
Abstract
Rough fuzzy clustering algorithms have received extensive attention due to the excellent ability to handle overlapping and uncertainty of data. However, existing rough fuzzy clustering algorithms generally consider single view clustering, which neglects the clustering requirements of multiple views and results in the failure to identify diverse data structures in practical applications. In addition, rough fuzzy clustering algorithms are always sensitive to the initialized cluster centers and easily fall into local optimum. To solve the above problems, the multi-view and transfer learning are introduced into rough fuzzy clustering and a robust multi-view knowledge transfer-based rough fuzzy c-means clustering algorithm (MKT-RFCCA) is proposed in this paper. First, multiple distance metrics are adopted as multiple views to effectively recognize different data structures, and thus positively contribute to clustering. Second, a novel multi-view transfer-based rough fuzzy clustering objective function is constructed by using fuzzy memberships as transfer knowledge. This objective function can fully explore and utilize the potential information between multiple views and characterize the uncertainty information. Then, combining the statistical information of color histograms, an initialized centroids selection strategy is presented for image segmentation to overcome the instability and sensitivity caused by the random distribution of the initialized cluster centers. Finally, to reduce manual intervention, a distance-based adaptive threshold determination mechanism is designed to determine the threshold parameter for dividing the lower approximation and boundary region of rough fuzzy clusters during the iteration process. Experiments on synthetic datasets, real-world datasets, and noise-contaminated Berkeley and Weizmann images show that MKT-RFCCA obtains favorable clustering results. Especially, it provides satisfactory segmentation results on images with different types of noise and preserves more specific detail information of images.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Clustering is an unsupervised learning technique that is widely used in data mining [1, 2], pattern recognition [3, 4], etc. It aims to partition unlabeled data into groups or clusters such that similar data points belong to the same class [5]. In general, clustering methods mainly include prototype-based clustering [6,7,8], density-based clustering [9,10,11], graph-based clustering [12,13,14], and so on. Among them, the prototype-based clustering algorithms consist of two main architecture types, including soft clustering and hard clustering.
Hard clustering algorithms fail to obtain satisfactory results since data in real scenes usually contain ambiguity information and noise. In contrast, soft clustering algorithms are more flexible, which allow pixels to belong to multiple specific regions or classes. In particular, fuzzy c-means (FCM) [15], rough c-means (RCM) [16] and rough fuzzy c-means (RFCM) [17, 18] have been successfully applied in many fields. To effectively deal with ambiguity and overlapping partitions, FCM utilizes fuzzy membership degree to measure the belongingness of each sample to all clusters. RCM introduces the concepts of upper and lower approximations in rough set theory to divide the samples so as to handle the incompleteness and uncertainty of clusters. And RFCM synthesizes the advantages of FCM and RCM. It combines the fuzzy membership degree and the concepts of upper and lower approximations, which enhances the ability of the algorithm to handle the uncertainty and vagueness of clusters, and also improves the robustness of the algorithm to outliers in data. However, the following issues are associated with these classical clustering algorithms: (1) Clustering results are sensitive to the initialized cluster centers and susceptible to noise; (2) These algorithms are designed for single view clustering, ignoring the clustering requirements of multiple views and restricting the application in practice.
To solve the sensitivity to the initialized cluster centers in the first issue, Murugesan et al. [19] proposed a new initialization and performance measure method based on maximizing the ratio of inter-cluster variance to intra-cluster variance to improve the clustering accuracy of RCM. Inspired by the average diversity of datasets, Wu et al. [20] presented an improved cluster centroids initialization method to avoid randomization of cluster centers in FCM. Some scholars also use evolutionary strategies to optimize one or more fitness functions to find the optimal cluster centers. For example, Liu et al. [21] proposed a multiobjective fuzzy clustering algorithm with multiple spatial information (MFCMSI) by combining evolutionary operations and fuzzy clustering. Kumar et al. [22] developed a particle swarm optimization improved fuzzy c-means to deal with noisy data and initialization problem.
To overcome the influence of noise on performance of clustering algorithm, lots of improved clustering algorithms are proposed to more accurately resolve uncertainty [23,24,25,26]. For image segmentation, one of the most popular ideas is that local spatial information is incorporated into clustering algorithms to improve the segmentation effect. Lei et al. [27] proposed a fast and robust fuzzy c-means clustering algorithm (FRFCM) to improve the robustness of the algorithm by using morphological reconstruction (MR) and membership filtering. Wang et al. [28] presented an improved FCM with adaptive spatial & intensity constraint and membership linking (FCM-SICM) for noise image segmentation. Roy and Maji [29] proposed a spatially constrained rough fuzzy c-means (sRFCM) clustering algorithm, which incorporates the local spatial neighborhood information of the image into RFCM to avoid the effect of noise on brain magnetic resonance image segmentation. Recently, in order to reduce fuzzification and smooth over-preserved noisy pixels, Wang et al. [30] devised a fuzzy adaptive local and region-level information c-means (FALRCM) by introducing Kullback–Leibler information with locally median membership degrees. Wu et al. [31] proposed a full-parameter adaptive fuzzy clustering, which improves the robustness by integrating the spatial information of the image and implementing adaptive computation of parameters.
To overcome the limitation of single view clustering, some scholars have proposed multi-view clustering algorithms [32,33,34]. Generally speaking, the term “multi-view clustering” indicates a clustering algorithm that makes use of multiple different feature sets of the data. However, feature sets are not always available. In this case, the term “multi-view” is also able to be extended to the collaborative interaction of multiple different matrices that can be characterized by various distance measures based on a single feature space [35]. Therefore, we argue that the multi-view clustering algorithms possess the potential to deal with different forms of the data. To highlight the advantages of multi-view clustering, Wang et al. [36] proposed a multi-view clustering method by combining the minimax optimization and FCM, called MinimaxFCM. Recently, Hu et al. [37] developed a two-level weighted collaborative multi-view fuzzy clustering (TW-Co-MFC) algorithm. It can simultaneously consider the importance of views and features. However, the above methods are limited to the application to feature sets. Some methods based on the use of multiple relational descriptions or dissimilarity matrices have been proposed sequentially. Liu et al. [38] proposed a multi-objective evolutionary clustering based on combining multiple distance measures (MOECDM) that considers two different distance functions simultaneously to overcome the effect of view weights. García et al. [35] proposed a multi-objective evolutionary multi-view clustering (MVMC) method, which can consider multiple views that are different feature sets or different matrices, and also overcome the limitation of the number of views in existing multi-view clustering methods.
Compared to the single view, an important feature of multi-view is that complementary and consistent information is usually generated in different views [31]. The greater the difference in clustering results between arbitrary views, the greater the need to integrate this information. However, the potential information among views is frequently neglected, resulting in poor clustering results. In recent years, as an efficient learning strategy, transfer learning is widely applied in clustering [8, 39,40,41]. Gargees et al. [42] designed a transfer-learning possibilistic c-means (TLPCM), which takes the cluster prototypes of the source domain as the references for target data clustering to solve the problem of insufficient data. Shi et al. [43] proposed the transfer clustering ensemble selection algorithm (TECS) by combining the transfer learning and clustering ensemble selection, which adaptively selects clustering members based on the tradeoff between quality and diversity, and transfers them to a target dataset based on three objective functions. Jiao et al. [44] proposed a transfer evidential c-means algorithm (TECM). It uses the cluster prototype of the source data as knowledge to design a new objective function to solve the incompleteness and uncertainty in clustering.
On the basis of the issues discussed above, a robust multi-view knowledge transfer-based rough fuzzy c-means clustering algorithm (MKT-RFCCA) is proposed in this paper. The main contributions are highlighted as follows: (1) An enhanced version of RFCM combing with multi-view is presented to break through the limitation of the traditional algorithms with a single view. It employs different dissimilarity matrices as multiple views to improve the capability of the algorithm to explore multiple data structures; (2) Inspired by the knowledge transfer mechanism in transfer learning, a novel multi-view knowledge transfer-based rough fuzzy clustering objective function is constructed, which uses fuzzy memberships as the transfer knowledge to accomplish information with complementary and consistent interaction between views to further promote the clustering performance; (3) Based on the statistical information of color histogram, an initialized centroids selection strategy is proposed to overcome the instability and sensitivity of random cluster centroids in the image segmentation field; (4) A distance-based adaptive threshold determination mechanism is designed to determine the threshold parameter during the rough fuzzy clustering iteration process to improve the robustness of the algorithm.
The remainder of this paper is organized as follows. The brief description of related work is summarized in Sect. “Related work”. Sect. “A robust multi-view knowledge transfer-based rough fuzzy C-means clustering algorithm” describes the details of the proposed MKT-RFCCA. In addition, experimental results and analysis are provided in Sect. “Experimental study”. Finally, Sect. “Conclusion” gives some concluding remarks and discusses future works.
Related work
RFCM [18] introduces the concepts of upper and lower approximations of rough set theory into FCM. The combination of fuzzy membership and the lower and upper approximations of rough set theory in RFCM, which not only effectively handles overlapping partitions, but also deals with uncertainty, ambiguity and incompleteness in class definitions. Let \(X{ = }\left\{ {x_{1} ,x_{2} , \ldots ,x_{N} } \right\}\) be a dataset with N data points and \(v_{i} (1 \le i \le K)\) denotes the center of the cluster \(C_{i}\). The objective function of RFCM is given as follows:
where \(J_{P}\) and \(J_{Q}\) are defined as follows:
The cluster centroid is updated as follows:
where \(\mu_{ij}\) has the same meaning as the fuzzy membership in FCM and m is the fuzzification coefficient. \(L(C_{i} )\) and \(B(C_{i} )\) denote the lower approximation and the boundary region of the cluster \(C_{i}\), respectively. The boundary region \(B(C_{i} ) = \left\{ {UP(C_{i} ) - L(C_{i} )} \right\}\), where \(UP(C_{i} )\) is the upper approximation of the cluster \(C_{i}\). The parameter \(w_{low}\) and \(w_{bon}\) are important for the lower approximation and the boundary region, respectively. It is notable that the membership values of objects in the lower approximation of RFCM are assigned to 1. Moreover, since data points in the lower approximation definitely belong to a cluster, they should be assigned higher weight compared to the data points in the boundary region, that is \(0 < w_{bou} < w_{low} < 1,w_{low} + w_{bou} = 1\).
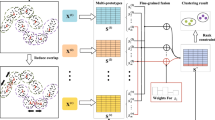
A robust multi-view knowledge transfer-based rough fuzzy C-means clustering algorithm
To effectively recognize the clustering structure and overcome the limitation of single view, this paper adopts different dissimilarity matrices as multiple views and fuzzy memberships as transfer knowledge, and proposes a robust multi-view knowledge transfer-based rough fuzzy c-means clustering algorithm to explore the potential information between views and subsequently improve the clustering performance. In addition, an initialized centroids selection strategy and a distance-based adaptive threshold determination mechanism are designed to enhance the robustness. The details of MKT-RFCCA are as follows.
Initialized centroids selection strategy
It is well known that most clustering algorithms are sensitive to the selection of the initialized centroids. Clustering algorithms with unsuitable initialized centroids may easily fall into local optimum. Therefore, choosing appropriate initialized centroids is an important task for clustering algorithms. In Ref. [19], a heuristic centroids initialization mechanism is proposed by using the ratio of between-cluster variance to within-cluster variance. This mechanism can ensure the separability of clusters and improve the performance of clustering. It should be noted that a pairwise distance matrix between samples needs to be firstly constructed in this initialization method. Therefore, this initialization mechanism is fit for clustering data with small data size. When applied to segment an image, clustering algorithms with this initialization strategy may suffer from the storage and computation problem of the huge distance matrix. In order to solve this problem, a new centroids initialization strategy is designed for color image segmentation in this section.
A color image consists of three color channels, namely red, green, and blue. And the range of pixel values for each channel is [0, 255]. The proposed centroids initialization strategy is used to obtain the corresponding centroids for each color channel and the details of this strategy are presented in Algorithm 1. In this Algorithm, the centroids initialization for red color channel is presented as an example, and another color channels adopt the same operation. First, the histogram of red color channel is calculated and noted as \(h_{R} (s)\), and then the cumulative sum of the histogram is computed by \(H_{R} (s) = \sum\nolimits_{l = 0}^{s} {h_{R} (l)}\), where s and l are the pixel values. Second, all the pixels are initially divided into K parts \(C_{kR} (1 \le k \le K)\) utilizing the histogram cumulative sum. Finally, the initialized centroid \(\tilde{v}_{kR} (1 \le k \le K)\) for red color channel is obtained by calculating the mean value of the pixels within the kth part. Similarly, the initialized centroid for the other two color channels can be achieved and the initialized centroid of the image is \(\tilde{v}_{k} = (\tilde{v}_{kR} ,\tilde{v}_{kG} ,\tilde{v}_{kB} )(1 \le k \le K)\). Figure 1 show an example of this initialization method. The cumulative sum of histogram is shown in Fig. 1d, and the obtained initialized centroids are presented in Fig. 1e.

Initialized centroids selection strategy for image segmentation

The centroids initialization on Berkeley #238011: a original image; b benchmark image; c RGB histogram; d histogram cumulative sum; e obtained initialized centroids
Distance-based adaptive threshold determination mechanism
Classical rough clustering algorithms generally utilize the relationship between the distance difference and the threshold \(\varepsilon\) to determine the upper and lower approximations of each cluster. The threshold \(\varepsilon\) is essential for rough clustering and is always manually set by experience. However, different values of threshold \(\varepsilon\) lead to different clustering results. Therefore, it is a significant task to find a suitable threshold \(\varepsilon\) for rough clustering. In this paper, a distance-based adaptive threshold determination mechanism is designed to reduce manual intervention. Suppose \(d(x_{j} ,v_{n} )\) and \(d(x_{j} ,v_{m} )\) denote the closest and second closest distance values between the data point \(x_{j}\) and the cluster centroids among all the clusters, respectively. The adaptive threshold \(\varepsilon\) is determined as follows:
where \(N\) is the number of data points. It is worth noting that the threshold \(\varepsilon\) will adaptively change in each iteration. In one iteration, if \(d(x_{j} ,v_{m} ) - d(x_{j} ,v_{n} ) > \varepsilon\), \(x_{j}\) belongs to the lower approximation of the cluster \(C_{n}\). Otherwise, \(x_{j}\) belongs to the upper approximations of the cluster \(C_{n}\) and \(C_{m}\), respectively, and it does not belong to any lower approximation of clusters.
The segmentation results of RFCM utilizing the fixed thresholds and the adaptive threshold determined by this mechanism are shown in Figs. 2 and 3. It is obvious that the adaptive threshold provides better segmentation results compared to the fixed thresholds.

Segmentation results on Weizmann #bbmf_lancaster_july_06: a original image; b benchmark image; c RFCM (\(\varepsilon\) = 20); d RFCM (\(\varepsilon\) = 160); e RFCM with the adaptive \(\varepsilon\)

Segmentation results on Berkeley #124084: a original image; b benchmark image; c RFCM (\(\varepsilon\) = 20); d RFCM (\(\varepsilon\) = 160); e RFCM with the adaptive \(\varepsilon\)
Multi-view knowledge transfer-based rough fuzzy clustering objective function
For most clustering algorithms, it is crucial to choose a distance measure to identify particular types of cluster structures [35]. Euclidean distance is very common and more suitable for spherically-shaped clusters. Mahalanobis distance is able to eliminate the limitation of correlation among data, and Manhattan distance is more robust in dealing with outliers. Therefore, a single distance measure may be unsuited to different data. In this work, two or more multiple distance matrices are utilized as multiple views and introduced into the objective function of rough fuzzy clustering to improve the clustering performance. In addition, a transfer learning strategy which employs fuzzy memberships as transfer knowledge is introduced in the objective function to fully utilize the information between views and provide beneficial impacts on clustering.
In MKT-RFCCA, a novel rough fuzzy clustering objective function \(J_{MKT - RFCCA}\) is constructed based on multi-view knowledge transfer. It consists of two parts: the intra-cluster compactness term within each view and the knowledge transfer term between views. In detail, \(J_{MKT - RFCCA}\) is defined by
where L is the number of views, \(\lambda\) is a nonnegative transfer learning factor which controls the important degree of knowledge learning between views. \(J_{1}\) in the first term ensures the intra-cluster compactness in each view, and \(J_{2}\) in the second term utilizes the potential information between views. They are defined as follows:
where \(L(C_{i} )\) and \(B(C_{i} )\) denote the lower approximation and the boundary region of the cluster \(C_{i}\), respectively. The parameter \(w_{low}\) indicates the importance of the lower approximation and boundary region. \(J_{L1}\), \(J_{B1}\), \(J_{L2}\) and \(J_{B2}\) are defined as follows:
where K is the number of clusters, \(v_{i} \, (1 \le i \le K)\) denotes the center of the cluster \(C_{i}\). \(\mu_{lij}\) indicates the membership of the jth data point \(x_{j}\) belonging to the ith cluster in the lth view. It should satisfy \(\sum\nolimits_{i = 1}^{K} {\mu_{lij} } = 1\) and \({0} \le \mu_{lij} \le 1\). m is the fuzzification coefficient. When the proposed method is applied to segment the image, a morphological reconstruction method [27] is utilized to filter the image in advance to avoid the influence of the image noise.
In MKT-RFCCA, the Euclidean distance \(D_{1}^{2} {(}x_{j} ,v_{i} {) = }\left\| {x_{j} - v_{i} } \right\|^{2}\) and Mahalanobis distance \(D_{2}^{2} {(}x_{j} ,v_{i} {) = }(x_{j} - v_{i} )^{T} \Sigma_{i}^{{{ - }1}} (x_{j} - v_{i} )\) are adopted as two views, where \(\Sigma_{i}\) is the covariance matrix of the ith cluster. According to the analysis of the weights assigned to each view in other multi-view clustering methods [36, 37], the importance of each view is equal and the transfer factor satisfies \(\lambda = 1/L\) in our study. By utilizing the Lagrange multiplier method to minimize Eq. (6), the updating formulas of \(v_{i} \, \) and \(\mu_{lij}\) are obtained and presented in detail in Appendix. The centroid updating formula is given as:
where \(F_{L}\) and \(F_{B}\) are defined as follows:
The membership updating formula is given as follows:
Because the importance of views is the same in our algorithm, the final membership degree of the jth data sample belonging to the ith cluster is calculated by
Algorithm procedure
The details of the proposed method are described in Algorithm 2.

Multi-view knowledge transfer-based rough fuzzy C-means clustering algorithm (MKT-RFCCA)
Time complexity analysis
Assume that there are N samples in the dataset, feature dimension is D, the number of views is L, the number of clusters is K, and the iteration number is T. In MKT-RFCCA, the initialized cluster centers are obtained in advance using the initialized centroids selection strategy, and the corresponding time complexity is \(O\left( {KND} \right)\).Then, the time complexity of updating the membership degree values and cluster centers under one iteration is \(O\left( {LKND} \right)\) and \(O\left( {LKND} \right)\), respectively. In T complete iterations, the time complexity consumed by the objective function computation is \(O\left( {TLKND} \right)\). Therefore, the total time complexity of MKT-RFCCA is \(O\left( {TLKND} \right)\).
Experimental study
In order to verify the effectiveness and superiority of the proposed algorithm, we conduct experiments on synthetic datasets [38], real-world datasets [45], Berkeley images [46], and Weizmann images [47]. A total of seven prevalent clustering algorithms are adopted as comparative algorithms for MKT-RFCCA, which are FCM [15], RCM [16], RFCM [18], transfer fuzzy c-means (TFCM) [39], MVMC [35], FCM-SICM [28], and sRFCM [29]. Among these comparative algorithms, FCM-SICM and sRFCM are proposed for image segmentation and can overcome the influence of noise in the image. Therefore, these two comparative methods are only used in the experiments of image segmentation. All experiments are implemented on a server with Intel Core i7-12700 processor, 16 GB of RAM, and Windows 11. Parameter settings of all algorithms are shown in Table 1. To ensure the fairness of the experiments, the parameter of the lower approximation weight \(w_{low}\) in RCM, RFCM, sRFCM and MKT-RFCCA are set to the same value.
To measure the clustering performance of MKT-RFCCA and comparative algorithms, this paper employs two well-accepted validity indicators, namely, clustering accuracy (CA) [48] and normalized mutual information (NMI) [49]. The greater values of CA and NMI, the better performance of the corresponding algorithm. In addition, in order to fairly compare the performance of all algorithms, the indicator results in the experiments of this paper are calculated by averaging the five maximum values.
Validation of adaptive threshold determination mechanism in MKT-RFCCA
In Sect. “Distance-based adaptive threshold determination mechanism”, we have verified the effectiveness of the adaptive threshold determination mechanism under the framework of RFCM. The positive contribution of the adaptive threshold determination mechanism in MKT-RFCCA is confirmed in this section. The experiments are performed on synthetic datasets and images by using two fixed thresholds and adaptive threshold. In particular, White Gaussian noise with the normalized variance (NV) of 0.004 and Salt & Pepper noise with the noise percentage (NP) of 0.02 are added to the images, respectively. The values of CA and NMI on the synthetic datasets are shown in Figs. 4, 5, 6 and the corresponding clustering results are given in Figs. 7, 8, where the red stars represent the obtained cluster centers. It can be seen that the smaller threshold provides clear clusters, while the larger threshold leads to over-shifting of cluster centers and misclassification. In contrast, adaptive threshold not only achieves the same favorable clustering results, but also has more accurate cluster center locations. The two evaluation index results on the images are given in Figs. 5, 6, and the visual segmentation results are presented in Figs. 9, 10, 11, 12. Likewise, the outcomes show that different thresholds significantly affect the clustering results, and adaptive threshold holds better results. In summary, the adaptive threshold determination mechanism in MKT-RFCCA can effectively determine the threshold parameter automatically, which can improve the feasibility and robustness of the algorithm.

CA and NMI values under two fixed thresholds and the adaptive threshold on synthetic datasets: a #Data92; b #Sizes 5

CA and NMI values under two fixed thresholds and the adaptive threshold on Berkeley images with the Gaussian noise: a #238011; b #167062

CA and NMI values under two fixed thresholds and the adaptive threshold on Berkeley images with the Salt & Pepper noise: a #238011; b #167062

Clustering results on synthetic dataset #Data92: a benchmark result; b MKT-RFCCA (\(\varepsilon\) = 0.1); c MKT-RFCCA (\(\varepsilon\) = 1.5); d MKT-RFCCA

Clustering results on synthetic dataset #Sizes 5: a benchmark result; b MKT-RFCCA (\(\varepsilon\) = 0.1); c MKT-RFCCA (\(\varepsilon\) = 1.5); d MKT-RFCCA

Segmentation results on Berkeley #238011 with the Gaussian noise: a original image; b noisy image; c benchmark image; d MKT-RFCCA (\(\varepsilon\) = 20); e MKT-RFCCA (\(\varepsilon\) = 160); f MKT-RFCCA

Segmentation results on Berkeley #238011 with the Salt & Pepper noise: a original image; b noisy image; c BENCHMARK image; d MKT-RFCCA (\(\varepsilon\) = 20); e MKT-RFCCA (\(\varepsilon\) = 160); f MKT-RFCCA

Segmentation results on Berkeley #167062 with the Gaussian noise: a original image; b noisy image; c benchmark image; d MKT-RFCCA (\(\varepsilon\) = 20); e MKT-RFCCA (\(\varepsilon\) = 160); f MKT-RFCCA

Segmentation results on Berkeley #167062 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d MKT-RFCCA (\(\varepsilon\) = 20); e MKT-RFCCA (\(\varepsilon\) = 160); f MKT-RFCCA
Validation multi-view learning in MKT-RFCCA
The effectiveness of multi-view learning in MKT-RFCCA is validated in this section. In this experiment, only utilizing Euclidean distance in MKT-RFCCA is selected as the single view clustering case to compare with multi-view clustering. Some synthetic datasets and Berkeley images with noise are selected as test data. The corresponding experimental results are provided in Figs. 13, 14, 15. The experimental results reveal that the single view clustering results are difficult to maintain the optimal values on different types of data, which is due to the fact that the Euclidean distance only considers the spherical relationship. Comparatively, the multi-view clustering results are significantly better, which combines different distance metrics and utilizes transfer learning to further explore the potential complementary information between views, thus effectively enhancing the clustering performance of the algorithm. Therefore, the introduction of multi-view learning plays a crucial role in the superiority and effectiveness of MKT-RFCCA.

Clustering results on synthetic datasets: a CA index; b NMI index

Segmentation results on Berkeley images with the Gaussian noise (NV = 0.004): a CA index; b NMI index

Segmentation results on Berkeley images with the Salt & Pepper noise (NP = 0.02): a CA index; b NMI index
Clustering experiments on synthetic datasets
This section studies the capability of MKT-RFCCA to generate high-quality clustering solutions on synthetic datasets with different sizes, dimensions, and degrees of overlap. The synthetic datasets are used in this section are shown in Fig. 16. According to the data distribution, these synthetic datasets are classified into two categories: well-separated clusters and overlapping clusters. The details of the synthetic datasets and the corresponding clustering results of all algorithms are shown in Table 2, where N is the number of samples, D is the dimension, and K is the number of clusters.

Standard clustering results of the synthetic datasets
As shown in Table 2, most methods obtain desirable clustering results on the well-separated datasets Data43 and TwoDiamonds. For Square1 and Sizes5 datasets, FCM, RCM, RFCM and TFCM clustering algorithms based on a single Euclidean distance perform poorly due to the overlapping distribution of the data. MVMC and MKT-RFCCA consider different distance metrics and are able to recognize various data structures, and MKT-RFCCA performs better than MVMC because of introducing a transfer mechanism. FCM and TFCM using the Euclidean distance metric obtain better results on the dataset Data92 with spherical and overlapping distributions, but TFCM outperforms FCM due to the guidance of the transfer mechanism. The above experimental results confirm the effectiveness of MKT-RFCCA in handling different data distributions.
Clustering experiments on real-world datasets
Here, we apply MKT-RFCCA to real datasets to test the performance. Five datasets from the UCI database are selected: Iris, Glass, Haberman, German, and Zoo. The CA and NMI values of MKT-RFCCA and comparative algorithms are shown in Table 3. It is evident that the evaluation index values of MKT-RFCCA and MVMC based on multi-view clustering algorithms are significantly superior to the other comparison algorithms with single view on most datasets. Specifically, for Glass, Haberman and German datasets, MKT-RFCCA obtains competitive clustering results by using the transfer mechanism between views. And for Iris and Zoo datasets, MVMC achieves the optimal performance by virtue of the evolutionary strategy, which yields better clustering results.
Segmentation experiments on Berkeley images
In this section, several images from the Berkeley dataset are selected to demonstrate the segmentation performance of MKT-RFCCA. Although MVMC shows better clustering performance on some datasets in the previous sections, it is not applicable to image segmentation due to the large amounts of pixels in the image. In this section, FCM, RCM, RFCM, TFCM, FCM-SICM and sRFCM are used as the comparative algorithms. In this experiment, Berkeley images are added with the White Gaussian noise and the Salt & Pepper noise, respectively. The CA and NMI values of all algorithms on noisy images are shown in Tables 4 and 5. As can be seen, the performance of MKT-RFCCA outperforms the comparative algorithms on the majority of images with different noise types and levels.
In addition, some segmentation results of Berkeley images with the White Gaussian noise (NV = 0.004) and the Salt & Pepper noise (NP = 0.02) are selected to compare the performance of MKT-RFCCA and the comparison algorithms more intuitively, as shown in Figs. 17, 18, 19, 20, 21, 22. These visual segmentation results indicate that FCM, RCM, and RFCM fail to effectively overcome the influence of noise and retain a large number of misclassified pixels in the segmentation results. Although TFCM is an algorithm that considers the transfer mechanism, it provides unsatisfactory results by ignoring spatial information. FCM_SICM and sRFCM obtain poor results because the local spatial information has been contaminated by different types and levels of noise. In contrast, MKT-RFCCA not only provides excellent segmentation results on images with different types of noise, but also preserves the details of the images.

Segmentation results on Berkeley #101027 with the Gaussian noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Berkeley #15088 with the Gaussian noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Berkeley #124084 with the Gaussian noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Berkeley #167062 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Berkeley #238011 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Berkeley #118035 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA
Figure 23 shows the average values of CA and NMI metrics obtained by MKT-RFCCA and the comparative algorithms on sixty Berkeley images with the addition of the White Gaussian noise and the Salt & Pepper noise, respectively. It also demonstrates the superior clustering performance of MKT-RFCCA compared to the comparative algorithms.

Average metric values of MKT-RFCCA and comparative algorithms on sixty Berkeley images: a images with the Gaussian noise; b images with the Salt & Pepper noise
Segmentation experiments on Weizmann images
In this section, we choose some Weizmann images to further validate the segmentation performance of MKT-RFCCA on noisy images with different types and degrees of noise. The segmentation experiments on the Weizmann images use the same experimental settings as the segmentation experiments on the Berkeley images. The CA and NMI values of the noisy images on MKT-RFCCA and comparative algorithms are shown in Tables 6 and 7. It can be observed from these tables that MKT-RFCCA performs more effectively than other algorithms on most images. To visually evaluate the effectiveness of MKT-RFCCA and the comparative algorithms, the corresponding results on four Weizmann images with the White Gaussian noise (NV = 0.004) and the Salt & Pepper noise (NP = 0.02) are illustrated in Figs. 24, 25, 26, 27. As can be seen from the results, FCM-SICM, sRFCM, and MKT-RFCCA perform better than the other comparative algorithms. However, FCM-SICM and sRFCM are difficult to overcome the noise effect due to the local spatial information is contaminated. In contrast, MKT-RFCCA performs well in terms of noise robustness and detail preservation. For instance, it is obvious from Fig. 26 that the results of FCM, RCM, RFCM, TFCM and FCM-SICM contain some misclassified pixels in the background and island. MKT-RFCCA and sRFCM outperform the other methods. Compared to sRFCM, MKT-RFCCA can completely segment the island from the background and effectively suppress the noise.

Segmentation results on Weizmann #leafpav with the Gaussian noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Weizmann #bbmf_lancaster_july_06 with the Gaussian noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Weizmann #beltaine_4_bg_050502 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA

Segmentation results on Weizmann #europe_holiday_484 with the Salt & Pepper noise: a original image; b noisy image; c benchmark image; d FCM; e RCM; f RFCM; g TFCM; h FCM-SICM; i sRFCM; j MKT-RFCCA
Figure 28 shows the average values of CA and NMI metrics obtained by MKT-RFCCA and the comparative algorithms on thirty Weizmann images with the addition of the White Gaussian noise and the Salt & Pepper noise, respectively. It also reveals the superiority of MKT-RFCCA compared to the comparative algorithms.

Average metric values of MKT-RFCCA and comparative algorithms on thirty Weizmann images: a images with the Gaussian noise; b images with the Salt & Pepper noise
Comprehensive evaluation for all algorithms
In this section, in order to comprehensively compare significant differences of all algorithms, the technique for order preference by similarity to ideal solution (TOPSIS) [50] is applied to rank and evaluate all algorithms. The CA and NMI are selected as the benchmark test metrics, and the results in Tables 2, 3, 4, 5, 6, 7 are combined to calculate the proximity of all algorithms on synthetic and real-world datasets, Berkeley and Weizmann images. A higher proximity means the algorithm is superior. Tables 8 and 9 show the proximity results of each algorithm. As can be seen from these tables, MVMC and MKT-RFCCA outperform the other algorithms on the datasets, and more importantly MKT-RFCCA is superior in comparison. For images with noise, FCM-SICM and RFCM show slightly better results, however, as the image information is contaminated with increasing noise, their results deteriorate. MKT-RFCCA provides the highest proximity in all cases and is the optimal choice compared to other prevalent comparison algorithms.
Conclusion
In this paper, a robust multi-view knowledge transfer-based rough fuzzy c-means clustering algorithm (MKT-RFCCA) is proposed. First, in order to overcome the restriction of traditional clustering algorithms based on single view, different distance metrics are adopted as multiple views to identify different data structures and satisfies the diverse clustering demands in the real world. Second, the objective function of MKT-RFCCA is constructed by introducing the transfer learning mechanism. The objective function fully exploits and utilizes the potential information with complementarity and consistency between multiple views, thus improving the capability of the algorithm to handle uncertain information. In addition, in order to reduce the sensitivity of the algorithm to random cluster centroids, an initialized cluster centroids selection strategy for image segmentation is presented, which is helpful to generate more accurate and stable clustering results. Finally, a distance-based adaptive threshold determination mechanism is proposed to determine the lower approximation and boundary region in rough fuzzy clustering. It eliminates the drawbacks of manually setting the threshold parameter and improves the robustness. Satisfactory experimental results obtained on synthetic datasets, real-world datasets, and noise-contaminated Berkeley and Weizmann images validate the performance of MKT-RFCCA.
This work focuses on the clustering objective function of intra-cluster compactness and ignores other clustering criteria. One of our future studies aims to construct various complementary objective functions and perform multi-view rough fuzzy clustering under multiple objective functions. In addition, we will design more effective transfer mechanisms to further enhance the clustering performance and introduce evolutionary optimization strategies to find the global optimal scheme.
Data availability
The real-data that support the findings of this study are openly available in UCI Machine Learning Repository at http://archive.ics.uci.edu/ml/, Berkeley Image Library at https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/segbench/ and Weizmann Image Library at www.wisdom.weizmann.ac.il/~vision/databases.html. And the synthetic data that support the findings of this study are available upon reasonable request from the author Yang.
References
Cai L, Wang H, Jiang F et al (2022) A new clustering mining algorithm for multi-source imbalanced location data. Inf Sci 584:50–64. https://doi.org/10.1016/j.ins.2021.10.029
Gomez-Sanchez G, Delgado-Serrano L, Carrera D et al (2022) Clustering and graph mining techniques for classification of complex structural variations in cancer genomes. Sci Rep 12:3244. https://doi.org/10.1038/s41598-022-07211-6
Ullah K, Mahmood T (2019) On some distance measures of complex Pythagorean fuzzy sets and their applications in pattern recognition. Complex Intell Syst 6:15–27. https://doi.org/10.1007/S40747-019-0103-6
Singh S, Singh K (2023) Novel fuzzy similarity measures and their applications in pattern recognition and clustering analysis. Granul Comput 8:1715–1737. https://doi.org/10.1007/s41066-023-00393-y
Li X, Cai L, Li J (2021) A survey of clustering methods via optimization methodology. J Appl Numer Optim 3(1):151–174. https://doi.org/10.23952/jano.3.2021.1.09
Zeng S, Wang X, Duan X et al (2021) Kernelized Mahalanobis distance for fuzzy clustering. IEEE Trans Fuzzy Syst 29(10):3103–3117. https://doi.org/10.1109/TFUZZ.2020.3012765
Rubio E, Valdez F, Melin P et al (2017) An extension of the fuzzy possibilistic clustering algorithm using type-2 fuzzy logic techniques. Adv Fuzzy Syst 7094046:23. https://doi.org/10.1155/2017/7094046
Zhao F, Wang C, Liu H (2023) Differential evolution-based transfer rough clustering algorithm. Complex Intell Syst 9:5033–5047. https://doi.org/10.1007/s40747-023-00987-8
Zhou W, Wang L, Han X (2022) A novel density deviation multi-peaks automatic clustering algorithm. Complex Intell Syst 9:177–211. https://doi.org/10.1007/s40747-022-00798-3
Zhang M, Ma Y, Li J et al (2023) A density connection weight-based clustering approach for dataset with density-sparse region. Expert Syst Appl 230(15):120633. https://doi.org/10.1016/j.eswa.2023.120633
Bian Z, Chung F, Wang S (2021) Fuzzy density peaks clustering. IEEE Trans Fuzzy Syst 29(7):1725–1738. https://doi.org/10.1109/TFUZZ.2020.2985004
Wang Y, Chang D, Fu Z, Zhao Y (2021) Consistent multiple graph embedding for multi-view clustering. IEEE Trans Multimed. https://doi.org/10.1109/TMM.2021.3136098
Che L, Zhao Y, Zhang C (2022) Efficient kernel fuzzy clustering via random Fourier superpixel and graph prior for color image segmentation. Eng Appl Artif Intell 116:105335. https://doi.org/10.1016/j.engappai.2022.105335
Zhang G, Chen X, Zhou Y et al (2022) Kernelized multi-view subspace clustering via auto-weighted graph learning. Appl Intell 52:716–731. https://doi.org/10.1007/s10489-021-02365-8
Bezdek J (1981) Pattern recognition with fuzzy objective function algorithms. Springer. https://doi.org/10.1007/978-1-4757-0450-1
Peters G (2006) Some refinements of rough-means clustering. Pattern Recogn 39(8):1481–1491. https://doi.org/10.1016/j.patcog.2006.02.002
Mitra S, Banka H, Pedrycz W (2006) Rough-fuzzy collaborative clustering. IEEE Trans Syst 36(4):795–805. https://doi.org/10.1109/TSMCB.2005.863371
Maji P, Pal S (2007) RFCM: a hybrid clustering algorithm using rough and fuzzy sets. Fund Inform 80(4):475–496. https://doi.org/10.5555/2367421.2367428
Murugesan VP, Murugesan P (2020) A new initialization and performance measure for the rough k-means clustering. Soft Comput 24(15):11605–11619. https://doi.org/10.1007/s00500-019-04625-9
Wu Z, Zhao Y, Wang W et al (2023) Adaptive weighted fuzzy clustering based on intra-cluster data divergence. Neurocomputing 552:126550. https://doi.org/10.1016/j.neucom.2023.126550
Liu H, Zhao F (2021) Multiobjective fuzzy clustering with multiple spatial information for Noisy color image segmentation. Appl Intell 51:5280–5298. https://doi.org/10.1007/s10489-020-01977-w
Kumar N, Kumar H (2022) A fuzzy clustering technique for enhancing the convergence performance by using improved Fuzzy c-means and Particle Swarm Optimization algorithms. Data Knowl Eng 140:102050. https://doi.org/10.1016/j.datak.2022.102050
Kala R, Deepa P (2021) Spatial rough intuitionistic fuzzy c-means clustering for MRI segmentation. Neural Process Lett 53:1305–1353. https://doi.org/10.1007/s11063-021-10441-w
Kaushal M, Garg H (2023) Global intuitionistic fuzzy weighted C-ordered means clustering algorithm. Inf Sci 642:119087. https://doi.org/10.1016/j.ins.2023.119087
Mohapatra D, Chakraverty S, Castillo O (2023) Numerical investigation of fluid dynamic model in uncertain environment. Appl Comput Math 22(3):297–316. https://doi.org/10.30546/1683-6154.22.3.2023.297
Wang J, Zhang X, Nie F et al (2023) Enhanced robust fuzzy K-means clustering joint l0-norm constraint. Neurocomputing 561:126842. https://doi.org/10.1016/j.neucom.2023.126842
Lei T, Jia X, Zhang Y et al (2018) Significantly fast and robust fuzzy C-means clustering algorithm based on morphological reconstruction and membership filtering. IEEE Trans Fuzzy Sys 26(5):3027–3041. https://doi.org/10.1109/TFUZZ.2018.2796074
Wang Q, Wang X, Fang C et al (2020) Robust fuzzy c-means clustering algorithm with adaptive spatial & intensity constraint and membership linking for noise image segmentation. Appl Soft Comput 92:106318. https://doi.org/10.1016/j.asoc.2020.106318
Roy S, Maji P (2020) Medical image segmentation by partitioning spatially constrained fuzzy approximation spaces. IEEE Trans Fuzzy Syst 28(5):965–997. https://doi.org/10.1109/TFUZZ.2020.2965896
Wang Q, Wang X, Fang C et al (2021) Fuzzy image clustering incorporating local and region-level information with median memberships. Appl Soft Comput 105:107245. https://doi.org/10.1016/j.asoc.2021.107245
Wu J, Wang X, Wei T (2023) Full-parameter adaptive fuzzy clustering for noise image segmentation based on non-local and local spatial information. Comput Vis Image Underst 235:103765. https://doi.org/10.1016/j.cviu.2023.103765
Chao G, Sun S, Bi J (2023) A survey on multi-view clustering. Accessed: 07 Jan 2023. http://arxiv.org/abs/1712.06246.
Hussain SF, Khan M, Siddiqi I (2022) Co-clustering based classification of multi-view data. Appl Intell 52:14756–14772. https://doi.org/10.1007/s10489-021-03087-7
Tao S, Qiu R, Cao Y (2023) Intent with knowledge-aware multiview contrastive learning for recommendation. Complex Intell Syst. https://doi.org/10.1007/s40747-023-01222-0
José-García A, Handl J, Gómez-Flores W et al (2021) An evolutionary many-objective approach to multiview clustering using feature and relational data. Appl Soft Comput 108:107425. https://doi.org/10.1016/j.asoc.2021.107425
Wang Y, Chen L (2017) Multi-view fuzzy clustering with minimax optimization for effective clustering of data from multiple sources. Expert Syst Appl 72:457–466. https://doi.org/10.1016/j.eswa.2016.10.006
Hu J, Pan Y, Li T et al (2021) TW-Co-MFC: two-level weighted collaborative fuzzy clustering based on maximum entropy for multi-view data. Tinshhua Sci Technol 26(2):185–198. https://doi.org/10.26599/TST.2019.9010078
Liu C, Liu J, Peng D et al (2018) A general multiobjective clustering approach based on multiple distance measures. IEEE Access 6:41706–41719. https://doi.org/10.1109/ACCESS.2018.2860791
Deng Z, Jiang Y, Chung K et al (2016) Transfer prototype-based fuzzy clustering. IEEE Trans Fuzzy Syst 24(5):1210–1232. https://doi.org/10.1109/TFUZZ.2015.2505330
Dang B, Wang Y, Zhou J et al (2020) Transfer collaborative fuzzy clustering in distributed peer-to-peer networks. IEEE Trans Fuzzy Syst 30:500–514. https://doi.org/10.1109/TFUZZ.2020.3041191
Dang B (2019) Transfer learning based kernel fuzzy clustering. In: 2019 International Conference on Fuzzy Theory and Its Applications (iFUZZY), Taiwan, pp. 21–25. https://doi.org/10.1109/iFUZZY46984.2019.9066208
Gargees R, Keller J, Popescu M (2021) TLPCM: transfer learning possibilistic C-means. IEEE Trans Fuzzy Syst 29:940–952. https://doi.org/10.1109/TFUZZ.2020.3005273
Shi Y et al (2020) Transfer clustering ensemble selection. IEEE Trans Cybern 50(6):2872–2885. https://doi.org/10.1109/TCYB.2018.2885585
Jiao L, Wang F, Liu Z et al (2022) TECM: transfer learning-based evidential C-means clustering. Knowl Based Syst 257:109937. https://doi.org/10.1016/j.knosys.2022.109937
Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Arbeláez P, Maire M, Fowlkes C et al (2011) Contour detection and hierarchical image segmentation. IEEE Trans Pattern Anal Mach Intell 33(5):898–916. https://doi.org/10.1109/TPAMI.2010.161
Alpert S, Galun M, Brandt A et al (2012) Image segmentation by probabilistic bottom–up aggregation and cue integration. IEEE Trans Pattern Anal Mach Intell 34(2):315–327. https://doi.org/10.1109/TPAMI.2011.130
Schölkopf B, Platt J, Hofmann T (2007) A local learning approach for clustering. IN: Advances in Neural Information Processing Systems 19: Proceedings of the 2006 Conference, pp 1529–1536. https://doi.org/10.7551/mitpress/7503.003.0196
Covões TF, Hruschka ER, Ghosh J (2013) A study of K-means-based algorithms for constrained clustering. IDA 17(3):485–505. https://doi.org/10.3233/IDA-130590
Hwang C, Yoon K (1981) Multiple attribute decision making: methods and applications—a state-of-the-art survey. Lect Notes Econ Math Syst. https://doi.org/10.1007/978-3-642-48318-9
Acknowledgements
The authors thank both the editors and reviewers for their valuable suggestions. This work was supported by the National Natural Science Foundation of China (Grant Nos. 62071379, 62071378, 61901365 and 62106196) and the Youth Innovation Team of Shaanxi Universities.
Author information
Authors and Affiliations
Contributions
Feng Zhao: Conceptualization, Writing-review & Editing, Funding acquisition, Resources. Yujie Yang: Methodology, Data curation, Software, Writing-original draft preparation. Hanqiang Liu: Methodology, Visualization, Investigation, Supervision. Chaofei Wang: Visualization, Validation, Supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Compliance with ethical standards
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
This part gives the proof process of updating formulas in MKT-RFCCA. The objective function of MKT-RFCCA based on fuzzy clustering is as follows:
Firstly, the proof process of Eq. (15) is as follows:
The above optimization problem is converted to the following unconstrained minimization problem with the Lagrange multiplier technique.
where \(\eta\) is the Lagrange multiplier. Setting the partial derivatives of \(G\left( {\mu_{lij} ,\eta } \right)\) to zero with respect to \(\mu_{lij}\) and \(\eta\).
From Eq. (20), we have
Thus, \(\mu_{lij}\) update formula is obtained as follows:
Then, the proof process of Eq. (13) is as follows:
Setting the partial derivatives of \(J_{MKT - RFCCA}{\prime}\) to zero with respect to \(v_{i}\).
From Eq. (24), we have
When the transfer factor satisfies \(\lambda = 1/L\), the following equation holds. And Eq. (13) is obtained based on the weights average of the lower approximation and the fuzzy boundary.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhao, F., Yang, Y., Liu, H. et al. A robust multi-view knowledge transfer-based rough fuzzy C-means clustering algorithm. Complex Intell. Syst. 10, 5331–5358 (2024). https://doi.org/10.1007/s40747-024-01431-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-024-01431-1