
Abstract
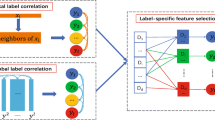
Aiming at the problem of multi-label classification, a multi-label classification algorithm based on label-specific features is proposed in this paper. In this algorithm, we compute feature density on the positive and negative instances set of each class firstly and then select m k features of high density from the positive and negative instances set of each class, respectively; the intersection is taken as the label-specific features of the corresponding class. Finally, multi-label data are classified on the basis of label-specific features. The algorithm can show the label-specific features of each class. Experiments show that our proposed method, the MLSF algorithm, performs significantly better than the other state-of-the-art multi-label learning approaches.
Similar content being viewed by others


References
Streich A, Buhmann J. Classification of multi-labeled data: A generative approach [C]//Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases. Berlin: Springer-Verlag, 2008: 390–405.
Clare A, King R. Knowledge discovery in multi-label phenotype data [C]//Proceedings of the 5th European Conference on Principles of Data Mining and Knowledge Discovery. London: Springer-Verlag, 2001: 42–53.
Tsoumakas G. Multi-label classification [J]. International Journal of Data Warehousing & Mining, 2007, 3(3): 12–16.
Chang E, Goh K, Sychay G, et al. CBSA: Content-based soft annotation for multimodal image retrieval using Bayes point machines [J]. IEEE Transactions on Circuits and Systems for Video Tech, 2003, 13(1): 268–281.
Joachims T. Text categorization with support vector machines: Learning with many relevant features [C]//Proceedings of European Conference on Machine Learning. Berlin: Springer-Verlag, 1998: 137–142.
Boutell M R, Luo J, Shen X, et al. Learning multi-label scene classification [J]. Pattern Recognition, 2004, 37(9): 1757–1771.
Weiss G. M, Provost F J. Learning when training data are costly: The effect of class distribution on tree induction [J]. Journal of Artificial Intelligence Research, 2003, 19: 315–354.
Crammer K, Singer Y. A new family of online algorithms for category ranking [C]//Proceedings of the 25th Annual International ACM Special Interest Group on Information Retrieval Conference on Research and Development in Information retrieval. New York: ACM Press, 2002: 151–158.
Yang Y. An evaluation of statistical approaches to text categorization [J]. Information Retrieval, 1999, 1(1/2): 69–90.
Zhu S, Ji X, Xu W, et al. Multi-labelled classification using maximum entropy method [C]//Proceedings of the 28th annual international ACM Special Interest Group on Information Retrieval conference on Research and development in information retrieval. New York: ACM Press, 2005: 274–281.
Griffiths T, Ghahramani Z. Infinite latent feature models and the Indian buffet process [C]//Proceedings of National Institute for Physiological Sciences. London: Gatsby Unit, 2005: 475–499.
Cai L, Hofmann T. Hierarchical document categorization with support vector machines [C]//Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management. New York: ACM Press, 2004: 78–87.
Rousu J, Saunders C, Szedmak S, et al. On maximum margin hierarchical multi-label classification [C]//Proceedings of National Institute for Physiological Sciences Workshop on Learning with Structured Outputs. Whistler: Canadian Center of Science and Education Press, 2004: 284–287.
Lewis D, Yang Y, Rose T, et al. RCV1: A new benchmark collect ion for text categorization research [J]. The Journal of Machine Learning Research, 2004, 5: 391–397.
Tsoumakas G, Zhang M L, Zhou Z H. Learning from multi-label data [C]//Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases. Bled: Springer-Verlag, 2009: 156–180.
Zhang M L. LIFT: Multi-label learning with label-specific features [C]//Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona: The Association for the Advancement of Artificial Intelligence and The MIT Press (AAAI Press), 2011: 1609–1614.
Jain A K, Murty M N, Flynn P J. Data clustering: A review [J]. ACM Computing Surveys, 1999, 31(3): 264–323.
Zhang M L, Zhou Z H. ML-kNN: A lazy learning approach to multi-label learning [J]. Pattern Recognition, 2007, 40(7): 2038–2048.
Elisseeff A, Weston J. A kernel method for multi-labelled classification [J]. Advances in Neural Information Processing Systems, 2002, 14: 681–687.
Schapire R E, Singer Y. Boostexter: A boosting-based system for text categorization [J]. Machine Learning, 2000, 39(2/3): 135–168.
Author information
Authors and Affiliations
Corresponding author
Additional information
Foundation item: Supported by the Opening Fund of Key Laboratory of Symbol Computation and Knowledge Engineering of Ministry of Education (93K-17-2010-K02) and the Opening Fund of Key Discipline of Computer Soft-Ware and Theory of Zhejiang Province at Zhejiang Normal University (ZSDZZZZXK05)
Biography: QU Huaqiao, male, Master, research direction: data mining and machine learning.
Rights and permissions
About this article
Cite this article
Qu, H., Zhang, S., Liu, H. et al. A multi-label classification algorithm based on label-specific features. Wuhan Univ. J. Nat. Sci. 16, 520–524 (2011). https://doi.org/10.1007/s11859-011-0791-2
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11859-011-0791-2