
Abstract
Introduction
Medical diagnosis is a crucial step for patient treatment. However, diagnosis is prone to bias due to imbalanced datasets. To overcome the imbalanced dataset problem, simple minority oversampling technique (SMOTE) was proposed that can generate new synthetic samples at data level to create the balance between minority and majority classes. However, the synthetic samples are generated on a random basis which causes class mixture problem; thus, resulting in deteriorating the classification performance and biased diagnosis.
Purpose
In order to overcome the SMOTE shortcomings, some modified methods were proposed that try to generate synthetic samples along the line segment of selected minority samples. Most of these methods adopt one of the two policies for selecting minority samples to generate synthetic samples: borderline region sampling or safe region sampling. However, they both suffer from over-generalisation problem. We propose a modified SMOTE-based resampling method called RSMOTE to alleviate the medical imbalanced dataset problem. We provide an in-depth analysis and verify the performance of RSMOTE over imbalanced medical datasets.
Methods
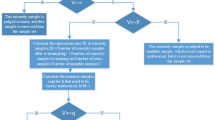
In this paper, the proposed RSMOTE divides the minority sample domain into four regions (normal, semi-normal, semi-critical, and critical) based on the minority sample density analysis. RSMOTE discovers the minority sample region globally and applies the resampling near a specific group of samples.
Results
Our analysis and experiments verify that if synthetic samples are generated in the regions with high minority sample density, classification performance will be improved due to low risk of class mixture. Unlike some safe region methods, RSMOTE decides the region of minority samples on a global basis, thus removing the over-generalisation problem. Classic and additional evaluation metrics are considered to measure the effectiveness of the modified method: Recall, FP Rate, Precision, F-Measure, ROC area, and Average Aggregated Metric. We carried out experiments over various imbalanced medical datasets.
Conclusion
Based on the minority sample density analysis, we propose RSMOTE method that divides the minority sample domain into four regions. The proposed RSMOTE includes four re-sampling methods that each of them carries out resampling on a specific region. According to the experimental results, resampling on the regions with high minority sample density obtained better results while those with lower minority sample density got the inferior results. Thus, we conclude that the RSMOTE is a more flexible resampling method for the imbalanced medical datasets that is capable of generating samples with various minority sample densities.




Similar content being viewed by others


References
Paiva JS, Cardoso J, Pereira T. Supervised learning methods for pathological arterial pulse wave differentiation: a svm and neural networks approach. Int J Med Inform. 2018;109:30–8.
Srivastava SK, Singh SK, Suri JS. Healthcare text classification system and its performance evaluation: A source of better intelligence by characterizing healthcare text. J Med Syst. 2018;42(5):97.
Al-Shammari A, Liu C, Naseriparsa M, Vo BQ, Anwar T, Zhou R. A framework for clustering and dynamic maintenance of xml documents. In: International Conference on Advanced Data Mining and Applications, Springer, New York; 2017. pp. 399–412.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res. 2002;16:321–57.
Al-Shammari A, Zhou R, Liu C, Naseriparsa M, Vo BQ. A framework for processing cumulative frequency queries over medical data streams. In: International Conference on Web Information Systems Engineering, Springer; 2018. pp. 121–131.
He H, Garcia EA. Learning from imbalanced data. IEEE Trans Knowl Data Eng. 2009;21(9):1263–84.
Batista GEAPA, Prati RC, Monard MC. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. 2004;6(1):20–9.
Maciejewski T, Stefanowski J. Local neighbourhood extension of SMOTE for mining imbalanced data, In: Proceedings of the IEEE symposium on computational intelligence and data mining, CIDM 2011, April 11–15, 2011, Paris, France, 2011; pp. 104–111.
Chawla NV, Japkowicz N, Kotcz A. Editorial: special issue on learning from imbalanced data sets. SIGKDD Explor. 2004;6(1):1–6.
Yang S, Guo J-Z, Jin J-W. An improved id3 algorithm for medical data classification. Comput Electr Eng. 2018;65:474–87.
Al-Shammari A, Zhou R, Naseriparsaa M, Liu C. An effective density-based clustering and dynamic maintenance framework for evolving medical data streams. Int J Med Informatics. 2019;126:176–86.
Zarchi M, Bushehri SF, Dehghanizadeh M. Scadi: a standard dataset for self-care problems classification of children with physical and motor disability. Int J Med Informatics. 2018;114:81–7.
World Health Organisation, https://www.who.int/, Accessed 20 Nov 2018.
Lynch CM, Abdollahi B, Fuqua JD, Alexandra R, Bartholomai JA, Balgemann RN, van Berkel VH, Frieboes HB. Prediction of lung cancer patient survival via supervised machine learning classification techniques. Int J Med Inform. 2017;108:1–8.
Sanchez-Pinto LN, Venable LR, Fahrenbach J, Churpek MM. Comparison of variable selection methods for clinical predictive modeling. Int J Med Inform. 2018;116:10–7.
Araújo FH, Santana AM, Neto PAS. Using machine learning to support healthcare professionals in making preauthorisation decisions. Int J Med Inform. 2016;94:1–7.
Chebouba L, Boughaci D, Guziolowski C. Proteomics versus clinical data and stochastic local search based feature selection for acute myeloid leukemia patients’ classification. J Med Syst. 2018;42(7):129.
Han H, Wang W, Mao B. Borderline-smote: a new over-sampling method in imbalanced data sets learning. In: Advances in Intelligent Computing, International Conference on Intelligent Computing, ICIC 2005, Hefei, China, August 23–26, 2005, Proceedings, Part I, 2005; pp. 878–887.
Sáez JA, Luengo J, Stefanowski J, Herrera F. SMOTE-IPF: addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering. Inf Sci. 2015;291:184–203.
Cheng K, Zhang C, Yu H, Yang X, Zou H, Gao S. Grouped SMOTE with noise filtering mechanism for classifying imbalanced data. IEEE Access. 2019;7:170668–81.
Fahrudin T, Buliali JL, Fatichah C. Enhancing the performance of smote algorithm by using attribute weighting scheme and new selective sampling method for imbalanced data set. Int J Innov Comput Inf Control. 2019;15:423–44.
Sáez JA, Luengo J, Stefanowski J, Herrera F. Managing borderline and noisy examples in imbalanced classification by combining SMOTE with ensemble filtering. In: Intelligent Data Engineering and Automated Learning - IDEAL 2014, 15th International Conference, Salamanca, Spain, September 10–12, 2014. Proceedings, Vol. 8669 of Lecture Notes in Computer Science, Springer; 2014. pp. 61–68.
Bunkhumpornpat C, Sinapiromsaran K, Lursinsap C. Safe-level-smote: safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem, in: Advances in Knowledge Discovery and Data Mining, 13th Pacific-Asia Conference, PAKDD 2009, Bangkok, Thailand, April 27–30, 2009, Proceedings; 2009. pp. 475–82.
Weiss GM. Mining with rarity: a unifying framework. SIGKDD Explor. 2004;6(1):7–19.
Chawla NV, Lazarevic A, Hall LO, Bowyer KW. Smoteboost: Improving prediction of the minority class in boosting. In: Proceedings of the 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Knowledge Discovery in Databases: PKDD 2003, Cavtat-Dubrovnik, Croatia, September 22–26, 2003, 2003; pp. 107–19.
Sun Y, Kamel MS, Wong AKC, Wang Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recogn. 2007;40(12):3358–78.
Chawla NV. Data mining for imbalanced datasets: an overview. In: Maimon O, Rokach L, editors. The data mining and knowledge discovery handbook. New York: Springer; 2005. p. 853–67.
Fawcett T. An introduction to ROC analysis. Pattern Recogn Lett. 2006;27(8):861–74.
UCI machine learning repository. http://archive.ics.uci.edu/ml/, accessed 7 Feb 2018.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Naseriparsa, M., Al-Shammari, A., Sheng, M. et al. RSMOTE: improving classification performance over imbalanced medical datasets. Health Inf Sci Syst 8, 22 (2020). https://doi.org/10.1007/s13755-020-00112-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13755-020-00112-w