
Abstract
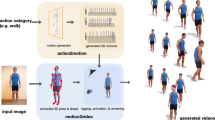
Data-driven garment animation is a current topic of interest in the computer graphics industry. Existing approaches generally establish the mapping between a single human pose or a temporal pose sequence, and garment deformation, but it is difficult to quickly generate diverse clothed human animations. We address this problem with a method to automatically synthesize dressed human animations with temporal consistency from a specified human motion label. At the heart of our method is a two-stage strategy. Specifically, we first learn a latent space encoding the sequence-level distribution of human motions utilizing a transformer-based conditional variational autoencoder (Transformer-CVAE). Then a garment simulator synthesizes dynamic garment shapes using a transformer encoder–decoder architecture. Since the learned latent space comes from varied human motions, our method can generate a variety of styles of motions given a specific motion label. By means of a novel beginning of sequence (BOS) learning strategy and a self-supervised refinement procedure, our garment simulator is capable of efficiently synthesizing garment deformation sequences corresponding to the generated human motions while maintaining temporal and spatial consistency. We verify our ideas experimentally. This is the first generative model that directly dresses human animation.

Article PDF
Similar content being viewed by others


Avoid common mistakes on your manuscript.
References
Santesteban, I.; Otaduy, M. A.; Casas, D. Learning-based animation of clothing for virtual try-on. Computer Graphics Forum Vol. 38, No. 2, 355–366, 2019.
Patel, C.; Liao, Z.; Pons-Moll, G. TailorNet: Predicting clothing in 3D as a function of human pose, shape and garment style. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7363–7373, 2020.
Tiwari, L.; Bhowmick, B. DeepDraper: Fast and accurate 3D garment draping over a 3D human body. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 1416–1426, 2021.
Ma, Q. L.; Yang, J. L.; Ranjan, A.; Pujades, S.; Pons-Moll, G.; Tang, S. Y.; Black, M. J. Learning to dress 3D people in generative clothing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6468–6477, 2020.
Bertiche, H.; Madadi, M.; Escalera, S. CLOTH3D: Clothed 3D humans. In: Computer Vision–ECCV 2020. Lecture Notes in Computer Science, Vol. 12365. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 344–359, 2020.
Santesteban, I.; Thuerey, N.; Otaduy, M. A.; Casas, D. Self-supervised collision handling via generative 3D garment models for virtual try-on. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11758–11768, 2021.
Ahn, H.; Ha, T.; Choi, Y.; Yoo, H.; Oh, S. Text2Action: Generative adversarial synthesis from language to action. In: Proceedings of the IEEE International Conference on Robotics and Automation, 5915–5920, 2018.
Ahuja, C.; Morency, L. P. Language2Pose: Natural language grounded pose forecasting. In: Proceedings of the International Conference on 3D Vision, 719–728, 2019.
Guo, C.; Zuo, X. X.; Wang, S.; Zou, S. H.; Sun, Q. Y.; Deng, A. N.; Gong, M. L.; Cheng, L. Action2Motion: Conditioned generation of 3D human motions. In: Proceedings of the 28th ACM International Conference on Multimedia, 2021–2029, 2020.
Petrovich, M.; Black, M. J.; Varol, G. Action-conditioned 3D human motion synthesis with transformer VAE. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 10965–10975, 2021.
Lee, H. Y.; Yang, X.; Liu, M. Y.; Wang, T. C.; Lu, Y. D.; Yang, M. H.; Kautz, J. Dancing to music. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Article No. 322, 3586–3596, 2019.
Li, J. M.; Yin, Y. H.; Chu, H.; Zhou, Y.; Wang, T. W.; Fidler, S.; Li, H. Learning to generate diverse dance motions with transformer. arXiv preprint arXiv:2008.08171, 2020.
Wen, Y. H.; Yang, Z. P.; Fu, H. B.; Gao, L.; Sun, Y. N.; Liu, Y. J. Autoregressive stylized motion synthesis with generative flow. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13607–13607, 2021.
Baraff, D.; Witkin, A. Large steps in cloth simulation. In: Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, 43–54, 1998.
Provot, X. Collision and self-collision handling in cloth model dedicated to design garments. In: Computer Animation and Simulation’ 97. Eurographics. Thalmann, D.; van de Panne, M. Eds. Springer Vienna, 177–189, 1997.
Volino, P.; Magnenat Thalmann, N. Collision and self-collision detection: Efficient and robust solutions for highly deformable surfaces. In: Computer Animation and Simulation’ 95. Eurographics. Terzopoulos, D.; Thalmann, D. Eds. Springer Vienna, 55–65, 1995.
Narain, R.; Samii, A.; O’Brien, J. F. Adaptive anisotropic remeshing for cloth simulation. ACM Transactions on Graphics Vol. 31, No. 6, Article No. 152, 2012.
Li, C.; Tang, M.; Tong, R. F.; Cai, M.; Zhao, J. Y.; Manocha, D. P-cloth: Interactive complex cloth simulation on multi-GPU systems using dynamic matrix assembly and pipelined implicit integrators. ACM Transactions on Graphics Vol. 39, No. 6, Article No. 180, 2020.
Guan, P.; Reiss, L.; Hirshberg, D. A.; Weiss, A.; Black, M. J. Drape. ACM Transactions on Graphics Vol. 31, No. 4, Article No. 35, 2012.
Wang, H. M.; Hecht, F.; Ramamoorthi, R.; O’Brien, J. F. Example-based wrinkle synthesis for clothing animation. ACM Transactions on Graphics Vol. 29, No. 4, Article No. 107, 2010.
Lähner, Z.; Cremers, D.; Tung, T. DeepWrinkles: Accurate and realistic clothing modeling. In: Computer Vision–ECCV 2018. Lecture Notes in Computer Science, Vol. 11208. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 698–715, 2018.
Xu, W. W.; Umentani, N.; Chao, Q. W.; Mao, J.; Jin, X. G.; Tong, X. Sensitivity-optimized rigging for example-based real-time clothing synthesis. ACM Transactions on Graphics Vol. 33, No. 4, Article No. 107, 2014.
Wu, N. N.; Chao, Q. W.; Chen, Y. Z.; Xu, W. W.; Liu, C.; Manocha, D.; Sun, W. X.; Han, Y.; Yao, X. R.; Jin, X. G. AgentDress: Realtime clothing synthesis for virtual agents using plausible deformations. IEEE Transactions on Visualization and Computer Graphics Vol. 27, No. 11, 4107–4118, 2021.
Gundogdu, E.; Constantin, V.; Seifoddini, A.; Dang, M.; Salzmann, M.; Fua, P. GarNet: A two-stream network for fast and accurate 3D cloth draping. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 8738–8747, 2019.
Wang, T. Y.; Ceylan, D.; Popovic, J.; Mitra, N. J. Learning a shared shape space for multimodal garment design. arXiv preprint arXiv:1806.11335, 2018.
Pan, X. Y.; Mai, J. M.; Jiang, X. W.; Tang, D. X.; Li, J. X.; Shao, T. J.; Zhou, K.; Jin, X. G.; Manocha, D. Predicting loose-fitting garment deformations using bone-driven motion networks. In: Proceedings of the ACM SIGGRAPH Conference, Article No. 11, 2022.
Wang, Y. T.; Shao, T.; Fu, K.; Mitra, N. Learning an intrinsic garment space for interactive authoring of garment animation. ACM Transactions on Graphics Vol. 38, No. 6, Article No. 220, 2019.
Li, Y. D.; Tang, M.; Yang, Y.; Huang, Z.; Tong, R. F.; Yang, S. C.; Li, Y.; Manocha, D. N-cloth: Predicting 3D cloth deformation with mesh-based networks. Computer Graphics Forum Vol. 41, No. 2, 547–558, 2022.
Zhang, M.; Wang, T. Y.; Ceylan, D.; Mitra, N. J. Dynamic neural garments. ACM Transactions on Graphics Vol. 40, No. 6, Article No. 235, 2021.
Bertiche, H.; Madadi, M.; Escalera, S. PBNS: Physically based neural simulator for unsupervised garment pose space deformation. ACM Transactions on Graphics Vol. 40, No. 6, Article No. 198, 2021.
Santesteban, I.; Otaduy, M. A.; Casas, D. SNUG: Self-supervised neural dynamic garments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8130–8140, 2022.
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, ?; Polosukhin, I. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010, 2017.
Kingma, D. P.; Welling, M. Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114, 2013.
Wang, T. M.; Wan, X. J. T-CVAE: Transformer-based conditioned variational autoencoder for story completion. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence, 5233–5239, 2019.
Kumar, S.; Pradeep, J.; Zaidi, H. Learning robust latent representations for controllable speech synthesis. arXiv preprint arXiv:2105.04458, 2021.
Jiang, J. Y.; Xia, G. G.; Carlton, D. B.; Anderson, C. N.; Miyakawa, R. H. Transformer VAE: A hierarchical model for structure-aware and interpretable music representation learning. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 516–520, 2020.
Barsoum, E.; Kender, J.; Liu, Z. C. HP-GAN: Probabilistic 3D human motion prediction via GAN. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 1499–149909, 2018.
Habibie, I.; Holden, D.; Schwarz, J.; Yearsley, J.; Komura, T. A recurrent variational autoencoder for human motion synthesis. In: Proceedings of the 28th British Machine Vision Conference, 119.1–119.12, 2017.
Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M. J. Smpl. ACM Transactions on Graphics Vol. 34, No. 6, Article No. 248, 2015.
Zhou, Y.; Barnes, C.; Lu, J. W.; Yang, J. M.; Li, H. On the continuity of rotation representations in neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5738–5746, 2019.
Devlin, J.; Chang, M. W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X. H.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning basic visual concepts with a constrained variational framework. In: Proceedings of the International Conference on Learning Representations, 2017.
Taubin, G. A signal processing approach to fair surface design. In: Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, 351–358, 1995.
Vidaurre, R.; Santesteban, I.; Garces, E.; Casas, D. Fully convolutional graph neural networks for parametric virtual try-on. Computer Graphics Forum Vol. 39, No. 8, 145–156, 2020.
Mahmood, N.; Ghorbani, N.; Troje, N. F.; Pons-Moll, G.; Black, M. AMASS: Archive of motion capture as surface shapes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 5441–5450, 2019.
Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z. M.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In: Proceedings of the NIPS Workshop Autodiff, 2017.
Ravi, N.; Reizenstein, J.; Novotny, D.; Gordon, T.; Lo, W. Y.; Johnson, J.; Gkioxari, G. Accelerating 3D deep learning with PyTorch3D. arXiv preprint arXiv:2007.08501, 2020.
Agarap, A. F. Deep learning using rectified linear units (ReLU). arXiv preprint arXiv:1803.08375, 2018.
Kingma, D. P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
Vasa, L.; Skala, V. A perception correlated comparison method for dynamic meshes. IEEE Transactions on Visualization and Computer Graphics Vol. 17, No. 2, 220–230, 2011.
Acknowledgements
We thank the volunteers for the user study. This work was supported by the National Natural Science Foundation of China (Grant No. 61972379).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Min Shi is an associate professor in the School of Control and Computer Engineering, North China Electric Power University. She received her Ph.D. degree in computer science and technology from the Chinese Academy of Sciences in 2013. Her research interests include cloth simulation, computer vision, and virtual reality.
Wenke Feng received his B.S. degree in software engineering from North China Electric Power University in 2018, where he is currently pursuing an M.S. degree in computer science and technology. His research interests include computer graphics and garment animation.
Lin Gao received his Ph.D. degree in computer science from Tsinghua University. He is currently an associate professor at the Institute of Computing Technology, Chinese Academy of Sciences. He has held a Newton Advanced Fellowship from the Royal Society and an AG Young Researcher Award. His research interests include computer graphics and geometric processing.
Dengming Zhu received his B.S. degree from Ningbo University, China, in 1996, his M.S. degree in theoretical physics from Shanghai Jiao Tong University, China, in 2001, and his Ph.D. degree in computer science from the Institute of Computing Technology, Chinese Academy of Sciences, in 2008. He is currently an associate professor in the Institute of Computing Technology. His research interests include computer graphics and virtual reality.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095. To submit a manuscript, please go to https://www.editorialmanager.com/cvmj.
About this article

Cite this article
Shi, M., Feng, W., Gao, L. et al. Generating diverse clothed 3D human animations via a generative model. Comp. Visual Media 10, 261–277 (2024). https://doi.org/10.1007/s41095-022-0324-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41095-022-0324-2