
Abstract
Accessible and reusable datasets are a necessity to accomplish repeatable research. This requirement poses a problem particularly for web science, since scraped data comes in various formats and can change due to the dynamic character of the web. Further, usage of web data is typically restricted by copyright-protection or privacy regulations, which hinder publication of datasets.
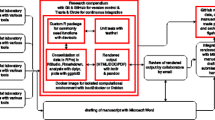
To alleviate these problems and reach what we define as “partial data repeatability”, we present a process that consists of multiple components. Researchers need to distribute only a scraper and not the data itself to comply with legal limitations. If a dataset is re-scraped for repeatability after some time, the integrity of different versions can be checked based on fingerprints. Moreover, fingerprints are sufficient to identify what parts of the data have changed and how much.
We evaluate an implementation of this process with a dataset of 250 million online comments collected from five different news discussion platforms. We re-scraped the dataset after pausing for one year and show that less than ten percent of the data has actually changed. These experiments demonstrate that providing a scraper and fingerprints enables recreating a dataset and supports the repeatability of web science experiments.






Similar content being viewed by others


Notes
Links to these platforms are https://www.dailymail.co.uk, https://www.theguardian.com, https://www.foxnews.com, https://www.independent.co.uk, https://www.rt.com.
References
Cohen KB, Xia J, Zweigenbaum P, Callahan TJ, Hargraves O, Goss F, Ide N, Névéol A, Grouin C, Hunter LE (2018) Three dimensions of reproducibility in natural language processing. In: Proceedings of the International Conference on Language Resources and Evaluation (LREC), May 7–12, 2018, European Language Resources Association (ELRA), Miyazaki, p. 156–165
Rozier KY, Rozier EWD (2014) Reproducibility, correctness, and buildability: The three principles for ethical public dissemination of computer science and engineering research. In: Proceedings of the International Symposium on Ethics in Engineering, Science, and Technology (ETHICS) IEEE, pp 1–13
Collberg C, Proebsting TA (2016) Repeatability in computer systems research. Commun ACM 59(3):62–69
Kovačević J (2007) How to encourage and publish reproducible research. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP) IEEE. vol 4, pp IV–1273
Vandewalle P, Kovacevic J, Vetterli M (2009) Reproducible research in signal processing. Signal Process Mag 26(3):37–47
Howe B (2012) Cde: A tool for creating portable experimental software packages. Comput Sci Eng 14(4):32–35
Janin Y, Vincent C, Duraffort R (2014) Care, the comprehensive archiver for reproducible execution. In: Proceedings of the SIGPLAN Workshop on Reproducible Research Methodologies and New Publication Models in Computer Engineering ACM, pp 1:1–1:7
Pham Q, Malik T, Foster IT (2013) Using provenance for repeatability. In: Proceedings of the Workshop on the USENIX Theory and Practice of Provenance, pp 2:1–2:4
Chirigati F, Rampin R, Shasha D, Freire J (2016) Reprozip: computational reproducibility with ease. In: Proceedings of the International Conference on Management of Data (SIGMOD) ACM, pp 2085–2088
Pedersen T (2008) Empiricism is not a matter of faith. Comput Linguist 34(3):465–470
Sonnenburg S, Braun ML, Ong CS, Bengio S, Bottou L, Holmes G, LeCun Y, Müller KR, Pereira F, Rasmussen CE et al (2007) The need for open source software in machine learning. J Mach Learn Res 8:2443–2466
Vitek J, Kalibera T (2011) Repeatability, reproducibility, and rigor in systems research. In: Proceedings of the International Conference on Embedded Software (EMSOFT) ACM, pp 33–38
Drummond C (2008) Finding a balance between anarchy and orthodoxy. In: Proceedings of the International Conference on Machine Learning: Workshop on Evaluation Methods for Machine Learning (ICML)
Blockeel H, Vanschoren J (2007) Experiment databases: towards an improved experimental methodology in machine learning. In: European Conference on Principles of Data Mining and Knowledge Discovery (ECML PKDD). Springer, Berlin Heidelberg, pp 6–17
Pandit H, Hamed RG, Lawless S, Lewis D (2016) The use of open data to improve the repeatability of adaptivity and personalisation experiment. In: Proceedings of the Conference on User Modelling, Adaptation and Personalization (UMAP Extended Proceedings)
Blanco R, Halpin H, Herzig DM, Mika P, Pound J, Thompson HS, Tran T (2013) Repeatable and reliable semantic search evaluation. Web Semant Sci Serv Agents World Wide Web 21:14–29
Godbole S, Bhattacharya I, Gupta A, Verma A (2010) Building re-usable dictionary repositories for real-world text mining. In: Proceedings of the International Conference on Information and Knowledge Management (CIKM). ACM, New York, pp 1189–1198
Napoles C, Tetreault J, Pappu A, Rosato E, Provenzale B (2017) Finding good conversations online: the yahoo news annotated comments corpus. In: Proceedings of the Linguistic Annotation Workshop, pp 13–23
Schabus D, Skowron M, Trapp M (2017) One million posts: A data set of german online discussions. In: Proceedings of the International Conference on Research and Development in Information Retrieval (SIGIR), pp 1241–1244
Wulczyn E, Thain N, Dixon L (2017) Ex machina: personal attacks seen at scale. In: International World Wide Web Conferences Steering Committee (ed) Proceedings of the International Conference on World Wide Web (WWW), pp 1391–1399
Davidson T, Warmsley D, Macy M, Weber I (2017) Automated hate speech detection and the problem of offensive language. In: Proceedings of the International Conference on Web and Social Media (ICWSM), pp 512–515
Charikar MS (2002) Similarity estimation techniques from rounding algorithms. In: Proceedings of the ACM Symposium on Theory of Computing ACM, pp 380–388
Manku GS, Jain A, Das Sarma A (2007) Detecting near-duplicates for web crawling. In: Proceedings of the International Conference on World Wide Web (WWW) ACM, pp 141–150
Halder R, Pal S, Cortesi A (2010) Watermarking techniques for relational databases: survey, classification and comparison. J Univers Comput Sci 16(21):3164–3190
Ambroselli C, Risch J, Krestel R, Loos A (2018) Prediction for the newsroom: Which articles will get the most comments? In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) ACL, pp 193–199
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Risch, J., Krestel, R. Measuring and Facilitating Data Repeatability in Web Science. Datenbank Spektrum 19, 117–126 (2019). https://doi.org/10.1007/s13222-019-00316-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13222-019-00316-9