
Abstract
We calculate the cross section for the inclusive production of \(B\) mesons in \(pp\) and \(p\bar{p}\) collisions at next-to-leading order in the general-mass variable-flavor-number scheme and show that a suitable choice of factorization scales leads to a smooth transition to the fixed-flavor-number scheme. Our numerical results are in good agreement with data from the Tevatron and LHC experiments at small and at large transverse momenta.
Similar content being viewed by others

1 Introduction
In the last 25 years, there has been much interest in the study of \(B\)-meson production in \(p\bar{p}\) and \(pp\) collisions at hadron colliders, both experimentally and theoretically. First measurements were done in the late 1980s by the UA1 Collaboration at the CERN \(Sp\bar{p}S\) collider [1] operating at a center-of-mass energy of \(\sqrt{S}=0.63\) TeV. Later measurements were performed by the CDF and D0 Collaborations at the Fermilab Tevatron in \(p\bar{p}\) collisions at \(\sqrt{S}=1.8\) TeV [2–5] and \(\sqrt{S}=1.96\) TeV [6–8]. Recently, the CMS [9–11], ATLAS [12, 13], and LHCb [14, 15] Collaborations at the CERN Large Hadron Collider (LHC) published their results for inclusive \(B^+\), \(B^0\), and \(B_s\) meson production in \(pp\) collisions at \(\sqrt{S}=7\) TeV. In all these measurements, the differential cross sections \(\mathrm{d}\sigma /\mathrm{d}p_T\), where \(p_T\) is the transverse momentum of the \(B\) meson, integrated over specific rapidity (\(y\)) regions, or \(\mathrm{d}\sigma /\mathrm{d}y\) integrated over \(p_T \ge p_{T, \mathrm{min}}\) were obtained. While the CMS and ATLAS data were obtained at central rapidities, LHCb performed measurements at forward rapidities, \(2 < y < 4.5\). Actually, only a few measurements were able to explore the small-\(p_T\) range down to \(p_{T, \mathrm{min}} \simeq 0\), namely those by CDF [6] and the two by LHCb [14, 15]. In all other data, the cut \(p_{T, \mathrm{min}} > 5\) GeV was imposed. A unified theoretical description of these data, which covers both the very small and the large \(p_T\) range, requires special efforts, which we shall undertake in this paper.
On the theoretical side, it is generally accepted that for the treatment of \(B\)-meson production at small \(p_T\) values, as well as for the calculation of the integrated cross section including the small-\(p_T\) range, i.e., with \(p_{T}\) of order \(O(m_b)\) and below, where \(m_b\) is the \(b\)-quark mass, one should use the so-called massive scheme or fixed-flavor-number scheme (FFNS) [16–20], in which the number of active quark flavors in the initial state is limited to \(n_f=4\), and the \(b\) quark appears with explicit mass dependence only in the final state. In this case, the \(b\) quark is treated as a heavy particle in the final state and not as a parton in the initial (anti)proton.
In the large-\(p_T\) region, characterized by \(p_T \gg m_b\), the so-called massless scheme or zero-mass variable-flavor-number scheme (ZM-VFNS) [21–32] is considered to be appropriate. This is the conventional parton model approach, where the \(b\) quark is considered massless like any other parton. The \(b\) quark is also treated as an incoming parton coming from the (anti)proton leading to additional contributions from hard-scattering subprocesses besides those with \(u\), \(d\), \(s\), and \(c\) quarks or the gluon (\(g\)) in the initial state. Although this approach can be used as soon as the factorization scales \(\mu _I\) and \(\mu _F\) associated with the initial- and final-state singularities are above the starting scale of the parton distribution functions (PDFs) and fragmentation functions (FFs), its predictions are reliable only in the large-\(p_T\) region, \(p_T \gg m_b\), where terms of the order of \(m_b^2/p_T^2\) can be safely neglected. A next-to-leading-order (NLO) calculation in this scheme automatically resums leading and next-to-leading logarithmic terms. At the same time, all non-logarithmic terms through \(O(\alpha _s)\) relative to the Born approximation are retained for \(m_b = 0\). With the conventional choice of renormalization and factorization scales, \(\mu _R = \mu _I = \mu _F = m_T\) with \(m_T = \sqrt{p_T^2+m_b^2}\), the results are dominated by contributions from the \(b\)-quark PDF down to \(p_T \simeq 0\).
On the other hand, the general-mass variable-flavor-number scheme (GM-VFNS) [33–48] provides a theoretical framework which combines the FFNS and the ZM-VFNS. The ZM-VFNS is extended into the intermediate-\(p_T\) range by retaining the mass-dependent terms of the FFNS. With the conventional choice of scales indicated above, the results in this scheme are also dominated by the contributions of the \(b\)-quark PDF down to \(p_T \simeq 0\). As a consequence, there is no smooth transition from the GM-VFNS at large \(p_T\) values to the FFNS in the small-\(p_T\) range, and the GM-VFNS fails to describe the small-\(p_T\) CDF and LHCb data.
The dominance of contributions with \(b\) quarks in the initial state at small \(p_T\) values is linked to the fact that this part is treated in the massless scheme, as a calculation of the \(b\)-quark-initiated subprocesses in a scheme with massive partons (like the ACOT scheme [49]) is not available for hadroproduction.Footnote 1 The cross section with massless partons is, however, divergent for \(p_T \rightarrow 0\). For a realistic description, we thus have to find a way to eliminate or modify this contribution in the small-\(p_T\) region. In this paper, we shall develop an approach to modify the GM-VFNS in such a way that it matches the FFNS with the exact \(m_b\) dependence by a suitable choice of \(\mu _I\) and \(\mu _F\). We shall study how these modifications can lead to a better agreement with presently available experimental data at small \(p_T\) values.
The content of this paper is as follows. In Sect. 2, we introduce our strategy for the transition to the FFNS and compare our predictions with the CDF [6] and LHCb [15] data. We shall also present results to be compared with measurements by the ATLAS Collaboration [13]. Our conclusions are presented in Sect. 3.
2 Small-\(p_T\) results and comparisons with data
In this section, we shall discuss a viable unified framework for theoretical predictions of inclusive \(B\)-meson production at small and large \(p_T\) values. We shall compare with the cross section distributions \(\mathrm{d}\sigma /\mathrm{d}p_T\) measured by CDF [6] and LHCb [15]. Throughout this paper, we take the \(b\)-quark pole mass to be \(m_b = 4.5\) GeV, evaluate \(\alpha _s^{(n_f)}(\mu _R)\) at NLO with \(n_f = 4\) and \(\Lambda _{\overline{\mathrm {MS}}}^{(4)} = 328\) MeV if \(\mu _R<m_b\) and with \(n_f = 5\) and \(\Lambda _{\overline{\mathrm {MS}}}^{(5)} = 226\) MeV if \(\mu _R>m_b\), and use the CTEQ6.6M proton PDFs [51] unless otherwise stated.
We start with results to be compared with the CDF data [6]. In Fig. 1, we show NLO predictions in the FFNS with \(n_f = 4\). The full line shows the result for the default choice of scales, \(\mu _i = \xi _i m_T\) with \(\xi _i = 1\) for \(i=R,I\), while the dashed lines represent an estimate of the theoretical error obtained in the usual way, by varying \(\xi _i\) up and down by a factor of 2. We take the transition of \(b\) and \(\bar{b}\) quarks to the observed \(B\) mesons into account by using the branching fraction \(B(b \rightarrow B) = 39.8\,\%\) [52] as an overall normalization factor. The prediction in the FFNS agrees with the CDF data quite well, within experimental errors, up to \(p_T \simeq 15\) GeV. Beyond this value of \(p_T\), the FFNS starts to overestimate the data, as has been shown already in our previous publication [42].

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(p\bar{p}\rightarrow B^++X\) with \(\sqrt{S}=1.96\) TeV and \(-1\le y\le 1\) in the FFNS are compared with CDF data [6]. The dashed lines represent the theoretical uncertainty estimated by varying \(\mu _R\) and \(\mu _I\) up and down by a factor of 2 about the default choice \(\mu _R = \mu _I = m_T\)
In the FFNS, there is no need for FFs. However, a \(\mu _F\)-independent FF might be introduced on phenomenological grounds and because of theoretical considerations to guarantee a proper matching between the schemes with \(n_f=4\) and \(n_f=5\). In the left panel of Fig. 2, we show results obtained using the \(\mu _F\)-independent Peterson FF [53] with parameter \(\epsilon = 10^{-4}\). We find only marginal differences with respect to the case where a constant branching fraction is used. Note that there are no \(g,q,\bar{q} \rightarrow B\) transitions in the FFNS.
In addition to uncertainties from scale variations, there are also uncertainties due to errors in the input. We postpone the discussion of errors in the parametrizations of the PDFs to when we present predictions for the LHCb experiments, in Fig. 8 below, but instead show the influence of \(m_b\) variations on the default prediction for the Tevatron measurement in the right panel of Fig. 2. At small \(p_T\) values, the uncertainty is comparable in size with the scale uncertainty, but it is negligible for \(p_T\gtrsim 2m_b\).

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(p\bar{p}\rightarrow B^++X\) with \(\sqrt{S}=1.96\) TeV and \(-1\le y\le 1\) in the FFNS are compared with CDF data [6]. Left panel evaluation using the Peterson FF with \(\epsilon = 10^{-4}\) and varying \(\mu _R\) and \(\mu _I\) by a factor of 2 up and down about the default choice \(\mu _R = \mu _I = m_T\). Right panel uncertainties from variations of \(m_b\)
In Ref. [42], we presented detailed comparisons of FFNS and GM-VFNS results with CDF data for \(B^+\) production (see, e.g., Figs. 7 and 8 in Ref. [42]). For calculations in the GM-VFNS, we use the \(\mu _F\)-dependent FFs described in Ref. [42]. In this case, there are also small contributions due to transitions from light quarks and gluons to \(B\) mesons. With the default choice \(\xi _R = \xi _I = \xi _F= 1\), the GM-VFNS predictions diverge for \(p_T \rightarrow 0\), in obvious disagreement with the data. We notice, however, that the FFNS and GM-VFNS predictions approach each other at around \(p_T \simeq 20\) GeV, i.e. 4 to 5 times \(m_b\). In Fig. 3, we show a similar comparison of the FFNS and GM-VFNS predictions for the case of the LHCb data [15]. Although these data correspond to much higher \(\sqrt{S}\) values and to different \(y\) ranges compared with the previous results in Ref. [42], we observe similar qualitative behaviors of the FFNS and GM-VFNS predictions and a transition point at about the same value of \(p_T\), namely \(p_T\simeq 20\) GeV.

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(pp\rightarrow B^\pm +X\) with \(\sqrt{S}=7\) TeV and \(2\le y\le 4.5\) in the FFNS (dashed line) and the GM-VFNS (solid line) are compared with LHCb data [15]
One should expect that a correct treatment of kinematic constraints due to the finite heavy-hadron mass is important, in particular at small \(p_T\) values. However, there is no unique prescription to take into account the finite masses of the heavy quark and the heavy hadron at the same time. A prescription for including the heavy-hadron mass in connection with massless quarks based on the light-cone scaling variable was introduced in Ref. [54]. Here, we propose a generalization to the massive-quark case. This amounts to scaling the partonic cross section for the production of the massive quark \(a\), with mass \(m_a\), energy \(E_a\), and three-momentum \(p_a\), which initiates the formation of the heavy hadron \(H\), with mass \(M_H\), energy \(E_H=\sqrt{M_H^2+p_T^2}\,{\mathrm {cosh}}\,y\), and three-momentum \(p_H=\sqrt{M_H^2{\mathrm {sinh}}^2\,y+p_T^2{\mathrm {cosh}}^2\,y}\), as
where \(z=(E_H + p_H)/(E_h + p_h)\) is the light-cone scaling variable. In contrast to naive expectations, one finds \(R_H < 1\) corresponding to a slight enhancement of the cross section. In Fig. 4, we show the result of a calculation where this correction factor is taken into account. The effect is small mainly because it is only the difference between the \(b\)-quark and \(B\)-meson masses that enters. Therefore, also the additional suppression from tighter phase space limits is numerically not relevant. The poor small-\(p_T\) behavior of the GM-VFNS calculation cannot be remedied by such a naive treatment of phase space restrictions.

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(p\bar{p}\rightarrow B^++X\) with \(\sqrt{S}=1.96\) TeV and \(-1\le y\le 1\) in the GM-VFNS are compared with CDF data [6]. Besides the default prediction for scale parameters \(\xi _i = 1\) (solid line), a theoretical-error band encompassed by the predictions for \(\xi _i = 1/2\) (upper dashed line) and \(\xi _i = 2\) (lower dashed line) is shown. The effect of including quark and hadron mass corrections via the phase space in the default prediction is also shown, for \(M_H = 5.28\) GeV (dotted line)
The results shown in Figs. 1, 2, 3 and 4 suggest that the predictions of the FFNS and the GM-VFNS are very similar in the range 15 GeV\({}\lesssim p_T \lesssim 20\) GeV. In this range, both theories are justified , with the FFNS naturally extending to smaller \(p_T\) values and the GM-VFNS to larger \(p_T\) values. Therefore, one could designate a transition point \(\mu _t\) at \(p_T \simeq 20\) GeV, say, where one switches from one scheme to the other [55, 56]. For practical purposes, this would require the knowledge of the PDFs in the scheme with \(n_f = 4\) active flavors up to \(\mu _I = \mu _t\) [57]. A naive prescription to combine the two schemes could be to use matching functions \(\theta (\mu _t^2 - p_T^2)\) and \([1- \theta (\mu _t^2 - p_T^2)]\) to multiply the FFNS and GM-VFNS cross sections, respectively. Such a prescription will, however, lead to a discontinuity in the combined cross section at \(p_T=\mu _t\), a property that is certainly unphysical. One could try to invent different ways to combine the two schemes by introducing some smooth matching function, e.g., \(G(p_T) = p_T^2 / (p_T^2 + c^2m_b^2)\) with \(c=5\) [58], and imposing, schematically, the prescription \(\sigma = G(p_T) \sigma _{\mathrm {GM-VFNS}} + [1-G(p_T)] \sigma _{\mathrm {FFNS}}\). However, such an approach would introduce a new parameter, and it is unclear how theoretical uncertainties related to the choice of this parameter should be estimated.
It will be helpful to take a closer look at the structure of the partonic cross sections in the GM-VFNS. They involve subtraction terms needed to separate the large logarithms \(\ln (p_T^2 / m_b^2)\) at fixed relative \(O(\alpha _s)\). For example, the cross section of the partonic subprocess \(gg \rightarrow gb\bar{b}\) contains terms with large logarithms which can be written, schematically, as convolutions \(f(g \rightarrow b) \otimes \sigma (gb \rightarrow gb)\) and \(\sigma (gg \rightarrow gg) \otimes d(g \rightarrow b)\) with a partonic PDF \(f(g \rightarrow b)\) and a partonic FF \(d(g \rightarrow b)\) (see Ref. [39] for definitions and a precise formulation of the corresponding cross sections). These splitting functions are absorbed in the PDFs and FFs, respectively. The large logarithms subtracted in this way are added back by calculating the cross sections of the \(gb \rightarrow gb\) and \(gg \rightarrow gg\) subprocesses with a \(b\)-quark PDF and a \(g \rightarrow B\) FF, respectively. There are similar subtraction terms and corresponding contributions involving PDFs and FFs of light quarks and the gluon in other channels as well.
In Fig. 5, we show numerical results for the subtraction terms needed in the \(gg\) channel (see Eqs. (45)–(53) in Ref. [39]), using a linear scale for better visibility. Their contribution is small, but not negligible, even at large \(p_T\) values. Specifically, the evaluations using the correct prescription with \(m_b \ne 0\) (dashed line) and the approximate one with \(m_b = 0\) (full line) are compared with each other. We observe from this that such mass effects are small and cannot be responsible for the unphysical increase of the total result for \(\mathrm{d}\sigma /\mathrm{d}p_T\) towards small \(p_T\) values.
It is, of course, unavoidable that the subtracted terms differ from those added back in the PDFs and FFs. The subtractions are obtained at fixed order, \(O(\alpha _s)\) in our case, while the PDFs and FFs contain the large logarithms resummed to all orders. Formally, the differences are of higher order in \(\alpha _s\). However, these higher-order terms are folded with cross sections calculated in the ZM-VFNS, and these cross sections are singular for \(p_T \rightarrow 0\). Therefore, it is not surprising that the contributions with \(b\) quarks in the initial state dominate at small \(p_T\) values.
Obviously, NLO cross sections of \(b\)-quark-initiated subprocesses that are convoluted with PDFs and FFs evolved at NLO contain terms singular for \(p_T \rightarrow 0\) at one order beyond the subtracted terms. In fact, it would be a major task to derive the missing next-to-next-to-leading-order (NNLO) subtraction terms. With such an extended version of the GM-VFNS including NNLO subtractions, but still using partonic cross sections derived in the ZM-VFNS, the problem would be shifted to one order higher, but it remains to be seen whether the required cancellations of singular terms can be obtained with the required numerical precision. In addition, strictly speaking, the NNLO subtraction terms only make sense in combination with the fixed-order calculation at NNLO. Otherwise, at large \(p_T\) values, the NNLO subtraction terms and their NLO fixed-order counterparts do not cancel, and the ZM-VFNS is not recovered.
In turn, one could argue that \(b\)-quark-initiated processes evaluated with \(b\)-quark PDFs and FFs should be included in the GM-VFNS at LO only. The predictions thus obtained [59] exhibit better agreement with data in the medium-\(p_T\) range, between 2 and 7 GeV or so, but switching off these NLO terms is again not sufficient to completely eliminate a singular behavior for \(p_T \rightarrow 0\). Moreover, and most importantly, numerical evaluations show that NLO corrections in the zero-mass part of the GM-VFNS are essential at large \(p_T\) values. Therefore, we do not follow this option either.
Instead, we try to exploit the freedom offered by the presence of \(\mu _R\), \(\mu _I\), and \(\mu _F\), parameters that are present anyway. Their values are not determined by theory, but some choice has to be made, based on some reasonable but ad-hoc physical argument. In fact, a judicious choice of scales can lead to a suppression of the potentially dangerous contributions from initial-state \(b\) quarks. This exploits the fact that all commonly available PDF fits assume that the \(b\)-quark PDF is zero below some starting scale, usually chosen to be \(\mu _I = m_b\). The same is true for the FFs: the FF for the \(b \rightarrow B\) transition vanishes for \(\mu _F < m_b\). Therefore, with \(\mu _{I,F} = \xi _{I,F} m_T\), a value \(\xi _{I,F}<1\) will render the \(b\)-quark PDF and FF zero for \(p_T < m_b \sqrt{1/\xi _{I,F}^2-1}\).

Subtraction term for the \(gg\) channel evaluated with zero (solid line) and finite (dashed line) \(m_b\) value in the NLO prediction for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(p\bar{p}\rightarrow B^++X\) with \(\sqrt{S}=1.96\) TeV and \(-1\le y\le 1\) in the GM-VFNS

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(p\bar{p}\rightarrow B^++X\) with \(\sqrt{S}=1.96\) TeV and \(-1\le y\le 1\) in the GM-VFNS are compared with CDF data [6]. Left panel evaluations with \(\xi _R = 1\) and \(\xi _I=\xi _F = 0.5\) (solid line), 0.4 (lower dashed line), and 0.6 (upper dashed line). Right panel evaluations with \(\xi _I=\xi _F = 0.5\) and \(\xi _R = 1\) (solid line), 0.5 (upper dashed line), and 2 (lower dashed line). If \(\xi _{I,F}<1\), then \(\mu _{I,F}=m_b\) is put for \(p_T<m_b\sqrt{1/\xi _{I,R}^2-1}\)
In Fig. 6, we show results obtained with such scale choices and compare them with CDF data [6]. Indeed, values for \(\xi _I\) and \(\xi _F\) of about 1/2 lead to the required suppression of \(b\)-quark-initiated contributions. Specifically, in the left panel of Fig. 6, we choose \(\xi _R = 1\) and \(\xi _I = \xi _F = 0.4, 0.5, 0.6\). In all these cases, there is a turn-over near \(p_T = 2.5\) GeV, and the agreement with the CDF data is reasonably good. We impose the additional constraint that \(\mu _I\) and \(\mu _F\) are not allowed to take values \(\mu _I,\mu _F < m_b\), i.e. the DGLAP evolutions of the PDFs and FFs are frozen below this scale.Footnote 2 This explains the slight bumps that occur in the \(p_T\) distribution at \(p_T = 6.0\), 7.8, and 10.3 GeV for \(\xi _I=\xi _F = 0.6\), 0.5, and 0.4, respectively. Obviously, the freedom in the choice of the default values of \(\xi _I\) and \(\xi _F\) leads to a moderate extra uncertainty close to the transition region, but the results in the small-\(p_T\) range, \(p_T \lesssim 5\) GeV, and for large \(p_T\) values stay unaffected.
Taking now \(\xi _R = 1\), \(\xi _I = \xi _F = 0.5\) as the new default scale choice, we estimate the theoretical errors in the usual way by varying the scale parameters by a factor 2 up and down about the default scale choice. In fact, it turns out that the variation of \(\mu _R\) is the dominant source of the theoretical uncertainties, and we simplify the subsequent calculations by only considering variations of \(\xi _R\) in the range from 0.5 to 2. Note that we do not introduce an extra prescription to freeze \(\mu _R\) below \(m_b\) because, first, the choice of \(\mu _R\) is not related to switching off \(b\)-quark-initiated subprocesses and, second, full variations of \(\mu _R\) are needed to obtain realistic estimates of the theoretical uncertainty. The resulting error band is shown in the right panel of Fig. 6. We emphasize that the freedom in choosing specific values of \(\xi _I\) and \(\xi _F\) as default does not introduce a large additional uncertainty, as may be understood by comparing the left and right panels of Fig. 6.
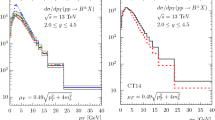
In Fig. 7, we compare the LHCb data [15] with our theoretical predictions implemented with the scale conventions introduced above. In the left panel, we see again nice agreement between the FFNS predictions and the experimental data. The right panel tells us that the data are not quite as well described by the GM-VFNS predictions, but the agreement is quite acceptable, as the data points are covered by the error band for \(p_T\gtrsim 2.5\) GeV. In this \(p_T\) range, the agreement of the data with predictions obtained in the FONLL scheme [32] is quite similar [15].

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(pp\rightarrow B^\pm +X\) with \(\sqrt{S}=7\) TeV and \(2\le y\le 4.5\) in the FFNS (left panel) and the GM-VFNS (right panel) are compared with LHCb data [15]. The default scale choice is \(\xi _R=1\) and \(\xi _I=\xi _F=0.5\) (solid lines), and the theoretical-error bands are obtained by varying \(\xi _R\) by a factor of 2 up (lower dashed lines) and down (upper dashed lines). If \(\xi _{I,F}<1\), then \(\mu _{I,F}=m_b\) is put for \(p_T<m_b\sqrt{1/\xi _{I,R}^2-1}\)
In Fig. 8, we show a comparison of results obtained using different PDF parametrizations. Specifically, we use the CT10 [60], MSTW [61], HERA-PDF1.5(NLO) [62], and NNPDF 2.3 [63, 64] PDF sets. The CTEQ6.6M [51] PDFs adopted elsewhere in this paper yield a result that is very similar to the one obtained using the CT10 PDFs. We observe that there are differences in the small-\(p_T\) range, \(p_T\lesssim 4\) GeV, which are somewhat larger than the experimental errors. We should, therefore, expect that \(B\)-meson production data at the LHC will help us to further constrain the PDFs. In particular, there is sensitivity to the gluon PDF in this kinematic range.

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(pp\rightarrow B^\pm +X\) with \(\sqrt{S}=7\) TeV and \(2\le y\le 4.5\) in the GM-VFNS with default scale choice are compared with LHCb data [15]. The PDF error is estimated by using the CT10 (solid line) [60], MSTW (dashed line) [61], HERAPDF1.5(NLO) (lower dotted line) [62], and NNPDF 2.3 (upper dotted line) [63, 64] sets
For completeness, we also consider the production of \(B^0\) and \(B_s^0\) mesons. Appropriate experimental data were published by the LHCb Collaboration in Ref. [15]. In Fig. 9, we present comparisons with NLO predictions in the GM-VFNS using the scale setting and theoretical-error estimation prescriptions described above to find good agreement.

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(pp\rightarrow B^0/\overline{B}^0+X\) (left panel) and \(pp\rightarrow B_s^0/\overline{B}_s^0+X\) (right panel) with \(\sqrt{S}=7\) TeV and \(2\le y\le 4.5\) in the GM-VFNS are compared with LHCb data [15]. The default predictions and theoretical-error bands are evaluated as in the right panel of Fig. 6
Finally, in Fig. 10, we compare \(B^+\)-meson production data taken by the ATLAS Collaboration [13] with our NLO GM-VFNS predictions. These data extend into the very-large-\(p_T\) range, where we expect the GM-VFNS to be quite appropriate. Indeed, we find good agreement, except for the lowest \(p_T\) bin, 9–13 GeV, and for central rapidities, where the data are slightly overestimated. Because of the large \(p_T\) values probed, the adjustment of scales to match to the FFNS as described above is not an issue here.

NLO predictions for \(\mathrm{d}\sigma /\mathrm{d}p_T\) of \(pp\rightarrow B^++X\) with \(\sqrt{S}=7\) TeV and \(0\le y\le 0.5\) (upper left panel), \(0.5\le y\le 1\) (upper right panel), \(1\le y\le 1.5\) (lower left panel), and \(1.5\le y\le 2.25\) (lower right panel) in the GM-VFNS are compared with ATLAS data [13]. The default predictions and theoretical-error bands are evaluated as in the right panel of Fig. 6
3 Conclusions
Any theoretical prediction for hadronic collisions within perturbative QCD requires the factorization of initial- and final-state singularities. This unavoidably introduces factorization scale parameters, which cannot be predicted from theory. Their choice must be based on physical arguments. We exploited the freedom in this choice to find a prescription that extends the reliability of NLO predictions in the GM-VFNS down to small \(p_T\) values. With scale parameters \(\xi _{I} < 1\), it is possible to eliminate contributions from the heavy quark in the initial state. These contributions, dominated by the subprocess \(gb \rightarrow gb\), are treated in the parton model with zero quark masses and would lead to an unphysical increase of the cross section for \(p_T \rightarrow 0\). We showed, however, that, with a judicious choice of \(\xi _R\), \(\xi _I\), and \(\xi _F\), one can switch off these contributions in the small-\(p_T\) range. Our prescription leads to a modified GM-VFNS yielding results in good agreement with recent data from the Tevatron and LHC experiments.
Notes
For deep inelastic scattering, heavy-quark-initiated processes at NLO with massive quarks have been considered in Ref. [50].
In fact, we have to freeze \(\mu _I\) slightly below \(m_b\), \(\mu _I = C m_b\) with \(C<1\), since the \(b\)-quark PDF parametrization of the CTEQ6.6M set, which we use here, vanishes only strictly below threshold. For our numerical evaluations, we choose \(C=0.99\).
References
C. Albajar et al., UA1 Collaboration, Phys. Lett. B 213, 405 (1988)
F. Abe et al., CDF Collaboration, Phys. Rev. Lett. 75, 1451 (1995). hep-ex/9503013
D.E. Acosta et al., CDF Collaboration, Phys. Rev. D 66, 052005 (2002)
S. Abachi et al., D0 Collaboration, Phys. Rev. Lett. 74, 3548 (1995)
B. Abbott et al., D0 Collaboration, Phys. Rev. Lett. 84, 5478 (2000). hep-ex/9907029
D. Acosta et al., CDF Collaboration, Phys. Rev. D 71, 032001 (2005). hep-ex/0412071
A. Abulencia et al., CDF Collaboration, Phys. Rev. D 75, 012010 (2007). hep-ex/0612015
T. Aaltonen et al., CDF Collaboration, Phys. Rev. D 79, 092003 (2009). arXiv:0903.2403 [hep-ex]
V. Khachatryan et al., CMS Collaboration, Phys. Rev. Lett. 106, 112001 (2011). arXiv:1101.0131 [hep-ex]
S. Chatrchyan et al., CMS Collaboration, Phys. Rev. Lett. 106, 252001 (2011). arXiv:1104.2892 [hep-ex]
S. Chatrchyan et al., CMS Collaboration, Phys. Rev. D 84, 052008 (2011). arXiv:1106.4048 [hep-ex]
G. Aad et al., ATLAS Collaboration, Nucl. Phys. B 864, 341 (2012). arXiv:1206.3122 [hep-ex]
G. Aad et al., ATLAS Collaboration, JHEP 1310, 042 (2013). arXiv:1307.0126 [hep-ex]
R. Aaij et al., LHCb Collaboration, JHEP 1204, 093 (2012). arXiv:1202.4812 [hep-ex]
R. Aaij et al., LHCb Collaboration, JHEP 1308, 117 (2013). arXiv:1306.3663 [hep-ex]
P. Nason, S. Dawson, R.K. Ellis, Nucl. Phys. B 303, 607 (1988)
P. Nason, S. Dawson, R.K. Ellis, Nucl. Phys. B 327, 49 (1989). [Erratum-ibid. B 335, 260 (1990)]
W. Beenakker, H. Kuijf, W.L. van Neerven, J. Smith, Phys. Rev. D 40, 54 (1989)
W. Beenakker, W.L. van Neerven, R. Meng, G.A. Schuler, J. Smith, Nucl. Phys. B 351, 507 (1991)
I. Bojak, M. Stratmann, Phys. Rev. D 67, 034010 (2003). hep-ph/0112276
M. Cacciari, M. Greco, Nucl. Phys. B 421, 530 (1994). hep-ph/9311260
B.A. Kniehl, M. Krämer, G. Kramer, M. Spira, Phys. Lett. B 356, 539 (1995). hep-ph/9505410
M. Cacciari, M. Greco, B.A. Kniehl, M. Krämer, G. Kramer, M. Spira, Nucl. Phys. B 466, 173 (1996). hep-ph/9512246
J. Binnewies, B.A. Kniehl, G. Kramer, Z. Phys. C 76, 677 (1997). hep-ph/9702408
B.A. Kniehl, G. Kramer, M. Spira, Z. Phys. C 76, 689 (1997). hep-ph/9610267
J. Binnewies, B.A. Kniehl, G. Kramer, Phys. Rev. D 58, 014014 (1998). hep-ph/9712482
J. Binnewies, B.A. Kniehl, G. Kramer, Phys. Rev. D 58, 034016 (1998). hep-ph/9802231
B.A. Kniehl, G. Kramer, Phys. Rev. D 60, 014006 (1999). hep-ph/9901348
B.A. Kniehl, in Proceedings of the 14th Topical Conference on Hadron Collider Physics: Hadron Collider Physics 2002, Karlsruhe, Germany, 2002, ed. by M. Erdmann, Th. Müller (Springer, Berlin, 2003), p. 161. hep-ph/0211008
B.A. Kniehl, G. Kramer, Phys. Rev. D 71, 094013 (2005). hep-ph/0504058
B.A. Kniehl, G. Kramer, Phys. Rev. D 74, 037502 (2006). hep-ph/0607306
M. Cacciari, S. Frixione, N. Houdeau, M.L. Mangano, P. Nason, G. Ridolfi, JHEP 1210, 137 (2012). arXiv:1205.6344 [hep-ph]
M. Buza, Y. Matiounine, J. Smith, R. Migneron, W.L. van Neerven, Nucl. Phys. B 472, 611 (1996). hep-ph/9601302
M. Buza, Y. Matiounine, J. Smith, W.L. van Neerven, Eur. Phys. J. C 1, 301 (1998). hep-ph/9612398
G. Kramer, H. Spiesberger, Eur. Phys. J. C 22, 289 (2001). hep-ph/0109167
G. Kramer, H. Spiesberger, Eur. Phys. J. C 28, 495 (2003). hep-ph/0302081
G. Kramer, H. Spiesberger, Eur. Phys. J. C 38, 309 (2004). hep-ph/0311062
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Phys. Rev. D 71, 014018 (2005). hep-ph/0410289
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Eur. Phys. J. C 41, 199 (2005). hep-ph/0502194
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, A.I.P. Conf. Proc. 792, 867 (2005). hep-ph/0507068
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Phys. Rev. Lett. 96, 012001 (2006). hep-ph/0508129
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Phys. Rev. D 77, 014011 (2008). arXiv:0705.4392 [hep-ph]
T. Kneesch, B.A. Kniehl, G. Kramer, I. Schienbein, Nucl. Phys. B 799, 34 (2008). arXiv:0712.0481 [hep-ph]
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Phys. Rev. D 79, 094009 (2009). arXiv:0901.4130 [hep-ph]
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Eur. Phys. J. C 62, 365 (2009). arXiv:0902.3166 [hep-ph]
G. Kramer, H. Spiesberger, Phys. Lett. B 679, 223 (2009). arXiv:0906.2533 [hep-ph]
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Phys. Rev. D 84, 094026 (2011). arXiv:1109.2472 [hep-ph]
B.A. Kniehl, G. Kramer, I. Schienbein, H. Spiesberger, Eur. Phys. J. C 72, 2082 (2012). arXiv:1202.0439 [hep-ph]
M.A.G. Aivazis, J.C. Collins, F.I. Olness, W.-K. Tung, Phys. Rev. D 50, 3102 (1994). hep-ph/9312319
S. Kretzer, I. Schienbein, Phys. Rev. D 58, 094035 (1998). hep-ph/9805233
P.M. Nadolsky, H.-L. Lai, Q.-H. Cao, J. Huston, J. Pumplin, D. Stump, W.-K. Tung, C.-P. Yuan, CTEQ Collaboration, Phys. Rev. D 78, 013004 (2008). arXiv:0802.0007 [hep-ph]
K. Nakamura et al., Particle Data Group, J. Phys. G 37, 075021 (2010)
C. Peterson, D. Schlatter, I. Schmitt, P.M. Zerwas, Phys. Rev. D 27, 105 (1983)
S. Albino, B.A. Kniehl, G. Kramer, Nucl. Phys. B 803, 42 (2008). arXiv:0803.2768 [hep-ph]
J.C. Collins, Phys. Rev. D 58, 094002 (1998). hep-ph/9806259
W.-K. Tung, S. Kretzer, C. Schmidt, J. Phys. G 28, 983 (2002). hep-ph/0110247
A. Kusina, F.I. Olness, I. Schienbein, T. Ježo, K. Kovařík, T. Stavreva, and J.Y. Yu, Phys. Rev. D 88, 074032 (2013) arXiv:1306.6553 [hep-ph]
M. Cacciari, M. Greco, P. Nason, JHEP 9805, 007 (1998). hep-ph/9803400
F.I. Olness, R.J. Scalise, W.-K. Tung, Phys. Rev. D 59, 014506 (1999). hep-ph/9712494
H.-L. Lai, M. Guzzi, J. Huston, Z. Li, P.M. Nadolsky, J. Pumplin, C.-P. Yuan, CTEQ Collaboration, Phys. Rev. D 82, 074024 (2010). arXiv:1007.2241 [hep-ph]
A.D. Martin, W.J. Stirling, R.S. Thorne, G. Watt, Eur. Phys. J. C 64, 653 (2009). arXiv:0905.3531 [hep-ph]
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, NNPDF Collaboration, Nucl. Phys. B 849, 296 (2011). arXiv:1101.1300 [hep-ph]
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, NNPDF Collaboration, Nucl. Phys. B 855, 153 (2012). arXiv:1107.2652 [hep-ph]
Acknowledgments
We thank I. Bierenbaum for help in checking some of our numerical calculations and J. Rojo for clarifying an issue related to the heavy-quark threshold used in the NNPDF PDFs [63, 64]. This work was supported in part by the German Federal Ministry for Education and Research BMBF through Grant No. 05H12GUE.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Funded by SCOAP3 / License Version CC BY 4.0.
About this article

Cite this article
Kniehl, B.A., Kramer, G., Schienbein, I. et al. Inclusive \(B\)-meson production at small \(p_T\) in the general-mass variable-flavor-number scheme. Eur. Phys. J. C 75, 140 (2015). https://doi.org/10.1140/epjc/s10052-015-3360-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-015-3360-6