
Abstract
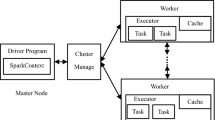
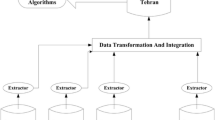
Nowadays, radar technique is widely used in many applications, such as electronic warfare, weather prediction, navigation, and self-driving car. Large amounts of radar data has been generated by the wide use of radar technique. Analyzing radar data has a quite important role in daily life, as well as in military. Finding the frequent sequences in radar data is significant for radar data analysis. However, traditional analysis systems using standalones cannot process big data due to the four features of big data, namely, volume, velocity, variety and value. Many distributed frameworks are promising for processing large scale data sets, such as Hadoop and Spark. Therefore, to deal with the problem of finding frequent sequences from large amounts of radar data, we built a system based on Hadoop and Spark. With the combination of Hadoop and Spark, we can store big data, as well as analyze big radar data more easily. In the proposed system, Hadoop distributed file system offers stable data storage, and Spark offers efficient in-memory calculation. In this paper, a three-node Hadoop–Spark cluster was built to perform the distributed data mining algorithm. Additionally, to make the analysis of radar data accurate, we proposed ideas of preprocessing radar data and post processing mining results. Experimental results show that the system we proposed can analyze the large amounts of radar data efficiently and accurately.

















Similar content being viewed by others

Change history
01 September 2020
The below affiliation for author Chi Yang was missed to be included in the original article.
References
Achar A, Ibrahim A, Sastry PS (2013) Pattern-growth based frequent serial episode discovery. Data Knowl Eng 87(9):91–108
Agrawal R, Srikant R (1995) Mining sequential patterns. Proc Eleventh Inter Conf Data Eng 31(6):3–14
Daszykowski M, Walczak B, Massart DL (2002) Looking for natural patterns in analytical data. 2. Tracing local density with optics. J Chem Inf Comput Sci 42(3):500
Dean J, Ghemawat S (2010) Mapreduce: a flexible data processing tool. Commun ACM 53(1):72–77
Ester M (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. In: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), pp 226–231
Fournier-Viger P, Wu CW, Gomariz A, Tseng VS (2014) VMSP: efficient vertical mining of maximal sequential patterns. In: Canadian conference on artificial intelligence, pp 109–120
Garcagil D, Ramrezgallego S, Garca S, Herrera F (2017) A comparison on scalability for batch big data processing on apache spark and apache flink. Big Data Anal 2(1):1
Ghazi MR, Gangodkar D (2015) Hadoop, mapreduce and HDFS: a developers perspective. Proc Comput Sci 48:45–50
Merrill IS (2001) Introduction to radar systems. McGraw-Hill, Boston, pp 607–609
Ji X, Bailey J, Dong G (2007) Mining minimal distinguishing subsequence patterns with gap constraints. Knowl Inf Syst 11(3):259–286
Jian L, Yang X, Zhou Z, Zhou K, Liu K (2018) Multi-scale image fusion through rolling guidance filter. Future Gener Comput Syst 83:1399–1420
Jiang QB, Hong guang MA, Xi A (2006) A novel nonmatched detection algorithm of radar pulse signal. Mod Radar 28(11):36–40
Koliopoulos AK, Yiapanis P, Tekiner F, Nenadic G, Keane J (2015) A parallel distributed weka framework for big data mining using spark. 9–16
Lin X, Wang P, Wu B (2014) Log analysis in cloud computing environment with hadoop and spark. In: IEEE international conference on broadband network and multimedia technology, pp 273–276
Malewicz G, Austern MH, Bik AJC, Dehnert JC, Horn I, Leiser N, Czajkowski G (2010) Pregel: a system for large-scale graph processing. In: ACM SIGMOD international conference on management of data, pp 135–146
Meng X, Bradley J, Yavuz B, Sparks E, Venkataraman S, Liu D, Freeman J, Tsai D, Amde M, Owen S (2015) Mllib: machine learning in apache spark. J Mach Learn Res 17(1):1235–1241
Pei J, Han J, Mortazaviasl B, Pinto H, Chen Q, Dayal U, Hsu MC (2001) Prefixspan: mining sequential patterns efficiently by prefix-projected pattern growth. In: International conference on data engineering, p 215
Rathore MMU, Ahmad A, Paul A (2017) Hadoop-based intelligent care system (hics): analytical approach for big data in iot. ACM Trans Internet Technol 2016(1):1–24
Shi J, Qiu Y, Minhas UF, Jiao L, Wang C, Reinwald B (2015) Clash of the titans: mapreduce vs. spark for large scale data analytics. Proc Vldb Endow 8(13):2110–2121
Shvachko KV (2010) HDFS scalability: the limits to growth. USENIX Mag 35:6–16
Srikant R, Agrawal R (1996) Mining sequential patterns: generalizations and performance improvements. In: International conference on extending database technology, Springer, pp 1–17
White T, Cutting D (2012) Hadoop : the definitive guide, vol 215(11). Oreilly Media Inc, Gravenstein Highway North, pp 1–4
Yang X, Wu W, Liu K, Kim PW, Sangaiah AK, Jeon G (2018) Multi-semi-couple super-resolution method for edge computing. IEEE Access PP(99):1–1
Zaharia M, Chowdhury M, Franklin MJ, Shenker S, Stoica I (2010) Spark: cluster computing with working sets. In: Usenix conference on hot topics in cloud computing, pp 10–10
Acknowledgements
The research in our paper is sponsored by National Natural Science Foundation of China (Nos. 61701327, 61711540303, 61771378), and Science Foundation of Sichuan Science and Technology Department (No. 2018GZ0178).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, C., Yang, X. & Yang, F. A system based on Hadoop for radar data analysis. J Ambient Intell Human Comput 10, 3899–3913 (2019). https://doi.org/10.1007/s12652-018-0980-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-018-0980-3