
Abstract
Refinery complexity quantifies the sophistication and capital intensity of a refinery and has found widespread application in facility classification, cost estimation, sales price models, and other uses. Despite the ubiquity and widespread use of refining complexity, however, surprisingly little material has been written on its applications. The purpose of this review is to describe the primary applications of refinery complexity and some recent extensions. A secondary purpose of this review is to provide a framework that unifies complexity applications and suggests avenues for future research. Examples illustrate the applications considered.
Similar content being viewed by others


1 Introduction
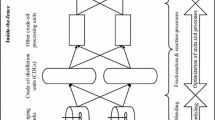
A refinery is an industrial plant where crude oil and other feedstocks are processed into petroleum products. The main principle of refining is to separate and improve the hydrocarbon compounds that constitute crude oil to produce saleable products which satisfy regulatory requirements. A refinery is comprised of three main sections—separation, conversion, and finishing—and each section contains one or more process units that apply various combinations of temperature, pressure, and catalyst to perform their function.
All modern refineries have distillation units that perform separation, but not all refineries perform conversion and finishing operations. There are a dozen or so main process operations in modern refining (Table 1), and for each process, several technologies have been developed over the past 150 years (Table 2). Different technologies involve different trade-offs between operating and capital cost, reliability and maintenance requirements (Schobert 2002; Parkash 2003; Raseev 2003; Meyers 2004; Gary et al. 2007; Riazi et al. 2013).
1.1 Separate, convert, finish
Crude oil consists of hundreds of different types of hydrocarbon molecules. Before processing, all refiners physically separate crude oil into molecular weight ranges by boiling point using a distillation tower (Fig. 1). The longer the carbon chain, the higher the temperature the hydrocarbon compounds will boil. “Cuts” of similar boiling point compounds are processed to allow the conversion steps to operate efficiently. Processes downstream of distillation take these cuts, and using various chemical and physical operations, improve and change the physical properties of molecules which are subsequently blended for fuels and other products (Speight 1998).

Distillation separates crude oil into boiling point cuts for further processing and sales
The conversion units in a modern refinery include thermal cracking, catalytic cracking, hydrocracking and coking. Thermal cracking was the first technology used to increase gasoline production in 1913, but has been largely replaced by more efficient processes. Conversion units are expensive to build and operate and represent a major investment decision, but once installed significantly extend refinery flexibility and capability.
Products from the conversion steps frequently require treatment to make them ready for sale. Treatment primarily involves improving product specification and reducing sulfur levels to satisfy regulatory requirements. Hydrotreating is the most common finishing process in refineries and use hydrogen and catalyst to remove sulfur and other impurities from feedstock and refined products. Most treatment and conversion processes employ catalyst to increase the speed of chemical reactions and enhance conversion rates.
1.2 Production, imports, and exports
The products of refining can be classified by form, as gases (e.g., methane, ethane, propane), liquids (e.g., gasoline, kerosene, diesel), and solids (e.g., coke, asphalt), or by usage, as transportation fuels (e.g., gasoline, jet fuel, fuel oil), non-fuel products (e.g., lubricants, solvents, waxes), and petrochemical feedstock (e.g., ethylene, propylene, benzene). Liquid fuel products are by far the largest category of production and in the US, for example, contribute over 90% of total products (Fig. 2). In 2014, US refiners processed 5.8 billion barrels of crude oil and feedstocks, and almost half of every barrel output was motor gasoline, followed by distillate fuel oil (30%) and jet fuels (10%). In Europe and Asia, a larger proportion of diesel and fuel oils are produced with smaller quantities of gasoline.

Source: EIA (2015d)
US petroleum refining product distribution in 2014.
The US is importing less oil as the country’s crude production increases (Fig. 3), while exports of refined oil products have nearly quadrupled over the past decade (Fig. 4). In May 2015, US production of crude oil was 9.5 million barrels per day (MMbpd) and 2.8 MMbpd of refined petroleum products was exported (EIA 2015a, b). A ban on crude oil exports was enacted in 1973 after the Arab oil embargo, and in late 2015 Congress approved lifting the ban.


Source: EIA (2015a)
US exports of petroleum products, 2005–2015.
1.3 Refinery complexity
The primary fixed assets of a refinery are its process units, and the easiest way to describe the units is in terms of their production capacity, technology application, and capital expenditures for acquisition and construction. A refinery represents a collection of integrated process units which are characterized by the number, size, and type of process units, and the technologies applied. It is common to classify refineries broadly by the presence or absence of particular units (e.g., cracking refineries contain cracking units, coking refineries contain cokers). The manner in which the units are integrated and the cost associated with the receipt and dispatch of feedstock and refined product, including storage capacity, are important but are usually considered secondary factors.
No two refineries have the same configuration or apply the same technologies because of their feedstock and product requirements, processing characteristics, degree of integration, and how the plant has evolved. Enumerating units is easy to perform, but somewhat unwieldy and difficult when comparing plants. Complexity factors were introduced to quantify and simplify classification so that refineries could be compared relative to their sophistication and capital intensity.
Wilbur Nelson introduced the concept of complexity factor in the 1960s to quantify the grassroots construction cost of process units (Nelson 1976a). New construction is referred to as grassroots construction or unit addition, whereas expansion projects add incremental barrels to existing facilities. Both investments add capacity, but the natureFootnote 1 of the construction and capital intensity differ. Nelson expressed the complexity of a process unit as the grassroots construction cost of the unit relative to the cost of the atmospheric distillation unit (ADU) normalized on a capacity basis:
Nelson applied the unit complexity factor to describe the complexity and sophistication of a refinery. Each process unit of a refinery is assigned a complexity factor via reference to projects constructed in the region at similar times, and the sum of the complexity factors weighted by the unit capacity relative to distillation capacity defines the complexity index of the refinery at a point in time:
1.4 Applications
Complexity indices quantify refinery complexity and have been used in many different ways and for many different purposes (Fig. 5). The more complex the refinery, the more capital was invested to achieve its configuration, and therefore, the greater the cost to insure and/or replace the process units. Hence, refinery complexity is frequently used by underwriters in determining premiums. Larger refineries (refineries with greater distillation capacity) are not necessarily more complex than smaller refineries, but a refiner’s conversion capacity, that is, its cracking and coking capacity, tend to be correlated to complexity, illustrating how complexity may enter correlation studies.

Applications of refinery complexity vary widely
Sophisticated refineries are more expensive to build relative to simple refineries and should transact at a premium, for all things equal, because they consist of more valuable assets, provide higher yields of more valuable products, and generate greater margins. Complexity indices are frequently used in sales price and replacement cost models in appraisal studies, and derived measures such as complexity barrels are frequently used in valuation and by credit rating agencies.
1.5 Outline
The outline of this paper is as follows. We begin by defining an ideal refinery and the variables and notation employed throughout the paper. Complexity factors and cross factors are introduced, and the methodologies used in their measurement are reviewed. Complexity indices differentiate refinery type and complexity classes are described along with a snapshot of US statistics circa 2014. The refinery complexity equation is used to quantify changes in complexity index for changes in capacity and complexity factor and is used to visually illustrate basic relations.
The relation between complexity, yields, and margins are discussed, and applications to cost estimation are described. By using cost functions, more precise formulations of complexity are introduced and compared with the traditional statistical approach. Using the complexity equation, refinery complexity is more precisely described in terms of its average and variance. Spatial complexity generalizes the complexity index at geographic scales, and application of complexity to replacement cost and sales price models are illustrated.
Refinery complexity is commonly used as a correlating variable in empirical studies, and complexity barrels represent one of the most popular uses of complexity that combine distillation capacity and complexity and enjoys widespread use by credit rating agencies when evaluating corporate debt. The review concludes by formulating and solving on inverse problem, where complexity factors are inferred from a set of refinery complexity indices based on the solution of a linear system of equations. The solution to the inverse problem allows an analyst to infer the complexity factors used in an assessment under particular conditions if those factors are not provided.
2 Ideal refinery
A refinery R at time t is composed of n + 1 process units (U 0, U 1, …, U n ) with charge or production capacities (Q 0, Q 1, …, Q n ) that depend on the unit type (Fig. 6). Process unit U 0 is designated as atmospheric distillation and Q 0 denotes distillation capacity. Charge capacity is the liquid volume of the crude that is fed to the process unit, while production capacity refers to the barrels of product produced and both are expressed in barrels per stream day (bpsd) or barrels per calendar day (bpd).Footnote 2 In gas processing and hydrogen plants, million cubic feet per day (MMcfd) of gas are the base units; for solid coke and sulfur processing, long tons are applied. Internationally, cubic meters and metric tonnes are commonly employed in measurements.

Refinery is described by its process units U i and their charge or production capacity Q i
The grassroots construction cost of unit U i of capacity Q i is denoted C i (Q i ) = C(U i , Q i ) and is always referenced with respect to a specific project, time, and location. Project characteristics, time, and location differences translate to differences in the capital cost of construction which requires adjustment and normalization before processing with other cost data. Each process unit is described by a complexity factor CF i , i = 1, …, n, and by definition, the complexity factor of atmospheric distillation is one, CF0 = 1. Complexity factors are derived measures based on an empirical evaluation of cost data.
3 Complexity factors
3.1 Nelson complexity
Nelson defined the complexity factor of a process unit as the cost of the unit relative to the cost of atmospheric distillation normalized on a capacity basis:
For example, if a 20,000 bpsd atmospheric distillation unit in Houston, Texas, cost $5 million to construct in 1960, and a 2500 bpsd delayed coking unit cost $3 million to construct in Lake Charles, Louisiana, in 1961, then the complexity factor for delayed coking circa 1960 in the US Gulf Coast (USGC) would be approximately five:
In other words, the cost to construct one barrel of a 2500 bpsd delayed coker in the USGC circa 1960 was about five times more expensive per barrel than the cost to build a 20,000 bpsd atmospheric distillation unit.
Two projects are not necessarily representative of regional trends, and to increase confidence in the results data collection should be expanded to ensure that a variety of sizes, locations, and technologies are considered in evaluation. Unfortunately, since multiple process units are not frequently built in the same region or using the same technologies, and because of confidentiality concerns in contract negotiation, significant constraints exist in data collection and the ability to provide reliable statistics on complexity factors.
3.2 Measurement
Nelson published a list of complexity factors in the Oil & Gas Journal (OGJ) for the major process units in the 1960s (Nelson 1976a, b, 1977), which was later updated by Farrar (1985, 1989) and continued to the present day in a commercial format (Table 3). The last publicly reported USGC complexity factors were in 1998, and so reference in this paper to OGJ complexity factors refer to 1998 values.Footnote 3
From 1961 to 1972, the complexity factors of vacuum distillation, thermal cracking/visbreaking, and catalytic hydrotreating were reported as two, indicating that during this time, grassroots construction costs were about twice the cost of a barrel of atmospheric distillation. Isomerization capacity was three times as expensive as distillation, catalytic reforming and hydrorefining four times as expensive, and so on. Aromatics were reported as the most expensive technology on a per barrel basis, and unlike the other units, its complexity factor has declined. Complexity factors for lubes, oxygenates, hydrogen, and asphalt units were added in later years.
3.3 Complexity cross factor
Complexity factors are normalized with respect to atmospheric distillation since atmospheric distillation is usually the cheapest process unit to build and has the greatest throughput capacity. However, it is obvious that complexity factors can be defined with respect to any two process technologies, for example, hydrotreating or catalytic cracking, in what we refer to as complexity cross factors, or more simply cross factors.
The complexity cross factor for process unit U i with respect to unit U j is defined as the normalized construction cost per barrel for the respective units:
Cross factors can be inferred from known complexity factors, if available, since the distillation normalization cancels out in the numerator and denominator terms:
Conversely, if cross factors are available, complexity factors can be inferred via the relation:
3.4 Uncertainty
If process units were built frequently and reported their construction cost consistently using standardized cost categories and accounting, complexity factors could be computed with a high degree of reliability and would be subject to minimal uncertainty and measurement bias, but because units are not built frequently or in the same region or time or with the same technologies or capacities, and because cost data are rarely publicly available, the sample sets from which complexity factors are computed are often small, heterogeneous, and of low quality. Reliable cost data therefore needs to be processed carefully, adjusted and normalized prior to evaluation, with a clear understanding of the inherent limitations of the analysis. Since only small sample sets are available, small data analysis techniques are applied, and uncertainty levels are expected to be high.
Example
Six USGC grassroots projects completed in 2010–2012 report construction cost ranging from $923/bpd for distillation to $21,429/bpd for delayed coking (Table 4). Based on this sample, complexity factors are computed to be 23 for delayed coking, 22 for VGO hydrocracking, 10 for catalytic reforming, 8 for diesel hydrotreating, and 6 for gasoline desulfurization, about two to four times greater than the 1998 OGJ complexity factors. Cross factors for the sample data and OGJ factors indicate a slightly smaller range of variation (Table 5).
4 Refinery complexity
Refinery complexity quantifies the type of process units in a refinery and their capacity relative to atmospheric distillation. Each process unit is assigned a complexity factor, CF i , which is multiplied by the unit capacity Q i relative to distillation capacity Q 0, and when summed over all the process units defines the complexity index CI(R) of the refinery:
All process units of the refinery are part of the evaluation, and if petrochemical facilities such as steam crackers (olefins plant), cyclohexene, cumene, ammonia, and methanol synthesis are present, these should be included. Refinery configuration and process flows do not enter the evaluation nor is the number of units (redundancy), vintage, or specific technologies part of the computation.
Using the complexity index of a process unit, CI(U i ), the refinery complexity is computed as the sum of the complexity indices of its units:
where CI(U i ) = (Q i /Q 0)CF i .
Example
In 2015, Kern Oil & Refining’s Bakersfield, California, refinery reported 25 Mbpd atmospheric distillation capacity, 3 Mbpd catalytic reforming capacity, and 13 Mbpd hydrotreating capacity. Using the 1998 OGJ complexity factors, the refining complexity is computed as
Example
In 2014, PBF Energy’s Delaware City, Delaware, refinery reported 190 Mbpd atmospheric distillation capacity, 102 Mbpd vacuum distillation, 82 Mbpd fluid catalytic cracking, 47 Mbpd fluid coking, and 18 Mbpd hydrocracking capacity. Hydrotreaters process straight run naphtha, diesel, and middle distillates with 160 Mbpd total capacity, and there is 16 Mbpd polymerization, 11 Mbpd alkylation, and 6 Mbpd isomerization capacity. Hydrogen production is via steam methane reforming. Refinery complexity circa 2014 computed using 1998 OGJ complexity factors is 12.9 (Table 6).
5 Refinery classification
5.1 Categorization
In the US, refineries are commonly referred to as simple or complex, or using more specific descriptors (Fig. 7). Refineries with cracking and coking capacity are generally referred to as “cracking” and “coking” refineries, respectively, or as “complex” or “very complex” refineries, to distinguish from “simple” refineries which do not have such units. In Europe and elsewhere, it is common to refer to complex refineries as “conversion” or “deep conversion” refineries.

Refinery classification including specialty and integrated refinery and typical complexity ranges
Simple refineries are often referred to as topping or hydroskimming plants since they only split crude oil into its main components and perform basic finishing operations. Topping facilities are basically just a distillation tower, while hydroskimmers also contain reforming and hydrotreating, and sometimes aromatics recovery units. Simple refineries maintain a high straight run fuel oil production and produce a high straight run fuel oil. Most coking facilities have cracking capacity, but not all cracking facilities have cokers. Coking refineries upgrade most of the fuel oil to lighter products.
The terminology to distinguish refinery classes and the complexity ranges employed are not universally recognized, but the following names and thresholds are common:
Classification | Name | Complexity range |
|---|---|---|
Very simple | Topping | <2 |
Simple | Hydroskimming | 2–5 |
Complex | Cracking, conversion | 5–14 |
Very complex | Coking, deep conversion | >14 |
Specialty | Lube oils, asphalt | >5 |
Integrated | Petrochemical | >10 |
Specialty refineries usually refer to lubricating and base oil plants or asphalt refineries. Refineries integrated with petrochemical facilities typically employ a large amount of aromatics recovery and include cumene and cyclohexane units, ammonia and methanol synthesis.
5.2 Topping refinery
A “topping” refinery relies entirely on distillation to separate cuts and is the simplest type of refinery that can be built. Residuum is sold as a heavy fuel oil, and if vacuum distillation is available, part of the residuum could be made into asphalt. No additional processing occurs at topping refineries, and much of the output stream is sold to other refineries with additional processing capacity. Topping refineries are usually built to prepare feedstocks for petrochemical manufacture or for the production of industrial fuels in remote areas. A large portion of the production from topping refineries is straight run fuel oil.
A topping refinery has no conversion or finishing processes, and its range of products is entirely dependent on the characteristics of the crude oil. For example, a crude that contains 25% gasoline boiling range molecules and 15% diesel boiling range molecules will produce approximately 25% gasoline boiling range cuts and 15% diesel cuts in a topping facility. A portion of the naphtha stream may be suitable for low octane gasoline in some areas, but because topping refineries do not have facilities for controlling product sulfur levels, the gasoline products may not be suitable for direct consumption and the refinery probably cannot produce ultralow sulfur fuels unless the crude is light and sweet.
Example
The Prudhoe Bay Crude Oil Topping Unit (COTU), owned and operated by ConocoPhillips Alaska Inc., maintained 16,000 bpsd (15,000 bpd) distillation capacity in 2014 to provide arctic heating fuel (AHF) for the Endicott/Badami field operations in the North Slope of Alaska. The COTU consists entirely of two parallel atmospheric distillation towers. Each plant heats the crude to approximately 550 °F and distills off the AHF fraction. The AHF is sent to storage tanks for use, and the remaining fluids are recombined and re-injected back into the oil transfer line. Each plant is capable of processing approximately 7000–8000 bpd of crude with production of 1200–1400 bpd of AHF. Production of Jet A is done on a periodic batch basis. AHF and Jet A are the only products of the unit and all production is consumed on site.
5.3 Simple refinery
Low-complexity refineries typically run light/sweet crude oil and produce a high yield of low-quality products (Fig. 8). Hydroskimmers make extensive use of hydrogen treatment to clean up the naphtha and distillate streams to satisfy regulatory specifications, and to pre-treat naphtha feedstock to remove sulfur to avoid poisoning the reformer catalyst. Reformers upgrade naphtha into high-octane reformate to meet gasoline octane specification and provide an important source of hydrogenFootnote 4 for hydrotreating. Reforming produces aromatics (e.g., benzene, toluene, xylene) and some hydroskimmers employ aromatics recovery units to separate out these high-value products for sales to petrochemical plants.

Schematic of a low-complexity refinery and typical product output
Example
In 2015, Galp Energia’s 91.3-Mbpd Matosinhos refinery in Portugal had vacuum distillation capacity of 16.4 Mbpd, catalytic reforming capacity of 25.4 Mbpd, catalytic hydrotreating capacity of 76.9 Mbpd, and aromatics capacity of 17.3 Mbpd. Using OGJ complexity factors as a proxy for international construction, the Matosinhos refinery complexity is computed to be 7.3 (Table 7).
Galp Energia refer to their refinery as a hydroskimmer, and although the complexity index exceeds the normal cutoff of a “simple” US refinery, the classification is appropriate since the facility does not contain any conversion processes. Aromatics contribute about 40% of the complexity score, and because the plant also produces lubricants, base oils, and solvents, if located in the US the refinery would be called a fuels-lubes plant.
5.4 Complex (conversion) refinery
Conversion processes carry out chemical reactions that crack large, high-boiling point hydrocarbon molecules into smaller, lighter molecules suitable for gasoline, jet fuel, diesel fuel, petrochemical feedstocks, and other high-value products. The primary conversion processes that perform these operations are fluid catalytic cracking (FCC), hydrocracking, and coking. Visbreaking is a thermal conversion process similar to coking but is milder and rarely used in the US anymore, but is still common in Europe and other parts of the world where legacy units remain in operation.
Complex refineries typically run heavier and more sour crude oils and produce more higher quality products (Fig. 9). High-complexity refineries typically produce the highest yields of lighter and higher-value products by application of catalytic cracking, hydrocracking, and coking capacity (Fig. 10). Complex refineries take advantage of the price differentials that exist between different crude oils due to supply and demand, gravity, quality, and location imbalances.

Schematic of a medium-complexity refinery and typical product output

Schematic of a high-complexity refinery and typical product output
Refineries with a FCC unit are considered a medium-upgraded facility because it converts a portion of straight run fuel oil to gasoline and diesel but still produces a significant volume of heavy fuel oil. A coker refinery upgrades most of the fuel oil to lighter products and thus makes the low-value fuel oil effectively “disappear.” Coking breaks down the heaviest fractions of crude oil into lighter, higher-value products and elemental carbon (coke) that is sold for steel production and anode manufacturing. Hydrocarbon compounds used in cokers would otherwise only be usable as residual fuel or asphalt.
The pressure of cracking and coking units almost always indicates additional process technologies within the refinery such as alkylation or polymerization units for converting olefin streams to gasoline and petrochemical blendstocks, aromatics, asphalt plants, sulfur recovery, and hydrogen production.
Conversion capacity is a measure of a refinery’s conversion units relative to atmospheric distillation. It is defined as the ratio of a plant’s cracking and coking capacity divided by atmospheric distillation capacity:
Cracking includes thermal cracking, visbreaking, catalytic cracking, and hydrocracking. The conversion capacity of the most complex US refineries are generally greater than 75%, and in some cases, can exceed 100%. Refinery size is not correlated with conversion capacity.
Example
Pasadena Refining’s Pasadena, Texas, and Citgo Petroleum’s Corpus Christi, Texas, refineries have complexity indices of 7.4 and 13.8, respectively (Table 8). Neither facility has a hydrogen plant. The Corpus Christi refinery has a greater percentage of more complex units as well as greater hydrotreating capacity which is responsible for its higher complexity index. At the Pasadena refinery, the conversion capacity is 53% (=62/117), and at Corpus Christ, the conversion capacity is 70% (=110/157).
Example
SK Group’s Ulsan 840-Mbpd refinery in South Korea has a complexity index of 7.2 and is the third largest refinery in the world circa 2014 with 147 Mbpd catalytic cracking and 45 Mbpd hydrocracking capacity. The conversion capacity at Ulsan, however, is only 23% (=192/840), representing low-upgrading capacity.
6 USA and world statistics
In 2014, world refining capacity was 90 MMbpd, and approximately half of the 646 refineries were cracking facilities, 35% were cokers, 10% were hydroskimmers, and 5% were topping plants (OGJ 2014). North America and Europe held about a quarter of refining capacity each, followed by the Middle East, Central and South America (Fig. 11). The Asia–Pacific region, which includes Russia, China, India, and Australia, held about a third of global distillation capacity. In the United States, the vast majority of refineries are conversion facilities of medium-to-high complexities. In Asia, the Middle East, and South America, areas that are experiencing rapid growth for gasoline demand and light products, almost all new construction is conversion and deep conversion facilities. In Europe, Japan, and Russia, hydroskimming refineries are common, and in recent years several have been shut down or under severe financial distress due to competition with newly built refineries.

Source: BP
World refinery capacity distribution circa 2014.
In 2014, 122 refineries in the USA maintained 18.1 MMbpd distillation capacity with an average plant complexity of 8.7 (Fig. 12). There were four refineries (3%) with complexity index less than 2, 17 refineries (14%) with complexity between 2 and 6, 96 refineries (70%) with complexity between 6 and 12, and 15 refineries (13%) with complexity greater than 12 (Fig. 13). Large variations in complexity are due to local market requirements, development pathways and consolidation trends, and of course, diverse configurations across plants. About a third of US refineries have complexity index greater than 10.

US refinery complexity per plant circa 2014

US refinery complexity distribution circa 2014
Most topping refineries are located in Alaska, but the most recent topping plant and the first US greenfield refinery built since 1976 is the $430 million 20-Mbpd Dakota Prairie Refining LLC (DPR) joint ventureFootnote 5 which started operations in North Dakota in 2013. There are eight refineries in the US with complexity index greater than 14, four in the USGC, three in California, and one in Kansas (Table 9). Delek US Holding’s El Dorado facility in Arkansas is currently the most complex refinery. Most complex refineries are relatively large facilities, but Calumet’s Princeton, Louisiana, specialty lubricant plant has only 10 Mbpd capacity.
The top 10 refineries in the world have crude capacities that range from 540 to 940 Mbpd, but the majority of these facilities are low-conversion low-complexity plants (Table 10). Paraguana Refining Center’s Cadon refinery is the largest refinery in the world with a 33% conversion capacity. South Korea has three of the top 10 largest refineries. Exxon Mobil’s Baytown, Texas, refinery is the only US refinery among the top 10 and has the greatest conversion capacity in the group.
Complexity and throughput show no correspondence (Fig. 14), but conversion capacity shows a modest correlation with complexity because most US refineries contain conversion units which comprise a significant portion of the complexity index (Fig. 15). Using the regression relation shown in the figure, a US refinery with conversion capacity of 60% in 2015 would be expected to have a refinery complexity of approximately CI(R) = 0.09(60) + 4.67 = 10. For every 10% increase in refinery conversion capacity, complexity increases by about a point.

Refinery complexity and atmospheric distillation capacity of US refineries (2014)

Refinery complexity and conversion capacity of US refineries (2014)
7 Complexity equation
Refinery configurations constantly evolve and change over time as new units are added or expanded and other units are retired or mothballed. Complexity factors also change as technologies change, and the relative cost of construction change. If the distillation capacity of a plant increases holding all other process capacities and complexity factors fixed, for example, refinery complexity will decrease since the individual weight factors will decline, while if one or more units are added or expanded for a given crude capacity, refinery complexity will increase. Refinery complexity will also change if complexity factors change over time.
Refinery complexity is a function of the capacity variables (Q 0, Q 1, …, Q n ) and complexity factors (CF0, CF1, …, CF n ) as expressed in the complexity equation:
Clearly, refinery complexity is linear in Q i and CF i , and nonlinear in Q 0. The partial derivatives provide predictive information on the shape of the complexity function, and its sensitivity to parameter variation when one variable changes and all other variables are held fixed (Fig. 16):

Partial derivatives provide information on the shape of the refinery complexity equation
Example
Silver Eagle Refining Inc.’s Woods Cross, Utah, refinery in 2014 had 6.25 Mbpd atmospheric distillation capacity, 6 Mbpd vacuum distillation, 2.2 Mbpd catalytic reforming, 6.2 Mbpd catalytic hydrotreating, and 1.2 Mbpd asphalt production.
The refinery complexity equation as a function of atmospheric distillation capacity is written:
Using OGJ complexity factors for the process units (CFVDU = 2, CFCCR = 5, CFHT = 2, CFASH = 1.5), the refinery complexity relation simplifies as CI(Q 0) = 1 + 37.2/Q 0 (Fig. 17). For the refinery configuration circa 2014 with 6.25 Mbpd distillation capacity, the complexity index is 7.0, but if distillation capacity increased to 9.25 Mbpd holding all the other units and complexity factors fixed, the complexity index would be 5.0. As ADU capacity increases refinery complexity decreases nonlinearly, which is related to the slope of the relation. The slope of the complexity equation at any capacity along the curve is determined by the first derivative, \( \partial {\text{CI/}}\partial Q_{0} \) = \( - 37.2/Q_{0}^{2} \).

Woods Cross, Utah, refinery complexity as a function of crude capacity and reforming capacity circa 2014
The refinery complexity equation for variable reformer capacity holding all other process units and complexity factors fixed is evaluated as:
Increasing reformer capacity increases refinery complexity linearly defined by the 0.8 slope of the equation (Fig. 17).
Similarly, holding all the process capacities fixed and varying the complexity factor for one unit, say the asphalt plant, the refinery complexity equation becomes CI(CFASH) = 6.664 + 0.192·CFASH and the slope of complexity equation describes how changes in the asphalt complexity factor change the complexity index. For example, if the actual asphalt complexity factor was 4.5 instead of 1.5, the refinery complexity would be 7.5.
8 Cost estimation
Complexity factors are derived from cost data and are therefore useful in cost estimation, but to be an accurate and reliable indicator of cost, they must be up-to-date and representative for the region of interest. Rearranging the complexity factor equation yields the cost estimation relation:
The cost of a process unit is estimated using the relation between complexity factors and capacities and the cost of a known unit.
Example
A 325-Mbpd atmospheric distillation unit was built in Texas in 2012 for $300 million. If the complexity factor of hydrocracking is 22, then the cost to construct a 35-Mbpd hydrocracker in Texas in 2012 is estimated to be $711 million:
Example
A 57-Mbpd USGC hydrocracker cost $1000 million to construct in 2012. If the complexity cross factor for the hydrocracker and refiner is 2.2, the construction cost of a 40-Mbpd reformer built in the USGC in 2012 is estimated to be $319 million:
Example
A 400-Mbpd coking refinery in Jieyang, China, is expected to be completed in 2017–2018 (Table 11). The 60,000-bpd catalytic cracking unit cost $406 million, and its normalized construction cost is computed as $6766/bpd. Using this data point and normalizing by the USGC complexity factors, the total cost of the refinery is estimated at $6.6 billion, about three-quarters of the $9 billion reported estimate. Differences between the estimated and expected total cost is due to regional variation in the complexity factors and the first-order approximation of the estimation equation.
9 Functional complexity
9.1 Cost function formulations
A more precise way to formulate complexity factors is to process the sample data using cost functions, and then to apply the cost functions at specified capacities, or to specify the capacity interval of each unit and create the complexity factor functional (Kaiser 2016). The cost data are the same in all three approaches, of course, but how the data are processed and evaluated are different, and consequently, the resultant complexity factor values will also be different (Fig. 18).

Traditional statistical approach to computing complexity factors and two alternative formulations based on cost functions
In the traditional (statistical) approach to complexity factors, the cost data are normalized by capacity via division, and then statistical techniques are applied in processing. The computations are easy to perform, but one of the limitations of the method is the inability to account directly for the impact of capacity on cost. There is no “control” in the data sample, and since we are not controlling for capacity directly, its impact is unknown. Capacity is not a control variable, but used as input data to normalize the complexity factor.
In the reference capacity approach, the use of cost functions improves the reliability and transparency of the calculations and accounts for capacity variation, and since capacity is required in the assessment, it improves specificity since this term must be specified. Complexity factors at reference capacity (CFRC) specify “representative” capacities in the cost functions, but the data used in constructing cost functions span a wide spectrum of costs and capacities. By selecting two specific capacities in evaluation, the range of capacities and costs are effectively excluded. Since cost curves describe cost as a function of capacity, it is natural to employ cost functions directly to infer the variation in complexity factor from its functional formulation. In the complexity factor functional approach (CFFA), the moments of the functional, namely the average and standard deviation, are evaluated over its parameter domain and provide a more nuanced and precise formulation of complexity factor.
9.2 Complexity factor at reference capacity
The complexity factor for units A and B at reference capacities \( Q_{*} \) and \( q_{*} \) are computed in terms of the cost functions of the units as follows:
where the cost functions are described by C(A, Q) = KQ a and C(B, q) = Lq b, and the reference capacities Q * and \( q_{*} \) are specified. Capacities are denoted by Q and q to reinforce the notion that the capacities are for different units and range over different intervals. Reference capacities are stated explicitly for each unit to specify the measure. One logical choice for reference capacity is the active average capacity for all units in the region of interest or for recently built units in the region (Table 12). Median capacities may be preferred if the difference in the minimum and maximum capacities of the sample are significant.
Example
The complexity factor at reference capacity for diesel hydrotreating (DHT) based on 2014 average capacities in the US and 2009 USGC cost functions, C(DHT) = 8.61Q 0.63 and C(ADU) = 8.20q 0.51, is 3.3:
9.3 Complexity factor functional average
The complexity factor functional CF(Q, q) is a two-dimensional function of the capacities of the two units A and B written as follows:
where again the cost functions are described by C(A, Q) = KQ a and C(B, q) = Lq b and parameters (K, a) and (L, b) are given, but instead of specifying the reference capacities of evaluation (i.e., Q * and q * ), the range of the capacities of each unit is specified by I A = (c, d) and I B = (e, f). It is convenient to select a range based on average capacities plus/minus a fraction of standard deviation. Specification of the capacity intervals is required for the function definition.
As capacity intervals vary, the complexity functional will be defined over different domains, which will impact its size and shape and (derived) properties such as the average and variance. To compute the average of the complexity factor function CF(Q, q) over the intervals I A = (c, d) and I B = (e, f), a double integration is performed:
And because the cost functions are power law expressions, a closed-form (analytic) solution is possible (see Kaiser 2016 for derivation). The mean and variance of the complexity factor function is readily computed:
Example
The catalytic reforming complexity factor functional is constructed using MATLAB based on 2009 USGC cost curves, C(CCR) = 12.19Q 0.55 and C(ADU) = 8.2q 0.51, and capacity intervals defined by average active US capacities circa 2014 plus/minus one standard deviation, I CCR = (5, 55) and I ADU = (22, 276) Mbpd (Fig. 19). The function ranges in value from 1.1 to 11.1 over its domain, increases rapidly for high ADU capacity and low CCR capacity, and declines as CCR capacity increases.

Catalytic reforming complexity factor functional
The distribution of complexity factor values is lognormal, and using an interval of 1 Mbpd, the mean is empirically computed as 4.02 with a standard deviation of 1.71 (Fig. 20). Formula (theoretical) values using the above equations yield E(CF) = 3.98 and SD(CF) = 1.65. The complexity factor functional average for catalytic reforming is approximately 4.0, similar to OGJ’s complexity factor value of 5, but here we have derived additional useful information on the standard deviation of the statistic which is not available elsewhere.

Catalytic reforming complexity factor distribution
9.4 Comparison
Complexity factors at reference capacity were computed using 2009 USGC cost functions described in Kaiser and Gary (2009) and average active US capacities circa 2014 (Table 13). Ideally, the reference year of the cost curves and inventory period should approximately match, but cost curves are not usually available except on a periodic basis, and simply adjusting the cost functions through indexing will not change the complexity factor values since the same adjustment applies in both the numerator and denominator and cancel out. To match evaluation periods, the cost functions need to be updated using recent project cost data.
For delayed coking, gasoline hydrotreating, and lubes, the complexity factors at reference capacity differ by less than 20% from OGJ values, but for other units, differences are greater, and in some cases, far greater. For vacuum distillation, catalytic cracking, reforming, and alkylation, the OGJ values are about one-and-a-half times larger than the complexity factor at average capacity, while for aromatics, isomerization, and oxygenates, the OGJ values are more than two-and-a-half times larger. For polymerization and hydrogen plants, OGJ complexity factors are notably smaller than the complexity factor at average capacity. Complexity factor functional average values appear in the last column in Table 13 and are slightly larger (about 10%) than the complexity factor at reference capacity values.
Cost curves are the primary element in the reference capacity and complexity factor functional approaches, while in the traditional approach, the complexity factor is computed directly from the raw data (Fig. 21). In the cost function approach, cost curves are used which allows the impact of capacity to be incorporated either directly through baseline capacity selection or through a more integrated treatment. Costs are determined at reference capacities which are a priori specified. In the traditional approach, capacities are not controlled or specified, and confound the assessment. Complexity factor functional average values are considered the most precise of the three metrics because they incorporate the entire spectrum of the functional values in an integrated fashion and provide a natural interpretation of variance for small sample sets. The introduction of complexity variance in this context is new and can be applied in various ways as shown in the next section to compute complexity moments.

Statistical approach to complexity factor and two new approaches that use cost functions, complexity factor at reference capacity, and the complexity factor functional average
CFRC and CFFA values were computed for each US refinery circa 2014 and compared to the traditional OGJ complexity factor approach. The three indices are broadly similar on an aggregate basis (Figs. 22, 23). The average US refinery complexity circa 2014 is 8.7 using the OGJ complexity factors, 8.9 using the CFRC formulation, and 9.0 using the CFFA approach.

Complexity index of US refineries circa 2014 based on OGJ complexity factors, complexity factor at reference capacity, and complexity factor functional averages

Complexity index distribution of US refineries circa 2014 based on OGJ complexity factors, complexity factor at reference capacities, and complexity factor functional averages
10 Refinery complexity moments
Complexity factors represent stochastic variables with a mean and variance, and so refinery complexity also exhibits a mean and variance. The moments of the refinery complexity index are computed based on the complexity equation and the linearity of the operators. Process units are assumed independent. Since Q i is fixed at a point in time and complexity factors are independent random variables described by E(CF i ) = CFFA(CF i ) and V(CF i ), i = 1, …, n, the expected value and variance of the refinery complexity is computed as follows:
Example
PBF Energy’s 190-Mbpd Delaware City, Delaware, refinery complexity was previously computed as 12.9 using OGJ complexity factors (Table 6). To compute the variance of the complexity index requires knowledge of the variance of the complexity factors. Applying the CFFA values in Table 13 and the variance formula shown above, the expected value and variance of the refinery complexity is computed to be 13.0 and 3.6, respectively (Table 14).
11 Spatial complexity
Refining complexity can be evaluated at any level of spatial aggregation from the plant up through the country level and beyond (Fig. 24), but as geographic scales expand and include different states and/or countries, the use of one set of complexity factors becomes problematic since the data from which they are derived are typically estimated regionally. Complexity factors established for the USGC are not expected to be reliable outside the USA, but because of the paucity and uncertainty of international data, it is often used as a proxy. Complexity factors are computed for a specific region based on regional data, or adjusted using a location factor (Maples 2000).

Spatial aggregation in refining complexity applications
Example
Shell Oil Products, USA, operates a 145-MMbpd refinery in Martinez, California, and a 145-MMbpd refinery in Anacortes, Washington. Using OGJ 1998 complexity factors, the complexity index for Shell Oil Products, USA, combined operations is computed as 12.1 (Table 15). Using the complexity reference and complexity factor functional formulations, CFRC(Shell Oil, USA) = 12.2 and CFFA(Shell Oil, USA) = 12.8.
Example
California’s 13 active refineries in 2013 comprised 2035 Mbpd distillation capacity and a composite complexity index of 13.5 using CFFA values with a standard deviation of 1.6 (Table 16). Using OGJ complexity factors, CF(California) = 11.2 and CFRC(California) = 12.8.
12 Replacement cost
Reproduction cost and replacement cost are commonly used for valuation and appraisal studies and in the insurance industry. Reproduction cost is the estimated cost to construct an exact replica of the property with the same materials, construction standards, and obsolescence. Replacement cost is the estimated cost to construct a property with the same utility but with contemporary materials and standards. Reproduction cost is more difficult to reliably estimateFootnote 6 and generally less useful than replacement cost in refining studies and is not commonly employed.
Example
PBF Energy acquired the 170-Mbpd Toledo, Ohio, cracking refinery from Sunoco in March 2011 for approximately $400 million, and the replacement cost reported by management at the time of the acquisition was $2.4 billion. Using 2009 USGC cost functions, and assumed off-site cost of 30%, capitalized interest of 10%, 4.5 million barrels storage, and storage cost of $38/bbl, replacement cost new is estimated at $2 billion (Table 17). Nelson-Farrar construction cost indices were used to adjust the reference year of the cost curves to the 2011 evaluation period.
13 Sales price models
13.1 Asset transactions
Complexity and complexity barrels are commonly used to analyze refinery sales data in an attempt to normalize for the sophistication and size of units and their replacement cost. A high refinery complexity indicates a high level of capital investment in sophisticated process units, a higher cash margin potential per barrel of throughput, and a greater refining asset value per barrel of distillation capacity, for all things equal.
Refineries represent business combinations, and sales are for combinations of real, personal, and business assets. Sales price is determined by many factors, several of which may be relevant in evaluating the transaction, but not all factors are observable. It is never possible to include all the relevant factors in evaluation, and because samples are typically small and the number of relevant factors potentially large, it is necessary to select a small set of factors (primary factors) and use these primary factors to reconcile model results.
Transactions may include investment participation, financing, partial interests, offtake and supply contracts, and other closing contingencies that are not disclosed. Since many details are confidential, the sales price may not be adequately verifiable or properly adjusted. Buyers and sellers typically do not breakdown prices attributable to individual assets. Market adjustments are important as the value markets place on refineries change frequently due to macroeconomic conditions, including trends in the general economy, crude and refined product prices, regulations, etc.
13.2 Formulation
Capacity, complexity, complexity barrels, and replacement cost new (RCN) are the most common descriptors in sales price models which are applied in model form as follows:
-
Price(Capacity · Complexity) = K · (Complexity · Capacity)a
-
Price(Capacity, Complexity) = K · Capacitya · Complexityb
-
Price(RCN) = K·RCNa
where the parameter values (K, a, b) are determined by regression analysis. Units for sale price and RCN are US dollars, and capacity and complexity barrels may be reported in bpsd or bpd. Complexity barrels are denoted as cbpsd or cbpd.
Capacity is defined by the refinery configuration, while sales price, RCN, and complexity are derived quantities that enter the model relation. Price data are available from the market at varying levels of quality and requires adjustment and normalization whenever multiple sales are compared (Neumuller 2005). Complexity and RCN calculations are often performed by multiple organizations and are subject to uncertainty if not calibrated consistently. RCN values exhibit greater levels of uncertainty relative to refinery complexity calculations.
Example
A sampleFootnote 7 of refinery transactions between 2010 and 2012 is used to illustrate the computational methods and models (Table 18). The transaction data includes whether the refinery was active at the time of sale, and the sales data excludes pipelines, terminals, and inventory. Replacement costs new were estimated by the purchaser and were not reported for all sales.
The weighted average sales price per barrel for the sample is $1665/bpd, and the weighted average sales price per complexity barrel is $152/cbpd (Table 19). Standard deviations are the same order as the averages $1591/bpd and $202/cbpd, respectively, indicating wide variation in market valuations. Idle (mothballed) refineries at the time of sale sell at a discount relative to active refineries. The average sales price for active refineries is $2723/bpd, and the average sales price per complexity barrel is $238/cbpd; for inactive refineries, the average sales prices are $1067/bpd and $114/cbpd.
The average replacement cost per capacity barrel is $16,600/bpd with $9800/bpd standard deviation. Sales price per replacement cost averaged 12% with a 4.5% standard deviation. Refinery assets are normally purchased at a discount to replacement cost, and then, capital is spent to upgrade and improve the plant equipment and product slate and crude supply access. The price discount for this sample and time period is relatively steep; earlier in the decade discounts typically averaged between 25 to 40%.
Using the refinery sales for active units, the parameters of the sales price models are estimated as follows:
-
Price = 0.80 (Complexity · Capacity)1.39, R 2 = 0.85
-
Price = 0.11 Capacity1.69 Complexity0.66, R 2 = 0.87
-
Price = 14.7 RCN0.39, R 2 = 0.39
13.3 Constraints
Using transactions is a strong indicator of value because it reflects the actions of buyers and sellers in the market. Multifactor regression models are limited in their ability to capture all of the relevant factors of transactions, however, because sample sizes are usually much smaller than the factor set, and so a small number of factors are usually selected for evaluation. The critical ingredient is to select “comparable” sales and to perform “suitable” adjustments prior to parameter estimation, but these activities are subject to user preferences and experience. Two transactions are never the same. Standard practice usually requires the consideration of actual sales data, if available, in appraising a property. Complexity and complexity barrels find common use in reporting market data and transaction metrics.
14 Complexity barrels
Fitch, Moody’s, Standards & Poor (S&P) and other rating agencies use complexity barrels, also referred to as equivalent distillation capacity, in their assessment of the credit rating of companies (Fitch 2012; Moody’s 2013; S&P 2011). As the name implies, complexity barrels are simply the product of distillation capacity and refinery complexity and, because it incorporates both the size of the refinery and its overall complexity, are considered a useful measure for comparison and trending purposes. Complexity barrels recognize a company’s throughput capacity and signal the quality of that capacity via the refining complexity.
Example
The equivalent distillation capacity of Exxon Mobil’s Baton Rouge refinery increased by 170 cbpd, or about 4%, from 2000 to 2013. Exxon Mobil’s Baton Rouge refinery configuration and complexity has not changed significantly over the past decade, and therefore, its complexity barrels have also not changed significantly (Table 20).
The purpose of rating agencies is to assess the likelihood a company will repay its debt, the interest, and principal on its bonds. Agencies use a letter and number system to rate corporate bonds, and the lower the bond rating, the higher the interest required on the bond issue since ratings correlate with the probability of corporate default (Table 21). High bond ratings are associated with lower interest rates and lower risk of default than low bond ratings. Each rating agency applies different methodologies, thresholds and notation, but they are broadly similar across the industry.
Rating agencies use a weighted risk index based on several financial and operational components of the company, including refinery configuration, capital leverage, competition, and other factors. Equivalent distillation capacity is one component of ratings that is taken into account, and the greater the value the higher the rating.
Complexity barrels, Mcbpd | Rating |
|---|---|
≥9000 | Aaa |
7500–9000 | Aa |
5000–7500 | A |
3500–5000 | Baa |
2000–3500 | Ba |
500–2000 | B |
<500 | Caa |
Example
In 2014, Western Refining owned a 122-Mbpd refinery with a complexity index of 5.2, and a 26-Mbpd refinery with a complexity index of 9.6. Western Refining’s complexity barrels are computed as (122 Mbpd) (5.2) + (26 Mbpd) (9.6) = 884 Mcbpd, which would be assigned a B component rating using Moody’s system. The product of the corporate complexity index and total capacity is usually a good proxy if individual plant data are unavailable. Western Refining’s 5.9 corporate complexity index yields an equivalent distillation capacity of 873 Mcbpd.
15 Inverse problem
Complexity factors are the key ingredient in computing refinery complexity and are often sold as part of a commercial database, which explains why they are often viewed as proprietary. This perspective is misguided, however, and there is no reason to think of complexity factors as confidential since they can always be inferred by solving a system of linear equations using the refinery complexity relations.
If Q = (Q 0, Q 1, …, Q n ) and CF = (1, CF1, CF2, …, CF n ) are given, the complexity index of refinery R is computed as the inner product of the vectors divided by Q 0, or CI(R) = Q · CFT/Q 0. In the inverse problem, the complexity factors are unknown, and the task is to infer their value based on (reported) refinery complexity. Refinery complexities are frequently reported in company financial statements and press releases, among other sources. If there are n complexity factors to infer, there needs to be n refinery indices available for plants with roughly similar process units. A three refinery example illustrates the procedure followed by the general framework.
15.1 Three refinery example
Three international refineries located in the same country and containing vacuum distillation, reforming, and hydrotreating capacity report complexity indices CI(A) = 3.9, CI(B) = 4.0, and CI(C) = 5.5 in investor presentations but do not disclose the complexity factors used in the calculation. Refinery configurations are as follows:
A, Mbpd | B, Mbpd | C, Mbpd | |
|---|---|---|---|
Atmospheric distillation | 100 | 80 | 50 |
Vacuum distillation | 40 | 45 | 30 |
Catalytic reforming | 20 | 15 | 10 |
Hydrotreating | 30 | 20 | 35 |
Since there are three refining units besides atmospheric distillation, three equations are needed to estimate the three complexity factors. First, write the complexity equation for each refinery:
Next, assume CFADU = 1, and solve for the unknowns:
Solving the system of equations yields CFVDU = 2, CFCCR = 6, and CFHT = 3, the (inferred) complexity factors used in the evaluation.
15.2 Matrix formulation
Let (\( Q_{0}^{i} ,Q_{1}^{i} ,\ldots,Q_{n}^{i} ) \) denote the process capacities and CI(R i) the complexity index of refinery R i, i = 1, 2, …, n. Denote the complexity indices of the n refineries in vector form as CI = (CI(R 1), CI(R 2), …, CI(R n)) and the complexity factors of the process units as CF = (1, CF1 …, CF n ). The refining equations for the n refineries are expressed as a matrix, which is readily verified to yield the refinery equations:
or, in matrix form:
CIT = \( \tilde{M} \) · CFT,
To solve for the complexity factors, invert the matrix and solve the system of equations. As long as the equations are well conditioned, which they almost always will be because of the unique nature of refinery configurations—literally, no two refineries are alike in process capacities—the complexity factors are computed thus:
CFT = \( \tilde{M}^{ - 1} \) · CI
Example
Five international refineries located in the same country report complexity indices CI(A) = 7.1, CI(B) = 6.7, CI(C) = 6.8, CI(D) = 7.6, and CI(E) = 5.7 in their annual reports. Refinery configurations are as follows:
A, Mbpd | B, Mbpd | C, Mbpd | D, Mbpd | E, Mbpd | |
|---|---|---|---|---|---|
Atm. distillation | 120 | 100 | 80 | 155 | 60 |
Vacuum distillation | 60 | 40 | 35 | 70 | 25 |
Thermal operation | 30 | 20 | 30 | 40 | 10 |
Cat. hydrocracking | 30 | 25 | 15 | 40 | 10 |
Reforming | 15 | 10 | 12 | 30 | 8 |
Hydrotreating | 50 | 45 | 30 | 70 | 20 |
Refinery complexity | 7.1 | 6.7 | 6.8 | 7.6 | 5.7 |
Set up the refinery equation for the unknown variables and solve.
Using Excel’s Solver function yields CFVDU = 2, CFTO = 3, CFHC = 9, CFCCR = 6.5, and CFHT = 3.
Notes
Typically, the objective of replacement units and modernization is to reduce energy consumption and lower operating costs, while new construction and capacity expansions are performed to increase operational flexibility and refining margins. Expansion projects are often cheaper than new construction on a per barrel basis because existing facilities can be used or revamped, construction activity is less intensive and of shorter duration, and less piping and labor are required.
A barrel per stream day is the nameplate (design) capacity of a unit. A barrel per calendar day represents the typical throughput capacity taking into account downtime and related factors. Normally, calendar day barrels range between 85% and 95% stream day barrels.
OGJ complexity factors for most of the process units have not changed significantly over several decades, either because construction cost did not change, or more likely, the cost data was not updated. OGJ complexity factors available for purchase closely follow 1998 values, and no documentation is provided on cost data collected or used.
Historically, many US refineries built before 1975 had their reformers designed to be in hydrogen balance with the hydrotreaters. Today, hydrogen requirements at US plants not satisfied by reforming are produced primarily by steam methane reforming.
DPR is owned and operated by WBI Energy, a 50–50 joint venture of MDU Resources Group, Inc. and Calumet Speciality Producer Partners LP. The plant produces 7000–8000 bpd of diesel, 6500 bpd of naphtha, and about 6000 bpd of atmospheric tower bottoms which is shipped to Calumet’s lube oil refineries in Louisiana.
How does one construct an exact replica of legacy units when technologies and materials change or become obsolete?
The results are not intended to be representative of the broader market.
References
BP p.l.c. 2015. BP statistical review of world energy June 2015. http://www.bp.com/content/dam/bp/pdf/Energy-economics/statistical-review-2015/bp-statistical-review-of-world-energy-2015-full-report.pdf. Accessed 17 Sept 2015.
Farrar GL. How Nelson cost indices are compiled. OGJ. 1985;(65):145.
Farrar GL. Interest reviving in complexity factors. OGJ. 1989;(69):90.
Fitch Ratings Inc. Special report—rating oil refining and marketing companies. 2012.
Gary JH, Handwerk GE, Kaiser MJ. Petroleum refining: technology and economics. 5th ed. Boca Raton: CRC Press; 2007. doi:10.1016/B0-12-227410-5/00556-1.
Kaiser MJ. A new approach to refinery complexity factors. Engineering Economist. 2016;30(4):1–33. doi:10.1080/0013791X.2016.1202365.
Kaiser MJ, Gary JH. Refinery cost functions in the U.S. Gulf Coast. Pet Sci Technol. 2009;27(2):168–81. doi:10.1080/10916460701434704.
Maples RE. Petroleum refining process economics. 2nd ed. Tulsa, OK: PennWell; 2000.
Meyers RA. Handbook of petroleum refining processes. 3rd ed. New York: McGraw-Hill; 2004.
Moody’s Investors Service. Global refining and marketing rating methodology. 2013.
Nelson WL. Guild to refinery operating cost (process costimating). 3rd ed. Tulsa, OK: Petroleum Publishing; 1976a.
Nelson WL. How the Nelson refinery construction-cost indexes evolved. OGJ. 1976b;(56):68.
Nelson WL. Here’s how operating cost indexes are computed. OGJ. 1977;(57):86.
Neumuller R. Method estimates U.S. refinery fixed costs. OGJ. 2005;(85):43.
Oil and Gas Journal. 2014. Worldwide refining survey. Tulsa, OK: PennWell. 2015. http://www.ogj.com/ogj-survey-downloads.html. Accessed 17 Sept 2015.
Parkash S. Refining process handbook. Amsterdam: Elsevier; 2003.
Raseev S. Thermal and catalytic processes in petroleum refining. New York: Marcel Dekker; 2003. doi:10.1201/9780203912300.
Riazi MR, Eser S, Agrawal SS, Diez JL Pena (Ed). Petroleum refining and natural gas processing. MNL58, ASTM international, West Conchohocken; 2013. doi:10.1520/MNL58-EB.
Schobert HJ. Energy and society. New York: Taylor and Francis; 2002.
Speight JG. The chemistry and technology of petroleum. 3rd ed. New York: Marcel Dekker Inc; 1998. doi:10.1201/9780824742119.
Standard & Poor’s Financial Services LLC. Key credit factors: criteria for rating the global oil refining industry; 2011.
U.S. Department of Energy, Energy Information Administration (EIA). U.S. exports of petroleum products. 2015a. http://www.eia.gov/dnav/pet/pet_move_exp_dc_NUS-Z00_mbbl_m.htm. Accessed 17 Sept 2015.
U.S. Department of Energy, Energy Information Administration (EIA). U.S. field production of crude oil. 2015b. http://www.eia.gov/dnav/pet/hist/LeafHandler.ashx?n=PET&s=MCRFPUS1&f=M. Accessed 17 Sept 2015.
U.S. Department of Energy, Energy Information Administration (EIA). U.S. imports of crude oil. 2015c. http://www.eia.gov/dnav/pet/hist/LeafHandler.ashx?n=pet&s=mcrimus1&f=a. Accessed 17 Sept 2015.
U.S. Department of Energy, Energy Information Administration (EIA). U.S. refinery net product. 2015d. http://www.eia.gov/dnav/pet/pet_pnp_refp2_dc_nus_mbbl_m.htm. Accessed 17 Sept 2015.
U.S. Department of Labor, Occupational Safety and Health Administration (OSHA), OSHA technical manual, in Petroleum Refining Processes, Washington, D.C., 2005, sec. IV, chap. 2.
Author information
Authors and Affiliations
Corresponding author
Additional information
Edited by Xiu-Qin Zhu
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kaiser, M.J. A review of refinery complexity applications. Pet. Sci. 14, 167–194 (2017). https://doi.org/10.1007/s12182-016-0137-y
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12182-016-0137-y