
Abstract
With the increasing traffic congestion in cities, the priority of public transit has become a consensus for the development and management of urban transportation. The traffic pre-signal mechanism, which gives priority in time and space to buses by optimizing road right-of-way allocation, has gained wide attention and application. In order to broaden the action exploration range of the agent and avoid the pre-signal decision from falling into suboptimal strategy or local optimal strategy. For the exploration strategy of the DDQN algorithm, this paper reduces the probability of directly selecting the local optimal action and increases the probability of selecting non-greedy actions based on the principle that “the action with a larger value function is more likely to be selected.” This paper addresses the problem that the existing urban traffic pre-signal mechanism cannot adaptively adjust the advance time, and proposes a traffic pre-signal adaptive timing mechanism based on a Hybrid Exploration Strategy Double Deep Q Network (HES-DDQN) by combining the \(\epsilon \)-greedy strategy and Boltzmann strategy. We have used the traffic simulation software VISSIM to conduct simulation experiments on an intersection. The experimental results show that, compared with the method of setting no pre-signal and the formula method of setting pre-signal, the HES-DDQN pre-signal mechanism can significantly reduce the average delay of buses, the waiting queue length, and the number of stops of social vehicles.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
According to the data released by the Traffic Administration Bureau of the Ministry of Public Security, the number of motor vehicles in China has reached 395 million by the end of 2021. The rapid increase of vehicles has aggravated the congestion on urban roads, making traffic congestion an urgent problem to be solved for sustainable urban development. Bus priority strategy can save resources and energy and reduce road occupancy, thus becoming an effective way to solve the congestion problem and promote sustainable urban development [1]. On the one hand, from the spatial dimension, we can take some measures to widen the driving space of buses, such as taking bus lanes, borrowing the opposite direct lane to turn left, and so on. On the other hand, from the temporal dimension, we can take some measures to improve the utilization of driving time, such as traffic restrictions based on even- and odd-numbered license plates, bus signal priority, left-turn waiting area, et al. [2]. Among them, setting bus lanes is commonly used in various cities. But faced with the contradiction between the increasing number of vehicles and the limitation of fixed road width, the benefit brought by bus lanes is close to saturation [3]. While the traffic pre-signal mechanism can provide better time and space priority for buses on the basis of setting bus lanes, which facilitates buses to through the road intersection quickly.

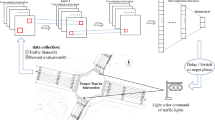
Pre-signal mechanism schematic diagram
The pre-signal mechanism improves bus driving efficiency of crossing the intersecion by generating guidance information in advance of social vehicles stopping to wait and bus priority. Its basic driving rules are shown in Fig. 1. A second signal is added at a certain position upstream of the main signal at the intersection, called pre-signal. The stop line under the control of the pre-signal is called the pre-stop line, and the area between the main stop line and the pre-stop line is called the bus advance area. The road side bus lane is set up on the upstream section of the pre-stop line, while all lanes in the bus advance area allow all types of vehicles to drive. When the pre-signal turns red, social vehicles need to stop and wait in front of the pre-stop line until the pre-signal turns green. While buses are not affected, bus drivers are allowed to continue to drive to the bus advance area and stop in front of the main stop line to wait for the main signal instructions. When the pre-signal turns green, social vehicle drivers are allowed to drive into the bus advance area and continue to line up behind the buses which enjoyed the convenience of privilege brought by pre-signal policy. The pre-signal mechanism provides more favorable time and space resources for buses and helps save time for buses to cross intersections.
According to the driving rules of the pre-signal mechanism, the phase duration setting of the pre-signal under the influence of the main signal (i.e., the phase difference setting between the main signal and pre-signal) becomes a key issue to be studied in order to improve road utilization and reduce the total vehicle delay. The main and pre-signal phase difference includes green phase difference and red phase difference, i.e., the time difference when the pre-signal turns green or red in advance compared to the time when the main signal changes.
-
Green Phase Difference: It refers to the period that the pre-signal turns green earlier than the main signal. Its setting problem is mainly oriented to the filling status of the bus advance area. It is necessary to realize that before the main signal turns green, the social vehicles drive into the bus advance area in advance and queue up to cross the intersection just after the bus queue so as to maximize the effect of the green light on the main signal.
-
Red Phase Difference: It refers to the period that the pre-signal turns red earlier than the main signal. Its setting problem is mainly oriented to the emptying status of the bus advance area. Before the main signal turns red, it is necessary to intercept the social vehicles that are not enough to drive through the intersection in the current phase cycle to drive into the bus advance area so that all social vehicles already in the bus advance area can travel through the intersection, and the buses that drive into the bus advance area in the next phase can be at the front of the queue.
Bus priority strategies have been heavily put into practice, but some challenges remain. The installation of bus lanes, while effective in reducing bus delays, also reduces the number of lanes available for social vehicles [4]. It may also cause delays on entire roads during peak periods. Although the bus signal priority strategy can facilitate bus priority through the intersection and improve the service quality of the bus, it can also weaken the driving performance of social vehicles and increase the delay in the direction of social vehicles.
Based on the above-mentioned problems, this paper, oriented to bus priority, addresses the red and green phase setting problem of traffic pre-signal, and investigates a model based on Hybrid Exploration Strategy Double DQN (HES-DDQN) to achieve an adaptive intelligent timing scheme for pre-signal and to effectively reduce bus delay without increasing social vehicle delay.
The main contributions of this paper are:
-
We summarize the shortcomings of using the formula method to calculate the phase difference between the main and pre-signal.
-
We apply deep reinforcement learning to the pre-signal mechanism to achieve adaptive optimal control of the pre-signal.
-
We propose a pre-signal timing model based on a hybrid exploration strategy, and verify the effectiveness of the model by comparing experiments with the formulation method and mainstream deep reinforcement learning algorithms.
This paper is organized as follows.“Related Work” section presents background concepts and the related work. In “Model Setting” section, we elaborate on the state, action, and reward function settings for the pre-signal mechanism in terms of reinforcement learning definition. We describe our proposed method in “Pre-signal Mechanism of HES-DDQN” section. Next, the experiments and results are presented in “Experiment” section. Finally, in “Conclusion and Prospect” section, we present the conclusions and future work.
Related work
The concept of “bus pre-signal” was first introduced in 1991 in a study of bus development in the U.K. In 1993, a large-scale practical application of pre-signal was implemented in London [5]. Wu and Hounsell [6] from the University of Southampton investigated how and under what conditions pre-signal could be set up, and pre-signal mechanisms were evaluated for buses and social vehicles in terms of capacity, signal settings, and start-stop delay. In 1994, the pre-signal mechanism was further developed when the double stop line approach was proposed by Oakes [7]. In 2005, Transport for London [8] published Bus pre-signals assessment and design guidance, which is the first complete summary of the research results and practical experience of pre-signal. The manual comprehensively presents possible problems and their solutions in the implementation of pre-signal mechanisms through feasibility, assessment, consultation, design, implementation, and post-management.
In addition to the U.K., the pre-signal mechanism has been practically applied to urban roads in countries such as Switzerland and Germany [9]. Guler et al. collected real data on existing pre-signal in Zurich, Switzerland, proposed an analytical formula for calculating bus delay based on queuing theory for both the main signal below saturation [10] and over saturation [11], and demonstrated the validity of the analytical formula by comparing it with real data. Using the proposed analytical formulation, Guler et al. [12] further introduced the basic guidelines for implementing pre-signal in traffic roads, providing practitioners with tools to assess the feasibility of pre-signal. He et al. [13] determined the environmental conditions and parameters required for adaptive control and proposed an adaptive control algorithm that can cope with different traffic demands. Bhattacharyya et al. [14] compared the effectiveness of queuing bypass lanes for non-priority vehicles for scenarios with and without pre-signal and used queuing bypass lanes to separate buses from the main traffic flow to give bus priority. In recent years, many studies have combined the pre-signal mechanism with other priority strategies and applied them to a variety of traffic scenarios to more effectively alleviate traffic congestion. Zhao et al. [15] applied the pre-signal and sorting zone combination to the exit ramp area to eliminate the conflict of traffic flow and increase the overall capacity of the roadway. Li et al. [16] proposed a pre-signal intersection geometry design using a phase-switching strategy to select a more appropriate sorting zone distance and improve space utilization. Bie et al. [17] applied the pre-signal to signalized intersections, determined the detector location layout, and established a bus signal priority adaptive control algorithm to alleviate the congestion caused by the priority strategy on social vehicles. Zhang et al. [18] introduced several parameters of road state as variables for deciding the pre-signal advance time and worked on minimizing the per capita delay.
In the domestic research work on pre-signal, Li et al. [19] studied the microscopic simulation method of pre-signal, proposed the formula for calculating the main and pre-signal phase difference, and compared the intersection delay before and after the pre-signal setting. Wu et al. [20] utilized the opposing straight lanes with left-turn pre-signal indicators to reduce left-turn delay and accomplish the work of improving the capacity of left-turn vehicle flow. An et al. [21] used bus lanes to widen the number of left-turn lanes for medial road bus lanes and investigated the phase scheme and coordinated timing relationships of the main signal and pre-signal. Xue [22] combined pre-signal and channelization design to optimize the bus right-of-way priority problem by comparing and analyzing four evaluation indexes of average queue length, per capita delay, vehicle delay, and average parking times. Huang [23] investigated the effect of bus advance area length on traffic flow. He solved the conflict between left-turn vehicles and straight-through vehicles and avoided the obstruction of vehicles to subsequent queues during congested periods. As for the layout method and setting conditions of pre-signal, Deng et al. [24] studied the appropriate entrance lane layout method and setting conditions for setting bus advance area to achieve bus priority and proved that the setting of bus advance area can significantly reduce the average delay of buses and social vehicles. Wang [25] considered the random arrival of vehicles, constructed a timing scheme solution model with the objective of maximizing the capacity, and proposed a pre-signal dynamic control method based on real-time traffic demand. Wang [26] analyzed the working principle of pre-signal at the entrance lane from the aspects of the composition of traffic flow and the layout mode of pre-signal, proposed the setting conditions of pre-signal, and provided a method to determine the sequence of setting pre-signal at each entrance lane. Zhao et al. [27] used the principle of pre-signal setting to dynamically set some of the entrance lanes as inlet lanes or outlet lanes, established an optimization model of optimal intersection geometric layout and signal timing, and proposed a new type of intersection with a working zone to improve the actual capacity of the intersection. Liu [28] introduced environmental factors into the pre-signal optimization model and studied the extent of the effect of different green light durations on emissions by comparing the vehicle emissions before and after setting the pre-signal, which supported the study of pre-signal.
From the results of domestic and foreign related work on pre-signal mechanisms, it is clear that although the pre-signal mechanism can reduce bus delay, it is also more likely to increase social vehicle delay. The pre-signal mechanism has been practically applied for many years in countries such as the UK and Switzerland, but in practice, it still requires exploratory adjustments according to local traffic rules, traffic flow characteristics, and road characteristics. The driving rules of domestic intersections, the behavioral characteristics of drivers and pedestrians, and the structure of road traffic flow are different from those of foreign countries, so it is difficult to learn from and reuse the existing pre-signal setting schemes abroad. Also, road environment factors such as the distance between the pre-signal and the upstream bus stop, the installation location of the monitor, and the length of the bus advance area need further study.
In addition, a computational formula is applied in the related literature [19] to assign a constant value to the main and pre-signal phase difference. However, for the green phase difference, if it is simply calculated by the length of the bus advance area, it may cause social vehicles to enter the bus advance area prematurely, clashing with queuing buses and causing secondary parking problems, thus increasing start-up delay and energy loss. Therefore, Li [29] improved the formula for calculating the green phase difference by calculating the total length of the bus queue in the bus advance area based on the arrival rate of buses during the red of the main signal, the length of a bus, the safe vehicle distance, the proportion of pre-signal-controlled buses to total buses, and red duration of the main signal, and then make a difference with the length of the bus advance area to calculate the expected travel distance of social vehicles, and dividing the travel distance with the average vehicle speed to obtain the green phase difference. As for the red phase difference, a social vehicle is assumed to drive into the bus advance area just when the pre-signal turns red and the main signal just turns red when it drives through the intersection, then calculated the travel time of the vehicle and set it as the red phase difference. However, such a setup does not take into account the randomness of vehicle arrivals, and the result does not adjust adaptively to the real-time changing traffic characteristics.
There is a lack of targeted research work on the problem of adaptive control of pre-signals using real-time characteristics of traffic flow. The problem focuses on the adaptive setting of the main and pre-signal phase difference, which is very similar to the problem of cooperative control of multiple intersection signals. There have been a number of studies on multi-signal cooperative control problems based on deep reinforcement learning, deep neural networks, and other artificial intelligence methods. Wu et al. [30] set different priorities to distinguish between buses and social vehicles and proposed a multi-agent recursive depth deterministic policy gradient algorithm for signal control research. Nishi et al. [31] used stacked neural network layers to automatically extract traffic flow characteristics between intersections and proposed algorithms that can control a wider range of traffic flow variations with shorter average waiting times. Kumar et al. [32] used real-time traffic information as input to achieve autonomous switching of fair mode, priority mode and emergency mode, and proposed an intelligent signal control system that can dynamically adjust the signal duration. Shabestray et al. [33] abandoned the need to extract features in state space and directly applied the available information obtained from highly detailed traffic sensors to propose a multimodal intelligent depth signal control system to improve the travel time of vehicles and passengers. Based on the idea of multiple intersection signal cooperative control, this study realizes pre-signal adaptive control based on deep reinforcement learning algorithm. Zeng et al. [34] combined Deep Q-Network and recurrent neural network to train to generate a traffic signal control strategy that reduced the average vehicle delay. Li et al. [35] build deep neural networks to model changes in control behavior and system state to adjust signal timing strategies. Gu et al. [36] proposed double networks algorithm for DDQN to control the traffic flow in different directions, which guaranteed the fixed phase order and improved the traffic capacity.
Model setting
In the study of deep reinforcement learning-based pre-signal control, the pre-signal is defined as an agent, and the entrance lane with pre-signal is configured as an environment in the traffic network. At any moment t, the state \(s_t\) of the current environment is captured from the environment, and the time difference when the pre-signal turns green and red earlier than the main signal, i.e., action \(a_t\), is selected and executed. By the next moment \(t+1\), the environment that has executed the action \(a_t\) generates a new state \(s_{t+1}\), and at the same time, the agent receives a reward \(r_t\) for evaluating the merit of the action. The flow of interaction between the agent and the environment is shown in Fig. 2.

Agent and environment interaction diagram
The adaptive optimal control of the pre-signal is equivalent to the problem of how an agent selects and performs multi-step actions to obtain the maximum cumulative reward value and then evaluates the effectiveness of the actions performed by the agent based on the reward value to continuously optimize the network model. This optimization process can be defined as a Markovian Decision Process, represented by a five-tuple \(<S, A, P, R, \gamma>\). Where:
-
S denotes the set of states of the entrance lane environment. \(s_t\in S\) denotes the vehicle distribution of the entrance lane at time t.
-
A denotes the set of actions that can be executed by the agent. \(a_t\in A\) denotes the specific action executed by the agent at time t.
-
P denotes the probability of state transfer. The state of the interactive system at time t is \(s_t\), and the action executed by the agent is \(a_t\), then it will switch to the next state \(s_{t+1}\) based on the state transfer probability of \(P(s_{t+1} \mid s_t,a_t)\).
-
R denotes the reward value. \(r_t\) denotes the immediate reward value obtained by the agent after executing the action \(a_t\).
-
\(\gamma \) denotes the reward decay factor. \(\gamma \) indicates the importance of future rewards relative to current rewards.
Deep reinforcement learning algorithms seek optimal policies by adjusting their policy choices through the state of the environment, the action chosen by the agent, and the reward obtained after executing the action. In the study of adaptive optimal control of pre-signal, state, action, and reward, need to be set up specifically.
State setting
Referring to the setting scenarios of most pre-signals, the pre-signal is firstly considered to be set on a single entrance lane. It is assumed that the road intersection consists of four entrance lanes in the east, west, south, and north directions, and the entrance lane in each direction contains four motor vehicle lanes, the outermost of which is a bus-only lane, as shown in Fig. 3. The classical reinforcement learning algorithm takes the queue length and total traffic flow of each entrance lane as the state input, but it can only describe the traffic network state with coarse granularity, which is not conducive to specifically portraying the difference between buses and social vehicles and cannot reflect the special characteristics of buses.

DTSE schematic diagram
Based on the idea of bus priority, the state setting in this paper uses discrete traffic state encoding (DTSE) [37], which divides the intersection entrance lane into multiple cells and counts the vehicle information in the cells as the state input. Using the DTSE method can accurately represent real-time location and vehicle speed information of buses and social vehicles, thus enabling real-time and specific descriptions of the state of the traffic network. As shown in Fig. 3, the DTSE method cuts the area consisting of the entrance lane bus advance area and a certain distance upstream into multiple cells according to a fixed length. To determine whether there are buses, social vehicles in each cell: no vehicles is represented by “0”; the presence of a social vehicle is represented by “1”; the presence of a bus is represented by “10” (the importance of buses is 10 times that of social vehicles), this constitutes the vehicle position matrix. At the same time, the speed matrix is constructed based on the speed of the vehicle, which corresponds to the position matrix: the presence of the vehicle is represented by the specific speed value (unit: km/h), and no vehicle is represented by “0”.
Action setting
In the traffic network with a pre-signal mechanism, the pre-signal as an agent selects the optimal action by sensing the current traffic state, determining whether to activate the pre-signal, and deciding the duration of the corresponding phase. In order to more closely match the actual road driving requirements, the original periodic timing control scheme is used for the main signal in this study, while the duration of the pre-signal meets the minimum green light setting [6]. In the signal setting of this paper, the timing scheme of the pre-signal contains 2 cases: the first one is the green phase difference, i.e., the length of time that the pre-signal turns green earlier than the main signal. When the remaining time from the end of the main signal red is \(t_g\) (the green phase difference decision moment), the action space set of the pre-signal is \(\left\{ t_g-p_g+1, ..., t_{g}-1, t_g\right\} \), which means the green phase difference of the pre-signal can be set as an integer from \(t_g-p_g+1\) to \(t_g\), where \(p_g\) is set according to the minimum green light duration. The second one is the red phase difference, i.e., the length of time that the pre-signal turns red earlier than the main signal. When the remaining time from the end of the main signal green is \(t_r\) (the red phase difference decision moment), the action space set of the pre-signal is \(\left\{ t_r-p_r+1, ..., t_{r}-1, t_r\right\} \), which means the red phase difference of the pre-signal can be set as an integer between \(t_r-p_r+1\) and \(t_r\), where \(p_r\) is set according to the maximum green light duration. In order to facilitate the comparison of the pre-signal timing effects of different methods, an alert message is set before the pre-signal transition to ensure traffic safety during the transition phase. Based on the above main signal phase sequence and pre-signal action set, the agent selects the optimal action, thus realizing the real-time optimal control of the pre-signal.
Reward setting
In traffic networks using deep reinforcement learning algorithms, rewards are set to provide feedback to the algorithm on the results after the execution of an action in order to evaluate the chosen action and thus have an impact on the next round of action selection by the agent. Appropriate reward settings can positively affect the learning process and motivate the agent to learn the correct and optimal coordination strategies. In this study, the reward setting is also divided into two cases according to the timing scheme: the first one is the reward for green phase difference, with the purpose of improving the utilization rate of the bus advance area and protecting the speed of social vehicles at the same time, by calculating the average speed of social vehicles \(s_{avg}\), the number of social vehicles in the bus advance area \(n_{forward\_vehicle}\), the number of stops \(m_{speed0}\) and the space utilization rate of the bus advance area \(p_{distance}\), so as to evaluate the reasonableness of the green phase difference setting, and such reward function \(r_{green}\) is shown in Eq. 1. The second one is the red phase difference with the purpose of emptying the vehicles in the waiting area by calculating the number of residual social vehicles in the bus advance area when the main signal ends red \(n_{social\_vehicle}\) and the duration after emptying the social vehicles \(t_{no\_car\_time}\), so as to evaluate the reasonableness of the red phase difference setting, and such reward function \(r_{red}\) is shown in Eq. 2. Where \(k_{1}\), \(k_{2}\), \(k_{3}\), \(k_{4}\), and \(k_{5}\) are the weight parameters corresponding to the variables, setting based on the experimental tuning parameters.

Algorithm structure diagram of DDQN
Pre-signal mechanism of HES-DDQN
Double deep Q network
DDQN belongs to the classical algorithm of temporal differencing like DQN [38]. DDQN inherits the two Q-network structures of the original DQN algorithm. And the problem of overestimation of DQN is mitigated by decoupling the selection of target actions and the calculation of target Q values. The structure that constitutes the DDQN algorithm includes the main network and the target network that evaluate the state-action and the replay buffer that stores the experience samples. DDQN trains the agent by the historical experience samples, which makes the agent better at making decisions about the action. The algorithm structure of DDQN is shown in Fig. 4.
Pre-signal mechanism model based on DDQN
The main and pre-signal phase difference calculation method proposed in the related literature [29] uses only the predicted total bus length to participate in the calculation, while the buses queued in the bus advance area during the main signal red are likely to be scattered in all lanes, which will have a large error, resulting in a waste of space in the bus advance area and a waste of time for the main signal green. Therefore, this paper constructs the deep reinforcement learning model HES-DDQN for the pre-signal mechanism and investigates the DDQN algorithm based on the Hybrid Exploration Strategy to realize the adaptive control of the green phase difference and the red phase difference according to the setting method of pre-signal, the traffic state of the urban road and the timing scheme of the main signal, as shown in Fig. 5.

HES-DDQN pre-signal timing model
In this model, the Q values corresponding to each phase difference are first obtained by fully connected operation of the position and speed information of the vehicles on the entrance lane. A target network with the same internal structure is constructed to assist the training of the main network to avoid repeated oscillations of the output Q values. At the same time, an experience replay pool is used to store the rewards and state updates of the interaction with the environment after each selected action. A certain amount of training samples will be taken from the experience replay pool each time to calculate the late target values and continuously optimize the pre-signal model, thus improving the strategy for calculating the green phase difference and the red phase difference.
Improved DDQN algorithm based on hybrid exploration strategy
The trade-off between exploration and exploitation is one of the challenges of reinforcement learning. Exploration causes the agent to select new actions for further improvement of the strategy, while exploitation causes the agent to act based on historical experience for the purpose of maximizing the cumulative reward.
Hybrid exploration strategies based on \(\epsilon \)-greedy and the Boltzmann strategy
The \(\epsilon \)-greedy strategy [39] is commonly used in deep reinforcement learning to deal with the exploration-exploitation trade-off problem [40]. This strategy uses a linear approach to adjust the exploration factor by assigning a higher sampling probability to actions with a larger corresponding value function, which is shown in Eq. 3.
For non-greedy actions, the \(\epsilon \)-greedy strategy treats their probabilities uniformly. However, different non-greedy actions still have different effects on the model training effect, where the actions with large corresponding value functions should be sampled with a higher probability than those with small corresponding value functions. In contrast, the Boltzmann strategy [41] softens the probability of action sampling \(p(a_i)\) according to the corresponding value function, i.e., the probability of a non-greedy action being selected is proportional to its corresponding action value function, which is calculated as shown in Eq. 4.
where K denotes the number of actions in the action set and \(\tau \) is the temperature regulation parameter. In order to avoid the pre-signal decision from falling into suboptimal or locally optimal strategies, a hybrid strategy combining \(\epsilon \)-greedy and Boltzmann strategy is used to achieve a corresponding improvement based on the DDQN algorithm. First, \(\epsilon \) is defined as a greedy factor of 0.9 gradually decreasing to 0.01, and \(\zeta \) is set as the threshold of policy selection. Then, a value q between [0,1] is randomly generated, and if \( q \le \epsilon \), the pre-signal mechanism adopts a random action; if \(q > \epsilon \) and \(\epsilon \le \zeta \), the pre-signal mechanism adopts the greedy strategy for exploration; if \(q > \epsilon \) and \(\epsilon > \zeta \), the pre-signal mechanism adopts the Boltzmann strategy for exploration. The formula for the hybrid exploration strategy is shown in Eq. 5.
The improved hybrid exploration strategy incorporates the respective advantages of the \(\epsilon \)-greedy strategy and Boltzmann, allowing the value of \(\epsilon \) to gradually shrink with time while adding greater explorability to the process of greedy action selection. The exploratory nature is enhanced by using random actions with higher probability at the beginning of the model training, and the chance of executing the optimal action is increased at the end of the model training to promote convergence of the model training. This approach improves on the traditional exploration approach by using the magnitude of the value function corresponding to different actions to calculate the probability of each action selection, which entails a small computational cost and can ensure a more adequate exploration of the environment and actions by the agent.
Pre-signal mechanism model based on HES-DDQN not only calculates the total length of buses in the bus advance area in real-time when determining the green phase difference but also takes into account the acceleration and speed difference of the remaining social vehicles in the previous cycle and the social vehicles in front of the pre-stop line. When determining the red phase difference, it not only calculates the number of social vehicles remaining in the bus advance area and not driving through the intersection during the green period of the main signal but also considers the invalid time after the social vehicles have emptied at the same time, which helps to improve the accuracy and precision of the algorithm by obtaining the real-time state of the road and the real-time speed of the vehicles.
The pre-signal control scheme based on HES-DDQN algorithm obtains real-time road status and real-time vehicle speed through discrete traffic coding, uses a hybrid exploration strategy to obtain appropriate action execution, and generates a reward function based on factors such as social vehicles stranded in the waiting area and the number of stops. The agent continuously interacts with the environment under more extensive exploration, while adjusting the strategy based on the guidance of the reward value, and gradually masters a more effective signal control method, which helps to improve the accuracy and precision of the intelligent algorithm applied to signal control.
The HES-DDQN algorithm pseudocode
The pseudo-code of the Adaptive Timing Mechanism for Urban Traffic Pre-signal Based on Hybrid Exploration Strategy to Improve DDQN is shown in Algorithm 1.

Experiment
Simulation setting
We set up two sets of simulation experiments: the south-to-north inlet road of the road at the intersection of Wenling Road-Tumen Street in Quanzhou City, Fujian Province as the simulation object, and the traffic flow data of 17:30–18:30 on October 21, 2018 were selected; the southwest inlet road at the intersection of Ningxi Road and Xingye Road in Zhuhai, Guangdong Province as the simulation object, and the traffic flow data of 14:00–15:00 on March 26, 2015 were selected. The social traffic flow and bus flow through the above two intersections are used as input data for the simulation, as shown in Table 1.
A pre-signal is set up 40 m before the main signal. The 40-meter bus advance area and the 100-m section upstream of the pre-signal are used as monitoring objects. The length of the cell is 5 m. The main signal original timing scheme period is 140 s for the Quanzhou data set and 136 s for the Zhuhai data set, as shown in Fig. 6 for the specific phase.

Experimental phase schematic diagram
Evaluation indicator
The indicators used in the experiment to verify the effectiveness of HES-DDQN mainly include the average vehicle delay, average queue length, and the average number of social vehicle stopping times. The relevant definitions are shown in Eq. 6.
where \(t_{delay\_avg}\) denotes the average vehicle delay, which is the average of all vehicle delay within the observed section compared to the ideal trip condition (no signal control, no other vehicle influence). \(l_{queue\_avg}\) denotes the average queue length, which refers to the average length formed by the vehicles satisfying the queue state in the upstream section of the bus advance area, where whether the vehicles are in the queue state is measured by the vehicle speed (the speed interval is [0, 5 km/h]), and T denotes the simulation duration of the experiment. \(m_{stop\_avg}\) indicates the average number of stops, which is the average of the number of stops of all social vehicles in the bus advance area.
Experimental results and analysis
Experimental parameters and environmental settings
The initial parameters of the HES-DDQN pre-signal timing model are shown in Table 2. In the initial stage of simulation, an experience replay operation is performed first, and the training data generated by this process are not included in the final experimental results.
The experiments use the Vissim 4.30 traffic simulation platform which has convenient visualization components and well-established interfaces. Acquiring and manipulating objects from road network files via win32com. The experiments are conducted using Python 3.7 on Tensoeflow-gpu2.4.0 deep learning framework for training learning of reinforcement learning models. The equipment used is configured with an Intel Core i7-11700 CPU processor, a GeForce RTX 3060 12 GB graphics card, and DDR4 3200 MHz 32 GB RAM.
In the definition of the network model, the network structure of the evaluation network and the target network of HES-DDQN consists of four fully connected layers. The first hidden layer consists of a fully connected layer of 512 neurons, the second hidden layer consists of a fully connected layer of 256 neurons, and the third hidden layer consists of a fully connected layer of 64 neurons, and the activation functions of the first three layers are ReLU. The last layer is the output layer, and the number of neurons is the number of action sets. The error function of the network model is the mean square error, and the optimizer is Adam, which combines the advantages of AdaGrad and RMSProp. Adam uses the same learning rate for each parameter and adapts independently as learning proceeds. The error function used is the mean-squared error.
Analysis of experimental results
In order to verify the effectiveness of the HES-DDQN pre-signal timing model for pre-signal control, this paper conducts multiple sets of comparison experiments with the mainstream DQN, Dueling-DQN, the original DDQN algorithm, and the formula-based pre-signal mechanism under the conditions of equal parameter settings and analyzes the experimental effects of the improved algorithm according to the defined evaluation indicators. Considering that the deep reinforcement learning algorithm has not yet converged in the early stage of the model experiments, the reference value of the experimental results is not high, while the model has better convergence and stability in the late stage of the experiments. Therefore, comparing the data in the later stages of the model experiment, the comparison of the results of the second 100 rounds (i.e., rounds 1101 to 1200) of the Quanzhou and Zhuhai dataset experiments are shown in Figs. 7 and 8, Tables 3 and 4.


Experimental results of HES-DDQN pre-signal timing model for the Quanzhou data set


Experimental results of HES-DDQN pre-signal timing model for the Zhuhai dataset
From the figures and tables, it can be seen that compared with DQN, Dueling-DQN, and the original DDQN algorithm, the HES-DDQN pre-signal timing model proposed in this paper is optimal in the evaluation of straight bus delay, social vehicle delay, social vehicle queue length and stopping times indicators. In the experiment of the Quanzhou dataset, the social vehicle delay and social vehicle queue length average metrics improved by 3.8\(\%\) and 3.0\(\%\) compared to the suboptimal DDQN algorithm. In the Zhuhai dataset, the social vehicle delay is improved by 4.8\(\%\), and the social vehicle queue length is improved by 7.3\(\%\) compared to the suboptimal DDQN algorithm. As the above two sets of experimental results demonstrate, HES-DDQN applied to the pre-signal mechanism can not only improve the efficiency of bus traffic but also minimize the impact on social vehicles. However, it is also concluded from Table 3 and the comparison graph of left-turn bus delays that none of the above algorithms achieve stable optimization for both left-turn bus delays, and social vehicle stopping times indicators. Although HES-DDQN can effectively improve the efficiency of left-turning buses in most cases as in the Zhuhai dataset, there is a chance that the optimization is not as effective as in the Quanzhou dataset. The main reason for such experimental results is that there is a conflict between straight-ahead social vehicles and left-turn buses in the bus advance area, which leads to left-turn buses failing to pass the main signal in time and forcing social vehicles to stop. This problem can be solved by appropriately extending the green time of the main signal so that buses can pass smoothly, and it is also a problem that needs to be solved in subsequent research work.
Conclusion and prospect
The rapid increase of social vehicles has aggravated the congestion of urban traffic, and the pre-signal mechanism for bus priority can effectively relieve the road traffic pressure. In response to the method of calculating the main and pre-signal phase difference using the formula method in previous literature, this paper proposes a HES-DDQN pre-signal timing model using the deep reinforcement learning method based on its shortcomings to realize the adaptive optimal control of pre-signal and better allocate time and space priority for buses. HES-DDQN combines the \(\epsilon \)-greedy strategy with the Boltzmann strategy and employs a hybrid exploration strategy. Through multiple comparison experiments with mainstream DQN, Dueling-DQN, original DDQN algorithm, and pre-signal mechanism based on formula method, we are able to find that HES-DDQN achieves better results in terms of social vehicle delay, queue length, and number of stops.
However, the experimental results show that there are still driving conflicts between straight-ahead social vehicles and left-turn buses in the bus advance area, leading to bus delay and an increase in the number of social vehicle stopping times. Therefore, in the next step of work, the coordinated linkage control of the intersection main signal and pre-signal will be focused on. In this paper, only the pre-signal setting of a single inlet lane is considered for the time being, and the subsequent work should further consider applying the pre-signal to all inlet lanes of a single intersection. And the pre-signal will be combined with the main signal for coordinated control to further improve the efficiency of bus priority traffic. In addition, subsequent research should consider the behavioral characteristics of pedestrians and non-motorized vehicles and construct scenarios that are closer to the actual road conditions to improve the practicality of the algorithm.
References
Seredynski M, Laskaris G, Viti F (2019) Analysis of cooperative bus priority at traffic signals. IEEE Trans Intell Transp Syst 21(5):1929–1940
Gu W, Mei Y, Chen H, Xuan Y, Luo X (2021) An integrated intersection design for promoting bus and car traffic. Transp Res Part C: Emerg Technol 128:103211
Anderson P, Daganzo CF (2020) Effect of transit signal priority on bus service reliability. Transp Res Part B: Methodol 132:2–14
Russo A, Adler MW, van Ommeren JN (2022) Dedicated bus lanes, bus speed and traffic congestion in rome. Transp Res Part A: Policy Pract 160:298–310
Seman LO, Koehler LA, Camponogara E, Kraus W Jr (2020) Integrated headway and bus priority control in transit corridors with bidirectional lane segments. Transp Res Part C: Emerg Technol 111:114–134
Wu J, Hounsell N (1998) Bus priority using pre-signals. Transp Res Part A: Policy Pract 32(8):563–583
Oakes J, Metzger D (1995) Park view pre-signals in uxbridge road, ealing. Traffic engineering & control 36(2)
Benerrlli DA (2005) Bus pre-signals assessment and design guidance. Transit Cooper Res Program Transp Res Board Natl Res Council 15(2):127–138
Guler SI, Menendez M (2013) Empirical evaluation of bus and car delays at pre-signals. In: Swiss Transport Research Conference (STRC), Ascona, Switzerland, pp. 1–11. SPIE
Guler SI, Menendez M (2014) Analytical formulation and empirical evaluation of pre-signals for bus priority. Transp Res Part B: Methodol 64:41–53
Guler SI, Menendez M (2014) Evaluation of presignals at oversaturated signalized intersections. Transp Res Rec 2418(1):11–19
Guler SI, Menendez M (2015) Pre-signals for bus priority: basic guidelines for implementation. Public Transport 7(3):339–354
He H, Guler SI, Menendez M (2016) Adaptive control algorithm to provide bus priority with a pre-signal. Transportation Research Part C: Emerging Technologies 64:28–44
Bhattacharyya K, Maitra B, Boltze M (2019) Implementation of bus priority with queue jump lane and pre-signal at urban intersections with mixed traffic operations: lessons learned? Transp Res Rec 2673(3):646–657
Zhao J, Ma W, Xu H (2017) Increasing the capacity of the intersection downstream of the freeway off-ramp using presignals. Computer-Aided Civil and Infrastructure Engineering 32(8):674–690
Li Y, Nan S, Gong X, Ma R (2019) A geometric design method for intersections with pre-signal systems using a phase swap sorting strategy. PLoS ONE 14(5):0217741
Bie Y, Liu Z, Wang H (2020) Integrating bus priority and presignal method at signalized intersection: Algorithm development and evaluation. Journal of Transportation Engineering, Part A: Systems 146(6):04020044
Zhang Y (2020) An adaptive pre-signal setting to provide bus priority under a coordinated traffic-responsive network. In: 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), pp. 1–6. IEEE
Jia L, Mei-Lan S, Han-Hui H (2007) Study on bus priority using pre-signal based on traffic simulation. Journal of Hunan University Natural Sciences(in Chinese) 34(11):20–24
Wu J, Liu P, Qin X, Zhou H, Yang Z (2019) Developing an actuated signal control strategy to improve the operations of contraflow left-turn lane design at signalized intersections. Transportation research part C: emerging technologies 104:53–65
Shi A, Lang S, Jian W, Ya-qing W, Xiao-wei H (2020) Main and pre-signal control scheme optimization of turning left by using bus lanes. China Journal of Highway and Transport(in Chinese) 33(4):115
Jing X (2020) Research on priority control method of bus signal at intersection based on pre-signal. Master’s thesis, Chongqing Jiaotong University
Huang J, Hu M-B, Jiang R, Li M (2018) Effect of pre-signals in a manhattan-like urban traffic network. Physica A 503:71–85
Deng M, Chen J, Yao Y (2020) Intersection signal control based on bus priority and comprehensive approach area. Journal of Chongqing Jiaotong University(Natural Science)(in Chinese) 39(8):36–44
Wang B, Wang Y (2020) Simulation of intersection signal optimization control method based on pre-signal. Computer Simulation(in Chinese) 3
Wang Y, Zhang W (2019) Application of pre-signal in subright bus lane. China Transportation Review(in Chinese), 74–79
Zhao J, Kigen KK, Xia X (2022) An alternative design for traffic intersections with work zones by using pre-signals. Journal of Intelligent Transportation Systems 26(2):168–182
Liu Y (2021) Research on optimization of bus priority pre-signal control. In: Fifth International Conference on Traffic Engineering and Transportation System (ICTETS 2021), vol. 12058, pp. 451–455. SPIE
Li Y (2017) Research of intended bus priority approach based pre-signal adaptive control system. Master’s thesis, Chang’an University
Wu T, Zhou P, Liu K, Yuan Y, Wang X, Huang H, Wu DO (2020) Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks. IEEE Trans Veh Technol 69(8):8243–8256
Nishi T, Otaki K, Hayakawa K, Yoshimura T (2018) Traffic signal control based on reinforcement learning with graph convolutional neural nets. In: 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pp. 877–883. IEEE
Kumar N, Rahman SS, Dhakad N (2020) Fuzzy inference enabled deep reinforcement learning-based traffic light control for intelligent transportation system. IEEE Trans Intell Transp Syst 22(8):4919–4928
Shabestray SMA, Abdulhai B (2019) Multimodal intelligent deep (mind) traffic signal controller. In: 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pp. 4532–4539. IEEE
Zeng J, Hu J, Zhang Y (2018) Adaptive traffic signal control with deep recurrent q-learning. In: 2018 IEEE Intelligent Vehicles Symposium (IV), pp. 1215–1220. IEEE
Li L, Lv Y, Wang F-Y (2016) Traffic signal timing via deep reinforcement learning. IEEE/CAA Journal of Automatica Sinica 3(3):247–254
Gu J, Fang Y, Sheng Z, Wen P (2020) Double deep q-network with a dual-agent for traffic signal control. Appl Sci 10(5):1622
Zhang R, Ishikawa A, Wang W, Striner B, Tonguz OK (2020) Using reinforcement learning with partial vehicle detection for intelligent traffic signal control. IEEE Trans Intell Transp Syst 22(1):404–415
Van Hasselt H, Guez A, Silver D (2016) Deep reinforcement learning with double q-learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30
dos Santos Mignon A, da Rocha RLdA (2017) An adaptive implementation of \(\varepsilon \)-greedy in reinforcement learning. Procedia Computer Science 109:1146–1151
Lipton Z, Li X, Gao J, Li L, Ahmed F, Deng L (2018) Bbq-networks: Efficient exploration in deep reinforcement learning for task-oriented dialogue systems. Proceedings of the AAAI Conference on Artificial Intelligence 32(1):5237–5244
Cesa-Bianchi N, Gentile C, Lugosi G, Neu G (2017) Boltzmann exploration done right. Adv Neural Inf Process Syst 30:355–362
Acknowledgements
This work was supported by the Fujian Province Science and Technology Plan under Grant No. 2020H0016, National Natural Science Foundation of China under Grant No. 61802133, National Natural Science Foundation of China Grant No. 61871196.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, M., Zhang, H., Chen, Y. et al. An adaptive timing mechanism for urban traffic pre-signal based on hybrid exploration strategy to improve double deep Q network. Complex Intell. Syst. 9, 2129–2145 (2023). https://doi.org/10.1007/s40747-022-00903-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00903-6