
Abstract
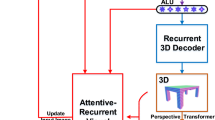
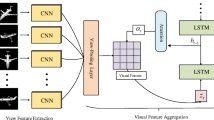
Active vision is inherently attention-driven: an agent actively selects views to attend in order to rapidly perform a vision task while improving its internal representation of the scene being observed. Inspired by the recent success of attention-based models in 2D vision tasks based on single RGB images, we address multi-view depth-based active object recognition using an attention mechanism, by use of an end-to-end recurrent 3D attentional network. The architecture takes advantage of a recurrent neural network to store and update an internal representation. Our model, trained with 3D shape datasets, is able to iteratively attend the best views targeting an object of interest for recognizing it. To realize 3D view selection, we derive a 3D spatial transformer network. It is differentiable, allowing training with backpropagation, and so achieving much faster convergence than the reinforcement learning employed by most existing attention-based models. Experiments show that our method, with only depth input, achieves state-of-the-art next-best-view performance both in terms of time taken and recognition accuracy.
Article PDF
Similar content being viewed by others

Avoid common mistakes on your manuscript.
References
Denzler, J.; Brown, C. M. Information theoretic sensor data selection for active object recognition and state estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 24, No. 2, 145–157, 2002.
Huber, M. F.; Dencker, T.; Roschani, M.; Beyerer, J. Bayesian active object recognition via Gaussian process regression. In: Proceedings of the 15th International Conference on Information Fusion, 1718–1725, 2012.
Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1912–1920, 2015.
Jayaraman, D.; Grauman, K. Look-ahead before you leap: End-to-end active recognition by forecasting the effect of motion. In: Computer Vision — ECCV 2016. Lecture Notes in Computer Science, Vol. 9909. Leibe, B.; Matas, J.; Sebe, N.; Welling, M. Eds. Springer Cham, 489–505, 2016.
Xu, K.; Shi, Y.; Zheng, L.; Zhang, J.; Liu, M.; Huang, H.; Su, H.; Cohen-Or, D.; Chen, B. 3D attention-driven depth acquisition for object identifiation. ACM Transactions on Graphics Vol. 35, No. 6, Article No. 238, 2016.
Chen, S.; Zheng, L.; Zhang, Y.; Sun, Z.; Xu, K. VERAM: View-enhanced recurrent attention model for 3D shape classification. IEEE Transactions on Visualization and Computer Graphics doi: https://doi.org/10.1109/TVCG.2018.2866793, 2018.
Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In: Proceedings of the Advances in Neural Information Processing Systems 27, 2204–2212, 2014.
Xu, K.; Ba, J. L.; Kiros, R.; Courville, A.; Salakhutdinov, R.; Zemel, R. S.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd International Conference on Machine Learning, Vol. 37, 2048–2057, 2015.
Corbetta, M.; Shulman, G. L. Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience Vol. 3, No. 3, 201–215, 2002.
Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In: Proceedings of the Advances in Neural Information Processing Systems 28, 2017–2025, 2015.
Scott, W. R.; Roth, G.; Rivest, J.-F. View planning for automated three-dimensional object reconstruction and inspection. ACM Computing Surveys Vol. 35, No. 1, 64–96, 2003.
Dutta Roy, S.; Chaudhury, S.; Banerjee, S. Active recognition through next view planning: A survey. Pattern Recognition Vol. 37, No. 3, 429–446, 2004.
Qi, C. R.; Su, H.; Mo, K.; Guibas, L. J. PointNet: Deep learning on point sets for 3D classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 652–660, 2017.
Qi, C. R.; Yi, L.; Su, H.; Guibas, L. J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In: Proceedings of the Advances in Neural Information Processing Systems 30, 5099–5108, 2017.
Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional ShapeContextNet for point cloud recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4606–4615, 2018.
Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 264–272, 2018.
Borotschnig, H.; Paletta, L.; Prantl, M.; Pinz, A. Appearance-based active object recognition. Image and Vision Computing Vol. 8, No. 9, 715–727, 2000.
Callari, F. G.; Ferrie, F. P. Active object recognition: Looking for differences. International Journal of Computer Vision Vol. 43, No. 3, 189–204, 2001.
Arbel, T.; Ferrie, F. P. Entropy-based gaze planning. Image and Vision Computing Vol. 19, No. 11, 779–786, 2001.
Paletta, L.; Pinz, A. Active object recognition by view integration and reinforcement learning. Robotics and Autonomous Systems Vol. 31, No. 1, 71–86, 2000.
Kurniawati, H.; Hsu, D.; Lee, W. S. SARSOP: Efficient point-based POMDP planning by approximating optimally reachable belief spaces. In: Proceedings of the Robotics: Science and Systems, Vol. 2008, 2008.
Lauri, M.; Atanasov, N.; Pappas, G.; Ritala, R. Active object recognition via Monte Carlo tree search. In: Proceedings of the Workshop on Beyond Geometric Constraints at the International Conference on Robotics and Automation, 2015.
Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research Vol. 17, No. 39, 1–40, 2016.
Malmir, M.; Sikka, K.; Forster, D.; Movellan, J.; Cottrell, G. W. Deep Q-learning for active recognition of germs: Baseline performance on a standardized dataset for active learning. In: Proceedings of the British Machine Vision Conference, 161–171, 2016.
Krizhevsky, A.; Sutskever, I.; Hinton, G. E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the Advances in Neural Information Processing Systems 25, 1097–1105, 2012.
Mozer, M. C. A focused back-propagation algorithm for temporal pattern recognition. Complex Systems Vol. 3, No. 4, 349–381, 1989.
Wu, Z.; Song, S.; Khosla, A.; Tang, X.; Xiao, J. 3D ShapeNets for 2.5D object recognition and next-best-view prediction. arXiv preprint arXiv:1406.5670, 2014.
Chang, A. X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; Xiao, J.; Yi, L.; Yu, F. ShapeNet: An information-rich 3D model repository. arXiv preprint arXiv:1512.03012, 2015.
Johns, E.; Leutenegger, S.; Davison, A. J. Pairwise decomposition of image sequences for active multi-view recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3813–3822, 2016.
Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE International Conference on Computer Vision, 945–953, 2015.
Bajcsy, R. Active perception. Proceedings of the IEEE Vol. 76, No. 8, 966–1005, 1988.
Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 842–850, 2015.
Acknowledgements
We thank the anonymous reviewers for their valuable comments. This work was supported, in part, by National Natural Science Foundation of China (Nos. 61572507, 61622212, and 61532003). Min Liu is supported by the China Scholarship Council.
Author information
Authors and Affiliations
Corresponding author
Additional information
Min Liu is a Ph.D. candidate in the School of Computers, National University of Defense Technology. He received his B.S. degree in geodesy and geomatics from Wuhan University and M.S. degree in computer science from National University of Defense Technology in 2013 and 2016, respectively. He is visiting the University of Maryland at College Park from 2018 to 2020. His research interests mainly include robot manipulation and 3D vision.
Yifei Shi received his B.S. degree in geodesy and geomatics from Wuhan University and M.S. degree in computer science from National University of Defense Technology in 2012 and 2015, respectively. He is pursing a doctorate in computer science at the National University of Defense Technology. His research interests mainly include data-driven scene understanding, RGBD reconstruction, and 3D vision.
Lintao Zheng received his B.S. degree in applied mathematics from Xi’an Jiaotong University and M.S. degree in computer science from the National University of Defense Technology in 2013 and 2016, respectively. He is pursuing a doctorate in computer science at the National University of Defense Technology. His research interests mainly include computer graphics, deep learning, and robot vision.
Kai Xu is an associate professor at the School of Computers, National University of Defense Technology, where he received his Ph.D. degreee in 2011. He conducted visiting research at Simon Fraser University during 2008–2010, and Princeton University during 2017–2018. His research interests include geometry processing and geometric modeling, especially on data-driven approaches to the problems in those directions, as well as 3D-geometry-based computer vision. He has published over 60 research papers, including 21 SIGGRAPH/TOG papers. He has organized two SIGGRAPH Asia courses and one Eurographics STAR tutorial. He is currently serving on the editorial boards of Computer Graphics Forum, Computers & Graphics, and The Visual Computer. He also served as paper co-chair of CAD/Graphics 2017 and ICVRV 2017, as well as a PC member for several prestigious conferences including SIGGRAPH Asia, SGP, PG, GMP, etc. His research work can be found in his personal website: https://doi.org/www.kevinkaixu.net.
Hui Huang is Distinguished Professor, Founding Director of the Visual Computing Research Center, Shenzhen University. She received her Ph.D. degree in applied math from the University of British Columbia in 2008 and another Ph.D. degree in computational math from Wuhan University in 2006. Her research interests are in computer graphics and vision, focusing on geometric modeling, shape analysis, point optimization, image processing, 3D/4D acquisition, and creation. She is currently an Associate Editor-in-Chief of The Visual Computer (TVC) and on the editorial boards of Computers & Graphics and Frontiers of Computer Science. She has served on the program committees of almost all major computer graphics conferences including SIGGRAPH Asia, EG, SGP, PG, 3DV, CGI, GMP, SMI, GI, and CAD/Graphics. She was a CHINAGRAPH 2018 Program Vice-Chair, in addition to SIGGRAPH Asia 2017 Technical Briefs and Posters Co-Chair, SIGGRAPH Asia 2016 Workshops Chair and SIGGRAPH Asia 2014 Community Liaison Chair. She is the recipient of an NSFC Excellent Young Scientist Award, Guangdong Technological Innovation Leading Talent Award, CAS Youth Innovation Promotion Association Excellent Member Award, Guangdong Outstanding Graduate Advisor Award, CAS International Cooperation Award for Young Scientists, and CAS Lujiaxi Young Talent Award. She is also a CCF Distinguished Member and ACM/IEEE Senior Member.
Dinesh Manocha is the Paul Chrisman Iribe Chair in Computer Science & Electrical and Computer Engineering at the University of Maryland at College Park. He is also the Phi Delta Theta/Matthew Mason Distinguished Professor Emeritus of Computer Science at the University of North Carolina Chapel Hill. He has won many awards, including Alfred P. Sloan Research Fellow, NSF Career Award, ONR Young Investigator Award, and the Hettleman Prize for scholarly achievement. His research interests include multi-agent simulation, virtual environments, physically-based modeling, and robotics. His group has developed a number of packages for multi-agent simulation, crowd simulation, and physics-based simulation that have been used by hundreds of thousands of users and licensed to more than 60 commercial vendors. He has published more than 480 papers and supervised more than 35 Ph.D. dissertations. He is an inventor of 9 patents, several of which have been licensed to industry. His work has been covered by the New York Times, NPR, Boston Globe, Washington Post, ZDNet, as well as DARPA Legacy Press Release. He is a Fellow of AAAI, AAAS, ACM, and IEEE and also received the Distinguished Alumni Award from IIT Delhi. See https://doi.org/www.cs.umd.edu/dm.
Rights and permissions
This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://doi.org/creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from https://doi.org/www.springer.com/journal/41095. To submit a manuscript, please go to https://doi.org/www.editorialmanager.com/cvmj.
About this article

Cite this article
Liu, M., Shi, Y., Zheng, L. et al. Recurrent 3D attentional networks for end-to-end active object recognition. Comp. Visual Media 5, 91–104 (2019). https://doi.org/10.1007/s41095-019-0135-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41095-019-0135-2