
Abstract
Link prediction is the problem of inferring new relationships among nodes in a network that are likely to occur in the near future. Classical approaches mainly consider neighborhood structure similarity when linking nodes. However, we may also want to take into account if the two nodes are already indirectly interacting and if they will benefit from the link by having an active interaction over the time. For instance, it is better to link two nodes u and v if we know that these two nodes will interact in the social network even in the future, rather than suggesting \(v'\), which will never interact with u. In this paper, we deal with a variant of the link prediction problem: Given a pair of indirectly interacting nodes, predict whether or not they will form a link in the future. We propose a solution to this problem that leverages the predicted duration of their interaction and propose two supervised learning approaches to predict how long will two nodes interact in a network. Given a set of network-based predictors, the basic approach consists of learning a binary classifier to predict whether or not an observed indirect interaction will last in the future. The second and more fine-grained approach consists of estimating how long the interaction will last by modeling the problem via survival analysis or as a regression task. Once the duration is estimated, new links are predicted according to their descending order. Experimental results on Facebook Network and Wall Interaction and Wikipedia Clickstream datasets show that our more fine-grained approach performs the best and beats a link prediction model that does not consider the interaction duration and is based only on network properties.
Similar content being viewed by others

1 Introduction
Nodes in a network interact in many ways. They can directly call, message, or email each other. More interestingly, nodes interact even if they are not linked together in the network, e.g., via group messages, chat rooms, etc. This phenomenon is called indirect interaction and, when persistent and observed between a pair of non-linked nodes, it can represent two nodes’ need to be linked together. More specifically, an indirect interaction between nodes u and v means that there is a particular action depending on the type of network under study that is involving both u and v during a given time interval \([t_a,t_b)\). Indirect interactions are present in all types of networks:
On social networks such as Facebook, users can interact through Wall posts, comments, group conversations, and shares with the users that are not on their friends’ list.
On Twitter, users can re-tweet or reply to tweets written by users who are not in their connections.
On Wikipedia hyperlink network, readers can navigate from page u to page v through the search box (on the top right corner of page u) in case there is no explicit link on page u to v. Some of these searches are casual and occasional, some last for a while because of current trending associations between things, while others suggest the demand of a physical link from page u to page v.
On Amazon co-purchased products network, we can discover future co-purchased products by looking at users’ search logs that may suggest examples of product recommendations: “people who purchased (or searched for) product u may also be interested in product v.” Moreover, considering a pair of products, if there are a relatively higher number of users purchasing those two products, then it will be helpful to allocate them in same warehouses.
On consumer review Web sites such as Yelp, people can write and read reviews on various products or businesses. As social networking Web sites, people make connections with others and share information. We can identify indirect interactions in such networks based on their common reviewed products and predict users’ future connections (friendships).

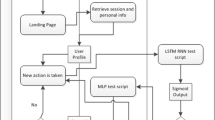
Examples of indirect interactions in Facebook (left) and Wikipedia (right)
We consider pairs (u, v) of non-linked yet indirectly interacting nodes. Figure 1 shows examples of indirect interactions in Facebook and Wikipedia. The indirect interaction between these nodes during an observational time interval \([t_a,t_b)\) is, in fact, the signal that u and v may have something in common and then it may be convenient linking them. Therefore, we study indirect interactions and their duration to connect nodes that can benefit from the new relationship. Indeed, not all the indirect interactions are useful. Casual indirect interactions are irregular and may be “one-time” interactions among different nodes. For instance in Wikipedia, during February 2016, the time when Donald Trump was nominated as Republican Nominee, users navigated from his Wikipedia page to different other Wikipedia pages like Trump University, Hollywood Walk of Fame, Hillary Clinton, etc. Though the number of interactions between those pages were in thousands, it was a casual interaction as it did not continue after that time period. Instead, persistent indirect interactions are indirect interactions that last over time. For instance, in Wikipedia, there were indirect interactions between two pages Doctor Strange (film) and Baron Mordo in February 2016 and users continued to navigate between these two pages even until April 2016. Later on, a hyperlink from Doctor Strange (film) to Baron Mordo was created after April 2016.
In this paper, we define a variant of the link prediction problem: Given a pair of indirectly interacting nodes, predict whether or not they will form a link in the future. Our solution for this problem leverages the predicted duration of their indirect interaction. In fact, we observed on two longitudinal real-world datasets, namely Facebook Network and Wall Interactions and Wikipedia Clickstream, that the longer the indirect interaction between u and v the higher the probability that u and v end up forming a link. Thus, we propose two supervised learning approaches to predict how long will two nodes interact in a network. Given a set of network-based predictors, the basic approach consists of learning a binary classifier to predict whether or not an observed indirect interaction will last in the future. The second and more fine-grained approach consists of estimating how long the interaction will last by modeling the problem via survival analysis or as a regression task. Once the duration is estimated, new links are predicted according to their descending order.
We performed an extensive experimental evaluation on Facebook and Wikipedia longitudinal datasets to test our approach to predict indirect interaction duration and its application to the link prediction task. Based on all the experiments, our results show that our more fine-grained approach with survival analysis shows maximum improvement for predicting the duration of indirect interactions and achieves the best mean average precision on both Facebook and Wikipedia datasets for link prediction between indirectly interacting nodes. Moreover, our approach performs with a better mean average precision on both the datasets considered than a link prediction model that does not consider the interaction duration and is based only on network properties.
The paper is organized as follows. Section 2 discusses the related work. Section 3 presents our approach for link prediction between indirectly interacting nodes. Section 4 introduces the network-based predictors used in our proposed approach. Section 5 details the Facebook Network and Wall Interactions and Wikipedia Clickstream datasets used in the paper. Section 6 reports on experimental evaluation. Finally, conclusions are drawn in Sect. 7.
2 Related work
In this section, we describe related work on link prediction, link strength prediction, and survival analysis applied to data science problems.
2.1 Link prediction
Many works address the link prediction problem on different types of networks such as social networks, co-authorship networks, and protein–protein interaction networks (Backstrom and Leskovec 2011; Lei and Ruan 2012; Liben-Nowell and Kleinberg 2007; Pavlov and Ichise 2007, 2007). Liben-Nowell and Kleinberg (2007) defined the link prediction problem in their seminal paper as the problem of predicting the likelihood of a future relationship between any two nodes in a network. Hasan and Zaki (2011) provide a survey of link prediction in social networks. They divide the main features for link prediction into the following categories: node neighborhood-based features (common neighbors, Jaccard and Adamic–Adar similarities), path-based features (shortest path distance, rooted PageRank), and vertex or edge property based (preferential attachment, local clustering coefficient, SimRank). Subsequent work proposed other link prediction approaches based on supervised random walks (Backstrom and Leskovec 2011) or via matrix factorization (Menon and Elkan 2011), to cite a few.
Currently, the new frontier is to predict links by using the features produced by node embedding techniques (see Goyal and Ferrara 2018 for a survey and performance comparison). One example of these techniques is Node2Vec that we chose to use in our paper because it is scalable and outperforms other node embedding techniques such as LINE (Tang et al. 2015), DeepWalk (Perozzi et al. 2014), and spectral clustering (Tang and Liu 2011) in the task of link prediction (Grover and Leskovec 2016).
2.1.1 Link prediction in Wikipedia
There is plenty of work on hyperlink prediction problem in Wikipedia. Adafre and de Rijke (2005) proposed an approach to find missing hyperlinks in the network by considering a Wikipedia corpus and its underlying abstract words. They stated that similar pages should have similar hyperlinks. Noraset et al. (2014) did a similar work by considering the text in Wikipedia pages. West et al. (2009) proposed a method based on principal component analysis of the hyperlink adjacency matrix. In another work, West et al. (2015) used human navigation logs available from The Wiki GameFootnote 1 and Wikispeedia (West et al. 2009) to identify missing links in Wikipedia.
Recently, Paranjape et al. (2016) addressed the problem of suggesting hyperlinks to add in the encyclopedia that improve readers’ navigation and maintain a high-quality link structure. In some sense, they are close to our work because they are suggesting links that are useful in the future. However, there is a main difference between our work and the one of Paranjape et al. when we have to predict the link between two pages (prev, curr) having \(type='other'\). More specifically, their method relies on the number of hits from prev to curr only, while we consider the estimated duration of the indirect interaction computed by using many other network-based variables. Moreover, the distribution (shown in Fig. 2) of number of hits for pairs of pages having \(type='other'\) for persistent and casual interactions is the same in February 2016 Clickstream dataset, suggesting that number of hits alone is not a good predictor for our problem. We further compare our approach with the algorithm proposed by Paranjape et al. for hyperlink prediction in Wikipedia in Sect. 6.3.

Number of hits distribution in February 2016 Wikipedia Clickstream dataset
2.2 Link strength prediction
Link strength prediction is a problem close to link prediction and is defined as follows: Given an existing link between two nodes, predict the weight or strength of this link. While some works focus on predicting the number of interactions between two linked nodes (Kamath et al. 2014; Zignani et al. 2016), others attempt to predict the type of the relationship: weak or strong tie (Dhakal et al. 2017; Gilbert and Karahalios 2009; Jones et al. 2013; Kahanda and Neville 2009; Xiang et al. 2010), or degree of like/dislike (Kumar et al. 2016; Qian and Adali 2014; West et al. 2014).
Zignani et al. (2016) addressed the problem of predicting if “newborn” Facebook links will interact or not in the future. Kamath et al. (2014) studied the problem of predicting the number of interactions between two nodes in Twitter.
Wilson et al. (2012) addressed the issue if all the connections/links were valid indicators of real interactions among the users in a social network. They observed that the interactivity in Facebook skewed toward a smaller portion of user’s friendship network raising the doubt whether or not all links imply equal friendship relationships. They also suggested that applications in social networks should consider interaction activity rather than mere connections.
Many works agree on the fact that social network interactivity is a solid indicator of the nodes relationship types (Gilbert and Karahalios 2009; Jones et al. 2013; Kahanda and Neville 2009). For instance, many papers show that measures of the intimacy, intensity, and duration of node communications are the most important features to predict weak/strong ties (Gilbert and Karahalios 2009; Jones et al. 2013; Xiang et al. 2010). Kahanda and Neville (2009) through their experiments suggested that it is necessary to consider transactional events such as file sharing, Wall posts, picture tags, and messages, as they are very useful for predicting link strength among the users in the social network.
2.3 Survival analysis applications
Survival analysis is often used in the medical domain to predict the probabilities of occurrence of an event, i.e., chances or survival or estimated death probabilities, etc., but it has been applied to other problems as well. Dave et al. (2017) used survival analysis for the reciprocal link prediction problem, i.e., predicting when a link will be reciprocated in a network. Rakesh et al. (2016) and Li et al. (2016) used survival analysis on crowd-funding platforms and studied if the goal for the crowd-funding project was met within the stipulated time or not. Murtaugh et al. (1999) and Ameri et al. (2016) studied the student retention problem and used survival analysis to estimate whether a student will drop out or not and if so, when will they drop out. Survival analysis can also be used to predict the probability (also called click-through rate) of a user clicking the advertisement within time t (Cacheda et al. 2017; Richardson et al. 2007).
3 Link prediction framework
In this section, we address the new problem of predicting whether or not a pair of non-linked nodes, yet showing an indirect interaction, will become a link in the future. On the contrary, the classical link prediction problem consists of predicting new links between any pair of nodes.
We adopt the link prediction framework with single feature proposed by Liben-Nowell and Kleinberg (2007). This framework consists of the following steps:
- 1.
assign a score to each candidate pair of non-linked nodes,
- 2.
order the candidate pairs in descending order and take the top-n pairs with the highest score,
- 3.
evaluate how many of these top-n pairs are links in the test set.
Our hypothesis in this paper is that pairs of nodes for which we can predict that the indirect interaction will last longer should be prioritized with respect to candidates that are predicted to last shorter time because in the former case linking the two nodes can be more beneficial for both of them. Therefore, we propose to assign a score score(u, v) to each pair of indirectly interacting nodes (u, v) that are not linked that is proportional to the estimated duration of their indirect interaction. To have a training period to learn a model that estimates the indirect interaction duration, we consider the time divided into the following intervals:
\([t_a, t_b)\) is the time interval we use to observe indirect interactions between nodes.
\([t_b, t_c]\) is the time interval we use to observe when an indirect interaction individuated within the time interval \([t_a, t_b)\) will stop.
\((t_d, t_e]\) is the time interval we use to observe which new links have been formed.
We say that an indirect interaction stops in the time interval \([t_b, t_c]\) if it is not persistent in that time interval.
Definition 1
(Persistent Indirect Interaction) Let (u, v) be a pair of nodes having an indirect interaction during the time interval \([t_a,t_b)\). We say that this indirect interaction is persistent during the time interval \([t_b,t_c] = [t_b, t_b+k) \cup [t_b+k, t_b+2k) \cup \dots \cup [t_b+hk, t_c]\) if the number of indirect interactions between nodes u and v during each time interval \([t_b+(h-1)k, t_b+hk)\), \(h \in \{1,2,\dots ,L=\frac{{t_c - t_b}}{k}\}\), is always greater than or equal to a threshold \(\gamma\).
Thus, we assume the time interval \([t_b,t_c]\) to be divided into k time periods, e.g., days, weeks, months, etc., and we require an indirect interaction to show some regularity to be persistent, i.e., at least \(\gamma\) interactions per day, or week, or month, etc.
3.1 Checking the validity of our hypothesis
We performed a two-sample one-tail t-test on the two datasets used in this paper, namely Facebook Network and Wall Interaction and Wikipedia Clickstream, to test whether or not there is sufficient evidence to support the hypothesis that the indirect interaction lasts longer for a pair of nodes that end up forming a link than for those pairs that will not be linked in the future. The null hypothesis and alternative hypothesis are formulated as follows: \(H_0 = \mu _0 \ge \mu _1\) and \(H_1 = \mu _0 < \mu _1\), where \(\mu _0\) (resp. \(\mu _1\)) is the average duration (during the time interval \([t_b, t_c]\)) of an indirect interaction for pair of nodes that are not linked (resp. that are linked) at time \(t \in (t_d, t_e]\). The p-values for a significant level \(\alpha = 0.01\) result less than 0.001 on both datasets, suggesting that there is strong statistical evidence to reject the null hypothesis (\(H_0\)) and validate our hypothesis (\(H_1\)) on both Facebook and Wikipedia datasets. More specifically, we observe an indirect interaction to last 3.09 k for links versus 1.47 k for non-links in Facebook and 2.02 k for links versus 1.56 k for non-links in Wikipedia. We set k equal to six months for Facebook and one month for Wikipedia.
3.2 Predicting indirect interaction duration
In this section, we propose several approaches to the problem of predicting how long will an indirect interaction between two nodes last.
Definition 2
(Indirect interaction duration problem) Given two nodes u and v in a network such that during the time interval \([t_a,t_b)\):
- (1)
there is no link between them, and
- (2)
we observe an “indirect interaction” between u and v, predict how long the nodes u and v will keep interacting after \(t_b\).
We propose two supervised learning approaches to the problem of predicting the duration of indirect interaction. Given a candidate pair of indirectly interacting nodes \(i=(u,v)\) and a vector of predictors \(X_i\), the basic approach consists of predicting whether or not the indirect interaction \(i=(u,v)\) will last, while the more fine-grained approach consists of estimating how long the indirect interaction will last. These approaches are detailed in the following sections.
3.2.1 Basic approach
In order to predict whether the indirect interaction between a pair of non-linked nodes \(i=(u,v)\) will last or not, we model the problem as a binary classification task where the input features are given by \(X_i\), and the positive class is given by the set of instances that do not stop interacting in the time interval \([t_b, t_c]\), i.e., their indirect interaction continues after \(t_c\). All the instances that stop their indirect interaction at any time \(t_b \le t \le t_c\) fall into the negative class.
3.2.2 Fine-grained approach
To predict the indirect interaction duration in the time interval \([t_b, t_c],\) we can use two different methods, namely survival analysis and regression. In the following, we describe how we can model the problem according to these two methods.
Modeling the problem via survival analysis Survival analysis is a statistical method to estimate the expected duration of time until an event of interest occurs (Wang et al. 2017).
We apply survival analysis to the time interval \([t_b, t_c]\) to compute the survival time or duration of indirect interaction. In our case, the event of interest is when the indirect interaction between two nodes stops. The time when the event of interest happens for the instance \(i = (u,v)\) is denoted by \(T_i\) (\(T_i \in [t_b, t_c]\)). During the study of our survival analysis problem, it is possible that the event of interest is not observed for some instances; this occurs because we are observing the problem in the limited time window \([t_b, t_c]\) or we miss the traces of some instances. If this happens for an instance i, we say that i is censored and denote by \(C_i\) the censored time. Censored instances can be effectively approached using survival analysis. Let \(\delta _i\) be a Boolean variable indicating whether or not the instance i is not censored, i.e., if \(\delta _i = 1\) then the instance i is not censored. We denote by \(y_i\) the observed time for the instance i that is equal to \(T_i\) if i is uncensored and \(C_i\) otherwise, i.e.,
Given a new instance j described by the feature vector \(X_j\), survival analysis estimates a survival function \(S_j\) that gives the probability that the event for the instance j will occur after time t, i.e., \(S_j(t) = Pr(T_j \ge t)\).
The survival function can be used to compute the expected time \(\hat{y_j}\) of event occurrence for an instance j as explained in Sect. 3.3.
There are different types of statistical methods to estimate the survival function. In this paper, we consider parametric methods such as the accelerated failure time, where we hypothesized the survival times can follow Weibull, exponential or lognormal distribution, and semiparametric methods such as the Cox model where the knowledge of the underlying distribution of survival times is not required (Wang et al. 2017).
Modeling the problem via regression Another way to estimate the duration of an indirect interaction is to model the problem as a regression task, i.e., estimating the parameters \(\beta\) of a function f such that \(y_i \approx f(X_i,\beta )\), for each instance i in the training set. The main difference between regression and survival analysis is that regression is not able to incorporate the information coming from censored instances within the predictive model. In the case of regression, censored instances are typically ignored or their observed time \(y_i\) is modeled as a constant \(t_R\) much bigger than \(t_c\).
3.3 Scoring candidate pairs
In the previous section, we proposed several methods to predict the indirect interaction duration. We now explain how to compute the value of score(u, v) for each of these methods.
Classification If we are using classification, score(u, v) is equal to the probability given by the classifier that the instance \(i=(u,v)\) is in the positive class, i.e., the indirect interaction will last.
Survival analysis If we are using survival analysis, the score is given by the expected time \(\hat{y_i}\) the indirect interaction is predicted to stop, i.e., \(score(u,v)=\hat{y_i}\). The predicted expected time \(\hat{y_i}\) of event occurrence is computed as follows. From the survival analysis model, we will have the following probabilities: \(S_i(t_b)=Pr(T_i \ge t_b)\), \(S_i(t_{b}+k)=Pr(T_i \ge t_{b}+k)\), ..., \(S(t_c)=Pr(T_i \ge t_c)\). The probability \(Pr(t_b + (h-1)k \le T_i < t_b + hk)\) that the indirect interaction will stop in the interval \([t_b + (h-1)k,t_b + hk)\) is given by
for \(1 \le h \le L\), where L is the number of units we divided the interval \([t_b,t_c]\) into.
Because we have a limited time window \([t_b, t_c]\) to observe when the indirect interaction is stopping, a lower bound of the expected time \(\hat{y_i}\) when the indirect interaction will stop is given by
When \(\hat{y_i} = t_c\) we can say that the indirect interaction can stop at any time \(t \ge t_c\), but we do not know exactly when.
Regression Finally, if we are using regression, \(score(u,v)=\hat{y_i}\) where \(\hat{y_i}=f(X_i,\beta )\) is the estimated duration of the indirect interaction i predicted by the regression model.
4 Predictors
In this section, we describe the list of predictors we used to predict the duration of indirect interaction. These are classical network-based predictors commonly used for link prediction that we will test on a new task. We recall that the contribution of this paper is not in the definition of new predictors for link prediction, but in the definition of a new link prediction problem and a solution that takes into account the indirect interaction duration to predict future links in a network.
We consider three broad categories of predictors, namely node based, neighborhood based, and network based. For each dataset, these features are computed within the time interval \([t_a,t_b)\).
Let \(G=(V,E)\) be an undirected graph where V is the set of nodes and \(E \subseteq V \times V\) is the set of edges. Let u be a node in V, we denote by \(\varGamma (u)\) the set of neighbors of node u where \(\varGamma (u)=\{ v \in V | (u,v) \in E \vee (v,u) \in E\}\). For directed graphs, we define by \(\varGamma _{in}(u)=\{ v \in V | (v,u) \in E \}\) the set of nodes pointing toward u and by \(\varGamma _{out}(u)=\{ v \in V | (u,v) \in E \}\) the set of nodes pointed by u.
4.1 Node-based features
We consider the following node-based features.
Degree For an undirected graph, the degree of a node \(u \in V\) is \(deg(u) = |\varGamma (u)|\), i.e., the number of its neighbors. For directed graphs, we consider both the in-degree \(indeg(u)= |\varGamma _{in}(u)|\) and out-degree \(outdeg(u)= |\varGamma _{out}(u)|\).
Hits For an undirected graph, hits(u, v) is the number of indirect interactions between u and v. For directed graphs, we split this variable into two and consider number of indirect interactions from u to v and number of indirect interactions from v to u.
4.2 Neighborhood-based features
We consider the following neighbors-based features.
Common neighbors For a pair of nodes (u, v), we define as common neighbors CN(u, v) the number of nodes that share an edge with both nodes u and v. For an undirected graph, \(CN(u,v) = |\varGamma (u) \cap \varGamma (v)|\). For a directed graph, \(CN(u,v) = |(\varGamma _{in}(u) \cup \varGamma _{out}(u)) \cap (\varGamma _{in}(v) \cup \varGamma _{out}(v))|\).
Jaccard Similarity The Jaccard similarity between two nodes u and v is defined as
for an undirected graph and
for directed graphs.
Adamic–Adar Similarity The Adamic–Adar similarity between two nodes u and v is defined as
It can be extended to directed graphs in the same way we extend the Jaccard similarity.
Preferential attachment score For a pair of nodes (u, v), the preferential attachment (PA) score is given by
for undirected graphs and
for directed graphs.
Local clustering coefficient The local clustering coefficient (LCC) measures the probability that the neighbors of a node are connected, and it is equal to
Given a pair of nodes (u, v), we consider both LCC(u) and LCC(v) as features.
4.3 Network-based features
We consider the following network-based features.
PageRank The PageRank (PR) is a popularity measure for nodes in a network and it is defined as
where \(\beta\) is the damping factor usually set to 0.85 (Brin and Page 1998). Given a pair of nodes (u, v), we consider both PR(u) and PR(v) as features.
Node2Vec. Network embedding is a technique for mapping each node in a graph in a geometric high dimensional space. Once the embedding is obtained for each entity, its geometric representation can be used as features in input to machine learning algorithms. Node2Vec (Grover and Leskovec 2016) is an embedding technique based on random walks. It computes the embedding in two steps. First, the context of a node (or neighborhood at a distance d) is approximated with biased-random walks of length d that provide a trade-off between breadth-first and depth-first graph searches. Second, the values of the embedding features for the node are computed by maximizing the likelihood of generating the context by the given node. Since Node2Vec returns a vector of feature F(u) for each node u, we combined the Node2Vec features for a pair of nodes (u, v) to be the Hadamard (or entrywise) product of F(u) and F(v). Grover and Leskovec (2016) showed this type of vectorial product works the best for link prediction.
5 Datasets
In this paper, we consider two longitudinal datasets, namely Facebook Network and Wall Interactions and Wikipedia Clickstream. Facebook is an example of a network with node-dependent indirect interactions, i.e., the nodes in the network are the agents performing the indirect interaction. Instead, Wikipedia is an example of a network with node-independent indirect interactions, i.e., there exists an external agent, the user surfing the hyperlink network, in this case, that is responsible for causing the indirect interaction.
5.1 Facebook Network and Wall Interactions
This dataset contains the evolution of the friendship network and users’ Wall Interactions crawled from the New Orleans Facebook Network from September 2006 to January 2009 (Viswanath et al. 2009). We have about 60 K nodes, 800 K edges, and 176 K Wall Interactions between pairs of users in the dataset. We divided the time into intervals of 6 months.
We considered two users u and v to have an interaction if they were both tagged by another user z’s post. The Wall Interactions are described by triples \((u,v,t_s)\) in the dataset whose meaning is that user v is posting on user u’s Wall a time \(t_s\). Then, to identify these interactions, we grouped the Wall Interaction triples by timestamp and first user and also by timestamp and second user. In the first case, we get, for each user u and timestamp \(t_s\) the set of users \(\{v_1, v_2, \ldots , v_n\}\) that were tagged in u’s post, while, in the second case, we get, for each user v and timestamp \(t_s\) the set of users \(\{u_1, u_2, \ldots , u_m\}\) that were tagged in v’s post. Therefore, we considered all pairs of users in \(\{v_1, v_2, \ldots , v_n\}\) and all pairs of users in \(\{u_1, u_2, \ldots , u_m\}\) to have an interaction. If those pairs of users do not have a link, then they have an indirect interaction.
5.2 Wikipedia Clickstream
Wikipedia Clickstream is a Wikimedia’s research project Footnote 2 in progress. The dataset consists of pairs of (referrer page, resource page) obtained from the extracted request logs of Wikipedia. There are eight (non-contiguous) months’ datasets released till December 2017, starting from January 2015. Each dataset contains a set of tuples of the form (prev, curr, type, n) where:
prev is the referrer URL or Wikipedia page title if the referrer is within Wikipedia.
curr is the title of the Web page the client requested or Wikipedia page title if the resource page is within Wikipedia.
type describes (prev, curr) as (a) link if the referrer and request are both Wikipedia pages and the referrer links to the request, (b) external if the referrer host is not en.wikipedia.org, and (c) other if the referrer and request are both Wikipedia pages, but the referrer does not link to the request. This can happen when clients search or spoof their referrer.
n is the number of occurrences (greater than 10) of the (referrer, resource) pair. Considered as number of hits from prev to curr.
This dataset explicitly provides us the indirect interactions as those pair of pages having type=‘other’. They refer to pairs of pages from Wikipedia which do not have a direct link between them, but that users navigated through search bar of the Wikipedia pages.
In this paper, we consider February 2016 (27 M of tuples), March 2016 (25 M of tuples), and April 2016 (21 M of tuples) datasets as they are the longest consecutive months available in Clickstream. For new links ground truth we considered August 2016 dataset (24 M of tuples, out of which 14 M have type = ‘link’).
6 Experimental evaluation
In this section, we report on our extensive experimental evaluation to test our approach to predict the duration of indirect interaction and newly formed links between indirectly interacting nodes.
6.1 Experimental setting
To perform our experiments, we divided each dataset into three time periods as follows:
for Facebook we set \(t_a=Sep2006\), \(t_b=Jan2007\), \(t_c=t_d=Dec2008\), and \(t_e=Jan2009\);
for Wikipedia we set \(t_a=Feb1,2016\), \(t_b=Mar1,2016\), \(t_c=Apr30,2016\), \(t_d=Jul31,2016\), and \(t_e=Aug31,2016\).
For each dataset, we selected all pairs of nodes I that showed an indirect interaction in the time interval \([t_a,t_b)\). Then, for each pair \(i=(u,v) \in I\) we checked whether (u, v) continued to persistently interact in the interval \([t_b,t_c]\). If no, we set \(T_i=0\), if yes when the persistent interaction stopped at some time \(t\in [t_b,t_c]\) we set \(T_i=t\), and if the persistent interaction never stopped in the interval \([t_b,t_c]\) we considered the instance i to be censored. The number of indirect interactions in the time interval \([t_a,t_b)\) and censored instances is reported for each dataset in Table 1. For Wikipedia, we filtered out from February 2016 other types of tuples having prev or curr equal to the Wikipedia main page. This is because the main page changes every day and searches from or to this page represent noise in the dataset. We computed the set of predictors by considering the status of the network during the time interval \([t_a,t_b)\). For link prediction ground truth, we considered new links formed in the time interval \((t_d,t_e]\).
In all the datasets, we are considering we have the class imbalance problem, i.e., we have more negative instances (instances that stopped interacting) than positive instances (the interaction did not stop in the observational period - these are censored instances). Then, we used a majority under sampling strategy as proposed in Dave et al. (2017) for a similar problem. For each dataset, we created a pool of sub-datasets as follows. First, we created 10 random samples of the majority class whose size to be the same as the one of the minority class. Then, we paired each of these samples with all the instances in the minority class and performed a fivefold cross-validation in each of those 10 balanced datasets. We finally averaged the results obtained from all the fivefold cross-validations. We used the same subsets of datasets across all the experiments we did in this paper.
Baselines As baselines to compare our results on indirect interaction duration prediction and link prediction, we consider number of hits, Jaccard similarity, Adamic–Adar similarity, preferential attachment score, and the cosine similarity between the Node2Vec features of the two nodes in the candidate pair. These are popular baselines typically used for link prediction as shown in the experimental setting used in Grover and Leskovec (2016).
6.2 Predicting indirect interaction duration
This section reports experimental results on predicting indirect interaction duration with both our proposed approach: basic and fine-grained.
6.2.1 Will the indirect Interaction last or not?
In this experiment, we consider our predictors as input to a binary classifier to predict if the indirect interaction will last or not. In this case, we considered censored instances as positive instances (the interaction will last) and instances where the event occurred (i.e., they stopped to interact) negative instances. We used support vector machine (SVM) with linear and radial basis function kernel (RBF) kernel, logistic regression, K-nearest neighbors (K-NN), and random forest as classification algorithms. We compared the performances according to area under the ROC curve (AUROC) and mean average precision (MAP). Results are reported in Table 2 (top rows). As we can see, the best classifier is random forest for all the cases. For Facebook, we can predict whether or not an indirect interaction will last with an AUROC of 0.90 and a MAP of 0.89. For the same problem on the Wikipedia dataset, we achieve an AUROC of 0.78 and a MAP of 0.78.
Comparison with baselines. Given the baselines described in Sect. 6.1, we computed the AUROC and MAP between the rank provided by these features on the candidate pairs and the class values. Results are reported in Table 2 (bottom rows). Jaccard similarity is the best for Facebook (AUROC of 0.707 and MAP of 0.701), while for Wikipedia Node2Vec is the best according to AUROC (0.583) and Adamic–Adar similarity is the best according to MAP (0.611). Overall, our best approach from Table 2 (top rows) significantly beats these baselines.
6.2.2 How long will the indirect interaction last?
In this experiment, we compare survival analysis and regression on the task of predicting how long will an indirect interaction lasts.
For survival analysis, we used the Cox model and the accelerated failure time parametric model with different distributions for survival time, namely Weibull, exponential and lognormal. We used the implementations of these models available in R. For regression, we considered Ridge regression, Lasso regression, and support vector regression (SVR) with RBF kernel. Since regression cannot deal with censored instances, we approximated the occurrence time of censored instances with a time value \(t_R>> t_{e}\).
To compare the performances of these two classes of algorithms, we considered two metrics that are commonly used to evaluate survival analysis models, namely c-index and mean absolute error (MAE) (Wang et al. 2017).
The c-index is defined as
where \(N_{\mathrm{cnt}}\) is the number of all pairs \((y_i,y_j)\) such that \(C_i=1\) (non-censored instances) and it holds that \(y_j > y_i\), \(\hat{y_i}\) is the estimated duration predicted by the model. The c-index measures the concordance probability between the actual observation times and the predicted values. It is worth noting that the baseline value for the c-index of a random classifier is not 0.5, but it is 0.31 for Facebook and 0.22 for Wikipedia according to the distribution of observed times for events of interest in the datasets.
The mean absolute error is defined as the average absolute difference between the predicted duration of the event and the actual one
where N is the number of non-censored instances, i.e., for which the event occurred. The results reported in the paper for MAE are normalized.
Also, we considered the Pearson correlation coefficient (PCC) between the actual time and the predicted time of event occurrence. Higher c-index and PCC and lower MAE are desirable.
Table 3 reports the values of the above three metrics for survival analysis on all the datasets. Table 4 shows the results for regression.
By looking at these results, it is clear that for both the Facebook and Wikipedia datasets, survival analysis with the Cox model performs better than regression in predicting the duration of the indirect interaction. In the case of Facebook, both Cox model and Ridge and Lasso regression achieve the same value of c-index, but Cox has a lower MAE (0.25 vs. 0.38) and a higher PCC (0.46 vs. 0.41). Even though SVR has the best MAE (0.22), its values for c-index and PCC are worse.
In the case of Wikipedia, the Cox model outperforms other survival analysis algorithms and regression according to all the measures considered: c-index of 0.502, MAE of 0.11 and PCC of 0.32.
Comparison with Baselines. Table 5 shows the c-index, MAE, and PCC with respect to the baselines. In this case, we are using the values of the baselines to approximate the indirect interaction duration. Again, the c-index results to be not a good measure to discriminate among our approaches and the baselines because their values are all comparable.
Overall, our approach is better than the baselines for both the datasets. For Facebook, our best MAE and PCC obtained with survival analysis are better than the ones of all the baselines except for hits that beats us according to MAE. However, hits achieves very low values for c-index and PCC in than our approach. For Wikipedia, our best approach obtained with survival analysis is always better than the baselines according to MAE and PCC, and comparable with respect to c-index.
6.3 Link prediction
In this section, we report on the experiments we performed on link prediction between indirectly interacting nodes. On Wikipedia, the problem is to predict whether or not there should be a hyperlink placed from page u to page v. We considered the hyperlinks present as type “link” in August 2016 Clickstream dataset as ground truth. For Facebook, the problem is to predict whether or not two nodes u and v should become friends. As ground truth for Facebook, we used the links formed in January 2009.
In this experiment, we first trained the model (classification, survival analysis, or regression) to predict when (or “if” in the case of classification) the indirect interaction will stop. Then, we computed the area under the ROC curve (AUROC) and the mean average precision (MAP) between these predicted times Footnote 3 and the class values (1 if the link has been created later on, 0 otherwise). AUROC and average precision are two measures that are commonly used to evaluate classification on unbalanced datasets. However, they have a different meaning. The AUROC score gives the probability that a classifier will correctly identify a randomly selected (positive or negative) sample. The average precision score gives the probability that a classifier will correctly identify a randomly selected positive sample (e.g., the presence of a link between two nodes) as being positive. Higher average precision values mean higher precision (correct prediction of links) and higher recall (finding all links). Moreover, the average precision is not influenced by the data sampling in the evaluation
Table 6 shows the comparison of the AUROC and MAP values for classification, survival analysis, and regression. As we can see, the best results are achieved on both datasets by the more fine-grained approach that is predicting how long the interaction will last. More specifically, survival analysis with the accelerated failure time model with exponential distribution for Facebook and the Cox model for Wikipedia, outperforms both regression and classification. In fact, on the Facebook dataset, we obtain and AUROC of 0.854 and the best MAP of 0.214. On the Wikipedia dataset, we achieve the best MAP of 0.661, while the AUROC values are generally not good. This result can be related to the time periods of the Wikipedia dataset. In fact, the model to estimate the indirect interaction duration is learned on the data for the months of February, March, and April 2016, while the ground truth labels are extracted from the August 2016 dataset, so the times are not contiguous as happens, instead, in the Facebook dataset.
Comparison with Baselines. Table 7 shows the best results for link prediction we obtained with our approach in comparison with the baselines. In this experiment, we are assuming that the values of each baseline can be considered as the predicted values for the indirect interaction duration, i.e., the AUROC is computed between the baseline values and the class. For Wikipedia, we also compare with the hyperlink prediction method from Paranjape et al. (2016) that, as we have seen in Sect. 2.1.1, it is the closest to our work. We implemented their algorithm with the best objective function (\(f_3\)) according to the experiments in their paper. The results in Table 7 show that our best approach is always better than the baselines, with the exception of Paranjape et al. (2016) in Wikipedia that achieves a better AUROC of 0.618 on Wikipedia, but a worse MAP of 0.562 (vs. 0.661 obtained with our best approach).
Also, we performed another experiment to compare our approach. More specifically, we use all the predictors computed with a snapshot of the network during the time interval \([t_a,t_b)\) as input to a classifier to directly predict whether or not there will be a link during the time interval \((t_d,t_e]\) between nodes that are indirectly interacting during the time interval \([t_a,t_b)\). This is a classical link prediction solution that does not consider the indirect interaction duration. Results are reported in Table 8 for different classifiers: K-nearest Neighbors (K-NN), support vector machine (SVM) with different kernels (linear and RBF), logistic regression, and random forest. As we can see, if we skip the step of predicting the indirect interaction duration, a model based only on network properties achieves worse MAP values, on both datasets on the link prediction task between indirectly interacting nodes, than the values achieved by our best approach that considers the predicted interaction duration (0.214 vs. 0.080 for Facebook and 0.661 vs. 0.17 for Wikipedia).
In general, algorithms that optimize the AUROC are not guaranteed to optimize the average precision (Davis and Goadrich 2006), as it happens in the Wikipedia dataset. In this case, the experiments presented in this section (see Tables 7 and 8) show a better AUROC for Paranjape et al. (2016) (0.618) and classical link prediction without indirect interaction duration (0.679 with K-NN) than our best method (0.528). However, our best method shows a much better average precision for the Wikipedia dataset: 0.661 versus 0.562 for Paranjape et al. (2016) and 0.015 for classical link prediction without indirect interaction duration (with K-NN).
In summary, the experimental results shown in this section suggest that knowing how long an indirect interaction persists in the training period is helpful in making more precise predictions about whether those indirectly interacting nodes will form a link in the future.
7 Conclusion
In this paper, we addressed the problem of predicting links between pairs of indirectly interacting nodes. We proposed an approach to solve the problem in two steps. First, we focused on the problem of predicting how long will a pair of nodes (u, v) interact in a network for those pairs of nodes that are not connected, yet show some indirect interaction. Second, once the duration was estimated, we leveraged this information for the link prediction task. We proposed two supervised learning approaches for the problem of predicting the duration of indirect interaction. Given a set of predictors, the basic approach consisted of learning a binary classifier to predict whether or not an observed indirect interaction will last in the future. The second and more fine-grained approach consisted of estimating how long the interaction will last by modeling the problem via survival analysis or as a regression task.
We performed experiments on the longitudinal Facebook Network and Wall Interactions and Wikipedia Clickstream datasets. Our experimental results showed that survival analysis on Facebook and regression on Wikipedia achieved the maximum improvement for predicting the duration of indirect interactions (MAE 0.25 and PCC 0.46 in Facebook and MAE 0.09 and PCC 0.91 in Wikipedia) and reached the best MAP values of 0.214 on Facebook and 0.661 on Wikipedia for link prediction between indirectly interacting nodes. We also observed that if we do not consider the predicted indirect interaction duration, a classifier based only on network properties performed with 0.080 and 0.170 MAP on Facebook and Wikipedia, respectively, on link prediction which is lower than what was achieved by considering predicted interactivity duration.
Notes
For the case of classification, we considered the predicted probability of having a link in the future.
References
Adafre SF, de Rijke M (2005) Discovering missing links in Wikipedia. In: LinkKDD ’05, pp 90–97
Ameri S, Fard MJ, Chinnam RB, Reddy CK (2016) Survival analysis based framework for early prediction of student dropouts. In: CIKM, pp 903–912
Backstrom L, Leskovec J (2011) Supervised random walks: predicting and recommending links in social networks. In: WSDM, pp 635–644
Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. Comput Netw 30(1–7):107–117
Cacheda F, Barbieri N, Blanco R (2017) Click through rate prediction for local search results. In: WSDM, pp 171–180
Dave VS, Hasan MA, Reddy CK (2017) How fast will you get a response? Predicting interval time for reciprocal link creation. In: ICWSM, pp 508–511
Davis J, Goadrich M (2006) The relationship between precision-recall and roc curves. In: Proceedings of the 23rd international conference on machine learning. ACM, pp 233–240
Dhakal N, Spezzano F, Xu D (2017) Predicting friendship strength for privacy preserving: a case study on Facebook. In: ASONAM, pp 1096–1103
Gilbert E, Karahalios K (2009) Predicting tie strength with social media. In: CHI, pp 211–220
Goyal P, Ferrara E (2018) Graph embedding techniques, applications, and performance: a survey. Knowledge-Based Syst 151:78–94
Grover A, Leskovec J (2016) Node2vec: scalable feature learning for networks. In: KDD, pp 855–864
Gundala LA, Spezzano F (2018) A framework for predicting links between indirectly interacting nodes. In: IEEE/ACM 2018 international conference on advances in social networks analysis and mining, ASONAM 2018, Barcelona, Spain, August 28–31, 2018, pp 544–551
Hasan MA, Zaki MJ (2011) A survey of link prediction in social networks. In: Aggarwal C (ed) Social network data analytics. Springer, Boston, MA, pp 243–275
Jones JJ, Settle JE, Bond RM, Fariss CJ, Marlow C, Fowler JH (2013) Inferring tie strength from online directed behavior. PloS One 8(1):e52168
Kahanda I, Neville J (2009) Using transactional information to predict link strength in online social networks. In: 3rd international AAAI conference on weblogs and social media, pp 74–81
Kamath K, Sharma A, Wang D, Yin Z (2014) Realgraph: user interaction prediction at twitter. In: User Engagement Optimization Workshop @ KDD
Kumar S, Spezzano F, Subrahmanian VS, Faloutsos C (2016) Edge weight prediction in weighted signed networks. In: ICDM, pp 221–230
Lei C, Ruan J (2012) A novel link prediction algorithm for reconstructing protein–protein interaction networks by topological similarity. Bioinformatics 29(3):355–364
Liben-Nowell D, Kleinberg J (2007) The link-prediction problem for social networks. J Assoc Inf Sci Technol 58(7):1019–1031
Li Y, Rakesh V, Reddy CK (2016) Project success prediction in crowdfunding environments. In: WSDM, pp 247–256
Menon AK, Elkan C (2011) Link prediction via matrix factorization. In: ECML PKDD, pp 437–452
Murtaugh PA, Burns LD, Schuster J (1999) Predictiong the retention of university students. Res High Educ 40(3):355–371
Noraset T, Bhagavatula C, Downey D (2014) Adding high-precision links to Wikipedia. In: EMNLP ’14, pp 651–656
Paranjape A, West R, Zia L, Leskovec J (2016) Improving website hyperlink structure using server logs. In: WSDM ’16, pp 615–624
Pavlov M, Ichise R (2007) Finding experts by link prediction in co-authorship networks. In: Proceedings of the 2nd international conference on finding experts on the web with semantics, vol 290, pp 42–55
Pavlov M, Ichise R (2007) Finding experts by link prediction in co-authorship networks. In: Proceedings of the 2nd international conference on finding experts on the web with semantics, vol 290. FEWS’07, pp 42–55
Perozzi B, Al-Rfou R, Skiena S (2014) Deepwalk: online learning of social representations. In: KDD, pp 701–710
Qian Y, Adali S (2014) Foundations of trust and distrust in networks: extended structural balance theory. ACM Trans Web (TWEB) 8(3):13
Rakesh V, Lee W, Reddy CK (2016) Probabilistic group recommendation model for crowd funding domains. In: WSDM, pp 257–266
Richardson M, Dominowska E, Ragno R (2007) Predicting clicks: estimating the click-through rate for new ads. In: WWW, pp 521–530
Tang L, Liu H (2011) Leveraging social media networks for classification. Data Min Knowl Discov 23(3):447–478
Tang J, Qu M, Wang M, Zhang M, Yan J, Mei Q (2015) Line: large-scale information network embedding. In: WWW, pp 1067–1077
Viswanath B, Mislove A, Cha M, Gummadi KP (2009) On the evolution of user interaction in Facebook. In: WOSN, pp 37–42
Wang P, Li Y, Reddy CK (2017) Machine learning for survival analysis: a survey. CoRR arXiv:abs/1708.04649
West R, Paranjape A, Leskovec J (2015) Mining missing hyperlinks from human navigation traces: a case study of Wikipedia. In: WWW ’15, pp 1242–1252
West R, Paskov HS, Leskovec J, Potts C (2014) Exploiting social network structure for person-to-person sentiment analysis. Trans Assoc Comput Linguist 2:297–310
West R, Pineau J, Precup D (2009) Wikispeedia: an online game for inferring semantic distances between concepts. In: IJCAI’09, pp 1598–1603
West R, Precup D, Pineau J (2009) Completing Wikipedia’s hyperlink structure through dimensionality reduction. In: CIKM ’09, pp 1097–1106
Wilson C, Sala A, Puttaswamy KP, Zhao BY (2012) Beyond social graphs: user interactions in online social networks and their implications. ACM Trans Web (TWEB) 6(4):17
Xiang R, Neville J, Rogati M (2010) Modeling relationship strength in online social networks. In: WWW, pp 981–990
Zignani M, Gaito S, Rossi GP (2016) Predicting the link strength of “newborn” links. In: WWW Companion, pp 147–148
Author information
Authors and Affiliations
Corresponding author
Additional information
This paper is an extended version of the conference paper “Laxmi Amulya Gundala and Francesca Spezzano, A Framework for Predicting Links Between Indirectly Interacting Nodes. In Proceedings of the IEEE/ACM 2018 International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2018), pp 544–551” (Gundala and Spezzano 2018).
Rights and permissions
About this article

Cite this article
Gundala, L.A., Spezzano, F. Estimating node indirect interaction duration to enhance link prediction. Soc. Netw. Anal. Min. 9, 17 (2019). https://doi.org/10.1007/s13278-019-0561-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13278-019-0561-2