, P10016 (2013). doi:10.1088/1748-0221/8/10/P10016. arXiv:1306.3130 [nucl-ex]
R. Santoro, G. Aglieri Rinella, F. Antinori, A. Badala, F. Blanco et al., The ALICE silicon pixel detector: readiness for the first proton beam. JINST 4, P03023 (2009)
B. Alessandro, S. Antinori, R. Bala, G. Batigne, S. Beole et al., Operation and calibration of the silicon drift detectors of the ALICE experiment during the 2008 cosmic ray data taking period. JINST 5, P04004 (2010). doi:10.1088/1748-0221/5/04/P04004. arXiv:1001.3088 [physics.ins-det]
ALICE Collaboration, G. Nooren, Experience with the silicon strip detector of ALICE. PoS RD09, 009 (2009)
ALICE Collaboration, A. Rossi, ALICE alignment, tracking and physics performance results. PoS VERTEX2010, 017 (2010). arXiv:1101.3491 [physics.ins-det]
M. Krivda, L. Barnby, M. Bombara, D. Evans, P. Jones et al., The ALICE trigger system performance for p-p and Pb-Pb collisions. JINST 7, C01057 (2012). doi:10.1088/1748-0221/7/01/C01057
ALICE Collaboration, B. Alessandro et al., ALICE: physics performance report, volume II. J. Phys. G 32, 1295–2040 (2006). doi:10.1088/0954-3899/32/10/001
ALICE Collaboration, B.B. Abelev et al., Performance of the ALICE experiment at the CERN LHC. Int. J. Mod. Phys. A 29, 1430044 (2014). doi:10.1088/1748-0221/8/10/P10016. arXiv:1402.4476 [nucl-ex]
ALICE Collaboration, B. Abelev et al., Measurement of inelastic, single- and double-diffraction cross sections in proton–proton collisions at the LHC with ALICE. Eur. Phys. J. C 73(6), 2456 (2013). doi:10.1140/epjc/s10052-013-2456-0. arXiv:1208.4968 [hep-ex]
P.Z. Skands, The perugia tunes, in Proceedings, 1st International Workshop on Multiple Partonic Interactions at the LHC (MPI08), Perugia, Italy, 27–31 October 2008 (2009), pp. 284–297. arXiv:0905.3418 [hep-ph]. http://lss.fnal.gov/cgi-bin/find_paper.pl?conf-09-113
T. Sjostrand, High-energy physics event generation with PYTHIA 5.7 and JETSET 7.4. Comput. Phys. Commun. 82, 74–90 (1994). doi:10.1016/0010-4655(94)90132-5
T. Sjostrand, S. Mrenna, P.Z. Skands, PYTHIA 6.4 physics and manual. JHEP 0605, 026 (2006). doi:10.1088/1126-6708/2006/05/026. arXiv:hep-ph/0603175 [hep-ph]
R. Engel, J. Ranft, S. Roesler, Hard diffraction in hadron hadron interactions and in photoproduction. Phys. Rev. D 52, (1995) 1459–1468. doi:10.1103/PhysRevD.52.1459. arXiv:hep-ph/9502319 [hep-ph]
S. Roesler, R. Engel, J. Ranft, The Monte Carlo event generator DPMJET-III, in Advanced Monte Carlo for Radiation Physics, Particle Transport Simulation and Applications. Proceedings, Conference, MC2000, Lisbon, Portugal, 23–26 October 2000, pp. 1033–1038 (2000). arXiv:hep-ph/0012252 [hep-ph]
A.B. Kaidalov, M.G. Poghosyan, Description of soft diffraction in the framework of reggeon calculus: Predictions for LHC, in Elastic and Diffractive Scattering. Proceedings, 13th International Conference, Blois Workshop, CERN, Geneva, Switzerland, 29 June–3 July 2009, pp. 91–98 (2009). arXiv:0909.5156 [hep-ph]
ALICE Collaboration, K. Aamodt et al., Charged-particle multiplicity density at mid-rapidity in central Pb–Pb collisions at \(\sqrt{s_{NN}} = 2.76\) TeV. Phys. Rev. Lett. 105, 252301 (2010). doi:10.1103/PhysRevLett.105.252301. arXiv:1011.3916 [nucl-ex]
J.F. Grosse-Oetringhaus, Measurement of the charged-particle multiplicity in proton–proton collisions with the ALICE detector. Ph.D. thesis, Munster U. (2009)
G. Cowan, Statistical Data Analysis (Oxford University Press, Oxford, 1998)
ALICE Collaboration, B. Abelev et al., Neutral pion and \(\eta \) meson production in proton–proton collisions at \(\sqrt{s}=0.9\) TeV and \(\sqrt{s}=7\) TeV. Phys. Lett. B 717, 162–172 (2012). doi:10.1016/j.physletb.2012.09.015. arXiv:1205.5724 [hep-ex]
ALICE Collaboration, K. Aamodt et al., Transverse momentum spectra of charged particles in proton–proton collisions at \(\sqrt{s} = 900\) GeV with ALICE at the LHC. Phys. Lett. B 693, 53–68 (2010). doi:10.1016/j.physletb.2010.08.026. arXiv:1007.0719 [hep-ex]
ALICE Collaboration, B.B. Abelev et al., Energy dependence of the transverse momentum distributions of charged particles in pp collisions measured by ALICE. Eur. Phys. J. C 73(12), 2662 (2013). doi:10.1140/epjc/s10052-013-2662-9. arXiv:1307.1093 [nucl-ex]
G. D’Agostini, A multidimensional unfolding method based on Bayes’ theorem. Nucl. Instrum. Methods A 362, 487–498 (1995). doi:10.1016/0168-9002(95)00274-X
A. Hocker, V. Kartvelishvili, SVD approach to data unfolding. Nucl. Instrum. Methods A 372, 469–481 (1996). doi:10.1016/0168-9002(95)01478-0. arXiv:hep-ph/9509307 [hep-ph]
M. Poghosyan, Two remarks about UA5 published data on general characteristics of \(p\bar{p}\) collisions at \(\sqrt{s} = 900\) GeV. arXiv:1005.1806 [hep-ph]
T. Pierog, I. Karpenko, J.M. Katzy, E. Yatsenko, K.Werner, EPOS LHC: test of collective hadronization with data measured at the CERN Large Hadron Collider. Phys. Rev. C 92(3), 034906 (2015). arXiv:1306.0121 [hep-ph]
T. Sjostrand, S. Mrenna, P.Z. Skands, A brief introduction to PYTHIA 8.1. Comput. Phys. Commun. 178, 852–867 (2008). doi:10.1016/j.cpc.2008.01.036. arXiv:0710.3820 [hep-ph]
R. Corke, T. Sjostrand, Interleaved parton showers and tuning prospects. JHEP 1103, 032 (2011). doi:10.1007/JHEP03(2011)032. arXiv:1011.1759 [hep-ph]
UA5 Collaboration, G. Alner et al., Scaling of pseudorapidity distributions at c.m. energies up to 0.9-TeV. Z. Phys. C 33, 1–6 (1986). doi:10.1007/BF01410446
CMS Collaboration, V. Khachatryan et al., Pseudorapidity distribution of charged hadrons in proton–proton collisions at \(\sqrt{s} = 13\) TeV. Phys. Lett. B 751, 143–163 (2015). arXiv:1507.05915 [hep-ex]
UA1 Collaboration, C. Albajar et al., A study of the general characteristics of \({\bar{\rm {p}}}{\rm {p}}\) collisions at \(\sqrt{s} = 0.2\) TeV to 0.9 TeV. Nucl. Phys. B 335, 261 (1990). doi:10.1016/0550-3213(90)90493-W
STAR Collaboration, B. Abelev et al., Systematic measurements of identified particle spectra in pp, d\(^+\)Au and Au+Au collisions from STAR. Phys. Rev. C 79, 034909 (2009). doi:10.1103/PhysRevC.79.034909. arXiv:0808.2041 [nucl-ex]
CDF Collaboration, F. Abe et al., Pseudorapidity distributions of charged particles produced in \({\bar{\rm {p}}}{\rm {p}}\) interactions at \(\sqrt{s} = 630\) GeV and 1800 GeV. Phys. Rev. D 41, 2330 (1990). doi:10.1103/PhysRevD.41.2330
PHOBOS Collaboration, R. Nouicer et al., Pseudorapidity distributions of charged particles in d\(^+\)Au and pp collisions at \(\sqrt{s_{NN}} = 200\) GeV. J. Phys. G 30, S1133–S1138 (2004). doi:10.1088/0954-3899/30/8/075. arXiv:nucl-ex/0403033 [nucl-ex]
Aachen-CERN-Heidelberg-Munich Collaboration, W. Thome et al., Charged-particle multiplicity distributions in pp collisions at ISR energies. Nucl. Phys. B 129, 365 (1977). doi:10.1016/0550-3213(77)90122-5
UA5 Collaboration, K. Alpgard et al., Comparison of \({\bar{\rm{p}}}{\rm{p}}\) and pp interactions at \(\sqrt{s} = 53\) GeV. Phys. Lett. B 112, 183 (1982). doi:10.1016/0370-2693(82)90325-2
M. Ambrosio, G. Anzivino, G. Barbarino, G. Carboni, V. Cavasinni, T. Del Prete, P. Grannis, G. Kantardjian, D. L. Owen, M. Morganti et al., Total and elastic cross-sections and global event characteristics in \({\bar{\rm {p}}}{\rm {p}}\) and pp collisions at \(\sqrt{s} = 53\) GeV, in Proton–Antiproton Collider Physics-1981, vol. 85. (Madison, 1981), pp. 602–625
UA5 Collaboration, G. Alner et al., UA5: a general study of proton–antiproton physics at \(\sqrt{s} = 546\) GeV. Phys. Rep. 154, 247–383 (1987). doi:10.1016/0370-1573(87)90130-X
M. Csanad, T. Csorgo, Initial energy density of pp collisions at the LHC, in Proc. EDS Blois 2013, Saariselkä, Finnland (2013), p. 53. arXiv:1307.2082 [hep-ph]
P. Ghosh, Negative binomial multiplicity distribution in proton-proton collisions in limited pseudorapidity intervals at LHC up to \(\sqrt{s} = 7\) TeV and the clan model. Phys. Rev. D 85, 054017 (2012). doi:10.1103/PhysRevD.85.054017. arXiv:1202.4221 [hep-ph]
A. Giovannini, L. Van Hove, Negative binomial multiplicity distributions in high-energy hadron collisions. Z. Phys. C 30, 391 (1986). doi:10.1007/BF01557602
G. Fowler, E. Friedlander, R. Weiner, G. Wilk, Possible manifestation of quark-gluon plasma in multiplicity distributions from high-energy reactions. Phys. Rev. Lett. 57, 2119 (1986)
A. Giovannini, R. Ugoccioni, Possible scenarios for soft and semihard components structure in central hadron hadron collisions in the TeV region. Phys. Rev. D 59, 094020 (1999). doi:10.1103/PhysRevD.59.094020, doi:10.1103/PhysRevD.69.059903. arXiv:hep-ph/9810446 [hep-ph]
T. Alexopoulos, E. Anderson, N. Biswas, A. Bujak, D. Carmony et al., The role of double parton collisions in soft hadron interactions. Phys. Lett. B 435, 453–457 (1998). doi:10.1016/S0370-2693(98)00921-6
W.D. Walker, Multiparton interactions and hadron structure. Phys. Rev. D 69, 034007 (2004). doi:10.1103/PhysRevD.69.034007
J. Bjorken, Highly relativistic nucleus–nucleus collisions: the central rapidity region. Phys. Rev. D 27, 140–151 (1983). doi:10.1103/PhysRevD.27.140
L. McLerran, RHIC and high energy density matter. Annales Henri Poincaré 4, S229–S242 (2003). doi:10.1007/s00023-003-0918-x
ALICE Collaboration, B. Abelev et al., Multiplicity dependence of the average transverse momentum in pp, p–Pb, and Pb–Pb collisions at the LHC. Phys. Lett. B 727, 371–380 (2013). doi:10.1016/j.physletb.2013.10.054. arXiv:1307.1094 [nucl-ex]
Acknowledgements
The ALICE Collaboration would like to thank all its engineers and technicians for their invaluable contributions to the construction of the experiment and the CERN accelerator teams for the outstanding performance of the LHC complex. The ALICE Collaboration gratefully acknowledges the resources and support provided by all Grid centres and the Worldwide LHC Computing Grid (WLCG) collaboration. The ALICE Collaboration acknowledges the following funding agencies for their support in building and running the ALICE detector: A. I. Alikhanyan National Science Laboratory (Yerevan Physics Institute) Foundation (ANSL), State Committee of Science and World Federation of Scientists (WFS), Armenia; Austrian Academy of Sciences and Nationalstiftung für Forschung, Technologie und Entwicklung, Austria; Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), Universidade Federal do Rio Grande do Sul (UFRGS), Financiadora de Estudos e Projetos (Finep) and Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP), Brazil; Ministry of Science and Technology of China (MSTC), National Natural Science Foundation of China (NSFC) and Ministry of Education of China (MOEC), China; Ministry of Science, Education and Sport and Croatian Science Foundation, Croatia; Ministry of Education, Youth and Sports of the Czech Republic, Czech Republic; The Danish Council for Independent Research|Natural Sciences, the Carlsberg Foundation and Danish National Research Foundation (DNRF), Denmark; Helsinki Institute of Physics (HIP), Finland; Commissariat à l’Energie Atomique (CEA) and Institut National de Physique Nucléaire et de Physique des Particules (IN2P3) and Centre National de la Recherche Scientifique (CNRS), France; Bundesministerium für Bildung, Wissenschaft, Forschung und Technologie (BMBF) and GSI Helmholtzzentrum für Schwerionenforschung GmbH, Germany; Ministry of Education, Research and Religious Affairs, Greece; National Research, Development and Innovation Office, Hungary; Department of Atomic Energy Government of India (DAE), India; Indonesian Institute of Science, Indonesia; Centro Fermi-Museo Storico della Fisica e Centro Studi e Ricerche Enrico Fermi and Istituto Nazionale di Fisica Nucleare (INFN), Italy; Institute for Innovative Science and Technology, Nagasaki Institute of Applied Science (IIST), Japan Society for the Promotion of Science (JSPS) KAKENHI and Japanese Ministry of Education, Culture, Sports, Science and Technology (MEXT), Japan; Consejo Nacional de Ciencia (CONACYT) y Tecnología, through Fondo de Cooperación Internacional en Ciencia y Tecnología (FONCICYT) and Dirección General de Asuntos del Personal Academico (DGAPA), Mexico; Nationaal instituut voor subatomaire fysica (Nikhef), Netherlands; The Research Council of Norway, Norway; Commission on Science and Technology for Sustainable Development in the South (COMSATS), Pakistan; Pontificia Universidad Católica del Perú, Peru; Ministry of Science and Higher Education and National Science Centre, Poland; Korea Institute of Science and Technology Information and National Research Foundation of Korea (NRF), Republic of Korea; Ministry of Education and Scientific Research, Institute of Atomic Physics and Romanian National Agency for Science, Technology and Innovation, Romania; Joint Institute for Nuclear Research (JINR), Ministry of Education and Science of the Russian Federation and National Research Centre Kurchatov Institute, Russia; Ministry of Education, Science, Research and Sport of the Slovak Republic, Slovakia; National Research Foundation of South Africa, South Africa; Centro de Aplicaciones Tecnológicas y Desarrollo Nuclear (CEADEN), Cubaenergía, Cuba, Ministerio de Ciencia e Innovacion and Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas (CIEMAT), Spain; Swedish Research Council (VR) and Knut and Alice Wallenberg Foundation (KAW), Sweden; European Organization for Nuclear Research, Switzerland; National Science and Technology Development Agency (NSDTA), Suranaree University of Technology (SUT) and Office of the Higher Education Commission under NRU project of Thailand, Thailand; Turkish Atomic Energy Agency (TAEK), Turkey; National Academy of Sciences of Ukraine, Ukraine; Science and Technology Facilities Council (STFC), United Kingdom; National Science Foundation of the United States of America (NSF) and United States Department of Energy, Office of Nuclear Physics (DOE NP), United States of America.
Author information
Authors and Affiliations
Consortia
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Adam, J., Adamová, D., Aggarwal, M.M. et al. Charged-particle multiplicities in proton–proton collisions at \(\sqrt{s} = 0.9\) to 8 TeV. Eur. Phys. J. C 77, 33 (2017). https://doi.org/10.1140/epjc/s10052-016-4571-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-016-4571-1