
Abstract
In this study, we will propose a density estimation based data analysis procedure to investigate the co-morbid associations between migraine and the suspected diseases. The primary objective of this study has aimed to develop a novel analysis procedure that can discover insightful knowledge from large medical databases. The entire analysis procedure consists of two stages. During the first stage, a kernel density estimation algorithm named relaxed variable kernel density estimation (RVKDE) is invoked to identify the samples of interest. Then, in the second stage, a density estimation algorithm based on generalized Gaussian components and named G2DE is invoked to provide a summarized description of the distribution. The results obtained by applying the proposed two-staged procedure to analyze co-morbidities of migraine revealed that the proposed procedure could effectively identify a number of clusters of samples with distinctive characteristics. The results further revealed that the distinctive characteristics of the clusters extracted by the proposed procedure were in conformity with the observations reported in recently published articles. Accordingly, it is conceivable that the proposed analysis procedure can be exploited to provide valuable clues of pathogenesis and facilitate development of proper treatment strategies.
Similar content being viewed by others

1 Introduction
In recent years, data analysis based on large medical and clinical databases has gained attention among biomedical researchers (Himes et al. 2009; Lai et al. 2010; Lugardon et al. 2007). One major merit of this type of studies is that these databases collect cases with good demographic diversity. In addition, researchers can expeditiously verify their hypotheses since they do not need to spend a significant amount of efforts to recruit cases. Nevertheless, most studies have been conducted with conventional bio-statistical approaches. Accordingly, scientists have turned to exploit advanced machine learning and/or data mining approaches to extract valuable clues hidden in large medical and clinical databases (Himes et al. 2009; Lancashire et al. 2005; Li et al. 2004; Niederkohr and Levin 2005). For example, the Bayesian network has been exploited to identify the co-morbidity between chronic obstructive pulmonary disease and asthma (Himes et al. 2009). Furthermore, the decision tree algorithm has been exploited to guide diagnostic interpretation and therapeutic options for temporal arteritis (Niederkohr and Levin 2005).
In our study, we have aimed to exploit density estimation algorithms in the analysis of large medical/clinical databases. Density estimation is a classical problem in statistics aimed at constructing an approximate probability density function based on the samples randomly and independently taken from an underlined distribution. In the proposed approach, we have exploited the relaxed variable kernel density estimation (RVKDE) algorithm (Oyang et al. 2005) and the generalized Gaussian component based density estimation (G2DE) algorithm (Hsieh et al. 2009) that our research team has developed in recent years. The RVKDE algorithm has been exploited to identify those case samples that share some distinctive features in comparison with the control samples. Then, the G2DE algorithm has been invoked to provide a summarized and highly interpretable description of the underlying distribution.
In our study, aiming to learn the actual effects of the proposed analysis procedure, we have applied the proposed procedure to analyze co-morbidities of migraine. Migraine is a prevalent neurological disorder whereby patients suffer from recurrent headache attacks, nausea, photophobia, and phonophobia. Recent demographical studies showed that migraine was more common to women than to men and its burden has been underestimated. Many illnesses, physical or psychiatric, have been reported to be co-morbid with migraine (Aamodt et al. 2007; Bigal et al. 2010; Buse et al. 2010; Hagen et al. 2002; Kurth et al. 2008; Le et al. 2011); these disorders occur at a greater coincidental rate among migraine patients than among the general population. Understanding the association of migraine with other health conditions can help the clinicians providing better care and investigate the pathogenesis of these disorders.
2 Methods
2.1 Density estimation algorithms
In this section, we will elaborate the main features of the RVKDE algorithm and the G2DE algorithm exploited in the proposed analysis procedure and the desired effects achieved. Basically, the RVKDE algorithm was designed to construct an approximate probability density function with high accuracy. On the other hand, the G2DE algorithm was designed to provide a summarized and highly interpretable description of the underlying distribution.
Let {s 1, s 2, …, s n } be a set of samples randomly and independently taken from the distribution governed by probability density function f in a d-dimensional vector space. Then, the RVKDE algorithm constructs an approximate probability density function \( \hat{f} \) based on the following general form:
where \( \sigma_{i} = \beta \frac{{R(s_{i} )\sqrt \pi }}{{\root{d} \of {{(k + 1)\Upgamma (\tfrac{d}{2} + 1)}}}} \), R(s i ) is the maximum distance between s i and its k nearest training instances; Γ(·) is the gamma function (Artin 1964); β and k are parameters to be set either through cross validation or by the user.
The general form of the RVKDE algorithm indicates that, for each sample, a Gaussian function is placed at its corresponding coordinates in the vector space. Accordingly, the approximate function constructed by the RVKDE algorithm is composed of a large number of Gaussian functions and it is difficult for a user to gain an abstract image of the underlying distribution in a multiple-dimension vector space. Therefore, our research team has designed the G2DE algorithm to provide the complementary feature. The approximate function constructed by the G2DE algorithm is composed of a limited number of generalized Gaussian components as shown in the following:
where \( {\text{GGC}}\; (w_{i} ,\mu_{i} ,\Upsigma_{i} )= w_{i} \frac{1}{{\left| {\Upsigma_{i} } \right|^{1/2} }}\exp \left( { - \frac{1}{2}(v - \mu_{i} )^{T} \sum\nolimits_{i}^{ - 1} {(v - \mu_{i} )} } \right) \), d is the dimension of the vector space, \( w_{i} ,\mu_{i} ,\;{\text{and}}\;\Upsigma_{i} \) are the weight, center, and the covariance matrix of the i-th Gaussian component, respectively.
Since each Gaussian component in a G2DE based probability model corresponds to a cluster of samples, we can examine the centers and the covariance matrices of the Gaussian components to obtain an abstract image of the underlying distribution. Nevertheless, it must be noted that the number of parameters in a G2DE based probability model is equal to \( \frac{k(d + 2)(d + 1)}{2} \). As a result, if we do not set k and d to small integers, then we need to examine a large number of parameter values and it may be difficult for us to interpret the physical meanings of the parameter values.
2.2 The clinical database
The study reported in this article has been conducted based on the Research Database released by the National Health Insurance Program in Taiwan. The National Health Insurance (NHI) program in Taiwan was launched in 1995 and as in December 2010 covered about 23,074,000 insurants, which accounted for over 99 % of the entire population in Taiwan. In addition, almost all medical hospitals and clinics in Taiwan have joined the program. As in December 2010, there were 25,031 medical institutes enrolled in the program. Since 2000, the Bureau of the program began to release the National Health Insurance Research Database (NHIRD) to facilitate medical research. The updated version used in this study contains the ambulatory and hospitalization claims records of 1,000,000 randomly selected insurants over the period from 1996 to 2010 without significant difference in age, sex, and insurance cost relative to the whole population.
2.3 Case patient definition and control selection
The cases in this study include those patients who were diagnosed with migraine in outpatient and/or inpatient records during 2004–2008. The ICD-9 CM codes (International Classification of Disease, 9th Revision, Clinical Modification; http://icd9cm.chrisendres.com/) used for screening include 346.0×, 346.1×, 346.8×, and 346.9×, which correspond to patients with migraine with or without aura. In our study, for each migraine case, five controls without any migraine record during 1996–2010 and with matched gender and age were randomly selected from the NHIRD. As a result, the cohort contained 19,356 migraine cases and 96,780 controls. For a case, the date of the first migraine diagnosis was defined to be the index date and the same index date was assigned to the matched controls.
2.4 Medication exposure utilized as features
In our analysis, each cohort subject was associated with a feature vector that recorded the exposure of the subject to the commonly used medications for migraine treatment during the study period, including amitriptyline, flunarizine, propranolol, topiramate, and valproic acid. The exposure was measured by the number of days and the dosage in milligrams. The dosage was also calculated in defined daily dose (DDD) by World Health Organization (http://www.whocc.no/atc_ddd_index/) for validation. The exposure to each category of medications was counted separately. Accordingly, the feature vector is composed of ten elements. In our analysis, we further normalized the feature values corresponding to the same element in the feature vector by applying the standard min–max normalization.
The five categories of drugs for migraine treatment mentioned above all belong to preventive medicines. Aiming to validate drug medications of our study population, we also analyzed the prescription orders for ergotamine during the study period, which is a frequent relief treatment of migraine attacks.
2.5 Diseases utilized as outcomes
Our study focused on those diseases that had been reported to be the co-morbidities of migraine (Aamodt et al. 2007; Bigal et al. 2010; Buse et al. 2010; Hagen et al. 2002; Le et al. 2011). These diseases can be classified into six categories as follows based on the ICD-9 CM codes:
-
1.
Mental disorders: alcohol abuse (ICD-9 CM codes: 265.2, 291.xx, 303.xx, 305.0x, 357.5, 425.5, 535.3x, 571.0, 571.1, 571.3, 980.x, and V113); anxiety state (codes: 300.00, 300.02, and 300.09); bipolar disorder (codes: 296.0x, 296.1x, 296.4x, and 296.6x–296.9x); depression (codes: 296.2x, 296.3x, 296.5x, 300.4, 309.xx, and 311); drug abuse (codes: 292.xx, 304.xx, 305.2x–305.9x, and V6542); psychoses (codes: 293.8x, 295.xx, 297.x, and 298.x)
-
2.
Otolaryngology: allergic rhinitis (ICD-9 CM codes: 477.x); chronic pulmonary disease (codes: 490–496, 500–505, and 506.4); Meniere’s disease (codes: 386.0x)
-
3.
Musculoskeletal illnesses: low back pain (ICD-9 CM codes: 724.xx); neck pain (code: 723.1); neck sprain (code: 847.0); pain syndrome (codes: 719.4x and 729.1); rheumatoid arthritis (codes: 446.x, 701.0, 710.2, 710.3, 710.8, 710.9, 711.2x, 714.3x, 714.4, 714.89, 714.9, 719.3x, 720.xx, 728.5, 728.89, and 729.30); spinal disk herniation (codes: 722.0–722.2, and 722.7x);
-
4.
Metabolism and endocrinology: diabetes mellitus (ICD-9 CM codes: 250.0x–250.3x, and 250.7x); fluid electrolyte disorder (codes: 253.6 and 276.x); hyperlipidemia (codes: 272.x); hypothyroidism (codes: 240.9, 243, 244.x, 246.1, and 246.8); obesity (codes: 278.0x);
-
5.
Cardiovascular and neurological diseases: cardiac arrhythmias (ICD-9 CM codes: 426.0, 426.1x, 426.7, 426.9, 427.0–427.4x, 427.6x, 427.8x, 427.9, 785.0, 996.01, 996.04, V45.0x, and V53.3x); cerebrovascular disease (codes: 430–438.xx); coronary artery disease (codes: 410.xx–414.xx); heart failure (codes: 428.x); hypertension (codes: 401.x); peripheral vascular disease (codes: 441.9, 443.9, 785.4, and V434); epilepsy (codes: 345.xx)
-
6.
Gastroenterology and hepatology: kidney stone (ICD-9 CM codes: 592.0); liver disease (codes: 571.2, 571.4x–571.6); peptic ulcer disease (codes: 531.xx–534.xx); renal disease (codes: 582.xx, 583.0–583.2, 583.4, 583.6, 583.7, 585, 586, and 588.x).
For each subject, outpatient and/or inpatient diagnoses of these disorders during the study period would be analyzed. Demographics and clinical variables were compared between migraine cases and controls using the Chi-square test or student’s t test when appropriate. We have employed the odds ratio (OR) with 95 % confidence interval to quantify the risk of a co-morbidity of migraine in different groups of patients. All tests were two-tailed, and p values of <0.05 were considered significant.
2.6 The analysis procedure
The analysis procedure consists of two stages. During the first stage, the RVKDE algorithm was invoked to construct one approximate probability density function for the cases, denoted by \( \hat{f} \), and another probability density function for the controls, denoted by \( \hat{f}^{\prime } \). Then, all the cases were examined one by one. Let \( {\mathbf{s}}_{i} \) denote the feature vector corresponding to the i-th case in the dataset. If \( \hat{f}({\mathbf{s}}_{i} )/\hat{f}^{\prime } ({\mathbf{s}}_{i} ) \) is greater than a threshold, then the case was labeled as sample of interest. As mentioned earlier, this screening process aimed to identify those cases that shared some distinctive features in comparison with the controls.
During the second stage, the G2DE algorithm was invoked to cluster the cases of interest and provided summarized descriptions of the clusters. However, as mentioned earlier, the number of features, which correspond to the dimension of the vector space and thus the dimension of the covariance matrix output by the G2DE algorithm, should be limited to a small integer for us to easily obtain an abstract image of the underlying distribution. Accordingly, we incorporated a feature selection process before invoking the G2DE algorithm. The feature selection process proceeded as follows. First, the correlation matrix of the original ten features is derived based on the cases of interest identified in the first stage of analysis. Then, those eigenvectors with the corresponding eigenvalue larger than 1 are selected to form the factor space. Finally, the factor space is rotated orthogonally and the component features of the rotated factors with a loading larger than 0.4 are selected to form a subspace into which the original dataset is projected.
3 Results
Table 1 shows the demographics of the entire dataset, which includes 19,356 migraine cases and 96,780 controls. As expected, the distributions of ages and genders are identical among migraine cases and controls. Furthermore, both for preventive medicines (i.e., amitriptyline, flunarizine, propranolol, topiramate, and valproic acid) and relief treatment of migraine (i.e., ergotamine), case patients have significant higher proportions of utilization than control samples. However, for propranolol, topiramate, and valproic acid, case patients have lower exposure dosages and durations. It is observed that the mean prescription dosage of migraine medication in the current study follows the corresponding DDD (≤1 DDD per day).
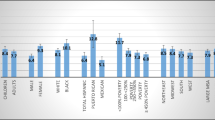
Figure 1 shows the results obtained with the conventional analysis procedure, i.e., without invoking the proposed density estimation-based procedure. The blue bars show the relative risks of suffering co-morbidities among migraine cases and controls. The odds ratios with respect to the following co-morbidities are: alcohol abuse 1.8/1.67, anxiety state 3.14/3.36, bipolar disorder 2.11/2.6, depression 3.2/3.53, drug abuse 2.96/4.17, psychoses 1.53/1.5, allergic rhinitis 2.19/2.34, chronic pulmonary disease 1.94/1.84, Meniere’s disease 4.03/3.89, low back pain 2.07/2.04, neck pain 2.58/2.78, neck sprain 2.25/2.18, pain syndrome 2.28/2.25, rheumatoid arthritis 2.03/2.13, spinal disk herniation 2.21/2.39, diabetes mellitus 1.16/1.15, fluid electrolyte disorder 1.78/1.56, hyperlipidemia 1.6/1.6, hypothyroidism 1.61/1.77, obesity 1.73/1.94, cardiac arrhythmias 2.17/2.03, cerebrovascular disease 2.55/2.34, coronary artery disease 1.82/1.77, heart failure 1.49/1.34, hypertension 1.6/1.61, peripheral vascular disease 2.09/2.25, epilepsy 2.74/2.42, kidney stone 1.92/1.83, liver disease 1.74/1.74, peptic ulcer disease 2.33/2.33, and renal disease 1.5/1.45. The data presented in Fig. 1 reveal that migraine patients were more likely than age- and sex-matched controls to suffer these illnesses. Please refer to Supplementary Table 1 for more detailed statistics.

Relative risks of co-morbidities among migraine cases and controls a for the study period of 24 months before the index date, and b for the study period of 12 months after the index date. The blue bars represent values for original subjects, and the red bars represent values for samples of interest (color figure online)
The red bars in Fig. 1 with the detailed data in Supplementary Table 2 show the relative risks of suffering co-morbidities between the migraine cases classified as samples of interest during the first stage of the proposed analysis procedure and their age- and sex-matched controls. In this respect, the RVKDE algorithm identified 7,146 migraine patients as samples of interest. Based on the data shown in Fig. 1 and the statistics shown in Supplementary Tables 1 and 2, we can conclude that those migraine cases of interest suffered even higher risks of co-morbidities.
According to the demographics shown in Table 2, the 7,146 cases of interest have lower male proportion than the remaining 12,210 migraine cases (24.8 vs. 29.1 %; p < 0.001). Moreover, the mean age of the cases of interest is older than the mean age of the remaining migraine cases, 45.3 versus 41.8 with p value <0.001. For both preventive medicines and relief treatment of migraine, cases of interest have significant higher utilization proportions than the remaining migraine patients. However, for topiramate and valproic acid, the cases of interest have lower exposure dosages and durations. Figure 2 and Supplementary Table 3 show the relative risks of co-morbidities among the cases of interest and the remaining migraine cases. We observed that the cases of interest suffered higher risks of co-morbidities than the remaining migraine patients.

Relative risks of co-morbidities among cases of interest and the remaining migraine cases for the study period of 24 months before the index date (blue bars), and for the study period of 12 months after the index date (red bars) (color figure online)
Since Figs. 1 and 2 (and Supplementary Tables 2, 3) confirm that the first stage of the proposed analysis procedure successfully identified a subset of migraine cases who suffered higher risks of developing co-morbidities according to characteristics of medication exposure, it is highly desirable to conduct an in-depth analysis. Accordingly, in the second stage of the proposed analysis procedure, the G2DE algorithm was invoked to identify the main clusters among the 7,146 cases of interest. As mentioned earlier, before invoking the G2DE algorithm, factor analysis was carried out to identify the most informative features. In this respect, it must be noted that the set of cases of interest passed the two criteria commonly adopted to measure the adequacy of applying factor analysis. In fact, applying the Kaiser–Meyer–Olkin (KMO) test on the set of cases of interest yielded a value of 0.502, which is higher than the commonly adopted threshold of 0.5, and applying the Bartlett’s test yielded a value smaller than 0.001, which is significant for variance homogeneity. The end result of the factor analysis is that exposure dosages (in unit of milligram) for the five preventive medicines of migraine: amitriptyline, flunarizine, propranolol, topiramate, and valproic acid, were selected respectively.
The G2DE algorithm identified two clusters with distinctive characteristics shown in Table 3. Comparing the cases in cluster 0 and cluster 1, we can find that the cases in cluster 1 were generally older (52.5 vs. 44.7 with p value <0.001) but they have almost the same gender distribution. Furthermore, for both preventive medicines and relief treatment of migraine attacks, the case samples in cluster 1 had significant larger exposure dosages and longer durations. According to the results shown in Fig. 3 and Supplementary Table 4, cases in cluster 1 had higher risks of suffering mental disorders [odds ratio (OR): alcohol abuse 2.31/2.77, anxiety state 2.68/1.81, bipolar disorder 5.12/5.27, depression 2.57/2.5, drug abuse 5.26/6.02, and psychoses 4.22/3.61], diabetes mellitus (OR = 2.1/2.09), fluid electrolyte disorder (OR = 2.51/2.59), and cardiovascular/neurological diseases (OR: cardiac arrhythmias 1.77/1.63, cerebrovascular disease 2.26/2.38, coronary artery disease 2.11/1.83, hypertension 2.4/2.34, and epilepsy 3.55/3.88).

Relative risks of co-morbidities among the clusters identified by G2DE for the study period of 24 months before the index date (blue bars), and for the study period of 12 months after the index date (red bars) (color figure online)
4 Discussions
4.1 Co-morbidities of migraine
According to the results shown in Fig. 1 and Supplementary Table 1, our study confirms co-morbid relationships between migraine and various diseases even without carrying out the screening process to identify samples of interest. In our study, the diseases included for co-morbidity analysis can be classified into six categories.
4.1.1 Mental disorders
The correlation between mental disorder and migraine has been studied extensively in recent years and our results match the previous observations. The American Migraine Prevalence and Prevention (AMPP) study demonstrated that both depression (OR = 2.0) and anxiety (OR = 1.8) were included in the co-morbidity profiles of chronic migraine and episodic migraine patients (Buse et al. 2010). Based on the Italian version of the Mini International Neuropsychiatry Interview (MINI), Beghi et al. (2010) reported that significant proportions of depression and moderate proportions of anxiety were among migraine and tension-type headache patients. Dilsaver et al. (2009) showed the association between bipolar disorder and migraine by observing that patients with a family history of bipolar disorder were 4.38 (OR = 4.38) times more likely to have migraine headaches than those without. A recent questionnaire survey revealed that migraine was far more prevalent in the substance abusers, e.g., alcohol, benzodiazepine, or opioids (Beckmann et al. 2012). Because of distinctness for study designs and data sources, we might not directly compare our quantitative results with benchmark values from literatures. Nevertheless, our results in Fig. 1 and Supplementary Table 1 confirm that migraine patients are more likely than controls to suffer mental disorders, which is in conformity with the observations reported in previous studies. Shared serotonergic dysfunction between migraine and affective disorders may contribute these associations.
4.1.2 Otolaryngology
The association between migraine and asthma has still been under debate. The Head-HUNT study showed that both migraine and non-migrainous headache were 1.5 times (OR = 1.5) more prevalent among those with asthma than those without (Aamodt et al. 2007). On the contrary, another study showed that the risk of developing follow-up incident asthma was not materially higher for migraine patients (Becker et al. 2008). Our results support the co-morbid associations between migraine and allergic rhinitis (OR = 2.19/2.34) as well as chronic pulmonary disease (OR = 1.94/1.84). Recent evidence has suggested that activation and sensitization of primary afferent meningeal nociceptive neurons trigger migraine attacks and the triggering factor is the involvement of mast cells (Levy et al. 2006). These findings may explain why allergic nasal symptoms accompany migraine. Finally, it has been reported that patients with Meniere’s disease suffered higher prevalence of migraine and Meniere’s disease patients with migraine suffered more severe vertigo or hearing loss (Cha et al. 2007). Again, the results from our population-based study are in conformity with these findings.
4.1.3 Musculoskeletal illnesses
The Nord-Trondelag Health Survey found that prevalence of chronic headache was 4.6 times (OR = 4.6) higher among individuals with musculoskeletal symptoms than among those without (Hagen et al. 2002). Similarly, 92 Israeli consecutive patients with migraine from a tertiary headache clinic suffered high incidence of fibromyalgia syndrome (Ifergane et al. 2006). In addition, the National Health Examination and Nutrition Survey (NHANES) showed adults with headache/migraine suffered increased odds of rheumatoid arthritis (OR = 1.95) (Kalaydjian and Merikangas 2008). Our results in Fig. 1 and Supplementary Table 1 confirm the co-morbid associations between migraine and various musculoskeletal illnesses.
4.1.4 Metabolism and endocrinology
Results of any significant association between migraine and diabetes are conflicting: some showed co-morbidity (OR = 1.4) (Bigal et al. 2010), some not (Le et al. 2011), and yet the other reported an inverse association (Burn et al. 1984). This debate may be why our results only show a slight co-morbid association between migraine and diabetes mellitus (OR = 1.16/1.15). Similarly, the International Headache Society (IHS) Classification of Headache Disorders Second Edition includes “Headache attributed to hypothyroidism”, and it was observed that approximately 30 % of 102 hypothyroid patients had bilateral, continuous headache (Moreau et al. 1998). Our observations also support this conclusion (OR = 1.61/1.77), but another population-based study obtained a conflicting result with negative correlation (OR = 0.5) (Hagen et al. 2001). Elevated levels of cholesterol (OR = 5.97) and triglycerides (OR = 4.42) had ever been reported to be associated with migraine (Rist et al. 2011), but there is no direct significant association between electrolyte imbalance and migraine as far as we are concerned to support our results (OR = 1.78/1.56). Finally, one epidemiologic study found the positive association between migraine and obesity (Peterlin et al. 2010). This suggestion is also supported by our analyses (OR = 1.73/1.94) while another population-based study disputed the association (OR = 1.03) (Winter et al. 2009).
4.1.5 Cardiovascular and neurological diseases
For over one decade, it has been a consensus among biomedical scientists that migraine increases atherosclerosis risk and ignites cardiovascular disorders such as instance angina, ischemic heart disease (OR = 1.94–2.2), and stroke (OR = 1.5–5.46) (Bigal et al. 2010; Kurth et al. 2008; Stang et al. 2005). Schurks et al. (2008) suggested that the MTHFR 677TT genotype magnifies risk of cardiovascular disease among migraine patients. Bigal et al. (2010) demonstrated a higher cardiovascular risk profile among migraine patients with higher cholesterol and blood pressure level. On the other hand, the co-morbidity between migraine and epilepsy has been suggested in one recent Dutch study (OR = 1.39) (Nuyen et al. 2006). The linkage between epilepsy and visual aura migraine possibly results from a gene defect located at chromosome 9q21–q22 (Deprez et al. 2007). In our population-based study, all these cardiovascular/neurological illnesses were prevalent among migraine patients than among matched controls.
4.1.6 Gastroenterology and hepatology
One recent study has concluded that kidney stone is a co-morbidity of migraine (OR = 1.43) (Le et al. 2011), which coincides with our analyses (OR = 1.92/1.83). It was suggested that topiramate dosage, which is commonly used for migraine preventive treatment, was inversely correlated to urinary citrate excretion and led to increased risk of stone-forming (Kaplon et al. 2011). On the other hand, Helicobacter pylori infection might be both causes of hepatic encephalopathy and migraine symptoms in patients with cirrhosis (Hong et al. 2007). Although non-steroidal anti-inflammatory drugs, which are the symptomatic relief of headache and migraine, may be ulcer-causing medications, peptic ulcer disease did not have a high prevalence in the US headache patients (Rozen and Fishman 2012). This is contradictory to our observations for the co-morbid relation between migraine and peptide-ulcer disease (OR = 2.33), and prescriptions for drugs of headache relief without the side effect of ulcer may explain this difference. Finally, increased plasma concentrations of endothelin-1 had been described in both migraine and renal disease patients; this might be the reason for their co-morbid association (Noll et al. 1996).
4.2 Analysis results of density estimation
The co-morbid associations of migraine and various kinds of illnesses can be observed in Fig. 1 and Supplementary Table 1. However, no matter comparing the 7,146 migraine patients of interest extracted by RVKDE to their 35,730 age- and sex-matched controls, or to the remaining 12,210 migraine cases, they were even more likely to suffer these co-morbid illnesses. Our study verifies the effectiveness of density estimation algorithms on medical information analyses. The extracted migraine “patients of interest” had higher utilization proportions of both preventive medicines and relief treatment for migraine than the filtered cases. Because migraine is a common chronic, recurrent condition, it is believed that patients with significant medication utilization are more representative for this disease. Since some of the co-morbid illnesses studied belong to the Charlson (Charlson et al. 1987) or Elixhauser index (Elixhauser et al. 1998), it is suggested that physicians screen these patients for further risks of poor health conditions.
Moreover 489 of the 7,146 migraine cases of interest could be identified by G2DE according to the characteristics of medication exposures for migraine. Although for flunarizine and ergotamine, the selected 489 cases and the remaining 6,657 ones did not show significant differences in utilization proportions, these migraine patients had larger exposure dosages and longer durations for all kinds of drugs studied. This can be treated as a migraine severity measurement. According to the results shown in Fig. 3 and Supplementary Table 4, exposure dosage/duration of medicines discriminates best for the mental disorders and cardiovascular/neurological diseases. It was observed that the worse the pain profile, the worse the physical functioning and mental health (Wang et al. 2001). So our results are in conformity with the previous conclusions.
Although conventional algorithms of regression analysis are applicable for data mining in medical and/or clinical information, they borrow the idea from multi-dimensional contingency table to determine certain associations between the dependent variable and the risk factors. Rather than fitting a more saturated model, it might be more inclined to reflect an interaction structure between the dependent variables and corresponding risk factors. However, in this research, we would like to refer the concept of discriminate analysis: classifying an object that comes from one of two populations having associated densities f1 and f2 could be based upon the likelihood ratio f1/f2. It is expected that the significant difference between density distributions represents variances of the dependent variables in distinct groups of independent variable, e.g., an overall migraine severity measurement quantified by synergistic medication exposures. In fact, we ever categorized the migraine patients of interest as the contingency table by age, but this clustering cannot discriminate mental disorders the way G2DE can (data are not shown). So the proposed density estimation-based analysis procedure conceivably provides valuable insights which might be overlooked by conventional methods.
4.3 Limitations
A major strength of our study was utilization of a large population-based medical claims database, but there were some limitations. First, administrative claims reported by hospitals or clinics may be less accurate than clinical diagnoses and observer-rating scales. Second, prescriptions of medications for migraine do not guarantee drug adherence. Third, the administrative claims data of NHIRD did not include detailed personal information like body mass index, living habits, or results of laboratory tests, which might be important confounding factors. Finally, more confounding factors of the outcome diseases, e.g., age, sex, medication drugs, treatment procedures, or associated symptoms, should be taken into account.
5 Conclusions
In recent years, data analysis based on large medical and clinical databases has gained attention among biomedical researchers. Furthermore, scientists have turned to exploit advanced machine learning and/or data mining approaches to extract valuable clues hidden in large medical and clinical databases. In this paper, we have proposed a density estimation-based data analysis procedure to investigate the co-morbid associations between migraine and the suspected diseases by characteristics of medication exposure. The primary objective of this study is to develop a novel analysis procedure that can discover insightful knowledge from large medical databases. The results obtained by applying the proposed two-staged procedure to analyze co-morbidities of migraine reveal that the proposed procedure can effectively identify a number of clusters of cases with distinctive characteristics. Furthermore, it has been observed that the distinctive characteristics of the clusters are in conformity with the recently discovered knowledge in biomedical research. Accordingly, it is conceivable that the proposed analysis procedure will be exploited to provide valuable clues of pathogenesis and facilitate development of proper treatment strategies.
Three further courses are undertaken. Firstly, since effectiveness of the proposed analysis procedure has been verified, this method will be exploited to investigate characteristics of more epidemics, such as osteoporosis or herpes zoster. Secondly, appropriate statistical tests will be issued on the mined facts to strengthen persuasiveness of this approach. Finally, application of various advanced machine learning/data mining algorithms on medical and/or clinical databases will also be studied.
References
Aamodt AH, Stovner LJ, Langhammer A, Hagen K, Zwart JA (2007) Is headache related to asthma, hay fever, and chronic bronchitis? Head-HUNT Study Headache 47(2):204–212. doi:10.1111/j.1526-4610.2006.00597.x
Artin E (1964) The gamma function. Holt, Rinehart
Becker C, Brobert GP, Almqvist PM, Johansson S, Jick SS, Meier CR (2008) The risk of newly diagnosed asthma in migraineurs with or without previous triptan prescriptions. Headache 48(4):606–610. doi:10.1111/j.1526-4610.2007.01030.x
Beckmann YY, Seckin M, Manavgat AI, Zorlu N (2012) Headaches related to psychoactive substance use. Clin Neurol Neurosurg. doi:10.1016/j.clineuro.2012.02.041
Beghi E, Bussone G, D’Amico D, Cortelli P, Cevoli S, Manzoni GC, Torelli P, Tonini MC, Allais G, De Simone R, D’Onofrio F, Genco S, Moschiano F, Beghi M, Salvi S (2010) Headache, anxiety and depressive disorders: the HADAS study. J Headache Pain 11(2):141–150. doi:10.1007/s10194-010-0187-2
Bigal ME, Kurth T, Santanello N, Buse D, Golden W, Robbins M, Lipton RB (2010) Migraine and cardiovascular disease: a population-based study. Neurology 74(8):628–635. doi:10.1212/WNL.0b013e3181d0cc8b
Burn WK, Machin D, Waters WE (1984) Prevalence of migraine in patients with diabetes. Br Med J (Clin Res Ed) 289(6458):1579–1580
Buse DC, Manack A, Serrano D, Turkel C, Lipton RB (2010) Sociodemographic and comorbidity profiles of chronic migraine and episodic migraine sufferers. J Neurol Neurosurg Psychiatry 81(4):428–432. doi:10.1136/jnnp.2009.192492
Cha YH, Brodsky J, Ishiyama G, Sabatti C, Baloh RW (2007) The relevance of migraine in patients with Meniere’s disease. Acta Otolaryngol 127(12):1241–1245. doi:10.1080/00016480701242469
Charlson ME, Pompei P, Ales KL, MacKenzie CR (1987) A new method of classifying prognostic comorbidity in longitudinal studies: development and validation. J Chronic Dis 40(5):373–383
Deprez L, Peeters K, Van Paesschen W, Claeys KG, Claes LR, Suls A, Audenaert D, Van Dyck T, Goossens D, Del-Favero J, De Jonghe P (2007) Familial occipitotemporal lobe epilepsy and migraine with visual aura: linkage to chromosome 9q. Neurology 68(23):1995–2002. doi:10.1212/01.wnl.0000262764.78511.17
Dilsaver SC, Benazzi F, Oedegaard KJ, Fasmer OB, Akiskal HS (2009) Is a family history of bipolar disorder a risk factor for migraine among affectively ill patients? Psychopathology 42(2):119–123. doi:10.1159/000204762
Elixhauser A, Steiner C, Harris DR, Coffey RM (1998) Comorbidity measures for use with administrative data. Med Care 36(1):8–27
Hagen K, Bjoro T, Zwart JA, Vatten L, Stovner LJ, Bovim G (2001) Low headache prevalence amongst women with high TSH values. Eur J Neurol 8(6):693–699
Hagen K, Einarsen C, Zwart JA, Svebak S, Bovim G (2002) The co-occurrence of headache and musculoskeletal symptoms amongst 51 050 adults in Norway. Eur J Neurol 9(5):527–533
Himes BE, Dai Y, Kohane IS, Weiss ST, Ramoni MF (2009) Prediction of chronic obstructive pulmonary disease (COPD) in asthma patients using electronic medical records. J Am Med Inform Assoc JAMIA 16(3):371–379. doi:10.1197/jamia.M2846
Hong L, Zhao Y, Han Y, Guo W, Wang J, Li X, Fan D (2007) Reversal of migraine symptoms by Helicobacter pylori eradication therapy in patients with hepatitis-B-related liver cirrhosis. Helicobacter 12(4):306–308. doi:10.1111/j.1523-5378.2007.00512.x
Hsieh C-H, Chang DTH, Oyang Y-J (2009) Data classification with a generalized Gaussian components based density estimation algorithm. In: Proceedings of the international joint conference on neural networks, 14–19 June 2009, pp 1259–1266
Ifergane G, Buskila D, Simiseshvely N, Zeev K, Cohen H (2006) Prevalence of fibromyalgia syndrome in migraine patients. Cephalalgia 26(4):451–456. doi:10.1111/j.1468-2982.2005.01060.x
Kalaydjian A, Merikangas K (2008) Physical and mental comorbidity of headache in a nationally representative sample of US adults. Psychosom Med 70(7):773–780. doi:10.1097/PSY.0b013e31817f9e80
Kaplon DM, Penniston KL, Nakada SY (2011) Patients with and without prior urolithiasis have hypocitraturia and incident kidney stones while on topiramate. Urology 77(2):295–298. doi:10.1016/j.urology.2010.06.048
Kurth T, Schurks M, Logroscino G, Gaziano JM, Buring JE (2008) Migraine, vascular risk, and cardiovascular events in women: prospective cohort study. BMJ 337:a636. doi:10.1136/bmj.a636337/aug07_1/a636
Lai MN, Wang SM, Chen PC, Chen YY, Wang JD (2010) Population-based case–control study of Chinese herbal products containing aristolochic acid and urinary tract cancer risk. J Natl Cancer Inst 102(3):179–186. doi:10.1093/jnci/djp467
Lancashire LJ, Mian S, Ellis IO, Rees RC, Ball GR (2005) Current developments in the analysis of proteomic data: artificial neural network data mining techniques for the identification of proteomic biomarkers related to breast cancer. Curr Proteomics 2(1):15–29. doi:10.2174/1570164053507808
Le H, Tfelt-Hansen P, Russell MB, Skytthe A, Kyvik KO, Olesen J (2011) Co-morbidity of migraine with somatic disease in a large population-based study. Cephalalgia 31(1):43–64. doi:10.1177/0333102410373159
Levy D, Burstein R, Strassman AM (2006) Mast cell involvement in the pathophysiology of migraine headache: a hypothesis. Headache 46(Suppl 1):S13–S18
Li L, Tang H, Wu Z, Gong J, Gruidl M, Zou J, Tockman M, Clark RA (2004) Data mining techniques for cancer detection using serum proteomic profiling. Artif Intell Med 32(2):71–83. doi:10.1016/j.artmed.2004.03.006
Lugardon S, Roussel H, Sciortino V, Montastruc JL, Lapeyre-Mestre M (2007) Triptan use and risk of cardiovascular events: a nested-case–control study from the French health system database. Eur J Clin Pharmacol 63(8):801–807. doi:10.1007/s00228-007-0332-2
Moreau T, Manceau E, Giroud-Baleydier F, Dumas R, Giroud M (1998) Headache in hypothyroidism. Prevalence and outcome under thyroid hormone therapy. Cephalalgia 18(10):687–689
Niederkohr RD, Levin LA (2005) Management of the patient with suspected temporal arteritis a decision-analytic approach. Ophthalmology 112(5):744–756. doi:10.1016/j.ophtha.2005.01.031
Noll G, Wenzel RR, Luscher TF (1996) Endothelin and endothelin antagonists: potential role in cardiovascular and renal disease. Mol Cell Biochem 157(1–2):259–267
Nuyen J, Schellevis FG, Satariano WA, Spreeuwenberg PM, Birkner MD, van den Bos GA, Groenewegen PP (2006) Comorbidity was associated with neurologic and psychiatric diseases: a general practice-based controlled study. J Clin Epidemiol 59(12):1274–1284. doi:10.1016/j.jclinepi.2006.01.005
Oyang YJ, Hwang SC, Ou YY, Chen CY, Chen ZW (2005) Data classification with radial basis function networks based on a novel kernel density estimation algorithm. IEEE Trans Neural Netw (a publication of the IEEE Neural Networks Council) 16(1):225–236. doi:10.1109/TNN.2004.836229
Peterlin BL, Rosso AL, Rapoport AM, Scher AI (2010) Obesity and migraine: the effect of age, gender and adipose tissue distribution. Headache 50(1):52–62. doi:10.1111/j.1526-4610.2009.01459.x
Rist PM, Tzourio C, Kurth T (2011) Associations between lipid levels and migraine: cross-sectional analysis in the epidemiology of vascular ageing study. Cephalalgia 31(14):1459–1465. doi:10.1177/0333102411421682
Rozen TD, Fishman RS (2012) Cluster headache in the United States of America: demographics, clinical characteristics, triggers, suicidality, and personal burden. Headache 52(1):99–113. doi:10.1111/j.1526-4610.2011.02028.x
Schurks M, Zee RY, Buring JE, Kurth T (2008) Interrelationships among the MTHFR 677C>T polymorphism, migraine, and cardiovascular disease. Neurology 71(7):505–513. doi:10.1212/01.wnl.0000316198.34558.e5
Stang PE, Carson AP, Rose KM, Mo J, Ephross SA, Shahar E, Szklo M (2005) Headache, cerebrovascular symptoms, and stroke: the Atherosclerosis Risk in Communities Study. Neurology 64(9):1573–1577. doi:10.1212/01.WNL.0000158326.31368.04
Wang SJ, Fuh JL, Lu SR, Juang KD (2001) Quality of life differs among headache diagnoses: analysis of SF-36 survey in 901 headache patients. Pain 89(2–3):285–292
Winter AC, Berger K, Buring JE, Kurth T (2009) Body mass index, migraine, migraine frequency and migraine features in women. Cephalalgia 29(2):269–278. doi:10.1111/j.1468-2982.2008.01716.x
Acknowledgments
This research has been supported by the National Science Council and National Taiwan University.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Yang, MH., Yang, FY. & Oyang, YJ. Application of density estimation algorithms in analyzing co-morbidities of migraine. Netw Model Anal Health Inform Bioinforma 2, 95–107 (2013). https://doi.org/10.1007/s13721-013-0028-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13721-013-0028-8