
Abstract
The mathematical modeling of the coronavirus disease-19 (COVID-19) pandemic has been attempted by a large number of researchers from the very beginning of cases worldwide. The purpose of this research work is to find and classify the modelling of COVID-19 data by determining the optimal statistical modelling to evaluate the regular count of new COVID-19 fatalities, thus requiring discrete distributions. Some discrete models are checked and reviewed, such as Binomial, Poisson, Hypergeometric, discrete negative binomial, beta-binomial, Skellam, beta negative binomial, Burr, discrete Lindley, discrete alpha power inverse Lomax, discrete generalized exponential, discrete Marshall-Olkin Generalized exponential, discrete Gompertz-G-exponential, discrete Weibull, discrete inverse Weibull, exponentiated discrete Weibull, discrete Rayleigh, and new discrete Lindley. The probability mass function and the hazard rate function are addressed. Discrete models are discussed based on the maximum likelihood estimates for the parameters. A numerical analysis uses the regular count of new casualties in the countries of Angola,Ethiopia, French Guiana, El Salvador, Estonia, and Greece. The empirical findings are interpreted in-depth.
Similar content being viewed by others

1 Introduction
Corona-Virus “COVID-19” was first reported in early December 2019 in Wuhan, China, and within three months spread like a pandemic around the whole globe. The World Health Organization (WHO) described COVID-19 as a pandemic on March 11, 2020. Refer to Figs. 1 and 2. Despite the drastic, large-scale containment measures implemented in most countries, these numbers rapidly increased every day—posing an unprecedented threat to the global health and economy of interconnected human societies. Countries around the world have therefore increased their efforts to decrease the COVID-19 spread rate.

The situation for the daily new cases over the world by the WHO Region has been shown in Figure 1

The situation for the daily new deaths over the world by the WHO Region has been shown in Figure 2
To model daily cases and deaths in the world, there are some mathematical/statistical models in the literature which are used to describe the dynamics of the evolution of COVID-19. The comparison of the COVID-19 epidemic dynamics among different countries is of great concern. In this regard, the researchers are making their best efforts to provide medical solutions for drugs and vaccines in reducing the risk of virus spread. The study of this aspect of science requires discrete distributions. For any researcher, the first question comes to mind- Why do we need discrete distributions? We are aware that most of the current continuous distributions do not fit adequately for modeling the cases of COVID-19 in count data analysis.
In the current situation, it is of great interest to study more about COVID-19 and compare different countries as many as possible. Therefore, in this article, an effort has been made to compare the COVID-19 pandemic outbreak in several countries around the world.
Recently, many authors introduced different discrete distributions such as natural discrete Lindley distribution has been implemented by Al-Babtain et al. (2020a, ??) to model everyday cases and deaths in the world. Almetwally et al. (2020) introduced a discrete Marshall-Olkin generalized exponential distribution to discuss the recent Egyptian cases regularly. Elbatal et al. (2022) obtained discrete odd Perks-G class of distributions. Almetwally et al. (2022) introduced discrete Marshall-Olkin inverse Toppe-Leone distribution with application to COVID-19 data. Nagy et al. (2021) discussed discrete extended odd Weibull exponential with different applications. Gillariose et al. (2021) proposed discrete generalization of the exponential model. A new discrete distribution, called discrete generalized Lindley, was analyzed by El-Morshedy et al. (2020) to examine the counts of daily coronavirus cases in Hong Kong and new daily fatalities in Iran. Maleki et al. (2020) have used an autoregressive time series model based on normal distribution of the two-piece scale mixture to estimate the recovered and reported cases of COVID-19. The study carried out by Hasab et al. (2020) where they used the susceptible infected recovered (SIR) epidemic dynamics of the COVID-19 pandemic for modelling the novel Coronavirus epidemic in Egypt. Nesteruk (2020) and Batista (2020b) have predicted regular new COVID-19 cases in China by using the mathematical model, named SIR. The logistic growth regression model used by Batista (2020a) for estimating the final size of the coronavirus outbreak and its peak time.
This research work aims to model the daily new fatalities of COVID-19 using a review of statistical models to determine the best model fitting of COVID-19 data for different countries as Angola, Ethiopia, French Guiana, El Salvador, Estonia, and Greece and aware of the risks resulting from the spread of Corona-Virus in the world. To accomplish this goal: First, we study separate models such as Poisson, geometric, negative binomial, discrete Burr, discrete Lindley, discrete alpha power inverse Lomax, discrete generalized exponential, discrete Marshall-Olkin Generalized exponential, discrete Gompertz-G-exponential, discrete Weibull, discrete inverse Weibull, exponentiated discrete Weibull, discrete Rayleigh, and new discrete Lindley. Second, in some countries such as Angola, Ethiopia, French Guiana, El Salvador, Estonia, and Greece, we define the best discrete models that match different regular Coronavirus death datasets.
The remainder of the paper is structured as follows. Discrete models are analyzed in Section 2. In Section 3, review for discrete models has been done based on survival discretization method. We discuss the parameter estimation of the discrete models in Section 4. Section 5 presents the new regular death of COVID-19 in the case of Angola, El Salvador, Estonia, and Greece to validate the use of models in suitable lifetime count results. Lastly, in Section 6, conclusions are made.
2 Review for Classical Discrete Models
In this Section, survival discretization method and some discrete distributions have been reviewed, such as Binomial, Poisson, Hypergeometric, discrete Burr, discrete Lindley, discrete alpha power inverse Lomax,discrete generalized exponential, discrete Marshall-Olkin Generalized exponential, discrete Gompertz-G-exponential, discrete Weibull, discrete inverse Weibull, exponentiated discrete Weibull, discrete Rayleigh, new discrete Lindley, negative binomial, beta-binomial, Skellam, beta negative binomial and Conway–Maxwell–Poisson distribution. We don’t use Logarithmic, Borel, discrete compound Poisson, Boltzmann, Benford’s law, Yule–Simon, Zipf’s law, and Zeta distribution because the range of x doesn’t support 0.
2.1 Binomial Distribution
The binomial distribution (bionm) can be defined, using the binomial expansion
as the distribution of a random variable X for which
where p + q = 1, 0 < p < 1, and n is a positive integer. Ifn = 1, the distribution is called the distribution of Bernoulli.
2.2 Poisson Distribution
If a random variable X has a Poisson (Pois) distribution with parameter 𝜃,then its PMF is given by
where 𝜃 > 0. For more information, see Johnson et al. (2005) chapter 4.
2.3 Hypergeometric Distribution
In a sample of n balls drawn without substitution from a population of (N) balls, (N𝜃) of which are white and (N − N𝜃) are black. The PMF of hypergeometric distribution is given by
For more information, see Johnson et al. (2005) chapter 6.
2.4 Waring Distribution
The distribution of Waring is a generalization of the distribution of Yule, see Johnson et al. (2005). Taking Pr[X = x] , Waring expansion proportional to the (x + 1) term in the sequence.
where α,𝜃 > 0. If α = 1 then, Yule distribution is the special case of Waring distribution.
2.5 Yule–Simon Distribution
The Yule–Simon distribution is a discrete probability distribution named after Udny Yule and Herbert A. Simon in probability and statistics. Originally, Simon named it the distribution of Yule by Simon (1955). The Yule-Simon (𝜃) PMF is
where 𝜃 > 0. The CDF of Yule-Simon distribution is
The hr function of the Yule-Simon distribution is given by
2.6 Discrete Rectangular Distribution
In its most general form, the discrete rectangular distribution (sometimes called the discrete uniform distribution) is defined by
2.7 Distribution of Leads
The distribution of leads in coin tossing (Johnson et al. 2005) has the PMF
2.8 Beta-binomial Distribution
The beta-binomial (Bbinom) distribution in probability theory and statistics is a family of discrete probability distributions on finite support of non-negative integers occurring when the probability of success is either unknown or random in each of a fixed or known number of Bernoulli trials, is discussed by Griffiths (1973). The PMF of Bbinom is given by
the CDF of Bbinom is given by
where FGH (a,b,x) is the generalized hypergeometric function.
2.9 Negative Binomial Distribution
The negative binomial(Nbionm) distribution in probability theory and statistics is a discrete probability distribution that models the number of successes before a given non-random number of failures (denoted by r) occur in a series of independent and identically distributed Bernoulli trials. The PMF of Nbinom is given by
where r is a number of failures until the experiment is stopped (integer, but the definition can also be extended to real numbers) and p is success probability in each experiment. For more information, see Johnson et al. (2005) chapter 5.
2.10 Geometric Distribution
The geometric distribution in probability theory and statistics is the probability distribution of the number X − 1 of failures before the first success, supported by the set{0,1,2,... }. The PMF is given as
where0 < p < 1.
2.11 Beta Negative Binomial Distribution
A beta negative binomial (BNbinom) distribution in probability theory is the probability distribution of a discrete random variable X equal to the number of failures needed to achieve achievements in a series of independent Bernoulli trials in which the probability p of success in each trial, though constant in any given experiment, is itself a random variable following a beta distribution. Wang (2011) discussed this distribution as a compound probability distribution. The PMF of BNbinom is given by
where x = 0, 1, 2,… and r,α,β > 0.
2.12 Logarithmic Distribution
A random variable X is said to have a logarithmic distribution with parameter 𝜃 if its PMF is in the form
For more information of logarithmic distribution, see Johnson et al. (2005) chapter 7.
2.13 Skellam Distribution
Let μ1,μ2 > 0, Skellam (1946) introduced the Skellam distribution (distribution of the difference between two independent Poisson random variables) and is denoted by Skellam (μ1,μ2) with PMF is given by
wherex = …,− 2,− 1, 0, 1, 2, … Ik (2μ1 μ2) is the modified Bessel function of the first kind.
2.14 Conway–Maxwell–Poisson Distribution
Shmueli et al. (2005) discussed the Conway–Maxwell–Poisson (CMP) distribution with PMF as
where Z (λ,𝜃) = ∑ j= 0∞ λj (j!)𝜃 is normalization constant.
3 Review for Discrete Models Based on Survival Discretization Method
In the statistics literature, sundry methods are available to obtain a discrete distribution from a continuous one. The most commonly used technique to generate discrete distribution is called a survival discretization method, it requires the existence of cumulative distribution function (CDF), survival function should be continuous and non-negative and times are divided into unit intervals. The PMF of discrete distribution is defined in Roy (2003) as
wherex = 0,1,2,…,S (x) = P (X ≥ x) = F (x; Θ), F (x; Θ) is a CDF of continuous distribution, and Θ is a vector of parameters. The random variable X is said to have the discrete distribution if its CDF is given by
The hazard rate is given by hr (x) = P (X=x) S(x). The reversed failure rate of discrete distribution is given as
3.1 Discrete Burr Distribution
The PMF of the discrete Burr (DB) distribution has been defined by Krishna and Pundir (2009) is given by
where x = 0,1,2,…, α > 0,0 < 𝜃 < 1, the CDF of the DBu distribution is
The hazard rate (hr) of the discrete Burr distribution is
3.2 Discrete Lindley Distribution
The PMF of the discrete Lindley (DLi) distribution has been defined by Gómez-Déniz and Calderín-Ojeda (2011) is given as follows
where x = 0,1,2,…, 0 < 𝜃 < 1.
The CDF of the DLi distribution is
The hazard rate of the DLi distribution is
3.3 Discrete Alpha Power Inverse Lomax
The discrete alpha power inverse Lomax (DAPIL) distribution is introduced by Almetwally and Ibrahim (2020). The PMF and the CDF of the DAPIL distribution are respectively given by
The hr function of the DAPIL distribution is given by
3.4 Discrete Generalized Exponential Distribution
The PMF of the discrete generalized exponential (DGE) distribution has been defined by Nekoukhou et al. (2013) is given as follows
where x = 0,1,2,…,α > 0, 0 < 𝜃 < 1, when 𝜃 = e−λ;λ > 0, the CDF of the DGEx distribution is
The hazard rate of the DGEx distribution is
3.5 The DMOGEx Distribution
The discrete Marshall-Olkin Generalized exponential (DMOGEx) distribution is introduced by Almetwally et al. (2020). The PMF and the CDF of the DMOGEx distribution are respectively given by
and
where 0 < ρ < 1, λ,𝜃 > 0.
The hr function of the DMOGEx distribution is given by
3.6 Discrete Gompertz-G Exponential
The discrete Gompertz-G- exponential (DGzEx) distribution was introduced by Eliwa et al. (2020). The PMF and the CDF of the DGzEx distribution are respectively given by
and
The hr function of the DGzEx distribution is given by
3.7 Discrete Weibull
A discrete Weibull (DW) distribution was introduced by ? Nakagawa-and-Osaki:1975 (), and is defined by the cumulative distribution function (CDF)as:
The DW distribution has PMF:
and the hazard rate of DW is
3.8 Discrete Inverse Weibull
A discrete inverse Weibull (DIW) distribution was introduced by Jazi et al. (2010), and is defined by the CDF:
The DIW distribution has PMF:
and the hazard rate of DIW is
3.9 Exponentiated Discrete Weibull
The exponentiated discrete Weibull (EDW) distribution was introduced by Nekoukhou and Bidram (2015), and is defined by the CDF:
The DIW distribution has PMF:
and the hazard rate of DIW is
The discrete Rayleigh (DR) distribution was introduced by Roy (2004), and can be defined when α = 2 and β = 1as follows:
The DR distribution has PMF:
and the hazard rate of DR is
3.10 New Discrete Lindley
The new discrete Lindley (NDL) distribution was introduced by Al-Babtain et al. (2020a, ??), and is defined by the CDF:
The NDL distribution has PMF:
and the hazard rate of NDL is
4 Parameter Estimation of Discrete Model
In this section, we estimate the parameters of the models using a maximum likelihood method. It is noted that the maximum likelihood method is also used to estimate unknown parameters of a statistical model because maximum likelihood estimates (MLEs) have several desirable properties; For example, they are asymptotically unbiased, symmetrical, consistent, asymptomatically normally distributed, etc. Let x1, x2,…, xn be a random sample of size n from the discrete distribution, and then the log-likelihood function is given by
where Θ = (Θ1,…,Θk)T, k is a length of Θ. The MLEs can be obtained by partially first derivatives of the log-likelihood function and equal to zero
provide the MLEs of Θ, say Θ̂ = (Θ̂1,…,Θ̂k)T, then using a computational process such as the k variable Newton-Raphson Algorithm are given by the solutions of the equations.
For interval estimation and hypothesis tests on the model parameters, we require the information matrix. The k × k observed information matrix is
One can use the normal distribution of Θ̂ to construct approximate confidence interval regions for some parameters. Indeed, an asymptotic 100(1 − ξ) confidence interval for each parameterΘj;j = 1,…,k, is given by
where ℶ ̂jj denotes the (i,i) diagonal element of In− 1 (Θ̂) and zξ2 is the (1 − ξ 2) thquantile of the standard normal distribution.
5 Applications of Real Data
In this section, we illustrate the empirical importance of the discrete distributions, such as DB, DLi, Binom, Pois, DR, DGE, Geometric, DW, DIW, DE, NDL, DGzEx, DMOGE, DAPLo, and EDW distributions using four applications to real data sets. The fitted models are compared using some criteria; namely, Akaike information criterion (AIC), corrected AIC (CAIC), Hannan-Quinn information criterion (HQIC), Chi-square (X2) with a degree of freedom and its p-value.
and
5.1 African Continent
5.1.1 Angola
This data represents the daily new deaths of 51 days from 10 October to 29 November 2020 belong to Angola country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 1, 2 and 3.
From Tables 1, 2 and 3, it is evident that all distributions are fitted and work quite well for analyzing these data except for the DB distribution. However, we always search for the best model to get the best evaluation of the data, and therefore, using AIC, BIC, CAIC, HQIC, χ2 and p-values, we can say that the DMKEx model provides the best fit among all the tested models because it has the largest p-value and the smallest values of AIC, CAIC, BIC, HQIC and χ2 statistics. Figure 1 supports the results of Tables 1, 2 and 3.

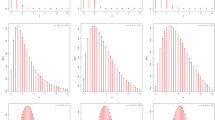
The fitted PMFs for Dataset of Angola
5.1.2 Ethiopia
This data represents the daily new deaths of 68 days from 1 April to 7 June 2020 belong to Ethiopia country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 4, 5, and 6.
From Tables 4, 5, and 6, it is evident that all distributions are fitted and works quite well for analyzing these data except for the DR, binomial, Poisson, Skellam, and BNbinom distributions. However, we always search for the best model to get the best evaluation by using AIC, BIC, CAIC, HQIC, χ2, and p-values. Figure 2 supports the results of Tables 4, 5 and 6.

The fitted PMFs for Dataset of Ethiopia
5.2 America Continent
5.3 El Salvador
This data represents the daily new deaths of 81 days from 1 April to 20 June 2020 belong to El Salvador country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 7, 8 and 9.
From Tables 7, 8 and 9, it is evident that all distributions are Fitted and work immensely well for analyzing these data except for the BNbionm, and DR distribution. However, we always search for the best model to get the best evaluation byusing AIC, BIC, CAIC, HQIC, χ2, and p-values. Figure 3 supports the results of Tables 7, 8 and 9.
5.3.1 French Guiana
This data represents the daily new deaths of 153 days from 1 June to 31 October 2020 belong to French Guiana country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 10, 11 and 12.
From Tables 10, 11 and 12, it is evident that all distributions are fitted and work immensely well for analyzing these data except for the DR and skellam distributions. However, we always search for the best model to get the best evaluation of the data, and therefore, using AIC, BIC, CAIC, HQIC, X2, and p-values, we can say that the DL in Table 7, DGE in Table 8, and DMOGE in Table 9 model provides the best fit among all the tested models because it has the largest p-value and the smallest values of AIC, CAIC, BIC, HQIC and χ2 statistics. Figure 4 supports the results of Tables 10, 11 and 12.
5.4 Europe Continent
5.4.1 Estonia
This data represents the daily new deaths of 81 days from 1 April to 20 May 2020 belong to Estonia country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 13, 14 and 15.
From Tables 13, 14, and 15, it is evident that all distributions are Fitted and work quite well for analyzing these data except for the Binom, Pois, and DR distributions. However, we always search for the best model to get the best evaluation of the data, and therefore, using AIC, BIC, CAIC, HQIC, X2, and p-values, we can say that the DL model provides the best fit among all the tested models because it has the smallest values of AIC, CAIC, BIC, HQIC, and χ2 statistics, as well as having the highest p-value. Figure 5 supports the results of Tables 13, 14 and 15.

The fitted PMFs for Dataset of El Salvador
5.4.2 Greece
This data represents the daily new deaths of 111 days from 12 March to 30 June 2020 belong to Greece country (see World Health Organization). The MLEs and the goodness of fit statistics are reported in Tables 16, 17 and 18.
From Tables 16, 17 and 18, it is evident that all distributions are Fitted and work quite well for analyzing these data except for the DB, Binom, Pois, DIW, and DR distribution. However, we always search for the best model to get the best evaluation of the data, and therefore, concerning the AIC, BIC, CAIC, HQIC, χ2and p-values, we can say that the DE model provides the best fit among all the tested models because it has the smallest values of AIC, CAIC, BIC, HQIC and χ2statistics, as well as having the highest p-value. Figures 6, 7 and 8 support the results of Tables 16, 17 and 18.

The fitted PMFs for Dataset of Guiana

The fitted PMFs for Dataset of Estonia

The fitted PMFs for Dataset of Greece
6 Concluding Remarks
In this article, we use 8 discrete distributions with one parameter, 7 discrete distributions with two parameters, and 4 discrete distributions with three parameters to fit and determine the best model of daily Coronavirus deaths in some countries, such as Angola,Ethiopia, French Guiana, El Salvador, Estonia, and Greece. In the case of discrete distributions with one parameter, we discussed DL, binomial, Poisson, DR, Geometric, DE, Nbinom, and NDL distributions. In the case of discrete distributions with two parameters, we discussed DB, DGE, DW, DIW, Bbinom, BNbinom, and skellam distributions. In the case of discrete distributions with three parameters, we discussed DGzEx, DMOGE, DAPL, and EDW distributions. A review of some important discrete distributions has been provided as DB, DL, DMOGE, DGE, DAPL, DR, DE, Geometric, Binomial, NDL, DGzEx, and EDW distribution. The maximum likelihood estimation method is discussed to estimate the parameters of the discrete distributions. We prove empirically that the discrete models fit different datasets of daily Coronavirus deaths in some countries as Angola, Ethiopia, French Guiana, El Salvador, Estonia, and Greece. DW and DB reveal its superiority over other competitive models for the analysis of daily deaths of the COVID-19 in the case of Angola, Ethiopia, French Guiana, El Salvador, Estonia, and Greece.
References
Al-Babtain, A. A., Ahmed, A. H. N. and Afify, A. Z. (2020a). A new discrete analog of the continuous lindley distribution, with reliability applications. Entropy22, 603.
Almetwally, E. M. and Ibrahim, G. M. (2020). Discrete alpha power inverse Lomax distribution with application of COVID-19 data. Int. J. Appl. Math. 9, 11–22.
Almetwally, E. M., Almongy, H. M. and Saleh, H. A. (2020). Managing risk of spreading “COVID-19” in Egypt: modelling using a discrete Marshall-Olkin generalized exponential distribution. Int. J. Probab. Stat. 9, 33–41.
Almetwally, E. M., Abdo, D. A., Hafez, E. H., Jawa, T. M., Sayed-Ahmed, N. and Almongy, H. M. (2022). The new discrete distribution with application to COVID-19 data. Results Phys. 32, 104987.
Batista, M. (2020a). Estimation of the final size of the coronavirus epidemic by the logistic model. https://doi.org/10.1101/2020.02.16.20023606.
Batista, M. (2020b). Estimation of the final size of the coronavirus epidemic by the SIR model. Online paper, ResearchGate.
Elbatal, I., Alotaibi, N., Almetwally, E. M., Alyami, S. A. and Elgarhy, M. (2022). On odd Perks-G class of distributions: properties, regression model, discretization, Bayesian and Non-Bayesian estimation, and applications. Symmetry 14, 883.
Eliwa, M. S., Alhussain, Z. A. and El-Morshedy, M. (2020). Discrete Gompertz-G family of distributions for over-and under-dispersed data with properties, estimation, and applications. Mathematics 8, 358.
El-Morshedy, M., Altun, E and Eliwa, MS (2020), A new statistical approach to model the counts of novel coronavirus cases. Res. Square. https://doi.org/10.21203/rs.3.rs-31163/v1.
Gillariose, J., Balogun, O. S., Almetwally, E. M., Sherwani, R. A. K., Jamal, F. and Joseph, J. (2021). On the discrete Weibull Marshall–Olkin family of distributions: properties, characterizations, and applications. Axioms 10, 287.
Gómez-Déniz, E. and Calderín-Ojeda, E. (2011). The discrete Lindley distribution: properties and applications. J. Stat. Comput. Simul. 81, 1405–1416.
Griffiths, D. A. (1973). Maximum likelihood estimation for the beta-binomial distribution and an application to the household distribution of the total number of cases of a disease. Biometrics 637–648.
Hasab, A. A., El-Ghitany, E. M. and Ahmed, N. N. (2020). Situational analysis and epidemic modeling of COVID-19 in Egypt. J. High Inst. Public Health50, 46–51.
Jazi, M. A., Lai, C. D. and Alamatsaz, M. H. (2010). A discrete inverse Weibull distribution and estimation of its parameters. Stat. Methodol. 7, 121–132.
Johnson, N. L., Kemp, A. W. and Kotz, S. (2005). Univariate discrete distributions (Vol. 444). Wiley.
Krishna, H. and Pundir, P. S. (2009). Discrete Burr and discrete Pareto distributions. Stat. Methodol. 6, 177–188.
Maleki, M., Mahmoudi, M. R., Wraith, D. and Pho, K. H. (2020). Time series modelling to forecast the confirmed and recovered cases of COVID-19. Travel Med. Infect. Dis. 101742.
Nagy, M., Almetwally, E. M., Gemeay, A. M., Mohammed, H. S., Jawa, T. M., Sayed-Ahmed, N. and Muse, A. H. (2021). The new novel discrete distribution with application on covid-19 mortality numbers in Kingdom of Saudi Arabia and Latvia. Complexity.
Nakagawa, T. and Osaki, S. (1975). The discrete Weibull distribution. IEEE Trans. Reliab. 24, 300–301.
Nekoukhou, V. and Bidram, H. (2015). The exponentiated discrete Weibull distribution. Sort 39, 127–146.
Nekoukhou, V., Alamatsaz, M. H. and Bidram, H. (2013). Discrete generalized exponential distribution of a second type. Statistics 47, 876–887.
Nesteruk, I. (2020). Statistics-based predictions of coronavirus epidemic spreading in mainland China. Innov. Biosyst. Bioeng. 4, 13–18.
Roy, D. (2003). The discrete normal distribution. Commun. Stat.-Theory Methods 32, 1871–1883.
Roy, D. (2004). Discrete rayleigh distribution. IEEE Trans. Reliab.53, 255–260.
Shmueli, G., Minka, T. P., Kadane, J. B., Borle, S. and Boatwright, P. (2005). A useful distribution for fitting discrete data: revival of the Conway–Maxwell–Poisson distribution. J. R. Stat. Soc.: Ser. C (Appl. Stat.) 54, 127–142.
Simon, H. A. (1955). On a class of skew distribution functions. Biometrika 42, 425–440.
Skellam, J. G. (1946). The frequency distribution of the difference between two Poisson variates belonging to different populations. J. R. Stat. Soc.: Ser. A 109, 296.
Wang, Z. (2011). One mixed negative binomial distribution with the application. J. Stat. Plan. Inference 141, 1153–1160.
Acknowledgments
The authors would like to thank the Editor and reviewer for their constructive comments and suggestions
Author information
Authors and Affiliations
Ethics declarations
Conflict of Interest
The authors declare no conflicts of interest
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Almetwally, E.M., Dey, S. & Nadarajah, S. An Overview of Discrete Distributions in Modelling COVID-19 Data Sets. Sankhya A 85, 1403–1430 (2023). https://doi.org/10.1007/s13171-022-00291-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13171-022-00291-6