
Abstract
Systems modeling represents an innovative approach for addressing the obesity epidemic at the community level. We developed an agent-based model of the Baltimore City food environment that permits us to assess the relative impact of different programs and policies, alone and in combination, and potential unexpected consequences. Based on this experience, and a review of literature, we have identified a set of principles, potential benefits, and challenges. Some of the key principles include the importance of early and multilevel engagement with the community prior to initiating model development and continued engagement and testing with community stakeholders. Important benefits include improving community stakeholder understanding of the system, testing of interventions before implementation, and identification of unexpected consequences. Challenges in these models include deciding on the most important, yet parsimonious factors to consider, how to model food source and food selection behavior in a realistic yet transferable manner, and identifying the appropriate outcomes and limitations of the model.
Similar content being viewed by others
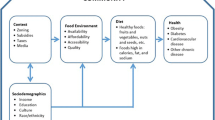

Introduction
Since the multifactorial causes and nature of obesity is well recognized, it is clear that no single community program or policy is likely to offer a comprehensive solution [1, 2]. Therefore, there is a need for multilevel, multicomponent (MLMC) interventions in the community to address obesity [3]. Such interventions, which work in many community settings simultaneously (e.g., food stores, schools, restaurants, worksites, etc.) have been shown to successfully prevent obesity [4–6]. However, MLMC interventions can be costly and challenging to design, implement, and evaluate. Communities are complex systems and interventions must plan for these complexities. Without adequate assurances, decision makers may be reluctant to try a MLMC intervention.
In many other fields, computational modeling has helped decision makers address a variety of different problems that sit in complex systems. For example, computational modeling is routinely used to help design, build, and evaluate transportation systems for cities and regions [7]. Many companies utilize simulation modeling to plan their manufacturing operations [8]. In the healthcare arena, simulation modeling has helped plan vaccine distribution and the prevention and control of infectious diseases in healthcare facilities [9–11].
What then is the potential of computational models in helping design, implement, and evaluate community-level obesity prevention and control measures? We review how computational models have been used for such interventions, use our ongoing obesity prevention trial to show the steps and key principles entailed in such applications of computational modeling, and summarize the benefits, challenges, and potential future directions of this work.
Brief Review of Obesity-Related Modeling
Compared to the use of modelling in infectious disease research, computational modeling for community-level obesity control interventions is nascent. Therefore, many of the existing models are explanatory, attempting to elucidate the mechanisms behind obesity. Some have focused on mechanisms at the genetic and physiology scales as well. For example, a model developed by Butte et al. looks at the physiological processes and energy balance within individuals that produce obesity in individuals [12]. Other recent work has aimed to delineate individual or small group behavior that produces increased obesity risk [13]. At the opposite end of the spectrum, some policy models represent very broad effects at a national level. There have been few attempts to tie these different mechanistic scales into one cohesive model. The Foresight program of UK published an obesity system map, illustrating 108 variables related to obesity and their interconnected relationships [14]. This map has been further simplified by other researchers [15, 16]. While all of these models have been helpful in elucidating mechanisms, they have not been oriented to impact and evaluate community-level decision-making and operations.
One form of modeling, agent-based models (ABMs) could help develop solutions to the obesity epidemic [17•]. ABMs include computational “agents” that can represent a person or group that act autonomously and demonstrate adaptive behavior within a virtual representation of a location or region [18]. Each agent is assigned characteristics (e.g., age, gender) and a set of behaviors and decision-making rules for interacting with other agents and the simulated environment [19••]. In the obesity field, ABMs have been developed to evaluate the effects of social norms on diet and physical activity [20] as well as the relationships between income inequalities, segregation, and healthy eating [19••]. Computational modeling has also been used to assess the effects of economic change [21] and social networks [22] on the obesity epidemic.
Developing and Utilizing a Computational Model for Community-Level Decision-Making: A Case Study in Baltimore City
To illustrate the steps, processes, and considerations involved in developing a computational model that can assist community-level decision-making, we will provide the example of the development and use of our Baltimore Low Income Food Environment (BLIFE) model, a geospatially specific agent-based model (ABM) representing low-income African American adolescents and their after school food environment in low-income neighborhoods in Baltimore City. Development of BLIFE occurred in Netlogo, a multiagent programmable modeling environment [23]. Using this model as an example, we will address the following questions:
-
1.
What key principles underlie the development of multilevel simulation models to address the obesity epidemic?
-
2.
What are the potential benefits of these models?
-
3.
What are some of the most significant challenges that must be addressed when building systems science models for obesity prevention, and how might they be overcome?
Key Principles
We have identified five principles for systems science modeling for community-based obesity prevention:
Principle 1: Understand and Engage with the Community Being Modeled Prior to Developing the Model
To be relevant to decision makers for a community, it is important to have a deep understanding of and connection with the community. The groundwork for BLIFE was laid long before development of the ABM began. Members of the BLIFE development team have had over 12 years of experience in improving the Baltimore City food environment, through multiple intervention trials in corner stores [24–26], carryouts [27, 28], recreation centers [29], and churches [30, 31]. Additionally, the team has strong, longstanding connections with key stakeholders in Baltimore City, including the City Health Department, City Council, Department of Recreation and Parks, Food Policy Advisory Committee, and more.
Principle 2: Integrate Model Development with Data Collection
BLIFE development was tied to extensive data collection activities. BLIFE includes a grid for mapping homes, schools, food sources (i.e., corner stores, carryouts, supermarkets), and recreation centers, covering approximately 15 % of the total area of Baltimore City in its current version. The model incorporates Maryland Food System Data from the Center for the Livable Future [32] and baseline data from the B’more Healthy Communities for Kids Program (BHCK). BHCK data were collected from 299 low-income African American children ages 10 to 14 and their caregivers living in food deserts [33••]. In addition to anthropometric measurements, the youth completed a questionnaire that assessed food-purchasing behavior, attitudes about healthy and unhealthy food, self-efficacy for making positive changes to their diet, and food-related psychosocial factors. They were asked how much money they typically spend when they buy food from carryouts and corner stores and how often they shopped in corner stores, carryouts, and fast-food restaurants, convenience stores, supermarkets, or at schools or other locations in the last 7 days.
Principle 3: Represent All of the Processes That May Be Relevant to the Interventions Under Consideration, but No More
The principle of parsimony is important in modeling. The model should not include excessive detail that can cloud relevant interactions and relationships. However, the model should include every process that is relevant to the interventions being explored. The BLIFE model captures adolescent behaviors (food foraging and physical activity) on a daily basis. Agents in the model are characterized based on real data that inform their movement from school to small food store(s) to recreation centers to home. Decision-making of agents in the simulated food environment was based on data collected from 299 African American adolescents (10–14 years). Growth for each agent in the ABM is simulated over a 5-year period, and the weight trajectory of each agent is a perturbation of the CDC growth charts [33••, 34]. As the model is geospatially specific, food foraging and activity behaviors vary based on the agent and environment characteristics. At each time period, the agent computes the likely food source it accesses or the recreation center it could go to. Our studies have shown that afterschool consumption at small food stores is a major source of added calories and this has been incorporated in the model to make it more locally relevant. On the other hand, purchase and consumption of foods from fast-food restaurant chains is not common among our sample of children and is not represented in the model—invoking the principle of parsimony.
Principle 4: Involve Stakeholders in Model Development to Give Them “Ownership” of the Model
We found that grounding the model in data from the specific communities involved helped convince decision makers that the model truly represents their own communities. Stakeholders are more likely to trust a model if they understand and feel ownership. This can be achieved by involving them along each step of the model development process. For BLIFE, we conducted multiple meetings with groups of policymakers and city agency representatives, where they were given the opportunity to review the model, suggest means of improving it and making it more relevant to their work.
Principle 5: Make the Model Understandable and Accessible to Key Decision Makers
Stakeholders are less likely to trust a model that is a “black box” to them and that they cannot “test-drive” themselves. To help facilitate the accessibility of BLIFE, we developed a graphical user interface (GUI) for BLIFE. This GUI allows the user to modify characteristics of the simulated food environment that can influence dietary behaviors and obesity risk through the use of several “levers.” These were determined based on findings from the literature and from our extensive intervention work to improve the food environment in Baltimore.
The BLIFE model has generated considerable interest among local policymakers, city agencies, and other community institutions, who view it as a means of providing evidence in support of new and ongoing policy initiatives and testing what-if scenarios to examine the potential intended and unintended consequences of new programs. For example, the Family League of Baltimore, anticipating proposed closures of many of its summer meal program sites, found utility in the model to predict potential impact on household food security. Other city stakeholders have asked us to use the BLIFE model to simulate the effects of programs and policies with many diverse outcomes, including changes to food access, school achievement, and the financial viability of small food stores associated with new Farm Bill regulations.
Benefits of Modeling for Communities
We have identified several benefits of ABM from the research and community perspectives:
Benefit #1: Helps Community Stakeholders Understand How Multiple Variables, Factors, and Interventions Interact
Without the assistance of computational models, humans can struggle to consider more than a few factors and relationships at a time—and the potential consequences may be unclear. The BLIFE model, for example, weighs multiple factors when considering where a youth goes to purchase food, including proximity, type of food source, previous reported use of food sources, and relationship to school and home locations.
Benefit #2: Test Potential Strategies Before Going to Scale, Saving Time and Money
Simulation modeling can test the potential impact of programs and policies in the “safety” of a virtual environment before they can be implemented, saving considerable time, effort, costs, and resources. Findings from simulation models can provide insight on the most promising approaches, when presented with a number of options. For example, the BLIFE model has been used to test the expected change in adolescent BMI percentile, over a 5-year period, as a result of (1) improving the availability of healthy food options in corner stores alone, (2) improving the availability of healthy food options in carryout restaurants alone, and (3) improving the availability of healthy food options in both corner stores and carryouts [35].
Benefit #3: Demonstrates Potential Secondary and Tertiary Effects (and Even Unintended Consequences) of Intervention Strategies
A continuing challenge of working with MLMC interventions is that any action may have ripple effects throughout different parts of the system. Traditional methods that focus on only a component or portion of the system may miss these reverberations. From the BLIFE model work, we have come to realize that small stores can only access the foods that exist in their own food environment (what is offered by their wholesalers). Requiring these small stores to stock a broad range of healthy foods without working at higher levels of the food system to improve access could have the consequence of making these small businesses unworkable.
Benefit #4: Can Guide/Prioritize Data Collection
Data collection is time consuming and expensive. It can be difficult to determine the impact of having certain types of data. Simulation modeling can help determine the value of having different types of data and can help prioritize selection of data sources. We have found it crucial to understand the food selection process of youth and how that might or might not be impacted by different intervention strategies (e.g., labeling, reducing price, increasing availability).
Benefit #5: Facilitates Dialogue Among Stakeholders
A model can help communicate a person’s or group’s understanding of a system. In many ways, a model puts this understanding on the “table” for key stakeholders to consider, evaluate, critique, and discuss. It gives stakeholders something to react to and galvanizes discussion. For example, based on the request from a local city council member, the BLIFE model was used to simulate the potential impact of implementing a city tax credit for urban farmers on improving adolescent access to fresh produce and dietary behavior. The research team was invited to present findings from the simulation in support of the tax credit at a public hearing session held in October 2014.
Challenges Encountered
In developing the BLIFE model, we have encountered multiple challenges.
Challenge #1: Choosing What Factors and Relationships to Include or Exclude
A model is by definition a simplification and cannot possibly include every possible factor and relationship. A factor or relationship should be included if it may affect the ultimate evaluation or outcome of the intervention. In some cases, a factor or relationship is included if a key stakeholder would like to see it even though it has little impact on the results. As complete consensus might be harder to reach on some points, choosing what factors and relationships to not include requires judgment and experience. For example, the current version of the BLIFE model does not include social networks and peer relationships as a driving force in food selection. This is largely due to the complexity in collecting these data. We have used formative research as part of the process in determining key components to operationalize. Formative research not only helps in planning and development of intervention strategies and data collection instruments [36] but can also be used to identify the most salient and important factors for inclusion in simulation models. For example, our formative research indicated that corner stores were commonly used by children in low-income areas of Baltimore—which led us to carefully operationalize this component of the food system [33••]. On the other hand, carryouts are much less frequently used by youth and play a smaller role in their diet.
Challenge #2: A Model Should Be Used for the Purpose That It Was Designed
Once a model is developed, there is the temptation to use it for every question or decision that arises. However, every model has its limitations, which should be clearly stated. The current iteration of the BLIFE model evaluates different obesity prevention programs and policies alone or in combination—in terms of its impact on childhood obesity, and cannot be used to assess economic effects.
Challenge #3: How Best to Incorporate and Operationalize/Quantify Key Relationships/Feedback Loops?
A key feature of obesity epidemic is that there exist multilevel interactions among the different components. For instance, store owners adjust stock and price according to children’s purchase behavior and policy intervention, while children choose foods based on price, availability, and promotion. Store owners interact with wholesalers in a similar kind of supply-demand loop. These feedback loops can be modeled using behavioral algorithms to capture the interaction between agents in an ABM. The current BLIFE model does not contain feedback loops. This weakness exists due to several factors. Foremost is the enormous number of feedback loops involved in modeling food selection behavior over time. Each time a child visits a store and selects a kind of food, there will be feedback impacting the decision-making moving forward. Hence, the whole system will have a very large number of feedback loops for each combination of child, store, and food. Another challenge is that individual-level behavioral algorithms cannot capture all store-level changes. Selling of cold beverages strongly depends on daily weather, while many other foods do not. Fresh fruit stocking is highly seasonal. Customers of stores near schools will not visit during holidays, even if the prices are low. To model the feedback loops reasonably, surveys have to be conducted across multiple components of the model to effectively capture food stocking and purchases.
Challenge #4: To What Degree Should Data on Current Practices (Behaviors) Be Incorporated into Modeling?
A key challenge is the degree to which actual behavioral data should be used to simulate decision-making. For example, for the BLIFE model, we used survey data on store selection and food purchasing by youth to create relative proportions of selection of different kinds of stores and foods. This makes the model very accurate (presumably) for predicting food-purchasing behavior in the Baltimore setting. On the other hand, there is a potential loss of transferability and generalizability from the model to other settings. Data on food store selection and purchasing are very specific to a particular setting and are related to the availability of those foods, their prices, amount of money youth in that setting have in hand, etc. It is important to come up with more general algorithms for modeling food choices (and other behaviors).
Challenge #5 (Food Sources): How to Model Selection of Food Sources?
Using proximity as a sole measure of food store selection provides inconsistent findings when linked to dietary intake and obesity [37–48]. A more comprehensive understanding involves incorporating multiple personal, socio-environmental, and behavioral factors [49, 50]. The dynamics of these influences are very difficult to understand through statistical models alone, hence, the utility of ABMs. In silico models developed by Auchincloss et al. showed how residential income segregation at the community level can impact dietary behavior by disaggregating the distribution of grocery stores [19••]. The model highlighted that spatial segregation among high-income and low-income areas can exacerbate residential availability of healthy foods in those areas. Social influences on eating behaviors have been explored in ABM by Zhang et al. [51]. For the BLIFE model, the agents take advantage of the extensive data collected previously to capture food source selection in Baltimore City based on food-purchasing behavior, neighborhood availability, attitudes about healthy and unhealthy food, etc. (detailed earlier).
Challenge #6: What Are the Factors That Influence Food Choice Decisions of Youth and Other Key Actors Within a Selected Food Source?
A range of factors influences adolescent food choice within a store. Food choices can be influenced by promotional signage, displays, and taste-tests in stores [33••]. Structural changes in stores (i.e., refrigeration units) and storeowner trainings can encourage consumer purchasing of healthier food options [52]. Formative research from the BHCK obesity-intervention trial further revealed that taste, preference, and familiarity with a given food were important factors in decision-making [33••]. For example, some found that diet beverages were not as satisfying or palatable as regular sugar-sweetened beverages. Another factor is price sensitivity of adolescents, especially in urban low-income neighborhoods. Reduction in pricing has been shown to influence food choice as well [28]. Finally, while identifying the most important drivers is challenging, system dynamics modeling and social network analyses can be helpful to tease apart the influence of parental and household factors (i.e., income, education) and to better understand the underlying mechanisms of food choice. For the BLIFE model, we developed an algorithm to model food choice based on reported frequency of consumption of foods from different categories, classified as healthy and unhealthy options. For example, our data indicated that children were three times more likely to select a sugar-sweetened beverage than a healthier alternative like water.
Challenge #7: How Should Physical Activity Be Incorporated into Obesity Prevention Models?
Changes in BMI are reflective of the energy imbalances between energy intake/storage and mobilization (energy expenditure, growth) [53]. The factors that influence energy expenditure and energy intake have varying degree of influence and complexity [54, 55]. A model developed by Butte et al. has been widely used in systems modeling literature to predict changes in energy intake and physical activity associated with weight gain in children and adolescents [12]. A modified version of the model has been used in the BLIFE model to understand energy imbalance in adolescents taking into account walking and recreational center activities. The next iteration of the BLIFE model will look to incorporate more types of physical activities to represent varying activity intensity levels (light, moderate, vigorous) [56].
Challenge #8: How to Best Incorporate Potential Intervention Levers?
The usefulness of ABMs is directly related to how readily they can be employed to simulate the impact of different intervention strategies. For example, a lever which allows the user to change availability of healthy foods in small food stores would permit the testing of this strategy. Many such levers could be conceptualized, such as pricing, promotional materials, training, etc. However, the addition of more levers means more increased complexity and challenges for how to weigh each of these additional variables. Should the impact of lowered prices for healthier foods be weighted as more influential than materials (like shelf labels) promoting the health benefits of these foods? For the BLIFE model, we developed an array of over 30 different levers, with 3–6 levers assigned to each component of the food environment (corner stores, carryouts, etc.).
Challenge #9: Need for Integration of Social Networks into Complex Systems Models?
Previous, obesity-related ABMs lacked an empirically based social network structure. The agents often moved randomly in simulated environments or develop a network randomly in their environment with other agents based on a limited set of requirements [57•, 58]. Similarly, studies of social networks and their relationship to obesity have not rigorously investigated the interactions between the environments in which children live, study, and play and how these environments shape social networks and are in turn shaped by them [22, 59, 60]. Instead, researchers have focused on defending whether the environment or social networks are more important in explaining the “spread” and clustering of obesity over time and controlled for the other variables. This work is complicated by a lack of method operationalization and standardization [61]. These measures are only weakly associated with obesity prevalence and do not actually reflect how individuals interact within their local food environments [39, 62]. The BLIFE model adds to other recent advances in the social environments and obesity literature [63, 64] by using data from real children, precisely identifying where children are obtaining food, how often, and with whom. This specificity will help us investigate the interaction between food environments and social networks as they relate to clustering of obesity in social networks and neighborhoods.
Challenge #10: What Are the Most Appropriate Outcomes to Track?
Development of any systems science model should be driven by a specific inquiry—what is the purpose of developing the model and what question is one seeking to answer with the model? For the BLIFE model, the outcome of interest was change in youth BMI percentile and obesity risk. However, there is significant value added when stakeholders and policymakers can utilize the evidence from systems science models to inform their own programs and policies. Therefore, it is important to consider other outcomes that may be of interest to a range of users. We have been asked to expand the BLIFE model to be used as a tool to examine potential change in student attendance/student achievement, energy intake/energy expenditure, and food security and hunger.
Conclusions
Simulation modeling has tremendous potential to transform the design, planning, implementation, and evaluation of community-level obesity control. The use of modeling in this realm is still relatively nascent as much of the existing obesity-related models have been focused on particular scales and purposes. We have outlined several guiding principles for developing community-level models for obesity control and highlighted the benefits and challenges involved in the process. As the use of simulation modeling to guide such interventions grows, stakeholders may become more accepting of this method. Greater experience will undoubtedly lead to modification of these principles, benefits, and challenges over time.
Additional research is needed to address each of the challenges listed above. It would help to develop a “shared language” among diverse stakeholders around obesity to encourage consensus building over time. Nevertheless, the benefit of being able to test potential interventions virtually before implementation to assess cost-effectiveness and potential impact is enormously valuable.
Importantly, it should be emphasized that computational models, such as the BLIFE agent-based model, should not replace human decision-making or other types of studies. Models are intended to facilitate human decision-making and complement other studies, but not replace them.
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
Rutter H. The single most important intervention to tackle obesity. Int J Public Health. 2012;57:657–8.
Rutter H. Where next for obesity? Lancet. 2011;378:746–7.
Sallis JF, Glanz K. Physical activity and food environments: solutions to the obesity epidemic. Milbank Q. 2009;87:123–54.
Sanigorski AM, Bell A, Kremer PJ, Cuttler R, Swinburn BA. Reducing unhealthy weight gain in children through community capacity-building: results of a quasi-experimental intervention program, be active eat well. Int J Obes. 2008;32:1060–7.
Economos CD, Folta SC, Goldberg J, et al. Peer reviewed: a community-based restaurant initiative to increase availability of healthy menu options in Somerville, Massachusetts: shape up Somerville. Prev Chron Dis. 2009;6(3):A102.
Economos CD, Hyatt RR, Goldberg JP, et al. A community intervention reduces BMI z‐score in children: shape up Somerville first year results. Obesity. 2007;15:1325–36.
Chen B, Cheng HH. A review of the applications of agent technology in traffic and transportation systems. Intell Transp Syst IEEE Trans. 2010;11:485–97.
Buzacott JA, Shanthikumar JG. Stochastic models of manufacturing systems. NJ: Prentice Hall Englewood Cliffs; 1993.
Lee BY, Bartsch SM, Wong KF, et al. Simulation shows hospitals that cooperate on infection control obtain better results than hospitals acting alone. Health Aff. 2012;31:2295–303.
Lee BY, Brown ST, Bailey RR, et al. The benefits to all of ensuring equal and timely access to influenza vaccines in poor communities. Health Aff. 2011;30:1141–50.
Lee BY, Cakouros BE, Assi TM, et al. The impact of making vaccines thermostable in Niger’s vaccine supply chain. Vaccine. 2012;30:5637–43.
Butte NF, Cai G, Cole SA, et al. Metabolic and behavioral predictors of weight gain in Hispanic children: the Viva la Familia Study. Am J Clin Nutr. 2007;85:1478–85.
Hammond RA. Complex systems modeling for obesity research. Prev Chron Dis. 2009;6:A97.
Vandenbroeck P, Goossens J, Clemens M. Foresight, tackling obesities: future choices—building the obesity system map. London: Government Office for Science; 2007.
Finegood DT, Merth TDN, Rutter H. Implications of the foresight obesity system map for solutions to childhood obesity. Obesity. 2010;18:S13–6.
Huang TT, Drewnowski A, Kumanyika SK, Glass TA. A systems-oriented multilevel framework for addressing obesity in the 21st century. Prev Chron Dis. 2009;6(3):A82.
El-Sayed AM, Scarborough P, Seemann L, Galea S. Social network analysis and agent-based modeling in social epidemiology. Epidemiol Perspect Innovations EP + I. 2012;9:1. This paper looks at the use of social network analysis and ABMs in social epidemiology research and the factors that need to be accounted for when using both.
Epstein JM, Axtell RL. Growing artificial societies: social science from the bottom up. Brookings Institution Press, Washington, DC; 1996.
Auchincloss AH, Riolo RL, Brown DG, Cook J, Diez Roux AV. An agent-based model of income inequalities in diet in the context of residential segregation. Am J Prev Med. 2011;40:303–11. This study explores the use of ABMs in understanding effects of income differences in healthy eating and explores policy levers to counter income disparities in diet.
Hammond R, Epstein J. Exploring price-independent mechanisms in the obesity epidemic (paper no. 48). Washington (DC): The Brookings Institution; 2007.
Burke MA, Heiland F. Social dynamics of obesity. Econ Inq. 2007;45:571–91.
Christakis NA, Fowler JH. The spread of obesity in a large social network over 32 years. N Engl J Med. 2007;357:370–9.
{NetLogo}. Center for connected learning and computer-based modeling, Northwestern University, 1999. at http://ccl.northwestern.edu/netlogo/.)
Gittelsohn J, Song HJ, Suratkar S, et al. An urban food store intervention positively affects food-related psychosocial variables and food behaviors. Health Educ Behav Off Publ Soc Public Health Educ. 2010;37:390–402.
Song H-J, Gittelsohn J, Kim M, Suratkar S, Sharma S, Anliker J. A corner store intervention in a low-income urban community is associated with increased availability and sales of some healthy foods. Public Health Nutr. 2009;12:2060–7.
Gittelsohn J, Suratkar S, Song H-J, et al. Process evaluation of Baltimore healthy stores: a pilot health intervention program with supermarkets and corner stores in Baltimore City. Health Promot Pract. 2010;11:723–32.
Lee-Kwan SH, Bleich SN, Kim H, Colantuoni E, Gittelsohn J. Environmental intervention in carryout restaurants increases sales of healthy menu items in a low-income urban setting. Am J Health Promot. 2014. doi:10.4278/ajhp.130805-QUAN-408
Lee-Kwan SH, Goedkoop S, Yong R, et al. Development and implementation of the Baltimore healthy carry-outs feasibility trial: process evaluation results. BMC Public Health. 2013;13:638.
Gittelsohn J, Dennisuk LA, Christiansen K, et al. Development and implementation of Baltimore healthy eating zones: a youth-targeted intervention to improve the urban food environment. Health Educ Res. 2013;28:732–44.
Wang HE, Lee M, Hart A, Summers AC, Anderson Steeves E, Gittelsohn J. Process evaluation of healthy bodies, healthy souls: a church-based health intervention program in Baltimore City. Health Educ Res. 2013;28:392–404.
Summers A, Confair AR, Flamm L, et al. Designing the healthy bodies, healthy souls church-based diabetes prevention program through a participatory process. Am J Health Educ. 2013;44:53–66.
Maryland Food System. 2014. at http://mdfoodsystemmap.org/.)
Gittelsohn J, Anderson Steeves E, Mui Y, Kharmats AY, Hopkins LC, Dennis DB. More healthy communities for kids: design of a multi-level intervention for obesity prevention for low-income African American children. BMC Public Health. 2014;14:942. This paper looks at understanding a multi-level, multi-component obesity prevention obesity intervention trial that uses novel computational modeling methodologies to generate informed decisions for variosus stakeholders.
Igusa TMY, Oke J, Steeves EA, Gittelsohn J. Agent-based model for childhood obesity for policy makers. Poster presented at: The 31st Annual Scientific Meeting of the Obesity Society. Atlanta, GA; 2013.
Mui Y, Oke O, Lin S, Igusa T, Anderson-Steeves E, Gittelsohn J. An agent-based model simulates interventions in small food stores to improve the urban food environment. Presentation at: The International Congress on Obesity. Kuala Lumpur, Malaysia; 2014.
Gittelsohn J, Steckler A, Johnson CC, et al. Formative research in school and community-based health programs and studies: “state of the art” and the TAAG approach. Health Educ Behav Off Publ Soc Public Health Educ. 2006;33:25–39.
Block JP, Christakis NA, O’Malley AJ, Subramanian SV. Proximity to food establishments and body mass index in the Framingham heart study offspring cohort over 30 years. Am J Epidemiol. 2011;174:1108–14.
Boone-Heinonen J, Gordon-Larsen P, Kiefe CI, Shikany JM, Lewis CE, Popkin BM. Fast food restaurants and food stores: longitudinal associations with diet in young to middle-aged adults: the CARDIA study. Arch Intern Med. 2011;171:1162–70.
Caspi CE, Sorensen G, Subramanian SV, Kawachi I. The local food environment and diet: a systematic review. Health Place. 2012;18:1172–87.
Drewnowski A, Aggarwal A, Hurvitz PM, Monsivais P, Moudon AV. Obesity and supermarket access: proximity or price? Am J Public Health. 2012;102:e74–80.
Gustafson AA, Sharkey J, Samuel-Hodge CD, et al. Perceived and objective measures of the food store environment and the association with weight and diet among low-income women in North Carolina. Public Health Nutr. 2011;14:1032–8.
Inagami S, Cohen DA, Finch BK, Asch SM. You are where you shop: grocery store locations, weight, and neighborhoods. Am J Prev Med. 2006;31:10–7.
Laraia BA, Siega-Riz AM, Kaufman JS, Jones SJ. Proximity of supermarkets is positively associated with diet quality index for pregnancy. Prev Med. 2004;39:869–75.
Macdonald L, Ellaway A, Ball K, Macintyre S. Is proximity to a food retail store associated with diet and BMI in Glasgow, Scotland? BMC Public Health. 2011;11:464.
Morland K, Diez Roux AV, Wing S. Supermarkets, other food stores, and obesity: the atherosclerosis risk in communities study. Am J Prev Med. 2006;30:333–9.
Morland K, Wing S, Diez RA. The contextual effect of the local food environment on residents’ diets: the atherosclerosis risk in communities study. Am J Public Health. 2002;92:1761–7.
Morland KB, Evenson KR. Obesity prevalence and the local food environment. Health Place. 2009;15:491–5.
Pereira CA, Larder N, Somerset S. Food acquisition habits in a group of African refugees recently settled in Australia. Health Place. 2010;16:934–41.
Nestle M, Wing R, Birch L, et al. Behavioral and social influences on food choice. Nutr Rev. 1998;56:S50–64. Discussion S-74.
Story M, Neumark-Sztainer D, French S. Individual and environmental influences on adolescent eating behaviors. J Am Diet Assoc. 2002;102:S40–51.
Zhang D, Giabbanelli PJ, Arah OA, Zimmerman FJ. Impact of different policies on unhealthy dietary behaviors in an urban adult population: an agent-based simulation model. Am J Public Health. 2014;104:1217–22.
Ayala GX, Baquero B, Laraia BA, Ji M, Linnan L. Efficacy of a store-based environmental change intervention compared with a delayed treatment control condition on store customers’ intake of fruits and vegetables. Public Health Nutr. 2013;16:1953–60.
Hall KD, Hammond RA, Rahmandad H. Dynamic interplay among homeostatic, hedonic, and cognitive feedback circuits regulating body weight. Am J Public Health. 2014;104:1169–75.
Kohl HW, Fulton JE, Caspersen CJ. Assessment of physical activity among children and adolescents: a review and synthesis. Prev Med. 2000;31:S54–76.
McGuire S. Institute of Medicine. 2013. Evaluating obesity prevention efforts: a plan for measuring progress. Washington, DC: The National Academies Press, 2013. Adv Nutr. 2014;5:191–2.
Ainsworth BE, Haskell WL, Whitt MC, et al. Compendium of physical activities: an update of activity codes and MET intensities. Med Sci Sports Exerc. 2000;32:S498–504.
Hammond RA, Ornstein JT. A model of social influence on body mass index. Ann N Y Acad Sci. 2014:1331:34–42. This paper discusses the development of an ABM to look at social influence on body weight and focuses on the insights it generates, and its implications for public health policy.
Orr M, Galea S, Riddle M, Kaplan G. Reducing racial disparities in obesity: simulating the effects of improved education and social network influence on diet behavior. Ann Epidemiol. 2014;24:563–9.
Cohen-Cole E, Fletcher JM. Is obesity contagious? Social networks vs. environmental factors in the obesity epidemic. J Health Econ. 2008;27:1382–7.
Fowler JH, Christakis NA. Estimating peer effects on health in social networks: a response to Cohen-Cole and Fletcher; and Trogdon, Nonnemaker, and Pais. J Health Econ. 2008;27:1400–5.
Feng J, Glass TA, Curriero FC, Stewart WF, Schwartz BS. The built environment and obesity: a systematic review of the epidemiologic evidence. Health Place. 2010;16:175–90.
Guthman J. Too much food and too little sidewalk? Problematizing the obesogenic environment thesis. Environ Plan A. 2013;45:142–58.
De la Haye K, Robins G, Mohr P, Wilson C. Obesity-related behaviors in adolescent friendship networks. Soc Networks. 2010;32:161–7.
de la Haye K, Robins G, Mohr P, Wilson C. Adolescents’ intake of junk food: processes and mechanisms driving consumption similarities among friends. J Res Adolesc. 2013;23:524–36.
Acknowledgments
Research reported in this publication was supported by the Global Obesity Prevention Center (GOPC) at Johns Hopkins, and the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD) and the Office of the Director, National Institutes of Health (OD) under award number U54HD070725. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. Atif Adam, Sen Lin, Anna Kharmats, and Takeru Igusa report grants from NICHD U-54 Grant # 1U54HD070725-02.
Compliance with Ethics Guidelines
ᅟ
Conflict of Interest
Joel Gittelsohn, Yeeli Mui, Atif Adam, Sen Lin, Anna Kharmats, Takeru Igusa, and Bruce Y. Lee declare that they have no conflict of interest.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Author information
Authors and Affiliations
Corresponding author
Additional information
This article is part of the Topical Collection on Obesity Prevention
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
Gittelsohn, J., Mui, Y., Adam, A. et al. Incorporating Systems Science Principles into the Development of Obesity Prevention Interventions: Principles, Benefits, and Challenges. Curr Obes Rep 4, 174–181 (2015). https://doi.org/10.1007/s13679-015-0147-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13679-015-0147-x