
Abstract
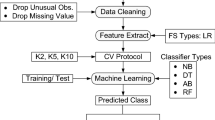
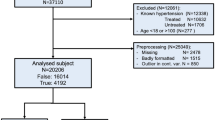
Hypertension is a leading risk factor contributing to cardiovascular diseases and cardiovascular mortality and morbidity across the world. Developing good risk prediction models to arbitrate individuals risk predictions, pay off high value by reducing mortality and morbidity. To build such a good prediction model a reliable BP data is needed, but real-life data is often noisy, inconsistent and incomplete. Hence, it is important to pre-process data before building prediction model. This paper aims to pre-process (impute data) the data using unsupervised neural network, Adaptive Resonance Theory 2 (ART2) clusters and build prediction model using decision trees, Naive Bayes, random forest after handling imbalanced class of dataset from one of the Health and Demographic Surveillance System (HDSS) site Vadu, India. Its a part of International Network for the Demographic Evaluation of Populations and Their Health (INDEPTH) network in developing countries, aiming to help developing countries to set health priorities based on longitudinal evidence. The experimental results of the proposed technique shows the importance of pre-processing in enhancing the performance of the prediction models.



Similar content being viewed by others

References
LaFreniere D, Zulkernine F, Barber D, Martin K (2016) Using machine learning to predict hypertension from a clinical dataset. In: 2016 IEEE symposium series on computational intelligence (SSCI). IEEE, pp 1–7
Poli R, Cagnoni S, Livi R, Coppini G, Valli G (1991) A neural network expert system for diagnosing and treating hypertension. Computer 24(3):64–71
Echouffo-Tcheugui JB, Batty GD, Kivimäki M, Kengne AP (2013) Risk models to predict hypertension: a systematic review. PloS ONE 8(7):e67370
Srivastava P, Srivastava A, Burande A, Khandelwal A (2013) A note on hypertension classification scheme and soft computing decision making system. ISRN Biomath 2013:342970. https://doi.org/10.1155/2013/342970
Ture M, Kurt I, Kurum AT, Ozdamar K (2005) Comparing classification techniques for predicting essential hypertension. Expert Syst Appl 29(3):583–588
Japkowicz N (2000) The class imbalance problem: significance and strategies. In: Proceedings of the international conference on artificial intelligence
Ling CX, Li C (1998) Data mining for direct marketing: problems and solutions. In: KDD, vol 98, pp 73–79
Solberg AHS, Solberg R (1996) A large-scale evaluation of features for automatic detection of oil spills in ERS SAR images. In: International geoscience and remote sensing symposium, 1996 (IGARSS’96), remote sensing for a sustainable future. IEEE, vol 3, pp 1484–1486
Van Minh H, Soonthornthada K, Ng N, Juvekar S, Razzaque A, Ashraf A, Ahmed SM, Bich TH, Kanungsukkasem U (2009) Blood pressure in adult rural INDEPTH population in Asia. Global Health Action 2(1):2010
Ku WC, Jagadeesh GR, Prakash A, Srikanthan T (2016) A clustering-based approach for data-driven imputation of missing traffic data. In: 2016 IEEE forum on integrated and sustainable transportation systems (FISTS). IEEE, pp 1–6
Yozgatligil C, Aslan S, Iyigun C, Batmaz I (2013) Comparison of missing value imputation methods in time series: the case of Turkish meteorological data. Theor Appl Climatol 112(1–2):143–167
Carpenter GA, Grossberg S (2017) Adaptive resonance theory. Springer, Berlin
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shobha, K., Nickolas, S. Analysis of importance of pre-processing in prediction of hypertension. CSIT 6, 209–214 (2018). https://doi.org/10.1007/s40012-018-0197-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40012-018-0197-9