
Abstract
Recent achievements in the field of adaptive dynamic programming (ADP), as well as the data resources and computational capabilities in modern control systems, have led to a growing interest in learning and data-driven control technologies. This paper proposes a twin deterministic policy gradient adaptive dynamic programming (TDPGADP) algorithm to solve the optimal control problem for a discrete-time affine nonlinear system in a model-free scenario. To solve the overestimation problem resulted from function approximation errors, the minimum value between the double Q network is taken to update the control policy. The convergence of the proposed algorithm in which the value function is served as the Lyapunov function is verified. By designing a twin actor-critic network structure, combining the target network and a specially designed adaptive experience replay mechanism, the algorithm is convenient to implement and the sample efficiency of the learning process can be improved. Two simulation examples are conducted to verify the efficacy of the proposed method.
Similar content being viewed by others

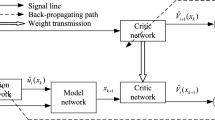
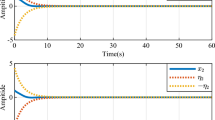
References
K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, “Deep reinforcement learning: A brief survey,” IEEE Signal Processing Magazine, vol. 34, no. 6, pp. 26–38, 2017.
D. Liu, S. Xue, B. Zhao, B. Luo, and Q. Wei, “Adaptive dynamic programming for control: A survey and recent advances,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 1, pp. 142–160, 2021.
J. Xu, H. Wang, J. Rao, and J. Wang, “Zone scheduling optimization of pumps in water distribution networks with deep reinforcement learning and knowledge-assisted learning,” Soft Computing, vol. 25, pp. 14757–14767, 2021.
M. C. Weinstein and R. J. Zeckhauser, “The optimal consumption of depletable natural resources,” The Quarterly Journal of Economics, vol. 89, no. 3, pp. 371–392, 1975.
P. J. Werbos, “Building and understanding adaptive systems: A statistical/numerical approach to factory automation and brain research,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 17, no. 1, pp. 7–20, 1987.
S. G. Papachristos, Adaptive Dynamic Programming in Inventory Control, The University of Manchester, United Kingdom, 1977.
R. Cui, C. Yang, Y. Li, and S. Sharma, “Adaptive neural network control of AUVs with control input nonlinearities using reinforcement learning,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 47, no. 6, pp. 1019–1029, 2017.
J. Lu, Q. Wei, and F.-Y. Wang, “Parallel control for optimal tracking via adaptive dynamic programming,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 6, pp. 1662–1674, 2020.
Q. Wei, R. Song, Z. Liao, B. Li, and F. L. Lewis, “Discrete-time impulsive adaptive dynamic programming,” IEEE Transactions on Cybernetics, vol. 50, no. 10, pp. 4293–4306, 2019.
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, MIT press, 2018.
W. Guo, J. Si, F. Liu, and S. Mei, “Policy approximation in policy iteration approximate dynamic programming for discrete-time nonlinear systems,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 7, pp. 2794–2807, 2017.
Q. Wei, D. Liu, and H. Lin, “Value iteration adaptive dynamic programming for optimal control of discrete-time nonlinear systems,” IEEE Transactions on Cybernetics, vol. 46, no. 3, pp. 840–853, 2015.
B. Luo, Y. Yang, H.-N. Wu, and T. Huang, “Balancing value iteration and policy iteration for discrete-time control,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 50, no. 11, pp. 3948–3958, 2019.
D. Liu and Q. Wei, “Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems,” IEEE Transactions on Neural Networks and Learning Systems, vol. 25, no. 3, pp. 621–634, 2013.
Q. Wei and D. Liu, “Neural-network-based adaptive optimal tracking control scheme for discrete-time nonlinear systems with approximation errors,” Neurocomputing, vol. 149, pp. 106–115, 2015.
H. Li and D. Liu, “Optimal control for discrete-time affine non-linear systems using general value iteration,” IET Control Theory & Applications, vol. 6, no. 18, pp. 2725–2736, 2012.
B. Zhao, D. Wang, G. Shi, D. Liu, and Y. Li, “Decentralized control for large-scale nonlinear systems with unknown mismatched interconnections via policy iteration,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 48, no. 10, pp. 1725–1735, 2017.
B. Luo, D. Liu, H.-N. Wu, D. Wang, and F. L. Lewis, “Policy gradient adaptive dynamic programming for data-based optimal control,” IEEE Transactions on Cybernetics, vol. 47, no. 10, pp. 3341–3354, 2016.
B. Luo, Y. Yang, and D. Liu, “Adaptive q-learning for data-based optimal output regulation with experience replay,” IEEE Transactions on Cybernetics, vol. 48, no. 12, pp. 3337–3348, 2018.
Y. Zhang, B. Zhao, and D. Liu, “Deterministic policy gradient adaptive dynamic programming for model-free optimal control,” Neurocomputing, vol. 387, pp. 40–50, 2020.
S. Thrun and A. Schwartz, “Issues in using function approximation for reinforcement learning,” Proc. of the 4th Connectionist Models Summer School, pp. 255–263, Hillsdale, NJ, 1993.
H. van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” Proc. of the 30th AAAI Conference on Artificial Intelligence, pp. 2094–2100, 2016.
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” Proc. of International Conference on Machine Learning, PMLR, pp. 1587–1596, 2018.
R. Bellman, “On the theory of dynamic programming,” Proceedings of the National Academy of Sciences of the United States of America, vol. 38, no. 8, p. 716, 1952.
T. Degris, M. White, and R. Sutton, “Off-policy actor-critic,” Proc. of International Conference on Machine Learning, 2012.
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
P. Wawrzyński, “Real-time reinforcement learning by sequential actor-critics and experience replay,” Neural Networks, vol. 22, no. 10, pp. 1484–1497, 2009.
R. Liu and J. Zou, “The effects of memory replay in reinforcement learning,” Proc. of 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), IEEE, pp. 478–485, 2018.
Z. Wang, V. Bapst, N. Heess, V. Mnih, R. Munos, K. Kavukcuoglu, and N. de Freitas, “Sample efficient actor-critic with experience replay,” arXiv preprint arXiv:1611.01224, 2016.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by National Natural Science Foundation of China (61633019).
Jiahui Xu received his B.S. degree in the School of Electrical and Automation Engineering, Jilin University, Changchun, China, in 2019. He is currently pursuing a Ph.D. degree with the Department of Automation, Shanghai Jiao Tong University, Shanghai, China (2019-). His current research interests include reinforcement learning and optimal control.
Jingcheng Wang received his B.S. and M.S. degrees from Northwestern Polytechnic University, Xi’an, China, in 1992 and 1995, respectively, and a Ph.D. degree from Zhejiang University, Hangzhou, China, in 1998. He is a Former Research Fellow with Alexander von Humboldt Foundation, Rostock University, Rostock, Germany, and he is currently a Professor with Shanghai Jiao Tong University, Shanghai, China. His current research interests include robust control, intelligent control, and real-time control and simulation.
Jun Rao received his B.S. degree in electrical engineering and automation from Northwest A&F University, Yanglin, China, in 2020. He is currently pursuing a Ph.D. degree in the School of Automation from Shanghai Jiao Tong University, Shanghai, China. His current research interests include neural networks and reinforcement learning.
Yanjiu Zhong received his M.S. degree in the School of Mechanical Engineering, Hefei University of Technology, Hefei, China, in 2019. He is currently pursuing a Ph.D. degree in the School of Automation from Shanghai Jiao Tong University, Shanghai, China. His major research areas are non-convex optimization and reinforcement learning.
Shangwei Zhao received his B.S. degree in automation from Northeastern University, Shenyang, China, in 2018. He is currently pursuing a Ph.D. degree with the Department of Automation, Shanghai Jiao Tong University, Shanghai, China (2018-). His current research interests include adaptive dynamic programming, switched systems, and nonlinear system control.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Xu, J., Wang, J., Rao, J. et al. Twin Deterministic Policy Gradient Adaptive Dynamic Programming for Optimal Control of Affine Nonlinear Discrete-time Systems. Int. J. Control Autom. Syst. 20, 3098–3109 (2022). https://doi.org/10.1007/s12555-021-0473-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12555-021-0473-6