
Abstract
Recent advancements in large language models (LLMs) have paved the way for automated information extraction in the materials science domain. However, fine-tuning these models, crucial for effective machine learning pipelines in materials science, is hindered by a lack of pre-annotated data. Manual annotation, a laborious process, exacerbates the challenge. To address this, we introduce a tailored semi-automated annotation process, using Google’s Gemini Pro language model. Our approach focuses on two key tasks: extracting information in structured JSON format and generating abstractive summaries from materials science texts. The collaborative process, a symbiotic effort between human annotators and the LLM, driven by structured prompts and user-guided examples, enhances the annotation quality and augments the LLM’s capacity to comprehend materials science intricacies. Importantly, it streamlines human annotation efforts by leveraging the LLM’s proficient starting point.


Similar content being viewed by others
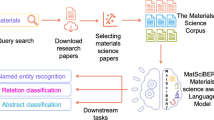

References
Olivetti EA, Cole JM, Kim E, Kononova O, Ceder G, Han TY-J, Hiszpanski AM (2020) Data-driven materials research enabled by natural language processing and information extraction. Appl Phys Rev 7:041317
Sayeed HM, Smallwood W, Baird SG, Sparks TD (2024) NLP meets materials science: quantifying the presentation of materials data in scientific literature. Mater Sci 7(3):723–727
Isayev O, Fourches D, Muratov EN, Oses C, Rasch K, Tropsha A, Curtarolo S (2015) Materials cartography: representing and mining materials space using structural and electronic fingerprints. Chem Mater 27:735–743
Lederer Y, Toher C, Vecchio KS, Curtarolo S (2018) The search for high entropy alloys: a high-throughput ab-initio approach. Acta Mater 159:364–383
Sanvito S, Oses C, Xue J, Tiwari A, Zic M, Archer T, Tozman P, Venkatesan M, Coey M, Curtarolo S (2017) Accelerated discovery of new magnets in the Heusler alloy family. Sci Adv 3:e1602241
Xi L, Pan S, Li X, Xu Y, Ni J, Sun X, Yang J, Luo J, Xi J, Zhu W et al (2018) Discovery of high-performance thermoelectric chalcogenides through reliable high-throughput material screening. J Am Chem Soc 140:10785–10793
Curtarolo S, Setyawan W, Wang S, Xue J, Yang K, Taylor RH, Nelson LJ, Hart GL, Sanvito S, Buongiorno-Nardelli M et al (2012) AFLOWLIB.ORG: a distributed materials properties repository from high-throughput ab initio calculations. Comput Mater Sci 58:227–235
Talirz L, Kumbhar S, Passaro E, Yakutovich AV, Granata V, Gargiulo F, Borelli M, Uhrin M, Huber SP, Zoupanos S et al (2020) Materials Cloud, a platform for open computational science. Sci Data 7:299
Jain A, Ong SP, Hautier G, Chen W, Richards WD, Dacek S, Cholia S, Gunter D, Skinner D, Ceder G et al (2013) Commentary: The Materials Project: a materials genome approach to accelerating materials innovation. APL Mater 1:011002
Kirklin S, Saal JE, Meredig B, Thompson A, Doak JW, Aykol M, Rühl S, Wolverton C (2015) The Open Quantum Materials Database (OQMD): assessing the accuracy of DFT formation energies. npj Comput Mater 1:1–15
Zagorac D, Müller H, Ruehl S, Zagorac J, Rehme S (2019) Recent developments in the Inorganic Crystal Structure Database: theoretical crystal structure data and related features. J Appl Crystallogr 52:918–925
Groom CR, Bruno IJ, Lightfoot MP, Ward SC (2016) The Cambridge structural database. Acta Crystallogr Sect B Struct Sci Cryst Eng Mater 72:171–179
Blokhin E, Villars P (2020) The PAULING FILE project and materials platform for data science: from big data toward materials genome. In: Handbook of materials modeling: methods: theory and modeling, pp 1837–1861
Vaitkus A, Merkys A, Gražulis S (2021) Validation of the crystallography open database using the crystallographic information framework. J Appl Crystallogr 54:661–672
Gallego SV, Perez-Mato JM, Elcoro L, Tasci ES, Hanson RM, Momma K, Aroyo MI, Madariaga G (2016) MAGNDATA: towards a database of magnetic structures. I. The commensurate case. J Appl Crystallogr 49:1750–1776
Huang S, Cole JM (2022) BatteryBERT: a pretrained language model for battery database enhancement. J Chem Inf Model 62:6365–6377
Shetty P, Rajan AC, Kuenneth C, Gupta S, Panchumarti LP, Holm L, Zhang C, Ramprasad R (2023) A general-purpose material property data extraction pipeline from large polymer corpora using natural language processing. npj Comput Mater 9:52
Dunn A, Dagdelen J, Walker N, Lee S, Rosen AS, Ceder G, Persson K, Jain A (2022) Structured information extraction from complex scientific text with fine-tuned large language models. arXiv preprint arXiv:2212.05238
Trewartha A, Walker N, Huo H, Lee S, Cruse K, Dagdelen J, Dunn A, Persson KA, Ceder G, Jain A (2022) Quantifying the advantage of domain-specific pre-training on named entity recognition tasks in materials science. Patterns 3:100488
Beltagy I, Lo K, Cohan A (2019) SciBERT: a pretrained language model for scientific text. arXiv preprint arXiv:1903.10676
Gupta T, Zaki M, Krishnan NA, Mausam (2022) MatSciBERT: a materials domain language model for text mining and information extraction. Npj Comput Mater 8:102
Bonet-Jover A, Sepúlveda-Torres R, Saquete E, Martınez-Barco P (2023) A semi-automatic annotation methodology that combines Summarization and Human-In-The-Loop to create disinformation detection resources. Knowl Based Syst 275:110723
Jain S, Van Zuylen M, Hajishirzi H, Beltagy I (2020) SciREX: a challenge dataset for document-level information extraction. arXiv preprint arXiv:2005.00512
Dagdelen J, Dunn A, Lee S, Walker N, Rosen AS, Ceder G, Persson KA, Jain A (2024) Structured information extraction from scientific text with large language models. Nat Commun 15:1418
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A et al (2020) Language models are few-shot learners. In: Advances in neural information processing systems, vol 33, pp 1877–1901
Rubin O, Herzig J, Berant J (2021) Learning to retrieve prompts for in-context learning. arXiv preprint arXiv:2112.08633
Reynolds L, McDonell K (2021) Prompt programming for large language models: Beyond the few-shot paradigm. In: Extended abstracts of the CHI conference on human factors in computing systems, pp 1–7
Zhang H, Zhang X, Huang H, Yu L (2022) Prompt-based meta-learning for few-shot text classification. In: Proceedings of the 2022 conference on empirical methods in natural language processing, pp 1342–1357
Blecher L, Cucurull G, Scialom T, Stojnic R (2023) Nougat: neural optical understanding for academic documents. arXiv preprint arXiv:2308.13418
Acknowledgements
We acknowledge the assistance provided by ChatGPT, which was used for rephrasing and achieving coherence. However, it is important to note that all core ideas, text, tables, and figures were the original work of the authors. This research was supported by the National Science Foundation (NSF) under grant number DMR 2334411. We extend our appreciation to the NSF for their financial support, which made this study possible.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sayeed, H.M., Mohanty, T. & Sparks, T.D. Annotating Materials Science Text: A Semi-automated Approach for Crafting Outputs with Gemini Pro. Integr Mater Manuf Innov (2024). https://doi.org/10.1007/s40192-024-00356-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40192-024-00356-4