
Abstract
We introduce a new wrapped exponential distribution named transmuted wrapped exponential (TWE) distribution, for the modeling of circular datasets by using the Transmutation Rank-Map method. This method is employed for the first time for a wrapped distribution with this study. The introduced distribution is more flexible than traditional wrapped exponential distribution. The paper provides the explicit form of important distributional properties of the introduced distribution such as expectation, median, moments, characteristic function, quantile function, hazard rate function and stress-strength reliability. Rényi and Shannon entropies are also obtained. The statistical inference problem for the TWE distribution is investigated using maximum likelihood, least squares and weighted least squares and comparative numerical study results are presented. Furthermore, we present a real dataset analysis.
Similar content being viewed by others


Introduction
In statistical meaning, it is known that the performance of a statistical analysis depends on the selected model distribution for a data set. If the selected distribution is an optimal model to data, then the obtained statistical inference from the dataset is the best. Because of this, a number of researchers suggested adding extra parameters to the distributions in order to be able to create more flexible distributions. Quadratic rank transmutation map (QRTM) technique is one of these methods. Depending on a base distribution, the transmuted distribution is obtained as follows.
Suppose that X is a real-valued random variable and also \(G\left( x\right) \) and \(g\left( x\right) \) are the cumulative distribution function (cdf) and the probability density function (pdf) of X, respectively. Then
and
are called a transmuted cdf and pdf, respectively, depending on base cdf \(G\left( x\right) \) and pdf \(g\left( x\right) \), where \(\Lambda \) is the transmuting parameter [18]. So far, it has been shown by the conducted studies that the QRTM distributions obtained from the base distributions are better models to the dataset than the base distributions, because QRTM distributions have more parameters and they are more flexible than the base distribution. Khan et al. [10] proposed the Transmuted Generalized Exponential distribution using the QRTM method, and they compared their model with existing lifetime distributions such as, TGE, exponentiated Weibull (EW), modified Weibull (MW), generalized exponential (GE), weighted exponential, extended exponential (EE), Weibull (W), and Power generalized Weibull (PGW). Kemaloglu and Yilmaz [8] presented the Transmuted two-parameter Lindley distribution (TTLD) as a new lifetime distribution. They studied some important statistical properties of the TTLD. Aryal and Tsokos [2] introduced the transmuted Weibull distribution and studied its mathematical properties. In 2013, Merovci applied the QRTM to the exponentiated exponential distribution and introduced the transmuted exponentiated exponential distribution as a lifetime distribution [13]. We refer the interested reader to [3, 4, 9, 14, 16, 17, 20] and the references therein for more literature information on the transmuted families of distributions.
The main goal of this study is to create a more flexible distribution called transmuted wrapped exponential (TWE) for the modeling of circular data based on QRTM method. The QRTM technique is employed for the first time for a wrapped distribution with this study.
The rest of this paper is organized as follows: In "TWE distribution" section, the cdf and pdf of TWE distribution are obtained. In addition, some important properties of the TWE distribution such as trigonometric moments, characteristic function, location, dispersion, median, skewness, kurtosis, modality behavior, order statistics, entropy, stress-strength reliability and hazard rate function are studied in that section. The statistical inference problem for the TWE distribution according to the maximum likelihood (ML), the least squares (LS) and the weighted least squares (WLS) method are discussed in "Inference" section. A series of simulation experiments for comparing the performance of the obtained estimators are performed in "Monte Carlo simulation study" section. We analyze a real-life dataset from the literature for illustrative purposes in "Application to real data" section. Finally, the last section of the paper concludes the study.
TWE distribution
The wrapping method is a well-known approach to obtain a circular distribution based on a distribution family. The wrapped distributions play quite an important role in the modeling of circular data. Jammalamadaka and Kozubowski [5] introduced the wrapped exponential (WE) distribution with following pdf and cdf,
and
respectively, where \(\lambda >0\) and \(\theta \in \left[ 0,2\pi \right) \). The main motivation of this study is to obtain a more flexible circular distribution than WE to the optimal modeling of circular data. Therefore, by using formulas (3) and (4) in QRTM method, we obtain cdf and pdf of a TWE distributed random variable \(\Theta \) as
and
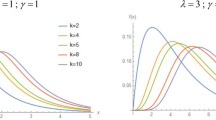
respectively, where and through the paper \(c={\mathrm{e}}^{-2\pi \lambda }-1\), \(\lambda >0\), \(\left| \Lambda \right| \le 1\) and \(\theta \in \left[ 0,2\pi \right) \). From now on, a random variable \(\Theta \) distributed the TWE with parameters \(\lambda \) and \(\Lambda \) will be indicated as \(\Theta \sim {\mathrm{TWE}}\left( \lambda ,\Lambda \right) \). Figure 1 illustrates the some of the possible shapes of the pdf of a TWE distribution for different values of the parameters \(\lambda \) and \(\Lambda \).

Pdf of transmuted wrapped exponential distribution for different values of \(\lambda \) and \(\Lambda \)
As it can be seen from Fig. 1, the TWE distribution is a unimodal distribution. When \(\Lambda >0\), the mode of the distribution is zero; otherwise, it differs from zero for some values of the \(\lambda \), see "Modality Behavior" section. We can say that the distribution has got often the negative skewness (we say anticlockwise skewness). The parameter \(\lambda \) plays an important role in the mean and variance of the TWE distribution as a heritage of its task in the exponential distribution.
Characteristic function
The characteristic function of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is
However, since a circular random variable is periodic, \(\Theta \) and \(\Theta +2\pi \) have the same distribution, and p must be restricted to the integer values [12].
Trigonometric moments
The value of the characteristic function of the circular random variable \(\Theta \sim {\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) at an integer p is called the pth trigonometric moment. One can also write pth trigonometric moments in terms of \(\alpha _{p}\) and \(\beta _{p}\)
where \(\alpha _{p}\) is pth cosine moment defined as \(\alpha _{p}=E(\cos p\Theta )\) and \(\beta _{p}\) is pth sine moment defined as \(\beta _{p}=E(\sin p\Theta )\). Hence, the pth cosine moment of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is
and pth sine moment is
where \(p=0,\pm \, 1,\pm \, 2,\ldots \).
Location, dispersion and median
The pth trigonometric moment of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) can be expressed in \(\varphi _{p}=\rho _{p}{\mathrm{e}}^{i\mu _{p}}\) where \(\mu _{p} ={\text {atan}}\left( \alpha _{p}\beta _{p}^{-1}\right) \) and \(\rho _{p}=\sqrt{\alpha _{p}^{2}+\beta _{p}^{2}}\). \(\varphi _{p}\) has a special meaning for \(p=1\). The \(\rho _{1}\) and the \(\mu _{1}\) are called angular concentration and mean direction, respectively. Here \({\text {atan}}( .) \) is quadrant inverse tangent function and defined as
Mean direction of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is
The mean direction vector gives information about the mean of the distribution as an analogy of the mean in the linear models. The length of this vector is a measure of dispersion around the mean and corresponds to the usual standard deviation or variance in linear models. The angular concentration for \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is
For a circular model, the circular variance is calculated as \(V=1-\rho _{1}\). Hence, using the (12), the circular variance of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is obtained as
Also, the circular standard deviation calculated as \(\sigma =\sqrt{-2\ln \rho _{1}}\) and calculated for \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution as
The quantile function of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) can be easily obtained from the solution of equation \(F\left( \theta \right) -u=0\) with respect to \(\theta \) as
where \(u\in \left( 0,1\right) \). Then the median direction of a circular distribution is a value M such that \(\int _{0}^{M}f_{\Theta }\left( \theta \right) {\mathrm{d}}\theta =\int _{M}^{2\pi }f_{\Theta }\left( \theta \right) {\mathrm{d}}\theta =0.5\). The median of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is obtained from equation \(M=Q\left( 0.5\right) \) as
Modality behavior
\({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) is a unimodal distribution for \(\Lambda \ne 0\). The critical value of its pdf (6) can be immediately calculated as
On the other hand, for
the parameter \(\Lambda \) must be negative. Thus, the mode of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \), say \(\theta _{T}\), is
when \(\frac{c}{3c+2}<\Lambda <\frac{c}{\left( 2-c\right) }\) and 0 otherwise.
Skewness and kurtosis
For a circular model, the pth central cosine and sine moments are\(\ {\bar{\alpha }}_{p}=E\left[ \cos p\left( \theta -\mu _{1}\right) \right] \) and \({\bar{\beta }}_{p}=E\left[ \sin p\left( \theta -\mu _{1}\right) \right] \), respectively [12]. As a measure of asymmetry, skewness coefficient is calculated by \({\varvec{\gamma }}_{1}={\bar{\beta }}_{2}V^{-3/2}\) for a circular distribution. Hence, the skewness coefficient of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) is obtained as
Kurtosis of a circular distribution is \({\varvec{\gamma }}_{2}=\left( {\bar{\alpha }}_{2}-\rho _{1}^{4}\right) \left( 1-\rho _{1}\right) ^{-2}\). Therefore, kurtosis coefficient of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) is obtained as
Figure 2 represents the contour plots of circular variance (V) , skewness \(\left( \gamma _{1}\right) \) and kurtosis \(\left( \gamma _{2}\right) \) of TWE distribution.

Contour plots of circular variance (V) , skewness \(\left( \gamma _1\right) \) and kurtosis \(\left( \gamma _2\right) \) coefficient of TWE distribution
In general, for a constant value of \(\Lambda \), it can be seen from Fig. 2 that when the \(\lambda \) increases, the circular variance decreases. However, this is not true for some negative values of \(\Lambda \). Similarly, for a constant value of \(\lambda \), when \(\Lambda \) increases, the circular variance decreases. As in the circular variance, the skewness decreases when \(\lambda \) increases. On the other hand, when \(\lambda \) increases Kurtosis increases.
Order statistics
Let \(\Theta _{1},\Theta _{2},\ldots ,\Theta _{n}\) be a random sample from \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution and let \(\Theta _{(1)} \ldots \Theta _{(n)}\), \(\left( \Theta _{(1)}< \cdots <\Theta _{(n)}\right) \), denote the order statistic for this sample. Then, the pdf of the random variable \(\Theta _{(i)}\), \(i=1,2,\ldots ,n\) is obtained as
where, \(\kappa =\Lambda +c-\Lambda {\mathrm{e}}^{-\lambda \theta }+\Lambda c\). The first order and nth order statistics can be immediately calculated from (18) as
and
respectively.
Rényi and Shannon entropy
The entropy is a measure of variation or uncertainty of a random variable. In this section, we investigate the Shannon and Rényi entropy, which are two most popular entropies, for TWE distribution. The Rényi entropy of a circular random variable with pdf \(f(\theta )\) is defined as
for \(\xi >0\) and \(\xi \ne 1\). Thus, Rényi entropy of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is obtained as
where \(_{2}F_{1}\) denotes the hypergeometric function, see [1]. The Shannon entropy is the special case of the Rényi entropy when \(\xi \rightarrow 1\) and it is defined as \(SE_{\theta }=E\left[ -\ln f(\theta )\right] \), see [11] for definition of Shannon entropy. Immediately, Shannon entropy of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution is obtained as
Stress-strength reliability
Suppose Y represents the ‘stress’ and X represents the ‘strength’ to sustain the stress, then the stress-strength reliability is denoted by \(R=P\left( Y<X\right) \). Let \(X\sim {\mathrm{TWE}}\left( \lambda _{x},\Lambda _{x}\right) \) and \(Y\sim {\mathrm{TWE}}\left( \lambda _{y},\Lambda _{y}\right) \). Stress-strength reliability \(P\left( Y<X\right) \) is
where \(c_{x}={\mathrm{e}}^{-2\pi \lambda _{x}}-1\) and \(c_{y}={\mathrm{e}}^{-2\pi \lambda _{y}}-1\). If \(\lambda _{x}=\lambda _{y}=\lambda \)
Hazard rate function
The hazard rate function \(h_{r}\) of \(\Theta \sim {\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) random variable is
where \(\theta \in \left[ 0,2\pi \right) ,~\lambda >0\), \(\left| \Lambda \right| \le 1\) and \(c={\mathrm{e}}^{-2\pi \lambda }-1\). Critical point of the \(h_{r}\left( \theta \right) \) is
The hazard rate function has bathtub shape when \(\Lambda \) is in the interval
Here, considering that the smallest value of c is \(-1\), \(h_{r}\left( \theta \right) \) appears to be a bathtub in the positive \(\Lambda \) values providing the above condition. We present Fig. 3 which plots the hazard rate functions of the \({\mathrm{TWE}}\left( 5.48,\; 0.25\right) \) and WE\(\left( 5.48\right) \) distributions for illustrative purposes.

The plots of hazard rate functions of TWE and WE distributions
Inference
In this section, we consider the statistical inference problem for \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \). To estimate the unknown parameters of \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \), we employ the ML, LS and WLS estimation methods commonly used in the literature.
Maximum likelihood estimation
Let \(\Theta _{1},\Theta _{2},\ldots ,\Theta _{n}\) be a random sample from \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution. From (6), the logarithmic likelihood function for the random variables \(\Theta _{i},i=1,2,\ldots ,n\) can be immediately written as
If the first derivatives of (19) with respect to parameters \(\lambda \) and \(\Lambda \) are taken and equalized them to zero, then we have the following normal equations
and
where \(c={\mathrm{e}}^{-2\pi \lambda }-1\). Hence, the ML estimates of the parameters \(\lambda \) and \(\Lambda \), say \({\hat{\lambda }}_{{\mathrm{ML}}}\) and \({\hat{\Lambda }}_{\mathrm{ML}}\), respectively, can numerically be obtained from the collective solution of (20) and (21).
Least squares estimation
To obtain the least squares estimates of the \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution, let us consider the ordered random sample \(\theta _{(1)}< \cdots <\theta _{(n)}\) from this distribution. Then, the LS estimates of the unknown parameters of the \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution, say \({\hat{\lambda }}_{LS}\), and \({\hat{\Lambda }}_{LS}\), are obtained by minimizing
with respect to \(\lambda \) and \(\Lambda \), respectively. Where \(\frac{j}{n+1}\) is the expectation of the empirical distribution function of the ordered data, see Swain et al. [19]. It is known that the LS estimates are biassed. A well-known modification of LS method is the WLS, which has a lower bias than the ordinary LS. The WLS estimates of the parameters of the \({\mathrm{TWE}}\left( \lambda ,\Lambda \right) \) distribution are obtained by minimizing
with respect to \(\lambda \) and \(\Lambda \).
Monte Carlo simulation study
In this section, we perform some Monte Carlo simulation studies for illustrating and comparing estimation performances of the ML, LS and the WLS estimators obtained in the previous section. In Monte Carlo simulations, we use the values of the parameters \(\lambda =0.5,1.5\) and \(\Lambda =-\,0.75,0.75\). For the different sample of sizes \(n = 30, 50,100\) and 1000, the obtained Bias and mean squared error (MSE) values based on the 1000 times replicated simulations are displayed in Table 1.
As can be clearly seen from Table 1, when the sample size increases, for all values of the parameters, both Bias and MSE values decreases. This shows that the estimates are precise and accurate and hence consistent and unbiased. This is an expected result for the ML estimators, since ML estimators are asymptotically unbiased estimators. The simulation results also show that the other estimators have the same characteristics. Besides, by Table 1, we can say that the ML estimators outperform both the LS and the WLS estimators with smaller MSE values.
Application to real data
In this section, to illustrate the modeling behavior of the TWE distribution on a real-life dataset , we analyze the turtle dataset, which is a popular circular dataset. This dataset contains the orientations of 76 turtles laying their eggs [6]. We obtain the maximum likelihood estimation of the parameters \(\lambda \) and \(\Lambda \) by using the “mle” subroutine in the package ‘stats4’ (version 3.4.3) of R. Note that when applying the mle subroutine, the parameter ranges should be selected as wide as possible to avoid local maxima. We also refer the advanced readers to an R package ‘wrapped’, introduced by Nadarajah and Zhang [15], for further computation in wrapped distributions.
For the turtle dataset, the ML estimation of the parameters and the corresponding mean direction and the resultant length are obtained as given in Table 2, when the dataset is modeled by the TWE distribution.
This dataset was recently used by Joshi and Jose [7] as an application of the wrapped Lindley \(\left( {\mathcal {WL}}\right) \) distribution. In order to make a comparison, maximized log likelihood values (L), Akaike information criterion (AIC), Kolmogorov–Smirnov with p values (KS) and Watson’s \(U^{2} \, (\hbox {W}^{2})\) statistics values for the TWE, WE and \({\mathcal {WL}}\) distributions are given in Table 3.
Plots of the fitted densities are shown in Fig. 4. Left panel of this figure represents the circular data plot, rose diagram and fitted pdf of the TWE, WE and \({\mathcal {WL}}\) distributions. The dashed arrow points out the sample mean resultant vector with values \(m_{1}=1.12~(\sim 64.2^{\circ })\) and resultant length \(r_{1}=0.4971\), and the solid arrow points out the mean direction vector and the resultant length of the fitted TWE distribution, which their values are given in Table 2.

Plots for turtle data. Circular data plot, fitted circular pdf and rose diagram (left), linear histogram and fitted pdf (center), empirical cdf and fitted cdf (right)
According to Table 3, the TWE distribution has the smallest negative log-likelihood value, AIC and Watson statistics than the others. Thus, we can clearly say that the TWE distribution gives better fit than \({\mathcal {WL}}\) distribution and WE distribution. Furthermore, according to the results of the KS test given in Table 3, the goodness of fit of the \({\mathcal {WL}}\) distribution cannot be accepted at a significance level of 0.05.
Conclusion
In this article, we have introduced a new transmuted wrapped distribution named TWE distribution, for modeling the circular data. To the best of our knowledge, the transmutation of a circular distribution is a new attempt to obtain more flexible circular distribution. In the paper, the pdf and the cdf of the introduced distribution are derived and their behaviors are illustrated. Rényi and Shannon entropies of the distribution are obtained in an open form. Furthermore, explicit forms of the basic characteristics of the introduced distribution such as mean, trigonometric moments, characteristic function, quantile function and others are obtained. To estimate the unknown parameters of the introduced distribution, the maximum likelihood, the least squares and the weighted least squares estimators are obtained. By a conducted Monte Carlo simulation study, the efficiencies of these estimators are comparatively illustrated. The results of the Monte Carlo simulation show that when the sample size increases, both Bias and MSE values decrease for all estimation methods. Finally, we apply the introduced distribution to a real-life dataset named turtles dataset. Using the log-likelihood, AIC and Watson’s statistic criteria, the modeling performance of the introduced distribution is compared with wrapped exponential distribution and wrapped Lindley distribution. According to the obtained results, we can say that the TWE distribution is a better model to the turtle data than WE and \({\mathcal {WL}}\) distributions.
References
Abramowitz, M., Stegun, I.A.: Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables, vol. 55. Courier Corporation, North Chelmsford (1964)
Aryal, G.R., Tsokos, C.P.: Transmuted weibull distribution: a generalization of theweibull probability distribution. Eur. J. Pure Appl. Math. 4(2), 89–102 (2011)
Fattah, A.A., Nadarajah, S., Ahmed, A.-H.N.: The exponentiated transmuted weibull geometric distribution with application in survival analysis. Commun. Stat. Simul. Comput. 46(6), 4244–4263 (2017)
Granzotto, D.C.T., Louzada, F.: The transmuted log-logistic distribution: modeling, inference, and an application to a polled tabapua race time up to first calving data. Commun. Stat. Theory Methods 44(16), 3387–3402 (2015)
Jammalamadaka, S.R., Kozubowski, T.J.: New families of wrapped distributions for modeling skew circular data. Commun. Stat. Theory Methods 33(9), 2059–2074 (2004)
Jammalamadaka, S.R., Sengupta, A.: Topics in Circular Statistics, vol. 5. World Scientific, Singapore (2001)
Joshi, S., Jose, K.: Wrapped lindley distribution. Commun. Stat. Theory Methods 47(5), 1013–1021 (2018)
Kemaloglu, S.A., Yilmaz, M.: Transmuted two-parameter lindley distribution. Commun. Stat. Theory Methods 46(23), 11866–11879 (2017)
Khan, M.S., King, R.: A new class of transmuted inverse weibull distribution for reliability analysis. Am. J. Math. Manag. Sci. 33(4), 261–286 (2014)
Khan, M.S., King, R., Hudson, I.L.: Transmuted generalized exponential distribution: a generalization of the exponential distribution with applications to survival data. Commun. Stat. Simul. Comput. 46(6), 4377–4398 (2017)
Khodabina, M., Ahmadabadib, A.: Some properties of generalized gamma distribution. Math Sci 4(1), 9–28 (2010)
Mardia, K.V., Jupp, P.E.: Directional Statistics, vol. 494. Wiley, Hoboken (2009)
Merovci, F.: Transmuted exponentiated exponential distribution. Math. Sci. Appl. E-Notes 1, 2 (2013)
Merovci, F., Alizadeh, M., Yousof, H.M., Hamedani, G.: The exponentiated transmuted-g family of distributions: theory and applications. Commun. Stat. Theory Methods 46(21), 10800–10822 (2017)
Nadarajah, S., Zhang, Y.: Wrapped: an r package for circular data. PLoS ONE 12(12), e0188512 (2017)
Naveed Shahzad, M., Asghar, Z.: Transmuted power function distribution: a more flexible distribution. J. Stat. Manag. Syst. 19(4), 519–539 (2016)
Nofal, Z.M., Afify, A.Z., Yousof, H.M., Cordeiro, G.M.: The generalized transmuted-g family of distributions. Commun. Stat. Theory Methods 46(8), 4119–4136 (2017)
Shaw, W.T., Buckley, I.R.: The alchemy of probability distributions: beyond gram-charlier expansions, and a skew–kurtotic-normal distribution from a rank transmutation map. arXiv preprint arXiv:0901.0434 (2009)
Swain, J.J., Venkatraman, S., Wilson, J.R.: Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 29(4), 271–297 (1988)
Tian, Y., Tian, M., Zhu, Q.: Transmuted linear exponential distribution: a new generalization of the linear exponential distribution. Commun. Stat. Simul. Comput. 43(10), 2661–2677 (2014)
Funding
Funding was provided by Kirikkale University (Grant No. 2018/050).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Yilmaz, A., Biçer, C. A new wrapped exponential distribution. Math Sci 12, 285–293 (2018). https://doi.org/10.1007/s40096-018-0268-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-018-0268-y