
Abstract
We develop a new methodology to compute differences in the expected longevity of individuals of a given cohort who are in different socioeconomic groups at a certain age. We address the two main problems associated with the standard use of life expectancy: (1) that people’s socioeconomic characteristics change, and (2) that mortality has decreased over time. Our methodology uncovers substantial heterogeneity in expected longevities, yet much less heterogeneity than what arises from the naive application of life expectancy formulae. We decompose the longevity differences into differences in health at age 50, differences in the evolution of health with age, and differences in mortality conditional on health. Remarkably, education, wealth, and income are health-protecting but have very little impact on two-year mortality rates conditional on health. Married people and nonsmokers, however, benefit directly in their immediate mortality. Finally, we document an increasing time trend of the socioeconomic gradient of longevity in the period 1992–2008, and we predict an increase in the socioeconomic gradient of mortality rates for the coming years.

Similar content being viewed by others


Notes
See, for instance, Montez et al. (2011) and references therein for recent findings of mortality differences by education level. Deaton and Paxson (1994) documented the negative relationship between mortality and family income, after controlling for education. Attanasio and Hoynes (2000) found a negative relationship between mortality and wealth. The Whitehall studies have uncovered important mortality differences according to the employment grade among British civil servants; see, for instance, Marmot et al. (1984, 1991). For mortality rates and marital status, see Hu and Goldman (1990) and the references therein.
The standard errors are obtained by drawing 25,000 samples of parameter values from the estimated asymptotic distribution of the model parameters and computing a life expectancy with each of them. See Appendix B for details.
The life expectancies we compute in the HRS should be somewhat larger than the ones reported by the NVSS because the HRS refers to the noninstitutionalized population. For instance, Brown et al. (2012) find that life expectancies at 65 in the HRS are about one year larger than in the NVSS.
See Appendix A for the exact definition of all these variables.
To point to particular examples, only 47 % of white males with wealth in the top quintile of the distribution at age 50 were in the same quintile by age 65 (with most of the movers going to the second quintile), and 88 % of white males who were married at age 50 were also married by age 65. Even more important are the changes in labor market status, because people clearly drop from the labor force as they age.
Allowing for interactions between age, type, and year would increase the parameterization of our logit and multilogit models beyond tractability. In addition, the rationale for interacting time effects with age comes from the evidence that long-run gains in survival rates are different at different ages. However, these findings relate to both age differences and time intervals much wider than ours. See Lee and Carter (1992) for details.
Despite the fact that the standard error associated to the change in female life expectancy is large (0.6 years), this discrepancy between the HRS and the NVSS is worrisome. In a sense, we are stretching the HRS to its limits. As shown in Fig. 1, information on deaths for old individuals contain limited time variation. For instance, individuals aged 85 and older come only from the original AHEAD cohort. This problem is more acute for women, who die an average of four years later.
The results for the 1980s and 1990s are based on data from the NLMS, whereas the comparison between 1990 and 2000 is based on data from the death certificates in the Multiple Cause of Death files.
Others include the Medical Expenditure Survey (MEPS), the National Health Interview Survey (NHIS), the National Health and Nutrition Examination Survey (NHANES), the National Longitudinal Study of Youth (NLSY), the Survey of Health Ageing and Retirement in Europe (SHARE), and the Panel Study of Income Dynamics (PSID).
Some authors choose to estimate the health and survival functions together through an ordered logit, thinking of death as an extra (and absorbing) health state (see, e.g., Yogo 2009). Our specification has two advantages. First, it is designed to estimate not only the effects of the type variables z into health but also the evolution of the type variables z and how this is affected by health itself. Second, it imposes less structure than an ordered logit model by allowing the marginal effect of any variable z on future health to differ from its marginal effect on mortality. This distinction is important. For instance, the effect of education on mortality is null after health is controlled for, but it is still an important determinant of the law of motion of health (see Appendix B). The decompositions in the next section are based precisely on this distinction.
See Lancaster (1990) for an overview of duration analysis.
References
Attanasio, O., & Hoynes, H. (2000). Differential mortality and wealth accumulation. Journal of Human Resources, 35, 1–29.
Brown, D. C., Hayward, M. D., Montez, J. K., Hummer, R. A., Chiu, C.-T., & Hidajat, M. M. (2012). The significance of education for mortality compression in the United States. Demography, 49, 819–840.
Brown, J. R. (2002). Differential mortality and the value of individual account retirement annuities. In M. Feldstein & J. B. Liebman (Eds.), The distributional aspects of social security and social security reform (pp. 401–446). Chicago, IL: University of Chicago Press.
Crimmins, E. M., Hayward, M. D., & Seeman, T. (2004). Race/ethnicity, socioeconomic status and health. In N. B. Anderson, R. A. Bulatao, & B. Cohen (Eds.), Critical perspectives on racial and ethnic differences in health in later life (pp. 310–352). Washington, DC: National Academy Press.
Currie, J., & Madrian, B. C. (1999). Health, health insurance and the labor market. In O. Ashenfelter & D. Card (Eds.), Handbook of labor economics (Vol. 3, pp. 3309–3416). Amsterdam, The Netherlands: Elsevier Science Publishers.
Deaton, A., & Paxson, C. (1994). Mortality, education, income and inequality among American cohorts. In D. A. Wise (Ed.), Themes in the economics of aging (pp. 129–170). Chicago, IL: University of Chicago Press.
Díaz-Giménez, J., Gover, A., & Ríos-Rull, J.-V. (2011). Facts on the distributions of earnings, income, and wealth in the United States: 2007 update. Federal Reserve Bank of Minneapolis Quarterly Review, 34(1), 2–31.
Díaz-Giménez, J., Quadrini, V., & Ríos-Rull, J.-V. (1997). Dimensions of inequality: Facts on the U.S. distribution of earnings, income and wealth. Federal Reserve Bank of Minneapolis Quarterly Review, 21(2), 3–21.
Diermeier, D., Eraslan, H., & Merlo, A. (2003). A structural model of government formation. Econometrica, 71, 27–70.
Elo, I. T., & Preston, S. H. (1996). Educational differentials in mortality: United States, 1979–85. Social Science & Medicine, 42, 47–57.
Fuster, L., Imrohoroglu, A., & Imrohoroglu, S. (2003). A welfare analysis of social security in a dynastic framework. International Economic Review, 44, 1247–1274.
Heathcote, J., Perri, F., & Violante, G. (2010). Unequal we stand: An empirical analysis of economic inequality in the United States, 1967–2006. Review of Economic Dynamics, 1(13), 15–51.
Hu, Y., & Goldman, N. (1990). Mortality differentials by marital status: An international comparison. Demography, 27, 233–250.
Idler, E. L., & Benyamini, Y. (1997). Self-rated health and mortality: A review of twenty-seven community studies. Journal of Health and Social Behavior, 38, 21–37.
Idler, E. L., & Benyamini, Y. (1999). Community studies reporting association between self-rated health and mortality. Research on Aging, 21, 392–401.
Kitagawa, E. M., & Hauser, P. M. (1973). Differential mortality in the United States: A study in socioeconomic epidemiology. Cambridge, MA: Harvard University Press.
Lancaster, T. (1990). The econometric analysis of transition data. Cambridge, UK: Cambridge University Press.
Lee, R. D., & Carter, L. R. (1992). Modeling and forecasting U.S. mortality. Journal of the American Statistical Association, 87, 659–671.
Lin, C. C., Rogot, E., Johnson, N. J., Sorlie, P. D., & Arias, E. (2003). A further study of life expectancy by socioeconomic factors in the National Longitudinal Mortality Study. Ethnicity and Disease, 13, 240–247.
Majer, I. M., Nusselder, W. J., Mackenbach, J. P., & Kunst, A. E. (2011). Socioeconomic inequalities in life and health expectancies around official retirement age in 10 Western-European countries. Journal of Epidemiology and Community Health, 65, 972–979.
Marmot, M. G., Shipley, M. J., & Rose, G. (1984). Inequalities in death-specific explanations of a general pattern? Lancet, 323, 1003–1006.
Marmot, M. G., Smith, G. D., Stansfeld, S., Patel, C., North, F., Head, J., . . . Feeney, A. (1991). Health inequalities among British civil servants: The Whitehall II study. Lancet, 337, 1387–1393.
Meara, E., Richards, S., & Cutler, D. (2008). The gap gets bigger: Changes in mortality and life expectancy, by education, 1981–2000. Health Affairs, 27, 350–360.
Montez, J. K., Hummer, R. A., Hayward, M. D., Woo, H., & Rogers, R. G. (2011). Trends in the educational gradient of U.S. adult mortality from 1986 through 2006 by race, gender, and age group. Research on Aging, 33, 145–171.
Preston, S. H., & Elo, I. T. (1995). Are educational differentials in adult mortality increasing in the United States? Journal of Aging and Health, 7, 476–496.
Rogers, R. G., Everett, B. G., Saint-Onge, J. M., & Krueger, P. M. (2010). Social, behavioral, and biological factors, and sex differences in mortality. Demography, 47, 555–578.
Singh, G. K., & Siahpush, M. (2006). Widening socioeconomic inequalities in us life expectancy, 1980–2000. International Journal of Epidemiology, 35, 969–979.
Smith, J. P. (1999). Healthy bodies and thick wallets: The dual relationship between health and economic status. Journal of Economic Perspectives, 13, 145–166.
Yogo, M. (2009). Portfolio choice in retirement: Health risk and the demand for annuities, housing, and risky assets (NBER Working Paper No. 15307). Cambridge, MA: National Bureau of Economic Research.
Acknowledgments
We are grateful for comments from Pierre-Carl Michaud, Pedro Mira, and Carolyn Wilkins; from attendants to seminars at University of Pennsylvania, Carlos III, and a LAEF conference on Health and Macroeconomics; and from the editor and referees. Inés Berniell provided excellent research assistance. Ríos-Rull thanks the National Science Foundation for Grant SES-1156228. The views expressed herein are those of the authors and not necessarily those of the Federal Reserve Bank of Minneapolis, or the Federal Reserve System.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Data
We use version M of the RAND files of the HRS, which covers 10 waves from 1992 to 2010.
Variable Definitions
Education:
Variable RAEDUC provides five educational categories: no high school diploma, high school dropout with GED tests, high school graduate, high school graduate with some college, and college graduate. We pool the second, third, and fourth categories for a wider high school graduate category.
Wealth:
The HRS provides several measures of assets and liabilities. We define wealth as total household net worth per adult, excluding second residences and mortgages on second residences because these two variables are unavailable for the third wave of the whole sample and for the second wave of the AHEAD subsample. Hence, total wealth is the sum of HwASTC, HwACHCK, HwACD, HwABOND, HwAOTH, HwAHOUS, HwARLES, HwATRANS, HwABSNS, and HwAIRA, minus HwDEBT, Hw-MORT, and HwHMLN. We then divide the resulting figure by 2 if the individual is married. We deflate our resulting variable by the CPI. Finally, in order to have a discrete version of the wealth variable, we classify every individual-year observation by the quintile of that individual-year observation in the wealth distribution over all individual-year observations, including both white males and white females. Hence, the top quintile represents individuals with household wealth over $207,450; the cutoff points for the second through fourth quintiles are, respectively, $95,497, $44,677, and $11,597. All figures are in 1992 dollars.
Income:
We use information on non-financial income, which is measured at the individual level. This is the sum of RwIEARN (labor earnings), RwIUNWC (unemployment benefits), RwIPENA (employer pensions and annuities), RwISRET (retirement income from social security), RwISSDI (disability income from social security), and RwIGXFR (other government transfers). We deflate our resulting variable by the CPI and compute the quintile for the individual-year observation in the income distribution over all individual-year observations, including both white males and white females. Hence, the top quintile represents individuals with nonfinancial income over $25,804; the cutoff points for the second through the fourth quintiles are, respectively, $14,096, $8,418, and $4,554. All figures are in 1992 dollars.
Labor market status:
Variable RwLBRF provides seven categories for the relationship of the respondent with the labor market. We reduce it to three: attached, semi-attached, and inactive. In the first category, we include individuals who are either working full-time or unemployed and looking for a job; in the second category, we include people working part-time or semiretired; in the third, we include individuals who are retired, disabled, or out of the labor force.
Marital status:
We use variable RwMSTAT to classify as married those who indicate that they are either married or partnered. We classify the remaining respondents (the separated, divorced, widowed, and never married) as nonmarried.
Smoking:
Variable RwSMOKEN reports whether the respondent is currently a smoker.
Health:
Variable RwSHLT, reports five categories for the respondent’s self-reported general health status: excellent, very good, good, fair, and poor.
Alive:
For every individual-year observation, we need to determine whether the individual survives into the next wave. Every wave contains the variable RwIWSTAT, which indicates whether the individual actually responded to the interview as well as the mortality status of the respondent. Code 1 indicates that the respondent actually responded to the interview, so he/she is alive. Code 4 indicates that the respondent dropped from the sample, but a follow-up on the individual verified that he/she was alive. These two cases are the ones we count as alive. Code 5 indicates that the individual did not survive to the current wave. Finally, code 7 indicates that the individual withdrew from the sample (because of either the sample design or sample attrition) and his/her survival is not known. We classify code 7 cases as “missing.”
Sample Selection
We start with all individuals in the age range 50 to 94. For every individual-year observation we record the relevant information for the next wave and drop individual-year observations in 2010—because information for the next wave is not available—and individual-year observations with zero sampling weight. This yields 12,219 males and 15,081 females. We omit individuals with missing information for race (17 males and 16 females), nonwhite individuals (2,364 males and 3,351 females), and individuals with missing information for education (2 males and 1 female), which leaves 9,836 males and 11,713 females. Every individual is observed in several waves, and every individual-year observation is useful to estimate survival probabilities and transitions of our covariates. Overall, we have 59,167 and 74,372 individual-year observations, respectively, for males and females. We next omit individual-year observations for which we do not know survival status into the next wave (596 and 748 individual-year observations for males and females, respectively); this happens for some observations of individuals who could not be followed upon withdrawing from the sample (code 7 in RwIWSTAT). Next, we drop individual-year observations with missing information on health (5,209 for males and 6,171 for females, which correspond to 286 and 331 different individuals, respectively). What is left is our working sample of 9,542 males who provide 53,362 individual-year observations and 11,236 females who provide 67,453 individual-year observations. Of these individual-year observations, we have 3,431 deaths for males and 3,235 for females, with average death rates of 6.4 % and 4.8 %, respectively.
Appendix B: Estimation of the Underlying Logistic Regressions
Survival Probabilities
We approximate parametrically the survival probabilities γ a as a function of age a only, and γ a (z) as a function of age and some type z ∈ Z. We run logistic regressions of survival as follows:
and
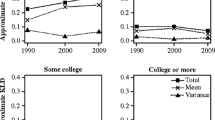
where \( {D}_{z_t={z}_i} \) is a dummy variable that takes value 1 if z t = z i , and zero otherwise; alive t + 2 is a dummy variable that takes value 1 if the individual is alive in the next wave, and zero otherwise. In Table 5, we show the results of these regressions for white males. The results of other regressions are available upon request. The categories into the set Z are always sorted from the most to the least advantaged type. We also tried specifications that add quadratic or cubic terms on age. In these specifications, the quadratic term is significant and improves the fit slightly. However, it does not change the computed life expectancies. Later, when we keep adding variables to the regression and interact them with age, it helps to have a parsimonious specification. In Fig. 2 we plot the survival rates for white males against age. In panel a, we plot the survival rates with the age term obtained through age dummy variables, and then also a linear, a quadratic, and a cubic polynomial. The quadratic polynomial improves the linear one in that it better captures the decline in survival in the very last years. In panel b, we plot the survival for college-educated males and individuals without a high school diploma with the age term captured either through age dummy variables or through a linear term, in both cases interacted with education. We see that the linear term is enough to capture the shape of the age profile in both education cases. In panels c and d, we do the same for health, and again the linear term captures the different shapes of each health group quite well.

Survival rates: parametric versus nonparametric age. Predicted yearly survival rates at a given age for the sample of white males. Because estimates correspond to two-year survivals, we report the square root of the predictions from our logit regressions. NHSD refers to no high school diploma
When examining the expected longevity differences in different years, we need to compute time-dependent age-specific survival probabilities γ a,t and γ a,t (z). To do so, we include a variable t for calendar year, as well as its interaction with the type variable z. We do not, however, interact it with age. See footnote 6 for a discussion.
and
We do not report the results of these and the following regressions, but they are available upon request.
When examining the expected longevities by education group, we run the same survival regressions but for the given education subpopulation only.
To compute survival probabilities γ a (h) and γ a (h, z), we use the same logistic regression upgraded to include self-rated health, h ∈ H:
and
An important finding in this article is that, after we control for self-rated health, differences in educational attainment have very little predictive power for two-year-ahead mortality rates. To see this, we first look at the predictive power of each variable alone. In Fig. 3, we plot the predicted survival rates by health (panel a) and education (panel b) when the logistic regressions include only health or education variables. The clear result is that differences in self-rated health imply much larger differences in survival than do differences in education.

Survival rates, by health and by education. Predicted yearly survival rates at a given age for the sample of white males. Because estimates correspond to two-year survivals, we report the square root of the predictions from our logit regressions. NHSD refers to no high school diploma; HSG, to high school graduates; and CG, to college graduates
When we put both types of variables together in the same regression, we can use differences in the likelihood to test how much information education adds to health and how much information health adds to education. In Table 6 we report results from the three logistic regressions: only health variables, only education variables, and both together. The first row corresponds to survival depending only on education; the second row, to survival depending only on health; and the third row, to survival depending on both. As suggested by Fig. 3, the odds ratios are much larger when education categories are compared than when health categories are. Interestingly, when the two types of variables are added, the odds ratios of education become statistically not different from 1. Instead, the odds ratios for health become slightly larger when education is added to the regression. The results of the likelihood ratio test are clear. Compared with the model regression with both education and health, the constraint that all the coefficients on the health variables are zero is rejected strongly. Instead, the constraint that the education variables are zero is rejected at the 10 % confidence level but not at the 1 % level.
A visual inspection of these results comes from Fig. 4. In panel a, we reproduce the survival rates by education group as in Fig. 3, panel b. In panels b, c, and d of Fig. 4, we plot the predicted survival rates by education group within a health category. It is easy to see that within the health category, the role of education is minimal.

Survival rates, by health and education jointly. Predicted yearly survival rates at a given age for the sample of white males. Because estimates correspond to two-year survivals, we report the square root of the predictions from our logit regressions. NHSD refers to no high school diploma; HSG, to high school graduates; and CG, to college graduates.
Transition Functions
We compute transition matrices p a (z′|z) by multivariate logistic regressions as follows:
with
When we need to compute time-dependent transition matrices p a,t (z′|z), we add a variable for calendar year and interact it with the dummy variables for type:
with
Finally, when we need to compute transition matrices p a (h′|h) and p a (z′, h′|z, h), we follow a similar approach. In the first case, we replace the z ∈ Z by h ∈ H. In the second one, we create new dummy variables by combining Z × H. This implies estimating very large models: the case for assets requires 25 outcome variables (5 asset categories multiplied by 5 health types). An alternative to using the transition matrices for the self-rated health would be to use an ordered logit. This approach is attractive because by imposing the structure of the ordered logit, we need to estimate much fewer parameters, and hence we could potentially add more variables together. However, the restrictions imposed by the ordered logit are statistically rejected, so we use the multivariate logit.
Standard Errors
We compute the standard errors of the life expectancies and the expected longevities by simulation. Following Diermeier et al. (2003), we draw 25,000 vectors of parameters from the corresponding estimated asymptotic distribution and compute the desired life expectancies or expected longevities with each vector of parameters. This gives us a sample of 25,000 observations for each statistic of interest, and we report the mean and the standard deviation of this distribution. The vectors of parameters estimated in the logistic and multivariate logistic regressions are asymptotically normally distributed, with the mean given by the point estimates, and the variance-covariance matrix of the parameters also obtained from the estimation process. The initial distributions φ50(h) and φ50(h|z j ) follow multinomial distributions.
Rights and permissions
About this article

Cite this article
Pijoan-Mas, J., Ríos-Rull, JV. Heterogeneity in Expected Longevities. Demography 51, 2075–2102 (2014). https://doi.org/10.1007/s13524-014-0346-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13524-014-0346-1