
Abstract
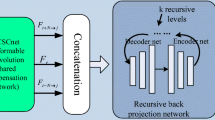
Recently, learning-based models have enhanced the performance of single-image super-resolution (SISR). However, applying SISR successively to each video frame leads to a lack of temporal coherency. Convolutional neural networks (CNNs) outperform traditional approaches in terms of image quality metrics such as peak signal to noise ratio (PSNR) and structural similarity (SSIM). On the other hand, generative adversarial networks (GANs) offer a competitive advantage by being able to mitigate the issue of a lack of finer texture details, usually seen with CNNs when super-resolving at large upscaling factors. We present iSeeBetter, a novel GAN-based spatio-temporal approach to video super-resolution (VSR) that renders temporally consistent super-resolution videos. iSeeBetter extracts spatial and temporal information from the current and neighboring frames using the concept of recurrent back-projection networks as its generator. Furthermore, to improve the “naturality” of the super-resolved output while eliminating artifacts seen with traditional algorithms, we utilize the discriminator from super-resolution generative adversarial network. Although mean squared error (MSE) as a primary loss-minimization objective improves PSNR/SSIM, these metrics may not capture fine details in the image resulting in misrepresentation of perceptual quality. To address this, we use a four-fold (MSE, perceptual, adversarial, and total-variation loss function. Our results demonstrate that iSeeBetter offers superior VSR fidelity and surpasses state-of-the-art performance.
Article PDF
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
References
Dong, C.; Loy, C. C.; He, K. M.; Tang, X. O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 38, No. 2, 295–307, 2016.
Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1664–1673, 2018.
Haris, M.; Widyanto, M. R.; Nobuhara, H. Inception learning super-resolution. Applied Optics Vol. 56, No. 22, 6043, 2017.
Kim, J.; Lee, J. K.; Lee, K. M. Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1646–1654, 2016.
Faramarzi, E.; Rajan, D.; Christensen, M. P. Unified blind method for multi-image super-resolution and single/multi-image blur deconvolution. IEEE Transactions on Image Processing Vol. 22, No. 6, 2101–2114, 2013.
Garcia, D. C.; Dorea, C.; de Queiroz, R. L. Super resolution for multiview images using depth information. IEEE Transactions on Circuits and Systems for Video Technology Vol. 22, No. 9, 1249–1256, 2012.
Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z. H.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4778–4787, 2017.
Tao, X.; Gao, H. Y.; Liao, R. J.; Wang, J.; Jia, J. Y. Detail-revealing deep video super-resolution. In: Proceedings of the IEEE International Conference on Computer Vision, 4472–4480, 2017.
Sajjadi, M. S. M.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6626–6634, 2018.
Haris, M.; Shakhnarovich, G.; Ukita, N. Recurrent back-projection network for video super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3897–3906, 2019.
Jo, Y.; Oh, S. W.; Kang, J.; Kim, S. J. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3224–3232, 2018.
Shi, W. Z.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A. P.; Bishop, R.; Rueckert, D.; Wang, Z. Realtime single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1874–1883, 2016.
Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. In: Proceedings of the Advances in Neural Information Processing Systems 28, 235–243, 2015.
Liu, D.; Wang, Z. W.; Fan, Y. C.; Liu, X. M.; Wang, Z. Y.; Chang, S. Y.; Huang, T. Robust video super-resolution with learned temporal dynamics. In: Proceedings of the IEEE International Conference on Computer Vision, 2507–2515, 2017.
Liao, R. J.; Tao, X.; Li, R. Y.; Ma, Z. Y.; Jia, J. Y. Video super-resolution via deep draft-ensemble learning. In: Proceedings of the IEEE International Conference on Computer Vision, 531–539, 2015.
Gers, F. A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Computation Vol. 12, No. 10, 2451–2471, 2000.
Makansi, O.; Ilg, E.; Brox, T. End-to-end learning of video super-resolution with motion compensation. In: Pattern Recognition. Lecture Notes in Computer Science, Vol. 10496. Roth, V.; Vetter, T. Eds. Springer Cham, 203–214, 2017.
Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP: Graphical Models and Image Processing Vol. 53, No. 3, 231–239, 1991.
Irani, M.; Peleg, S. Motion analysis for image enhancement: Resolution, occlusion, and transparency. Journal of Visual Communication and Image Representation Vol. 4, No. 4, 324–335, 1993.
Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4681–4690, 2017.
Ren, H.; Fang, X. Recurrent back-projection network for video super-resolution. In: Final Project for MIT 6.819 Advances in Computer Vision, 1–6, 2018.
Wang, Z. H.; Chen, J.; Hoi, S. C. H. Deep learning for image super-resolution: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence DOI: https://doi.org/10.1109/TPAMI.2020.2982166, 2020.
Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.
Johnson, J.; Alahi, A.; Li, F. F. Perceptual losses for real-time style transfer and super-resolution. In: Computer Vision — ECCV 2016. Lecture Notes in Computer Science, Vol. 9906. Leibe, B.; Matas, J.; Sebe, N.; Welling, M. Eds. Springer Cham, 694–711, 2016.
Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. In: Proceedings of the Advances in Neural Information Processing Systems 29, 658–666, 2016.
Bruna, J.; Sprechmann, P.; LeCun, Y. Superresolution with deep convolutional sufficient statistics. In: Proceedings of the 4th International Conference on Learning Representations, 2016.
Xue, T. F.; Chen, B. A.; Wu, J. J.; Wei, D. L.; Freeman, W. T. Video enhancement with task-oriented flow. International Journal of Computer Vision Vol. 127, No. 8, 1106–1125, 2019.
Liu, C.; Sun, D. Q. A Bayesian approach to adaptive video super resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 209–216, 2011.
Tsai, R. Multiframe image restoration and registration. Advance Computer Visual and Image Processing Vol. 1, 317–339, 1984.
Yang, J. C.; Huang, T. Image super-resolution: Historical overview and future challenges. In: Super-Resolution Imaging. Milanfar, P. Ed. CRC Press, 1–34, 2017.
Tai, Y.; Yang, J.; Liu, X. M. Image super-resolution via deep recursive residual network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3147–3155, 2017.
Kim, J.; Lee, J. K.; Lee, K. M. Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1637–1645, 2016.
Lai, W. S.; Huang, J. B.; Ahuja, N.; Yang, M. H. Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 624–632, 2017.
Kappeler, A.; Yoo, S.; Dai, Q. Q.; Katsaggelos, A. K. Video super-resolution with convolutional neural networks. IEEE Transactions on Computational Imaging Vol. 2, No. 2, 109–122, 2016.
Johnson, J.; Karpathy, A.; Li, F. F. DenseCap: Fully convolutional localization networks for dense captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4565–4574, 2016.
Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv preprint arXiv:1412.6632, 2014.
Yu, H. N.; Wang, J.; Huang, Z. H.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4584–4593, 2016.
Donahue, J.; Hendricks, L. A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Darrell, T.; Saenko, K. Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2625–2634, 2015.
Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks In: Proceedings of the Annual Conference of the North American Chapter of the ACL, 1494–1504, 2015.
Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In: Proceedings of the Advances in Neural Information Processing Systems 28, 1–9, 2015.
Drulea, M.; Nedevschi, S. Total variation regularization of local-global optical flow. In: Proceedings of the 14th International IEEE Conference on Intelligent Transportation Systems, 318–323, 2011.
He, K. M.; Zhang, X. Y.; Ren, S. Q.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision, 1026–1034, 2015.
Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In: Proceedings of the 20th International Conference on Pattern Recognition, 2366–2369, 2010.
Cheng, M.-H.; Lin, N.-W.; Hwang, K.-S.; Jeng, J.-H. Fast video super-resolution using artificial neural networks. In: Proceedings of the 8th International Symposium on Communication Systems, Networks & Digital Signal Processing, 1–4, 2012.
Wang, Z.; Bovik, A. C. A universal image quality index. IEEE Signal Processing Letters Vol. 9, No. 3, 81–84, 2002.
Gatys, L.; Ecker, A. S.; Bethge, M. Texture synthesis using convolutional neural networks. In: Proceedings of the Advances in Neural Information Processing Systems 28, 262–270, 2015.
Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In: Proceedings of the Advances in Neural Information Processing Systems 27, 2672–2680, 2014.
Aly, H. A.; Dubois, E. Image up-sampling using total-variation regularization with a new observation model. IEEE Transactions on Image Processing Vol. 14, No. 10, 1647–1659, 2005.
Hany, J.; Walters, G. Hands-On Generative Adversarial Networks with PyTorch 1. x: Implement next-generation neural networks to build powerful GAN models using Python. Packt Publishing Ltd., 2019.
Acknowledgements
The author would like to thank Andrew Ng’s lab at Stanford University for their guidance on this project. In particular, the authors express their gratitude to Mohamed El-Geish for the idea-inducing brainstorming sessions throughout the project.
Author information
Authors and Affiliations
Corresponding author
Additional information
Aman Chadha has held positions at some of the world’s leading semiconductor/product companies. He is currently based out of Cupertino (Silicon Valley), California and is currently pursuing his graduate studies in artificial intelligence from Stanford University. He has published in prestigious international journals and conferences, and has authored two books. His publications have garnered about 200 citations. He currently serves on the editorial boards of several international journals including IJATCA, IJLTET, IJCET, IJEACS, and IJRTER. He has served as a reviewer for IJEST, IJCST, IJCSEIT, and JESTEC. Aman graduated with an M.S. degree from the University of Wisconsin-Madison with an outstanding graduate student award in 2014 and his B.E. degree with distinction from the University of Mumbai in 2012. His research interests include computer vision (particularly, pattern recognition), artificial intelligence, machine learning and computer architecture. Aman has 18 publications to his credit.
John Britto is pursuing his M.S. degree in computer science from the University of Massachusetts, Amherst. He completed his B.E. degree in computer engineering from the University of Mumbai in 2018. His research interests lie in machine learning, natural language processing, and artificial intelligence.
M. Mani Roja is a full professor in the Electronics and Telecommunication Department at the University of Mumbai since the past 30 years. She received her Ph.D. degree in electronics and telecommunication engineering from Sant Gadge Baba Amravati University and her master degree in electronics and telecommunication engineering from the University of Mumbai. She has collaborated across the years in the fields of image processing, speech processing, and biometric recognition.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095. To submit a manuscript, please go to https://www.editorialmanager.com/cvmj.
About this article

Cite this article
Chadha, A., Britto, J. & Roja, M.M. iSeeBetter: Spatio-temporal video super-resolution using recurrent generative back-projection networks. Comp. Visual Media 6, 307–317 (2020). https://doi.org/10.1007/s41095-020-0175-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41095-020-0175-7