
Abstract
Cultural awareness, when applied to Intelligent Learning Environments (ILEs), contours the overall appearance, behaviour, and content used in these systems through the use of culturally-relevant student data and information. In most cases, these adaptations are system-initiated with little to no consideration given to student-initiated control over the extent of cultural-awareness being used. This paper examines some of the issues relevant to these challenges through the development of the ICON (Instructional Cultural cONtextualisation) system. The paper explores computational approaches for modelling the diversity of students within subcultures, and the necessary semantic formalisms for representing and reasoning about cultural backgrounds at an appropriate level of granularity for ILEs. The paper investigates how student-initiated control of dynamic cultural adaptation of educational content can be achieved in ILEs, and examines the effects of cultural variations of language formality and contextualisation on student preferences for different types of educational content. Evaluations revealed preliminary insight into quantifiable thresholds at which student perception for specific types of culturally-contextualised content vary. The findings further support the notion put forth in the paper that student-initiated control of cultural contextualisation should be featured in ILEs aiming to cater for diverse groups of students.
Similar content being viewed by others

Introduction
Intelligent Learning Environments (ILEs) are specialised educational systems which aim to produce interactive and adaptive learning experiences that are customised to students using various Artificial Intelligence techniques (Brusilovsky 1994; Biswas et al. 2001). Cultural-awareness, when applied to ILEs, refers to the use of culturally-relevant data and information that shape the overall appearance, behaviour and purpose of these learning environments (Blanchard & Ogan 2010). More specifically, an ILE's layout, instructional methods, and educational content are intended to be customised to suit a student's cultural background. With many culturally-aware ILEs, students are not typically given a choice of whether they want their cultural backgrounds to be factored into their learning experiences. On one hand, they are offered educational systems that are described as internationalised or devoid of culturally-charged references and design elements. On the other hand, students are offered educational systems which incorporate features that are considered to be culturally-appropriate based on national-level categorisations and stereotypes.
The problem with the former case is that despite careful attention to the goal of producing a culturally-neutral ILE, the design of an ILE can still be culturally-biased by designers and developers (Rehm 2011). For example, a developer might, when creating educational content for an ILE, select a particular set of images or use metaphors that he/she identifies with based inadvertently on his/her cultural background or preferences. The cultural viewpoints and references which are introduced into the ILE as a result, can then alienate or confuse students who do not share the same values or perspectives. The notion of cultural-neutrality with respect to educational content and ILEs is also problematic since teaching and learning tend to rely on rich contexts (examples, analogies, scenarios) in order to create learning experiences that students can relate to. This leads to the latter case which can suffer from similar risks if designers misinterpret or overly generalise the cultural backgrounds of the students when attempting to relate to students on a cultural level. Even if this is done correctly, students may or may not prefer to have certain aspects of their background factored into the learning process. In addition, a student's preference for cultural-awareness may fluctuate based on their mood or learning needs.
Giving students some control over how their cultural backgrounds are used and represented in ILEs would be a first step towards tackling these issues. In this paper we therefore investigate the use of computational techniques for student-initiated control in addition to system-initiated control of culturally-aware decision-making and adaptation of educational content. The paper focuses on the following research question: assuming that students are given individualised control over system-initiated variations of the cultural adaptations performed in an ILE, which variations do students prefer for specific types of educational content specifically problem descriptions, images, instructional feedback, and hints. The remainder of the paper is organised as follows. The next section examines some of the theoretical definitions of culture, and sets the philosophical frame of reference taken in the paper. A review of work related to the area of dynamic intracultural contextualisation is then undertaken in order to shed light on what has currently been achieved in the field. Next, a detailed description of the ICON (Instructional Cultural cONtextualisation) system is given which goes into the rationale behind the design choices that were made, outlines the system components, and discusses the reasoning strategies that were used. This is followed by a section that describes an example of how ICON makes culturally-aware decisions, performs reasoning, and how ICON was implemented in a practical ILE application called CRITS. Evaluation of the CRITS application is then discussed followed by the results obtained and the data trends that were observed. The paper concludes with a summary of the research contributions, and plans for further research.
Cultural Contextualisations and Variations
There are several perspectives for defining culture when grounding the theoretical foundations of culturally-aware ILEs. According to Rehm (2011), two perspectives have potential for producing computationally viable models of culture. The first considers culture as a set of commonly shared norms, values, and meanings where differences and similarities in behaviour can be used to identify members of a cultural group. This is the most commonly adopted definition as evidenced by the widespread use of the Hofstede (2001) and Hall (1966) theoretical models of culture which list several high-level characteristics that they believe account for differences in behaviour, preferences, and perceptions across cultures. The second perspective considers culture as a layered identity that has been constructed, distributed, and assimilated over time through interactions between individuals and groups (Henrich & McElreath 2007; Kashima & Gelfand 2012). We adopt this perspective in the paper because it is more flexible for specifying different levels of cultural granularity, and accommodates multicultural differences in a less restrictive manner than a set of national dimensions as in the former perspective. The layered identity perspective also lends itself more easily towards linking cultural influences and factors that act on a student, with the shared meanings and familiar representations that the student perceives as cultural.
Shared meanings, also called cultural conceptualisations (Sharifian 2003), result from human cognitive processes of categorising observations and experiences under familiar conceptual categories. These categories are intrinsically linked to language which conveys cultural knowledge and allows individuals to understand each other's perspectives when communicating (Allwood 1985; Kraus & Chiu 1998). Consider the situation where a teacher uses a linguistic or conceptual reference during an instructional activity with a student. The student's interpretation of the reference would be influenced by how familiar he/she is with the reference, or how recently the student has encountered the reference. Hong et al. (2000) describe this as accessibility, where a reference that has high accessibility can be easily understood by a student on a cultural level, and can activate cognitive processes that endorse particular cultural values, behaviour, or attitudes. The use of these linguistic or conceptual references that have cultural roots is defined in this paper as a cultural contextualisation. When applied to ILEs, cultural contextualisation refers to the process of integrating one or more cultural conceptualisations into aspects of a digital learning environment such as its appearance, behaviour, or instructional content.
Intercultural Versus Intracultural Perspectives, and Static versus Dynamic Approaches
Cultural conceptualisations can be studied using two perspectives namely intercultural and intracultural perspectives. In order to understand the differences between these two perspectives, the notion of a cultural group needs to be defined. According to Blanchard et al. (2011), a cultural group is a collection of individuals with shared beliefs, characteristics, and values who interact and live within a society. Over time, group-level interactions produce cultural conceptualisations which reflect these shared beliefs, characteristics, and values. However, cultural variations or differences can exist across different cultural groups. These variations often have linguistic roots that reflect the cognitive divergence in these groups with respect to particular cultural conceptualisations. This means that aspects of a cultural conceptualisation may differ across cultural groups in terms of linguistic references, physical manifestation or appearance, socio-cultural perception, and more importantly usage in educational contexts.
An intercultural perspective considers group-level cultural variations across nations, whereas an intracultural perspective focuses on cultural variations across individual subcultures within a society. Intercultural perspectives have been studied by many ILE researchers because of the collective differences that can be tracked across large scale cultural groups. Consequently, useful knowledge has emerged in the literature regarding intercultural variations in cultural conceptualisations. Intracultural perspectives have not been examined nearly as much. We posit that research into intracultural perspectives can be scaled up, and can help to clarify issues related to multicultural backgrounds which remains a challenge for intercultural research. This is possible because intracultural contextualisation requires study at a finer-level of granularity than intercultural perspectives, and this can lead to more meaningful capture of the nuances of multiculturalism.
Irrespective of whether an intracultural or intercultural perspective is taken, cultural contextualisation in ILEs necessitates the use of some sort of cultural conceptualisation. The process of integrating or applying said conceptualisations to a particular aspect of the ILE (its appearance, behaviour, or instructional content) can be carried out using a static or a dynamic approach. A static approach implies that all of the cultural features are determined and set in place before a student uses the ILE, and these features remain fixed while the ILE is in use. Naturally this approach offers students the least amount of control since options to turn off or adjust certain features of the cultural contextualisations are only available before the ILE is initialised. A dynamic approach has the opposite effect by accommodating real-time culturally-relevant changes in an ILE's features while the ILE is in use. This approach gives the students more control since their preferences for certain cultural features can be factored into the learning experience as they use the ILE. A dynamic approach can also provide real-time feedback regarding the acceptability of the cultural contextualisations, which can then be fed into the ILE for corrective adjustments as well as for modelling purposes.
Related Work
The study of student-initiated, intracultural contextualisation has not been taken up by many researchers (Mohammed & Mohan 2013b). So far, the focus has been on intercultural contextualisation with mostly system-initiated control of the extent and nature of the cultural adaptations. There are however a few examples of relevant work that relate to the area in general.
The most relevant work related to this paper is the ActiveMath system (Melis et al., 2009) which focuses on intercultural contextualisation of mathematics terminology such as notations, units, formulae, and theorem names. The system supports intercultural contextualisations for five target countries and follows a static approach. Here, students only have the option to change the values stored for the language they speak which in turn initiates contextualisation changes in the system. Melis et al. (2009) explain that the contextualisations conducted by ActiveMath go beyond literal translation of learning materials. For example, if the student was from Germany then translation of the content was done from English to German, along with conversion of the requisite formulae and units to suit the particular curriculum for German students. This was evident through the use of a domain ontology for relating the semantics of mathematics terminology to the five target countries. Melis et al. (2010) outlined further examples of culturally-aware adaptations that relate to instructional content. These include educational material selection and sequencing, context modification, and selection of presentation strategies and interaction styles. System feedback, whether instructional or emotive, was also considered to be a type of educational content.
For the most part, the instructional content in ActiveMath was not culturally contextualised fully, or rather micro-adapted culturally as described by the authors. Micro-adaptation is described by Melis et al. (2009) as the cultural variation of the content inside an instructional exercise. Cultural contextualisation, and indeed micro-adaptation to use their term, requires deeper semantic modelling of the cultural context of the exercises than was undertaken in ActiveMath. Cultural contextualisations were also not applied to tutorial dialogues and feedback given by ActiveMath, and this is one area where our approach goes further. Melis et al. (2009) however note the value of contextualising these aspects of an ILE, and have this as further work for the ActiveMath system. Overall, we concur with Melis et al. (2009) that ontological structures and Semantic Web techniques are necessary for achieving meaningful semantic contextualisations.
Another example of intercultural contextualisation is a plugin for the Assistment system described in (Vartak et al., 2008). Three countries are targeted by the plugin and a static approach is also used here. The plugin supports shallow syntactic contextualisation using variables and templates of preset insertion points in text-based content. These changes are however simple syntactic substitutions based on flags in the content, and do not really consider the student's cultural background fully. Here, countries are used as the sole criteria for cultural contextualisations. Most other work that relates to cultural modification of educational content merely translate content into different languages such as in the AdaptWeb system (Gasparini et al. 2011). This form of contextualisation is the most common. Blanchard (2009) describes how multimedia content is selected for students based on how well the content matches parameters of the student's cultural context. Here the contextualisation entails swapping in and out of images. Text-based content is not handled and this is where our approach goes further by handling images in addition to text.
The final examples of related work come from the area of virtual peers. ILE appearance changes are more prevalent in systems with virtual characters and enculturated conversational agents (ECAs). For example, Cassell (2009) studied children's acceptance, usage and recognition of African American Vernacular English (AAVE) using ECAs. Endrass et al. (2011) describe virtual characters with physical appearances adapted to suit particular cultural backgrounds. In Aylett et al. (2009), the ORIENT system features cultural characters modelled using agent technology who have culturally-enriched behaviour directed by emotive events. Finally, Finkelstein et al. (2013) investigate techniques for classifying a student's speech into AAVE or mainstream American English in a virtual peer. These research projects provide valuable insight into the requirements of dynamic cultural contextualisation since ECA adaptations are triggered by events. Furthermore, these real-time changes typically use parameterized or rule-based techniques which also shed light on how the computational approach described in this paper was devised.
Instructional Cultural Contextualisation (ICON) System
Architecture and Components
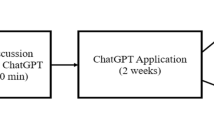
The ICON (Instructional Cultural cONtextualisation) system was designed to model conceptual and linguistic variations across the subcultures in a student's background, and generate relevant, meaningful cultural adaptations of educational content. The system's architecture is made up of four major components shown in Fig. 1: a Contextual Student Model, Contextual Element Repository, Cultural Linguistics Adapter, and a Controller. The Contextual Student Model, Contextual Element Repository, and Cultural Linguistics Adapter were patterned after some of the traditional components found in Intelligent Tutoring Systems (ITS) architecture, namely student models, domain models, and expert models. The Controller is essentially the interface between ICON and an ILE that uses ICON, and it functions as a bridge for data input and output.

ICON Architecture and Component Interaction
Contextual Student Model
The Contextual Student Model (CSM) was designed for storing data and knowledge about a student's cultural background, and for formalising inferences about socio-cultural factors and influences that impact upon the student. Twenty-four contextual dimensions were identified for the CSM based on the works of Blanchard (2012), Gasparini et al. (2011), and Reinecke et al. (2007). The dimensions fall into five categories that describe particular contextual groups: geographical groups, religious groups, ethnic groups, groups that share similar education levels, and groups that are familiar with particular physical environment settings and terrains (Mohammed & Mohan 2013c). The model collects detailed demographic data from the student, and limited demographic data from immediate socio-cultural groups that have important roles in the student's everyday life, such as family members. Lastly, national-level census data from neighbouring socio-cultural units that contribute toward the student's awareness of other cultural groups are also stored in the model. This data is supplemented with statistical data from the target country's national statistical office such as data on schools, locales, ethnic groups and their distributions, religious groups and their distributions, population distribution, economic activities across locales, and terrain and physical data for locales. All of the data is organised into an ontological structure, and is used to estimate the strength of a student's membership to specific cultural groups relevant to his/her background.
The justification for this approach comes from Sharifian (2003), and Henrich and McElreath (2007) who explain that interactions between members of cultural groups create a layered individual cultural identity over time. The strength of these interactions then determines which aspects of a culture an individual may commit to memory and/or assimilate into his/her identity eventually. The CSM therefore augments traditionally collected ITS data such as learner-related state, beliefs, and knowledge (Kay 2001) with details of a student's cultural identity and inferences regarding which cultural groups a student may and may not be familiar with. Sharifian (2011) defines this awareness or familiarity of cultural groups and by extension their respective cultural conceptualisations, as metacultural competence. Using a hybrid rule-based and algorithmic approach, the student's metacultural competence for each contextual group was measured as the weighted difference between the student's characteristics, and those of a contextual group. The weights used in CSM were based on the parent's level of influence and country level statistical data. This approach improves upon the one in (Blanchard 2009) by using weights that are directly related to the student's context rather than random assignment. This means that the CSM would strengthen a student's contextual group membership for a particular category, and weaken the same membership for another student. The weights in the model therefore change based on the significance of a dimension in a student's particular cultural context cluster.
The following is an example of one of the rules in the religious group rule base which uses the parental influence, specified by the student, to calculate the metacultural competence score for a particular religion R. The rule illustrates how two of the five dimensions (religious denomination of schools attended, religions of parents, and student's religion) specified for the religion contextual group play a role in the overall metacultural competence score for this group.
If (STUDENT S has PARENT P) and
(PARENT P has RELIGION R) and
(PARENT P has influence M on STUDENT S) and
(PARENT P has factor PF on RELIGIOUS_INFLUENCE RI)
Then (RELIGIOUS_INFLUENCE RI of RELIGION R is updated to RI + M*PF)
A student's membership to each of the five contextual groups was modelled on average by ten to fifteen rules depending on the complexity of the group. In this way, the CSM models specific subcultures that are relevant to the student's context (and educational content adaptation) and estimates how strongly the student might be associated with those subcultures.
Contextual Element Repository
As shown in Fig. 1, the Contextual Element Repository uses the estimates of a student's metacultural competence along with various pieces of cultural context data from the CSM. These are used to produce selections of educational resources or contextual elements from a repository. Here, contextual elements or resources refer to images that depict cultural conceptualisations (such as flora, fauna, places, artefacts) and linguistic references to these conceptualisations expressed as localised terms. The functionality of the Contextual Element Repository relies heavily on semantic metadata. An ontology called CERA (Contextual Element Resource Annotation) was developed in order to properly express and reason about the cultural context of a resource (Mohammed & Mohan 2014). The CERA ontology stores low level lexical concepts that describe localized natural language descriptions of the high level conceptualizations of the contextual elements depicted in the resources. The high-level concepts were then semantically linked to concepts associated with particular contextual groups in the target country thereby directly relating the ontological data of each resource in the repository to the five categories of the CSM. Eight types of high-level concepts were isolated as being suitable for describing the semantics of contextual elements: Concrete Animate Entity, Concrete Inanimate Entity, Concrete Locale, Abstract Inanimate Entity, Observable State, Observable Event, Observable Action, and Observable Characteristic.
The ontology was used together with inference rules to determine firstly whether the context of a resource will be familiar to a student based on his/her cultural background and secondly how strong the association would be for the student. This was done by matching and weighing the estimates of a student's metacultural competence against the semantic context of a cultural conceptualisation from geographical, religious, ethnic, and terrain/setting perspectives. Since the contextual categories of the CSM were used to describe the cultural context of a resource using similar semantics in CERA, reference points for determining how much of an overlap exists between a student's cultural context and an Entity's cultural context become accessible. These reference points originate from the alignment of instantiations of the CERA ontological category concepts with the values of a student's contextual estimates, and strength of metacultural competence. For example, the following rule shows how part of the religious overlap is estimated using the metacultural competence scores for the student's dominant and secondary religious influences when there is a religious context or implication associated with the resource.
If (RESOURCE R’ features CONCEPT C) and
(CONCEPT C is INOFFENSIVE to RELIGION R1) and
(STUDENT S has RELIGION R1 set as DOMINANT_INFLUENCE) and
(STUDENT S has RELIGIOUS_INFLUENCE RI1 for RELIGION R1) and
(STUDENT S has RELIGION R2 set as SECONDARY_INFLUENCE) and
(STUDENT S has RELIGIOUS_INFLUENCE RI2 for RELIGION R2) and
(CONCEPT C is OFFENSIVE to RELIGION R2) and
(RELIGIOUS_CONTEXT_WEIGHT is RW)
Then (RELIGIOUS_CONTEXT_OVERLAP = (RI1/100*RW) - (RI2/100*RW))
This particular rule checks whether the student's dominant religious influence aligns with the religious context of the resource, but there is a conflict with the student's secondary religious influence. The resource's overall religious semantic overlap score will then be lowered because of the conflict, in proportion to how strongly the student associates with his/her secondary religious influence. The religious context weight in the rule specifies the proportion of the overall semantic overlap score that is assigned to the religious context. In total, there were twenty-five rules in the rule base which score a resource based on how closely the cultural context of the conceptualisations in the resource's semantic metadata matches the student's context in the CSM. This approach is similar to the generation of cultural interest scores described by Blanchard (2009), but it can be applied to textual resources in addition to multimedia resources. At the end, a list of resources ranked by appropriateness using the overlap scores for the six CSM contextual group categories is returned.
Cultural Linguistics Adapter
The Cultural Linguistics Adapter was designed to convert formal text expressed in Standard English into less formal, more contextualised varieties that are familiar to a student based on his/her cultural background. This is achieved using two types of independent rules semantic shifting rules and grammatical transformation rules. The semantic shifting rules substitute one or more parts-of-speech in a sentence, with one or more localized, semantically equivalent parts-of-speech from a target natural language such that the context of the sentence is preserved. The substitutions are restricted to the vocabulary items of a language namely nouns, verbs, adjectives, and adverbs and are sourced from the Contextual Element Repository which filters appropriate candidate terms using the data from the CSM. This type of contextualisation focuses on the meaning being conveyed in a sentence and modifies the context to be more culturally-appropriate by using references to concepts that a student might be familiar with based on the metacultural competence scores and recommendations from the two previously described ICON components. The grammatical transformation rules modify the structure of a sentence according to the rules of a natural language. These transformations operate on pronouns, noun phrases, the tense and aspect of verb phrases, modal verbs, and adverbs and are more language-dependent compared to the semantic shifting rules.
There is a range of formality that can be expressed using natural languages (as dialects) which are in turn linked to cultural usage and norms (Gill 1983; Winford 1997). In some educational settings, students have been observed switching between one or more varieties of English as they interact and participate in learning exercises (Finkelstein et al., 2014). However, there are differences in student perception and reaction to less formal language varieties when is used in ILEs (Mohammed & Mohan 2011). The Cultural Linguistic Adapter therefore adjusts the formality of the language used in an ILE, however this is done for a range of dialect forms according to the rules of English-based languages namely English-based CreolesFootnote 1 (EbCs) and is only limited to the grammatical transformation rules. Szmrecsanyi and Kortmann (Szmrecsanyi & Kortmann 2009) surveyed over forty different varieties of English and collected patterns of similar structural features, morphology and syntax. These patterns were used to construct a generic rule base consisting of over sixty rules of which a subset (thirty rules) was selected for generating sentences that range in formality for Trinidad English Creole. Different combinations of the generic rules could therefore be used to produce different varieties of English-based dialects such as Jamaican English or Bajan based on Szmrecsanyi and Kortmann's (2009) patterns to suit the cultural background of the student as specified in the CSM.
There are no distinct categories of formality for separating these varieties of English in a comprehensive continuum (Deuber & Youssef 2007). As such, the fuzzy scale in Fig. 2 was developed in this research using examples of sentences in the literature to determine the boundaries for formality. Using an inference engine, semantic shifting rules, and grammatical transformation rules (ninety-one rules total), the Cultural Linguistics Adapter varies the formality of Standard English sentences along the scale shown in Fig. 2. Measurements of the variations were done using the number and category of word replacements and word omissions from the base text. We define this measurement as sentence distortion, such that it quantifies the degree to which a contextualised sentence varies from its original form in terms of formality, and occurrence of cultural references. The scale is applicable to content at different levels of granularity such as words, sentences, and paragraphs. The terms acrolect, mesolect, and basilect were adopted from Winford (1997) for characterising the formality of the dialect used where increasing sentence distortion is proportional to decreasing formality.

Graph of Fuzzy Definitions of Cultural Formality for Text-based Content
Dynamic Intracultural Contextualisation Strategy
This section describes how the ICON system produces culturally contextualised educational content for students. Using a detailed example, the section first sheds light on how system-initiated control is achieved, and describes the interaction of the various components in ICON. Next, the section discusses how student-initiated control is accommodated in ICON, and introduces the CRITS application as a concrete example of how ICON integrates with ILEs in practice.
System-Initiated Control
As an illustration of how ICON achieves intracultural contextualisation, consider the following example of the process followed. First, a student enters his/her demographic details into the system and creates a profile with a username. These details are used by ICON to build the student's Contextual Student Model, and generate his/her metacultural competence scores and values for the six categories of cultural context used by ICON. Figure 3 shows a sample of the geographic, religion, and ethnicity estimates generated for a student who lives in an industrialized, hilly city in the southern part of Trinidad, who has equals parts Caucasian and mixed ancestry, and who has a strong Roman Catholic background evidenced by schools attended and parent religions. The student also had additional minor influences for other ethnicities (totalling to 26 %). These were quantified using national statistics and population distributions for the cities that the student was familiar with in the northern part of Trinidad (hence the secondary geographic influence).

Sample of CSM Estimates Generated for a Student
Next, the Contextual Element Repository selects text-based and image-based assets that would be appropriate for the student based on these metacultural competence scores and values. The repository contained sixty assets (images) which were sourced from the national library of Trinidad and Tobago, and annotated with CERA ontological metadata (Mohammed & Mohan 2014). In the case of the student described by Fig. 3, the assets that were chosen included references to a variety of local foods such as ‘bake and shark’, ‘doubles’, and ‘Angostura bitters’, and locations in the southern and northern parts of the islands such as ‘Cedros beach’ and ‘Chaguaramas’. Few references to flora and fauna were recommended possibly because of the industrialised cities in the student's background. Overall, the recommended assets contained conceptual references that aligned with the specifics of the student's cultural background, or at the very least matched in a general sense. For instance, ‘Angostura bitters’ contains alcohol and would not be appropriate for students with Muslim backgrounds but does not conflict with the norms for students with Roman Catholic backgrounds.
Finally, the Cultural Linguistics Adapter uses the recommended conceptual references to modify the semantic context of text-based assets present in the educational content used in an ILE that incorporates ICON. It also uses the Contextual Student Model to determine the type of English-based dialect that would be appropriate for changing the formality of the language used in the ILE. Consider two original sentences S1 and S2 which might be used in an ILE to respectively set the frame for a problem description, and give feedback to the student.
S1: John gave away free biscuits to the customers.
S2: You have to attempt the question before you get a hint.
When S1 is provided as input to ICON, the resultant sentence S3 below would be produced for the student used in this example.
S3: John gave away free Angostura bitters to the customers.
In S3, the cultural reference to ‘Angostura bitters’, which was defined conceptually under the semantic category Food in the CERA ontology, was matched with the conceptual category of ‘biscuit’ which is also a type of Food albeit a more general one. Consequently, the Cultural Linguistics Adapter shifted the general reference (biscuit) in S1 to the more culturally-specific and culturally-appropriate reference in S3, which was selected for the student earlier. This demonstrates how ICON changes the cultural semantic context of the educational material while still preserving the learning context. When S2 is provided as input to ICON, there are several possible resultant sentences as shown in S4, S5 and S6 below.
S4: You have to attempt d question before you get a hint.
S5: You have to attempt d question before yuh get a hint.
S6: Yuh have to attempt d question before yuh get a hint.
In S4, the underlined words were changed because the Cultural Linguistics Adapter loaded the Trinidad English Creole rule base since the student has a Trinidadian context. Here, S4 has a fairly low level of sentence distortion, and falls under the acrolect category. Sentences S5 and S6 show how the same original input (S2) can be used to produce output with varying levels of formality which fall under the mesolect and basilect categories of the scale in Fig. 2. The variation of the level of formality used in the ILE is controlled by the system in this example; however the next section shows how student-initiated variation is also accommodated.
Student-Initiated Control
Previous tests of the ICON system revealed that system-initiated determination of the level of cultural formality and cultural references used in educational content was not unanimously accepted by students (Mohammed & Mohan 2011). This inspired a second investigation of whether the students wanted to have control over these cultural variations, which they indeed confirmed (Mohammed & Mohan 2013a). The educational content used in the previous tests was delivered using an Intelligent Tutoring System, CRIPSY, which was specific for Computer Science programming. Since the interface to ICON is not tied to a particular learning domain, CRIPSY was therefore updated and converted to CRITS in order to accommodate the possibility of choice where students can select the level of cultural contextualisation that they are comfortable with.
Culturally Relevant Intelligent Tutoring System (CRITS)
Figure 4 shows a screenshot of the Culturally Relevant Intelligent Tutoring System (CRITS) prototype which has a fundamentally similar interface to the CRIPSY interface with the exception of the cultural density slider. The CRITS interface presents students with a description of a programming exercise scenario, and a code editor where incorrect lines of code are highlighted in red. As a student attempts to correct syntax and logic programming errors in the code, CRITS gives feedback and hints if requested. When the exercise is completed, CRITS selects another programming exercise that increases in difficulty. Here, learning gains can be investigated from an ITS perspective using CRITS however the goal in this paper was to investigate which cultural variations are preferred by students for specific types of educational content, specifically problem descriptions, images, instructional feedback and hints. As such, movement of the cultural density slider triggers the contextualisation changes described in the previous section so that the educational content presented to the student in the three content panel areas are modified.

Screenshot of the CRITS Application Showing the Cultural Density Slider
The content areas shown in the CRITS interface are culturally varied by the Cultural Linguistics Adapter based on the cultural density slider's value. Essentially as the student moves the slider, the inference rules change the level of cultural language formality up to the selected percentage threshold. This applies to the hints, feedback, the number of cultural references used in the problem description, and the corresponding image that is associated with the problem description based on its semantic frame of reference. The slider's value is mapped directly to cultural formality scale shown in Fig. 2, and quantifies the amount of allowable cultural changes (whether grammatical and/or semantic) that can be/have been applied to the content by these rules. Each rule in the Cultural Linguistics Adapter is weighted. Depending on the type of rule and the type of modification that a rule performs, the overall density threshold is calculated using these weights. Semantic changes, done by the vocabulary shifting rules, generally take precedence over the grammatical changes (done by the grammatical transformation rules). This means that all of the allowable semantic changes to the CRITS content, for a given cultural density percentage, are done first. Any remaining thresholds are then brought up to the desired density percentage by the grammatical transformation rules. For example, Fig. 4 shows how CRITS would appear to students if they selected a cultural density value of 60 % using the slider. This corresponds to 60 % sentence distortion in ICON which in turn generated contextualised feedback and descriptions with a high level of dialect and cultural references (‘Calabashes’ and ‘Manzanilla’). The maximum number of semantic changes would therefore have been realised for 60 %. If the student changed the slider to 30 % then ICON would generate contextualisations at 30 % distortion (more formal) and with less semantic cultural references. If the student changed the slider to 0 % then ICON would not generate any contextualisations suited to his/her background, and it would restore the content to its original form. This shows how the student-initiated control is accommodated by the system.
Study Design and Results
A study was conducted using the CRITS application to find out the desirable levels of cultural contextualisation that would appeal to students from a Trinidadian context. Firstly, the study examined the effects of cultural contextualisation on student preferences in general. Secondly, the study investigated whether student preferences varied for different levels of cultural contextualisation across the four different types of educational content presented in CRITS (descriptions, images, hints, and feedback). The research question the study aimed to answer is as follows: Given individualised control over system-initiated variations of the cultural adaptations carried out by CRITS, which variations (cultural densities) do students prefer for specific types of educational content namely problem descriptions, images, instructional feedback, and hints.
Design and Procedure
The participants were first required to answer demographic questions in order to have their Contextual Student Models created by the CRITS application. They then logged on, and used the application to solve Computer Science programming problems. Each problem was made up of four content areas: a problem description/scenario, an image that related to the problem scenario, a set of hints, and instructional feedback. Participants were asked to change the cultural density slider on the screen in fixed increments of 20 % which started at 0 % and ended at 100 %. They observed the cultural changes made by the application to a problem's description, image, hints, and feedback for each cultural density level. There were six problems in total, and the scenarios and content changed for each problem. The participants were asked to repeat these observations for each new problem they encountered. They then rated how strongly they liked or disliked the content in each of these four areas using a five-point Likert scale as the cultural density was changed from 0 % to 100 %. The participants were required to observe all of the densities, and give ratings for each level and for each content type. There was no time limit for the problems, and after twenty minutes the system timed out. Each participant therefore gave one rating for each of the four types of content at each cultural density level (0 %, 20 %, 40 %, 60 %, 80 %, 100 %) for at least one problem. In total, a participant gave twenty-four ratings irrespective of how many problems he/she solved, how many hints he/she requested or how many attempts were made. They all experienced at least one hint and one piece of feedback for the first problem. So for example, after being given their first hint, participants would have been required to move the slider from 0 % to 20 %, observe the cultural changes, and note their preference, then they would have moved the slider from 20 % to 40 %, observed the changes, and noted their preference, and then the same from 40 % to 60 %, 60 % to 80 %, and 80 % to 100 %. The participants completed an online evaluation questionnaire where they typed in their ratings after using CRITS. They were also free to record their ratings in the questionnaire while using CRITS if they preferred. Usage logs were uploaded to a server, and retrieved for analysis.
Participants
Thirty-seven students from Computer Science and Information Technology programming courses at the University of the West Indies (U.W.I.), St. Augustine campus, voluntarily took part in the experiment. Four of the thirty-seven participants were excluded from the participant composition analysis because either they failed to upload their log files of the CRITS usage which contained their demographic data, or they mismatched their usernames for the questionnaires and the experiment. They were however included in the preference analysis since their questionnaires were successfully submitted. The remaining thirty-three participants were between the ages of 18 and 43 years (mean = 24, s.d. =6.18) and there were 19 males and 14 females. The ethnicity breakdown was East Indian (42.4 %), African/Black (33.3 %), and Mixed (24.2 %). The religious breakdown was Christian (54.5 %), Hindu (24.2 %), Muslim (6.1 %), and None (15.2 %).
Results
A single factor analysis of variance (ANOVA) test was conducted to determine if there were significant differences in student preferences for cultural contextualisations presented overall by the CRITS system. This was based on the number of responses collected for five preference categories: Liked Strongly, Liked, Neither Liked nor Disliked, Disliked, and Disliked Strongly.
The results, shown in Table 1, revealed that there were significant differences in student preferences since F > Fcritical and p <0.00001. A post-hoc Tukey HSD test revealed that the average number of responses in the Liked category differed significantly from all of the other preference categories at a 0.05 level of significance. All other mean comparisons also yielded significant differences with the exception of two comparisons. There were no significant differences between the means of the number of responses collected for the Disliked Strongly and the Disliked categories, and also between the means of the responses collected for the Liked Strongly and Neither Liked nor Disliked categories. In general, the students’ ratings tended towards the positive end of the rating scale. The largest number of ratings was in the ‘Liked’ category (45.3 %). The Neither Liked nor Disliked (25.9 %) and the Liked Strongly (19.5 %) categories had the second and third largest number of ratings respectively. The lowest number of ratings was in the Disliked (7 %) category followed by the Disliked Strongly (2.3 %) category.
Given that there were differences in student preferences in general, a two factor repeated measures ANOVA test was conducted to determine whether there were any significant effects on student preferences based on the cultural density levels and the type of educational content being rated. A repeated measures ANOVA was used here since the thirty-seven participants were asked to rate the educational content for each level of cultural density featured in the CRITS application. The results of this test, shown in Table 2, revealed that there were no statistically significant differences for the factors cultural density and content type on student ratings since F < Fcritical for both factors. In addition, there was no significant interaction between the factors (p > 0.05).
Despite these results, there were some interesting findings and observable trends when the data sets were represented graphically. For example, Fig. 5 shows the general trends for the students’ ratings for the feedback content category across the various cultural density levels. The observable peak in the graph matches the result reported at the start of the section for the majority of student ratings being in the Liked category. In addition, there is a general consistency in the ratings for the majority of the cultural density levels which also aligns with the repeated measures tests results. However, the graph reveals a divergent trend in student ratings towards the negative end of the rating scale at 60 % cultural density, indicated by the dashed line in the figure. This was not detected in the previous tests possibly due to the study's small sample size. This particular trend towards lowered student ratings at 60 % cultural density was also repeated for the hint content category.

Student Ratings of Instructional Feedback for Different Cultural Density Levels
Closer examination of the Liked ratings of the cultural densities within the content categories revealed the following trend. Content categories that were not modified with cultural semantically-congruent references had the largest number of Liked ratings at 20 % cultural density. These were the hint and feedback content types. Table 3 shows that the maximum number of Liked ratings (Max1) reported for these categories peaked at 20 % cultural density. For the question description and image content categories, which were modified with the cultural references such as place names, flora, fauna and so on, the peak in responses occurred at 40 % cultural density indicating that students tolerated higher levels of cultural density for these kinds of content and contextualisations. Table 3 shows that this observation was also repeated for the second largest group of Liked ratings (Max2) for the same content types as highlighted. Figure 6 illustrates this trend, which was repeated for the Liked Strongly ratings, more comprehensively. It shows that there were indeed similar rating patterns for question descriptions and images as indicated by the dashed data series plots for each content type. The trend continued for the pairing of the content categories for hints and feedback which, as mentioned before, were not modified semantically but rather only linguistically.

Cultural Density Trends for Content Types with Student Ratings “Liked Strongly”
Discussion of Results
The study aimed to find out which variations (cultural densities) were preferred by students for specific types of educational content, specifically problem descriptions, images, instructional feedback, and hints. In general, the student ratings tended to be positive irrespective of the type of content, and the type of cultural contextualisation being carried out (linguistic versus semantic). However, no statistically significant effects were found on student ratings for specific content types and for different cultural variation densities. Nonetheless, interesting trends were revealed upon closer examination of the data.
The results showed a divergent trend in the student ratings for the hint and feedback content types at 60 % cultural density compared to the rating patterns for cultural density levels set to 0 %, 20 % and 40 %. There was also a noticeable shift in the student ratings towards the Neither Liked nor Disliked category as the cultural density increased for these content types. One possible explanation for this is the change in language variety from a formal to an increasingly informal variety as defined in cultural contextualisation scale in Fig. 2. In previous experiments (Mohammed & Mohan 2011), students reported having difficulty with long paragraphs of text-based content expressed in full dialect and this result confirms that observation. A shift in student preference and possibly student perception of the ILE could therefore have been triggered by the introduction of informal dialect-based tones in the content. This change seem most tolerable by the students for feedback contextualisation since perhaps the feedback was perceived as more conversational rather than having as much pedagogical importance as the hints, question descriptions, or even the images.
Another observation from the data trends is that students in the study preferred higher cultural densities for the content types that featured cultural, semantically-congruent references where the peak interest was at 40 % for question descriptions and images, compared to 20 % for feedback and hints. There were also consistently positive ratings for higher levels of cultural density for these content types as shown in the graph in Fig. 6. In the questionnaire free-form section, this observation was supported by the answers given by the students for the various levels which they preferred, and for which they did not care much for. Some students specified different densities for different content types, and took the time to isolate what they liked. One student said that she liked the contextualisations of the question descriptions at 40 % but the hints at only 20 %. So, she had to compromise, and left the slider at 20 % because the hints at 40 % were too comical and distracted her from the learning activity. This sentiment was echoed by several other students who even preferred 0 % for the question description. Another common remark was that the images and content at 0 % were boring and even irrelevant. One student even stated that the programming exercise was ‘horrible’ at 0 % but better at 40 %. This was despite the fact that the exercise and semantics remained the same regardless of the density level; the only changes were the cultural context and language formality.
Cassell (2009) and Rehm (2011) explain that when cultural features are incorporated into software systems, people tend to draw upon their historical perceptions and beliefs of those features. In this case, as pointed out by Gill (1983) and Youssef (2004), informal varieties of English are typically associated with lower-class and uneducated members of society. Undesirable consequences may therefore result if an ILE exhibits this type of behaviour which may be perceived by students as lacking professionalism and pedagogical expertise. There is therefore a fine line separating an ILE’s productive use of cultural contextualisations for establishing rapport, creating cognitive cultural hooks, and providing emotive support from the degeneration into instructionally counter-intuitive experiences no matter how culturally-authentic. Overall, the study has revealed preliminary insight into the quantifiable thresholds at which this line of separation exists for specific types of content. The findings further support the notion put forth in the paper that student-initiated control of cultural contextualisation should be featured in ILEs aiming to cater for diverse groups of students. The results presented in the paper confirm the findings of previous work discussed in (Mohammed & Mohan 2011) that students do indeed have different preferences for variations of culturally-contextualised educational content.
One of the limitations of the study which prevents generalisation of the results and findings is firstly the small sample size used. The educational content used in the CRITS application was prepared for the Computer Science (CS) domain, and the modelling range of the ICON system was fully developed for only Trinidadian culture at the time of testing. In addition, convenience sampling from the population of CS and Information Technology students at the U.W.I. was adopted since the study required use of the CS lab and also required students who had completed the necessary CS topics covered in CRITS. These limitations introduce biases which may contribute to the sample not being representative of the CS student population at U.W.I. The participant composition analysis was included in order to counteract this bias and it showed that the sample, although small, was sufficiently representative of the cultural makeup of Trinidad. Testing with larger sample sizes and also for different cultural contexts supported by ICON is intended for confirming the generalizability of these results.
Conclusion and Future Work
There are deep issues involved in cultural contextualisation that go beyond the cosmetic treatments commonly found in the field. This paper has clarified some of these concerns through the research conducted, and has shown that computational approaches are useful, practical and necessary for formalising cultural contexts and conceptualisations. The dynamic approach that was designed, implemented and evaluated throughout this research has provided a realistic starting point for merging the positions on localisation and internationalisation of ILEs. The flexible continuum coupled with the contextual element selections and student model estimates are unique to this research. Together, they demonstrate how to automate and control various levels of cultural contextualisations with the end result of catering for diversity in student preferences and backgrounds. Also, the density ranges for which the effects of cultural contextualisations on students are the strongest and weakest have been identified. This is a useful discovery which sheds light on potential cultural thresholds which have not yet been investigated in a scientific manner with empirical results.
By changing these kinds of cultural contextualisations along a scale in response to student cultural contexts, the approach was shown to be flexible and applicable to various kinds of instructional content ranging from emotive feedback to content descriptions. It is also applicable for various types of ILEs with different levels of interactivity and pedagogical strategies such as serious games and intelligent tutoring systems. One possibility for further research involves the dynamic adjustment of cultural contextualisations particularly for real-time instructional feedback in response to the instructional events. Here, the goal could be to track student moods and adjust the contextualisation to promote learning experiences through emotive triggers or encouragement.
Notes
An English-based Creole (EbC) is a stable natural language based on a combination of parent languages, and is significantly influenced by the English language.
References
Allwood, J. (1985). Intercultural communication. In J. Allwood (Ed.), Tvärkulturell kommunikation, Papers in Anthropological Linguistics 12. Sweden: University of Göteborg.
Aylett, R., Paiva, A., Vannini, N., Enz, S., & André, E. (2009). But that was in another country: agents and intercultural empathy. In K. S. Decker, J. S. Sichman, C. Sierra, & C. Castelfranchi (Eds.) Proc. 8th International Conference on Autonomous Agents and Multi Agent Systems, Budapest, Hungary,10–15 May, 2009 (pp. 329–336). Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems.
Biswas, G., Katzlberger, T., Bransford, J., Schwartz, D., & TAG-V (The Teachable Agent Group at Vanderbilt). (2001). Extending intelligent learning environments with teachable agents to enhance learning. In J. D. Moore, C. Redfield, & W. L. Johnson (Eds.) Proc. 10th International Conference on Artificial Intelligence in Education, San Antonio, Texas,19-23 May, 2001 (pp. 389–397). Amsterdam: IOS Press.
Blanchard, E. G. (2009). Adaptation-oriented culturally-aware tutoring systems: When adaptive instructional technologies meet intercultural education. In H. Song & T. Kidd (Eds.), Handbook of Research on Human Performance and Instructional Technology (pp. 413–430). Hershey, PA: IGI Global.
Blanchard, E.G., (2012). Is it adequate to model the socio-cultural dimension of e-learners by informing a fixed set of personal criteria? In I. Aedo, R. M. Bottino, N.-S. Chen, C. Giovannella, Kinshuk & D.G. Sampson (Eds.) Proc. 12th IEEE International Conference on Advanced Learning Technologies, Rome, Italy, 4–6 July, 2012 (pp. 388–392). USA: IEEE Computer Society.
Blanchard, E. G., Mizoguchi, R., & Lajoie, S. P. (2011). Structuring the cultural domain with an upper ontology of culture. In E. G. Blanchard & D. Allard (Eds.), The Handbook of Research on Culturally-Aware Information Technology: Perspectives and Models (pp. 79–212). Hershey, PA: IGI Global.
Blanchard, E. G., & Ogan, A. (2010). Infusing cultural awareness into intelligent tutoring systems for a globalized world. In R. Nkambou, J. Bourdeau, & R. Mizoguchi (Eds.), Advances in Intelligent Tutoring Systems, SCI 308 (pp. 485–505). Berlin Heidelberg: Springer.
Brusilovsky, P. (1994). Student model centered architecture for intelligent learning environments. In Proc. 4th International Conference on User Modeling, Hyannis, MA, USA, 15–19 August, 1994 (pp. 31–36). Available online:<http://www.pitt.edu/~peterb/papers/UM94.html>.
Cassell, J. (2009). Social practice: Becoming enculturated in human-computer interaction. In C. Stephanidis (Ed.) Proc. 5th International Conference on Universal Access in HCI, Part III, HCI 2009, LNCS 5616, San Diego, CA, USA, 19–24 July, 2009 (pp. 303–313). Berlin, Heidelberg: Springer-Verlag.
Deuber, D., & Youssef, V. (2007). Teacher language in Trinidad: a pilot corpus study of direct and indirect creolisms in the verb phrase. In Proc. Corpus Linguistics Conference, 27–30 July, 2007, Birmingham, UK. Available online: http://www.birmingham.ac.uk/documents/college-artslaw/corpus/conference-archives/2007/31Paper.pdf
Endrass, B., André, E., & Rehm, M. (2011). Towards culturally-aware virtual agent systems. In E. G. Blanchard & D. Allard (Eds.), The Handbook of Research on Culturally-Aware Information Technology: Perspectives and Models (pp. 412–428). Hershey, PA: IGI Global.
Finkelstein, S., Ogan, A., Vaughn, C., & Cassell, J., (2013). Alex: A virtual peer that identifies student dialect. In Proc. Workshop on Culturally-aware Technology Enhanced Learning in conjuction with EC-TEL 2013, Paphos, Cyprus, September 17, 2013. Available online: www.macs.hw.ac.uk/CulTEL/submissions/cultel2013_submission_7.pdf
Finkelstein, S., Yarzebinski, E., Vaughn, C., Ogan, A., & Cassell, J. (2014). The effects of culturally congruent educational technologies on student achievement. In H.C. Lane, K. Yacef, J. Mostow, & P.I. Pavlik (Eds.) Proc. 16 th International Conference on Artificial Intelligence in Education, AIED 2013, Memphis, TN, USA, (pp 493–502) Berlin, Heidelberg: Springer.
Gasparini, I., Pimenta, M.S., & De Oliveira, J.P. (2011). How to apply context-awareness in an adaptive e-learning environment to improve personalization capabilities? In G. Acuña & J. A. Baier (Eds.) Proc. 30th International Conference of the Chilean Computer Society, SCCC 2011, Curico, Chile (pp.161-170). Washington, U.S.A.: IEEE Computer Society.
Gill, S. K. (1983). An exploratory case study of the code selection of an English speaker. Akademika, 23, 112–136.
Hall, E. T. (1966). The Hidden Dimension. Garden City, NY: Doubleday.
Henrich, J., & McElreath, R. (2007). Dual-inheritance theory: The evolution of human cultural capacities and cultural evolution. In J. Dunbar & L. Barrettt (Eds.), Handbook of Evolutionary Psychology (pp. 555–570). Oxford: Oxford University Press.
Hofstede, G. (2001). Culture's Consequences: Comparing Values, Behaviours, Institutions and Organizations Across Nations (2nd ed.). Thousand Oaks, CA: Sage Publications.
Hong, Y., Morris, M. W., Chiu, C., & Benet, V. (2000). Multicultural minds: A dynamic constructivist approach to culture and cognition. American Psychologist, 55(7), 709–720.
Kashima, Y., & Gelfand, M. J. (2012). A History of Culture in Psychology. In A. W. Kruglanski & W. Stroebe (Eds.), Handbook of the history of social psychology (pp. 499–520). New York: Taylor & Francis Group.
Kay, J. (2001). Learner Control. User Modeling and User-Adapted Interaction, 11, 111–127.
Kraus, R. M., & Chiu, C.-Y. (1998). Language and social behaviour. In D. T. Gilbert, S. T. Fiske, & G. Lindzey (Eds.), The Handbook of Social Psychology (4th ed., Vol. 2, pp. 41–88). Boston: McGraw-Hill.
Melis, E., Goguadze, G., Libbrecht, P., & Ullrich, C. (2010). Culturally-aware mathematics education technology. In E. G. Blanchard & D. Allard (Eds.), The Handbook of Research on Culturally-Aware Information Technology: Perspectives and Models (pp. 543–557). Hershey, PA: IGI Global.
Melis, E., Goguadze, G., & Libbrecht, P. (2009). Culturally adapted mathematics education with ActiveMath. Artificial Intelligence and Society Special Issue on Enculturating HCI, 24(3), 251–265.
Mohammed, P., & Mohan, P. (2011). The design and implementation of an enculturated web-based intelligent tutoring system for Computer Science education. In I. Aedo, N-S. Chen, D.G. Sampson, J.M. Spector, & Kinshuk (Eds.) Proc. 11th IEEE International Conference on Advanced Learning Technologies (ICALT) (pp. 501–505). Washington, USA: IEEE Computer Society.
Mohammed P., & Mohan, P. (2013a). A case study of the localization of an intelligent tutoring system. In Proc. 2nd International Workshop on Learning Technologies for the Developing World in conjunction with AIED 2013, Memphis, USA, July 9–13, 2013. Available online:http://cadmium.cs.umass.edu/LT4D2013Papers/Phaedra.pdf
Mohammed P., & Mohan, P. (2013b). Breakthroughs and challenges in culturally-aware technology enhanced learning. In Proc. Workshop on Culturally-aware Technology Enhanced Learning in conjuction with EC-TEL 2013, Paphos, Cyprus, September 17, 2013. Available online: www.macs.hw.ac.uk/CulTEL/submissions/cultel2013_submission_8.pdf
Mohammed P., & Mohan, P. (2013c). Contextualised student modelling for enculturated systems. In Proc. Fourth International Workshop on Culturally Aware Tutoring Systems in conjunction with AIED 2013 Memphis, USA, July 9–13, 2013. Available online: http://cats-ws.org/wp-content/uploads/2013/06/AIED2013-CATSproceedings.pdf
Mohammed, P., & Mohan, P. (2014). Representing and reasoning about cultural contexts in intelligent learning environments. In W. Eberle & C. Boonthum-Denecke (Eds.) Proc. 27th International Florida AI Research Society (FLAIRS) Conference. May 21–23, 2014, Pensacola, USA (pp 314–319). Palo Alto, CA: AAAI Press.
Rehm, M. (2011). Developing enculturated agents: Pitfalls and strategies. In E. G. Blanchard & D. Allard (Eds.), The Handbook of Research on Culturally-Aware Information Technology: Perspectives and Models (pp. 362–386). Hershey, PA: IGI Global.
Reinecke, K., Reif, G., & Bernstein, A. (2007). Cultural user modeling with CUMO: An approach to overcome the personalization bootstrapping problem. In Proc. First International Workshop on Cultural Heritage on the Semantic Web at the 6th International Semantic Web Conference 2007 (pp. 83–90.)
Sharifian, F. (2003). On cultural conceptualisations. Journal of Cognition and Culture, 3(3), 187–207.
Sharifian, F. (2011). Cultural conceptualisations and language: Theoretical framework and applications. Amsterdam/Philadelphia: John Benjamins.
Szmrecsanyi, B., & Kortmann, B. (2009). The morphosyntax of varieties of English worldwide: A quantitative perspective. Lingua, 119(11), 1643–1663.
Vartak, M.P., Almeida, S.F. & Heffernan, N.T. (2008). Extending ITS authoring tools to be culturally-aware. In E. Blanchard & D. Allard (Eds.) Culturally Aware Tutoring Systems in conjunction with ITS 2008, Montreal, Canada, 23-24th June, 2008. (pp. 101–105).
Winford, D. (1997). Re-examining caribbean English creole continua. World Englishes, 16(2), 233–279.
Youssef, V. (2004). ‘Is English we speaking’: Trinbagonian in the twenty-first century. English Today, 80(20), 42–49.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mohammed, P., Mohan, P. Dynamic Cultural Contextualisation of Educational Content in Intelligent Learning Environments using ICON. Int J Artif Intell Educ 25, 249–270 (2015). https://doi.org/10.1007/s40593-014-0033-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40593-014-0033-9