
Abstract
The goal of this paper is to develop provably efficient importance sampling Monte Carlo methods for the estimation of rare events within the class of linear stochastic partial differential equations. We find that if a spectral gap of appropriate size exists, then one can identify a lower dimensional manifold where the rare event takes place. This allows one to build importance sampling changes of measures that perform provably well even pre-asymptotically (i.e. for small but non-zero size of the noise) without degrading in performance due to infinite dimensionality or due to long simulation time horizons. Simulation studies supplement and illustrate the theoretical results.
Similar content being viewed by others


Notes
For the exact form of \(R(\eta ,T,|\left\langle z,e_1\right\rangle _H|^{2},M )\) we refer the interested reader to Theorem 4.7 in [5]. We do not report it here as the formula is long and not useful for our purposes.
Due to space limitations issues and due to the lack of any important additional information, we do not report estimated probability values for some of the test cases and we only report estimated relative errors per sample, which is the measure of performance being used. The data on probability estimates is available upon request.
References
Boué, M., Dupuis, P.: A variational representation for certain functionals of brownian motion. Ann. Probab. 26(4), 1641–1659 (1998)
Budhiraja, A., Dupuis, P.: A variational representation for positive functionals of infinite dimensional brownian motion. Probab. Math. Stat.-Wroclaw Univ. 20(1), 39–61 (2000)
Budhiraja, A., Dupuis, P., Maroulas, V.: Large deviations for infinite dimensional stochastic dynamical systems. Ann. Probab. 36(4), 1390–1420 (2008)
Da Prato, G., Zabczyk, J.: Stochastic Equations in Infinite Dimensions, vol. 152. Cambridge University Press, Cambridge (2014)
Dupuis, P., Spiliopoulos, K., Zhou, X.: Escaping from an attractor: importance sampling and rest points I. Ann. Appl. Probab. 25(5), 2909–2958 (2015)
Dupuis, P., Wang, H.: Subsolutions of an isaacs equation and efficient schemes for importance sampling. Math. Oper. Res. 32, 723–757 (2007)
Fleming, W.H.: Exit probabilities and optimal stochastic control. Appl. Math. Optim. 4, 329–346 (1978)
Freidlin, M.I., Wentzell, A.D.: Random Perturbations of Dynamical Systems, 3rd edn. Springer, Berlin (2012)
Jentzen, A., Kloeden P.E.: Overcoming the order barrier in the numerical approximation of stochastic partial differential equations with additive space–time noise. In: Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 465, pp. 649–667. The Royal Society (2009)
Author information
Authors and Affiliations
Corresponding author
Additional information
K.S. was partially supported by the National Science Foundation CAREER award DMS 1550918.
Appendices
Appendix A: Proof of Lemma 5.5
Before proving Lemma 5.5 let us define some useful quantities. Set
and notice that \(\rho _{1}\in [0,1]\), guarantees that \(\beta _{0}(x)\ge 0\). In addition, let us define
By the argument of Lemma 4.1 of [5] applied to \(\mathcal {G}^{\varepsilon }[U^{\delta ,\eta }](x)\) and (5.2) we get
for all \(x\in H\). The lower bound for the operator \(\mathcal {G}^{{\varepsilon }}[U^{\delta ,\eta },U^{\delta }](x)\), given by (A.1), will be based on a separate analysis for three different regions that are determined by level sets of \(V_{1}(x)=|<x,e_{1}>|^{2}\).
Let \(\kappa \in (0,1)\) to be chosen, \(\alpha \in (0,1-\kappa )\) and consider K such that \(\frac{e^{-K}}{e^{-K}+1}=\frac{3}{4}\), i.e., \(K=-\ln 3<0\). Let us also assume \({\varepsilon }\in (0,1)\) . Then, we define
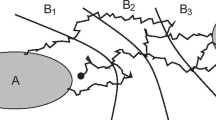
Lemma 5.5 is a direct consequence of Lemmas A.1, A.2 and A.3 that treat the regions \(B_{1}, B_{3}\) and \(B_{2}\) respectively.
Lemma A.1
Assume that \(x\in B_{1}\), \(\delta =2{\varepsilon }\), \(\eta \le 1/2\) and \({\varepsilon }\in (0,1)\). Then, up to an exponentially negligible term
Proof
In this region, we are guaranteed that \(F_{1}(x)> F_{2}^{{\varepsilon }}\). Indeed, we have that
since \({\varepsilon }<1\) and \(\alpha \in (0,1)\). Hence, we have that
This immediately implies that the term involving the weight \(\rho _{1}\) is exponentially negligible. Since \(\beta _{0}(x)\ge 0\) and \(\eta \le 1/2\), all other terms are non-negative, and the result follows. \(\square \)
Lemma A.2
Assume that \(x\in B_{3}\), \(\delta =2{\varepsilon }\), \(\eta \le 1/4\) and that \({\varepsilon }^{1-\kappa }\in (0,\alpha _{1}/2\lambda _1^2)\). Then, we have
Proof
In this region we have that \(V(x)\ge 2{\varepsilon }^{\kappa }-{\varepsilon }\beta K>0\) for \({\varepsilon }\) small enough. Moreover, since \(K=-\ln 3\) is chosen such that
we obtain that for \(x\in B_{3}\), \(\rho _{1}(x)\ge 3/4\). We have the following inequalities
In the third inequality we used the fact that \(\rho _{1}(x)\ge 3/4\) for \(x\in B_{3}\). In the next inequality we used that \(\eta \le 1/4\) and that for \(x\in B_{3}\), \(V_{1}(x)\ge 2{\varepsilon }^{\kappa } -{\varepsilon }K\). Lastly, in the last inequality, we used that \(K<0\) and that \(0<{\varepsilon }^{1-\kappa }<\alpha _{1}/(2\lambda _{1}^{2})\). This concludes the proof of the lemma. \(\square \)
Lemma A.3
Assume that \(x\in B_{2}\), \(\eta \le 1/4\) and set \(\delta =2{\varepsilon }\). Let \({\varepsilon }>0\) be small enough such that \({\varepsilon }^{1-\kappa }\le \frac{\alpha _{1}}{2\lambda _{1}^{2}}\). Then we have that
Proof
This is the most problematic region, since one cannot guarantee that \(\rho _{1}\) is exponentially negligible or of order one. We distinguish two cases depending on whether \(\rho _{1}(x)>1/2\) or \(\rho _{1}(x)\le 1/2\).
For the case \(\rho _{1}(t,x)>1/2\), one can just follow the proof of Lemma A.2. Then, one immediately gets that \(\mathcal {G}^{{\varepsilon }}[U^{\delta ,\eta },U^{\delta }](x)\ge 0\).
Let us now study the case \(\rho _{1}(x)\le 1/2\). Here we need to rely on the positive contribution of \(\beta _{0}(x)\). Dropping other terms on the right that are not possibly negative, we obtain from (A.1) that
where we used \(\rho _{1}(t,x)\le 1/2\). Recalling now the definitions of \(D_{x}F_{1}(x)\) and \(\gamma _{1}\), we subsequently obtain
In the last inequality we used that for \(x\in B_{2}\) \(V(x)\ge {\varepsilon }^{\kappa }\) and that \({\varepsilon }>0\) is small enough such that \({\varepsilon }^{1-\kappa }\le \frac{\alpha _{1}}{2\lambda _{1}^{2}}\). This concludes the proof of the lemma. \(\square \)
Appendix B: Galerkin approximation
The goal of this section is to get an explicit bound in terms of \({\varepsilon },T\) and the eigenvalues of the difference of \(X^{\varepsilon }(t)\) and its finite dimensional Galerkin approximation, see also [9] for general bounds. Our goal is not to present the most general result possible, but rather to point out the issues related for the problem studied in thus paper in the simplest situation possible. For \(N \in \mathbb {N}\) let \(H_N\) be the finite dimensional space \({ span }\{e_k\}_{k=1}^N\). Let \(\Pi _N: H \rightarrow H_N\) be the projection operator onto this space. That is, for any \(x \in H\),
Definition B.1
Letting \(A_N := \Pi _N A\), the \(N^{\text {th}}\) Galerkin approximation for \(X^{\varepsilon }\) is defined to be the solution to N-dimensional SDE
Given that in this paper, u represents the control being applied which turns out to be affine, we may, for the purposes of this section, embed this into A. We will do so and thus from now on set \(u=0\). The same conclusions hold when \(u\ne 0\).
Theorem B.2
For any initial condition \(x \in H\) and any \({\varepsilon }>0\), \(T>0\),
for some constant \(C<\infty \). The limit as \(N \rightarrow +\infty \) is zero but it is not uniform with respect to initial conditions in bounded subsets of H. The limit is uniform with respect to initial condition in the compact set \(\{x\in H: |(-A)^\eta x|_H \le R\}\) for any \(\eta > 0\).
Before proving this theorem in generality, we study the special case of the stochastic convolution.
Lemma B.3
For any \(T>0\), \(p\ge 1\), \(\frac{1}{2}<\gamma <1\) the Galerkin approximations of the stochastic convolution converge in \(L^p(\Omega ;C([0,T];H))\) and there exists a constant \(C=C(p,\gamma )\) such that
Proof
We use the stochastic factorization method (see [4]) which is based on the following identity. For any \(s<t\), \(0<\alpha <1\)
We then write the stochastic convolution as
Let \(\frac{1}{2}<\gamma <1\) and \(p\ge 1\). We then choose \(0<\alpha < \frac{1-\gamma }{2}\) and calculate that
We use the identity \(\sup _{x>0} x^\gamma e^{-x} =: C_\gamma <+\infty \) to show that
and it follows that there exists \(C=C(\alpha ,\gamma )\) such that
By the Burkholder–Davis–Gundy inequality, for any \(p\ge 2\),
By applying the Hölder inequality to (B.5)
If we choose p large enough so that \(\frac{p(\alpha -1)}{p}>-1\), then the first integral converges and is bouned for all \(t>0\) and
We can lower p by using Jensen’s inequality. \(\square \)
Proof of Theorem B.2
First, we observe that in the case being considered
So, we can write
We know that
If \(x \in (-A)^{-\eta }(H)\), then
The stochastic convolution term can be made small by Lemma B.3. We can combine these estimates to conclude that
The above expression converges to 0 and the convergence is uniform for initial conditions x satisfying \(|(-A)^{\eta }x|_H \le R\). \(\square \)
We conclude this section with two relevant remarks.
Remark B.4
The previous theorem shows that \(X^{\varepsilon }(t)\) and its Galerkin approximation \(X^{\varepsilon }_N(t)\) are pathwise close, but also that the Galerkin approximation’s accuracy for fixed n and \({\varepsilon }\) decreases as time T increases. This is not a failure of our estimation. The difference \(X^{\varepsilon }(t) - X^{\varepsilon }_N(t)\) is a Markov process that is exposed to the noise \(\sqrt{{\varepsilon }}(I-\Pi _N)B d w(t)\). While this noise is degenerate in H, it is nondegenerate on the the subspace \((I-\Pi _N)(H)\). We can guarantee by standard arguments that for fixed n and \({\varepsilon }\) and with probability one \(X^{\varepsilon }(t)\) and \(X^{\varepsilon }_N(t)\) will deviate from each other arbitrarily far on an infinite time horizon.
Remark B.5
In Theorem B.2, we claimed that the convergence of the Galerkin approximations is uniform if the initial conditions x are regular enough. In fact, over long time periods, the regularity of the initial conditions does not matter. This is because
Therefore we can have uniform convergence on bounded sets in \(D \subset H\) as long as we consider the estimate
for some \(t_0>0\).
Rights and permissions
About this article

Cite this article
Salins, M., Spiliopoulos, K. Rare event simulation via importance sampling for linear SPDE’s. Stoch PDE: Anal Comp 5, 652–690 (2017). https://doi.org/10.1007/s40072-017-0100-y
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40072-017-0100-y