
Abstract
The World Wide Web has become a global information service center with a vast amount of news, advertisements, product and service information, and disparate information from diversified sources. However, only a small portion of information is truly relevant and useful to the users who are seeking information on specific topics. In this paper, common relations among nodes are taken into consideration when constructing site style tree, and a new node type is introduced. Experimental results show that the proposed algorithm has higher precision and recall.
Similar content being viewed by others


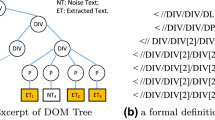
References
Ye Shiren, Chua Tatseng. Detecting and Partitioning Data Objects in Complex Web Pages[C]//Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence. Washington D C: IEEE Computer Society Press, 2004: 669–672.
Ye Shiren, Chua Tatseng. Learning Object Models from Semistructured Web Documents[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(3): 334–349.
Lin Shanhua, Huo Janming. Discovering Informative Content Blocks from Web Documents[C]//Proceedings of the Eighth ACM SIGKDD.New York: ACM Press, 2002: 588–593.
Yossef Z B, Rajagopalan S. Template Detection via Data Mining and Its Applications[C]//Association for Computing Machinery: www’02.New York: ACM Press, 2002:580–591.
Lee M L, Ling T W, Low W L. A Knowledge-Based Intelligent Data Cleaner [C]//Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2000:290–294.
Yong N U, Mikhail B, Raymond J M. Two Approaches to Handling Noisy Variation in Text Mining [C]// Proceedings of the ICML-2002 Workshop on Text Learning. New York: Springer-Verlag, 2002:18–27.
Xiong H, Gaurav P, Steinbach M, et al. Enhancing Data Analysis with Noise Removal[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(3): 304–319.
Fabrizio A, Clara P. Fast Outlier Detection in High Dimensional Spaces[C]//Proceedings of the 6th European Conference on Principles of Data Mining and Knowledge Discovery. London: Springer-Verlag, 2002:15–26.
Yi Lan, Liu Bing, Li Xiaoli. Eliminating Noisy Information in Web Pages for Data Mining[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD-2003). New York: IEEE Press, 2003: 296–305.
Zhao Chengli, Yi Dongyun. A Method of Eliminating Noises in Web Pages by Style Tree Model and Its Applications[J]. Wuhan University Journal of Natural Sciences, 2004, 9(5):611–616.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Zhu, F., Gong, C., Yao, H. et al. Enhancing site style tree construction algorithm. Wuhan Univ. J. Nat. Sci. 14, 129–133 (2009). https://doi.org/10.1007/s11859-009-0207-8
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11859-009-0207-8